 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Optimality in Noisy Importance Sampling
Jan 07, 2022
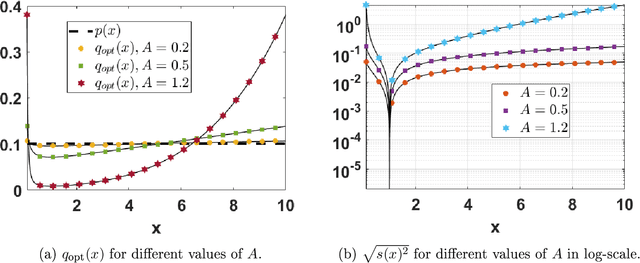
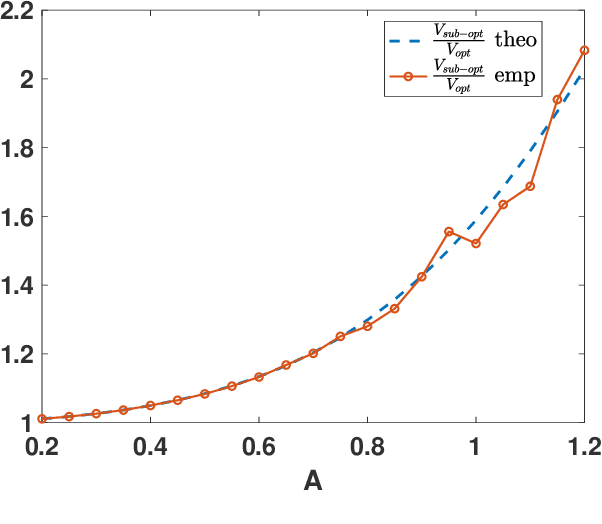
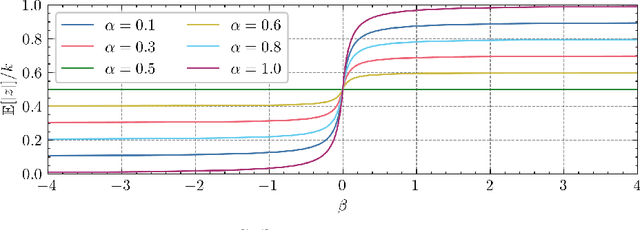
In this work, we analyze the noisy importance sampling (IS), i.e., IS working with noisy evaluations of the target density. We present the general framework and derive optimal proposal densities for noisy IS estimators. The optimal proposals incorporate the information of the variance of the noisy realizations, proposing points in regions where the noise power is higher. We also compare the use of the optimal proposals with previous optimality approaches considered in a noisy IS framework.
Fine-Grained Population Mobility Data-Based Community-Level COVID-19 Prediction Model
Feb 13, 2022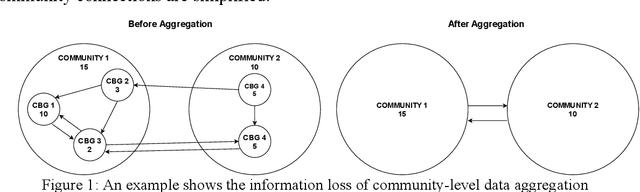
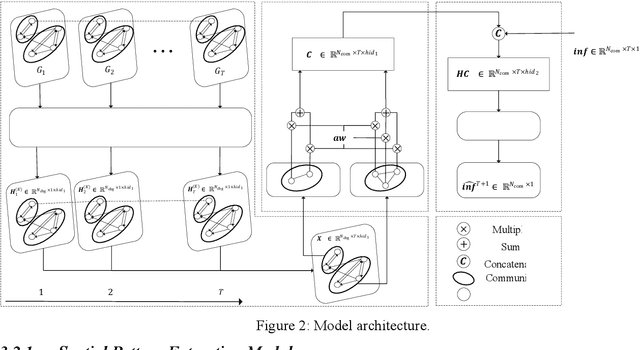
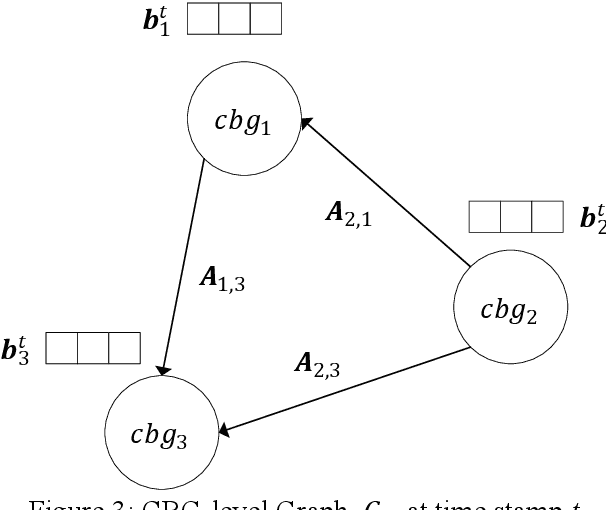
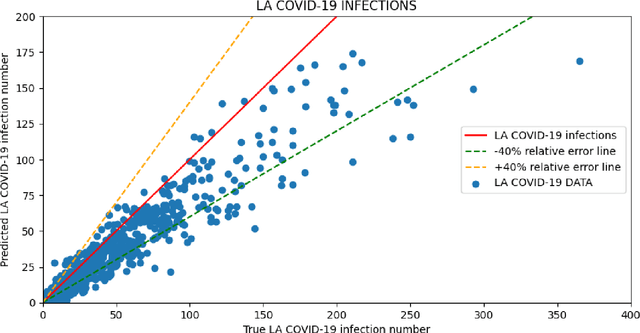
Predicting the number of infections in the anti-epidemic process is extremely beneficial to the government in developing anti-epidemic strategies, especially in fine-grained geographic units. Previous works focus on low spatial resolution prediction, e.g., county-level, and preprocess data to the same geographic level, which loses some useful information. In this paper, we propose a fine-grained population mobility data-based model (FGC-COVID) utilizing data of two geographic levels for community-level COVID-19 prediction. We use the