 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transfer in Reinforcement Learning via Regret Bounds for Learning Agents
Feb 02, 2022
We present an approach for the quantification of the usefulness of transfer in reinforcement learning via regret bounds for a multi-agent setting. Considering a number of $\aleph$ agents operating in the same Markov decision process, however possibly with different reward functions, we consider the regret each agent suffers with respect to an optimal policy maximizing her average reward. We show that when the agents share their observations the total regret of all agents is smaller by a factor of $\sqrt{\aleph}$ compared to the case when each agent has to rely on the information collected by herself. This result demonstrates how considering the regret in multi-agent settings can provide theoretical bounds on the benefit of sharing observations in transfer learning.
Learning to Detect Slip with Barometric Tactile Sensors and a Temporal Convolutional Neural Network
Feb 19, 2022



The ability to perceive object slip via tactile feedback enables humans to accomplish complex manipulation tasks including maintaining a stable grasp. Despite the utility of tactile information for many applications, tactile sensors have yet to be widely deployed in industrial robotics settings; part of the challenge lies in identifying slip and other events from the tactile data stream. In this paper, we present a learning-based method to detect slip using barometric tactile sensors. These sensors have many desirable properties including high durability and reliability, and are built from inexpensive, off-the-shelf components. We train a temporal convolution neural network to detect slip, achieving high detection accuracies while displaying robustness to the speed and direction of the slip motion. Further, we test our detector on two manipulation tasks involving a variety of common objects and demonstrate successful generalization to real-world scenarios not seen during training. We argue that barometric tactile sensing technology, combined with data-driven learning, is suitable for many manipulation tasks such as slip compensation.
Roadside Lidar Vehicle Detection and Tracking Using Range And Intensity Background Subtraction
Jan 14, 2022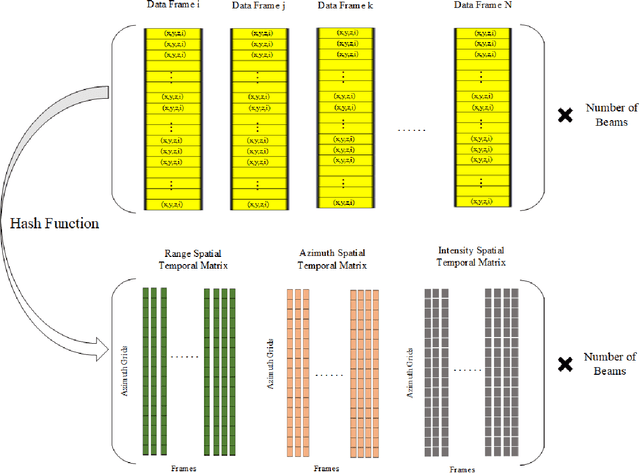

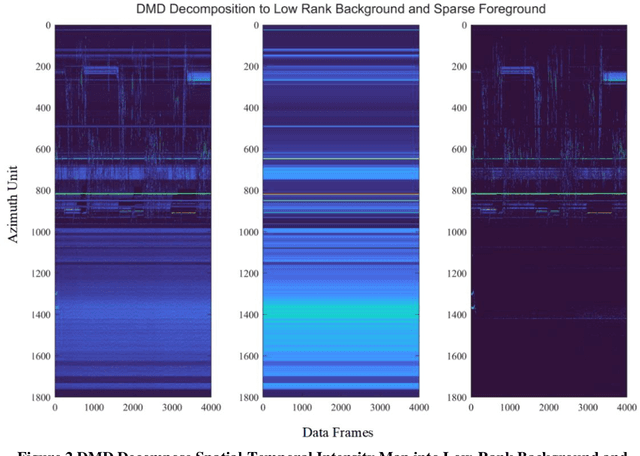
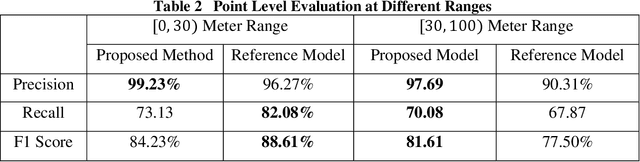
In this paper, we present the solution of roadside LiDAR object detection using a combination of two unsupervised learning algorithms. The 3D point clouds data are firstly converted into spherical coordinates and filled into the azimuth grid matrix using a hash function. After that, the raw LiDAR data were rearranged into spatial-temporal data structures to store the information of range, azimuth, and intensity. Dynamic Mode Decomposition method is applied for decomposing the point cloud data into low-rank backgrounds and sparse foregrounds based on intensity channel pattern recognition. The Triangle Algorithm automatically finds the dividing value to separate the moving targets from static background according to range information. After intensity and range background subtraction, the foreground moving objects will be detected using a density-based detector and encoded into the state-space model for tracking. The output of the proposed model includes vehicle trajectories that can enable many mobility and safety applications. The method was validated against a commercial traffic data collection platform and demonstrated to be an efficient and reliable solution for infrastructure LiDAR object detection. In contrast to the previous methods that process directly on the scattered and discrete point clouds, the proposed method can establish the less sophisticated linear relationship of the 3D measurement data, which captures the spatial-temporal structure that we often desire.
