 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The BrainScaleS-2 accelerated neuromorphic system with hybrid plasticity
Jan 26, 2022
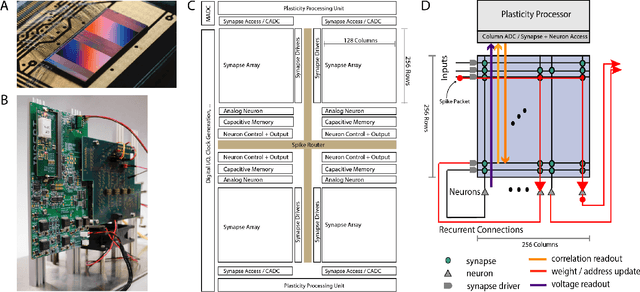
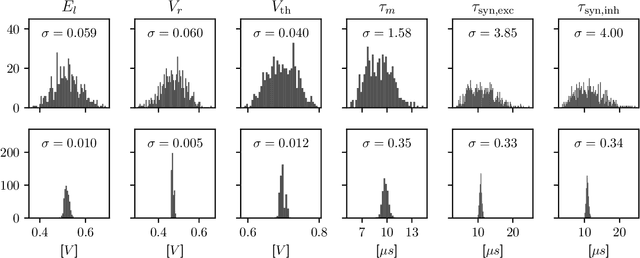
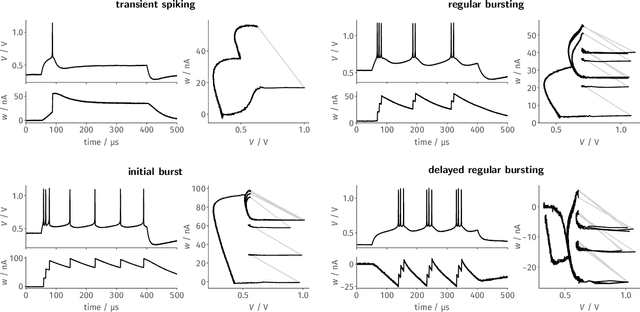
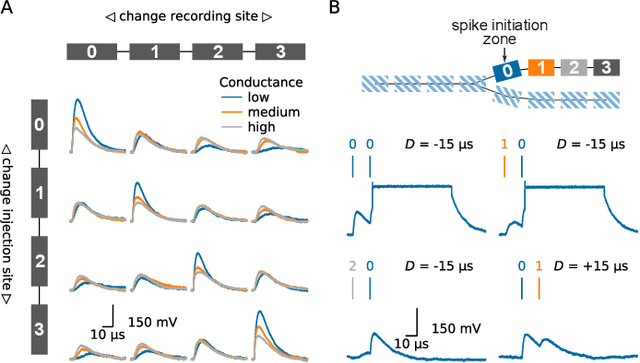
Since the beginning of information processing by electronic components, the nervous system has served as a metaphor for the organization of computational primitives. Brain-inspired computing today encompasses a class of approaches ranging from using novel nano-devices for computation to research into large-scale neuromorphic architectures, such as TrueNorth, SpiNNaker, BrainScaleS, Tianjic, and Loihi. While implementation details differ, spiking neural networks -- sometimes referred to as the third generation of neural networks -- are the common abstraction used to model computation with such systems. Here we describe the second generation of the BrainScaleS neuromorphic architecture, emphasizing applications enabled by this architecture. It combines a custom analog accelerator core supporting the accelerated physical emulation of bio-inspired spiking neural network primitives with a tightly coupled digital processor and a digital event-routing network.
Non-Gaussian Component Analysis via Lattice Basis Reduction
Dec 16, 2021Non-Gaussian Component Analysis (NGCA) is the following distribution learning problem: Given i.i.d. samples from a distribution on $\mathbb{R}^d$ that is non-gaussian in a hidden direction $v$ and an independent standard Gaussian in the orthogonal directions, the goal is to approximate the hidden direction $v$. Prior work \cite{DKS17-sq} provided formal evidence for the existence of an information-computation tradeoff for NGCA under appropriate moment-matching conditions on the univariate non-gaussian distribution $A$. The latter result does not apply when the distribution $A$ is discrete. A natural question is whether information-computation tradeoffs persist in this setting. In this paper, we answer this question in the negative by obtaining a sample and computationally efficient algorithm for NGCA in the regime that $A$ is discrete or nearly discrete, in a well-defined technical sense. The key tool leveraged in our algorithm is the LLL method \cite{LLL82} for lattice basis reduction.
