 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Increasing the skill of short-term wind speed ensemble forecasts combining forecasts and observations via a new dynamic calibration
Jan 28, 2022
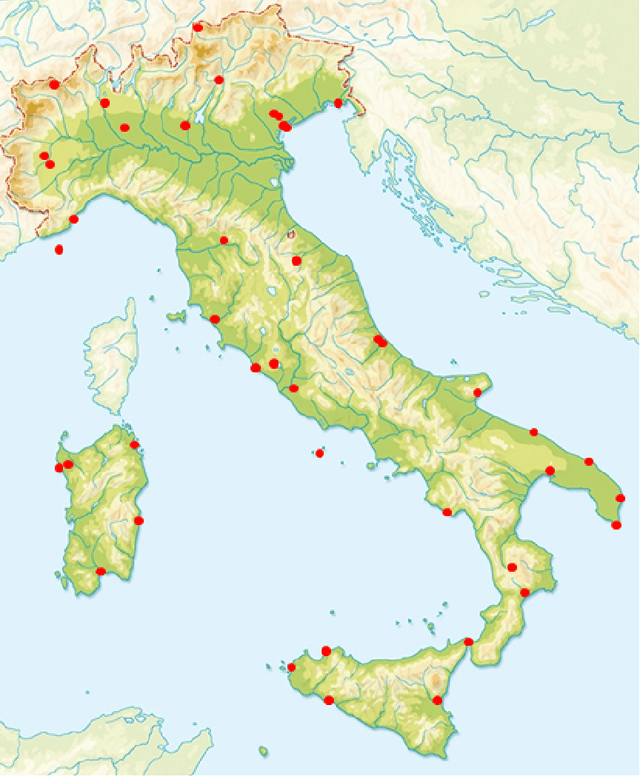
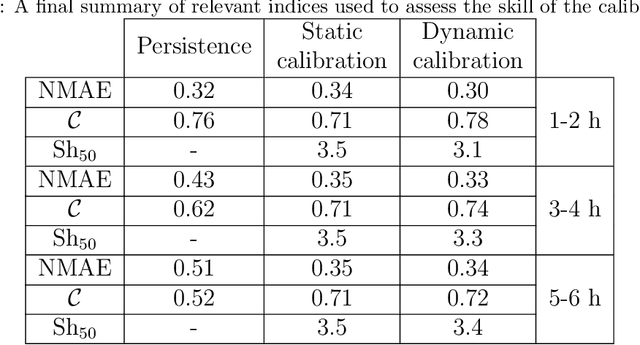
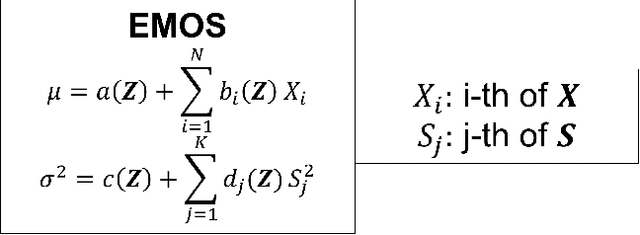
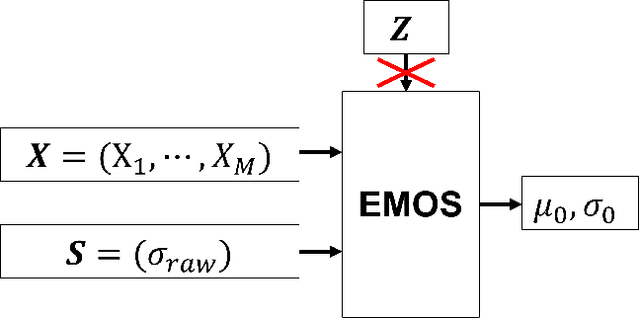
All numerical weather prediction models used for the wind industry need to produce their forecasts starting from the main synoptic hours 00, 06, 12, and 18 UTC, once the analysis becomes available. The six-hour latency time between two consecutive model runs calls for strategies to fill the gap by providing new accurate predictions having, at least, hourly frequency. This is done to accommodate the request of frequent, accurate and fresh information from traders and system regulators to continuously adapt their work strategies. Here, we propose a strategy where quasi-real time observed wind speed and weather model predictions are combined by means of a novel Ensemble Model Output Statistics (EMOS) strategy. The success of our strategy is measured by comparisons against observed wind speed from SYNOP stations over Italy in the years 2018 and 2019.