Self-attention based anchor proposal for skeleton-based action recognition
Dec 17, 2021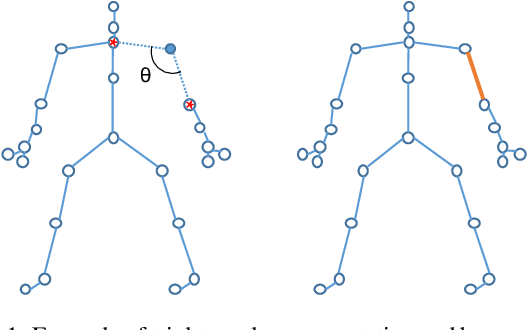
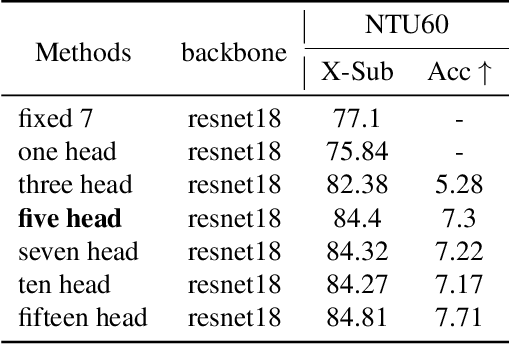
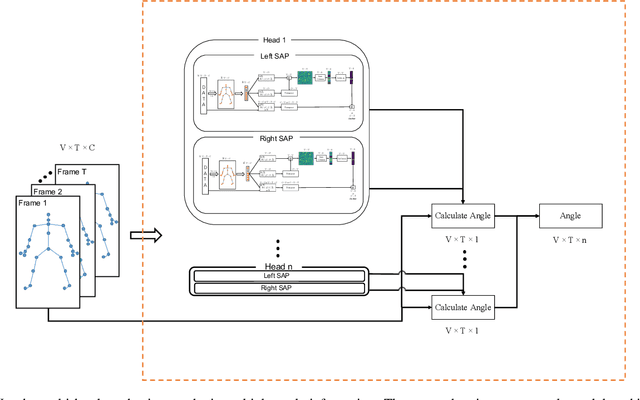
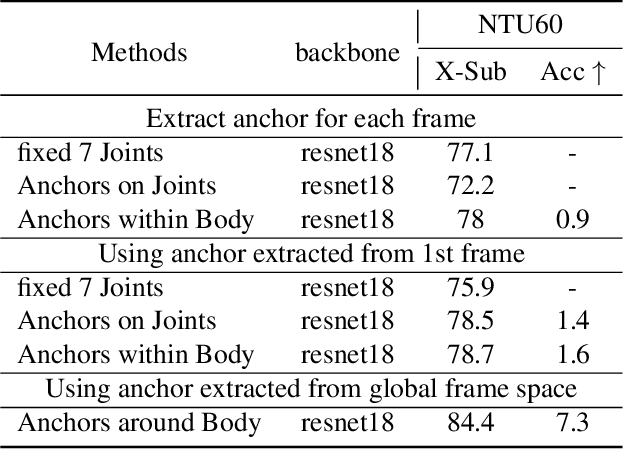
Skeleton sequences are widely used for action recognition task due to its lightweight and compact characteristics. Recent graph convolutional network (GCN) approaches have achieved great success for skeleton-based action recognition since its grateful modeling ability of non-Euclidean data. GCN is able to utilize the short-range joint dependencies while lack to directly model the distant joints relations that are vital to distinguishing various actions. Thus, many GCN approaches try to employ hierarchical mechanism to aggregate wider-range neighborhood information. We propose a novel self-attention based skeleton-anchor proposal (SAP) module to comprehensively model the internal relations of a human body for motion feature learning. The proposed SAP module aims to explore inherent relationship within human body using a triplet representation via encoding high order angle information rather than the fixed pair-wise bone connection used in the existing hierarchical GCN approaches. A Self-attention based anchor selection method is designed in the proposed SAP module for extracting the root point of encoding angular information. By coupling proposed SAP module with popular spatial-temporal graph neural networks, e.g. MSG3D, it achieves new state-of-the-art accuracy on challenging benchmark datasets. Further ablation study have shown the effectiveness of our proposed SAP module, which is able to obviously improve the performance of many popular skeleton-based action recognition methods.
