 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Private Read Update Write (PRUW) with Storage Constrained Databases
Feb 07, 2022
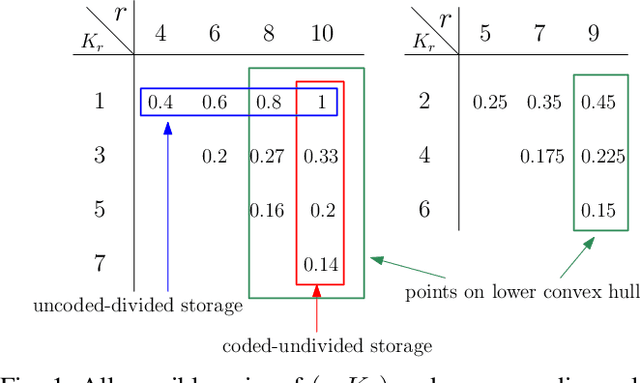
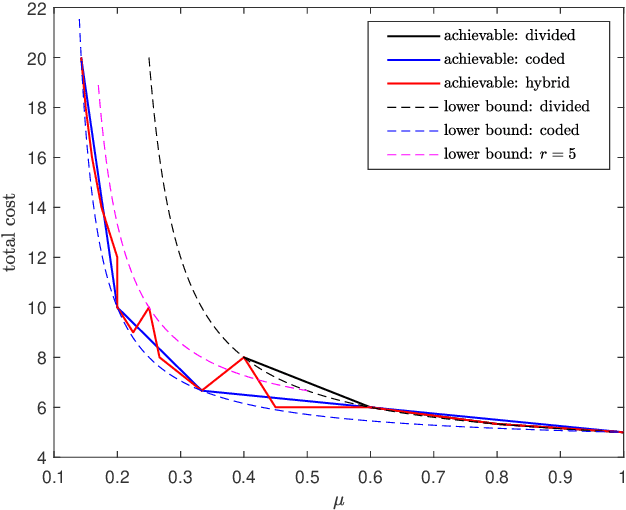
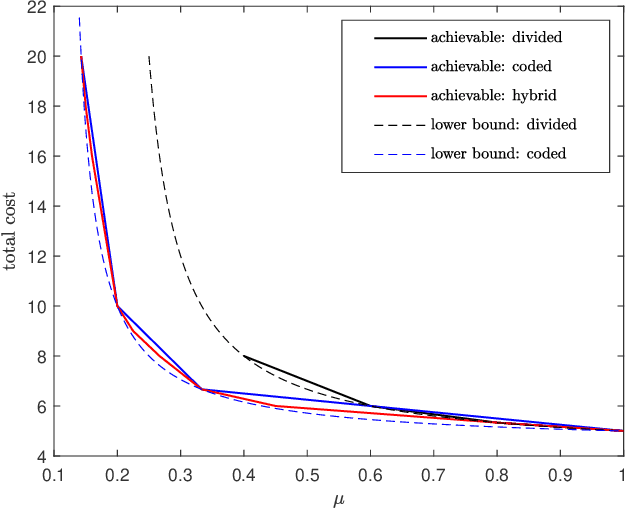
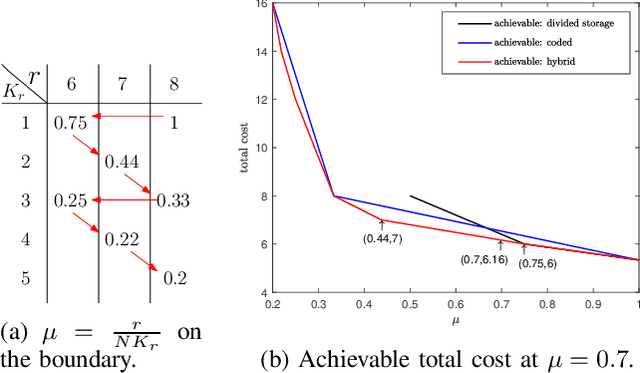
We investigate the problem of private read update write (PRUW) in relation to federated submodel learning (FSL) with storage constrained databases. In PRUW, a user privately reads a submodel from a system of $N$ databases containing $M$ submodels, updates it locally, and writes the update back to the databases without revealing the submodel index or the value of the update. The databases considered in this problem are only allowed to store a given amount of information specified by an arbitrary storage constraint. We provide a storage mechanism that determines the contents of each database prior to the application of the PRUW scheme, such that the total communication cost is minimized. We show that the proposed storage scheme achieves a lower total cost compared to what is achieved by using \emph{coded storage} or \emph{divided storage} to meet the given storage constraint.
