 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Single Trajectory Nonparametric Learning of Nonlinear Dynamics
Feb 16, 2022
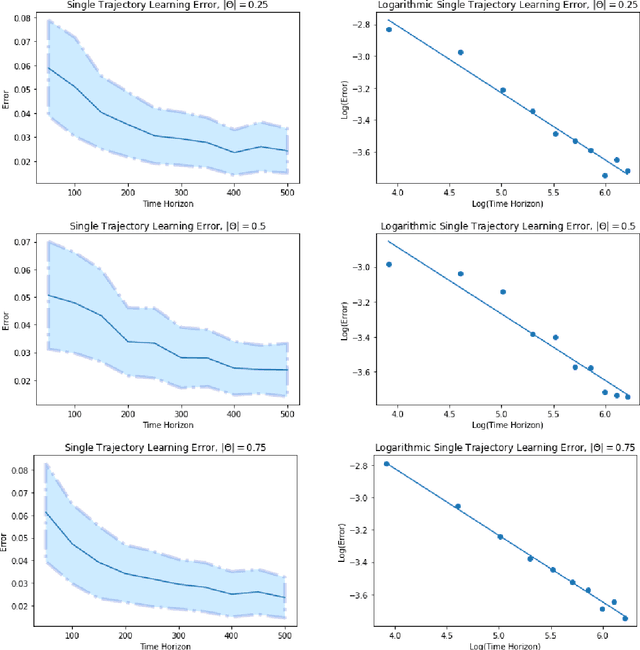
Given a single trajectory of a dynamical system, we analyze the performance of the nonparametric least squares estimator (LSE). More precisely, we give nonasymptotic expected $l^2$-distance bounds between the LSE and the true regression function, where expectation is evaluated on a fresh, counterfactual, trajectory. We leverage recently developed information-theoretic methods to establish the optimality of the LSE for nonparametric hypotheses classes in terms of supremum norm metric entropy and a subgaussian parameter. Next, we relate this subgaussian parameter to the stability of the underlying process using notions from dynamical systems theory. When combined, these developments lead to rate-optimal error bounds that scale as $T^{-1/(2+q)}$ for suitably stable processes and hypothesis classes with metric entropy growth of order $\delta^{-q}$. Here, $T$ is the length of the observed trajectory, $\delta \in \mathbb{R}_+$ is the packing granularity and $q\in (0,2)$ is a complexity term. Finally, we specialize our results to a number of scenarios of practical interest, such as Lipschitz dynamics, generalized linear models, and dynamics described by functions in certain classes of Reproducing Kernel Hilbert Spaces (RKHS).
LoSAC: An Efficient Local Stochastic Average Control Method for Federated Optimization
Dec 20, 2021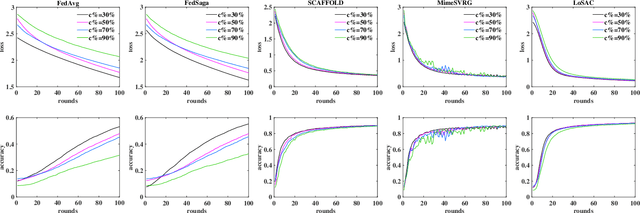
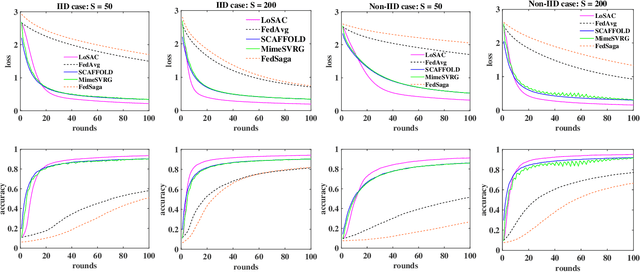
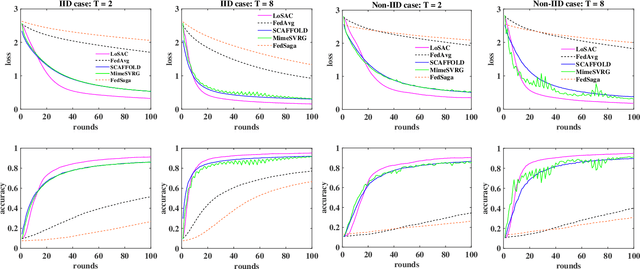
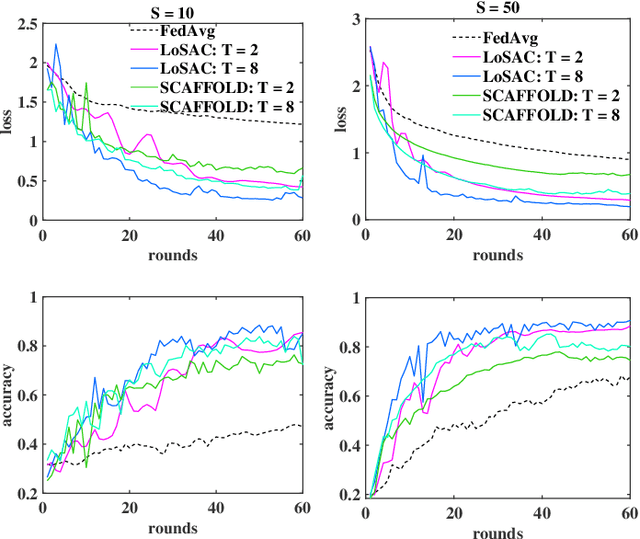
Federated optimization (FedOpt), which targets at collaboratively training a learning model across a large number of distributed clients, is vital for federated learning. The primary concerns in FedOpt can be attributed to the model divergence and communication efficiency, which significantly affect the performance. In this paper, we propose a new