population mobility data between Census Block Groups (CBGs), which is a finer-grained geographic level than community, to build the graph and capture the dependencies between CBGs using graph neural networks (GNNs). To mine as finer-grained patterns as possible for prediction, a spatial weighted aggregation module is introduced to aggregate the embeddings of CBGs to community level based on their geographic affiliation and spatial autocorrelation. Extensive experiments on 300 days LA city COVID-19 data indicate our model outperforms existing forecasting models on community-level COVID-19 prediction.
Model Agnostic Interpretability for Multiple Instance Learning
Jan 27, 2022
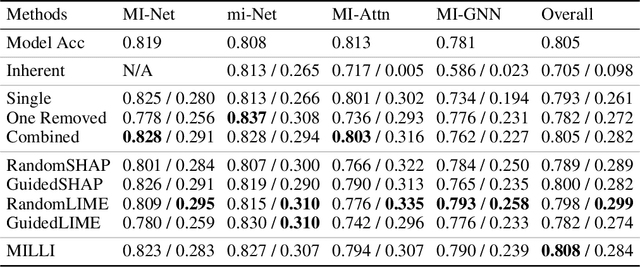

In Multiple Instance Learning (MIL), models are trained using bags of instances, where only a single label is provided for each bag. A bag label is often only determined by a handful of key instances within a bag, making it difficult to interpret what information a classifier is using to make decisions. In this work, we establish the key requirements for interpreting MIL models. We then go on to develop several model-agnostic approaches that meet these requirements. Our methods are compared against existing inherently interpretable MIL models on several datasets, and achieve an increase in interpretability accuracy of up to 30%. We also examine the ability of the methods to identify interactions between instances and scale to larger datasets, improving their applicability to real-world problems.
