 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Recurrent Auto-Encoder With Multi-Resolution Ensemble and Predictive Coding for Multivariate Time-Series Anomaly Detection
Feb 21, 2022
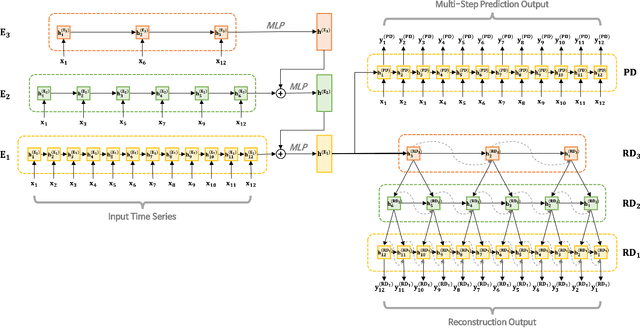

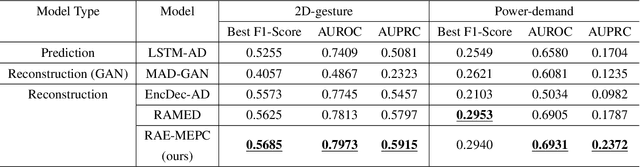
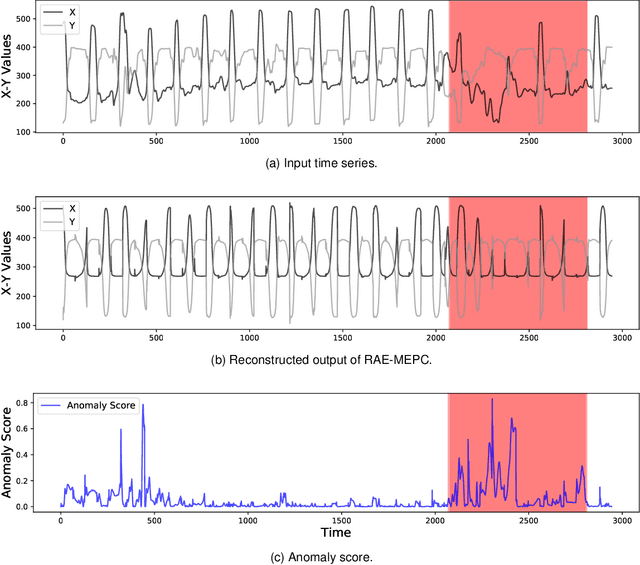
As large-scale time-series data can easily be found in real-world applications, multivariate time-series anomaly detection has played an essential role in diverse industries. It enables productivity improvement and maintenance cost reduction by preventing malfunctions and detecting anomalies based on time-series data. However, multivariate time-series anomaly detection is challenging because real-world time-series data exhibit complex temporal dependencies. For this task, it is crucial to learn a rich representation that effectively contains the nonlinear temporal dynamics of normal behavior. In this study, we propose an unsupervised multivariate time-series anomaly detection model named RAE-MEPC which learns informative normal representations based on multi-resolution ensemble and predictive coding. We introduce multi-resolution ensemble encoding to capture the multi-scale dependency from the input time series. The encoder hierarchically aggregates the temporal features extracted from the sub-encoders with different encoding lengths. From these encoded features, the reconstruction decoder reconstructs the input time series based on multi-resolution ensemble decoding where lower-resolution information helps to decode sub-decoders with higher-resolution outputs. Predictive coding is further introduced to encourage the model to learn the temporal dependencies of the time series. Experiments on real-world benchmark datasets show that the proposed model outperforms the benchmark models for multivariate time-series anomaly detection.