method, i.e., LoSAC, to learn from heterogeneous distributed data more efficiently. Its key algorithmic insight is to locally update the estimate for the global full gradient after {each} regular local model update. Thus, LoSAC can keep clients' information refreshed in a more compact way. In particular, we have studied the convergence result for LoSAC. Besides, the bonus of LoSAC is the ability to defend the information leakage from the recent technique Deep Leakage Gradients (DLG). Finally, experiments have verified the superiority of LoSAC comparing with state-of-the-art FedOpt algorithms. Specifically, LoSAC significantly improves communication efficiency by more than $100\%$ on average, mitigates the model divergence problem and equips with the defense ability against DLG.
SiamTrans: Zero-Shot Multi-Frame Image Restoration with Pre-Trained Siamese Transformers
Dec 17, 2021
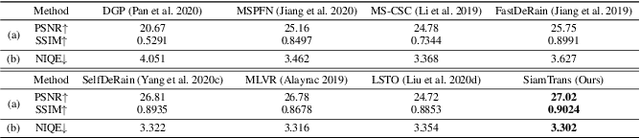
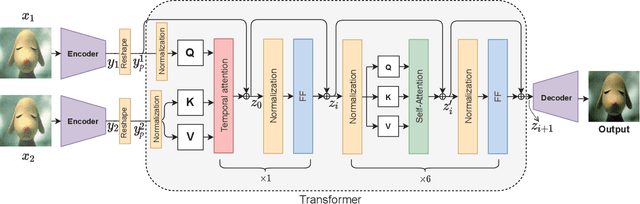
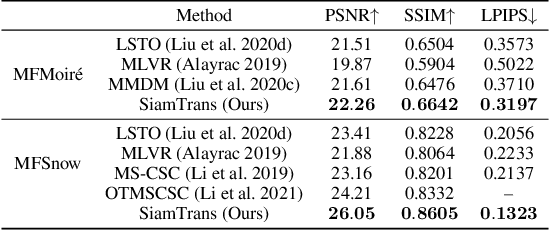
We propose a novel zero-shot multi-frame image restoration method for removing unwanted obstruction elements (such as rains, snow, and moire patterns) that vary in successive frames. It has three stages: transformer pre-training, zero-shot restoration, and hard patch refinement. Using the pre-trained transformers, our model is able to tell the motion difference between the true image information and the obstructing elements. For zero-shot image restoration, we design a novel model, termed SiamTrans, which is constructed by Siamese transformers, encoders, and decoders. Each transformer has a temporal attention layer and several self-attention layers, to capture both temporal and spatial information of multiple frames. Only pre-trained (self-supervised) on the denoising task, SiamTrans is tested on three different low-level vision tasks (deraining, demoireing, and desnowing). Compared with related methods, ours achieves the best performances, even outperforming those with supervised learning.