The CUHK-TENCENT speaker diarization system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 04, 2022
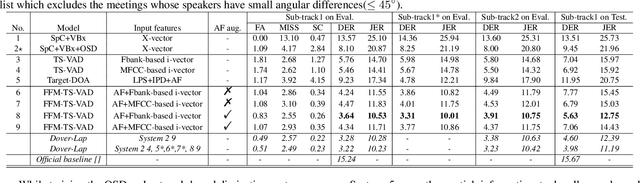
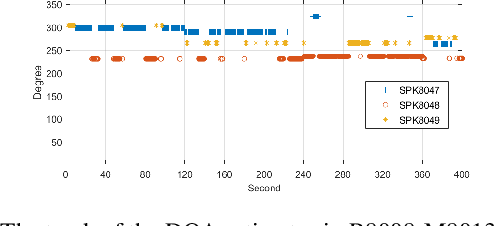
This paper describes our speaker diarization system submitted to the Multi-channel Multi-party Meeting Transcription (M2MeT) challenge, where Mandarin meeting data were recorded in multi-channel format for diarization and automatic speech recognition (ASR) tasks. In these meeting scenarios, the uncertainty of the speaker number and the high ratio of overlapped speech present great challenges for diarization. Based on the assumption that there is valuable complementary information between acoustic features, spatial-related and speaker-related features, we propose a multi-level feature fusion mechanism based target-speaker voice activity detection (FFM-TS-VAD) system to improve the performance of the conventional TS-VAD system. Furthermore, we propose a data augmentation method during training to improve the system robustness when the angular difference between two speakers is relatively small. We provide comparisons for different sub-systems we used in M2MeT challenge. Our submission is a fusion of several sub-systems and ranks second in the diarization task.
3D-Aware Indoor Scene Synthesis with Depth Priors
Feb 18, 2022
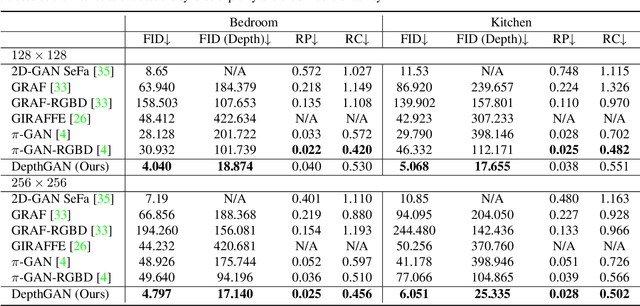
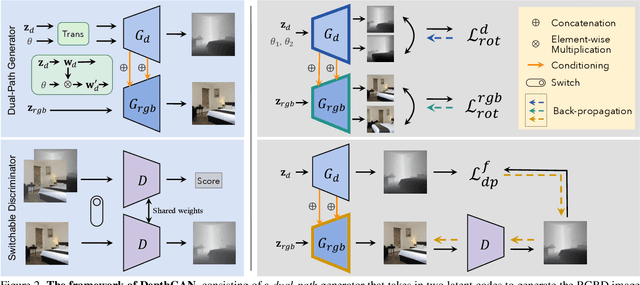
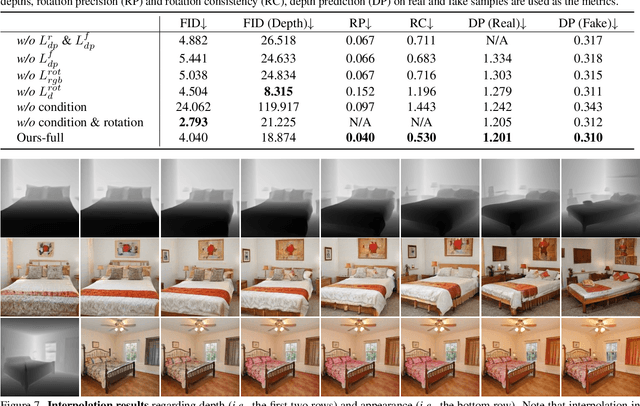
Despite the recent advancement of Generative Adversarial Networks (GANs) in learning 3D-aware image synthesis from 2D data, existing methods fail to model indoor scenes due to the large diversity of room layouts and the objects inside. We argue that indoor scenes do not have a shared intrinsic structure, and hence only using 2D images cannot adequately guide the model with the 3D geometry. In this work, we fill in this gap by introducing depth as a 3D prior. Compared with other 3D data formats, depth better fits the convolution-based generation mechanism and is more easily accessible in practice. Specifically, we propose a dual-path generator, where one path is responsible for depth generation, whose