Learning with Asymmetric Kernels: Least Squares and Feature Interpretation
Feb 03, 2022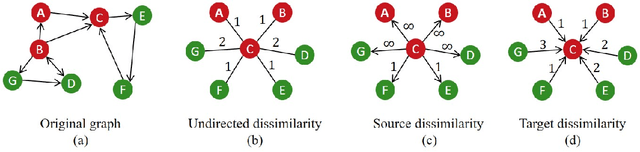
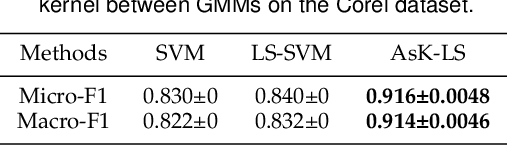
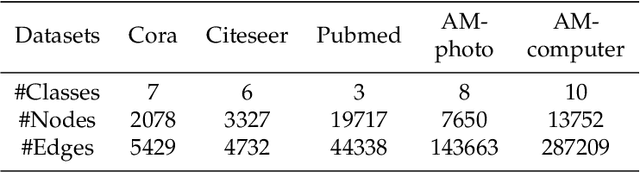
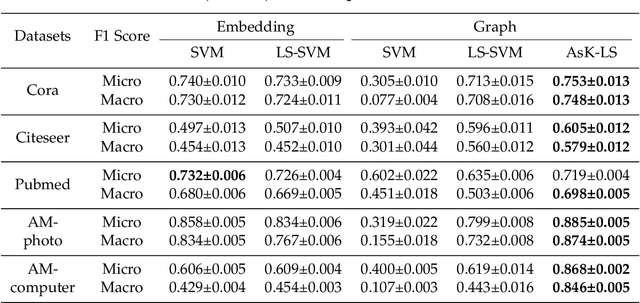
Asymmetric kernels naturally exist in real life, e.g., for conditional probability and directed graphs. However, most of the existing kernel-based learning methods require kernels to be symmetric, which prevents the use of asymmetric kernels. This paper addresses the asymmetric kernel-based learning in the framework of the least squares support vector machine named AsK-LS, resulting in the first classification method that can utilize asymmetric kernels directly. We will show that AsK-LS can learn with asymmetric features, namely source and target features, while the kernel trick remains applicable, i.e., the source and target features exist but are not necessarily known. Besides, the computational burden of AsK-LS is as cheap as dealing with symmetric kernels. Experimental results on the Corel database, directed graphs, and the UCI database will show that in the case asymmetric information is crucial, the proposed AsK-LS can learn with asymmetric kernels and performs much better than the existing kernel methods that have to do symmetrization to accommodate asymmetric kernels.
Improving adversarial robustness of deep neural networks by using semantic information
Aug 18, 2020
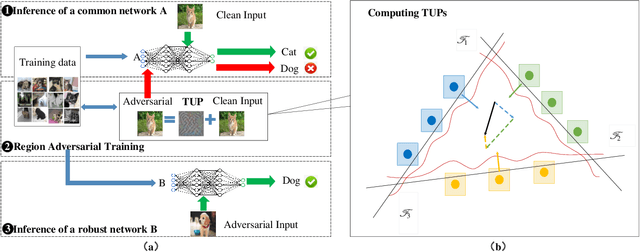
