 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Flowformer: Linearizing Transformers with Conservation Flows
Feb 13, 2022
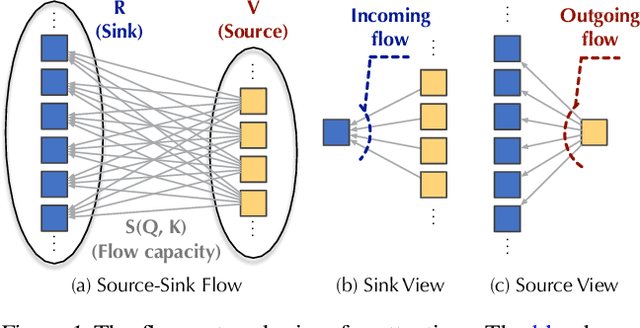
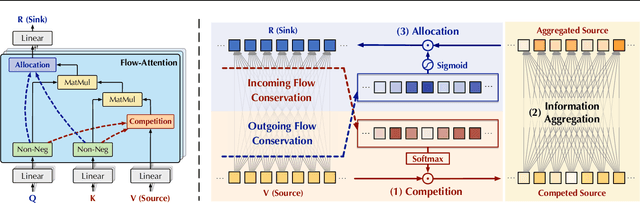
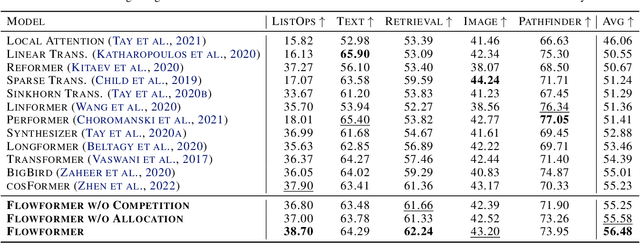
Transformers based on the attention mechanism have achieved impressive success in various areas. However, the attention mechanism has a quadratic complexity, significantly impeding Transformers from dealing with numerous tokens and scaling up to bigger models. Previous methods mainly utilize the similarity decomposition and the associativity of matrix multiplication to devise linear-time attention mechanisms. They avoid degeneration of attention to a trivial distribution by reintroducing inductive biases such as the locality, thereby at the expense of model generality and expressiveness. In this paper, we linearize Transformers free from specific inductive biases based on the flow network theory. We cast attention as the information flow aggregated from the sources (values) to the sinks (results) through the learned flow capacities (attentions). Within this framework, we apply the property of flow conservation with attention and propose the Flow-Attention mechanism of linear complexity. By respectively conserving the incoming flow of sinks for source competition and the outgoing flow of sources for sink allocation, Flow-Attention inherently generates informative attentions without using specific inductive biases. Empowered by the Flow-Attention, Flowformer yields strong performance in linear time for wide areas, including long sequence, time series, vision, natural language, and reinforcement learning.
RawNeXt: Speaker verification system for variable-duration utterances with deep layer aggregation and extended dynamic scaling policies
Dec 15, 2021



Despite achieving satisfactory performance in speaker verification using deep neural networks, variable-duration utterances remain a challenge that threatens the robustness of systems. To deal with this issue, we propose a speaker verification system called RawNeXt that can handle input raw waveforms of arbitrary length by employing the following two components: (1) A deep layer aggregation strategy enhances speaker information by iteratively and hierarchically aggregating features of various time scales and spectral channels output from blocks. (2) An extended dynamic scaling policy flexibly processes features according to the length of the utterance by selectively merging the activations of different resolution branches in each block. Owing to these two components, our proposed model can extract speaker embeddings rich in time-spectral information and operate dynamically on length variations. Experimental results on the VoxCeleb1 test set consisting of various duration utterances demonstrate that RawNeXt achieves state-of-the-art performance compared to the recently proposed systems. Our code and trained model weights are available at https://github.com/wngh1187/RawNeXt.
