 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph-Relational Domain Adaptation
Feb 08, 2022

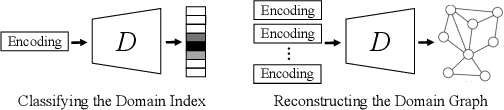
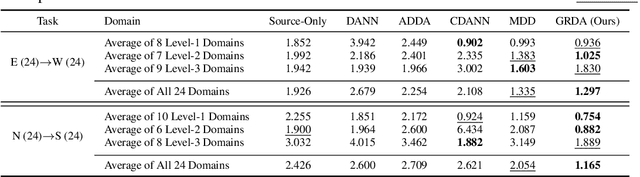
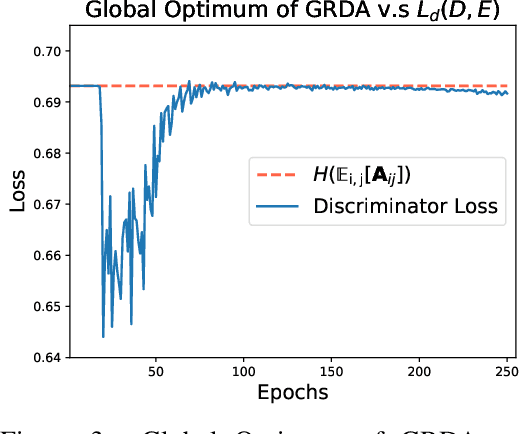
Existing domain adaptation methods tend to treat every domain equally and align them all perfectly. Such uniform alignment ignores topological structures among different domains; therefore it may be beneficial for nearby domains, but not necessarily for distant domains. In this work, we relax such uniform alignment by using a domain graph to encode domain adjacency, e.g., a graph of states in the US with each state as a domain and each edge indicating adjacency, thereby allowing domains to align flexibly based on the graph structure. We generalize the existing adversarial learning framework with a novel graph discriminator using encoding-conditioned graph embeddings. Theoretical analysis shows that at equilibrium, our method recovers classic domain adaptation when the graph is a clique, and achieves non-trivial alignment for other types of graphs. Empirical results show that our approach successfully generalizes uniform alignment, naturally incorporates domain information represented by graphs, and improves upon existing domain adaptation methods on both synthetic and real-world datasets. Code will soon be available at https://github.com/Wang-ML-Lab/GRDA.
Information Newton's flow: second-order optimization method in probability space
Jan 13, 2020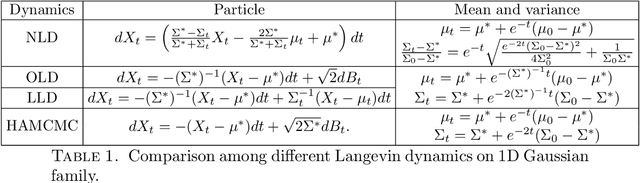
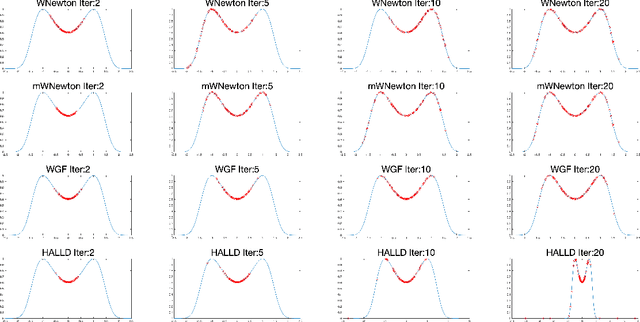

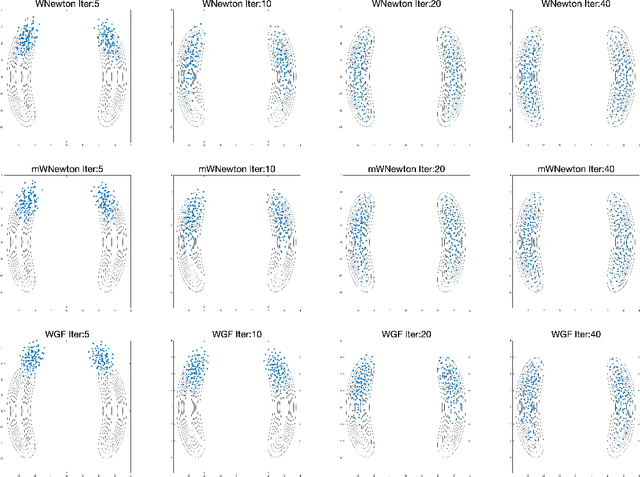
We introduce a framework for Newton's flows in probability space with information metrics, named information Newton's flows. Here two information metrics are considered, including both the Fisher-Rao metric and the Wasserstein-2 metric. Several examples of information Newton's flows for learning objective/loss functions are provided, such as Kullback-Leibler (KL) divergence, Maximum mean discrepancy (MMD), and cross entropy. The asymptotic convergence results of proposed Newton's methods are provided. A known fact is that overdamped Langevin dynamics correspond to Wasserstein gradient flows of KL divergence. Extending this fact to Wasserstein Newton's flows of KL divergence, we derive Newton's Langevin dynamics. We provide examples of Newton's Langevin dynamics in both one-dimensional space and Gaussian families. For the numerical implementation, we design sampling efficient variational methods to approximate Wasserstein Newton's directions. Several numerical examples in Gaussian families and Bayesian logistic regression are shown to demonstrate the effectiveness of the proposed method.