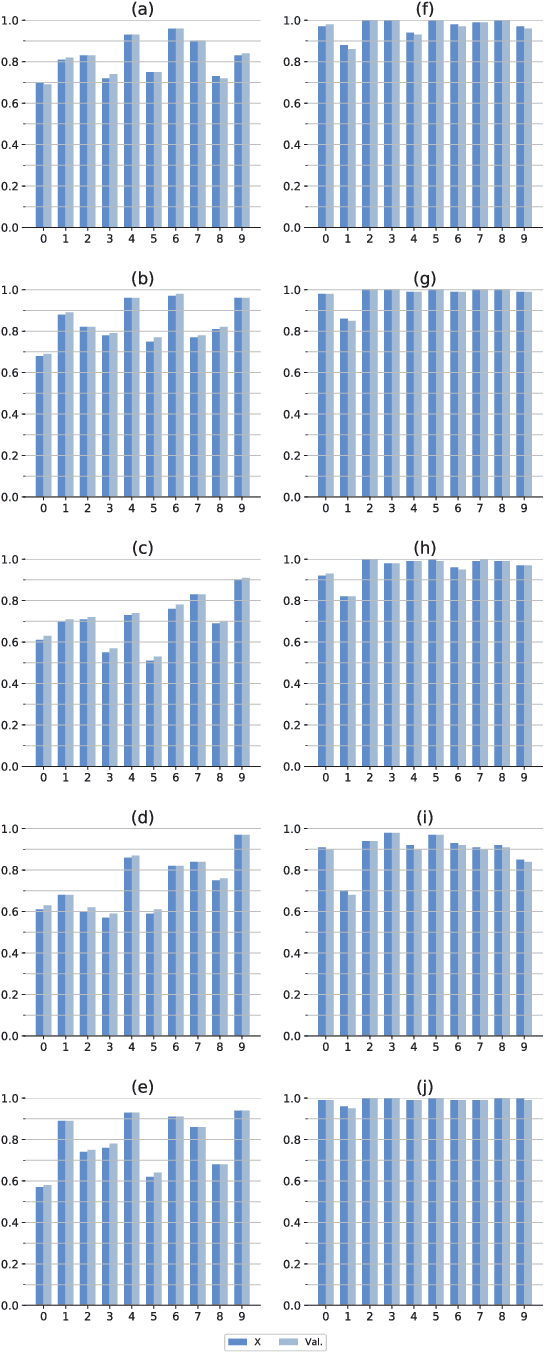
The vulnerability of deep neural networks (DNNs) to adversarial attack, which is an attack that can mislead state-of-the-art classifiers into making an incorrect classification with high confidence by deliberately perturbing the original inputs, raises concerns about the robustness of DNNs to such attacks. Adversarial training, which is the main heuristic method for improving adversarial robustness and the first line of defense against adversarial attacks, requires many sample-by-sample calculations to increase training size and is usually insufficiently strong for an entire network. This paper provides a new perspective on the issue of adversarial robustness, one that shifts the focus from the network as a whole to the critical part of the region close to the decision boundary corresponding to a given class. From this perspective, we propose a method to generate a single but image-agnostic adversarial perturbation that carries the semantic information implying the directions to the fragile parts on the decision boundary and causes inputs to be misclassified as a specified target. We call the adversarial training based on such perturbations "region adversarial training" (RAT), which resembles classical adversarial training but is distinguished in that it reinforces the semantic information missing in the relevant regions. Experimental results on the MNIST and CIFAR-10 datasets show that this approach greatly improves adversarial robustness even using a very small dataset from the training data; moreover, it can defend against FGSM adversarial attacks that have a completely different pattern from the model seen during retraining.