intermediate features are injected into the other path as the condition for appearance rendering. Such a design eases the 3D-aware synthesis with explicit geometry information. Meanwhile, we introduce a switchable discriminator both to differentiate real v.s. fake domains and to predict the depth from a given input. In this way, the discriminator can take the spatial arrangement into account and advise the generator to learn an appropriate depth condition. Extensive experimental results suggest that our approach is capable of synthesizing indoor scenes with impressively good quality and 3D consistency, significantly outperforming state-of-the-art alternatives.
OpenQA: Hybrid QA System Relying on Structured Knowledge Base as well as Non-structured Data
Dec 31, 2021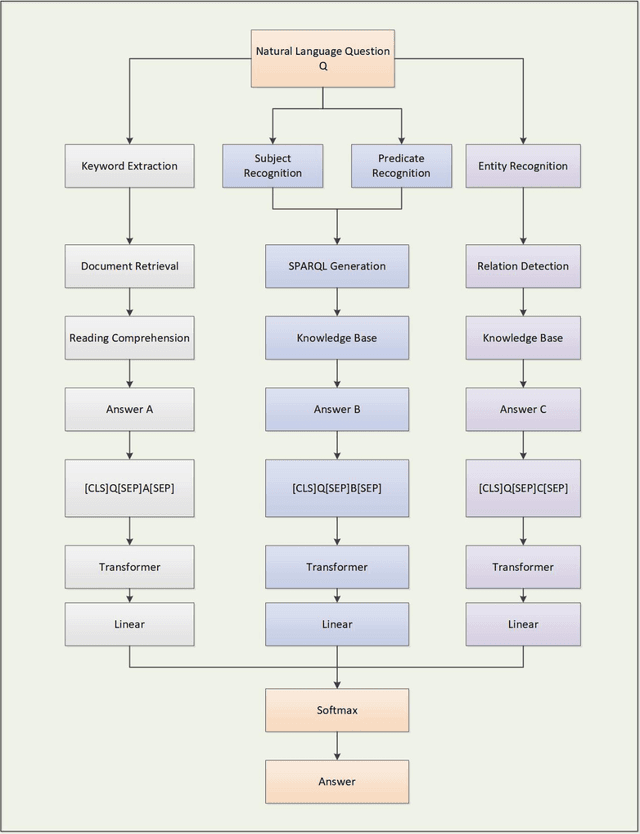
Search engines based on keyword retrieval can no longer adapt to the way of information acquisition in the era of intelligent Internet of Things due to the return of keyword related Internet pages. How to quickly, accurately and effectively obtain the information needed by users from massive Internet data has become one of the key issues urgently needed to be solved. We propose an intelligent question-answering system based on structured KB and unstructured data, called OpenQA, in which users can give query questions and the model can quickly give accurate answers back to users. We integrate KBQA structured question answering based on semantic parsing and deep representation learning, and two-stage unstructured question answering based on retrieval and neural machine reading comprehension into OpenQA, and return the final answer with the highest probability through the Transformer answer selection module in OpenQA. We carry out preliminary experiments on our constructed dataset, and the experimental results prove the effectiveness of the proposed intelligent question answering system. At the same time, the core technology of each module of OpenQA platform is still in the forefront of academic hot spots, and the theoretical essence and enrichment of OpenQA will be further explored based on these academic hot spots.