Combining Commonsense Reasoning and Knowledge Acquisition to Guide Deep Learning in Robotics
Jan 25, 2022
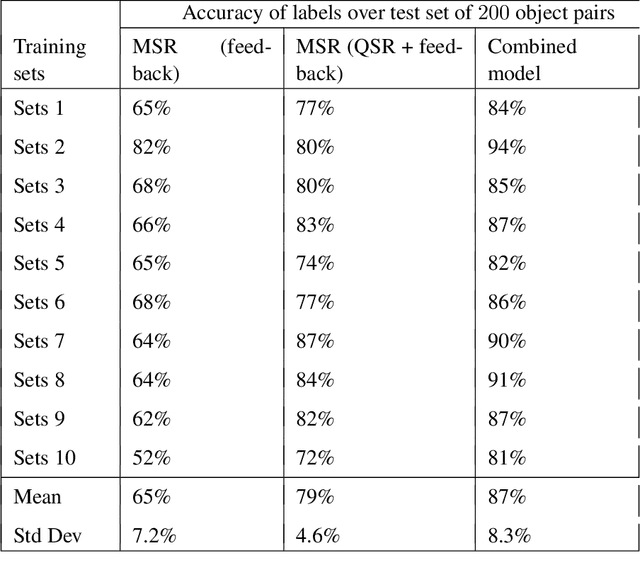
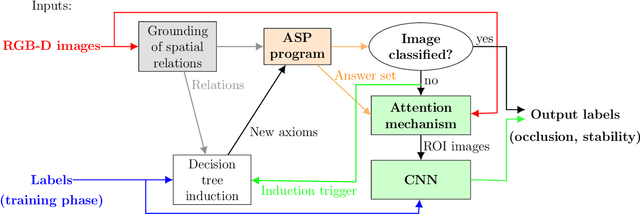

Algorithms based on deep network models are being used for many pattern recognition and decision-making tasks in robotics and AI. Training these models requires a large labeled dataset and considerable computational resources, which are not readily available in many domains. Also, it is difficult to explore the internal representations and reasoning mechanisms of these models. As a step towards addressing the underlying knowledge representation, reasoning, and learning challenges, the architecture described in this paper draws inspiration from research in cognitive systems. As a motivating example, we consider an assistive robot trying to reduce clutter in any given scene by reasoning about the occlusion of objects and stability of object configurations in an image of the scene. In this context, our architecture incrementally learns and revises a grounding of the spatial relations between objects and uses this grounding to extract spatial information from input images. Non-monotonic logical reasoning with this information and incomplete commonsense domain knowledge is used to make decisions about stability and occlusion. For images that cannot be processed by such reasoning, regions relevant to the tasks at hand are automatically identified and used to train deep network models to make the desired decisions. Image regions used to train the deep networks are also used to incrementally acquire previously unknown state constraints that are merged with the existing knowledge for subsequent reasoning. Experimental evaluation performed using simulated and real-world images indicates that in comparison with baselines based just on deep networks, our architecture improves reliability of decision making and reduces the effort involved in training data-driven deep network models.
SC-Reg: Training Overparameterized Neural Networks under Self-Concordant Regularization
Dec 14, 2021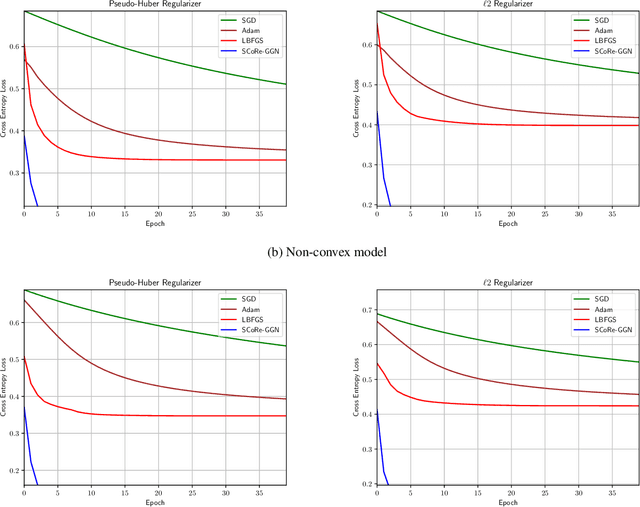

In this paper we propose the SC-Reg (self-concordant regularization) framework for learning overparameterized feedforward neural networks by incorporating second-order information in the \emph{Newton decrement} framework for convex problems. We propose the generalized Gauss-Newton with Self-Concordant Regularization (SCoRe-GGN) algorithm that updates the network parameters each time it receives a new input batch. The proposed algorithm exploits the structure of the second-order information in the Hessian matrix, thereby reducing the training computational overhead. Although our current analysis considers only the convex case, numerical experiments show the efficiency of our method and its fast convergence under both convex and non-convex settings, which compare favorably against baseline first-order methods and a quasi-Newton method.
