 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decentralized Multi-Task Stochastic Optimization With Compressed Communications
Dec 23, 2021
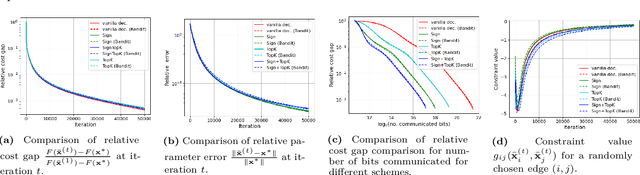
We consider a multi-agent network where each node has a stochastic (local) cost function that depends on the decision variable of that node and a random variable, and further the decision variables of neighboring nodes are pairwise constrained. There is an aggregate objective function for the network, composed additively of the expected values of the local cost functions at the nodes, and the overall goal of the network is to obtain the minimizing solution to this aggregate objective function subject to all the pairwise constraints. This is to be achieved at the node level using decentralized information and local computation, with exchanges of only compressed information allowed by neighboring nodes. The paper develops algorithms and obtains performance bounds for two different models of local information availability at the nodes: (i) sample feedback, where each node has direct access to samples of the local random variable to evaluate its local cost, and (ii) bandit feedback, where samples of the random variables are not available, but only the values of the local cost functions at two random points close to the decision are available to each node. For both models, with compressed communication between neighbors, we have developed decentralized saddle-point algorithms that deliver performances no different (in order sense) from those without communication compression; specifically, we show that deviation from the global minimum value and violations of the constraints are upper-bounded by $\mathcal{O}(T^{-\frac{1}{2}})$ and $\mathcal{O}(T^{-\frac{1}{4}})$, respectively, where $T$ is the number of iterations. Numerical examples provided in the paper corroborate these bounds and demonstrate the communication efficiency of the proposed method.
Structured access to AI capabilities: an emerging paradigm for safe AI deployment
Jan 13, 2022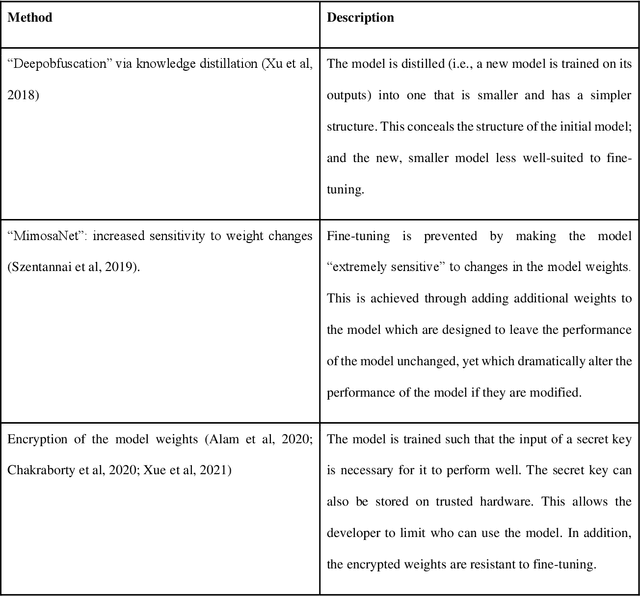
Structured capability access ("SCA") is an emerging paradigm for the safe deployment of artificial intelligence (AI). Instead of openly disseminating AI systems, developers facilitate controlled, arm's length interactions with their AI systems. The aim is to prevent dangerous AI capabilities from being widely accessible, whilst preserving access to AI capabilities that can be used safely. The developer must both restrict how the AI system can be used, and prevent the user from circumventing these restrictions through modification or reverse engineering of the AI system. SCA is most effective when implemented through cloud-based AI services, rather than disseminating AI software that runs locally on users' hardware. Cloud-based interfaces provide the AI developer greater scope for controlling how the AI system is used, and for protecting against unauthorized modifications to the system's design. This chapter expands the discussion of "publication norms" in the AI community, which to date has focused on the question of how the informational content of AI research projects should be disseminated (e.g., code and models). Although this is an important question, there are limits to what can be achieved through the control of information flows. SCA views AI software not only as information that can be shared but also as a tool with which users can have arm's length interactions. There are early examples of SCA being practiced by AI developers, but there is much room for further development, both in the functionality of cloud-based interfaces and in the wider institutional framework.