Mask-based Latent Reconstruction for Reinforcement Learning
Jan 28, 2022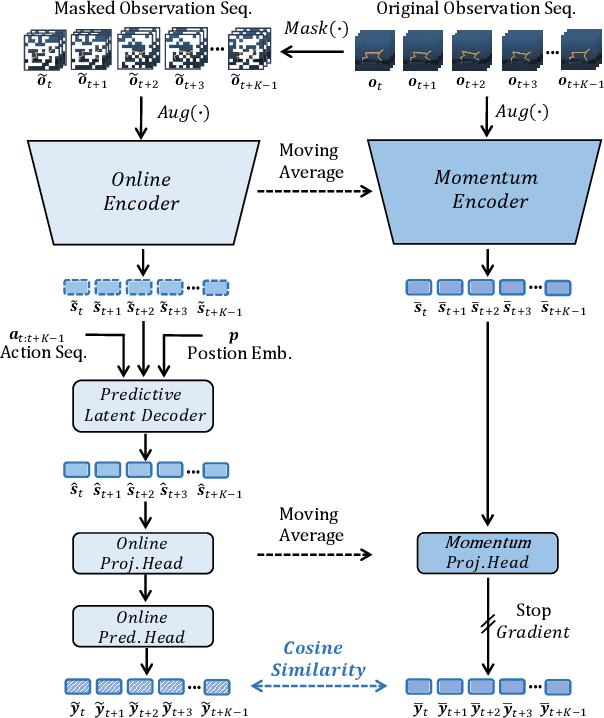
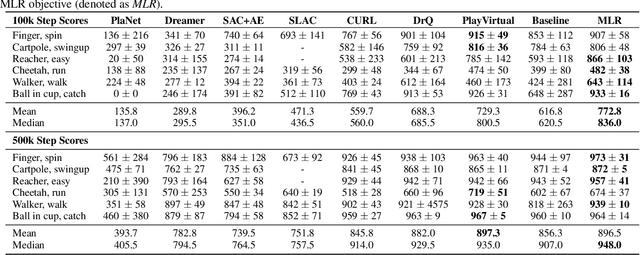
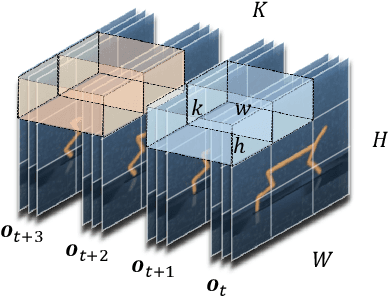
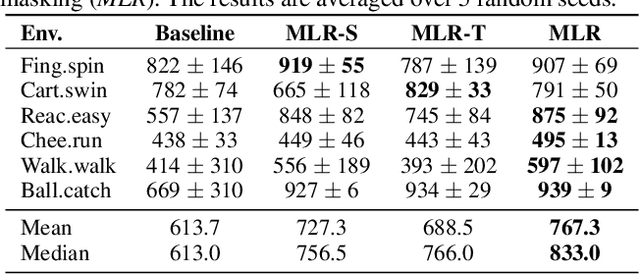
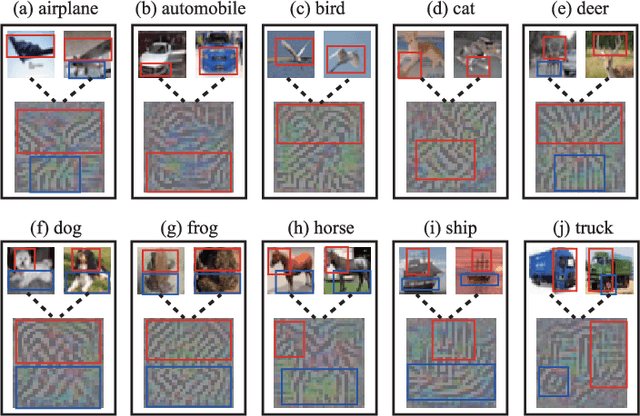
For deep reinforcement learning (RL) from pixels, learning effective state representations is crucial for achieving high performance. However, in practice, limited experience and high-dimensional input prevent effective representation learning. To address this, motivated by the success of masked modeling in other research fields, we introduce mask-based reconstruction to promote state representation learning in RL. Specifically, we propose a simple yet effective self-supervised method, Mask-based Latent Reconstruction (MLR), to predict the complete state representations in the latent space from the observations with spatially and temporally masked pixels. MLR enables the better use of context information when learning state representations to make them more informative, which facilitates RL agent training. Extensive experiments show that our MLR significantly improves the sample efficiency in RL and outperforms the state-of-the-art sample-efficient RL methods on multiple continuous benchmark environments.