Bidirectional Pricing and Demand Response for Nanogrids with HVAC Systems
Mar 01, 2022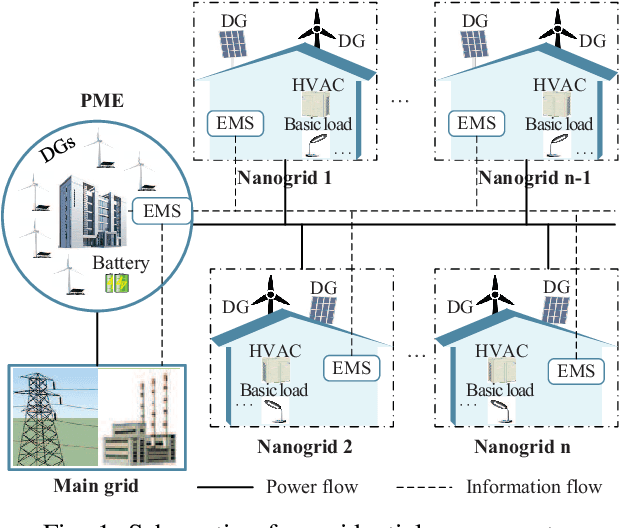

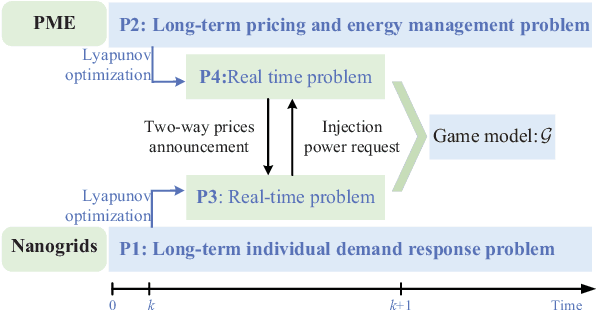
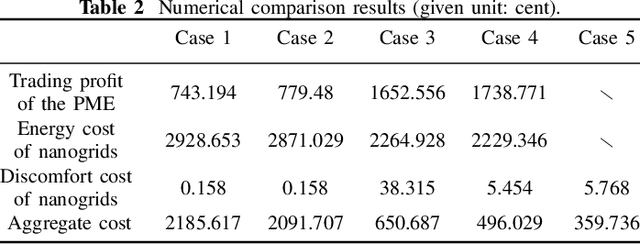
Owing to the fluctuant renewable generation and power demand, the energy surplus or deficit in each nanogrid is embodied differently across time. To stimulate local renewable energy consumption and minimize the long-term energy cost, some issues still remain to be explored: when and how the energy demand and bidirectional trading prices are scheduled considering personal comfort preferences and environmental factors. For this purpose, the demand response and two-way pricing problems concurrently for nanogrids and a public monitoring entity (PME) are studied with exploiting the large potential thermal elastic ability of heating, ventilation and air-conditioning (HVAC) units. Different from nanogrids, in terms of minimizing time-average costs, PME aims to set reasonable prices and optimize profits by trading with nanogrids and the main grid bi-directionally. In particular, such bilevel energy management problem is formulated as a stochastic form in a long-term horizon. Since there are uncertain system parameters, time-coupled queue constraints and the interplay of bilevel decision-making, it is challenging to solve the formulated problems. To this end, we derive a form of relaxation based on Lyapunov optimization technique to make the energy management problem tractable without forecasting the related system parameters. The transaction between nanogrids and PME is captured by a one-leader and multi-follower Stackelberg game framework. Then, theoretical analysis of the existence and uniqueness of Stackelberg equilibrium (SE) is developed based on the proposed game property. Following that, we devise an optimization algorithm to reach the SE with less information exchange. Numerical experiments validate the effectiveness of the proposed approach.
