 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Ultrasonic Backscatter Communication for Implantable Medical Devices
Feb 14, 2022
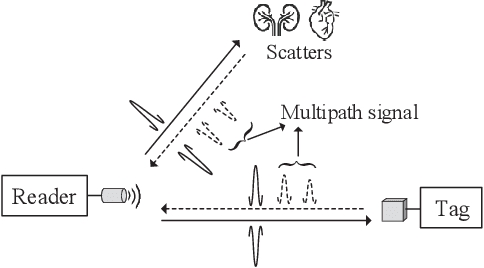
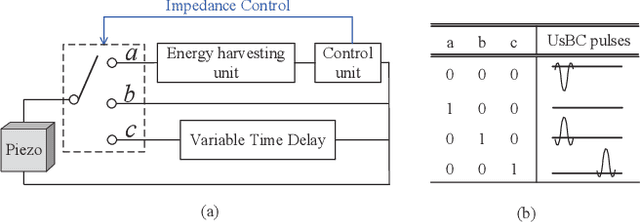
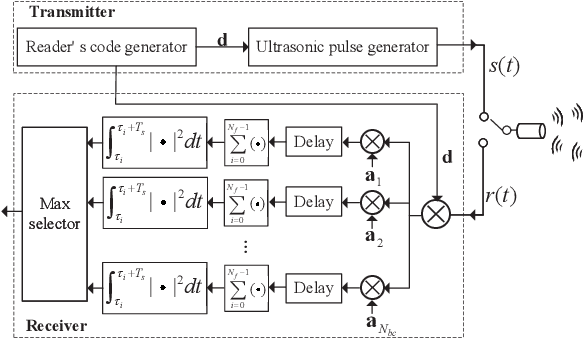
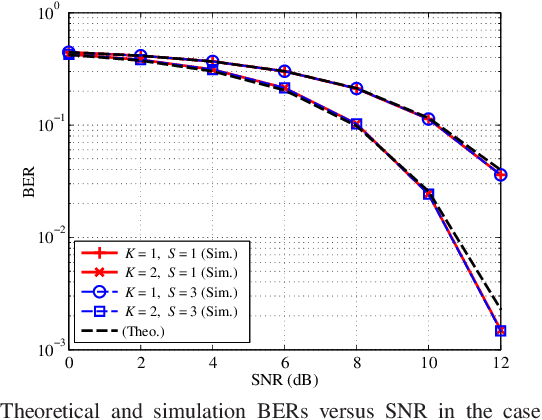
This paper proposes an ultrasonic backscatter communication (UsBC) system for passive implantable medical devices (IMDs) that can operate without batteries, enabling versatile revolutionary applications for future healthcare. The proposed UsBC system consists of a reader and a tag. The reader sends interrogation pulses to the tag. The tag backscatters the pulses based on the piezoelectric effect of a piezo transducer. We present several basic modulation schemes for UsBC by impedance matching of the piezo transducer. To mitigate the interference of other scatters in the human body, the tag transmits information bits by codeword mapping, and the reader performs codeword matching before energy detection in the reader. We further derive the theoretical bit-error rate (BER) expression. Monte Carlo simulations verify the theoretical analysis and show that passive UsBC can achieve low BER and low complexity, which is desirable for size- and energy-constrained IMDs.
Recovering medical images from CT film photos
Mar 10, 2022


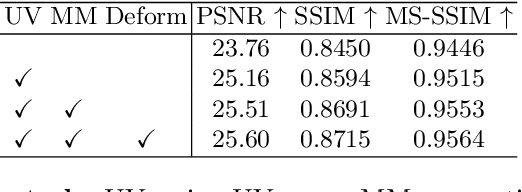
While medical images such as computed tomography (CT) are stored in DICOM format in hospital PACS, it is still quite routine in many countries to print a film as a transferable medium for the purposes of self-storage and secondary consultation. Also, with the ubiquitousness of mobile phone cameras, it is quite common to take pictures of CT films, which unfortunately suffer from geometric deformation and illumination variation. In this work, we study the problem of recovering a CT film, which marks \textbf{the first attempt} in the literature, to the best of our knowledge. We start with building a large-scale head CT film database CTFilm20K, consisting of approximately 20,000 pictures, using the widely used computer graphics software Blender. We also record all accompanying information related to the geometric deformation (such as 3D coordinate, depth, normal, and UV maps) and illumination variation (such as albedo map). Then we propose a deep framework called \textbf{F}ilm \textbf{I}mage \textbf{Re}covery \textbf{Net}work (\textbf{FIReNet}) to tackle geometric deformation and illumination variation using the multiple maps extracted from the CT films to collaboratively guide the recovery process. Finally, we convert the dewarped images to DICOM files with our cascade model for further analysis such as radiomics feature extraction. Extensive experiments demonstrate the superiority of our approach over the previous approaches. We plan to open source the simulated images and deep models for promoting the research on CT film image analysis.
