 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sample-Efficient Reinforcement Learning with loglog(T) Switching Cost
Feb 13, 2022
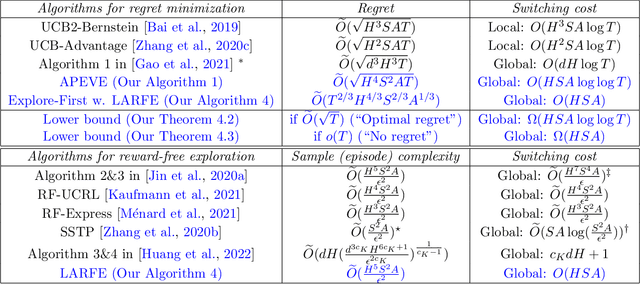
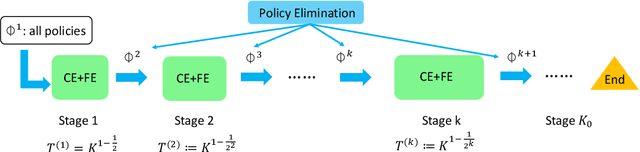
We study the problem of reinforcement learning (RL) with low (policy) switching cost - a problem well-motivated by real-life RL applications in which deployments of new policies are costly and the number of policy updates must be low. In this paper, we propose a new algorithm based on stage-wise exploration and adaptive policy elimination that achieves a regret of $\widetilde{O}(\sqrt{H^4S^2AT})$ while requiring a switching cost of $O(HSA \log\log T)$. This is an exponential improvement over the best-known switching cost $O(H^2SA\log T)$ among existing methods with $\widetilde{O}(\mathrm{poly}(H,S,A)\sqrt{T})$ regret. In the above, $S,A$ denotes the number of states and actions in an $H$-horizon episodic Markov Decision Process model with unknown transitions, and $T$ is the number of steps. We also prove an information-theoretical lower bound which says that a switching cost of $\Omega(HSA)$ is required for any no-regret algorithm. As a byproduct, our new algorithmic techniques allow us to derive a \emph{reward-free} exploration algorithm with an optimal switching cost of $O(HSA)$.
The Recurrent Reinforcement Learning Crypto Agent
Jan 29, 2022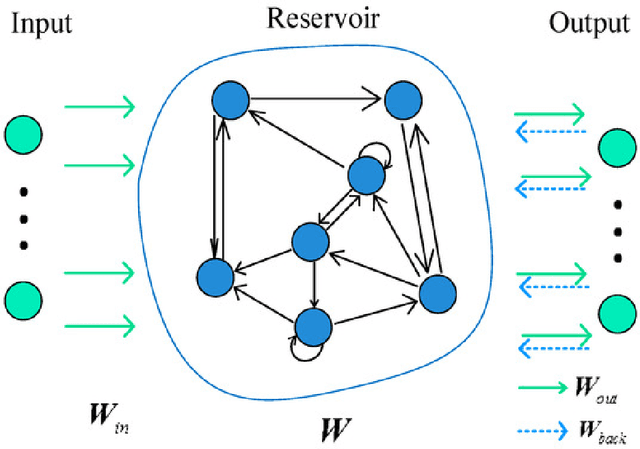
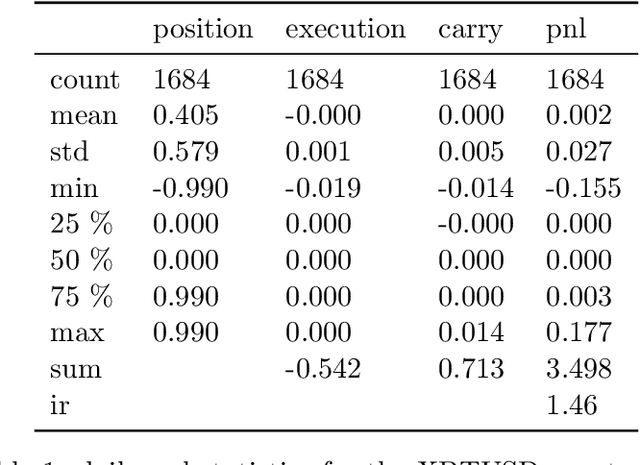
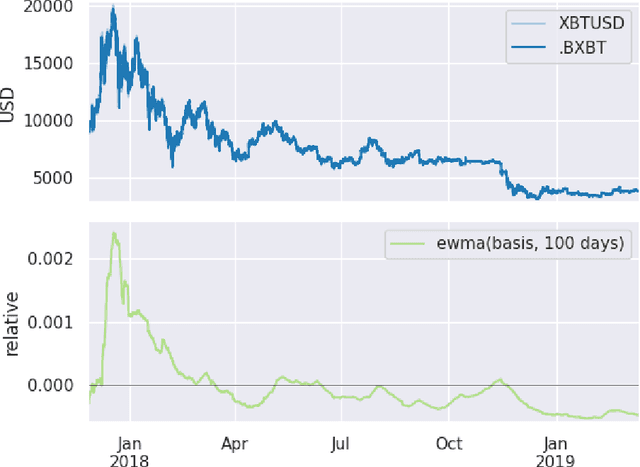
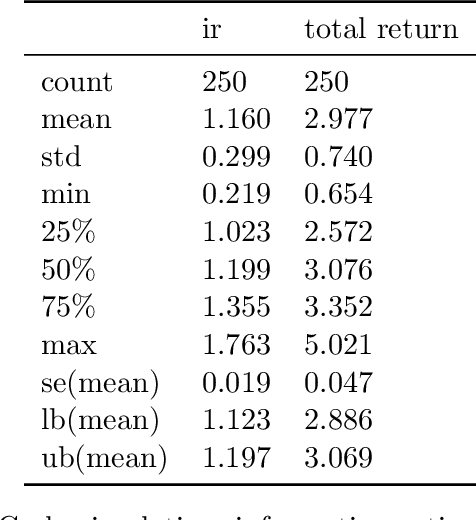
We demonstrate a novel application of online transfer learning for a digital assets trading agent. This agent makes use of a powerful feature space representation in the form of an echo state network, the output of which is made available to a direct, recurrent reinforcement learning agent. The agent learns to trade the XBTUSD (Bitcoin versus US