Learning Branch Probabilities in Compiler from Datacenter Workloads
Feb 10, 2022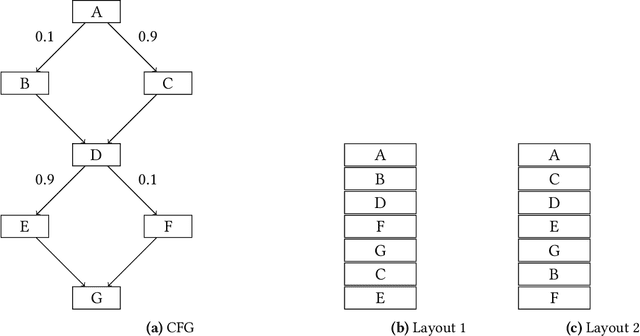
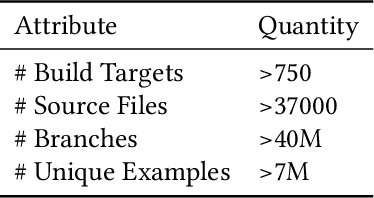
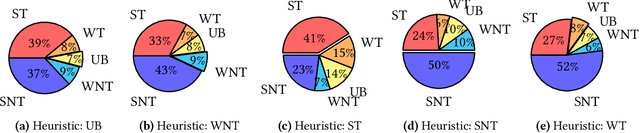
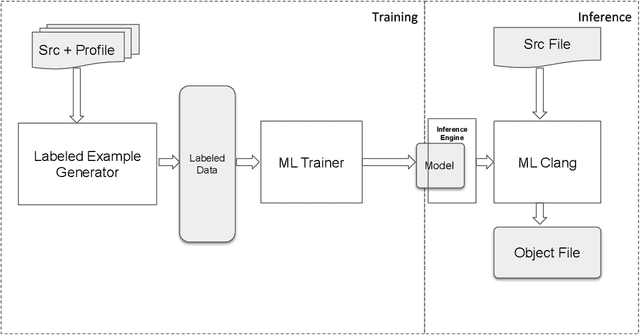
Estimating the probability with which a conditional branch instruction is taken is an important analysis that enables many optimizations in modern compilers. When using Profile Guided Optimizations (PGO), compilers are able to make a good estimation of the branch probabilities. In the absence of profile information, compilers resort to using heuristics for this purpose. In this work, we propose learning branch probabilities from a large corpus of data obtained from datacenter workloads. Using metrics including Root Mean Squared Error, Mean Absolute Error and cross-entropy, we show that the machine learning model improves branch probability estimation by 18-50% in comparison to compiler heuristics. This translates to performance improvement of up to 8.1% on 24 out of a suite of 40 benchmarks with a 1% geomean improvement on the suite. This also results in greater than 1.2% performance improvement in an important search application.
Unsupervised physics-informed disentanglement of multimodal data for high-throughput scientific discovery
Feb 07, 2022We introduce physics-informed multimodal autoencoders (PIMA) - a variational inference framework for discovering shared information in multimodal scientific datasets representative of high-throughput testing. Individual modalities are embedded into a shared latent space and fused through a product of experts formulation, enabling a Gaussian mixture prior to identify shared features. Sampling from clusters allows cross-modal generative modeling, with a mixture of expert decoder imposing inductive biases encoding prior scientific knowledge and imparting structured disentanglement of the latent space. This approach enables discovery of fingerprints which may be detected in high-dimensional heterogeneous datasets, avoiding traditional bottlenecks related to high-fidelity measurement and characterization. Motivated by accelerated co-design and optimization of materials manufacturing processes, a dataset of lattice metamaterials from metal additive manufacturing demonstrates accurate cross modal inference between images of mesoscale topology and mechanical stress-strain response.