CPPF: Towards Robust Category-Level 9D Pose Estimation in the Wild
Mar 07, 2022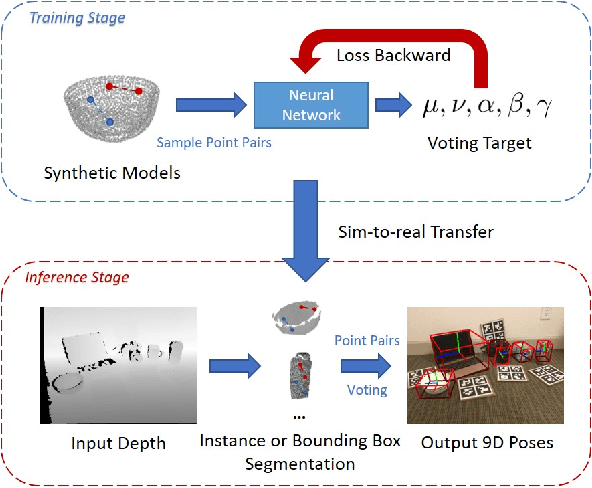
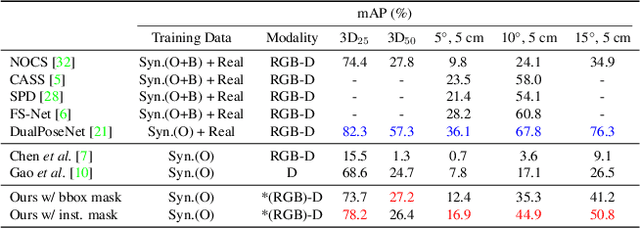
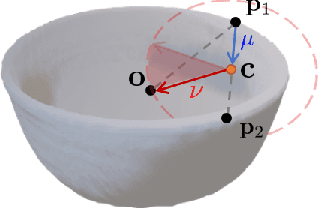
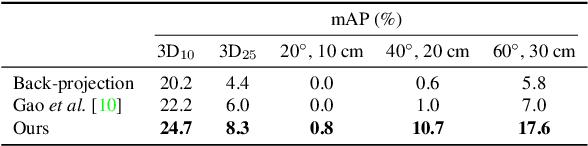
In this paper, we tackle the problem of category-level 9D pose estimation in the wild, given a single RGB-D frame. Using supervised data of real-world 9D poses is tedious and erroneous, and also fails to generalize to unseen scenarios. Besides, category-level pose estimation requires a method to be able to generalize to unseen objects at test time, which is also challenging. Drawing inspirations from traditional point pair features (PPFs), in this paper, we design a novel Category-level PPF (CPPF) voting method to achieve accurate, robust and generalizable 9D pose estimation in the wild. To obtain robust pose estimation, we sample numerous point pairs on an object, and for each pair our model predicts necessary SE(3)-invariant voting statistics on object centers, orientations and scales. A novel coarse-to-fine voting algorithm is proposed to eliminate noisy point pair samples and generate final predictions from the population. To get rid of false positives in the orientation voting process, an auxiliary binary disambiguating classification task is introduced for each sampled point pair. In order to detect objects in the wild, we carefully design our sim-to-real pipeline by training on synthetic point clouds only, unless objects have ambiguous poses in geometry. Under this circumstance, color information is leveraged to disambiguate these poses. Results on standard benchmarks show that our method is on par with current state of the arts with real-world training data. Extensive experiments further show that our method is robust to noise and gives promising results under extremely challenging scenarios. Our code is available on https://github.com/qq456cvb/CPPF.