Design and Implementation of Electronic Infrastructure For Academic Establishment
Feb 08, 2022Most establishments including academic institutions under goes the lengthy process of study-based document handling such as direct mailing, indexing and tracking. This daily task is time consuming and resource-intensive. Using a private network dedicated for such document management would benefit the establishment increasing operational efficiency. In this study, the Information and Communication Engineering (ICE) Department was used as a model to determine the requirements needed to build the intranet network. A packet tracer simulator was used to build a virtual intranet architecture.Then the simulation report was examined to ensure optimum functionality. Upon establishing a stable behavior an intranet infrastructure building commenced using the available hardware components and software.The system architecture was based on Windows 2012R2 server to manage 3 separated sub-networks connected to three switches and one router. Running the intranet for one semester proved its success in providing a fast, cheap and simplified service for all department needs. The accomplished system is a step forward to achieve a full electronic department in scientific establishments.
Deep Learning Algorithm for Threat Detection in Hackers Forum (Deep Web)
Feb 03, 2022In our current society, the inter-connectivity of devices provides easy access for netizens to utilize cyberspace technology for illegal activities. The deep web platform is a consummative ecosystem shielded by boundaries of trust, information sharing, trade-off, and review systems. Domain knowledge is shared among experts in hacker's forums which contain indicators of compromise that can be explored for cyberthreat intelligence. Developing tools that can be deployed for threat detection is integral in securing digital communication in cyberspace. In this paper, we addressed the use of TOR relay nodes for anonymizing communications in deep web forums. We propose a novel approach for detecting cyberthreats using a deep learning algorithm Long Short-Term Memory (LSTM). The developed model outperformed the experimental results of other researchers in this problem domain with an accuracy of 94\% and precision of 90\%. Our model can be easily deployed by organizations in securing digital communications and detection of vulnerability exposure before cyberattack.
Joint Information Preservation for Heterogeneous Domain Adaptation
May 22, 2019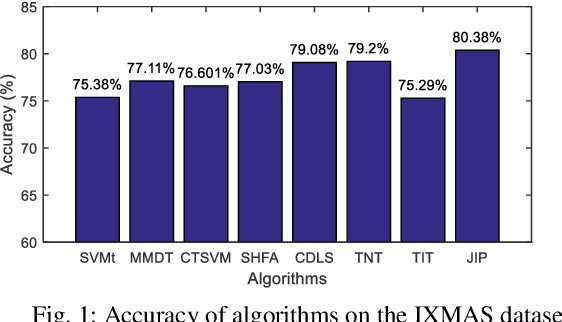
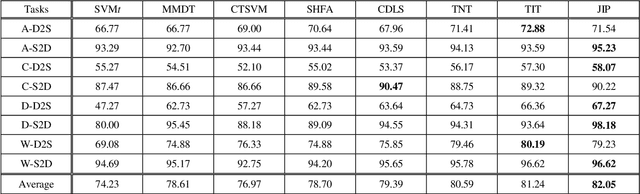
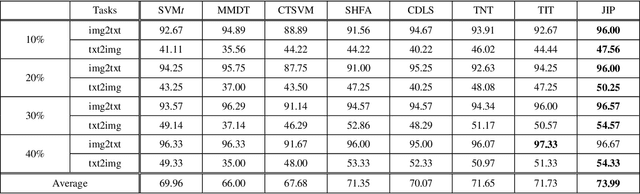