TURNER: The Uncertainty-based Retrieval Framework for Chinese NER
Feb 18, 2022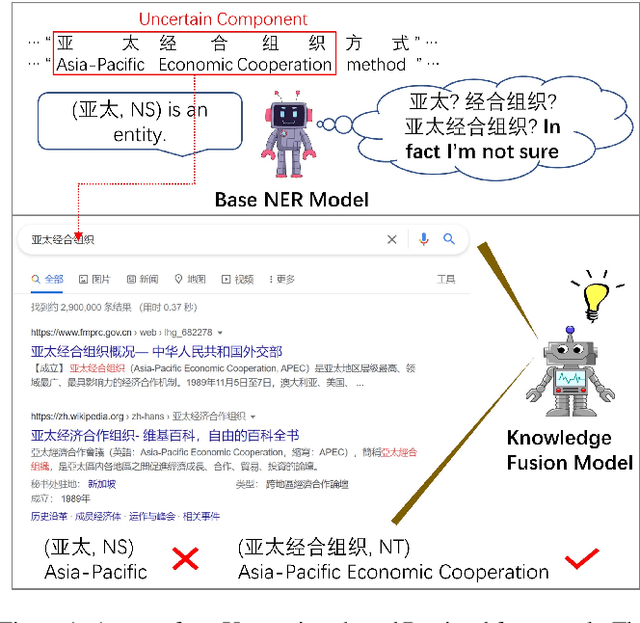

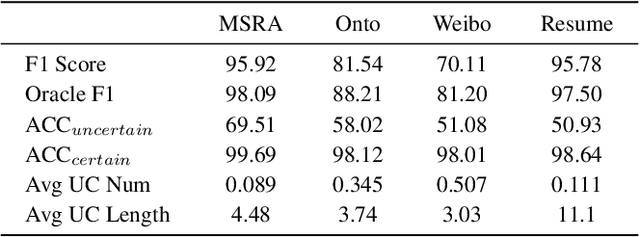
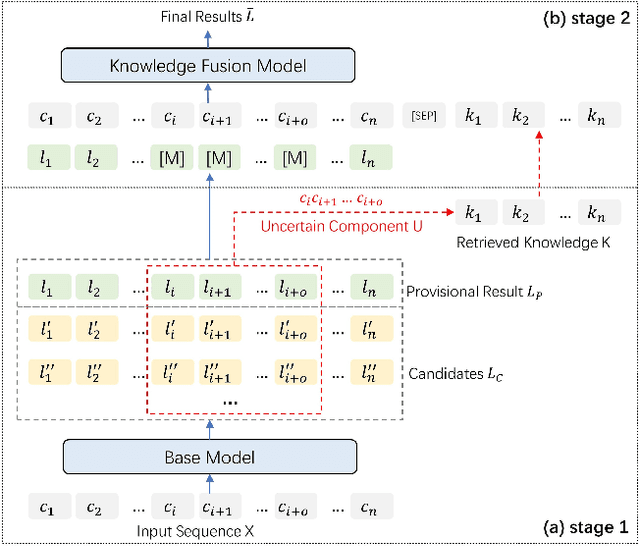
Chinese NER is a difficult undertaking due to the ambiguity of Chinese characters and the absence of word boundaries. Previous work on Chinese NER focus on lexicon-based methods to introduce boundary information and reduce out-of-vocabulary (OOV) cases during prediction. However, it is expensive to obtain and dynamically maintain high-quality lexicons in specific domains, which motivates us to utilize more general knowledge resources, e.g., search engines. In this paper, we propose TURNER: The Uncertainty-based Retrieval framework for Chinese NER. The idea behind TURNER is to imitate human behavior: we frequently retrieve auxiliary knowledge as assistance when encountering an unknown or uncertain entity. To improve the efficiency and effectiveness of retrieval, we first propose two types of uncertainty sampling methods for selecting the most ambiguous entity-level uncertain components of the input text. Then, the Knowledge Fusion Model re-predict the uncertain samples by combining retrieved knowledge. Experiments on four benchmark datasets demonstrate TURNER's effectiveness. TURNER outperforms existing lexicon-based approaches and achieves the new SOTA.