Temporally Resolution Decrement: Utilizing the Shape Consistency for Higher Computational Efficiency
Dec 02, 2021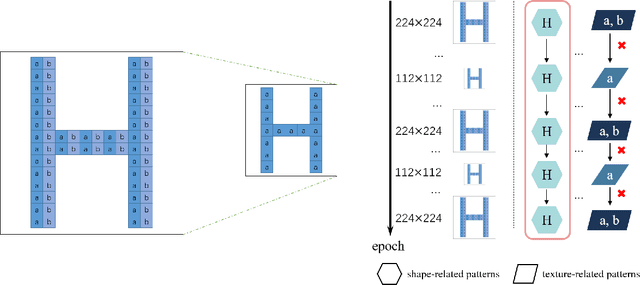
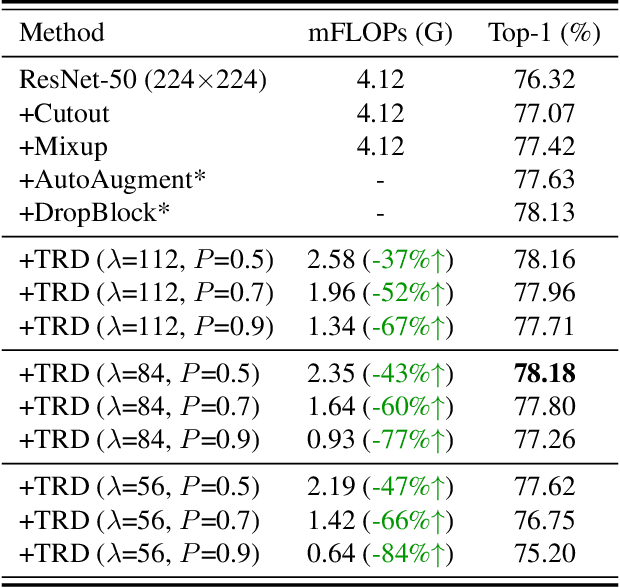
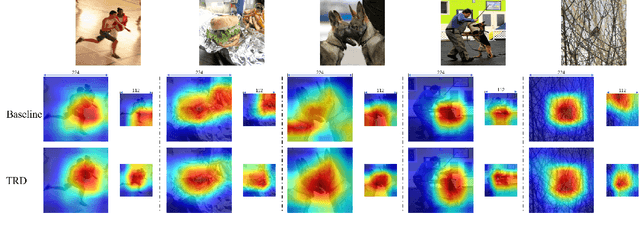
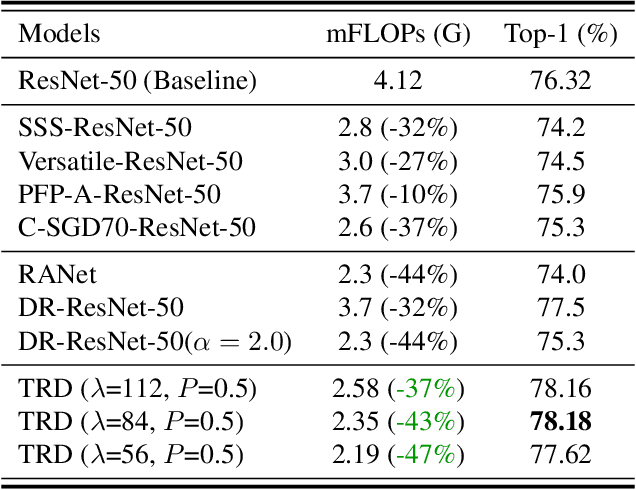
Image resolution that has close relations with accuracy and computational cost plays a pivotal role in network training. In this paper, we observe that the reduced image retains relatively complete shape semantics but loses extensive texture information. Inspired by the consistency of the shape semantics as well as the fragility of the texture information, we propose a novel training strategy named Temporally Resolution Decrement. Wherein, we randomly reduce the training images to a smaller resolution in the time domain. During the alternate training with the reduced images and the original images, the unstable texture information in the images results in a weaker correlation between the texture-related patterns and the correct label, naturally enforcing the model to rely more on shape properties that are robust and conform to the human decision rule. Surprisingly, our approach greatly improves the computational efficiency of convolutional neural networks. On ImageNet classification, using only 33% calculation quantity (randomly reducing the training image to 112$\times$112 within 90% epochs) can still improve ResNet-50 from 76.32% to 77.71%, and using 63% calculation quantity (randomly reducing the training image to 112 x 112 within 50% epochs) can improve ResNet-50 to 78.18%.