Dollars) perpetual swap derivatives contract on BitMEX on an intraday basis. By learning from the multiple sources of impact on the quadratic risk-adjusted utility that it seeks to maximise, the agent avoids excessive over-trading, captures a funding profit, and can predict the market's direction. Overall, our crypto agent realises a total return of 350%, net of transaction costs, over roughly five years, 71% of which is down to funding profit. The annualised information ratio that it achieves is 1.46.
Deep Neural Networks to Correct Sub-Precision Errors in CFD
Feb 09, 2022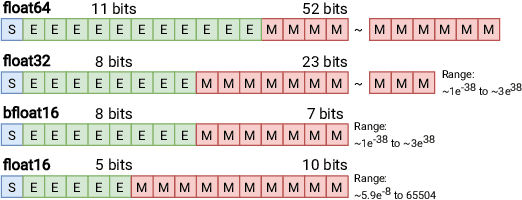

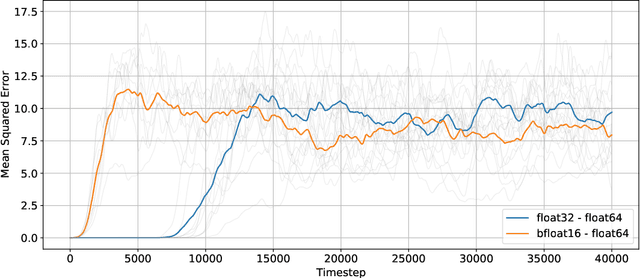

Loss of information in numerical simulations can arise from various sources while solving discretized partial differential equations. In particular, precision-related errors can accumulate in the quantities of interest when the simulations are performed using low-precision 16-bit floating-point arithmetic compared to an equivalent 64-bit simulation. Here, low-precision computation requires much lower resources than high-precision computation. Several machine learning (ML) techniques proposed recently have been successful in correcting the errors arising from spatial discretization. In this work, we extend these techniques to improve Computational Fluid Dynamics (CFD) simulations performed using low numerical precision. We first quantify the precision related errors accumulated in a Kolmogorov forced turbulence test case. Subsequently, we employ a Convolutional Neural Network together with a fully differentiable numerical solver performing 16-bit arithmetic to learn a tightly-coupled ML-CFD hybrid solver. Compared to the 16-bit solver, we demonstrate the efficacy of the ML-CFD hybrid solver towards reducing the error accumulation in the velocity field and improving the kinetic energy spectrum at higher frequencies.