Machine Learning for Utility Prediction in Argument-Based Computational Persuasion
Dec 15, 2021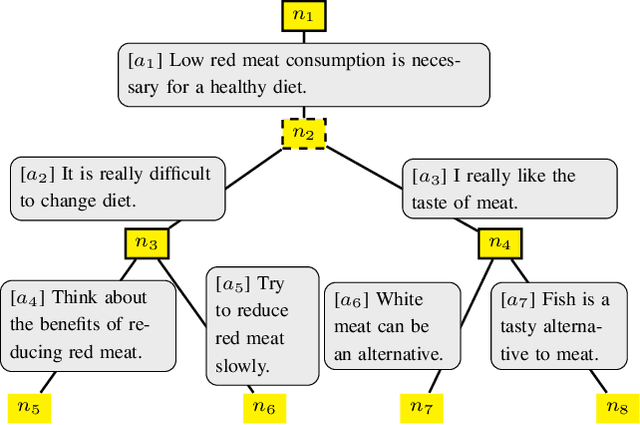
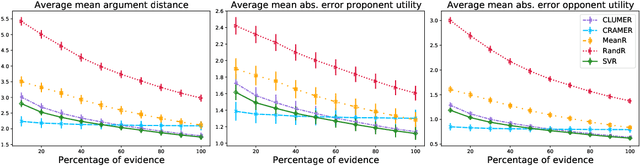
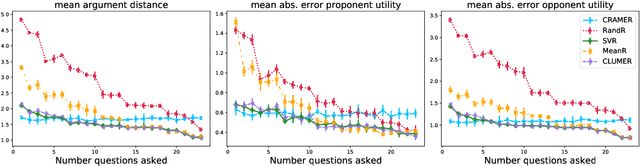
Automated persuasion systems (APS) aim to persuade a user to believe something by entering into a dialogue in which arguments and counterarguments are exchanged. To maximize the probability that an APS is successful in persuading a user, it can identify a global policy that will allow it to select the best arguments it presents at each stage of the dialogue whatever arguments the user presents. However, in real applications, such as for healthcare, it is unlikely the utility of the outcome of the dialogue will be the same, or the exact opposite, for the APS and user. In order to deal with this situation, games in extended form have been harnessed for argumentation in Bi-party Decision Theory. This opens new problems that we address in this paper: (1) How can we use Machine Learning (ML) methods to predict utility functions for different subpopulations of users? and (2) How can we identify for a new user the best utility function from amongst those that we have learned? To this extent, we develop two ML methods, EAI and EDS, that leverage information coming from the users to predict their utilities. EAI is restricted to a fixed amount of information, whereas EDS can choose the information that best detects the subpopulations of a user. We evaluate EAI and EDS in a simulation setting and in a realistic case study concerning healthy eating habits. Results are promising in both cases, but EDS is more effective at predicting useful utility functions.
Handling Imbalanced Datasets Through Optimum-Path Forest
Feb 17, 2022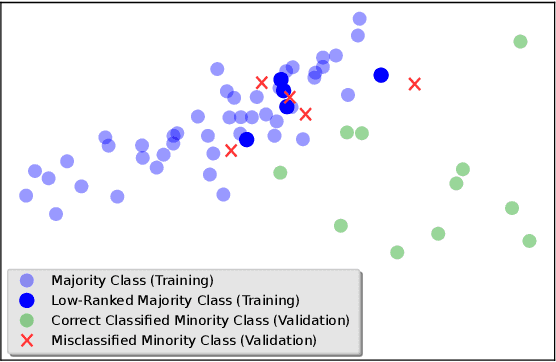
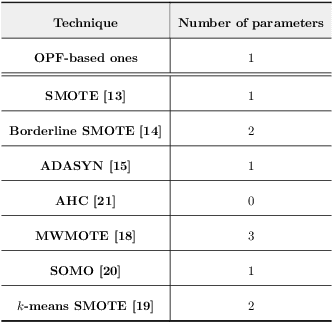
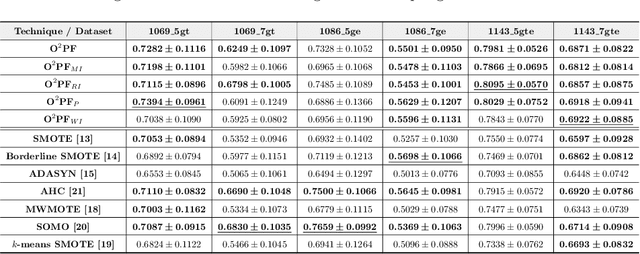
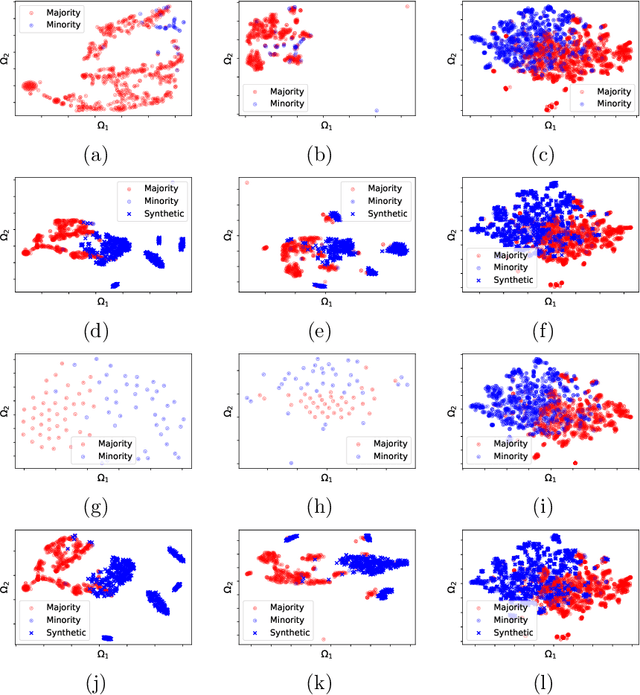
In the last decade, machine learning-based approaches became capable of performing a wide range of complex tasks sometimes better than humans, demanding a fraction of the time. Such an advance is partially due to the exponential growth in the amount of data available, which makes it possible to extract trustworthy real-world information from them. However, such data is generally imbalanced since some phenomena are more likely than others. Such a behavior yields considerable influence on the machine learning model's performance since it becomes biased on the more frequent data it receives. Despite the considerable amount of machine learning methods, a graph-based