QA4QG: Using Question Answering to Constrain Multi-Hop Question Generation
Feb 14, 2022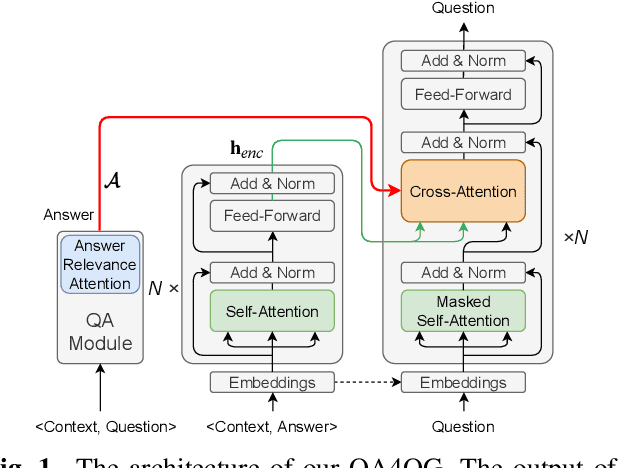
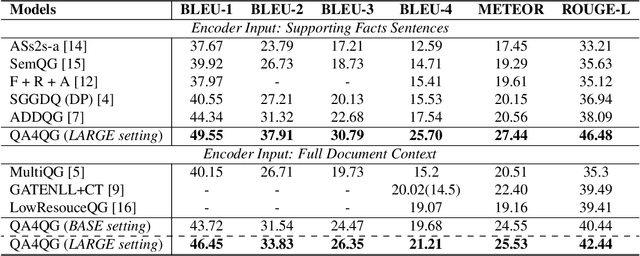
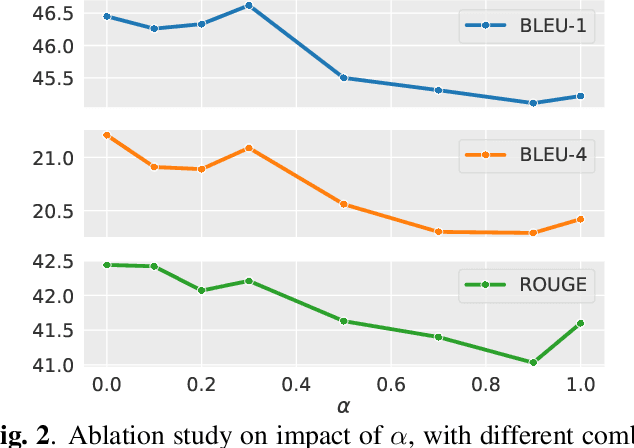
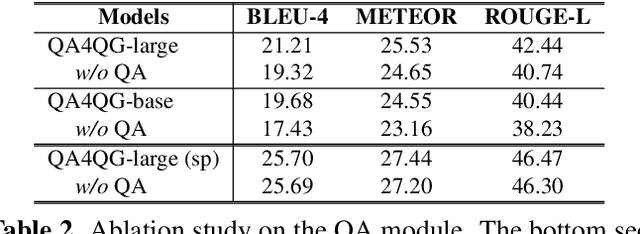
Multi-hop question generation (MQG) aims to generate complex questions which require reasoning over multiple pieces of information of the input passage. Most existing work on MQG has focused on exploring graph-based networks to equip the traditional Sequence-to-sequence framework with reasoning ability. However, these models do not take full advantage of the constraint between questions and answers. Furthermore, studies on multi-hop question answering (QA) suggest that Transformers can replace the graph structure for multi-hop reasoning. Therefore, in this work, we propose a novel framework, QA4QG, a QA-augmented BART-based framework for MQG. It augments the standard BART model with an additional multi-hop QA module to further constrain the generated question. Our results on the HotpotQA dataset show that QA4QG outperforms all state-of-the-art models, with an increase of 8 BLEU-4 and 8 ROUGE points compared to the best results previously reported. Our work suggests the advantage of introducing pre-trained language models and QA module for the MQG task.
