 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hyperparameter-free Continuous Learning for Domain Classification in Natural Language Understanding
Jan 05, 2022
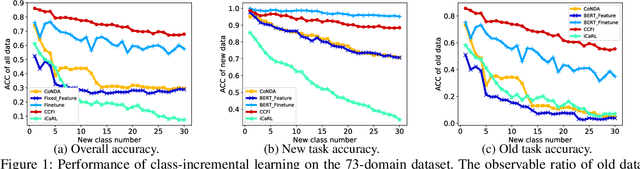

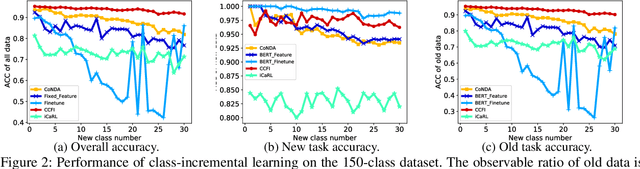

Domain classification is the fundamental task in natural language understanding (NLU), which often requires fast accommodation to new emerging domains. This constraint makes it impossible to retrain all previous domains, even if they are accessible to the new model. Most existing continual learning approaches suffer from low accuracy and performance fluctuation, especially when the distributions of old and new data are significantly different. In fact, the key real-world problem is not the absence of old data, but the inefficiency to retrain the model with the whole old dataset. Is it potential to utilize some old data to yield high accuracy and maintain stable performance, while at the same time, without introducing extra hyperparameters? In this paper, we proposed a hyperparameter-free continual learning model for text data that can stably produce high performance under various environments. Specifically, we utilize Fisher information to select exemplars that can "record" key information of the original model. Also, a novel scheme called dynamical weight consolidation is proposed to enable hyperparameter-free learning during the retrain process. Extensive experiments demonstrate that baselines suffer from fluctuated performance and therefore useless in practice. On the contrary, our proposed model CCFI significantly and consistently outperforms the best state-of-the-art method by up to 20% in average accuracy, and each component of CCFI contributes effectively to overall performance.
