 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Discriminative Dimension Reduction based on Mutual Information
Dec 11, 2019
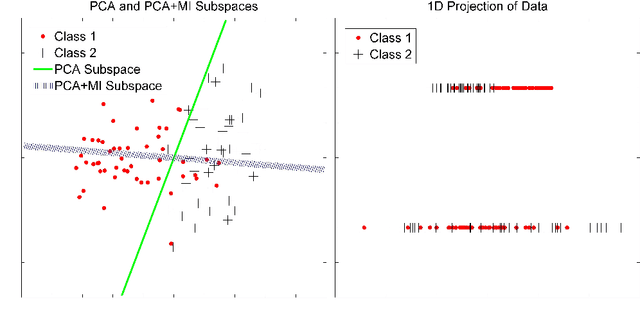
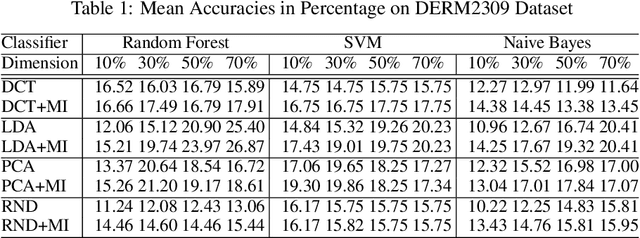
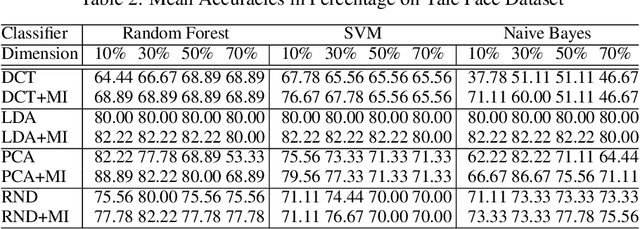
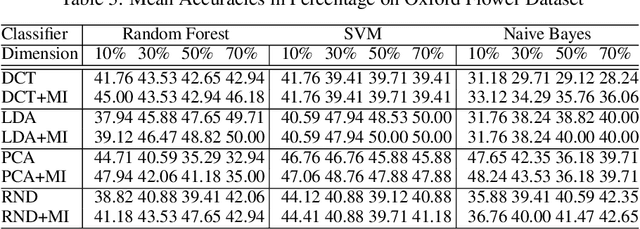
The "curse of dimensionality" is a well-known problem in pattern recognition. A widely used approach to tackling the problem is a group of subspace methods, where the original features are projected onto a new space. The lower dimensional subspace is then used to approximate the original features for classification. However, most subspace methods were not originally developed for classification. We believe that direct adoption of these subspace methods for pattern classification should not be considered best practice. In this paper, we present a new information theory based algorithm for selecting subspaces, which can always result in superior performance over conventional methods. This paper makes the following main contributions: i) it improves a common practice widely used by practitioners in the field of pattern recognition, ii) it develops an information theory based technique for systematically selecting the subspaces that are discriminative and therefore are suitable for pattern recognition/classification purposes, iii) it presents extensive experimental results on a variety of computer vision and pattern recognition tasks to illustrate that the subspaces selected based on maximum mutual information criterion will always enhance performance regardless of the classification techniques used.