Information Extraction of Clinical Trial Eligibility Criteria
Jun 15, 2020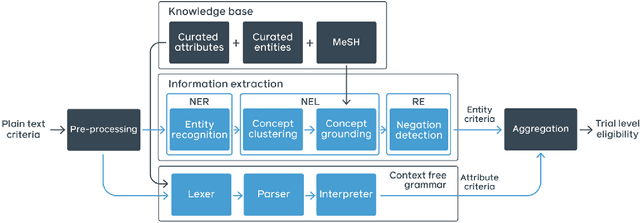
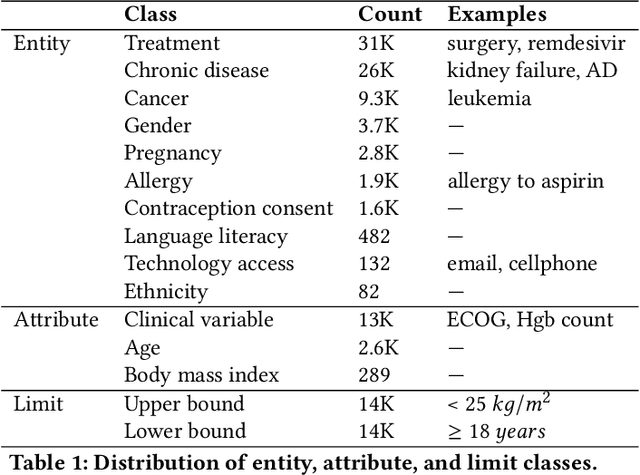
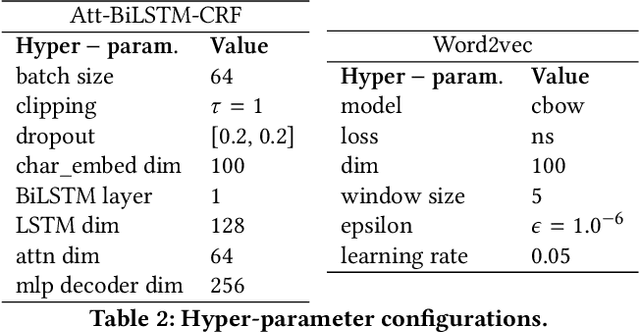
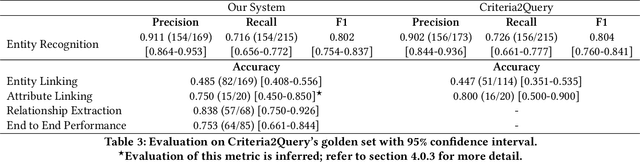
Clinical trials predicate subject eligibility on a diversity of criteria ranging from patient demographics to food allergies. Trials post their requirements as semantically complex, unstructured free-text. Formalizing trial criteria to a computer-interpretable syntax would facilitate eligibility determination. In this paper, we investigate an information extraction (IE) approach for grounding criteria from trials in ClinicalTrials.gov to a shared knowledge base. We frame the problem as a novel knowledge base population task, and implement a solution combining machine learning and context free grammar. To our knowledge, this work is the first criteria extraction system to apply attention-based conditional random field architecture for named entity recognition (NER), and word2vec embedding clustering for named entity linking (NEL). We release the resources and core components of our system on GitHub. Finally, we report our per module and end to end performances; we conclude that our system is competitive with Criteria2Query, which we view as the current state-of-the-art in criteria extraction.