HDC-MiniROCKET: Explicit Time Encoding in Time Series Classification with Hyperdimensional Computing
Feb 16, 2022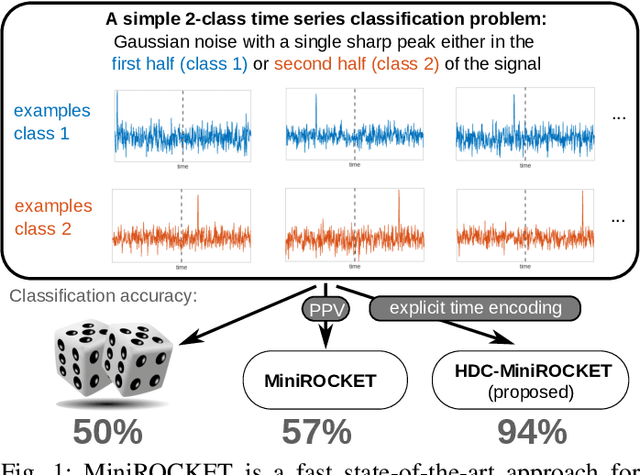
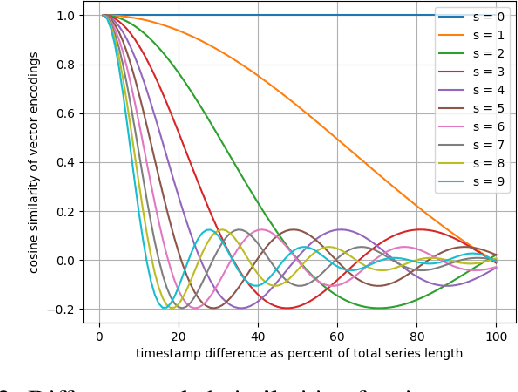
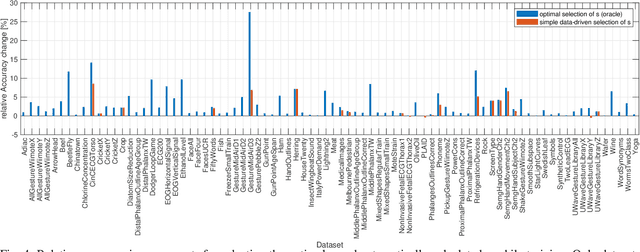
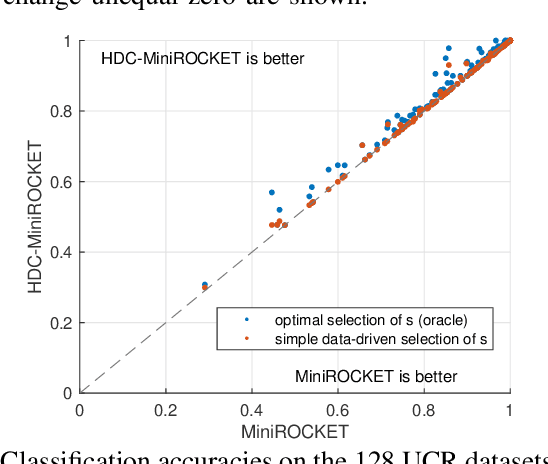
Classification of time series data is an important task for many application domains. One of the best existing methods for this task, in terms of accuracy and computation time, is MiniROCKET. In this work, we extend this approach to provide better global temporal encodings using hyperdimensional computing (HDC) mechanisms. HDC (also known as Vector Symbolic Architectures, VSA) is a general method to explicitly represent and process information in high-dimensional vectors. It has previously been used successfully in combination with deep neural networks and other signal processing algorithms. We argue that the internal high-dimensional representation of MiniROCKET is well suited to be complemented by the algebra of HDC. This leads to a more general formulation, HDC-MiniROCKET, where the original algorithm is only a special case. We will discuss and demonstrate that HDC-MiniROCKET can systematically overcome catastrophic failures of MiniROCKET on simple synthetic datasets. These results are confirmed by experiments on the 128 datasets from the UCR time series classification benchmark. The extension with HDC can achieve considerably better results on datasets with high temporal dependence without increasing the computational effort for inference.