Differentially Private Regret Minimization in Episodic Markov Decision Processes
Dec 20, 2021

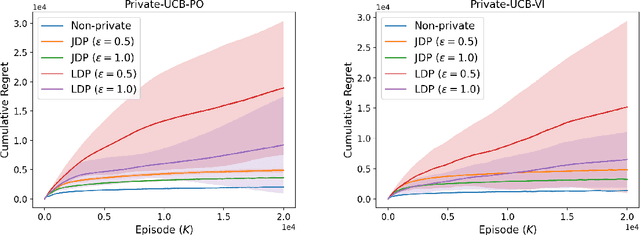
We study regret minimization in finite horizon tabular Markov decision processes (MDPs) under the constraints of differential privacy (DP). This is motivated by the widespread applications of reinforcement learning (RL) in real-world sequential decision making problems, where protecting users' sensitive and private information is becoming paramount. We consider two variants of DP -- joint DP (JDP), where a centralized agent is responsible for protecting users' sensitive data and local DP (LDP), where information needs to be protected directly on the user side. We first propose two general frameworks -- one for policy optimization and another for value iteration -- for designing private, optimistic RL algorithms. We then instantiate these frameworks with suitable privacy mechanisms to satisfy JDP and LDP requirements, and simultaneously obtain sublinear regret guarantees. The regret bounds show that under JDP, the cost of privacy is only a lower order additive term, while for a stronger privacy protection under LDP, the cost suffered is multiplicative. Finally, the regret bounds are obtained by a unified analysis, which, we believe, can be extended beyond tabular MDPs.
Graph-Relational Domain Adaptation
Feb 08, 2022
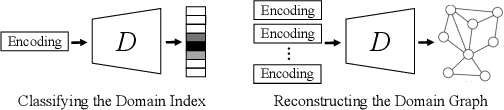
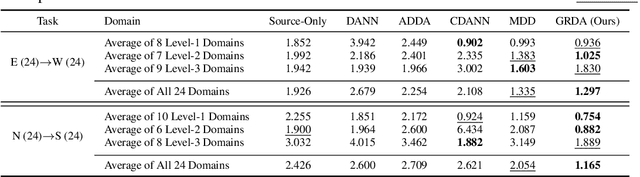
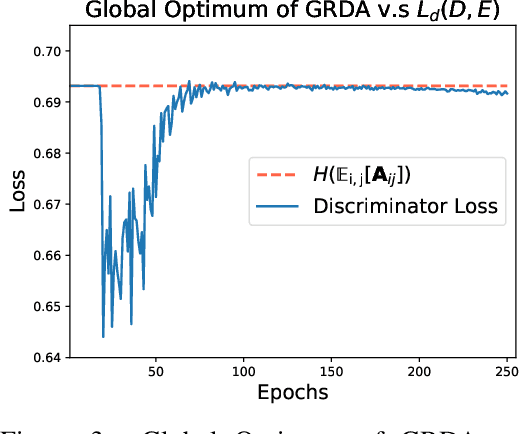
Existing domain adaptation methods tend to treat every domain equally and align them all perfectly. Such uniform alignment ignores topological structures among different domains; therefore it may be beneficial for nearby domains, but not necessarily for distant domains. In this work, we relax such uniform alignment by using a domain graph to encode domain adjacency, e.g., a graph of states in the US with each state as a domain and each edge indicating adjacency, thereby allowing domains to align flexibly based on the graph structure. We generalize the existing adversarial learning framework with a novel graph discriminator using encoding-conditioned graph embeddings. Theoretical analysis shows that at equilibrium, our method recovers classic domain adaptation when the graph is a clique, and achieves non-trivial alignment for other types of graphs. Empirical results show that our approach successfully generalizes uniform alignment, naturally incorporates domain information represented by graphs, and improves upon existing domain adaptation methods on both synthetic and real-world datasets. Code will soon be available at https://github.com/Wang-ML-Lab/GRDA.