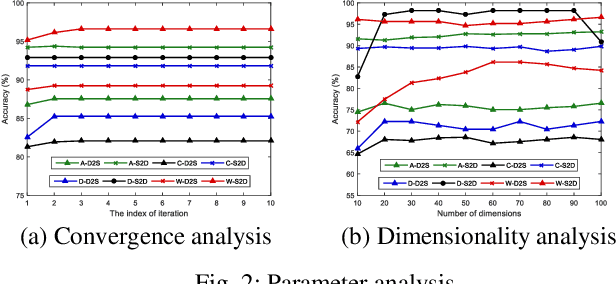
Domain adaptation aims to assist the modeling tasks of the target domain with knowledge of the source domain. The two domains often lie in different feature spaces due to diverse data collection methods, which leads to the more challenging task of heterogeneous domain adaptation (HDA). A core issue of HDA is how to preserve the information of the original data during adaptation. In this paper, we propose a joint information preservation method to deal with the problem. The method preserves the information of the original data from two aspects. On the one hand, although paired samples often exist between the two domains of the HDA, current algorithms do not utilize such information sufficiently. The proposed method preserves the paired information by maximizing the correlation of the paired samples in the shared subspace. On the other hand, the proposed method improves the strategy of preserving the structural information of the original data, where the local and global structural information are preserved simultaneously. Finally, the joint information preservation is integrated by distribution matching. Experimental results show the superiority of the proposed method over the state-of-the-art HDA algorithms.
Speaker conditioning of acoustic models using affine transformation for multi-speaker speech recognition
Oct 30, 2021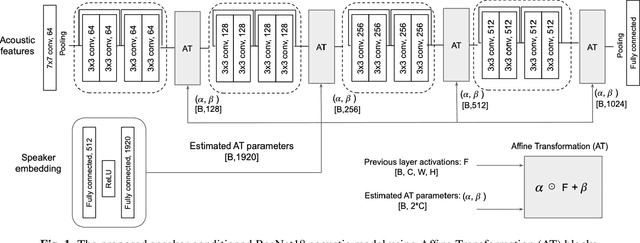
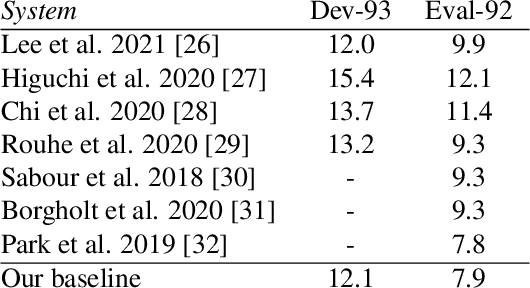
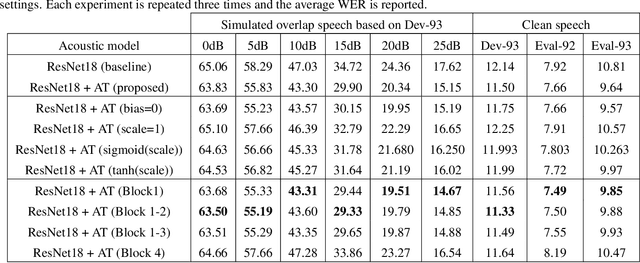
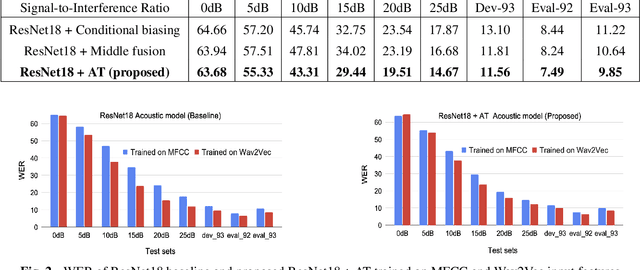
This study addresses the problem of single-channel Automatic Speech Recognition of a target speaker within an overlap speech scenario. In the proposed method, the hidden representations in the acoustic model are modulated by speaker auxiliary information to recognize only the desired speaker. Affine transformation layers are inserted into the acoustic model network to integrate speaker information with the acoustic features. The speaker conditioning process allows the acoustic model to perform computation in the context of target-speaker auxiliary information. The proposed speaker conditioning method is a general approach and can be applied to any acoustic model architecture. Here, we employ speaker conditioning on a ResNet acoustic model. Experiments on the WSJ corpus show that the proposed speaker conditioning method is an effective solution to fuse speaker auxiliary information with acoustic features for multi-speaker speech recognition, achieving +9% and +20% relative WER reduction for clean and overlap speech scenarios, respectively, compared to the original ResNet acoustic model baseline.