Filter-enhanced MLP is All You Need for Sequential Recommendation
Feb 28, 2022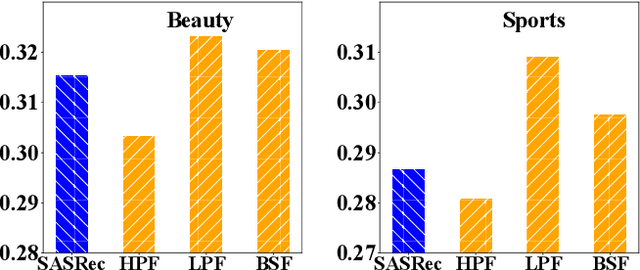
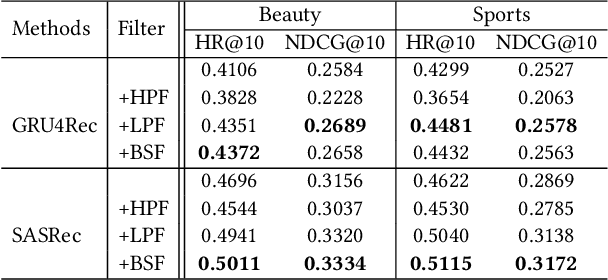
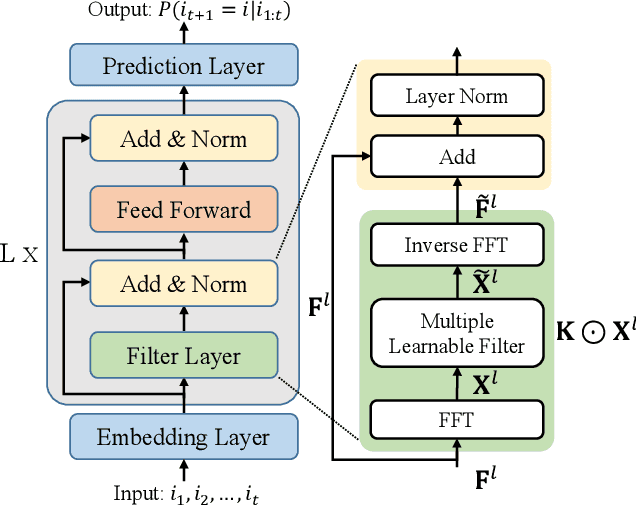
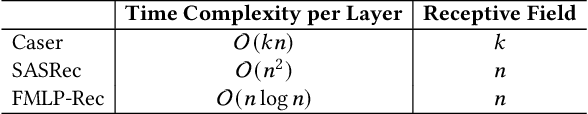
Recently, deep neural networks such as RNN, CNN and Transformer have been applied in the task of sequential recommendation, which aims to capture the dynamic preference characteristics from logged user behavior data for accurate recommendation. However, in online platforms, logged user behavior data is inevitable to contain noise, and deep recommendation models are easy to overfit on these logged data. To tackle this problem, we borrow the idea of filtering algorithms from signal processing that attenuates the noise in the frequency domain. In our empirical experiments, we find that filtering algorithms can substantially improve representative sequential recommendation models, and integrating simple filtering algorithms (eg Band-Stop Filter) with an all-MLP architecture can even outperform competitive Transformer-based models. Motivated by it, we propose \textbf{FMLP-Rec}, an all-MLP model with learnable filters for sequential recommendation task. The all-MLP architecture endows our model with lower time complexity, and the learnable filters can adaptively attenuate the noise information in the frequency domain. Extensive experiments conducted on eight real-world datasets demonstrate the superiority of our proposed method over competitive RNN, CNN, GNN and Transformer-based methods. Our code and data are publicly available at the link: \textcolor{blue}{\url{https://github.com/RUCAIBox/FMLP-Rec}}.