Visual Object Tracking on Multi-modal RGB-D Videos: A Review
Jan 23, 2022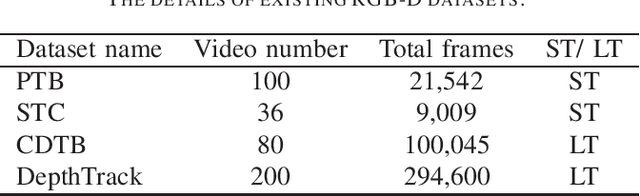
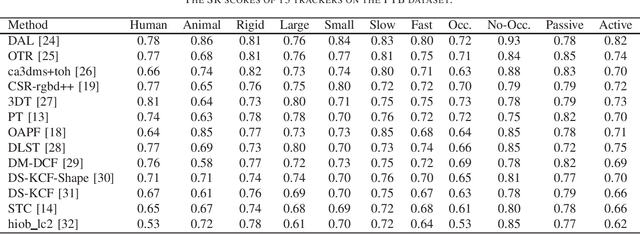
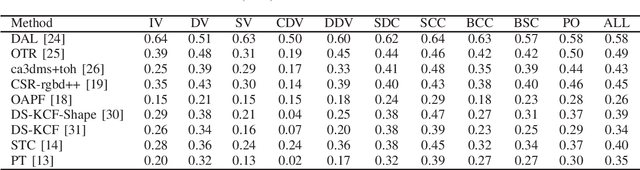

The development of visual object tracking has continued for decades. Recent years, as the wide accessibility of the low-cost RGBD sensors, the task of visual object tracking on RGB-D videos has drawn much attention. Compared to conventional RGB-only tracking, the RGB-D videos can provide more information that facilitates objecting tracking in some complicated scenarios. The goal of this review is to summarize the relative knowledge of the research filed of RGB-D tracking. To be specific, we will generalize the related RGB-D tracking benchmarking datasets as well as the corresponding performance measurements. Besides, the existing RGB-D tracking methods are summarized in the paper. Moreover, we discuss the possible future direction in the field of RGB-D tracking.
Multispectral image fusion by super pixel statistics
Dec 21, 2021
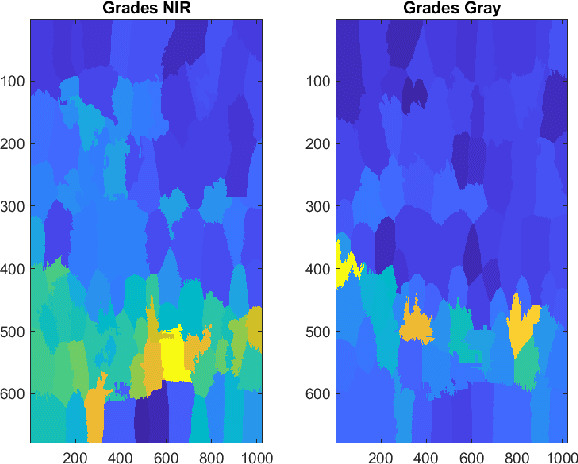

Multispectral image fusion is a fundamental problem of remote sensing and image processing. This problem is addressed by both classic and deep learning approaches. This paper is focused on the classic solutions and introduces a new novel approach to this family. The proposed method carries out multispectral image fusion based on the content of the fused images. It relies on analysis based on the level of information on segmented superpixels in the fused inputs. Specifically, I address the task of visible color RGB to Near-Infrared (NIR) fusion. The RGB image captures the color of the scene while the NIR captures details and sees beyond haze and clouds. Since each channel senses different information of the scene, their fusion is challenging and interesting. The proposed method is designed to produce a fusion that contains both advantages of each spectra. This manuscript experiments show that the proposed method is visually informative with respect to other classic fusion methods which can be run fastly on embedded devices with no need for heavy computation resources.