Recommendation Unlearning
Jan 18, 2022
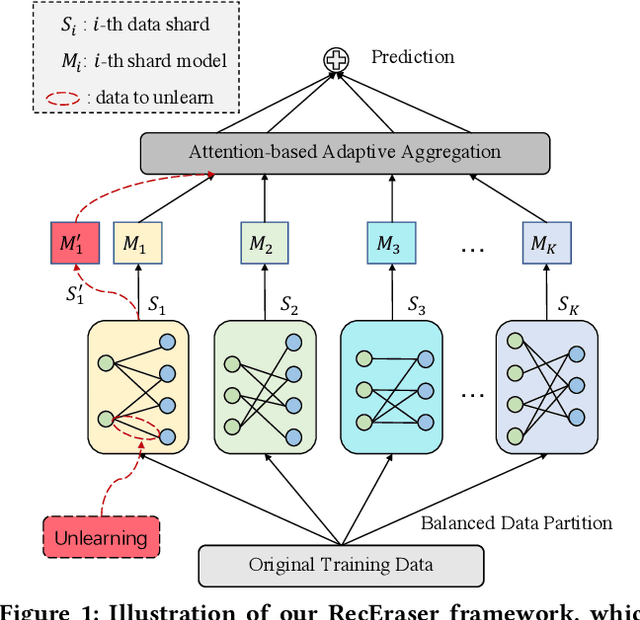
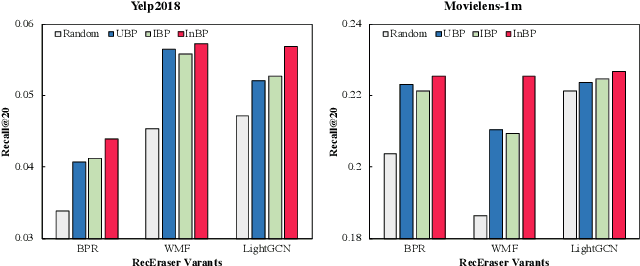
Recommender systems provide essential web services by learning users' personal preferences from collected data. However, in many cases, systems also need to forget some training data. From the perspective of privacy, several privacy regulations have recently been proposed, requiring systems to eliminate any impact of the data whose owner requests to forget. From the perspective of utility, if a system's utility is damaged by some bad data, the system needs to forget these data to regain utility. From the perspective of usability, users can delete noise and incorrect entries so that a system can provide more useful recommendations. While unlearning is very important, it has not been well-considered in existing recommender systems. Although there are some researches have studied the problem of machine unlearning in the domains of image and text data, existing methods can not been directly applied to recommendation as they are unable to consider the collaborative information. In this paper, we propose RecEraser, a general and efficient machine unlearning framework tailored to recommendation task. The main idea of RecEraser is to partition the training set into multiple shards and train a constituent model for each shard. Specifically, to keep the collaborative information of the data, we first design three novel data partition algorithms to divide training data into balanced groups based on their similarity. Then, considering that different shard models do not uniformly contribute to the final prediction, we further propose an adaptive aggregation method to improve the global model utility. Experimental results on three public benchmarks show that RecEraser can not only achieve efficient unlearning, but also outperform the state-of-the-art unlearning methods in terms of model utility. The source code can be found at https://github.com/chenchongthu/Recommendation-Unlearning