Graph-based Solutions with Residuals for Intrusion Detection: the Modified E-GraphSAGE and E-ResGAT Algorithms
Nov 26, 2021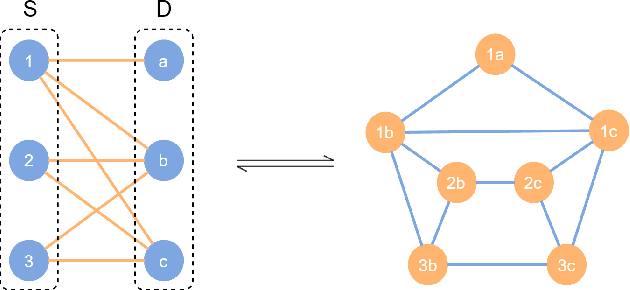
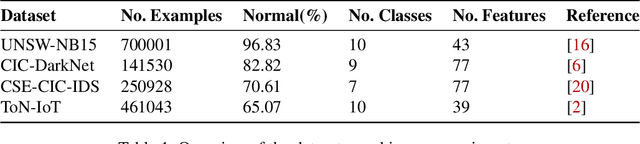
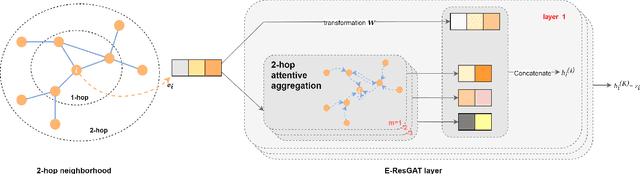
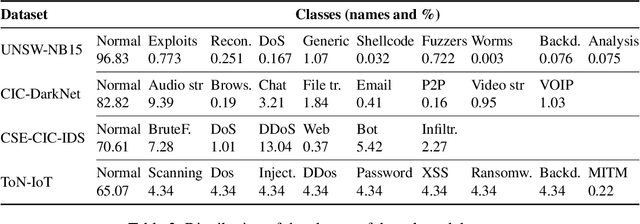
The high volume of increasingly sophisticated cyber threats is drawing growing attention to cybersecurity, where many challenges remain unresolved. Namely, for intrusion detection, new algorithms that are more robust, effective, and able to use more information are needed. Moreover, the intrusion detection task faces a serious challenge associated with the extreme class imbalance between normal and malicious traffics. Recently, graph-neural network (GNN) achieved state-of-the-art performance to model the network topology in cybersecurity tasks. However, only a few works exist using GNNs to tackle the intrusion detection problem. Besides, other promising avenues such as applying the attention mechanism are still under-explored. This paper presents two novel graph-based solutions for intrusion detection, the modified E-GraphSAGE, and E-ResGATalgorithms, which rely on the established GraphSAGE and graph attention network (GAT), respectively. The key idea is to integrate residual learning into the GNN leveraging the available graph information. Residual connections are added as a strategy to deal with the high-class imbalance, aiming at retaining the original information and improving the minority classes' performance. An extensive experimental evaluation of four recent intrusion detection datasets shows the excellent performance of our approaches, especially when predicting minority classes.