A Data Augmentation Method for Fully Automatic Brain Tumor Segmentation
Feb 13, 2022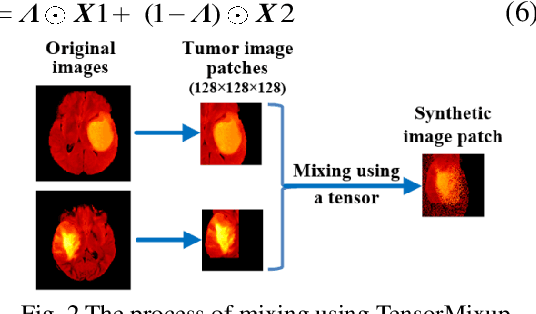

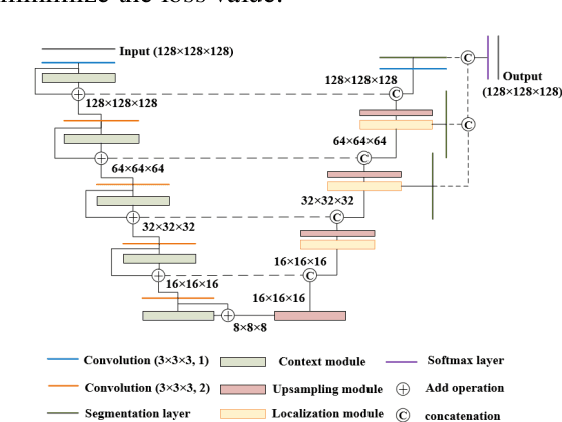
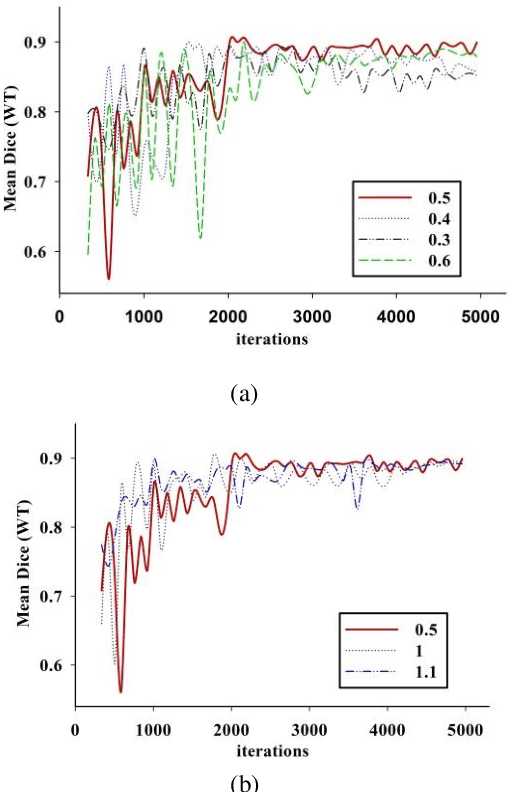
Automatic segmentation of glioma and its subregions is of great significance for diagnosis, treatment and monitoring of disease. In this paper, an augmentation method, called TensorMixup, was proposed and applied to the three dimensional U-Net architecture for brain tumor segmentation. The main ideas included that first, two image patches with size of 128 in three dimensions were selected according to glioma information of ground truth labels from the magnetic resonance imaging data of any two patients with the same modality. Next, a tensor in which all elements were independently sampled from Beta distribution was used to mix the image patches. Then the tensor was mapped to a matrix which was used to mix the one-hot encoded labels of the above image patches. Therefore, a new image and its one-hot encoded label were synthesized. Finally, the new data was used to train the model which could be used to segment glioma. The experimental results show that the mean accuracy of Dice scores are 91.32%, 85.67%, and 82.20% respectively on the whole tumor, tumor core, and enhancing tumor segmentation, which proves that the proposed TensorMixup is feasible and effective for brain tumor segmentation.