PanoDepth: A Two-Stage Approach for Monocular Omnidirectional Depth Estimation
Feb 02, 2022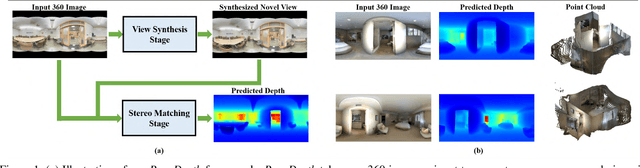
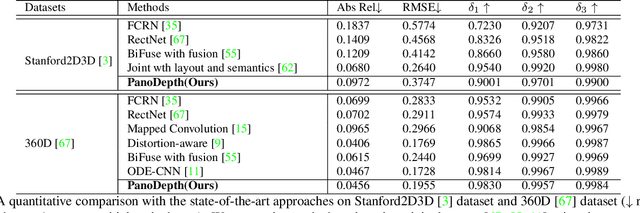
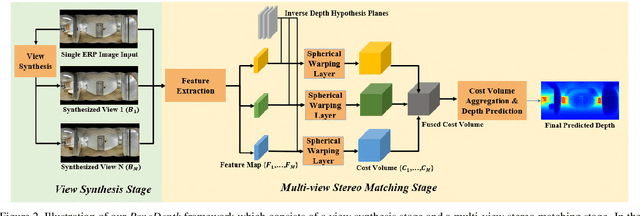

Omnidirectional 3D information is essential for a wide range of applications such as Virtual Reality, Autonomous Driving, Robotics, etc. In this paper, we propose a novel, model-agnostic, two-stage pipeline for omnidirectional monocular depth estimation. Our proposed framework PanoDepth takes one 360 image as input, produces one or more synthesized views in the first stage, and feeds the original image and the synthesized images into the subsequent stereo matching stage. In the second stage, we propose a differentiable Spherical Warping Layer to handle omnidirectional stereo geometry efficiently and effectively. By utilizing the explicit stereo-based geometric constraints in the stereo matching stage, PanoDepth can generate dense high-quality depth. We conducted extensive experiments and ablation studies to evaluate PanoDepth with both the full pipeline as well as the individual modules in each stage. Our results show that PanoDepth outperforms the state-of-the-art approaches by a large margin for 360 monocular depth estimation.
Recurrent Auto-Encoder With Multi-Resolution Ensemble and Predictive Coding for Multivariate Time-Series Anomaly Detection
Feb 21, 2022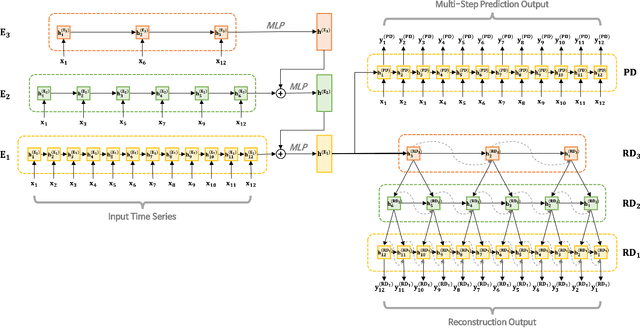

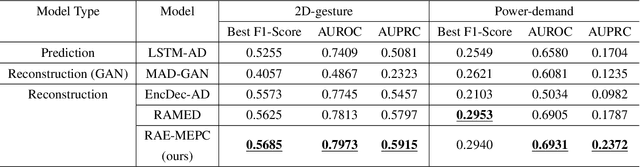
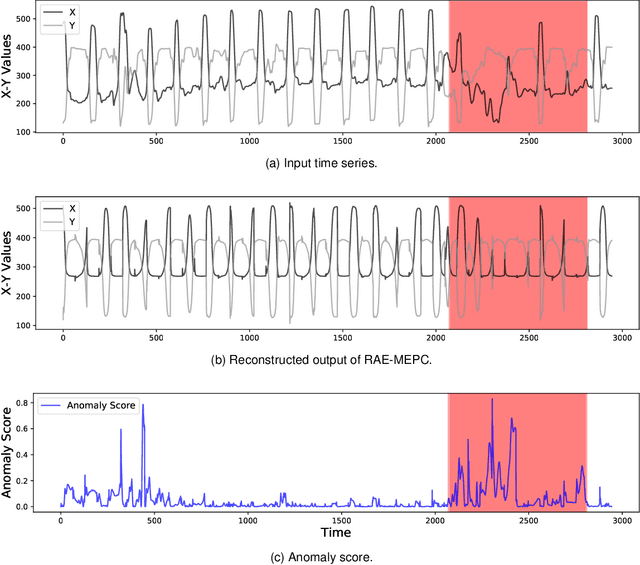