Generative Coarse-Graining of Molecular Conformations
Jan 28, 2022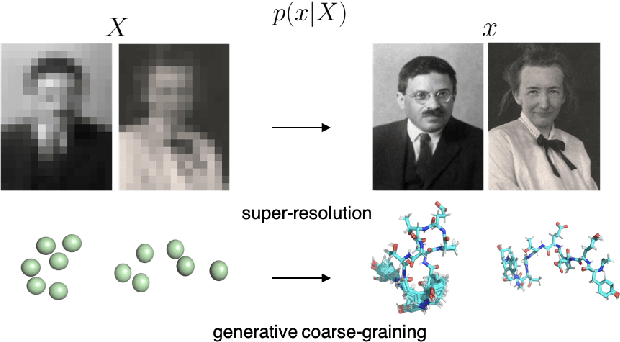

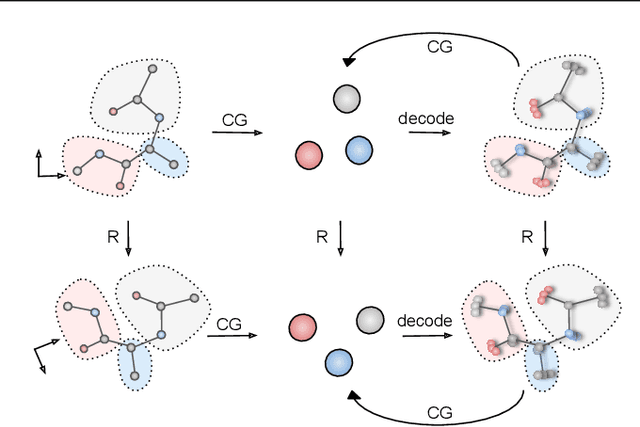
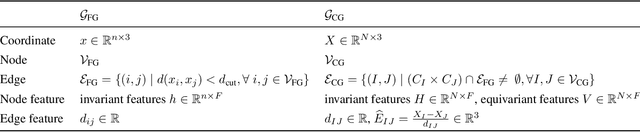
Coarse-graining (CG) of molecular simulations simplifies the particle representation by grouping selected atoms into pseudo-beads and therefore drastically accelerates simulation. However, such CG procedure induces information losses, which makes accurate backmapping, i.e., restoring fine-grained (FG) coordinates from CG coordinates, a long-standing challenge. Inspired by the recent progress in generative models and equivariant networks, we propose a novel model that rigorously embeds the vital probabilistic nature and geometric consistency requirements of the backmapping transformation. Our model encodes the FG uncertainties into an invariant latent space and decodes them back to FG geometries via equivariant convolutions. To standardize the evaluation of this domain, we further provide three comprehensive benchmarks based on molecular dynamics trajectories. Extensive experiments show that our approach always recovers more realistic structures and outperforms existing data-driven methods with a significant margin.
MAMDR: A Model Agnostic Learning Method for Multi-Domain Recommendation
Feb 25, 2022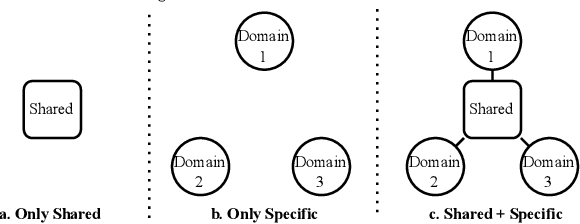
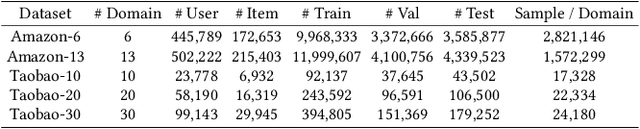
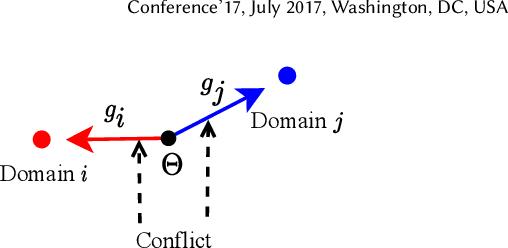
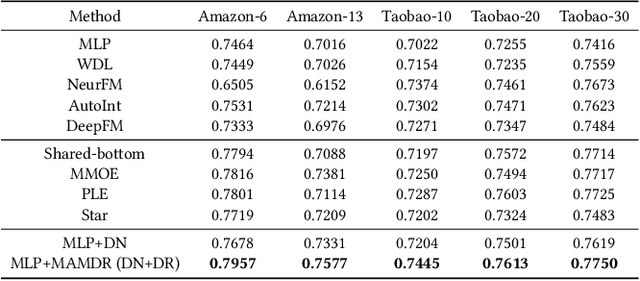
Large-scale e-commercial platforms in the real-world usually contain various recommendation scenarios (domains) to meet demands of diverse customer groups. Multi-Domain Recommendation (MDR), which aims to jointly improve recommendations on all domains, has attracted increasing attention from practitioners and researchers. Existing MDR methods often employ a shared structure to leverage reusable features for all domains and several specific parts to capture domain-specific information. However, data from different domains may conflict with each other and cause shared parameters to stay at a compromised position on the optimization landscape. This could deteriorate the overall performance. Despite the specific parameters are separately learned for each domain, they can easily overfit on data sparsity domains. Furthermore, data distribution differs across domains, making it challenging to develop a general model that can be applied to all circumstances. To address these problems, we