Bending Reality: Distortion-aware Transformers for Adapting to Panoramic Semantic Segmentation
Mar 02, 2022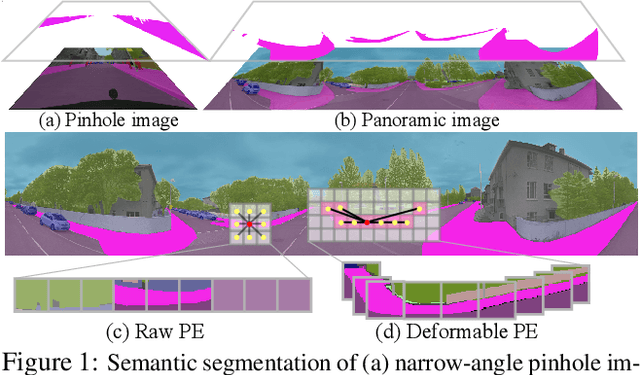
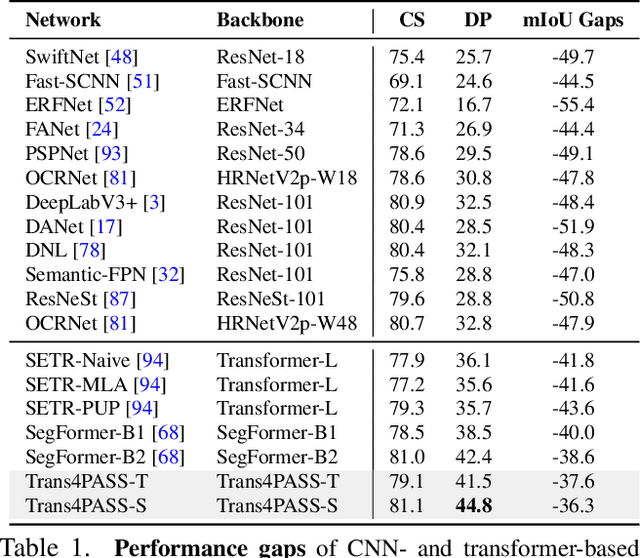
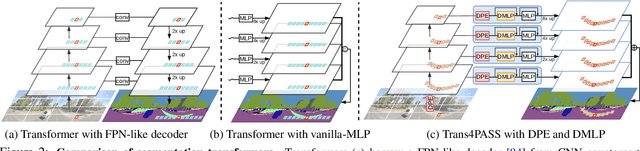
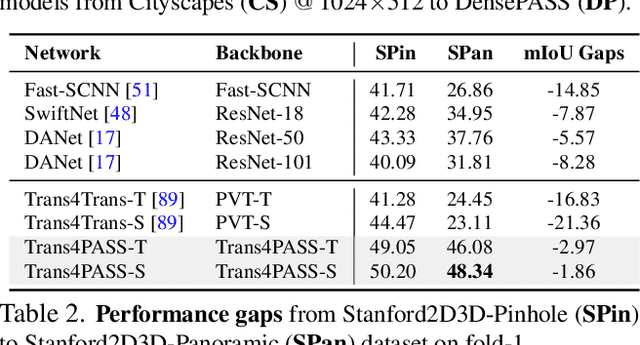
Panoramic images with their 360-degree directional view encompass exhaustive information about the surrounding space, providing a rich foundation for scene understanding. To unfold this potential in the form of robust panoramic segmentation models, large quantities of expensive, pixel-wise annotations are crucial for success. Such annotations are available, but predominantly for narrow-angle, pinhole-camera images which, off the shelf, serve as sub-optimal resources for training panoramic models. Distortions and the distinct image-feature distribution in 360-degree panoramas impede the transfer from the annotation-rich pinhole domain and therefore come with a big dent in performance. To get around this domain difference and bring together semantic annotations from pinhole- and 360-degree surround-visuals, we propose to learn object deformations and panoramic image distortions in the Deformable Patch Embedding (DPE) and Deformable MLP (DMLP) components which blend into our Transformer for PAnoramic Semantic Segmentation (Trans4PASS) model. Finally, we tie together shared semantics in pinhole- and panoramic feature embeddings by generating multi-scale prototype features and aligning them in our Mutual Prototypical Adaptation (MPA) for unsupervised domain adaptation. On the indoor Stanford2D3D dataset, our Trans4PASS with MPA maintains comparable performance to fully-supervised state-of-the-arts, cutting the need for over 1,400 labeled panoramas. On the outdoor DensePASS dataset, we break state-of-the-art by 14.39% mIoU and set the new bar at 56.38%. Code will be made publicly available at https://github.com/jamycheung/Trans4PASS.