Informative Causality Extraction from Medical Literature via Dependency-tree based Patterns
Mar 13, 2022
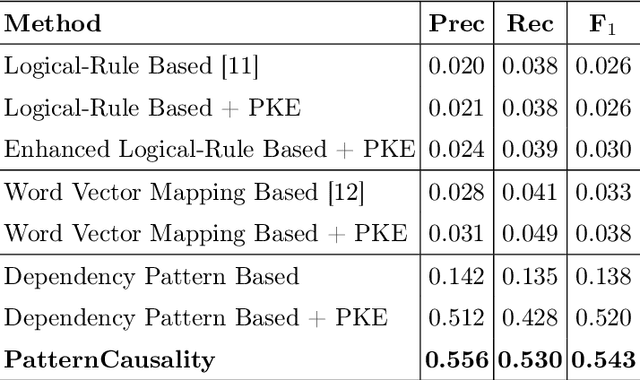
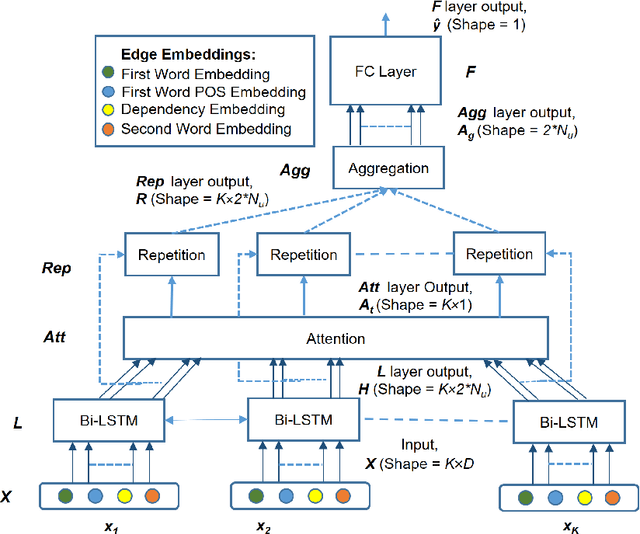
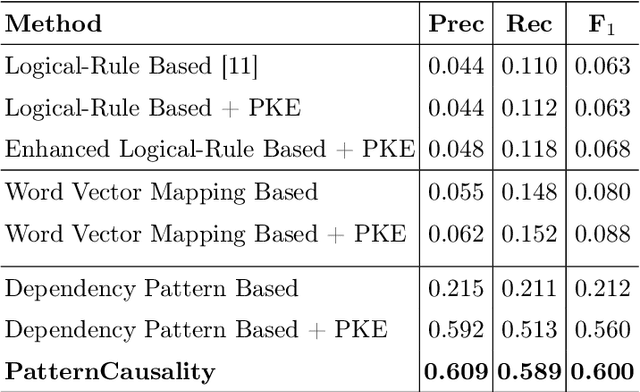
Extracting cause-effect entities from medical literature is an important task in medical information retrieval. A solution for solving this task can be used for compilation of various causality relations, such as, causality between disease and symptoms, between medications and side effects, between genes and diseases, etc. Existing solutions for extracting cause-effect entities work well for sentences where the cause and the effect phrases are name entities, single-word nouns, or noun phrases consisting of two to three words. Unfortunately, in medical literature, cause and effect phrases in a sentence are not simply nouns or noun phrases, rather they are complex phrases consisting of several words, and existing methods fail to correctly extract the cause and effect entities in such sentences. Partial extraction of cause and effect entities conveys poor quality, non informative, and often, contradictory facts, comparing to the one intended in the given sentence. In this work, we solve this problem by designing an unsupervised method for cause and effect phrase extraction, PatternCausality, which is specifically suitable for the medical literature. Our proposed approach first uses a collection of cause-effect dependency patterns as template to extract head words of cause and effect phrases and then it uses a novel phrase extraction method to obtain complete and meaningful cause and effect phrases from a sentence. Experiments on a cause-effect dataset built from sentences from PubMed articles show that for extracting cause and effect entities, PatternCausality is substantially better than the existing methods with an order of magnitude improvement in the F-score metric over the best of the existing methods.