propose a novel model agnostic learning method, namely MAMDR, for the multi-domain recommendation. Specifically, we first propose a Domain Negotiation (DN) strategy to alleviate the conflict between domains and learn better shared parameters. Then, we develop a Domain Regularization (DR) scheme to improve the generalization ability of specific parameters by learning from other domains. Finally, we integrate these components into a unified framework and present MAMDR which can be applied to any model structure to perform multi-domain recommendation. Extensive experiments on various real-world datasets and online applications demonstrate both the effectiveness and generalizability of MAMDR.
SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations
Dec 09, 2021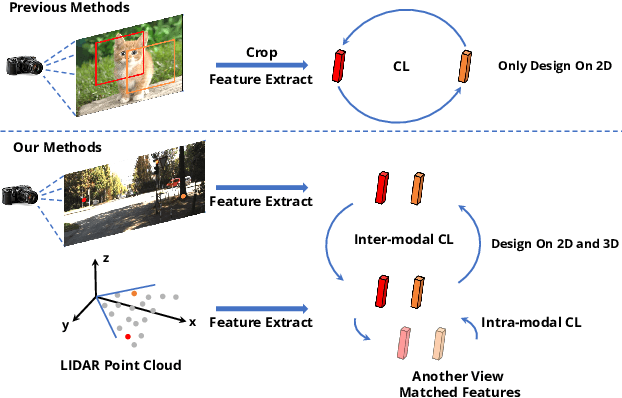
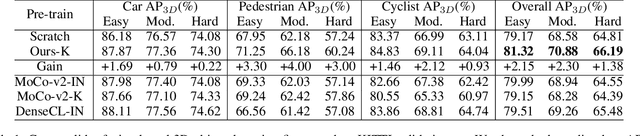
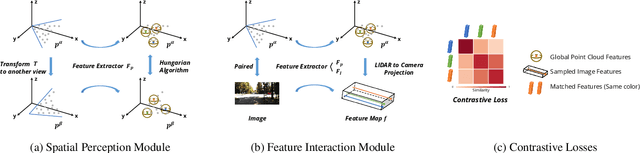

Pre-training has become a standard paradigm in many computer vision tasks. However, most of the methods are generally designed on the RGB image domain. Due to the discrepancy between the two-dimensional image plane and the three-dimensional space, such pre-trained models fail to perceive spatial information and serve as sub-optimal solutions for 3D-related tasks. To bridge this gap, we aim to learn a spatial-aware visual representation that can describe the three-dimensional space and is more suitable and effective for these tasks. To leverage point clouds, which are much more superior in providing spatial information compared to images, we propose a simple yet effective 2D Image and 3D Point cloud Unsupervised pre-training strategy, called SimIPU. Specifically, we develop a multi-modal contrastive learning framework that consists of an intra-modal spatial perception module to learn a spatial-aware representation from point clouds and an inter-modal feature interaction module to transfer the capability of perceiving spatial information from the point cloud encoder to the image encoder, respectively. Positive pairs for contrastive losses are established by the matching algorithm and the projection matrix. The whole framework is trained in an unsupervised end-to-end fashion. To the best of our knowledge, this is the first study to explore contrastive learning pre-training strategies for outdoor multi-modal datasets, containing paired camera images and LIDAR point clouds. Codes and models are available at https://github.com/zhyever/SimIPU.