As large-scale time-series data can easily be found in real-world applications, multivariate time-series anomaly detection has played an essential role in diverse industries. It enables productivity improvement and maintenance cost reduction by preventing malfunctions and detecting anomalies based on time-series data. However, multivariate time-series anomaly detection is challenging because real-world time-series data exhibit complex temporal dependencies. For this task, it is crucial to learn a rich representation that effectively contains the nonlinear temporal dynamics of normal behavior. In this study, we propose an unsupervised multivariate time-series anomaly detection model named RAE-MEPC which learns informative normal representations based on multi-resolution ensemble and predictive coding. We introduce multi-resolution ensemble encoding to capture the multi-scale dependency from the input time series. The encoder hierarchically aggregates the temporal features extracted from the sub-encoders with different encoding lengths. From these encoded features, the reconstruction decoder reconstructs the input time series based on multi-resolution ensemble decoding where lower-resolution information helps to decode sub-decoders with higher-resolution outputs. Predictive coding is further introduced to encourage the model to learn the temporal dependencies of the time series. Experiments on real-world benchmark datasets show that the proposed model outperforms the benchmark models for multivariate time-series anomaly detection.
Specializing Word Embeddings (for Parsing) by Information Bottleneck
Oct 01, 2019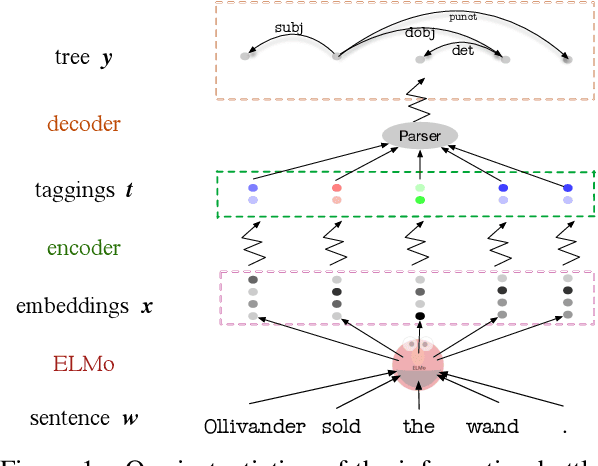
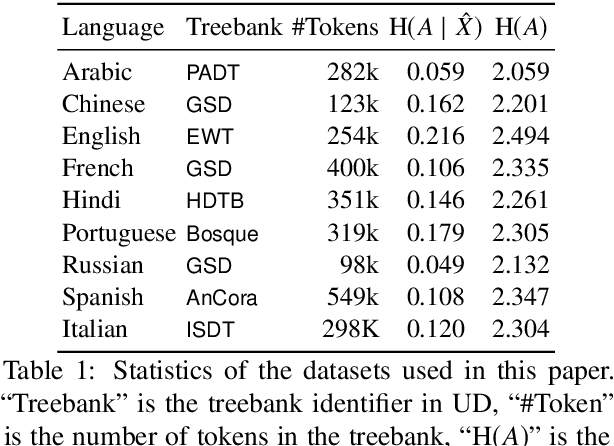
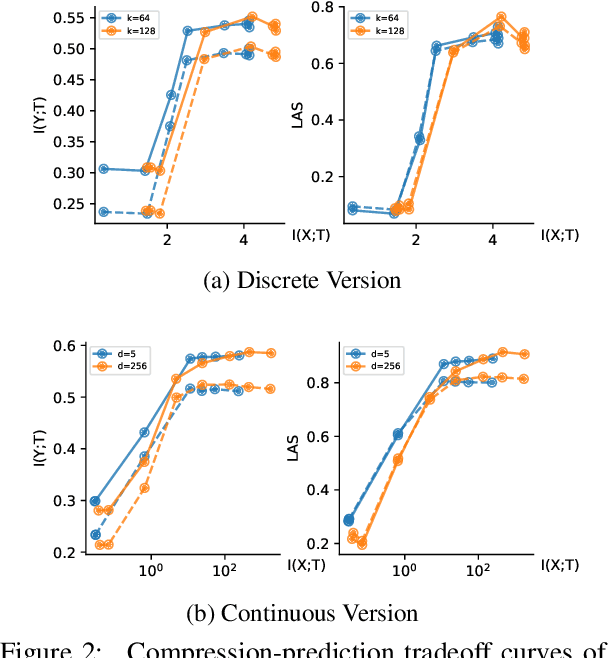
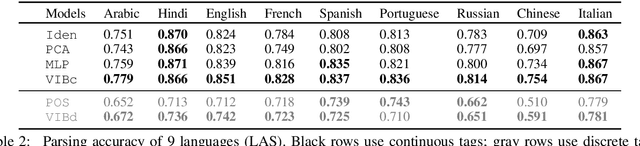