Real-World Graph Convolution Networks (RW-GCNs) for Action Recognition in Smart Video Surveillance
Jan 15, 2022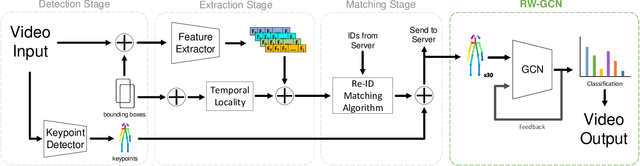
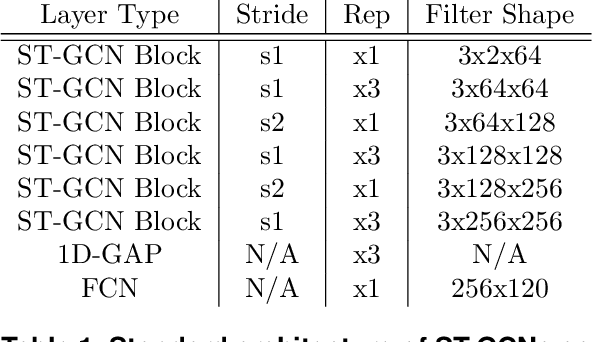

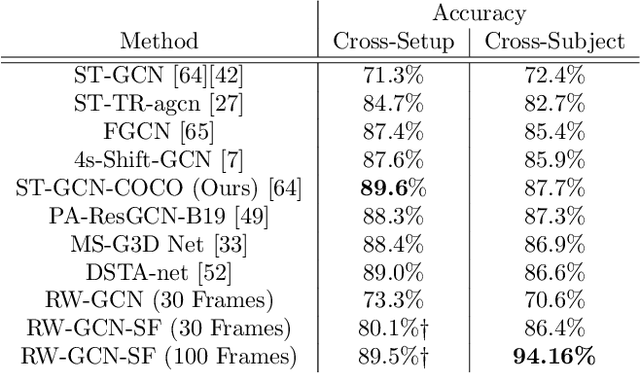
Action recognition is a key algorithmic part of emerging on-the-edge smart video surveillance and security systems. Skeleton-based action recognition is an attractive approach which, instead of using RGB pixel data, relies on human pose information to classify appropriate actions. However, existing algorithms often assume ideal conditions that are not representative of real-world limitations, such as noisy input, latency requirements, and edge resource constraints. To address the limitations of existing approaches, this paper presents Real-World Graph Convolution Networks (RW-GCNs), an architecture-level solution for meeting the domain constraints of Real World Skeleton-based Action Recognition. Inspired by the presence of feedback connections in the human visual cortex, RW-GCNs leverage attentive feedback augmentation on existing near state-of-the-art (SotA) Spatial-Temporal Graph Convolution Networks (ST-GCNs). The ST-GCNs' design choices are derived from information theory-centric principles to address both the spatial and temporal noise typically encountered in end-to-end real-time and on-the-edge smart video systems. Our results demonstrate RW-GCNs' ability to serve these applications by achieving a new SotA accuracy on the NTU-RGB-D-120 dataset at 94.1%, and achieving 32X less latency than baseline ST-GCN applications while still achieving 90.4% accuracy on the Northwestern UCLA dataset in the presence of spatial keypoint noise. RW-GCNs further show system scalability by running on the 10X cost effective NVIDIA Jetson Nano (as opposed to NVIDIA Xavier NX), while still maintaining a respectful range of throughput (15.6 to 5.5 Actions per Second) on the resource constrained device. The code is available here: https://github.com/TeCSAR-UNCC/RW-GCN.