Stage-Aware Feature Alignment Network for Real-Time Semantic Segmentation of Street Scenes
Mar 08, 2022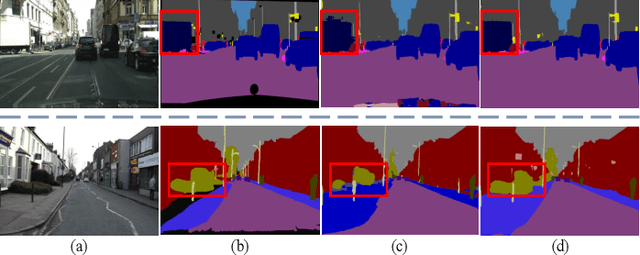
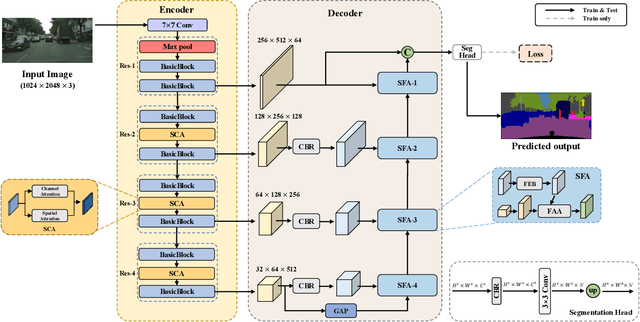
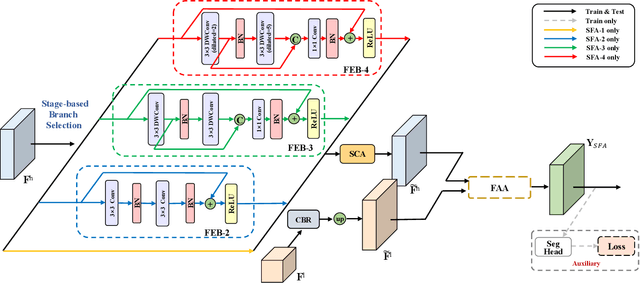
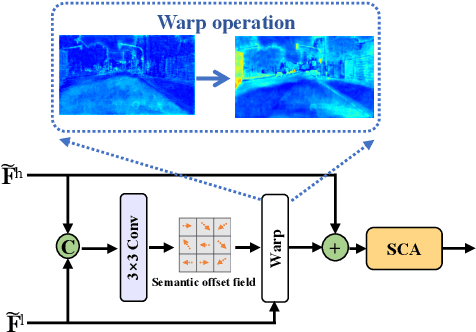
Over the past few years, deep convolutional neural network-based methods have made great progress in semantic segmentation of street scenes. Some recent methods align feature maps to alleviate the semantic gap between them and achieve high segmentation accuracy. However, they usually adopt the feature alignment modules with the same network configuration in the decoder and thus ignore the different roles of stages of the decoder during feature aggregation, leading to a complex decoder structure. Such a manner greatly affects the inference speed. In this paper, we present a novel Stage-aware Feature Alignment Network (SFANet) based on the encoder-decoder structure for real-time semantic segmentation of street scenes. Specifically, a Stage-aware Feature Alignment module (SFA) is proposed to align and aggregate two adjacent levels of feature maps effectively. In the SFA, by taking into account the unique role of each stage in the decoder, a novel stage-aware Feature Enhancement Block (FEB) is designed to enhance spatial details and contextual information of feature maps from the encoder. In this way, we are able to address the misalignment problem with a very simple and efficient multi-branch decoder structure. Moreover, an auxiliary training strategy is developed to explicitly alleviate the multi-scale object problem without bringing additional computational costs during the inference phase. Experimental results show that the proposed SFANet exhibits a good balance between accuracy and speed for real-time semantic