Model Selection With Graphical Neighbour Information
Aug 27, 2019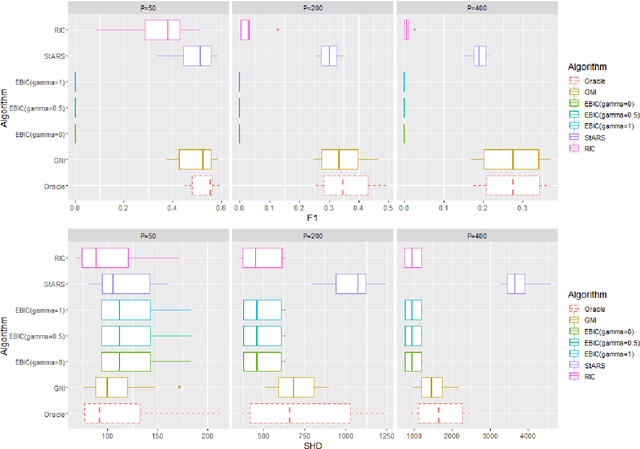
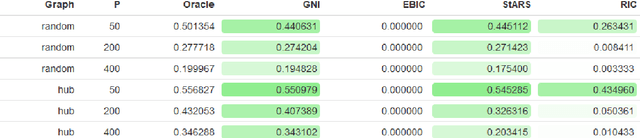
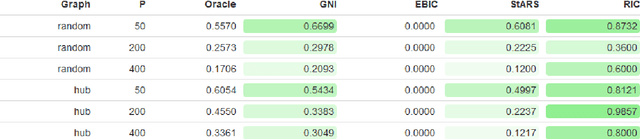
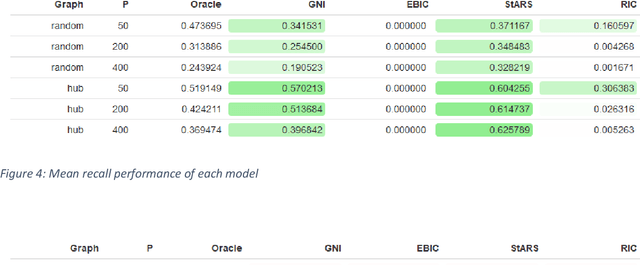
Accurate model selection is a fundamental requirement for statistical analysis. In many real-world applications of graphical modelling, correct model structure identification is the ultimate objective. Standard model validation procedures such as information theoretic scores and cross validation have demonstrated poor performance in the high dimensional setting. Specialised methods such as EBIC, StARS and RIC have been developed for the explicit purpose of high-dimensional Gaussian graphical model selection. We present a novel model score criterion, Graphical Neighbour Information. This method demonstrates oracle performance in high-dimensional model selection, outperforming the current state-of-the-art in our simulations. The Graphical Neighbour Information criterion has the additional advantage of efficient, closed-form computability, sparing