A Machine-Learning-Aided Visual Analysis Workflow for Investigating Air Pollution Data
Feb 11, 2022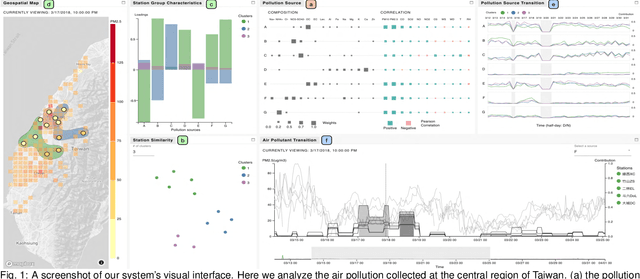
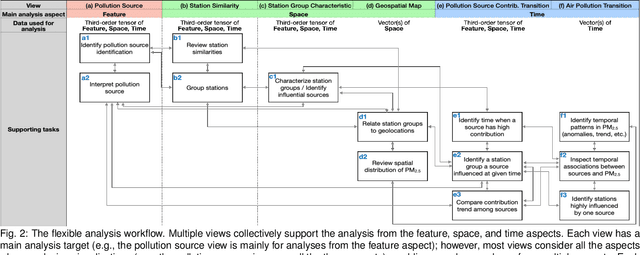
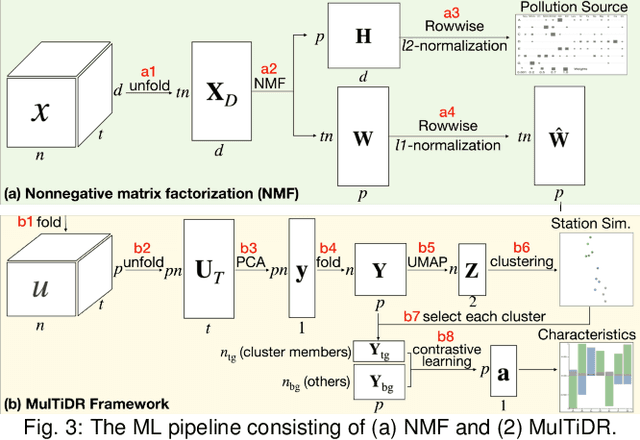
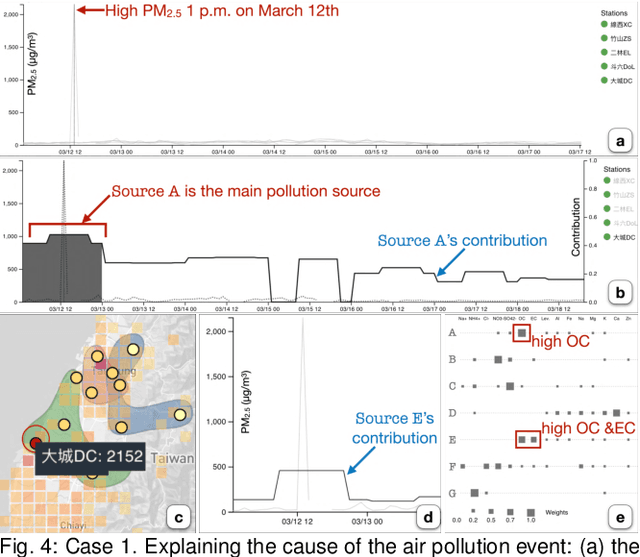
Analyzing air pollution data is challenging as there are various analysis focuses from different aspects: feature (what), space (where), and time (when). As in most geospatial analysis problems, besides high-dimensional features, the temporal and spatial dependencies of air pollution induce the complexity of performing analysis. Machine learning methods, such as dimensionality reduction, can extract and summarize important information of the data to lift the burden of understanding such a complicated environment. In this paper, we present a methodology that utilizes multiple machine learning methods to uniformly explore these aspects. With this methodology, we develop a visual analytic system that supports a flexible analysis workflow, allowing domain experts to freely explore different aspects based on their analysis needs. We demonstrate the capability of our system and analysis workflow supporting a variety of analysis tasks with multiple use cases.