One-stage Video Instance Segmentation: From Frame-in Frame-out to Clip-in Clip-out
Mar 12, 2022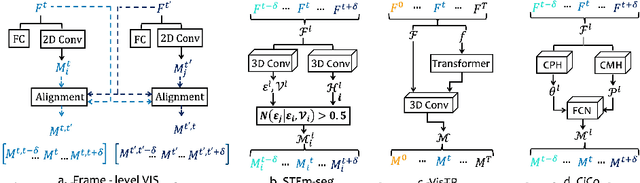
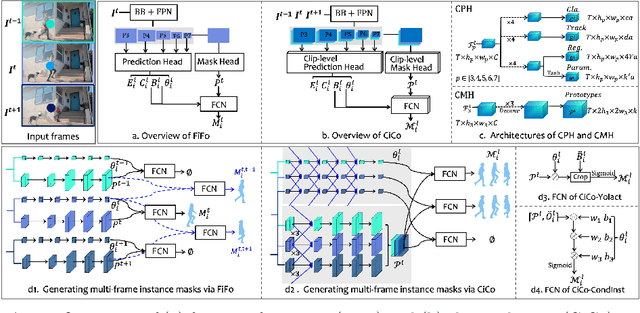
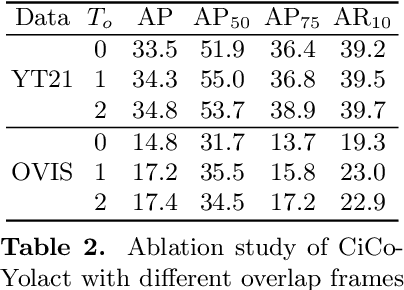

Many video instance segmentation (VIS) methods partition a video sequence into individual frames to detect and segment objects frame by frame. However, such a frame-in frame-out (FiFo) pipeline is ineffective to exploit the temporal information. Based on the fact that adjacent frames in a short clip are highly coherent in content, we propose to extend the one-stage FiFo framework to a clip-in clip-out (CiCo) one, which performs VIS clip by clip. Specifically, we stack FPN features of all frames in a short video clip to build a spatio-temporal feature cube, and replace the 2D conv layers in the prediction heads and the mask branch with 3D conv layers, forming clip-level prediction heads (CPH) and clip-level mask heads (CMH). Then the clip-level masks of an instance can be generated by feeding its box-level predictions from CPH and clip-level features from CMH into a small fully convolutional network. A clip-level segmentation loss is proposed to ensure that the generated instance masks are temporally coherent in the clip. The proposed CiCo strategy is free of inter-frame alignment, and can be easily embedded into existing FiFo based VIS approaches. To validate the generality and effectiveness of our CiCo strategy, we apply it to two representative FiFo methods, Yolact \cite{bolya2019yolact} and CondInst \cite{tian2020conditional}, resulting in two new one-stage VIS models, namely CiCo-Yolact and CiCo-CondInst, which achieve 37.1/37.3\%, 35.2/35.4\% and 17.2/18.0\% mask AP using the ResNet50 backbone, and 41.8/41.4\%, 38.0/38.9\% and 18.0/18.2\% mask AP using the Swin Transformer tiny backbone on YouTube-VIS 2019, 2021 and OVIS valid sets, respectively, recording new state-of-the-arts. Code and video demos of CiCo can be found at \url{https://github.com/MinghanLi/CiCo}.
Task-Adaptive Feature Transformer with Semantic Enrichment for Few-Shot Segmentation
Feb 14, 2022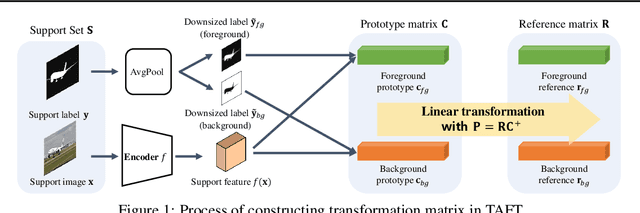
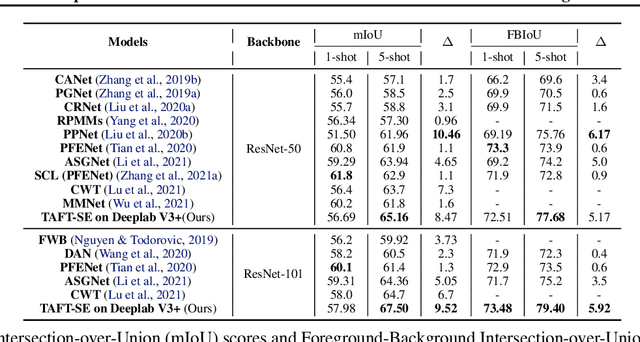
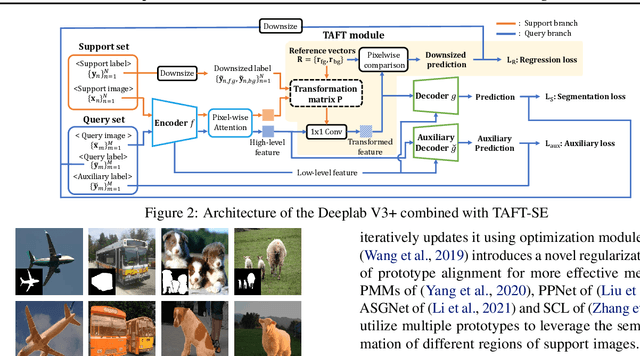
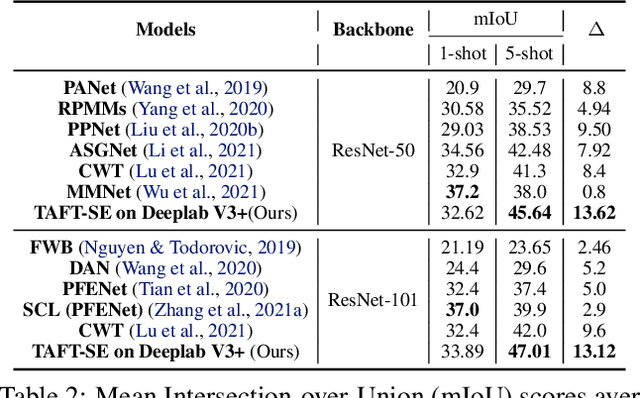