segmentation of street scenes. In particular, based on ResNet-18, SFANet respectively obtains 78.1% and 74.7% mean of class-wise Intersection-over-Union (mIoU) at inference speeds of 37 FPS and 96 FPS on the challenging Cityscapes and CamVid test datasets by using only a single GTX 1080Ti GPU.
Consistency and Coherence from Points of Contextual Similarity
Dec 22, 2021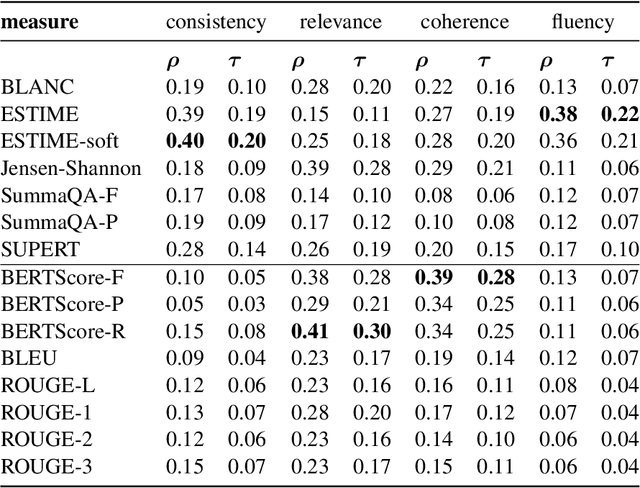
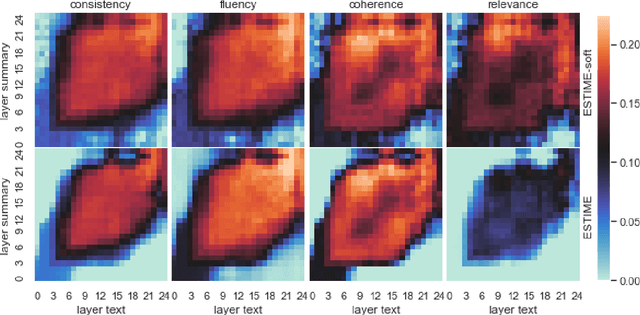
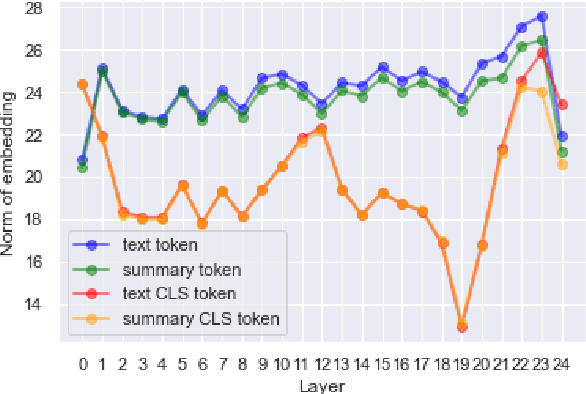
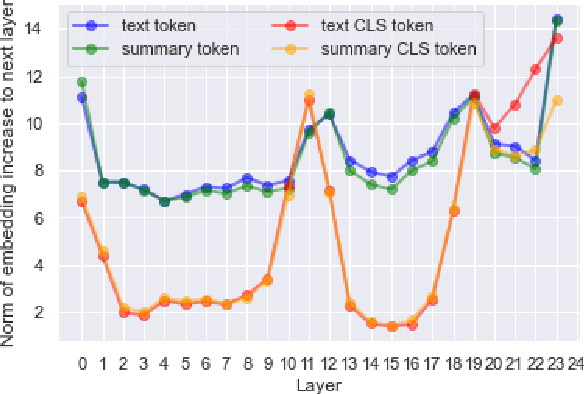
Factual consistency is one of important summary evaluation dimensions, especially as summary generation becomes more fluent and coherent. The ESTIME measure, recently proposed specifically for factual consistency, achieves high correlations with human expert scores both for consistency and fluency, while in principle being restricted to evaluating such text-summary pairs that have high dictionary overlap. This is not a problem for current styles of summarization, but it may become an obstacle for future summarization systems, or for evaluating arbitrary claims against the text. In this work we generalize the method, making it applicable to any text-summary pairs. As ESTIME uses points of contextual similarity, it provides insights into usefulness of information taken from different BERT layers. We observe that useful information exists in almost all of the layers except the several lowest ones. For consistency and fluency - qualities focused on local text details - the most useful layers are close to the top (but not at the top); for coherence and relevance we found a more complicated and interesting picture.
Sampling Random Group Fair Rankings
Mar 02, 2022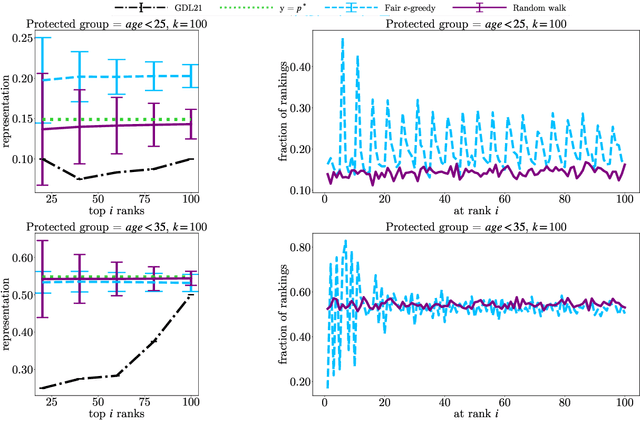
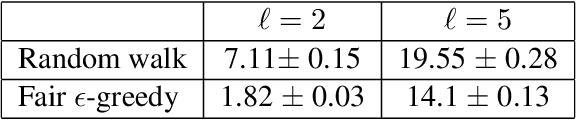