Finite-time enclosing control for multiple moving targets: a continuous estimator approach
Feb 01, 2022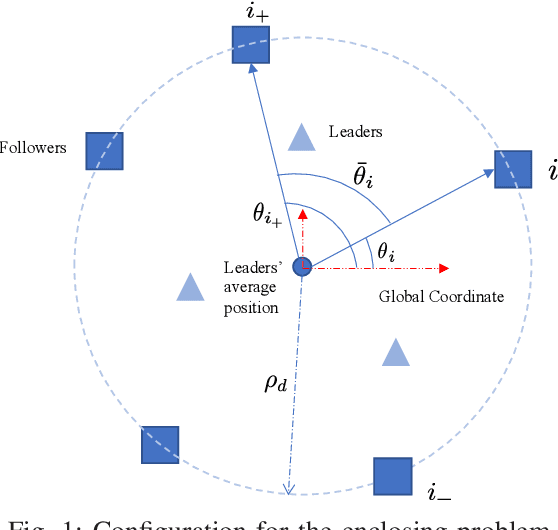
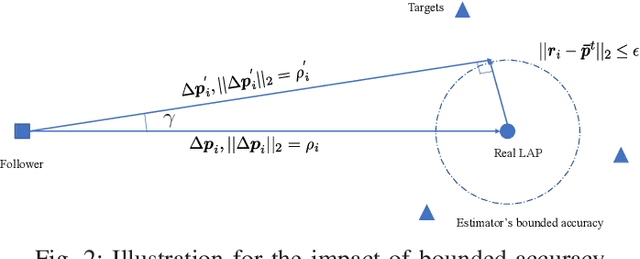
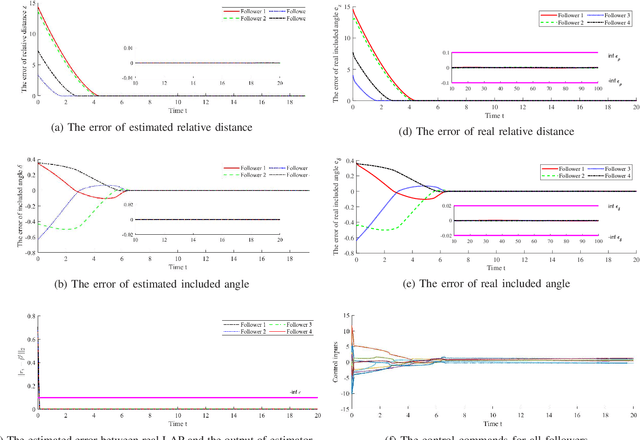
This work addresses the finite-time enclosing control problem where a set of followers are deployed to encircle and rotate around multiple moving targets with a predefined spacing pattern in finite time. A novel distributed and continuous estimator is firstly proposed to track the geometric center of targets in finite time using only local information for every follower. Then a pair of decentralized control laws for both the relative distance and included angle, respectively, are designed to achieve the desired spacing pattern in finite time based on the output of the proposed estimator. Through both theoretical analysis and simulation validation, we show that the proposed estimator is continuous and therefore can avoid dithering control output while still inheriting the merit of finite-time convergence. The steady errors of the estimator and the enclosing controller are guaranteed to converge to some bounded and adjustable regions around zero.