Design and Analysis of SWIPT with Safety Constraints
Nov 20, 2021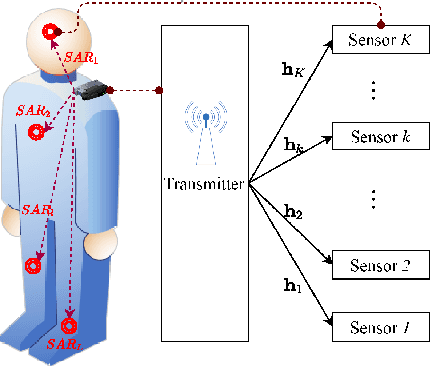
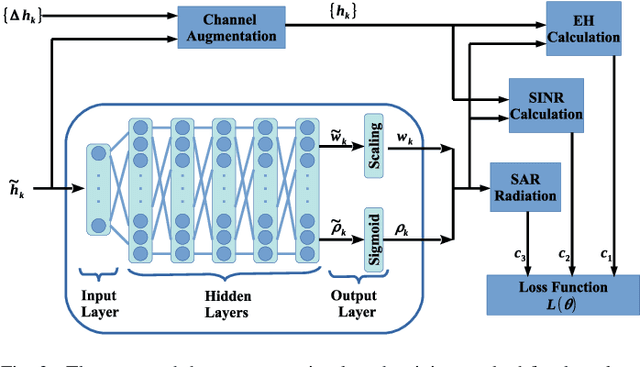
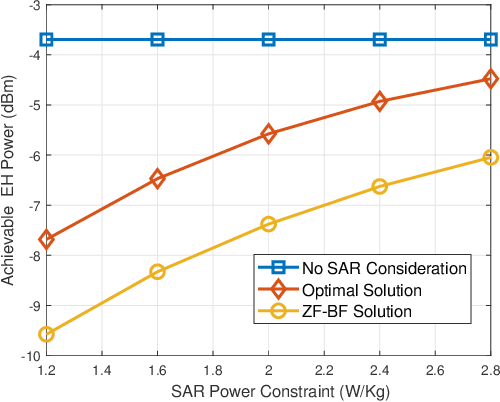
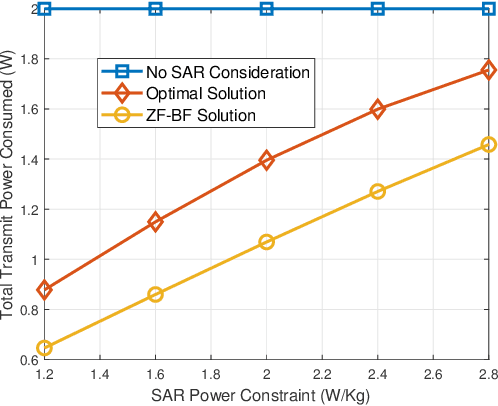
Simultaneous wireless information and power transfer (SWIPT) has long been proposed as a key solution for charging and communicating with low-cost and low-power devices. However, the employment of radio frequency (RF) signals for information/power transfer needs to comply with international health and safety regulations. In this paper, we provide a complete framework for the design and analysis of far-field SWIPT under safety constraints. In particular, we deal with two RF exposure regulations, namely, the specific absorption rate (SAR) and the maximum permissible exposure (MPE). The state-of-the-art regarding SAR and MPE is outlined together with a description as to how these can be modeled in the context of communication networks. We propose a deep learning approach for the design of robust beamforming subject to specific information, energy harvesting and SAR constraints. Furthermore, we present a thorough analytical study for the performance of large-scale SWIPT systems, in terms of information and energy coverage under MPE constraints. This work provides insights with regards to the optimal SWIPT design as well as the potentials from the proper development of SWIPT systems under health and safety restrictions.