Ask2Mask: Guided Data Selection for Masked Speech Modeling
Feb 24, 2022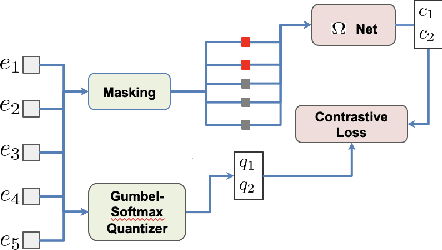
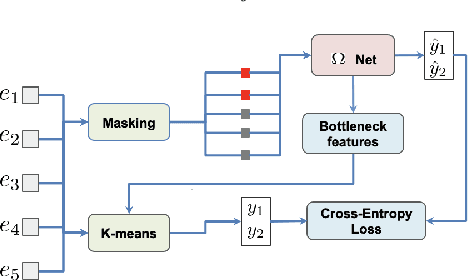
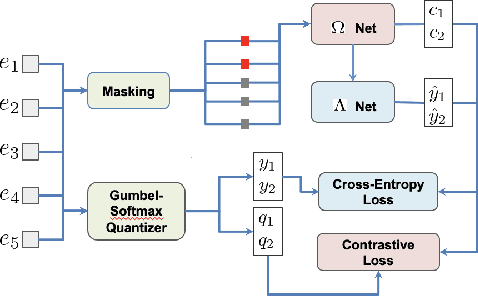
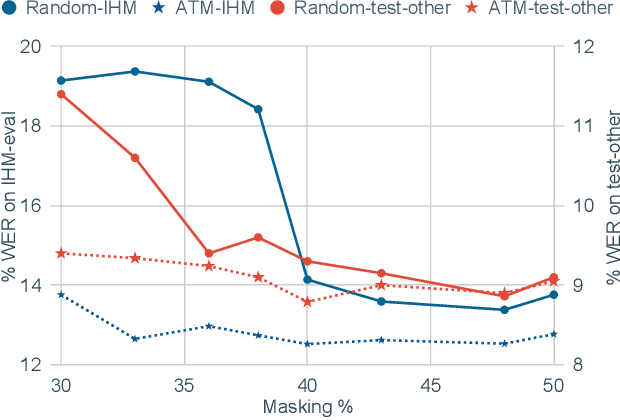
Masked speech modeling (MSM) methods such as wav2vec2 or w2v-BERT learn representations over speech frames which are randomly masked within an utterance. While these methods improve performance of Automatic Speech Recognition (ASR) systems, they have one major limitation. They treat all unsupervised speech samples with equal weight, which hinders learning as not all samples have relevant information to learn meaningful representations. In this work, we address this limitation. We propose ask2mask (ATM), a novel approach to focus on specific samples during MSM pre-training. ATM employs an external ASR model or \textit{scorer} to weight unsupervised input samples in two different ways: 1) A fine-grained data selection is performed by masking over the highly confident input frames as chosen by the scorer. This allows the model to learn meaningful representations. 2) ATM is further extended to focus at utterance-level by weighting the final MSM loss with the utterance-level confidence score. We conduct fine-tuning experiments on two well-benchmarked corpora: LibriSpeech (matching the pre-training data) and Commonvoice, TED-LIUM, AMI and CHiME-6 (not matching the pre-training data). The results substantiate the efficacy of ATM on significantly improving the recognition performance under mismatched conditions (up to 11.6\% relative over published results and upto 4.46\% relative over our internal baseline) while still yielding modest improvements under matched conditions.