Pre-trained word embeddings like ELMo and BERT contain rich syntactic and semantic information, resulting in state-of-the-art performance on various tasks. We propose a very fast variational information bottleneck (VIB) method to nonlinearly compress these embeddings, keeping only the information that helps a discriminative parser. We compress each word embedding to either a discrete tag or a continuous vector. In the discrete version, our automatically compressed tags form an alternative tag set: we show experimentally that our tags capture most of the information in traditional POS tag annotations, but our tag sequences can be parsed more accurately at the same level of tag granularity. In the continuous version, we show experimentally that moderately compressing the word embeddings by our method yields a more accurate parser in 8 of 9 languages, unlike simple dimensionality reduction.
DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR
Feb 08, 2022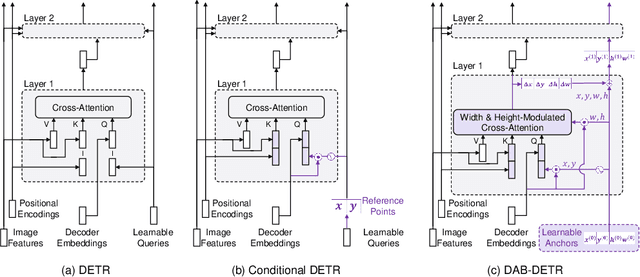


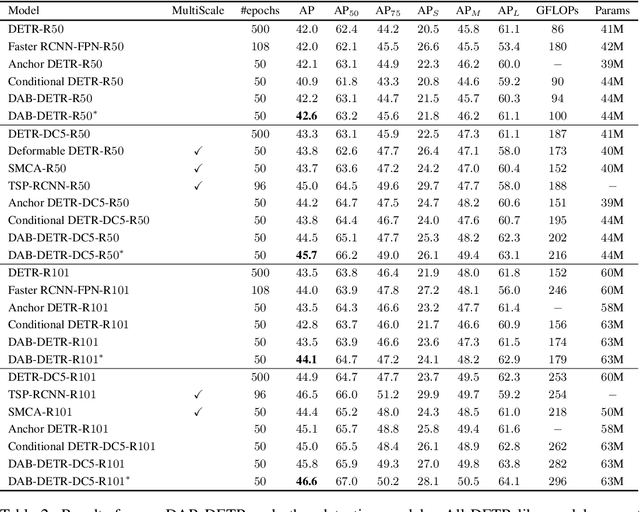
We present in this paper a novel query formulation using dynamic anchor boxes for DETR (DEtection TRansformer) and offer a deeper understanding of the role of queries in DETR. This new formulation directly uses box coordinates as queries in Transformer decoders and dynamically updates them layer-by-layer. Using box coordinates not only helps using explicit positional priors to improve the query-to-feature similarity and eliminate the slow training convergence issue in DETR, but also allows us to modulate the positional attention map using the box width and height information. Such a design makes it clear that queries in DETR can be implemented as performing soft ROI pooling layer-by-layer in a cascade manner. As a result, it leads to the best performance on MS-COCO benchmark among the DETR-like detection models under the same setting, e.g., AP 45.7\% using ResNet50-DC5 as backbone trained in 50 epochs. We also conducted extensive experiments to confirm our analysis and verify the effectiveness of our methods. Code is available at \url{https://github.com/SlongLiu/DAB-DETR}.