Towards Reducing Manual Workload in Technology-Assisted Reviews: Estimating Ranking Performance
Jan 14, 2022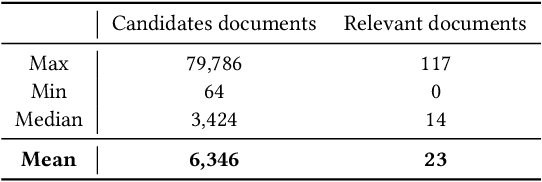

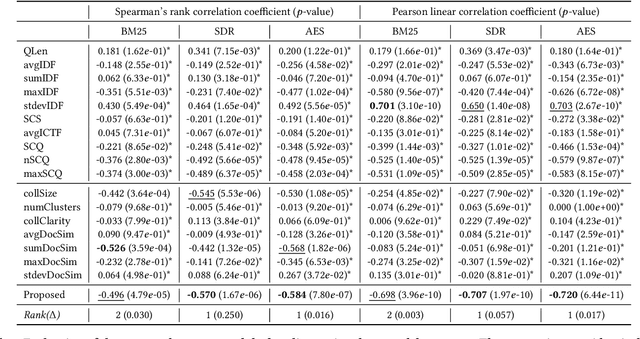
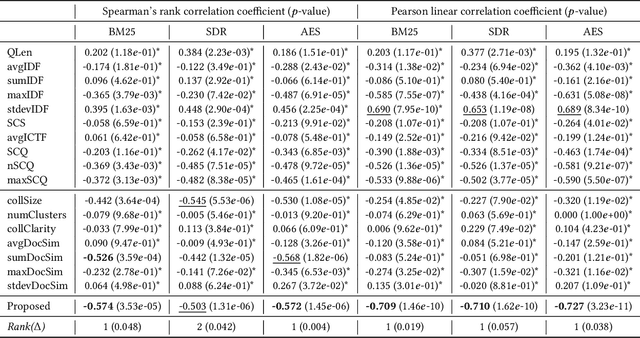
Conducting a systematic review (SR) is comprised of multiple tasks: (i) collect documents (studies) that are likely to be relevant from digital libraries (eg., PubMed), (ii) manually read and label the documents as relevant or irrelevant, (iii) extract information from the relevant studies, and (iv) analyze and synthesize the information and derive a conclusion of SR. When researchers label studies, they can screen ranked documents where relevant documents are higher than irrelevant ones. This practice, known as screening prioritization (ie., document ranking approach), speeds up the process of conducting a SR as the documents labelled as relevant can move to the next tasks earlier. However, the approach is limited in reducing the manual workload because the total number of documents to screen remains the same. Towards reducing the manual workload in the screening process, we investigate the quality of document ranking of SR. This can signal researchers whereabouts in the ranking relevant studies are located and let them decide where to stop the screening. After extensive analysis on SR document rankings from different ranking models, we hypothesize 'topic broadness' as a factor that affects the ranking quality of SR. Finally, we propose a measure that estimates the topic broadness and demonstrate that the proposed measure is a simple yet effective method to predict the qualities of document rankings for SRs.
Label Leakage and Protection from Forward Embedding in Vertical Federated Learning
Mar 04, 2022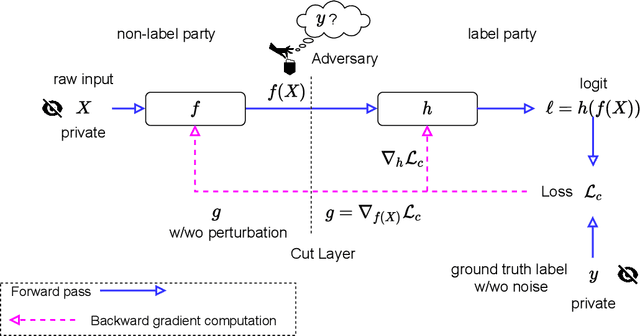
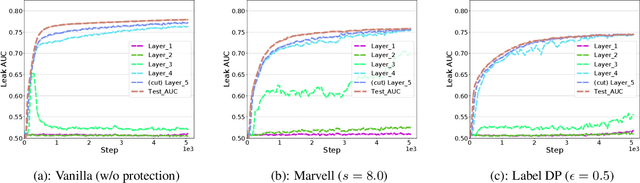
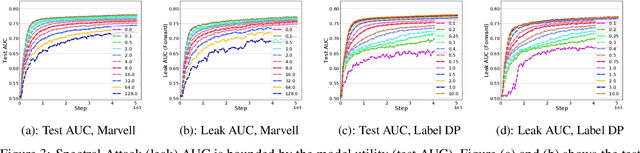
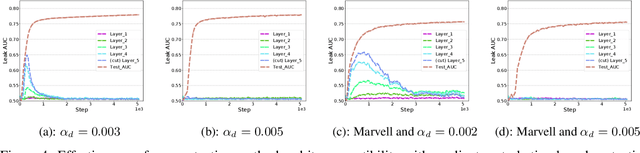