Sensing Method for Two-Target Detection in Time-Constrained Vector Poisson Channel
Jan 19, 2022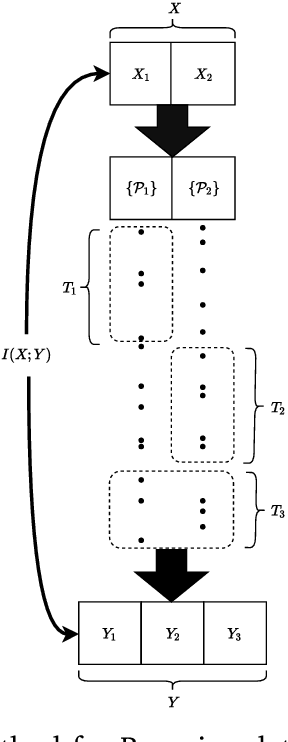
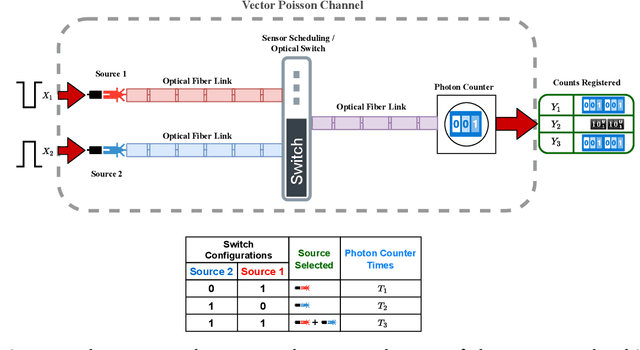
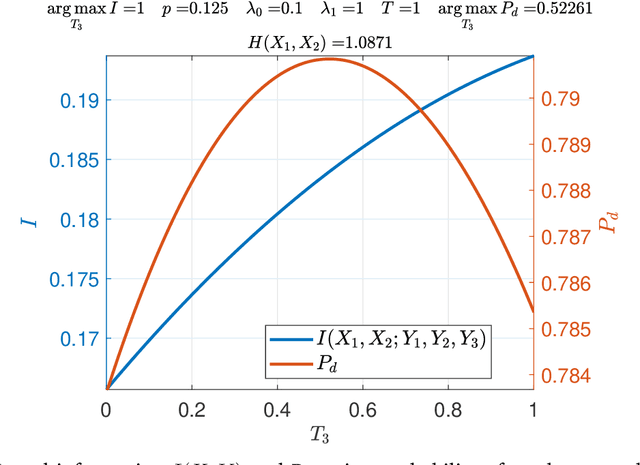
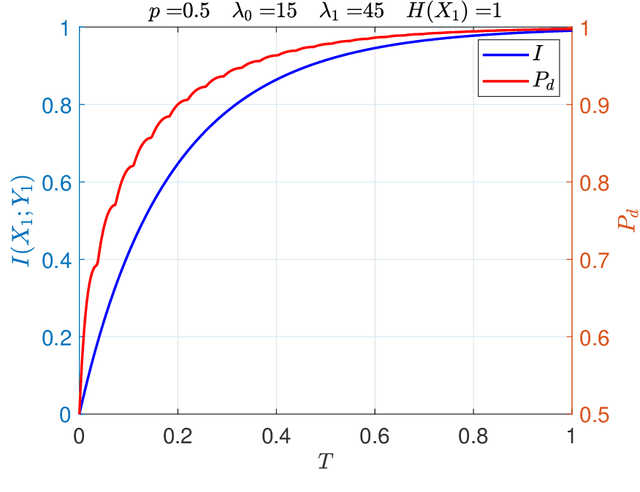
It is an experimental design problem in which there are two Poisson sources with two possible and known rates, and one counter. Through a switch, the counter can observe the sources individually or the counts can be combined so that the counter observes the sum of the two. The sensor scheduling problem is to determine an optimal proportion of the available time to be allocated toward individual and joint sensing, under a total time constraint. Two different metrics are used for optimization: mutual information between the sources and the observed counts, and probability of detection for the associated source detection problem. Our results, which are primarily computational, indicate similar but not identical results under the two cost functions.