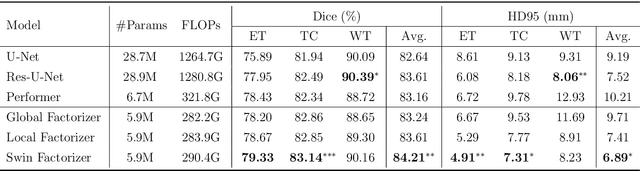
Factorizer: A Scalable Interpretable Approach to Context Modeling for Medical Image Segmentation
Feb 28, 2022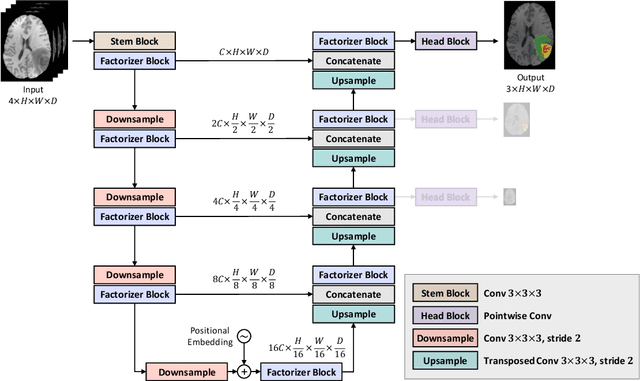
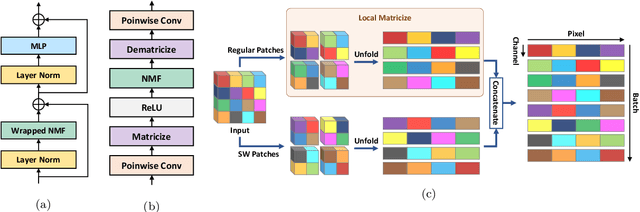
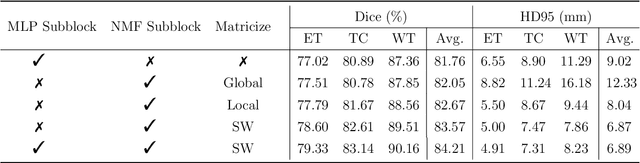
Convolutional Neural Networks (CNNs) with U-shaped architectures have dominated medical image segmentation, which is crucial for various clinical purposes. However, the inherent locality of convolution makes CNNs fail to fully exploit global context, essential for better recognition of some structures, e.g., brain lesions. Transformers have recently proved promising performance on vision tasks, including semantic segmentation, mainly due to their capability of modeling long-range dependencies. Nevertheless, the quadratic complexity of attention makes existing Transformer-based models use self-attention layers only after somehow reducing the image resolution, which limits the ability to capture global contexts present at higher resolutions. Therefore, this work introduces a family of models, dubbed Factorizer, which leverages the power of low-rank matrix factorization for constructing an end-to-end segmentation model. Specifically, we propose a linearly scalable approach to context modeling, formulating Nonnegative Matrix Factorization (NMF) as a differentiable layer integrated into a U-shaped architecture. The shifted window technique is also utilized in combination with NMF to effectively aggregate local information. Factorizers compete favorably with CNNs and Transformers in terms of accuracy, scalability, and interpretability, achieving state-of-the-art results on the BraTS dataset for brain tumor segmentation, with Dice scores of 79.33%, 83.14%, and 90.16% for enhancing tumor, tumor core, and whole tumor, respectively. Highly meaningful NMF components give an additional interpretability advantage to Factorizers over CNNs and Transformers. Moreover, our ablation studies reveal a distinctive feature of Factorizers that enables a significant speed-up in inference for a trained Factorizer without any extra steps and without sacrificing much accuracy.