the costly inference of multiple models on data subsamples. We provide a theoretical analysis of the method and benchmark simulations versus the current state of the art.
Performance Analysis of Multiple-Antenna Ambient Backscatter Systems at Finite Blocklengths
Jan 25, 2022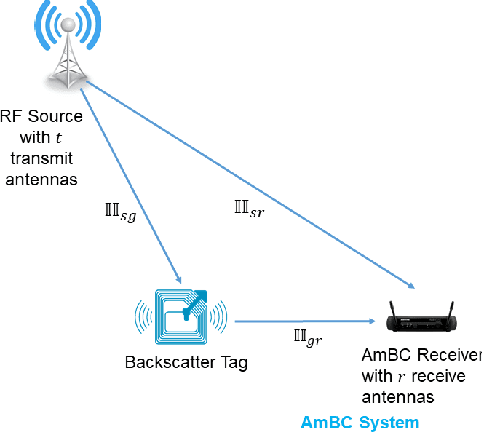
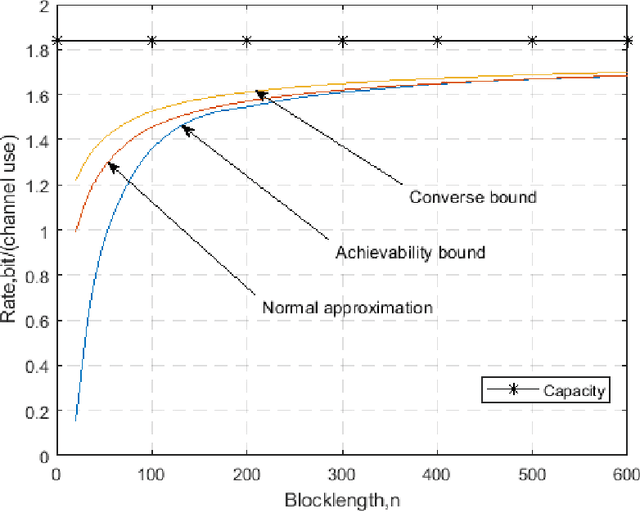
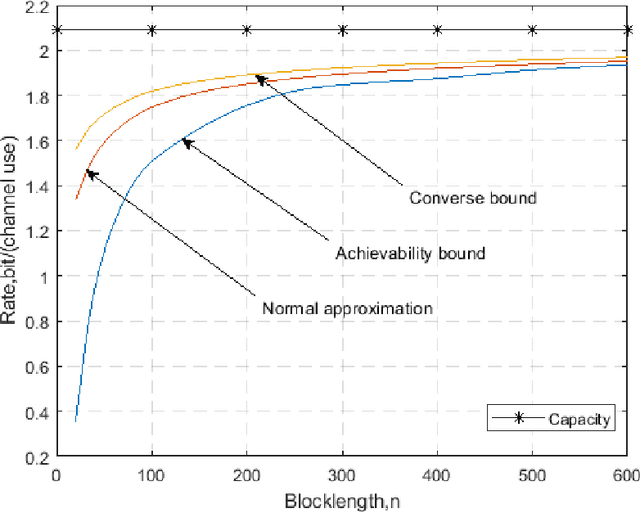
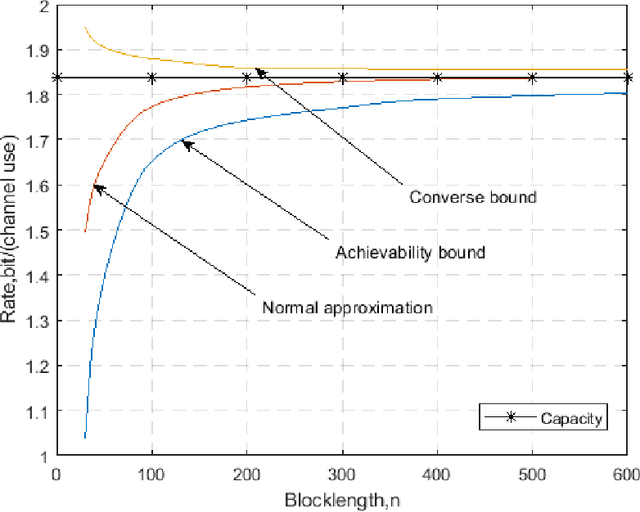
This paper analyzes the maximal achievable rate for a given blocklength and error probability over a multiple-antenna ambient backscatter channel with perfect channel state information at the receiver. The result consists of a finite blocklength channel coding achievability bound and a converse bound based on the Neyman-Pearson test and the normal approximation based on the Berry- Esseen Theorem. Numerical evaluation of these bounds shows fast convergence to the channel capacity as the blocklength increases and also proves that the channel dispersion is an accurate measure of the backoff from capacity due to finite blocklength.