Machine Learning for Utility Prediction in Argument-Based Computational Persuasion
Dec 09, 2021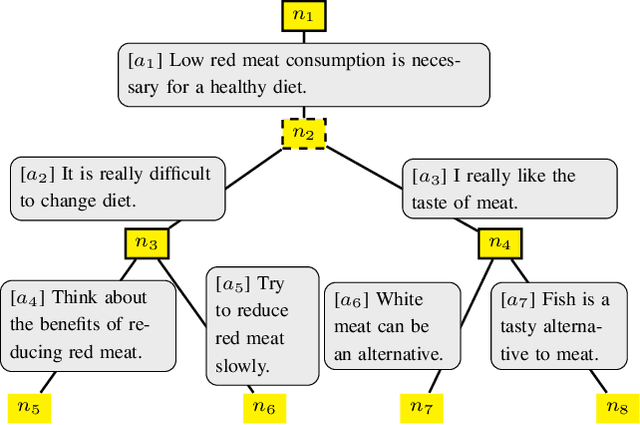
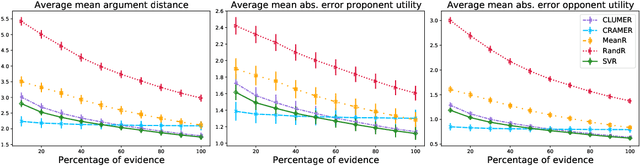
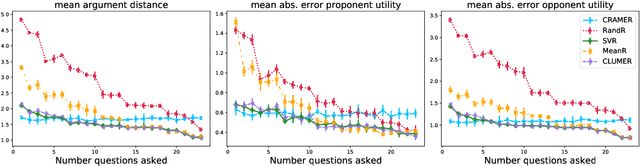
Automated persuasion systems (APS) aim to persuade a user to believe something by entering into a dialogue in which arguments and counterarguments are exchanged. To maximize the probability that an APS is successful in persuading a user, it can identify a global policy that will allow it to select the best arguments it presents at each stage of the dialogue whatever arguments the user presents. However, in real applications, such as for healthcare, it is unlikely the utility of the outcome of the dialogue will be the same, or the exact opposite, for the APS and user. In order to deal with this situation, games in extended form have been harnessed for argumentation in Bi-party Decision Theory. This opens new problems that we address in this paper: (1) How can we use Machine Learning (ML) methods to predict utility functions for different subpopulations of users? and (2) How can we identify for a new user the best utility function from amongst those that we have learned? To this extent, we develop two ML methods, EAI and EDS, that leverage information coming from the users to predict their utilities. EAI is restricted to a fixed amount of information, whereas EDS can choose the information that best detects the subpopulations of a user. We evaluate EAI and EDS in a simulation setting and in a realistic case study concerning healthy eating habits. Results are promising in both cases, but EDS is more effective at predicting useful utility functions.
Multivariate Time Series Forecasting with Dynamic Graph Neural ODEs
Feb 17, 2022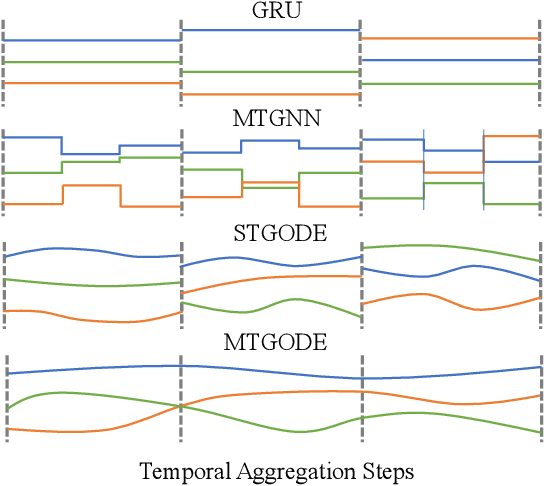

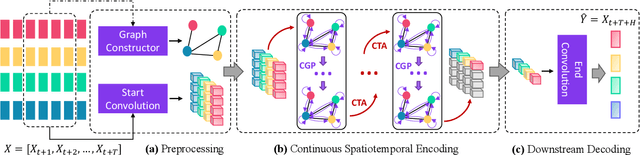
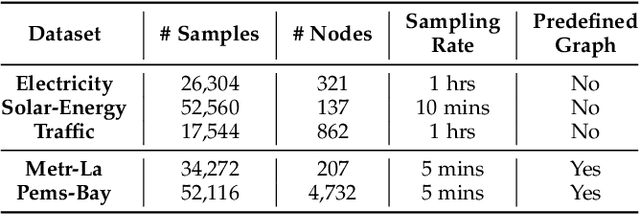
Multivariate time series forecasting has long received significant attention in real-world applications, such as energy consumption and traffic prediction. While recent methods demonstrate good forecasting abilities, they suffer from three fundamental limitations. (i) Discrete neural architectures: Interlacing individually parameterized spatial and temporal blocks to encode rich underlying patterns leads to discontinuous latent state trajectories