* 22 pages without comment
SEED: Sound Event Early Detection via Evidential Uncertainty
Feb 13, 2022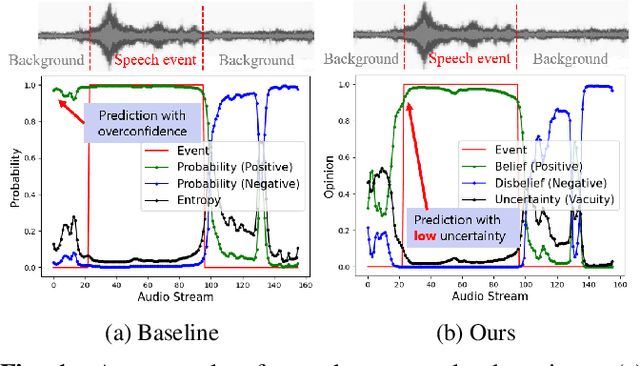

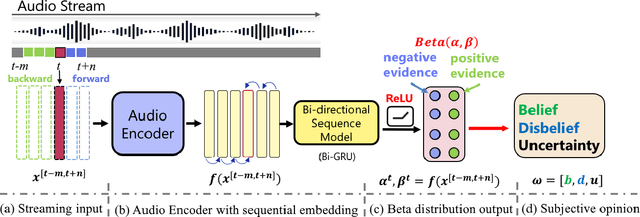
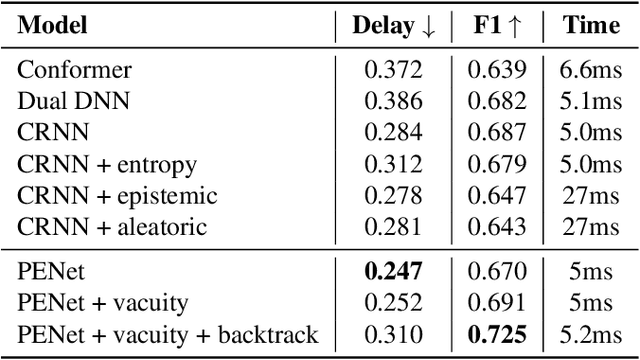
Sound Event Early Detection (SEED) is an essential task in recognizing the acoustic environments and soundscapes. However, most of the existing methods focus on the offline sound event detection, which suffers from the over-confidence issue of early-stage event detection and usually yield unreliable results. To solve the problem, we propose a novel Polyphonic Evidential Neural Network (PENet) to model the evidential uncertainty of the class probability with Beta distribution. Specifically, we use a Beta distribution to model the distribution of class probabilities, and the evidential uncertainty enriches uncertainty representation with evidence information, which plays a central role in reliable prediction. To further improve the event detection performance, we design the backtrack inference method that utilizes both the forward and backward audio features of an ongoing event. Experiments on the DESED database show that the proposed method can simultaneously improve 13.0\% and 3.8\% in time delay and detection F1 score compared to the state-of-the-art methods.
Joint Learning of Frequency and Spatial Domains for Dense Predictions
Feb 18, 2022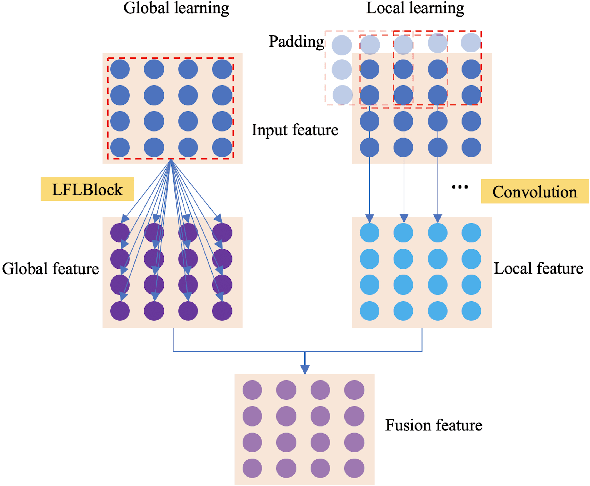
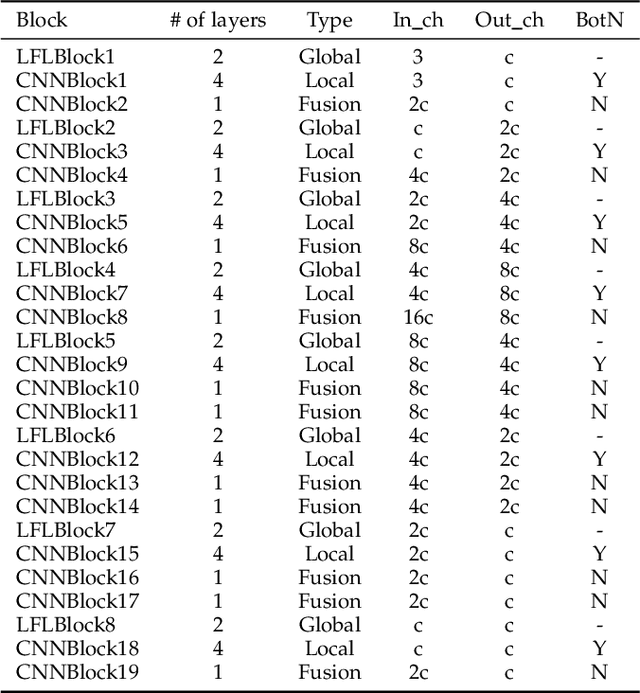
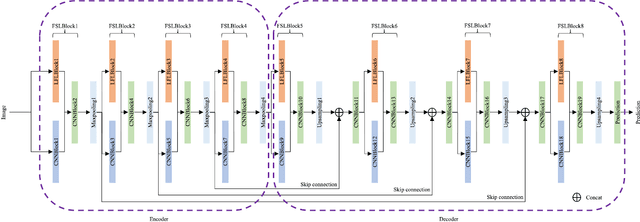