A Survey on Aspect-Based Sentiment Analysis: Tasks, Methods, and Challenges
Mar 02, 2022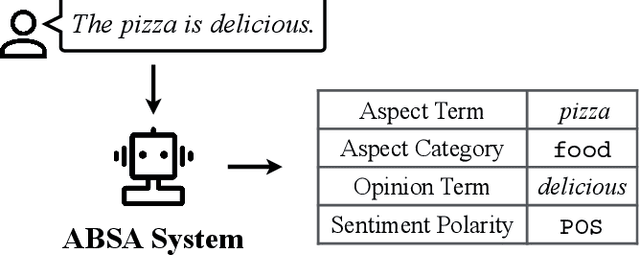
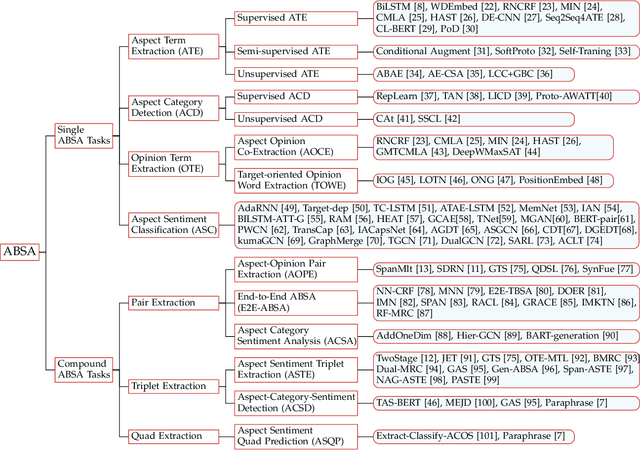
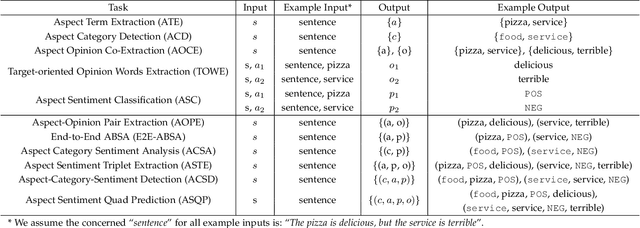
As an important fine-grained sentiment analysis problem, aspect-based sentiment analysis (ABSA), aiming to analyze and understand people's opinions at the aspect level, has been attracting considerable interest in the last decade. To handle ABSA in different scenarios, various tasks have been introduced for analyzing different sentiment elements and their relations, including the aspect term, aspect category, opinion term, and sentiment polarity. Unlike early ABSA works focusing on a single sentiment element, many compound ABSA tasks involving multiple elements have been studied in recent years for capturing more complete aspect-level sentiment information. However, a systematic review of various ABSA tasks and their corresponding solutions is still lacking, which we aim to fill in this survey. More specifically, we provide a new taxonomy for ABSA which organizes existing studies from the axes of concerned sentiment elements, with an emphasis on recent advances of compound ABSA tasks. From the perspective of solutions, we summarize the utilization of pre-trained language models for ABSA, which improved the performance of ABSA to a new stage. Besides, techniques for building more practical ABSA systems in cross-domain/lingual scenarios are discussed. Finally, we review some emerging topics and discuss some open challenges to outlook potential future directions of ABSA.
ViF-SD2E: A Robust Weakly-Supervised Method for Neural Decoding
Dec 02, 2021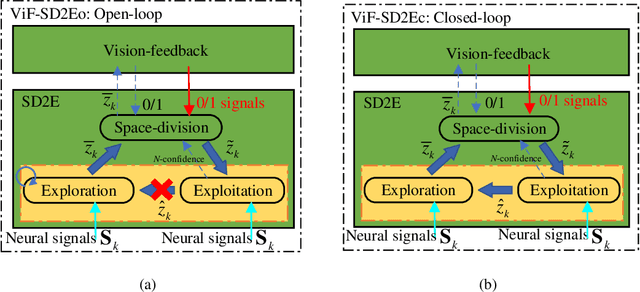
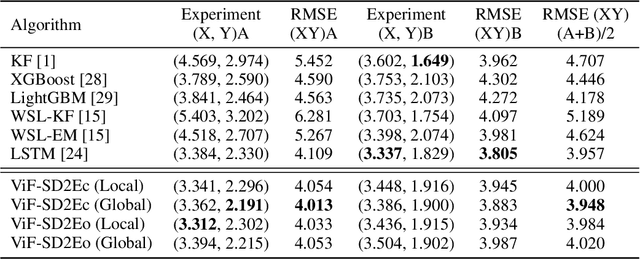
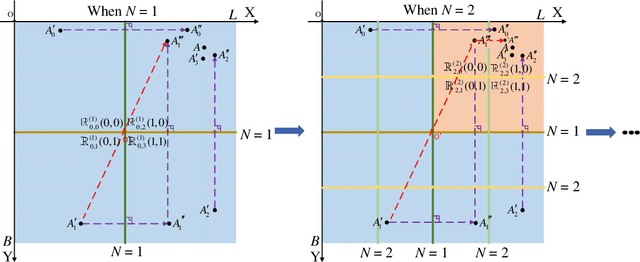
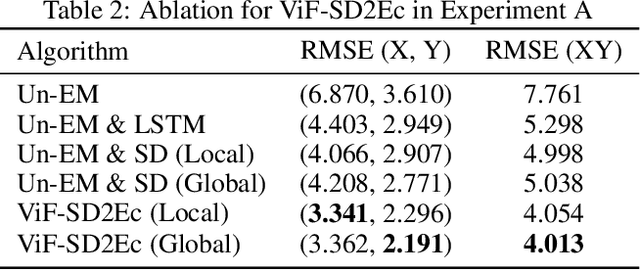
Neural decoding plays a vital role in the interaction between the brain and outside world. In this paper, we directly decode the movement track of the finger based on the neural signals of a macaque. The supervised regression methods may over-fit to actual labels contained with noise and require high labeling cost, while unsupervised approaches often have unsatisfactory accuracy. Besides, the spatial and temporal information are often ignored or not well exploited in these works. This motivates us to propose a robust weakly-supervised