Efficient Natural Gradient Descent Methods for Large-Scale Optimization Problems
Feb 13, 2022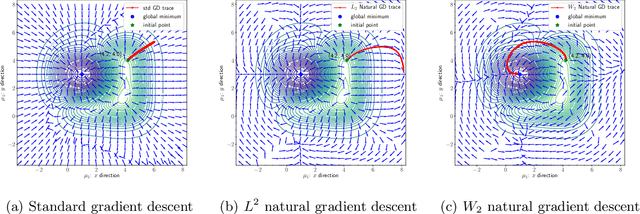
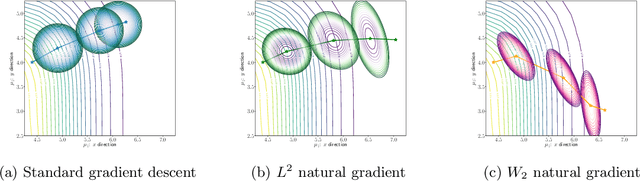
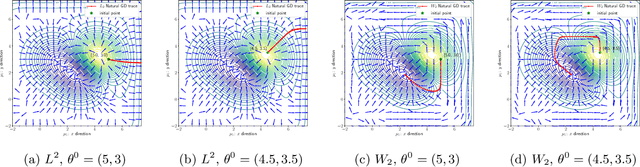
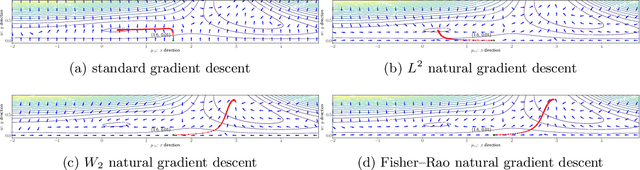
We propose an efficient numerical method for computing natural gradient descent directions with respect to a generic metric in the state space. Our technique relies on representing the natural gradient direction as a solution to a standard least-squares problem. Hence, instead of calculating, storing, or inverting the information matrix directly, we apply efficient methods from numerical linear algebra to solve this least-squares problem. We treat both scenarios where the derivative of the state variable with respect to the parameter is either explicitly known or implicitly given through constraints. We apply the QR decomposition to solve the least-squares problem in the former case and utilize the adjoint-state method to compute the natural gradient descent direction in the latter case. As a result, we can reliably compute several natural gradient descents, including the Wasserstein natural gradient, for a large-scale parameter space with thousands of dimensions, which was believed to be out of reach. Finally, our numerical results shed light on the qualitative differences among the standard gradient descent method and various natural gradient descent methods based on different metric spaces in large-scale nonconvex optimization problems.
ERF: Explicit Radiance Field Reconstruction From Scratch
Feb 28, 2022

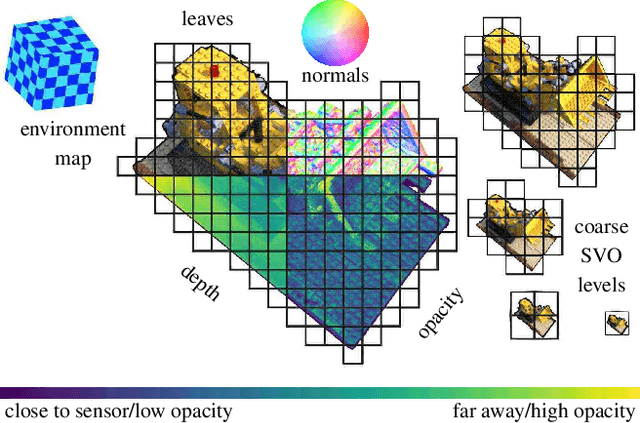
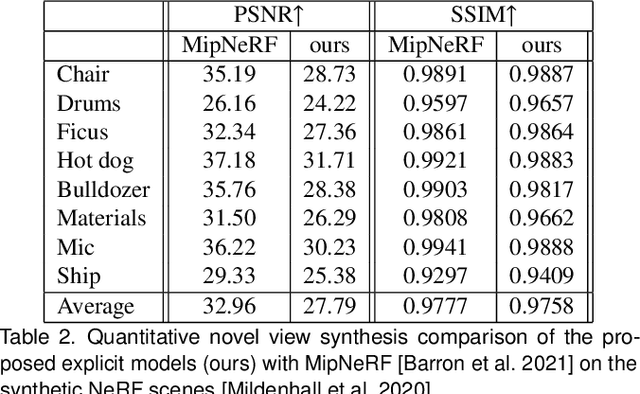
We propose a novel explicit dense 3D reconstruction approach that processes a set of images of a scene with sensor poses and calibrations and estimates a photo-real digital model. One of the key innovations is that the underlying volumetric representation is completely explicit in contrast to neural network-based (implicit) alternatives. We encode scenes explicitly using clear and understandable mappings of optimization variables to scene geometry and their outgoing surface radiance. We represent them using hierarchical volumetric