approach has attracted considerable notoriety due to the outstanding performance over many applications, i.e., the Optimum-Path Forest (OPF). In this paper, we propose three OPF-based strategies to deal with the imbalance problem: the $\text{O}^2$PF and the OPF-US, which are novel approaches for oversampling and undersampling, respectively, as well as a hybrid strategy combining both approaches. The paper also introduces a set of variants concerning the strategies mentioned above. Results compared against several state-of-the-art techniques over public and private datasets confirm the robustness of the proposed approaches.
Controlling the Quality of Distillation in Response-Based Network Compression
Dec 19, 2021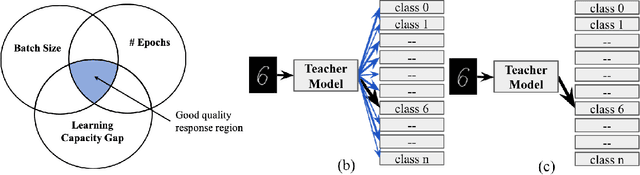


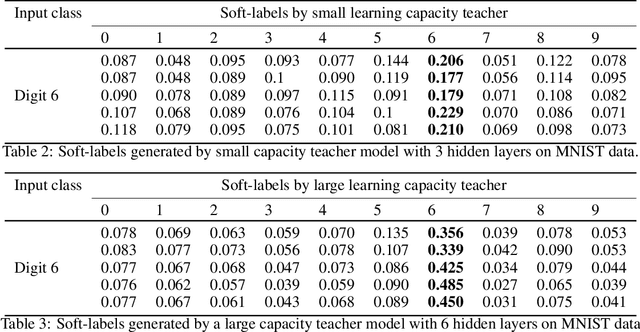
The performance of a distillation-based compressed network is governed by the quality of distillation. The reason for the suboptimal distillation of a large network (teacher) to a smaller network (student) is largely attributed to the gap in the learning capacities of given teacher-student pair. While it is hard to distill all the knowledge of a teacher, the quality of distillation can be controlled to a large extent to achieve better performance. Our experiments show that the quality of distillation is largely governed by the quality of teacher's response, which in turn is heavily affected by the presence of similarity information in its response. A well-trained large capacity teacher loses similarity information between classes in the process of learning fine-grained discriminative properties for classification. The absence of similarity information causes the distillation process to be reduced from one example-many class learning to one example-one class learning, thereby throttling the flow of diverse knowledge from the teacher. With the implicit assumption that only the instilled knowledge can be distilled, instead of focusing only on the knowledge distilling process, we scrutinize the knowledge inculcation process. We argue that for a given teacher-student pair, the quality of distillation can be improved by finding the sweet spot between batch size and number of epochs while training the teacher. We discuss the steps to find this sweet spot for better distillation. We also propose the distillation hypothesis to differentiate the behavior of the distillation process between knowledge distillation and regularization effect. We conduct all our experiments on three different datasets.
Pop Quiz! Can a Large Language Model Help With Reverse Engineering?