* 24 pages, 37 figures, journal article
Who will Leave a Pediatric Weight Management Program and When? -- A machine learning approach for predicting attrition patterns
Feb 13, 2022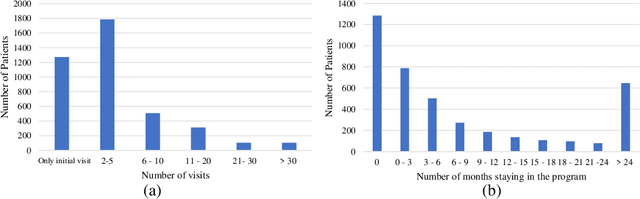
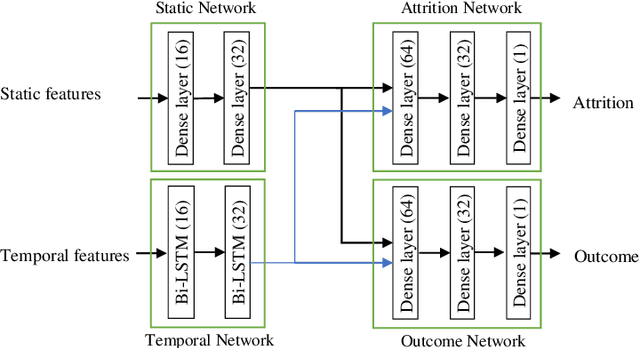
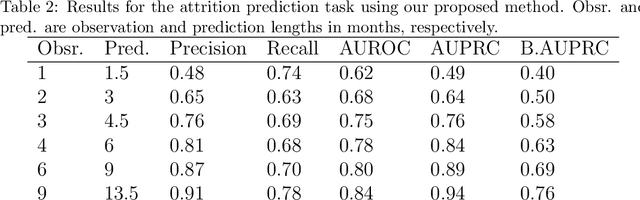
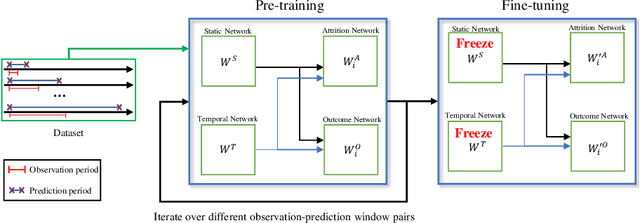
Childhood obesity is a major public health concern. Multidisciplinary pediatric weight management programs are considered standard treatment for children with obesity and severe obesity who are not able to be successfully managed in the primary care setting; however, high drop-out rates (referred to as attrition) are a major hurdle in delivering successful interventions. Predicting attrition patterns can help providers reduce the attrition rates. Previous work has mainly focused on finding static predictors of attrition using statistical analysis methods. In this study, we present a machine learning model to predict (a) the likelihood of attrition, and (b) the change in body-mass index (BMI) percentile of children, at different time points after joining a weight management program. We use a five-year dataset containing the information related to around 4,550 children that we have compiled using data from the Nemours Pediatric Weight Management program. Our models show strong prediction performance as determined by high AUROC scores across different tasks (average AUROC of 0.75 for predicting attrition, and 0.73 for predicting weight outcomes). Additionally, we report the top features predicting attrition and weight outcomes in a series of explanatory experiments.