fields stored in a sparse voxel octree. Robustly reconstructing such a volumetric scene model with millions of unknown variables from registered scene images only is a highly non-convex and complex optimization problem. To this end, we employ stochastic gradient descent (Adam) which is steered by an inverse differentiable renderer. We demonstrate that our method can reconstruct models of high quality that are comparable to state-of-the-art implicit methods. Importantly, we do not use a sequential reconstruction pipeline where individual steps suffer from incomplete or unreliable information from previous stages, but start our optimizations from uniformed initial solutions with scene geometry and radiance that is far off from the ground truth. We show that our method is general and practical. It does not require a highly controlled lab setup for capturing, but allows for reconstructing scenes with a vast variety of objects, including challenging ones, such as outdoor plants or furry toys. Finally, our reconstructed scene models are versatile thanks to their explicit design. They can be edited interactively which is computationally too costly for implicit alternatives.
Leveraging speaker attribute information using multi task learning for speaker verification and diarization
Oct 27, 2020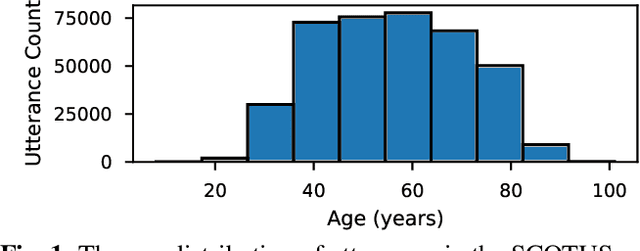
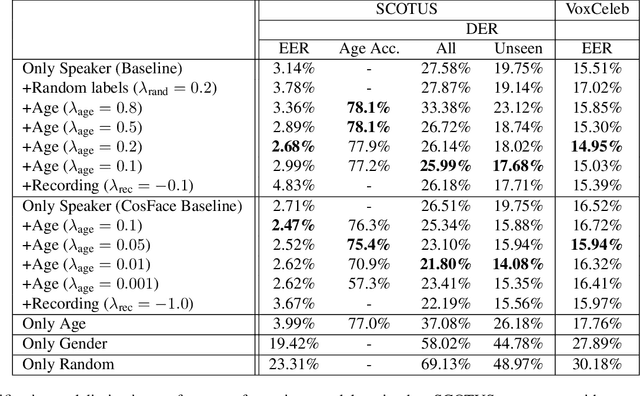
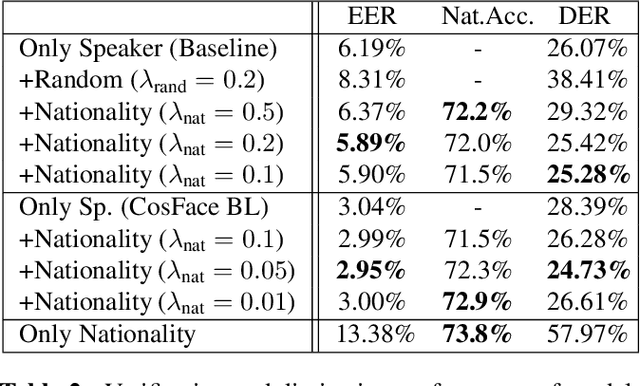
Deep speaker embeddings have become the leading method for encoding speaker identity in speaker recognition tasks. The embedding space should ideally capture the variations between all possible speakers, encoding the multiple aspects that make up speaker identity. In this work, utilizing speaker age as an auxiliary variable in US Supreme Court recordings and speaker nationality with VoxCeleb, we show that by leveraging additional speaker attribute information in a multi task learning setting, deep speaker embedding performance can be increased for verification and diarization tasks, achieving a relative improvement of 17.8% in DER and 8.9% in EER for Supreme Court audio compared to omitting the auxiliary task. Experimental code has been made publicly available.