Few-shot learning allows machines to classify novel classes using only a few labeled samples. Recently, few-shot segmentation aiming at semantic segmentation on low sample data has also seen great interest. In this paper, we propose a learnable module that can be placed on top of existing segmentation networks for performing few-shot segmentation. This module, called the task-adaptive feature transformer (TAFT), linearly transforms task-specific high-level features to a set of task agnostic features well-suited to conducting few-shot segmentation. The task-conditioned feature transformation allows an effective utilization of the semantic information in novel classes to generate tight segmentation masks. We also propose a semantic enrichment (SE) module that utilizes a pixel-wise attention module for high-level feature and an auxiliary loss from an auxiliary segmentation network conducting the semantic segmentation for all training classes. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets confirm that the added modules successfully extend the capability of existing segmentators to yield highly competitive few-shot segmentation performances.
Span Based Open Information Extraction
Mar 01, 2019
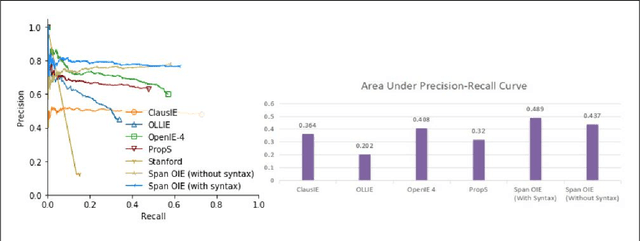
In this paper, we propose a span based model combined with syntactic information for n-ary open information extraction. The advantage of span model is that it can leverage span level features, which is difficult in token based BIO tagging methods. We also improve the previous bootstrap method to construct training corpus. Experiments show that our model outperforms previous open information extraction systems. Our code and data are publicly available at https://github.com/zhanjunlang/Span_OIE
Model Agnostic Interpretability for Multiple Instance Learning
Jan 28, 2022
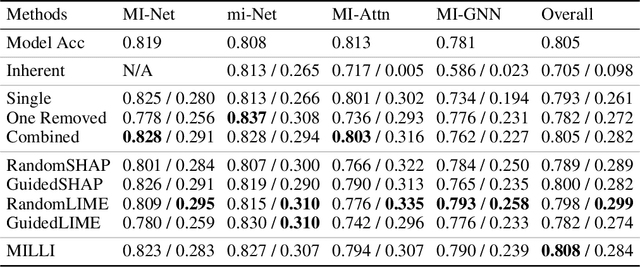

In Multiple Instance Learning (MIL), models are trained using bags of instances, where only a single label is provided for each bag. A bag label is often only determined by a handful of key instances within a bag, making it difficult to interpret what information a classifier is using to make decisions. In this work, we establish the key requirements for interpreting MIL models. We then go on to develop several model-agnostic approaches that meet these requirements. Our methods are compared against existing inherently interpretable MIL models on several datasets, and achieve an increase in interpretability accuracy of up to 30%. We also examine the ability of the methods to identify interactions between instances and scale to larger datasets, improving their applicability to real-world problems.