Multivariate Time Series Forecasting with Dynamic Graph Neural ODEs
Feb 17, 2022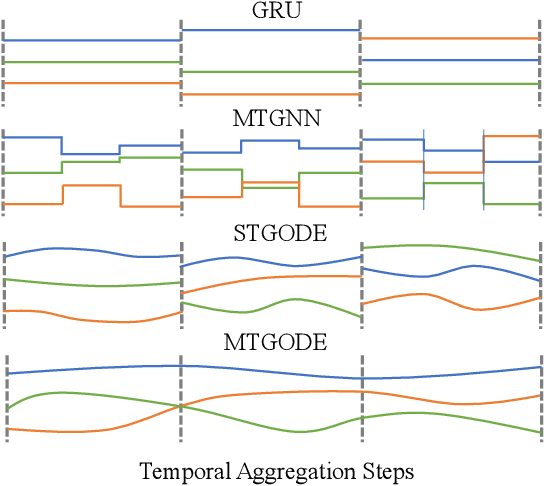

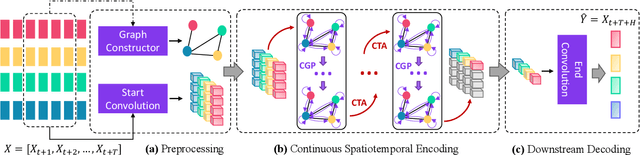
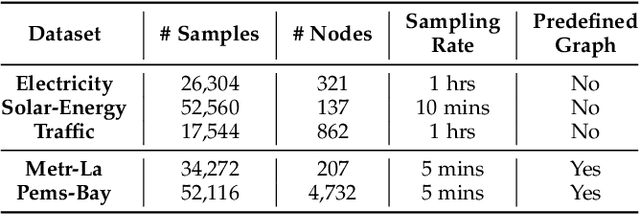
Multivariate time series forecasting has long received significant attention in real-world applications, such as energy consumption and traffic prediction. While recent methods demonstrate good forecasting abilities, they suffer from three fundamental limitations. (i) Discrete neural architectures: Interlacing individually parameterized spatial and temporal blocks to encode rich underlying patterns leads to discontinuous latent state trajectories and higher forecasting numerical errors. (ii) High complexity: Discrete approaches complicate models with dedicated designs and redundant parameters, leading to higher computational and memory overheads. (iii) Reliance on graph priors: Relying on predefined static graph structures limits their effectiveness and practicability in real-world applications. In this paper, we address all the above limitations by proposing a continuous model to forecast Multivariate Time series with dynamic Graph neural Ordinary Differential Equations (MTGODE). Specifically, we first abstract multivariate time series into dynamic graphs with time-evolving node features and unknown graph structures. Then, we design and solve a neural ODE to complement missing graph topologies and unify both spatial and temporal message passing, allowing deeper graph propagation and fine-grained temporal information aggregation to characterize stable and precise latent spatial-temporal dynamics. Our experiments demonstrate the superiorities of MTGODE from various perspectives on five time series benchmark datasets.
The fine line between dead neurons and sparsity in binarized spiking neural networks
Jan 28, 2022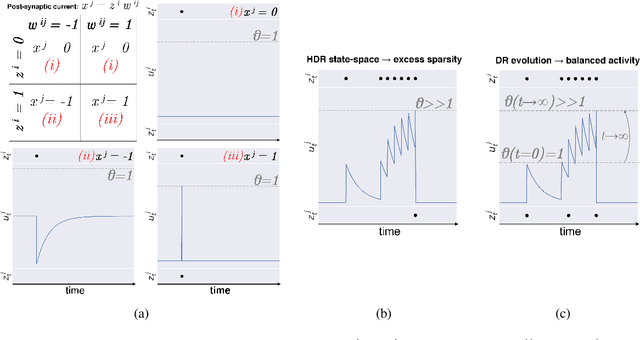
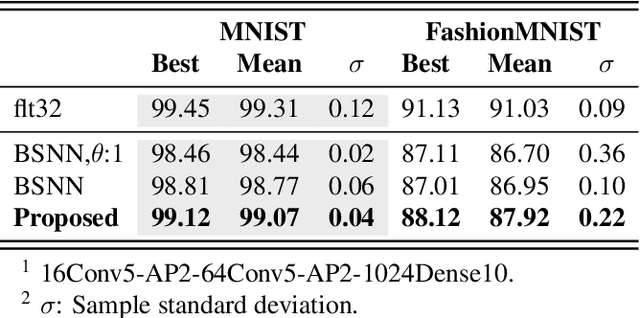
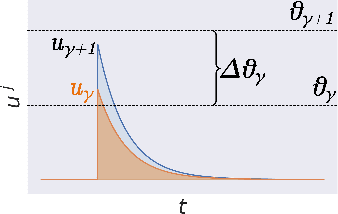
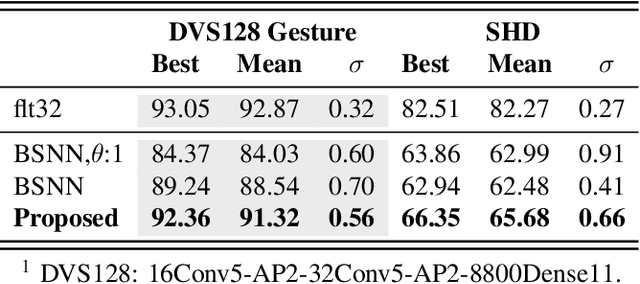