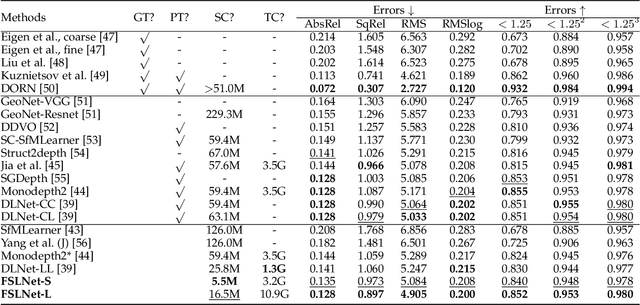
Current artificial neural networks mainly conduct the learning process in the spatial domain but neglect the frequency domain learning. However, the learning course performed in the frequency domain can be more efficient than that in the spatial domain. In this paper, we fully explore frequency domain learning and propose a joint learning paradigm of frequency and spatial domains. This paradigm can take full advantage of the preponderances of frequency learning and spatial learning; specifically, frequency and spatial domain learning can effectively capture global and local information, respectively. Exhaustive experiments on two dense prediction tasks, i.e., self-supervised depth estimation and semantic segmentation, demonstrate that the proposed joint learning paradigm can 1) achieve performance competitive to those of state-of-the-art methods in both depth estimation and semantic segmentation tasks, even without pretraining; and 2) significantly reduce the number of parameters compared to other state-of-the-art methods, which provides more chance to develop real-world applications. We hope that the proposed method can encourage more research in cross-domain learning.
GCN-Transformer for short-term passenger flow prediction on holidays in urban rail transit systems
Feb 27, 2022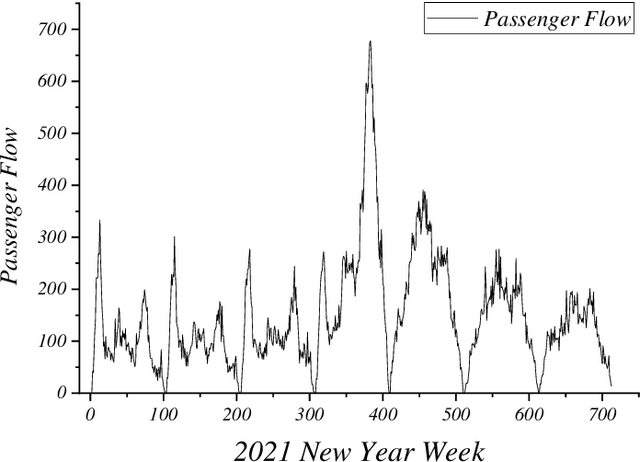
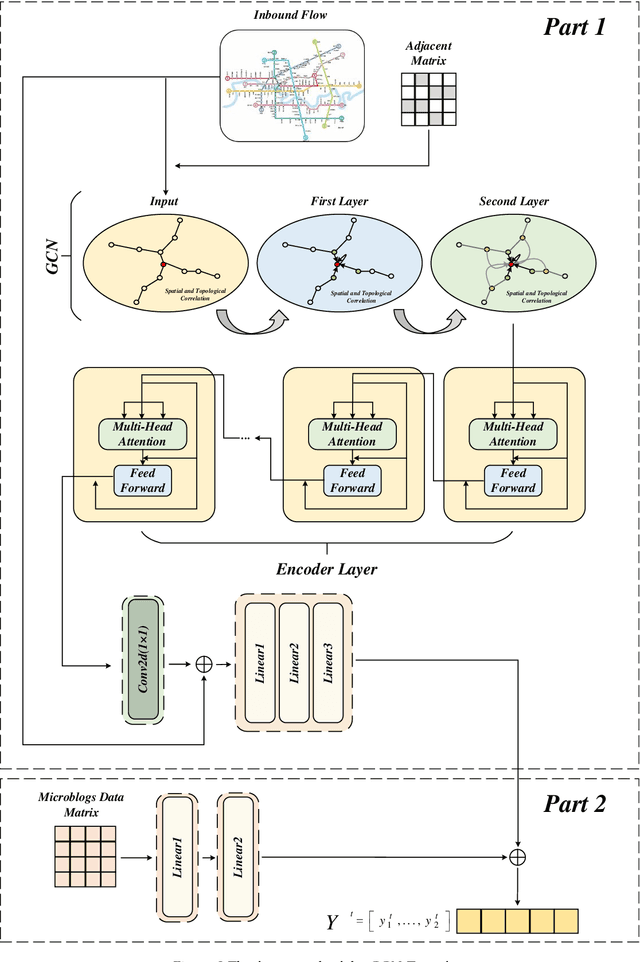
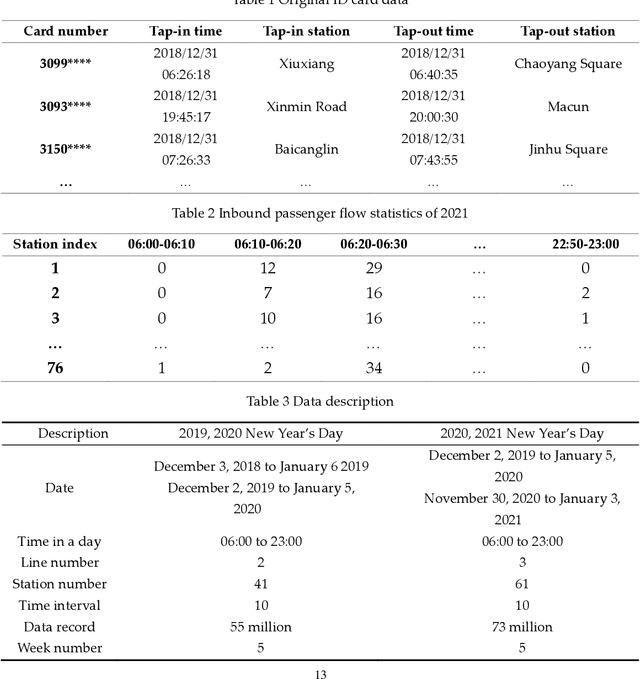