Online Deep Learning based on Auto-Encoder
Jan 19, 2022Online learning is an important technical means for sketching massive real-time and high-speed data. Although this direction has attracted intensive attention, most of the literature in this area ignore the following three issues: (1) they think little of the underlying abstract hierarchical latent information existing in examples, even if extracting these abstract hierarchical latent representations is useful to better predict the class labels of examples; (2) the idea of preassigned model on unseen datapoints is not suitable for modeling streaming data with evolving probability distribution. This challenge is referred as model flexibility. And so, with this in minds, the online deep learning model we need to design should have a variable underlying structure; (3) moreover, it is of utmost importance to fusion these abstract hierarchical latent representations to achieve better classification performance, and we should give different weights to different levels of implicit representation information when dealing with the data streaming where the data distribution changes. To address these issues, we propose a two-phase Online Deep Learning based on Auto-Encoder (ODLAE). Based on auto-encoder, considering reconstruction loss, we extract abstract hierarchical latent representations of instances; Based on predictive loss, we devise two fusion strategies: the output-level fusion strategy, which is obtained by fusing the classification results of encoder each hidden layer; and feature-level fusion strategy, which is leveraged self-attention mechanism to fusion every hidden layer output. Finally, in order to improve the robustness of the algorithm, we also try to utilize the denoising auto-encoder to yield hierarchical latent representations. Experimental results on different datasets are presented to verify the validity of our proposed algorithm (ODLAE) outperforms several baselines.
* 30 pages
Cross-Task Knowledge Distillation in Multi-Task Recommendation
Feb 20, 2022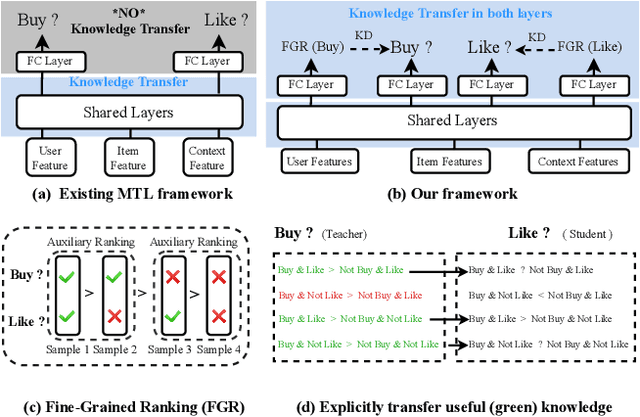

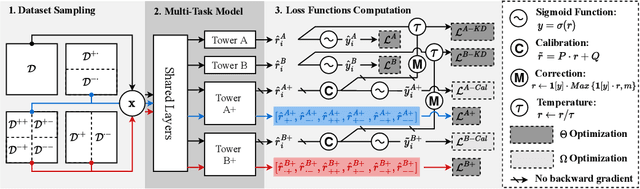
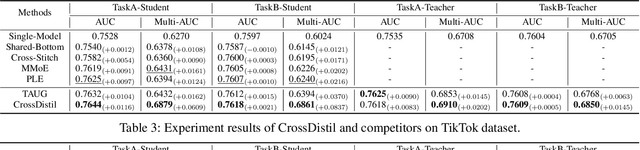
Multi-task learning has been widely used in real-world recommenders to predict different types of user feedback. Most prior works focus on designing network architectures for bottom layers as a means to share the knowledge about input features representations. However, since they adopt task-specific binary labels as supervised signals for training, the knowledge about how to accurately rank items is not fully shared across tasks. In this paper, we aim to enhance knowledge transfer for multi-task personalized recommendat optimization objectives. We propose a Cross-Task Knowledge Distillation (CrossDistil) framework in recommendation, which consists of three procedures. 1) Task Augmentation: We introduce auxiliary tasks with quadruplet loss functions to capture cross-task fine-grained ranking information, which could avoid task conflicts by preserving the cross-task consistent knowledge; 2) Knowledge Distillation: We design a knowledge distillation approach based on augmented tasks for sharing ranking knowledge, where tasks' predictions are aligned with a calibration process; 3) Model Training: Teacher and student models are trained in an end-to-end manner, with a novel error correction mechanism to speed up model training and improve knowledge quality. Comprehensive experiments on a public dataset and our production dataset are carried out to verify the effectiveness of CrossDistil as well as the necessity of its key components.