method termed ViF-SD2E for neural decoding. In particular, ViF-SD2E consists of a space-division (SD) module and a exploration-exploitation (2E) strategy, to effectively exploit both the spatial information of the outside world and temporal information of neural activity, where the SD2E output is compared with the weak 0/1 vision-feedback (ViF) label for training. Extensive experiments demonstrate the effectiveness of our method, which can be sometimes comparable to the supervised counterparts.
Model-Architecture Co-Design for High Performance Temporal GNN Inference on FPGA
Mar 10, 2022
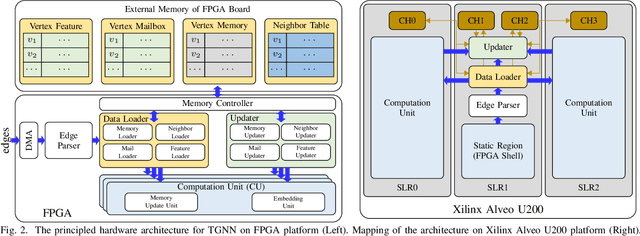
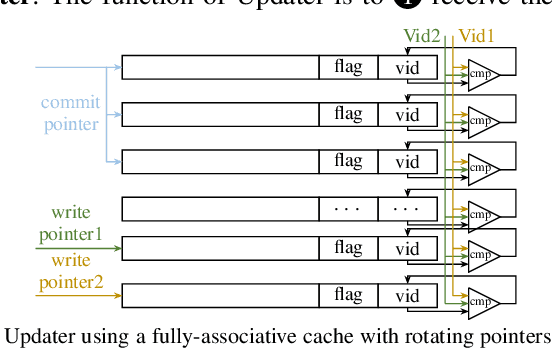
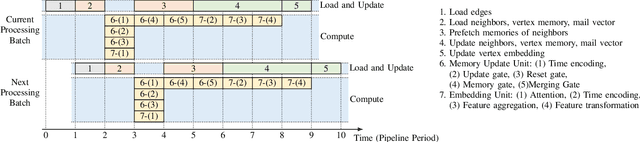
Temporal Graph Neural Networks (TGNNs) are powerful models to capture temporal, structural, and contextual information on temporal graphs. The generated temporal node embeddings outperform other methods in many downstream tasks. Real-world applications require high performance inference on real-time streaming dynamic graphs. However, these models usually rely on complex attention mechanisms to capture relationships between temporal neighbors. In addition, maintaining vertex memory suffers from intrinsic temporal data dependency that hinders task-level parallelism, making it inefficient on general-purpose processors. In this work, we present a novel model-architecture co-design for inference in memory-based TGNNs on FPGAs. The key modeling optimizations we propose include a light-weight method to compute attention scores and a related temporal neighbor pruning strategy to further reduce computation and memory accesses. These are holistically coupled with key hardware optimizations that leverage FPGA hardware. We replace the temporal sampler with an on-chip FIFO based hardware sampler and the time encoder with a look-up-table. We train our simplified models using knowledge distillation to ensure similar accuracy vis-\'a-vis the original model. Taking advantage of the model optimizations, we propose a principled hardware architecture using batching, pipelining, and prefetching techniques to further improve the performance. We also propose a hardware mechanism to ensure the chronological vertex updating without sacrificing the computation parallelism. We evaluate the performance of the proposed hardware accelerator on three real-world datasets.