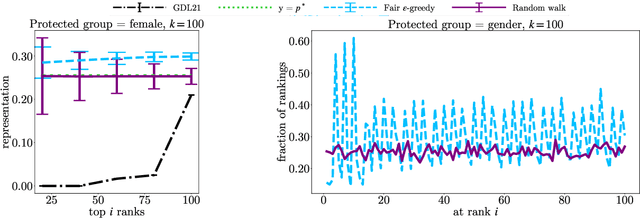
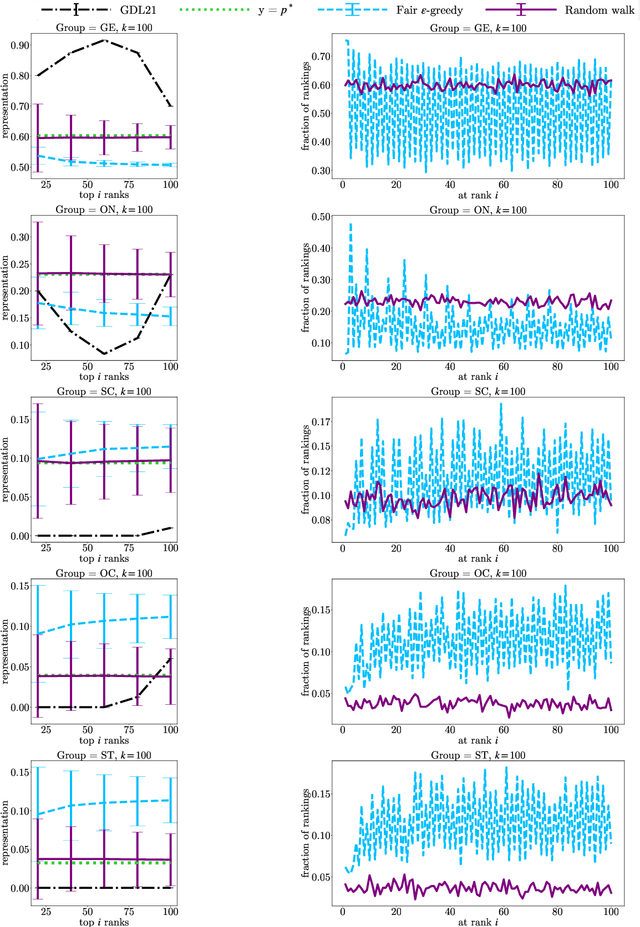
In this paper, we consider the problem of randomized group fair ranking that merges given ranked list of items from different sensitive demographic groups while satisfying given lower and upper bounds on the representation of each group in the top ranks. Our randomized group fair ranking formulation works even when there is implicit bias, incomplete relevance information, or when only ordinal ranking is available instead of relevance scores or utility values. We take an axiomatic approach and show that there is a unique distribution $\mathcal{D}$ to sample a random group fair ranking that satisfies a natural set of consistency and fairness axioms. Moreover, $\mathcal{D}$ satisfies representation constraints for every group at every rank, a characteristic that cannot be satisfied by any deterministic ranking. We propose three algorithms to sample a random group fair ranking from $\mathcal{D}$. Our first algorithm samples rankings from $\mathcal{D}$ exactly, in time exponential in the number of groups. Our second algorithm samples random group fair rankings from $\mathcal{D}$ exactly and is faster than the first algorithm when the gap between upper and lower bounds on the representation for each group is small. Our third algorithm samples rankings from a distribution $\epsilon$-close to $\mathcal{D}$ in total variation distance, and has expected running time polynomial in all input parameters and $1/\epsilon$ when there is a large gap between upper and lower bound representation constraints for all the groups. We experimentally validate the above guarantees of our algorithms for group fairness in top ranks and representation in every rank on real-world data sets.