SciREX: A Challenge Dataset for Document-Level Information Extraction
May 01, 2020
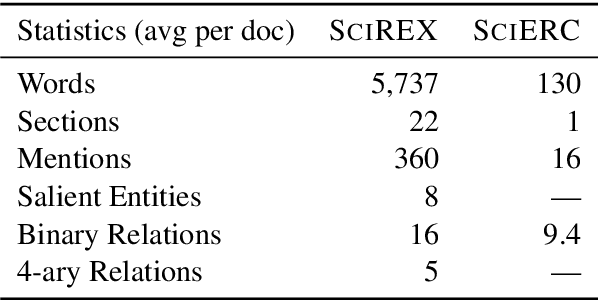
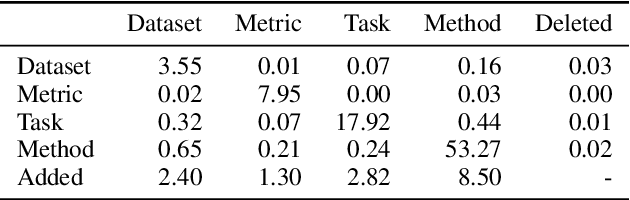
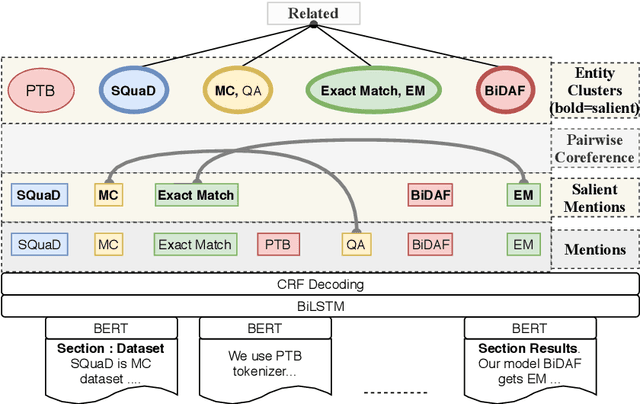
Extracting information from full documents is an important problem in many domains, but most previous work focus on identifying relationships within a sentence or a paragraph. It is challenging to create a large-scale information extraction (IE) dataset at the document level since it requires an understanding of the whole document to annotate entities and their document-level relationships that usually span beyond sentences or even sections. In this paper, we introduce SciREX, a document level IE dataset that encompasses multiple IE tasks, including salient entity identification and document level $N$-ary relation identification from scientific articles. We annotate our dataset by integrating automatic and human annotations, leveraging existing scientific knowledge resources. We develop a neural model as a strong baseline that extends previous state-of-the-art IE models to document-level IE. Analyzing the model performance shows a significant gap between human performance and current baselines, inviting the community to use our dataset as a challenge to develop document-level IE models. Our data and code are publicly available at https://github.com/allenai/SciREX