Vertical federated learning (vFL) has gained much attention and been deployed to solve machine learning problems with data privacy concerns in recent years. However, some recent work demonstrated that vFL is vulnerable to privacy leakage even though only the forward intermediate embedding (rather than raw features) and backpropagated gradients (rather than raw labels) are communicated between the involved participants. As the raw labels often contain highly sensitive information, some recent work has been proposed to prevent the label leakage from the backpropagated gradients effectively in vFL. However, these work only identified and defended the threat of label leakage from the backpropagated gradients. None of these work has paid attention to the problem of label leakage from the intermediate embedding. In this paper, we propose a practical label inference method which can steal private labels effectively from the shared intermediate embedding even though some existing protection methods such as label differential privacy and gradients perturbation are applied. The effectiveness of the label attack is inseparable from the correlation between the intermediate embedding and corresponding private labels. To mitigate the issue of label leakage from the forward embedding, we add an additional optimization goal at the label party to limit the label stealing ability of the adversary by minimizing the distance correlation between the intermediate embedding and corresponding private labels. We conducted massive experiments to demonstrate the effectiveness of our proposed protection methods.
TMS: A Temporal Multi-scale Backbone Design for Speaker Embedding
Mar 17, 2022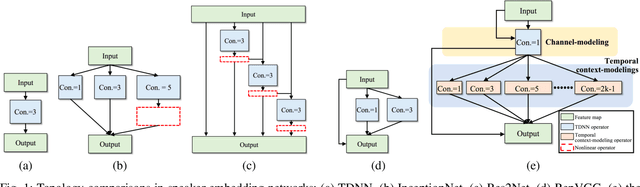
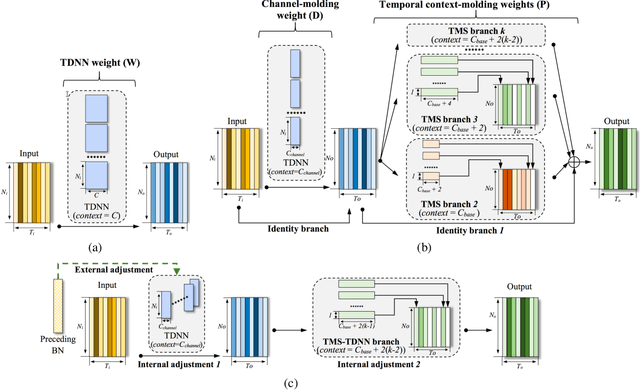
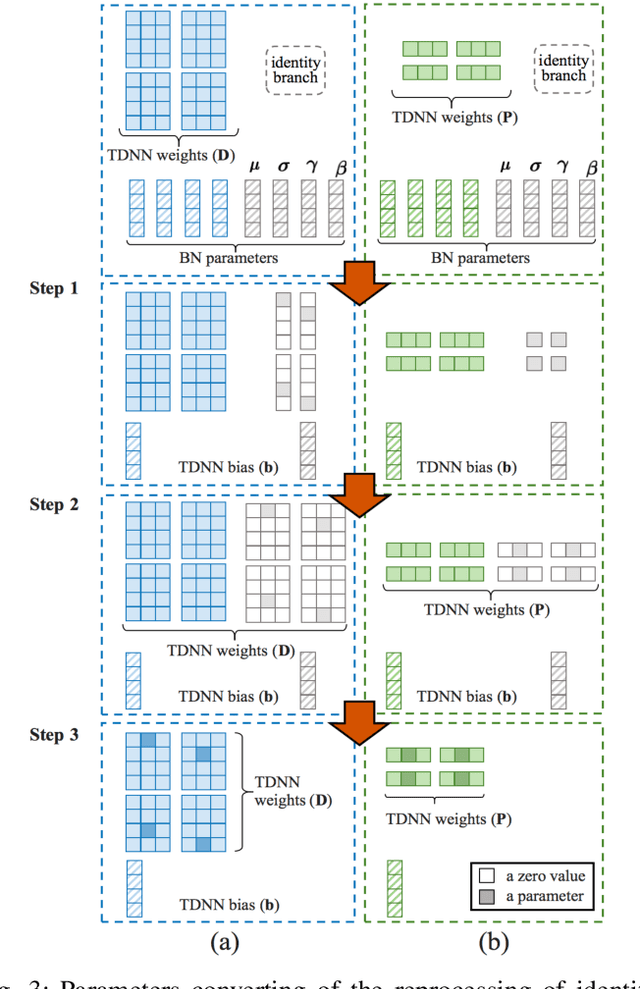
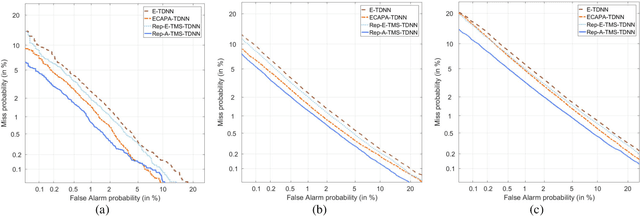