Safe multi-agent deep reinforcement learning for joint bidding and maintenance scheduling of generation units
Dec 20, 2021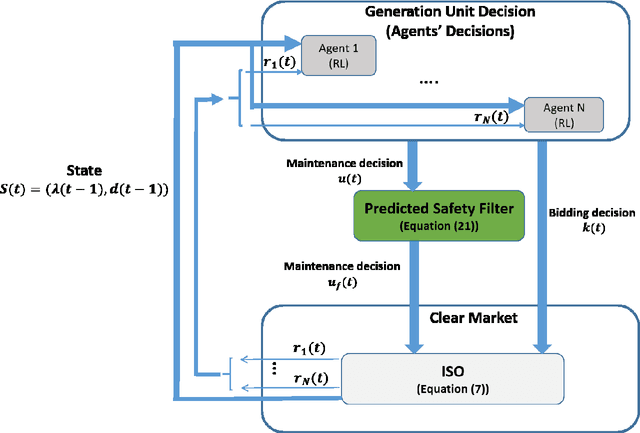
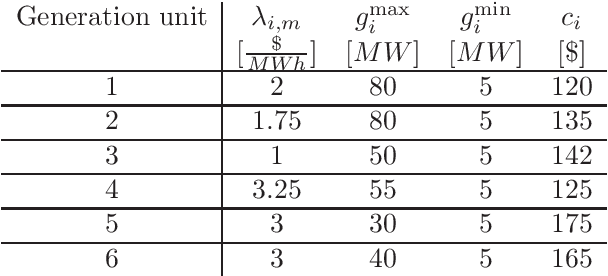
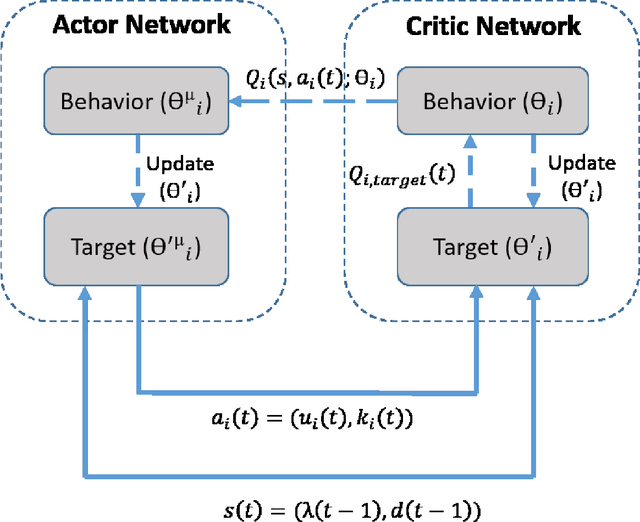
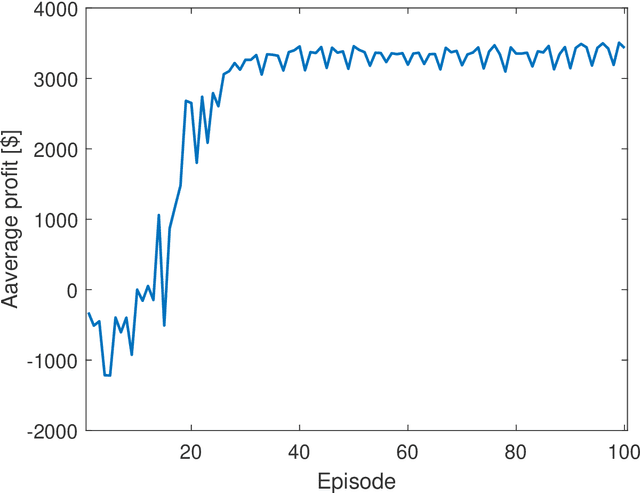
This paper proposes a safe reinforcement learning algorithm for generation bidding decisions and unit maintenance scheduling in a competitive electricity market environment. In this problem, each unit aims to find a bidding strategy that maximizes its revenue while concurrently retaining its reliability by scheduling preventive maintenance. The maintenance scheduling provides some safety constraints which should be satisfied at all times. Satisfying the critical safety and reliability constraints while the generation units have an incomplete information of each others' bidding strategy is a challenging problem. Bi-level optimization and reinforcement learning are state of the art approaches for solving this type of problems. However, neither bi-level optimization nor reinforcement learning can handle the challenges of incomplete information and critical safety constraints. To tackle these challenges, we propose the safe deep deterministic policy gradient reinforcement learning algorithm which is based on a combination of reinforcement learning and a predicted safety filter. The case study demonstrates that the proposed approach can achieve a higher profit compared to other state of the art methods while concurrently satisfying the system safety constraints.