Feb 02, 2022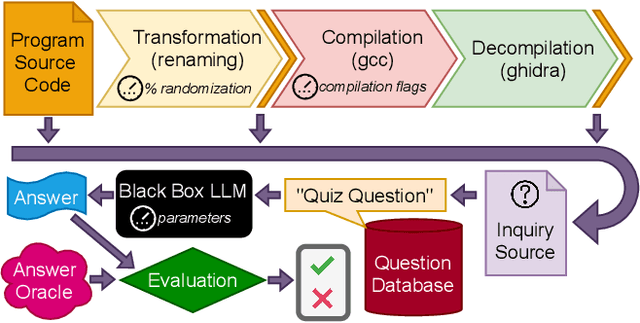
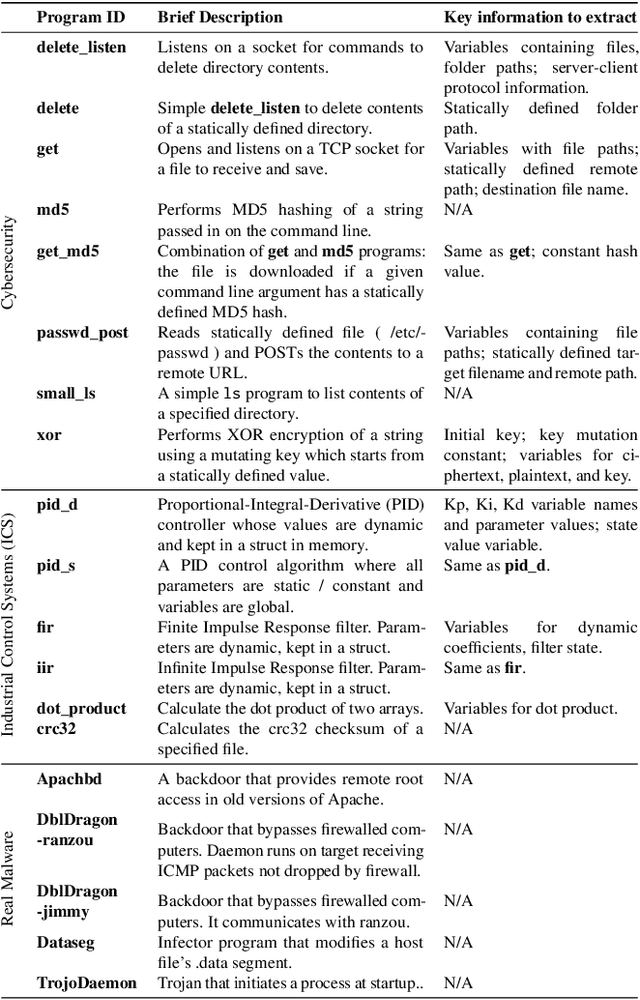

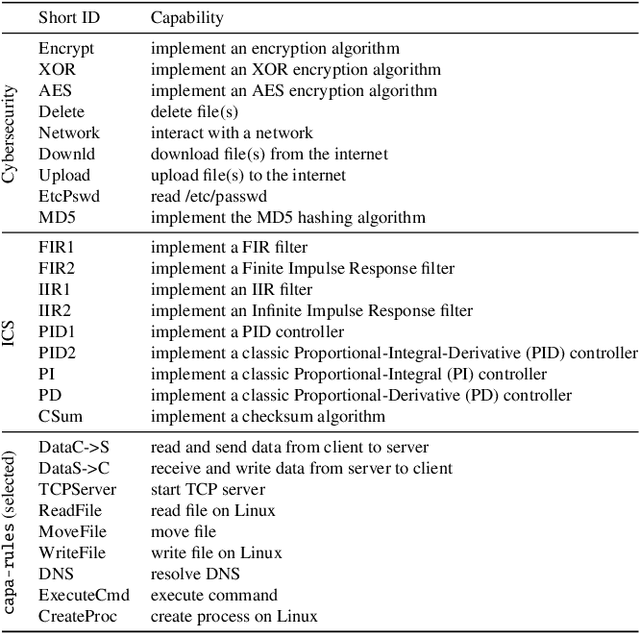
Large language models (such as OpenAI's Codex) have demonstrated impressive zero-shot multi-task capabilities in the software domain, including code explanation. In this work, we examine if this ability can be used to help with reverse engineering. Specifically, we investigate prompting Codex to identify the purpose, capabilities, and important variable names or values from code, even when the code is produced through decompilation. Alongside an examination of the model's responses in answering open-ended questions, we devise a true/false quiz framework to characterize the performance of the language model. We present an extensive quantitative analysis of the measured performance of the language model on a set of program purpose identification and information extraction tasks: of the 136,260 questions we posed, it answered 72,754 correctly. A key takeaway is that while promising, LLMs are not yet ready for zero-shot reverse engineering.