Lightweight Deep Learning Architecture for MPI Correction and Transient Reconstruction
Nov 29, 2021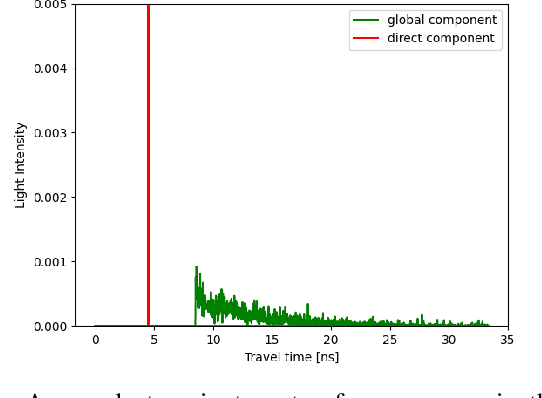
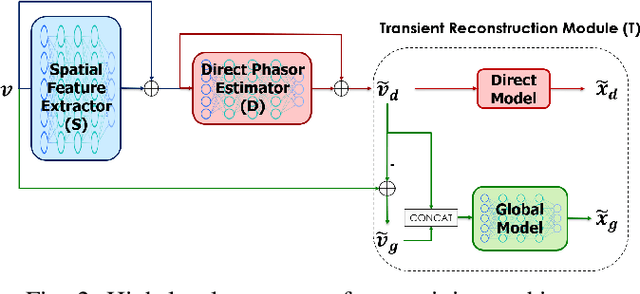
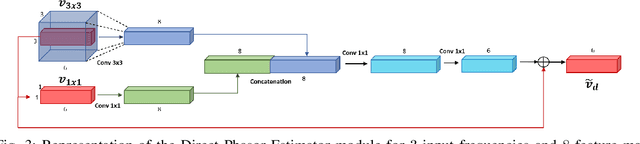
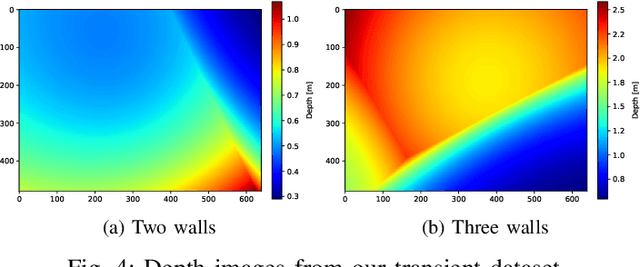
Indirect Time-of-Flight cameras (iToF) are low-cost devices that provide depth images at an interactive frame rate. However, they are affected by different error sources, with the spotlight taken by Multi-Path Interference (MPI), a key challenge for this technology. Common data-driven approaches tend to focus on a direct estimation of the output depth values, ignoring the underlying transient propagation of the light in the scene. In this work instead, we propose a very compact architecture, leveraging on the direct-global subdivision of transient information for the removal of MPI and for the reconstruction of the transient information itself. The proposed model reaches state-of-the-art MPI correction performances both on synthetic and real data and proves to be very competitive also at extreme levels of noise; at the same time, it also makes a step towards reconstructing transient information from multi-frequency iToF data.
SOInter: A Novel Deep Energy Based Interpretation Method for Explaining Structured Output Models
Feb 20, 2022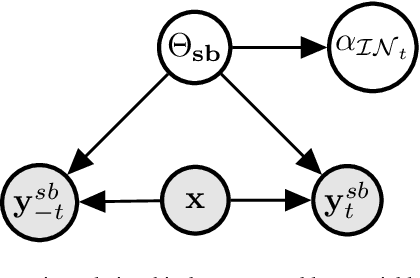
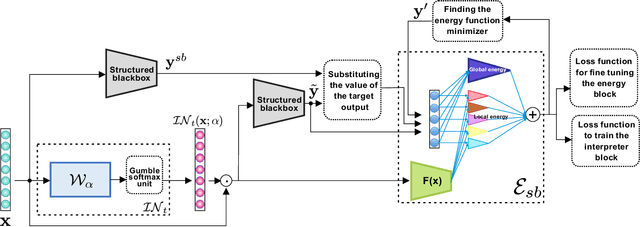
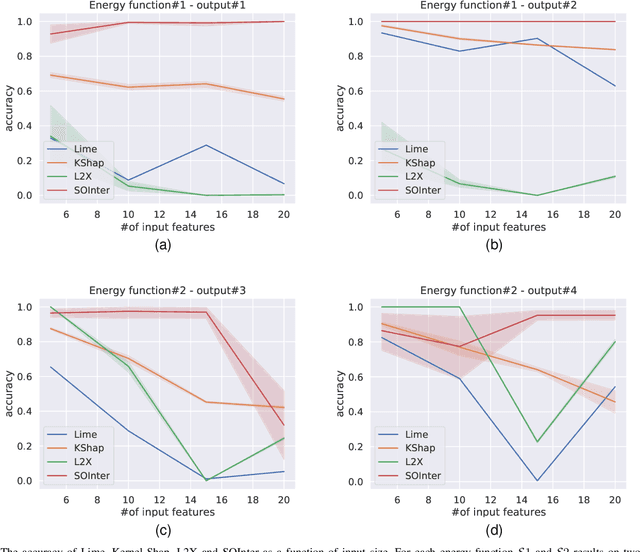
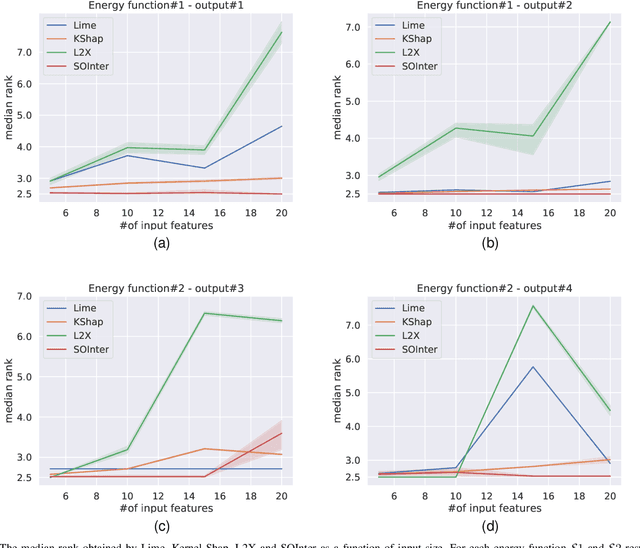
We propose a novel interpretation technique to explain the behavior of structured output models, which learn mappings between an input vector to a set of output variables simultaneously. Because of the complex relationship between the computational path of output variables in structured models, a feature can affect the value of output through other ones. We focus on one of the outputs as the target and try to find the most important features