APPLADE: Adjustable Plug-and-play Audio Declipper Combining DNN with Sparse Optimization
Feb 16, 2022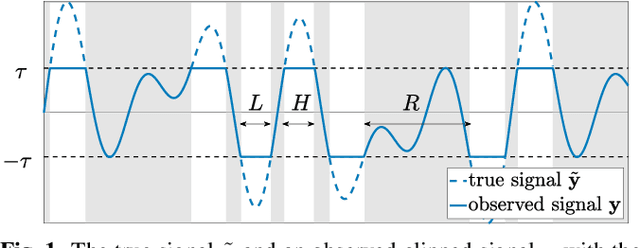
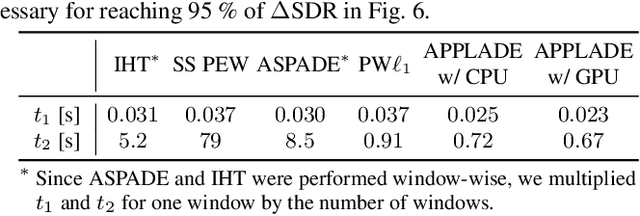
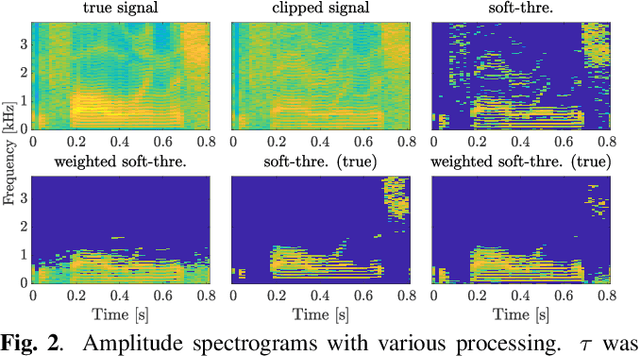
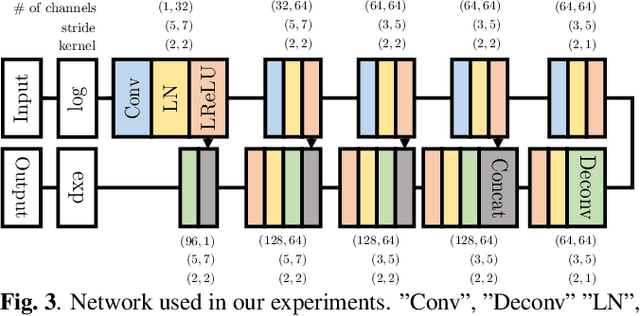
In this paper, we propose an audio declipping method that takes advantages of both sparse optimization and deep learning. Since sparsity-based audio declipping methods have been developed upon constrained optimization, they are adjustable and well-studied in theory. However, they always uniformly promote sparsity and ignore the individual properties of a signal. Deep neural network (DNN)-based methods can learn the properties of target signals and use them for audio declipping. Still, they cannot perform well if the training data have mismatches and/or constraints in the time domain are not imposed. In the proposed method, we use a DNN in an optimization algorithm. It is inspired by an idea called plug-and-play (PnP) and enables us to promote sparsity based on the learned information of data, considering constraints in the time domain. Our experiments confirmed that the proposed method is stable and robust to mismatches between training and test data.