Interpreting multi-variate models with setPCA
Nov 17, 2021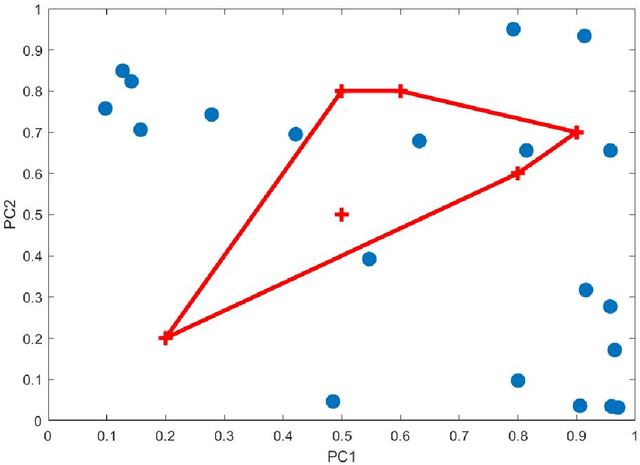
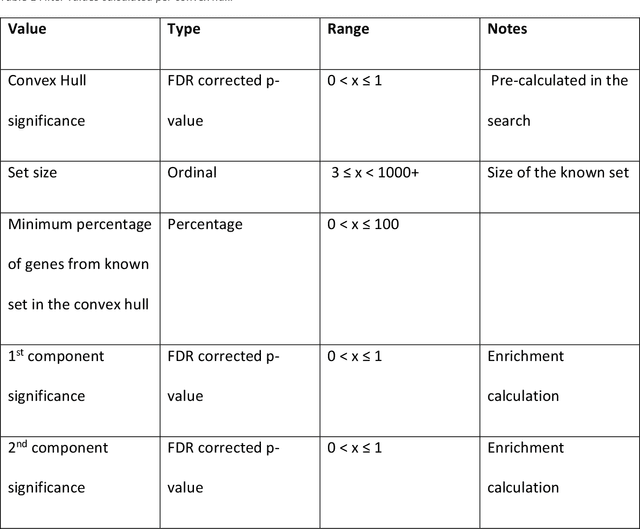
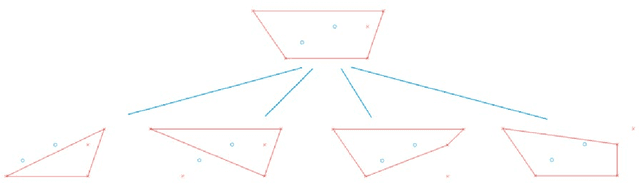
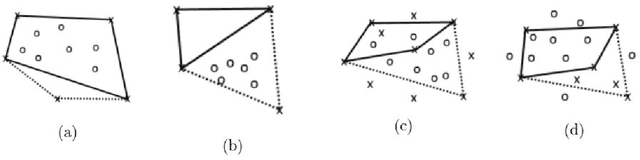
Principal Component Analysis (PCA) and other multi-variate models are often used in the analysis of "omics" data. These models contain much information which is currently neither easily accessible nor interpretable. Here we present an algorithmic method which has been developed to integrate this information with existing databases of background knowledge, stored in the form of known sets (for instance genesets or pathways). To make this accessible we have produced a Graphical User Interface (GUI) in Matlab which allows the overlay of known set information onto the loadings plot and thus improves the interpretability of the multi-variate model. For each known set the optimal convex hull, covering a subset of elements from the known set, is found through a search algorithm and displayed. In this paper we discuss two main topics; the details of the search algorithm for the optimal convex hull for this problem and the GUI interface which is freely available for download for academic use.