utilized by the structured model to decide on the target in each locality of the input space. In this paper, we assume an arbitrary structured output model is available as a black box and argue how considering the correlations between output variables can improve the explanation performance. The goal is to train a function as an interpreter for the target output variable over the input space. We introduce an energy-based training process for the interpreter function, which effectively considers the structural information incorporated into the model to be explained. The effectiveness of the proposed method is confirmed using a variety of simulated and real data sets.
An AGM Approach to Revising Preferences
Dec 28, 2021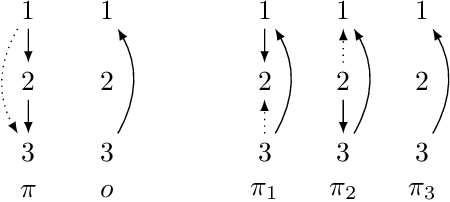
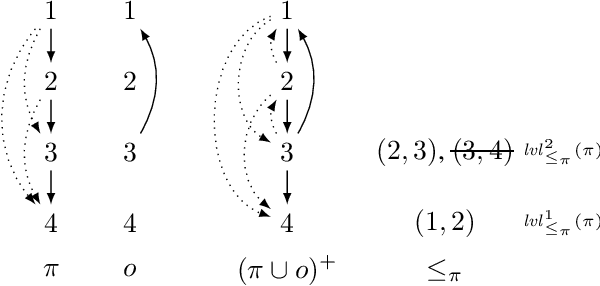
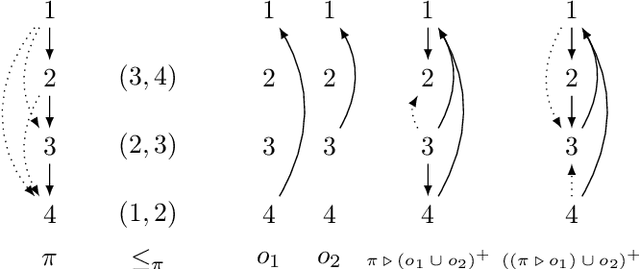

We look at preference change arising out of an interaction between two elements: the first is an initial preference ranking encoding a pre-existing attitude; the second element is new preference information signaling input from an authoritative source, which may come into conflict with the initial preference. The aim is to adjust the initial preference and bring it in line with the new preference, without having to give up more information than necessary. We model this process using the formal machinery of belief change, along the lines of the well-known AGM approach. We propose a set of fundamental rationality postulates, and derive the main results of the paper: a set of representation theorems showing that preference change according to these postulates can be rationalized as a choice function guided by a ranking on the comparisons in the initial preference order. We conclude by presenting operators satisfying our proposed postulates. Our approach thus allows us to situate preference revision within the larger family of belief change operators.