Ultra-Wideband Teach and Repeat
Feb 02, 2022Autonomously retracing a manually-taught path is desirable for many applications, and Teach and Repeat (T&R) algorithms present an approach that is suitable for long-range autonomy. In this paper, ultra-wideband (UWB) ranging-based T&R is proposed for vehicles with limited resources. By fixing single UWB transceivers at far-apart unknown locations in an indoor environment, a robot with 3 UWB transceivers builds a locally consistent map during the teach pass by fusing the range measurements under a custom ranging protocol with an on-board IMU and height measurements. The robot then uses information from the teach pass to retrace the same trajectory autonomously. The proposed ranging protocol and T&R algorithm are validated in simulation, where it is shown that the robot can successfully retrace the taught trajectory with sub-metre tracking error.
SciREX: A Challenge Dataset for Document-Level Information Extraction
May 01, 2020
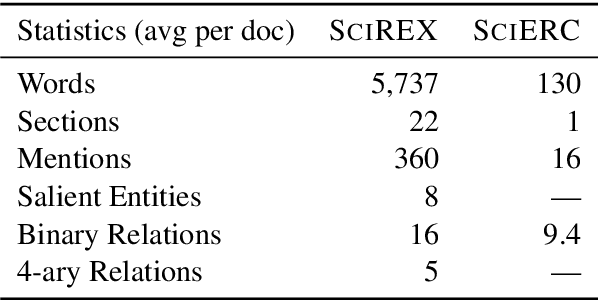
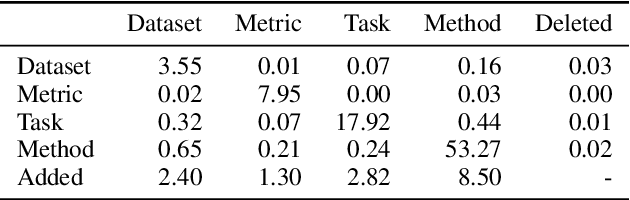
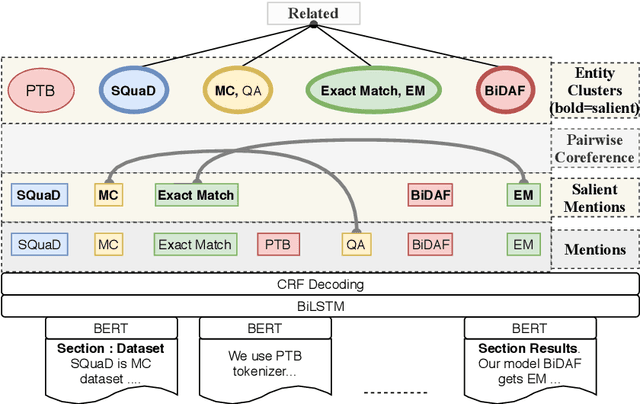
Extracting information from full documents is an important problem in many domains, but most previous work focus on identifying relationships within a sentence or a paragraph. It is challenging to create a large-scale information extraction (IE) dataset at the document level since it requires an understanding of the whole document to annotate entities and their document-level relationships that usually span beyond sentences or even sections. In this paper, we introduce SciREX, a document level IE dataset that encompasses multiple IE tasks, including salient entity identification and document level $N$-ary relation identification from scientific articles. We annotate our dataset by integrating automatic and human annotations, leveraging existing scientific knowledge