Assessment of Fetal and Maternal Well-Being During Pregnancy Using Passive Wearable Inertial Sensor
Nov 19, 2021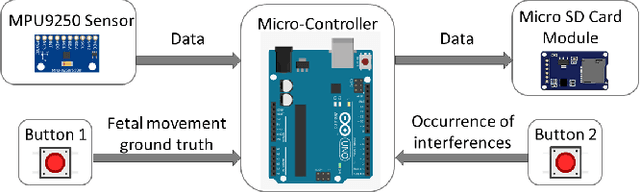
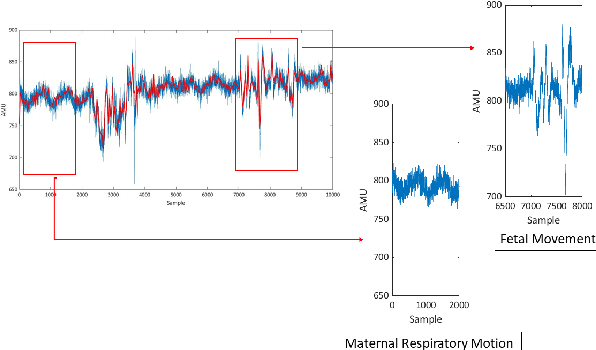
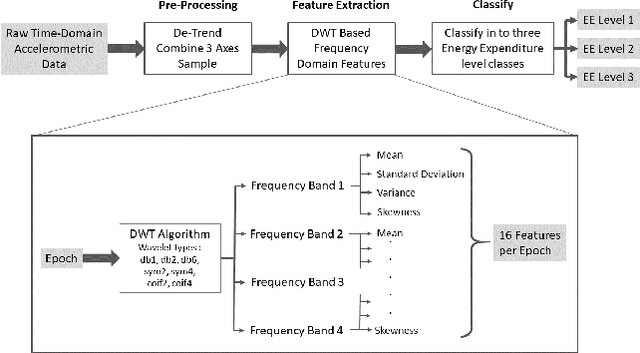
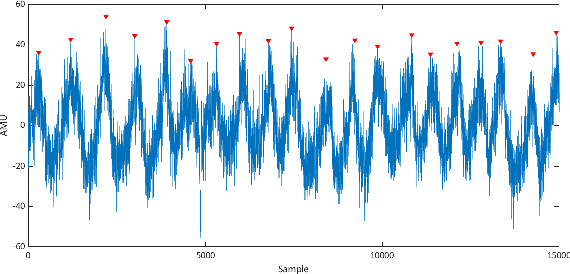
Assessing the health of both the fetus and mother is vital in preventing and identifying possible complications in pregnancy. This paper focuses on a device that can be used effectively by the mother herself with minimal supervision and provide a reasonable estimation of fetal and maternal health while being safe, comfortable, and easy to use. The device proposed uses a belt with a single accelerometer over the mother's uterus to record the required information. The device is expected to monitor both the mother and the fetus constantly over a long period and provide medical professionals with useful information, which they would otherwise overlook due to the low frequency that health monitoring is carried out at the present. The paper shows that simultaneous measurement of respiratory information of the mother and fetal movement is in fact possible even in the presence of mild interferences, which needs to be accounted for if the device is expected to be worn for extended times.