Automatic Extraction of Medication Names in Tweets as Named Entity Recognition
Nov 30, 2021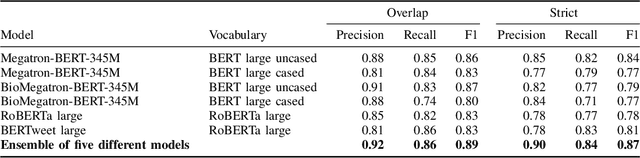

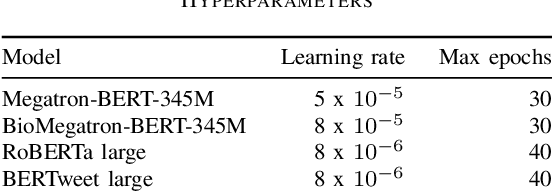
Social media posts contain potentially valuable information about medical conditions and health-related behavior. Biocreative VII Task 3 focuses on mining this information by recognizing mentions of medications and dietary supplements in tweets. We approach this task by fine tuning multiple BERT-style language models to perform token-level classification, and combining them into ensembles to generate final predictions. Our best system consists of five Megatron-BERT-345M models and achieves a strict F1 score of 0.764 on unseen test data.
Information Extraction of Clinical Trial Eligibility CriteriaYitong
Jun 12, 2020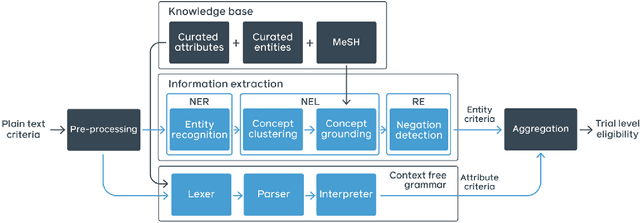
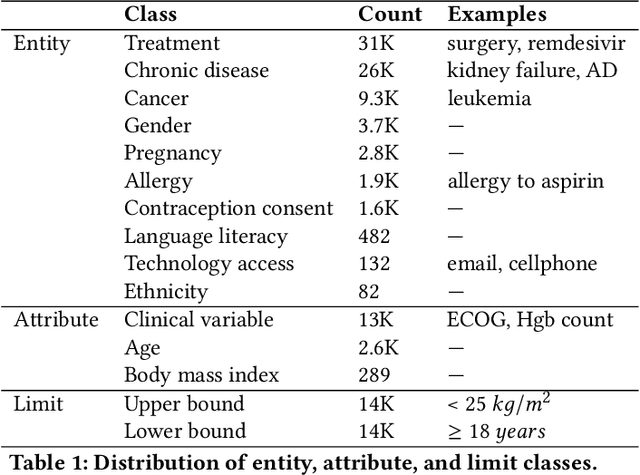
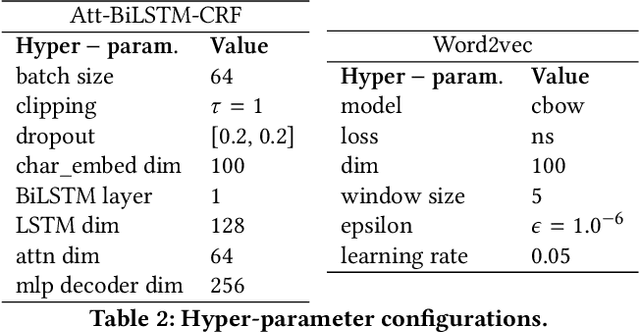
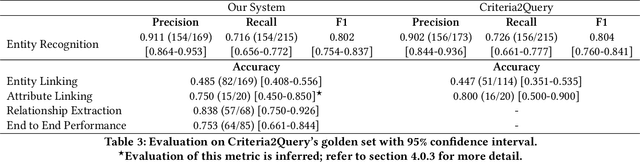
Clinical trials predicate subject eligibility on a diversity of criteria ranging from patient demographics to food allergies. Trials post their requirements as semantically complex, unstructured free-text. Formalizing trial criteria to a computer-interpretable syntax would facilitate eligibility determination. In this paper, we investigate an information extraction (IE) approach for grounding criteria from trials in ClinicalTrials.gov to a shared knowledge base. We frame the problem as a novel knowledge base population task, and implement a solution combining machine learning and context free grammar. To our knowledge, this work is the first criteria extraction system to apply attention-based conditional random field architecture for named entity recognition (NER), and word2vec embedding clustering for named entity linking (NEL). We release the resources and core components of our system on GitHub. Finally, we report our per module and end to end performances; we conclude that our system is competitive with Criteria2Query, which we view as the current state-of-the-art in criteria extraction.