An Off-grid Compressive Sensing Strategy for the Subarray Synthesis of Non-uniform Linear Arrays
Dec 31, 2021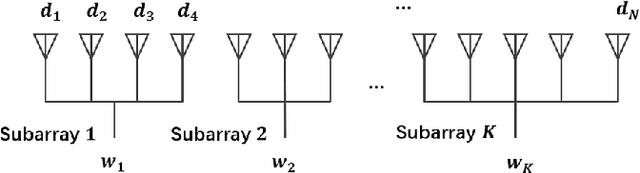
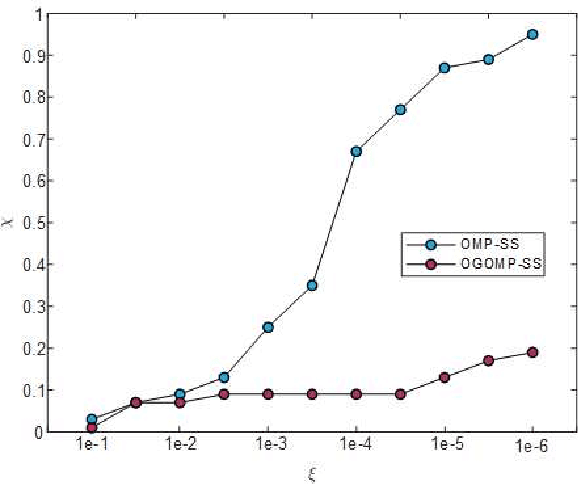
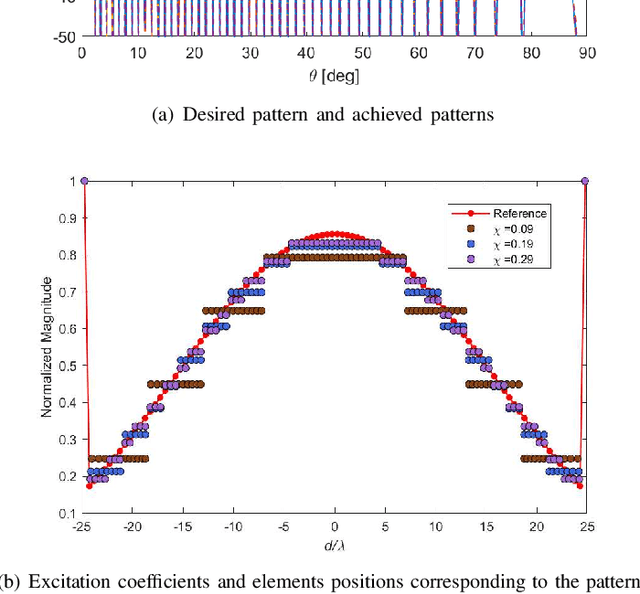
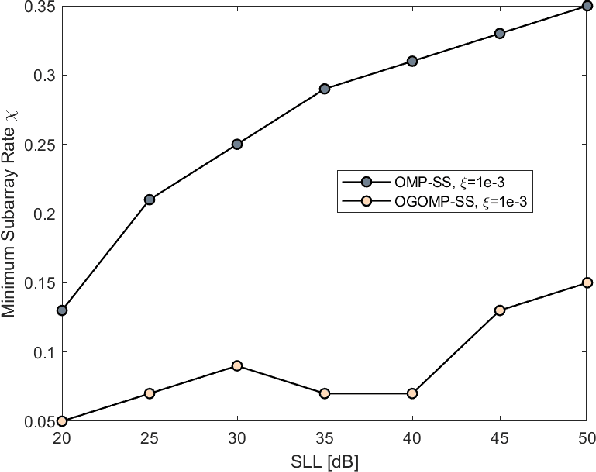
With the increasing popularity of large-scale antenna arrays, the subarraying technology becomes more attractive. In this paper, we propose two effective subarraying methods right after formulating the subarray synthesis as a compressive sensing (CS) problem: i) Orthogonal matching pursuit based subarray synthesis (OMP-SS), a common CS approach which can be used for the subarray synthesis to attain the subarray information (the subarray number, the number of elements per subarray and corresponding excitation coeffcients) and ii) Off-grid orthogonal matching pursuit based subarray synthesis (OGOMP-SS), an advanced approach for optimizing antenna elements positions and the subarray information mentioned above simultaneously. In addition, two user-defined modes are designed for different application scenarios, wherein, mode-1 is to optimize the pattern synthesis performance for the given the number of subarrays, and mode-2 is to obtain the minimum number of subarrays for the cases when the pattern synthsis accuracy is satisfied. Finally, our simulation results reveal that it is of paramount significance to optimize antenna elements positions for the subarray synthesis performance on the one hand and demonstrate the excellent performances of proposed schemes in comparison with other competitive state-of-the-art subarray synthesis methods on the other hand.