Initialization of Latent Space Coordinates via Random Linear Projections for Learning Robotic Sensory-Motor Sequences
Feb 26, 2022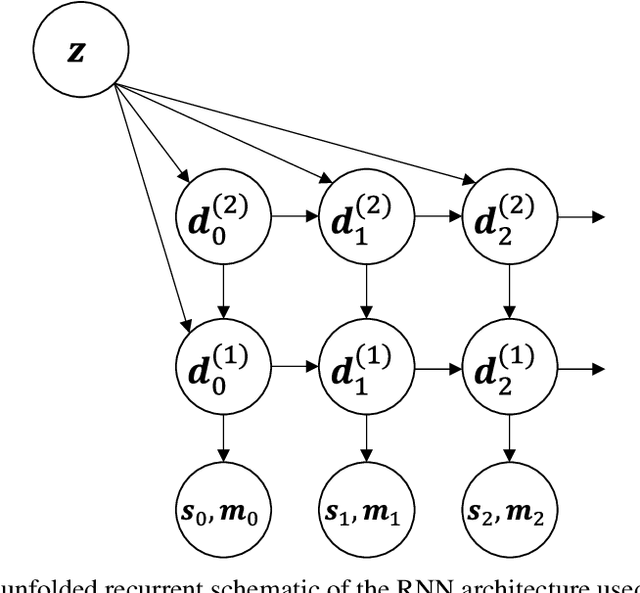

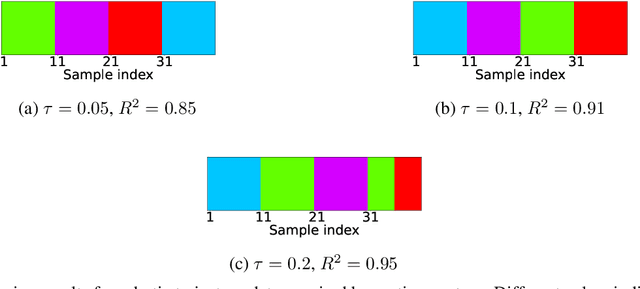

Robot kinematics data, despite being a high dimensional process, is highly correlated, especially when considering motions grouped in certain primitives. These almost linear correlations within primitives allow us to interpret the motions as points drawn close to a union of low-dimensional linear subspaces in the space of all motions. Motivated by results of embedding theory, in particular, generalizations of Whitney embedding theorem, we show that random linear projection of motor sequences into low dimensional space loses very little information about structure of kinematics data. Projected points are very good initial guess for values of latent variables in generative model for robot sensory-motor behaviour primitives. We conducted series of experiments where we trained a recurrent neural network to generate sensory-motor sequences for robotic manipulator with 9 degrees of freedom. Experimental results demonstrate substantial improvement in generalisation abilities for unobserved samples in the case of initialization of latent variables with random linear projection of motor data over initialization with zero or random values. Moreover, latent space is well-structured wherein samples belonging to different primitives are well separated from the onset of training process.
InfoFocus: 3D Object Detection for Autonomous Driving with Dynamic Information Modeling
Jul 16, 2020

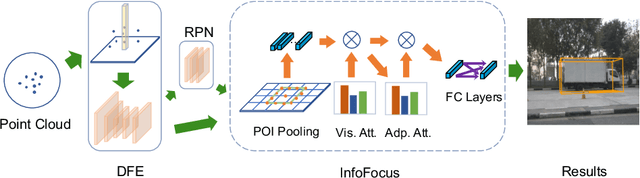
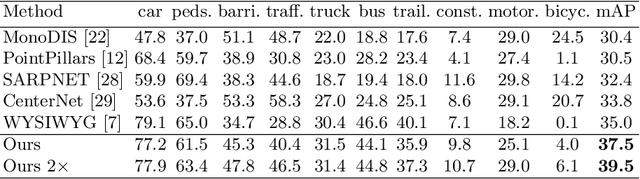
Real-time 3D object detection is crucial for autonomous cars. Achieving promising performance with high efficiency, voxel-based approaches have received considerable attention. However, previous methods model the input space with features extracted from equally divided sub-regions without considering that point cloud is generally non-uniformly distributed over the space. To address this issue, we propose a novel 3D object detection framework with dynamic information modeling. The proposed framework is designed in a coarse-to-fine manner. Coarse predictions are generated in the first stage via a voxel-based region proposal network. We introduce InfoFocus, which improves the coarse detections by adaptively refining features guided by the information of point cloud density. Experiments are conducted on the large-scale nuScenes 3D detection benchmark. Results show that our framework achieves the state-of-the-art performance with 31 FPS and improves our baseline significantly by 9.0% mAP on the nuScenes test set.