Boosting Entity Mention Detection for Targetted Twitter Streams with Global Contextual Embeddings
Jan 28, 2022
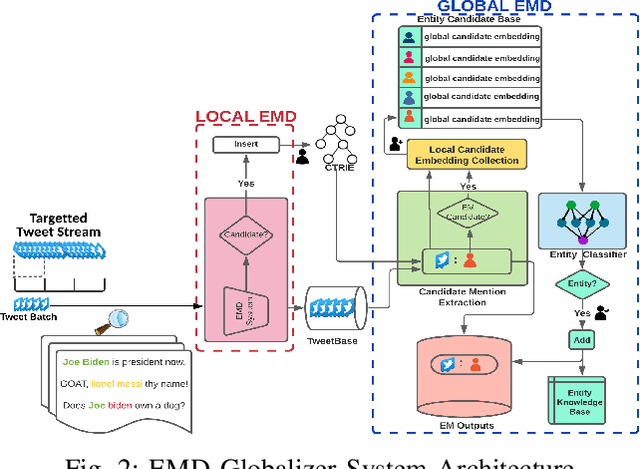
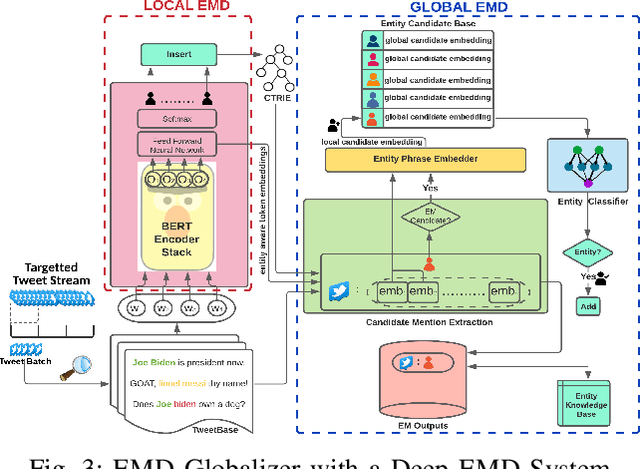
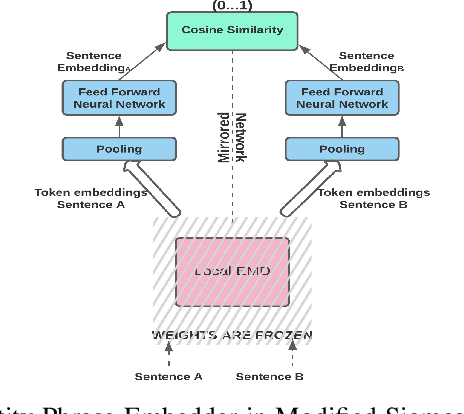
Microblogging sites, like Twitter, have emerged as ubiquitous sources of information. Two important tasks related to the automatic extraction and analysis of information in Microblogs are Entity Mention Detection (EMD) and Entity Detection (ED). The state-of-the-art EMD systems aim to model the non-literary nature of microblog text by training upon offline static datasets. They extract a combination of surface-level features -- orthographic, lexical, and semantic -- from individual messages for noisy text modeling and entity extraction. But given the constantly evolving nature of microblog streams, detecting all entity mentions from such varying yet limited context of short messages remains a difficult problem. To this end, we propose a framework named EMD Globalizer, better suited for the execution of EMD learners on microblog streams. It deviates from the processing of isolated microblog messages by existing EMD systems, where learned knowledge from the immediate context of a message is used to suggest entities. After an initial extraction of entity candidates by an EMD system, the proposed framework leverages occurrence mining to find additional candidate mentions that are missed during this first detection. Aggregating the local contextual representations of these mentions, a global embedding is drawn from the collective context of an entity candidate within a stream. The global embeddings are then utilized to separate entities within the candidates from false positives. All mentions of said entities from the stream are produced in the framework's final outputs. Our experiments show that EMD Globalizer can enhance the effectiveness of all existing EMD systems that we tested (on average by 25.61%) with a small additional computational overhead.