Information-Bottleneck Approach to Salient Region Discovery
Jul 22, 2019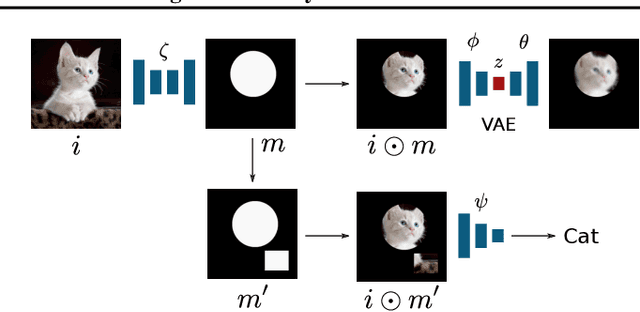



We propose a new method for learning image attention masks in a semi-supervised setting based on the Information Bottleneck principle. Provided with a set of labeled images, the mask generation model is minimizing mutual information between the input and the masked image while maximizing the mutual information between the same masked image and the image label. In contrast with other approaches, our attention model produces a Boolean rather than a continuous mask, entirely concealing the information in masked-out pixels. Using a set of synthetic datasets based on MNIST and CIFAR10 and the SVHN datasets, we demonstrate that our method can successfully attend to features known to define the image class.
Assessment of Fetal and Maternal Well-Being During Pregnancy Using Passive Wearable Inertial Sensor
Nov 19, 2021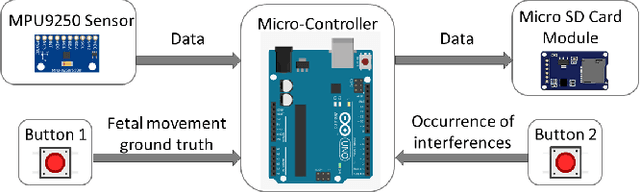
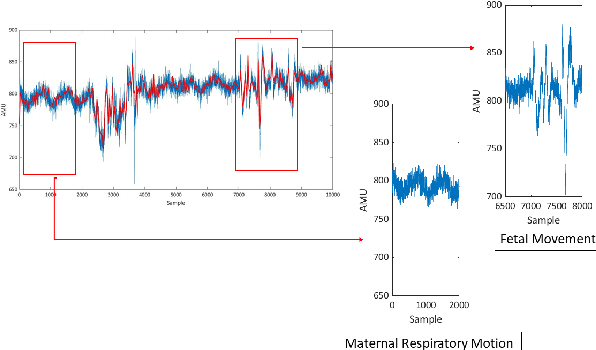
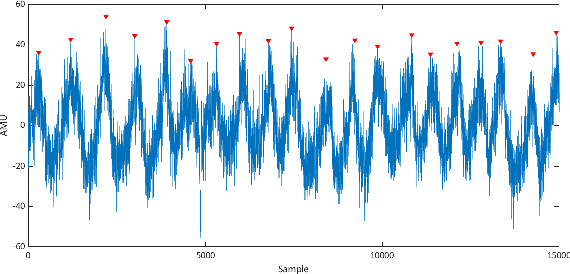
Assessing the health of both the fetus and mother is vital in preventing and identifying possible complications in pregnancy. This paper focuses on a device that can be used effectively by the mother herself with minimal supervision and provide a reasonable estimation of fetal and maternal health while being safe, comfortable, and easy to use. The device proposed uses a belt with a single accelerometer over the mother's uterus to record the required information. The device is expected to monitor both the mother and the fetus constantly over a long period and provide medical professionals with useful information, which they would otherwise overlook due to the low frequency that health monitoring is carried out at the present. The paper shows that simultaneous measurement of respiratory information of the mother and fetal movement is in fact possible even in the presence of mild interferences, which needs to be accounted for if the device is expected to be worn for extended times.