resources. We develop a neural model as a strong baseline that extends previous state-of-the-art IE models to document-level IE. Analyzing the model performance shows a significant gap between human performance and current baselines, inviting the community to use our dataset as a challenge to develop document-level IE models. Our data and code are publicly available at https://github.com/allenai/SciREX
Tac3D: A Novel Vision-based Tactile Sensor for Measuring Forces Distribution and Estimating Friction Coefficient Distribution
Feb 13, 2022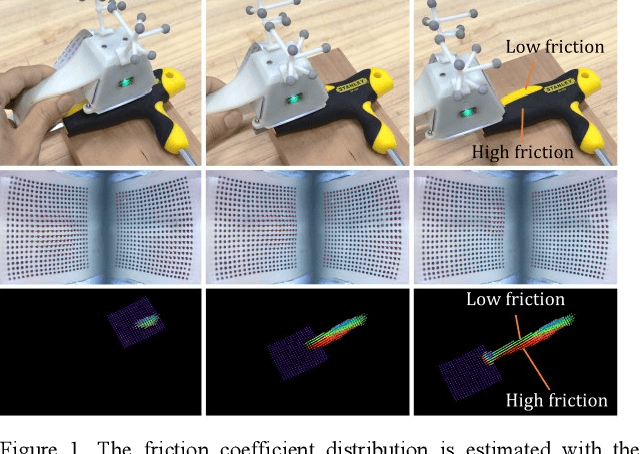
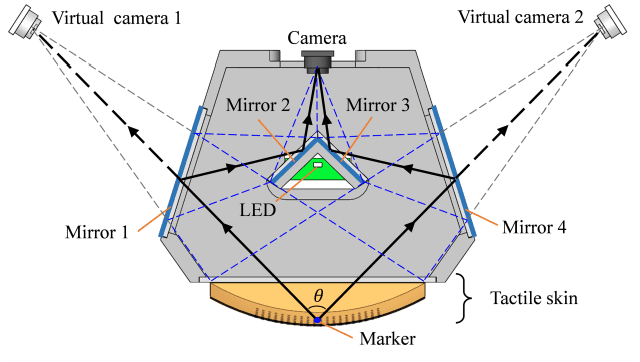
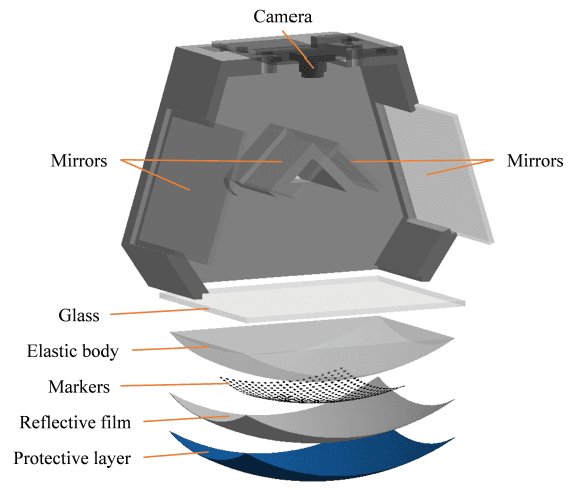
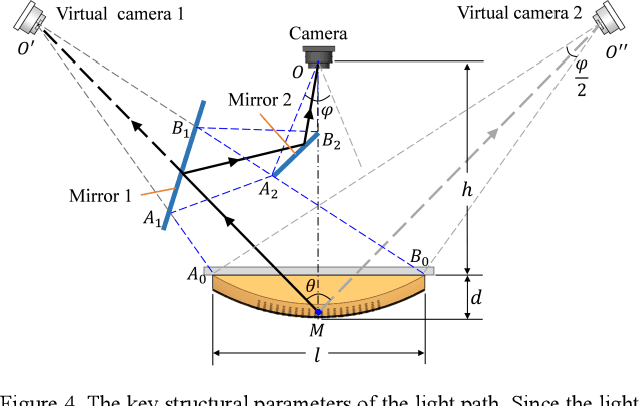
The importance of force perception in interacting with the environment was proven years ago. However, it is still a challenge to measure the contact force distribution accurately in real-time. In order to break through this predicament, we propose a new vision-based tactile sensor, the Tac3D sensor, for measuring the three-dimensional contact surface shape and contact force distribution. In this work, virtual binocular vision is first applied to the tactile sensor, which allows the Tac3D sensor to measure the three-dimensional tactile information in a simple and efficient way and has the advantages of simple structure, low computational costs, and inexpensive. Then, we used contact surface shape and force distribution to estimate the friction coefficient distribution in contact region. Further, combined with the global position of the tactile sensor, the 3D model of the object with friction coefficient distribution is reconstructed. These reconstruction experiments not only demonstrate the excellent performance of the Tac3D sensor but also imply the possibility to optimize the action planning in grasping based on the friction coefficient distribution of the object.