and higher forecasting numerical errors. (ii) High complexity: Discrete approaches complicate models with dedicated designs and redundant parameters, leading to higher computational and memory overheads. (iii) Reliance on graph priors: Relying on predefined static graph structures limits their effectiveness and practicability in real-world applications. In this paper, we address all the above limitations by proposing a continuous model to forecast Multivariate Time series with dynamic Graph neural Ordinary Differential Equations (MTGODE). Specifically, we first abstract multivariate time series into dynamic graphs with time-evolving node features and unknown graph structures. Then, we design and solve a neural ODE to complement missing graph topologies and unify both spatial and temporal message passing, allowing deeper graph propagation and fine-grained temporal information aggregation to characterize stable and precise latent spatial-temporal dynamics. Our experiments demonstrate the superiorities of MTGODE from various perspectives on five time series benchmark datasets.
DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR
Feb 08, 2022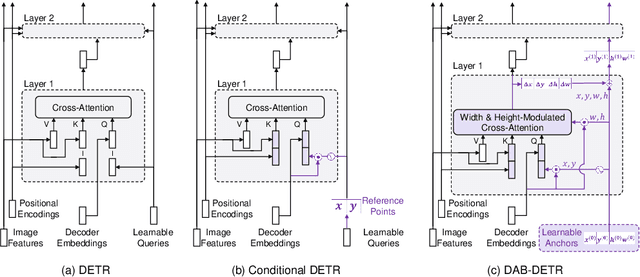


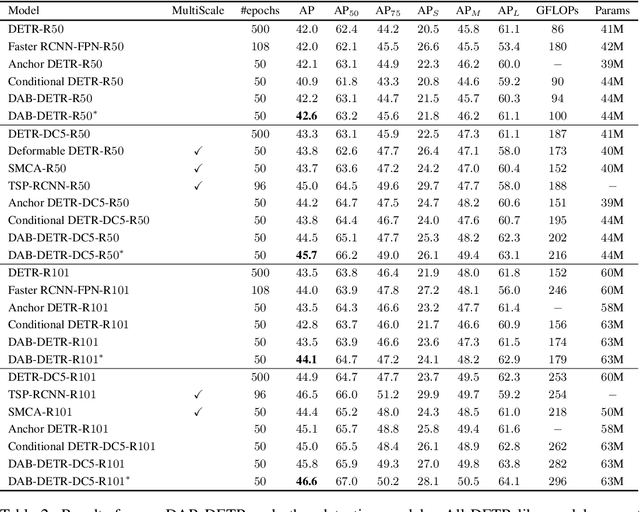
We present in this paper a novel query formulation using dynamic anchor boxes for DETR (DEtection TRansformer) and offer a deeper understanding of the role of queries in DETR. This new formulation directly uses box coordinates as queries in Transformer decoders and dynamically updates them layer-by-layer. Using box coordinates not only helps using explicit positional priors to improve the query-to-feature similarity and eliminate the slow training convergence issue in DETR, but also allows us to modulate the positional attention map using the box width and height information. Such a design makes it clear that queries in DETR can be implemented as performing soft ROI pooling layer-by-layer in a cascade manner. As a result, it leads to the best performance on MS-COCO benchmark among the DETR-like detection models under the same setting, e.g., AP 45.7\% using ResNet50-DC5 as backbone trained in 50 epochs. We also conducted extensive experiments to confirm our analysis and verify the effectiveness of our methods. Code is available at \url{https://github.com/SlongLiu/DAB-DETR}.