Semi-Random Sparse Recovery in Nearly-Linear Time
Mar 08, 2022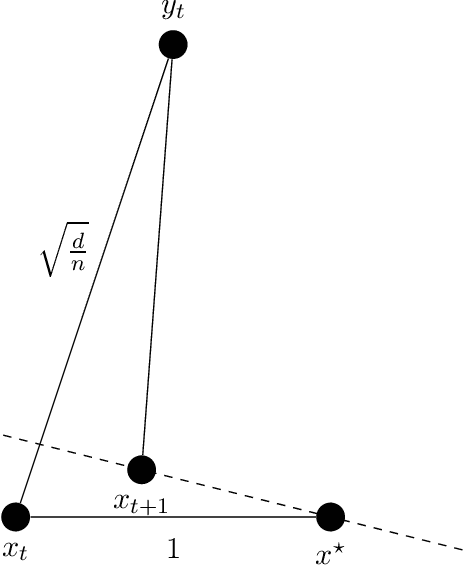
Sparse recovery is one of the most fundamental and well-studied inverse problems. Standard statistical formulations of the problem are provably solved by general convex programming techniques and more practical, fast (nearly-linear time) iterative methods. However, these latter "fast algorithms" have previously been observed to be brittle in various real-world settings. We investigate the brittleness of fast sparse recovery algorithms to generative model changes through the lens of studying their robustness to a "helpful" semi-random adversary, a framework which tests whether an algorithm overfits to input assumptions. We consider the following basic model: let $\mathbf{A} \in \mathbb{R}^{n \times d}$ be a measurement matrix which contains an unknown subset of rows $\mathbf{G} \in \mathbb{R}^{m \times d}$ which are bounded and satisfy the restricted isometry property (RIP), but is otherwise arbitrary. Letting $x^\star \in \mathbb{R}^d$ be $s$-sparse, and given either exact measurements $b = \mathbf{A} x^\star$ or noisy measurements $b = \mathbf{A} x^\star + \xi$, we design algorithms recovering $x^\star$ information-theoretically optimally in nearly-linear time. We extend our algorithm to hold for weaker generative models relaxing our planted RIP assumption to a natural weighted variant, and show that our method's guarantees naturally interpolate the quality of the measurement matrix to, in some parameter regimes, run in sublinear time. Our approach differs from prior fast iterative methods with provable guarantees under semi-random generative models: natural conditions on a submatrix which make sparse recovery tractable are NP-hard to verify. We design a new iterative method tailored to the geometry of sparse recovery which is provably robust to our semi-random model. We hope our approach opens the door to new robust, efficient algorithms for natural statistical inverse problems.
DeCorus: Hierarchical Multivariate Anomaly Detection at Cloud-Scale
Feb 14, 2022
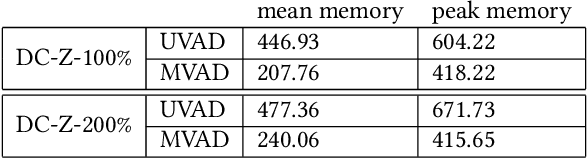
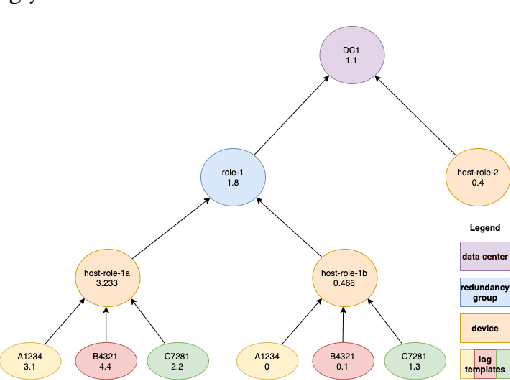
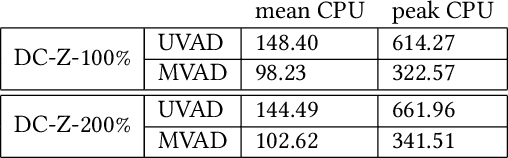
Multivariate anomaly detection can be used to identify outages within large volumes of telemetry data for computing systems. However, developing an efficient anomaly detector that can provide users with relevant information is a challenging problem. We introduce our approach to hierarchical multivariate anomaly detection called DeCorus, a statistical multivariate anomaly detector which achieves linear complexity. It extends standard statistical techniques to improve their ability to find relevant anomalies within noisy signals and makes use of types of domain knowledge that system operators commonly possess to compute system-level anomaly scores. We describe the implementation of DeCorus an online log anomaly detection tool for network device syslog messages deployed at a cloud service provider. We use real-world data sets that consist of $1.5$ billion network device syslog messages and hundreds of incident tickets to characterize the performance of DeCorus and compare its ability to detect incidents with five alternative anomaly detectors. While DeCorus outperforms the other anomaly detectors, all of them are challenged by our data set. We share how DeCorus provides value in the field and how we plan to improve its incident detection accuracy.