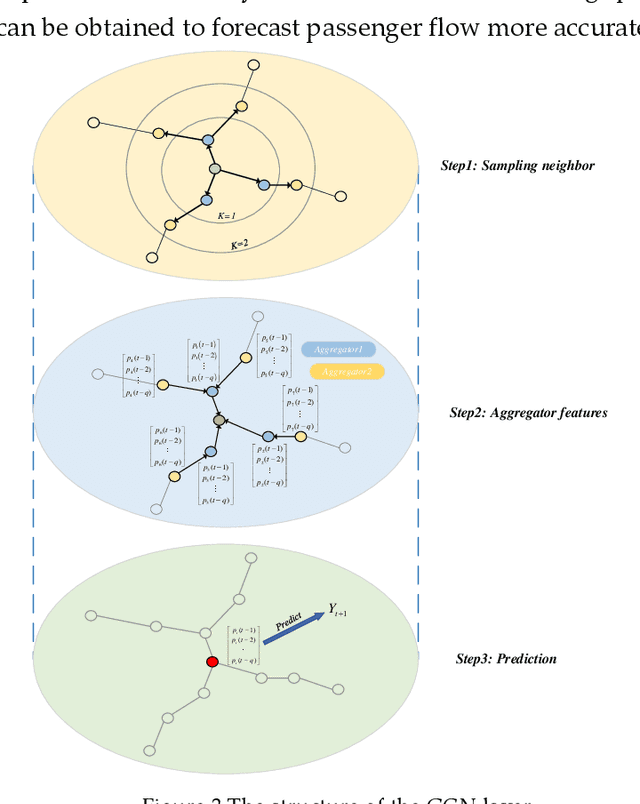
The short-term passenger flow prediction of the urban rail transit system is of great significance for traffic operation and management. The emerging deep learning-based models provide effective methods to improve prediction accuracy. However, most of the existing models mainly predict the passenger flow on general weekdays, while few studies focus on predicting the holiday passenger flow, which can provide more significant information for operators because congestions or accidents generally occur on holidays. To this end, we propose a deep learning-based model named GCN-Transformer comprising graph conventional neural network (GCN) and Transformer for short-term passenger flow prediction on holidays. The GCN is applied to extract the spatial features of passenger flows and the Transformer is applied to extract the temporal features of passenger flows. Moreover, in addition to the historical passenger flow data, social media data are also incorporated into the prediction model, which has been proven to have a potential correlation with the fluctuation of passenger flow. The GCN-Transformer is tested on two large-scale real-world datasets from Nanning, China during the New Year holiday and is compared with several conventional prediction models. Results demonstrate its better robustness and advantages among baseline methods, which provides overwhelming support for practical applications of short-term passenger flow prediction on holidays