State-of-the-Art Review of Design of Experiments for Physics-Informed Deep Learning
Feb 13, 2022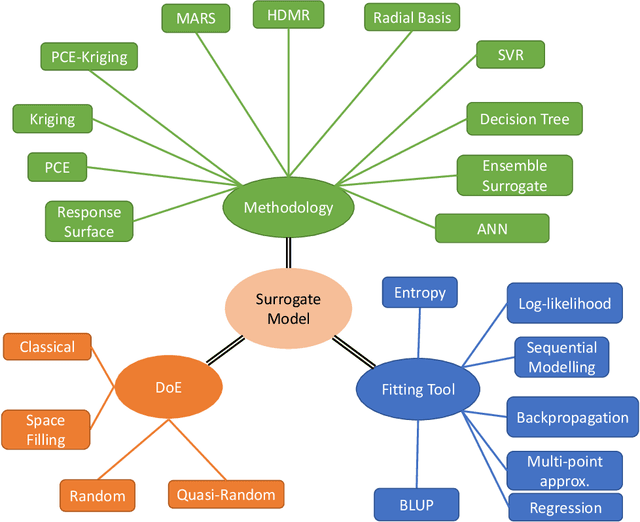

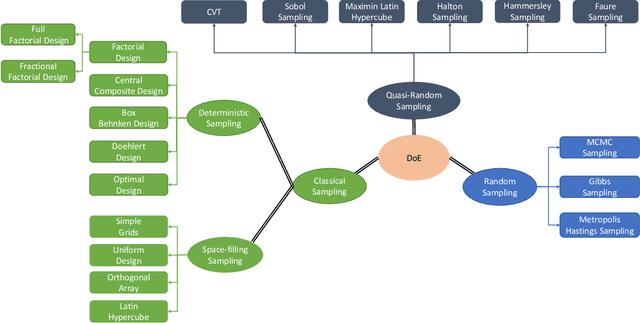
This paper presents a comprehensive review of the design of experiments used in the surrogate models. In particular, this study demonstrates the necessity of the design of experiment schemes for the Physics-Informed Neural Network (PINN), which belongs to the supervised learning class. Many complex partial differential equations (PDEs) do not have any analytical solution; only numerical methods are used to solve the equations, which is computationally expensive. In recent decades, PINN has gained popularity as a replacement for numerical methods to reduce the computational budget. PINN uses physical information in the form of differential equations to enhance the performance of the neural networks. Though it works efficiently, the choice of the design of experiment scheme is important as the accuracy of the predicted responses using PINN depends on the training data. In this study, five different PDEs are used for numerical purposes, i.e., viscous Burger's equation, Shr\"{o}dinger equation, heat equation, Allen-Cahn equation, and Korteweg-de Vries equation. A comparative study is performed to establish the necessity of the selection of a DoE scheme. It is seen that the Hammersley sampling-based PINN performs better than other DoE sample strategies.