An experimental study of the vision-bottleneck in VQA
Feb 14, 2022As in many tasks combining vision and language, both modalities play a crucial role in Visual Question Answering (VQA). To properly solve the task, a given model should both understand the content of the proposed image and the nature of the question. While the fusion between modalities, which is another obviously important part of the problem, has been highly studied, the vision part has received less attention in recent work. Current state-of-the-art methods for VQA mainly rely on off-the-shelf object detectors delivering a set of object bounding boxes and embeddings, which are then combined with question word embeddings through a reasoning module. In this paper, we propose an in-depth study of the vision-bottleneck in VQA, experimenting with both the quantity and quality of visual objects extracted from images. We also study the impact of two methods to incorporate the information about objects necessary for answering a question, in the reasoning module directly, and earlier in the object selection stage. This work highlights the importance of vision in the context of VQA, and the interest of tailoring vision methods used in VQA to the task at hand.
Non-Gaussian Component Analysis via Lattice Basis Reduction
Dec 16, 2021Non-Gaussian Component Analysis (NGCA) is the following distribution learning problem: Given i.i.d. samples from a distribution on $\mathbb{R}^d$ that is non-gaussian in a hidden direction $v$ and an independent standard Gaussian in the orthogonal directions, the goal is to approximate the hidden direction $v$. Prior work \cite{DKS17-sq} provided formal evidence for the existence of an information-computation tradeoff for NGCA under appropriate moment-matching conditions on the univariate non-gaussian distribution $A$. The latter result does not apply when the distribution $A$ is discrete. A natural question is whether information-computation tradeoffs persist in this setting. In this paper, we answer this question in the negative by obtaining a sample and computationally efficient algorithm for NGCA in the regime that $A$ is discrete or nearly discrete, in a well-defined technical sense. The key tool leveraged in our algorithm is the LLL method \cite{LLL82} for lattice basis reduction.
Multi-task head pose estimation in-the-wild
Feb 04, 2022
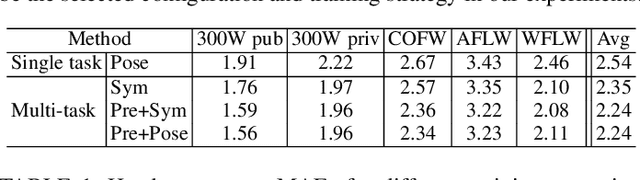

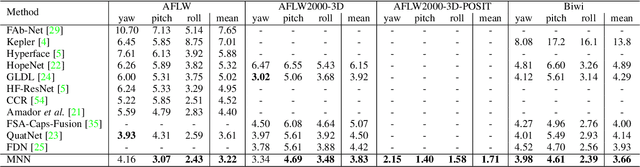
We present a deep learning-based multi-task approach for head pose estimation in images. We contribute with a network architecture and training strategy that harness the strong dependencies among face pose, alignment and visibility, to produce a top performing model for all three tasks. Our architecture is an encoder-decoder CNN with residual blocks and lateral skip connections. We show that the combination of head pose estimation and landmark-based face alignment significantly improve the performance of the former task. Further, the location of the pose task at the bottleneck layer, at the end of the encoder, and that of tasks depending on spatial information, such as visibility and alignment, in the final decoder layer, also contribute to increase the final performance. In the experiments conducted the proposed model outperforms the state-of-the-art in the face pose and visibility tasks. By including a final landmark regression step it also produces face alignment results on par with the state-of-the-art.