Joint CNN and Transformer Network via weakly supervised Learning for efficient crowd counting
Mar 12, 2022

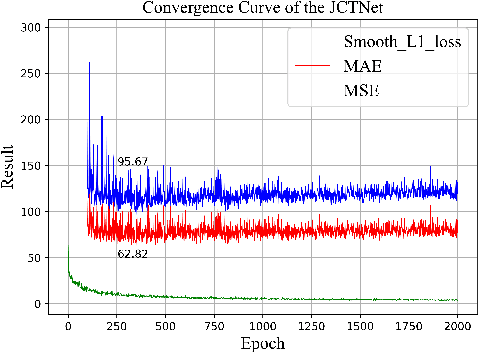
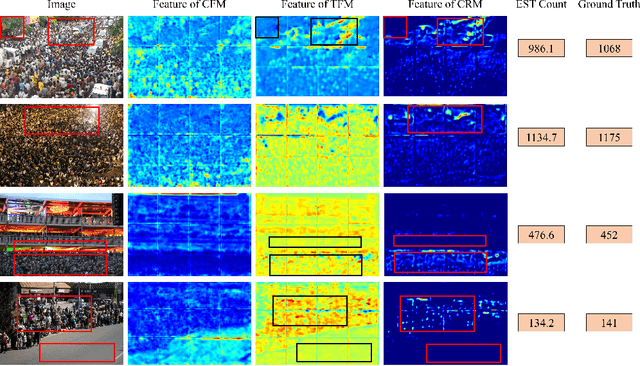
Currently, for crowd counting, the fully supervised methods via density map estimation are the mainstream research directions. However, such methods need location-level annotation of persons in an image, which is time-consuming and laborious. Therefore, the weakly supervised method just relying upon the count-level annotation is urgently needed. Since CNN is not suitable for modeling the global context and the interactions between image patches, crowd counting with weakly supervised learning via CNN generally can not show good performance. The weakly supervised model via Transformer was sequentially proposed to model the global context and learn contrast features. However, the transformer directly partitions the crowd images into a series of tokens, which may not be a good choice due to each pedestrian being an independent individual, and the parameter number of the network is very large. Hence, we propose a Joint CNN and Transformer Network (JCTNet) via weakly supervised learning for crowd counting in this paper. JCTNet consists of three parts: CNN feature extraction module (CFM), Transformer feature extraction module (TFM), and counting regression module (CRM). In particular, the CFM extracts crowd semantic information features, then sends their patch partitions to TRM for modeling global context, and CRM is used to predict the number of people. Extensive experiments and visualizations demonstrate that JCTNet can effectively focus on the crowd regions and obtain superior weakly supervised counting performance on five mainstream datasets. The number of parameters of the model can be reduced by about 67%~73% compared with the pure Transformer works. We also tried to explain the phenomenon that a model constrained only by count-level annotations can still focus on the crowd regions. We believe our work can promote further research in this field.
Neural Galerkin Scheme with Active Learning for High-Dimensional Evolution Equations
Mar 02, 2022


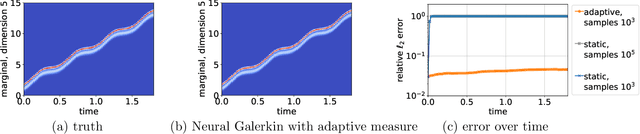
Machine learning methods have been shown to give accurate predictions in high dimensions provided that sufficient training data are available. Yet, many interesting questions in science and engineering involve situations where initially no data are available and the principal aim is to gather insights from a known model. Here we consider this problem in the context of systems whose evolution can be described by partial differential equations (PDEs). We use deep learning to solve these equations by generating data on-the-fly when and where they are needed, without prior information about the solution. The proposed Neural Galerkin schemes derive nonlinear dynamical equations for the network weights by minimization of the residual of the time derivative of the solution, and solve these equations using standard integrators for initial value problems. The sequential learning of the weights over time allows for adaptive collection of new input data for residual estimation. This step uses importance sampling informed by the current state of the solution, in contrast with other machine learning methods for PDEs that optimize the network parameters globally in time. This active form of data acquisition is essential to enable the approximation power of the neural networks and to break the curse of dimensionality faced by non-adaptative learning strategies. The applicability of the method is illustrated on several numerical examples involving high-dimensional PDEs, including advection equations with many variables, as well as Fokker-Planck equations for systems with several interacting particles.