Speaker embedding is an important front-end module to explore discriminative speaker features for many speech applications where speaker information is needed. Current SOTA backbone networks for speaker embedding are designed to aggregate multi-scale features from an utterance with multi-branch network architectures for speaker representation. However, naively adding many branches of multi-scale features with the simple fully convolutional operation could not efficiently improve the performance due to the rapid increase of model parameters and computational complexity. Therefore, in the most current state-of-the-art network architectures, only a few branches corresponding to a limited number of temporal scales could be designed for speaker embeddings. To address this problem, in this paper, we propose an effective temporal multi-scale (TMS) model where multi-scale branches could be efficiently designed in a speaker embedding network almost without increasing computational costs. The new model is based on the conventional TDNN, where the network architecture is smartly separated into two modeling operators: a channel-modeling operator and a temporal multi-branch modeling operator. Adding temporal multi-scale in the temporal multi-branch operator needs only a little bit increase of the number of parameters, and thus save more computational budget for adding more branches with large temporal scales. Moreover, in the inference stage, we further developed a systemic re-parameterization method to convert the TMS-based model into a single-path-based topology in order to increase inference speed. We investigated the performance of the new TMS method for automatic speaker verification (ASV) on in-domain and out-of-domain conditions. Results show that the TMS-based model obtained a significant increase in the performance over the SOTA ASV models, meanwhile, had a faster inference speed.
DKMA-ULD: Domain Knowledge augmented Multi-head Attention based Robust Universal Lesion Detection
Mar 14, 2022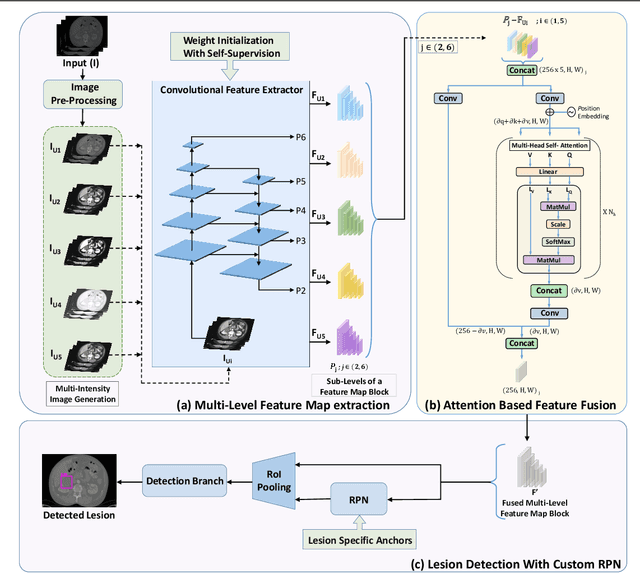
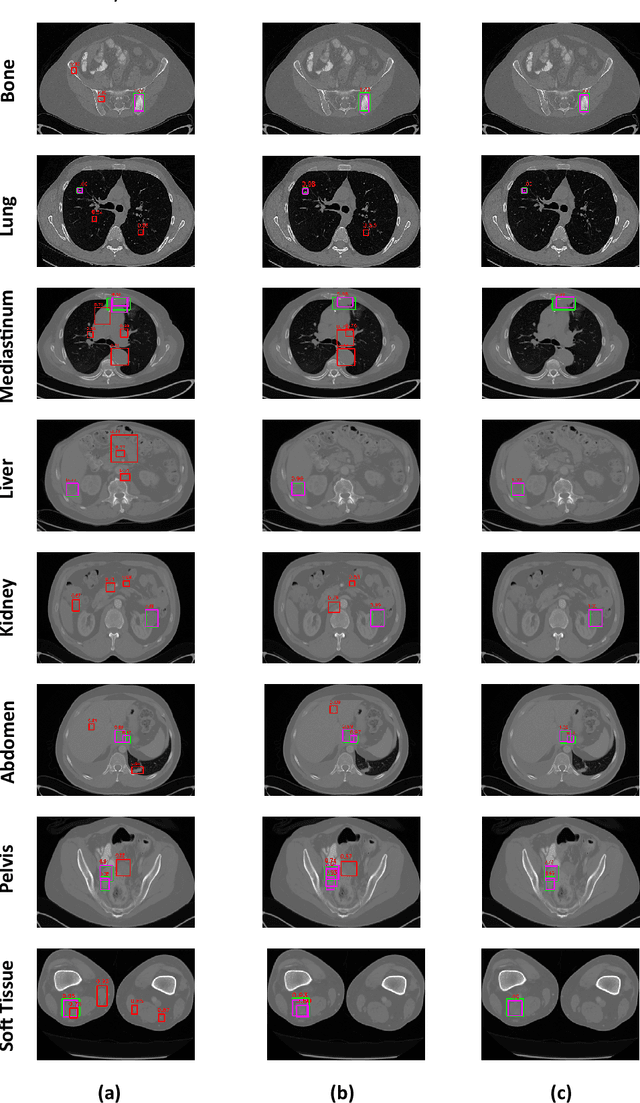
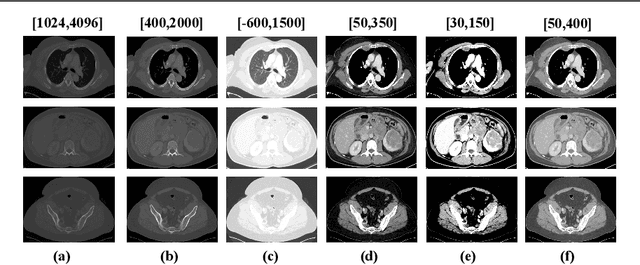