Bringing Rolling Shutter Images Alive with Dual Reversed Distortion
Mar 12, 2022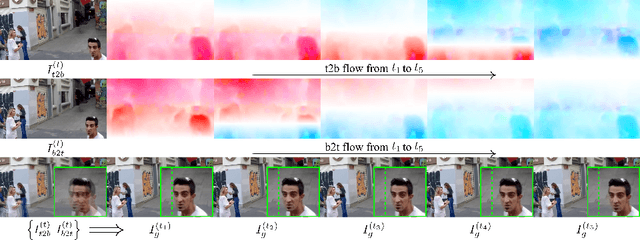

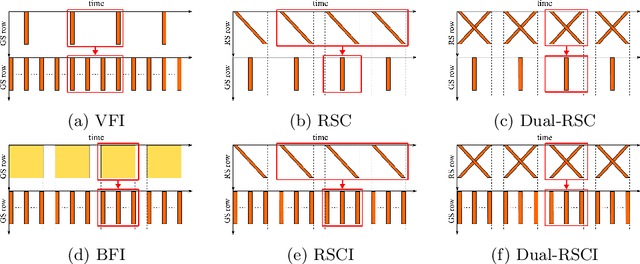
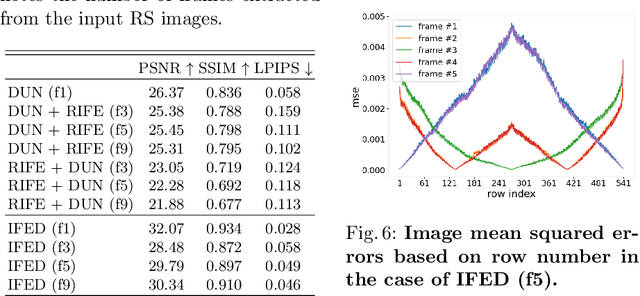
Rolling shutter (RS) distortion can be interpreted as the result of picking a row of pixels from instant global shutter (GS) frames over time during the exposure of the RS camera. This means that the information of each instant GS frame is partially, yet sequentially, embedded into the row-dependent distortion. Inspired by this fact, we address the challenging task of reversing this process, i.e., extracting undistorted GS frames from images suffering from RS distortion. However, since RS distortion is coupled with other factors such as readout settings and the relative velocity of scene elements to the camera, models that only exploit the geometric correlation between temporally adjacent images suffer from poor generality in processing data with different readout settings and dynamic scenes with both camera motion and object motion. In this paper, instead of two consecutive frames, we propose to exploit a pair of images captured by dual RS cameras with reversed RS directions for this highly challenging task. Grounded on the symmetric and complementary nature of dual reversed distortion, we develop a novel end-to-end model, IFED, to generate dual optical flow sequence through iterative learning of the velocity field during the RS time. Extensive experimental results demonstrate that IFED is superior to naive cascade schemes, as well as the state-of-the-art which utilizes adjacent RS images. Most importantly, although it is trained on a synthetic dataset, IFED is shown to be effective at retrieving GS frame sequences from real-world RS distorted images of dynamic scenes.