Spiking neural networks can compensate for quantization error by encoding information either in the temporal domain, or by processing discretized quantities in hidden states of higher precision. In theory, a wide dynamic range state-space enables multiple binarized inputs to be accumulated together, thus improving the representational capacity of individual neurons. This may be achieved by increasing the firing threshold, but make it too high and sparse spike activity turns into no spike emission. In this paper, we propose the use of `threshold annealing' as a warm-up method for firing thresholds. We show it enables the propagation of spikes across multiple layers where neurons would otherwise cease to fire, and in doing so, achieve highly competitive results on four diverse datasets, despite using binarized weights. Source code is available at https://github.com/jeshraghian/snn-tha/
PolarDenseNet: A Deep Learning Model for CSI Feedback in MIMO Systems
Feb 02, 2022
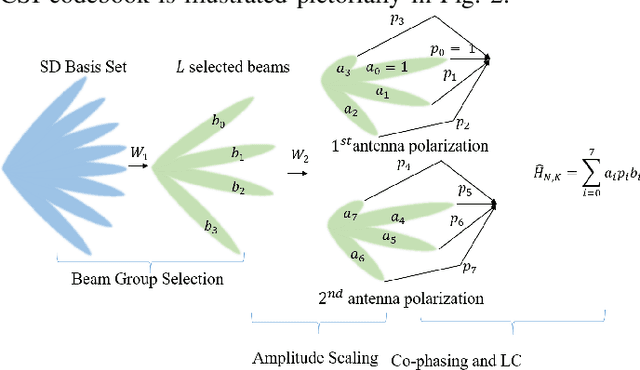
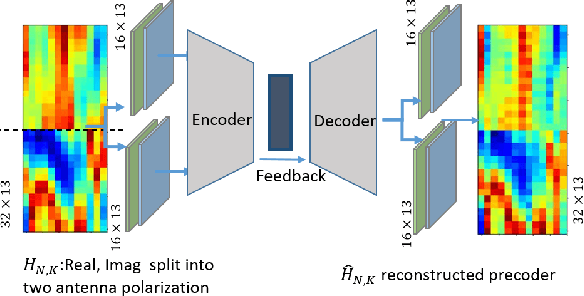
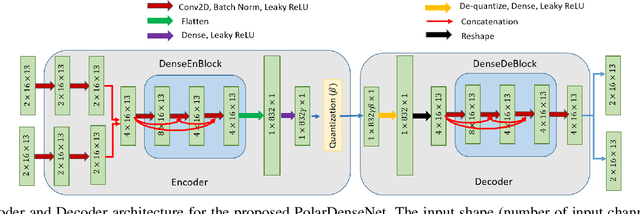
In multiple-input multiple-output (MIMO) systems, the high-resolution channel information (CSI) is required at the base station (BS) to ensure optimal performance, especially in the case of multi-user MIMO (MU-MIMO) systems. In the absence of channel reciprocity in frequency division duplex (FDD) systems, the user needs to send the CSI to the BS. Often the large overhead associated with this CSI feedback in FDD systems becomes the bottleneck in improving the system performance. In this paper, we propose an AI-based CSI feedback based on an auto-encoder architecture that encodes the CSI at UE into a low-dimensional latent space and decodes it back at the BS by effectively reducing the feedback overhead while minimizing the loss during recovery. Our simulation results show that the AI-based proposed architecture outperforms the state-of-the-art high-resolution linear combination codebook using the DFT basis adopted in the 5G New Radio (NR) system.