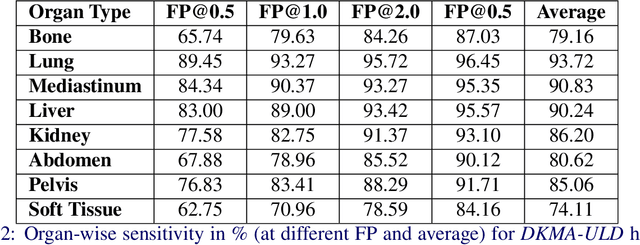
Incorporating data-specific domain knowledge in deep networks explicitly can provide important cues beneficial for lesion detection and can mitigate the need for diverse heterogeneous datasets for learning robust detectors. In this paper, we exploit the domain information present in computed tomography (CT) scans and propose a robust universal lesion detection (ULD) network that can detect lesions across all organs of the body by training on a single dataset, DeepLesion. We analyze CT-slices of varying intensities, generated using heuristically determined Hounsfield Unit(HU) windows that individually highlight different organs and are given as inputs to the deep network. The features obtained from the multiple intensity images are fused using a novel convolution augmented multi-head self-attention module and subsequently, passed to a Region Proposal Network (RPN) for lesion detection. In addition, we observed that traditional anchor boxes used in RPN for natural images are not suitable for lesion sizes often found in medical images. Therefore, we propose to use lesion-specific anchor sizes and ratios in the RPN for improving the detection performance. We use self-supervision to initialize weights of our network on the DeepLesion dataset to further imbibe domain knowledge. Our proposed Domain Knowledge augmented Multi-head Attention based Universal Lesion Detection Network DMKA-ULD produces refined and precise bounding boxes around lesions across different organs. We evaluate the efficacy of our network on the publicly available DeepLesion dataset which comprises of approximately 32K CT scans with annotated lesions across all organs of the body. Results demonstrate that we outperform existing state-of-the-art methods achieving an overall sensitivity of 87.16%.
* Main Paper: 13 Pages, 5 Figures, 2 Tables. Supplementary: 4 Pages, 1 Figure, 3 Tables. Paper accepted at The 32nd British Machine Vision Conference (BMVC'21)