Sketch-and-Lift: Scalable Subsampled Semidefinite Program for $K$-means Clustering
Feb 09, 2022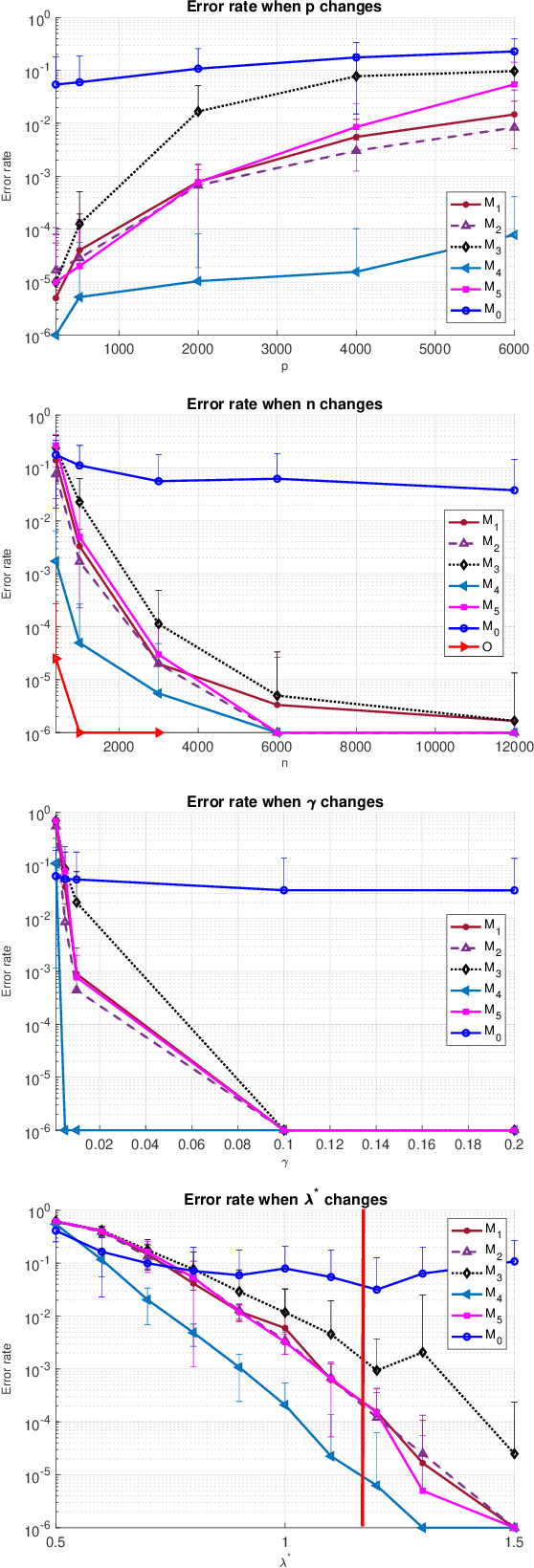
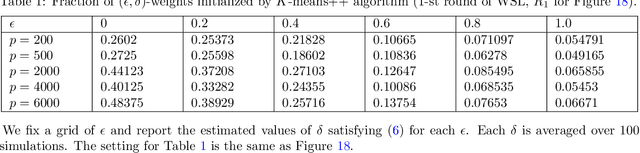
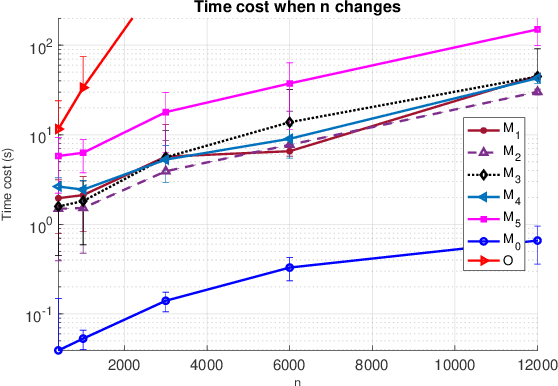
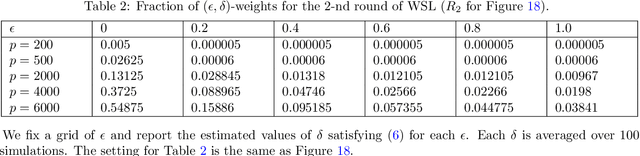
Semidefinite programming (SDP) is a powerful tool for tackling a wide range of computationally hard problems such as clustering. Despite the high accuracy, semidefinite programs are often too slow in practice with poor scalability on large (or even moderate) datasets. In this paper, we introduce a linear time complexity algorithm for approximating an SDP relaxed $K$-means clustering. The proposed sketch-and-lift (SL) approach solves an SDP on a subsampled dataset and then propagates the solution to all data points by a nearest-centroid rounding procedure. It is shown that the SL approach enjoys a similar exact recovery threshold as the $K$-means SDP on the full dataset, which is known to be information-theoretically tight under the Gaussian mixture model. The SL method can be made adaptive with enhanced theoretic properties when the cluster sizes are unbalanced. Our simulation experiments demonstrate that the statistical accuracy of the proposed method outperforms state-of-the-art fast clustering algorithms without sacrificing too much computational efficiency, and is comparable to the original $K$-means SDP with substantially reduced runtime.