Design and Implementation of Electronic Infrastructure For Academic Establishment
Feb 08, 2022Most establishments including academic institutions under goes the lengthy process of study-based document handling such as direct mailing, indexing and tracking. This daily task is time consuming and resource-intensive. Using a private network dedicated for such document management would benefit the establishment increasing operational efficiency. In this study, the Information and Communication Engineering (ICE) Department was used as a model to determine the requirements needed to build the intranet network. A packet tracer simulator was used to build a virtual intranet architecture.Then the simulation report was examined to ensure optimum functionality. Upon establishing a stable behavior an intranet infrastructure building commenced using the available hardware components and software.The system architecture was based on Windows 2012R2 server to manage 3 separated sub-networks connected to three switches and one router. Running the intranet for one semester proved its success in providing a fast, cheap and simplified service for all department needs. The accomplished system is a step forward to achieve a full electronic department in scientific establishments.
MAMDR: A Model Agnostic Learning Method for Multi-Domain Recommendation
Feb 25, 2022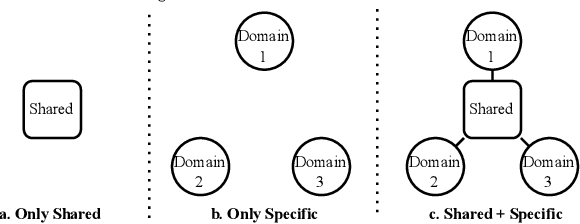
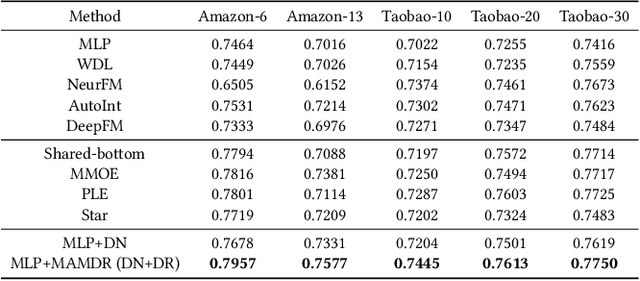
Large-scale e-commercial platforms in the real-world usually contain various recommendation scenarios (domains) to meet demands of diverse customer groups. Multi-Domain Recommendation (MDR), which aims to jointly improve recommendations on all domains, has attracted increasing attention from practitioners and researchers. Existing MDR methods often employ a shared structure to leverage reusable features for all domains and several specific parts to capture domain-specific information. However, data from different domains may conflict with each other and cause shared parameters to stay at a compromised position on the optimization landscape. This could deteriorate the overall performance. Despite the specific parameters are separately learned for each domain, they can easily overfit on data sparsity domains. Furthermore, data distribution differs across domains, making it challenging to develop a general model that can be applied to all circumstances. To address these problems, we propose a novel model agnostic learning method, namely MAMDR, for the multi-domain recommendation. Specifically, we first propose a Domain Negotiation (DN) strategy to alleviate the conflict between domains and learn better shared parameters. Then, we develop a Domain Regularization (DR) scheme to improve the generalization ability of specific parameters by learning from other domains. Finally, we integrate these components into a unified framework and present MAMDR which can be applied to any model structure to perform multi-domain recommendation. Extensive experiments on various real-world datasets and online applications demonstrate both the effectiveness and generalizability of MAMDR.
Increasing the skill of short-term wind speed ensemble forecasts combining forecasts and observations via a new dynamic calibration
Jan 28, 2022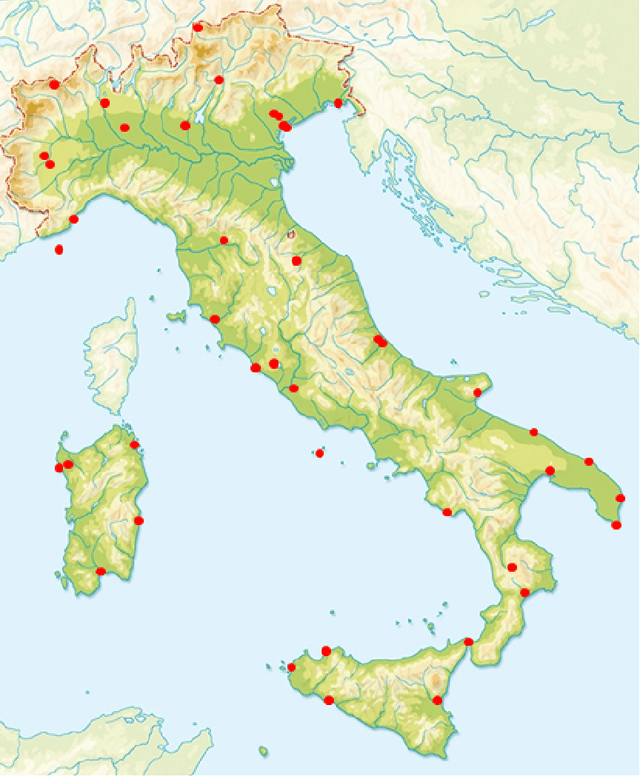
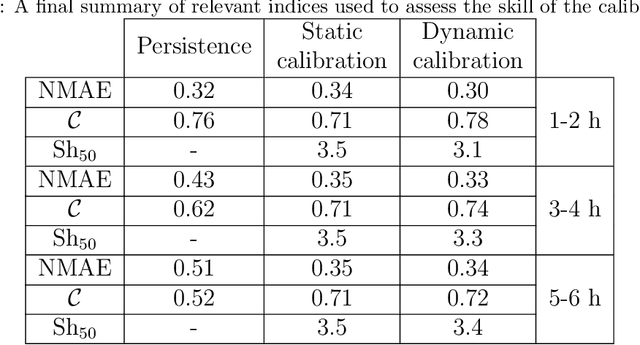
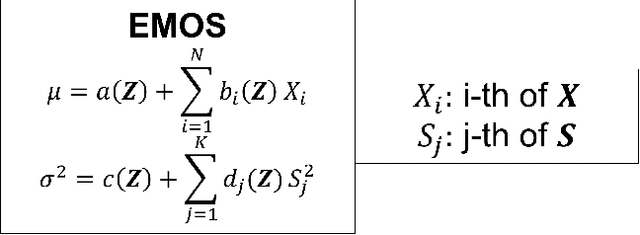
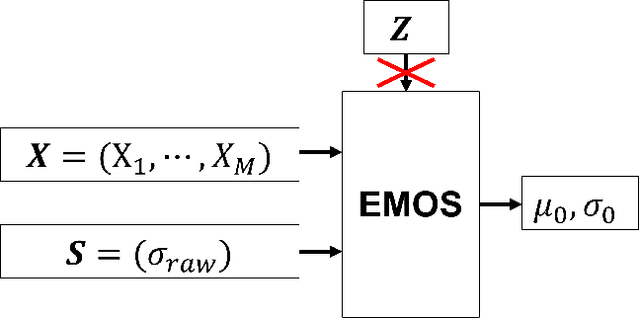
All numerical weather prediction models used for the wind industry need to produce their forecasts starting from the main synoptic hours 00, 06, 12, and 18 UTC, once the analysis becomes available. The six-hour latency time between two consecutive model runs calls for strategies to fill the gap by providing new accurate predictions having, at least, hourly frequency. This is done to accommodate the request of frequent, accurate and fresh information from traders and system regulators to continuously adapt their work strategies. Here, we propose a strategy where quasi-real time observed wind speed and weather model predictions are combined by means of a novel Ensemble Model Output Statistics (EMOS) strategy. The success of our strategy is measured by comparisons against observed wind speed from SYNOP stations over Italy in the years 2018 and 2019.