 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A resource-efficient deep learning framework for low-dose brain PET image reconstruction and analysis
Feb 14, 2022
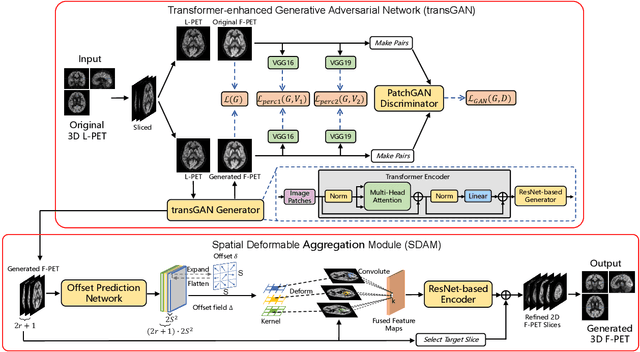

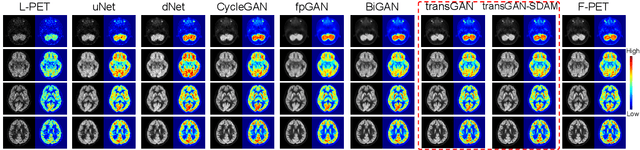

18F-fluorodeoxyglucose (18F-FDG) Positron Emission Tomography (PET) imaging usually needs a full-dose radioactive tracer to obtain satisfactory diagnostic results, which raises concerns about the potential health risks of radiation exposure, especially for pediatric patients. Reconstructing the low-dose PET (L-PET) images to the high-quality full-dose PET (F-PET) ones is an effective way that both reduces the radiation exposure and remains diagnostic accuracy. In this paper, we propose a resource-efficient deep learning framework for L-PET reconstruction and analysis, referred to as transGAN-SDAM, to generate F-PET from corresponding L-PET, and quantify the standard uptake value ratios (SUVRs) of these generated F-PET at whole brain. The transGAN-SDAM consists of two modules: a transformer-encoded Generative Adversarial Network (transGAN) and a Spatial Deformable Aggregation Module (SDAM). The transGAN generates higher quality F-PET images, and then the SDAM integrates the spatial information of a sequence of generated F-PET slices to synthesize whole-brain F-PET images. Experimental results demonstrate the superiority and rationality of our approach.
Texture Characterization of Histopathologic Images Using Ecological Diversity Measures and Discrete Wavelet Transform
Feb 27, 2022
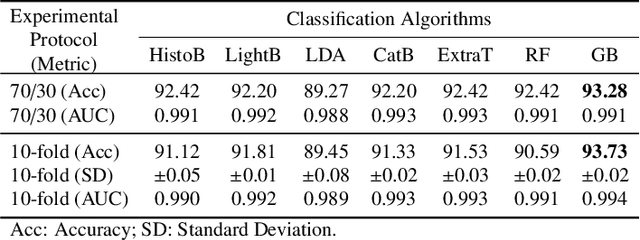
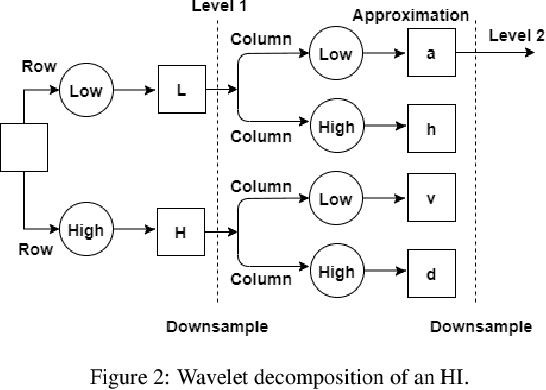
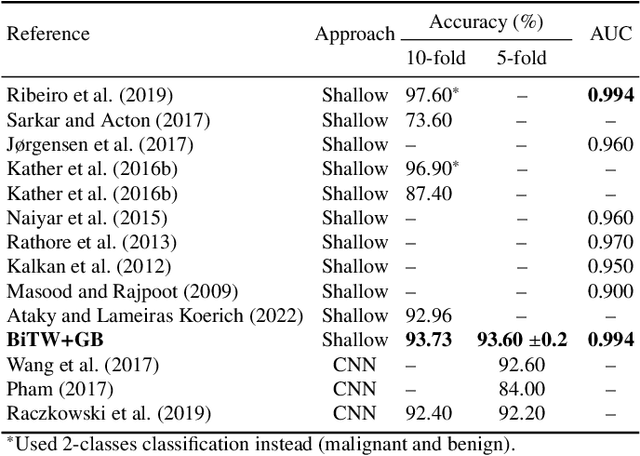
Breast cancer is a health problem that affects mainly the female population. An early detection increases the chances of effective treatment, improving the prognosis of the disease. In this regard, computational tools have been proposed to assist the specialist in interpreting the breast digital image exam, providing features for detecting and diagnosing tumors and cancerous cells. Nonetheless, detecting tumors with a high sensitivity rate and reducing the false positives rate is still challenging. Texture descriptors have been quite popular in medical image analysis, particularly in histopathologic images (HI), due to the variability of both the texture found in such images and the tissue appearance due to irregularity in the staining process. Such variability may exist depending on differences in staining protocol such as fixation, inconsistency in the staining condition, and reagents, either between laboratories or in the same laboratory. Textural feature extraction for quantifying HI information in a discriminant way is challenging given the distribution of intrinsic properties of such images forms a non-deterministic complex system. This paper proposes a method for characterizing texture across HIs with a considerable success rate. By employing ecological diversity measures and discrete wavelet transform, it is possible to quantify the intrinsic properties of such images with promising accuracy on two HI datasets compared with state-of-the-art methods.
QA4QG: Using Question Answering to Constrain Multi-Hop Question Generation
Feb 14, 2022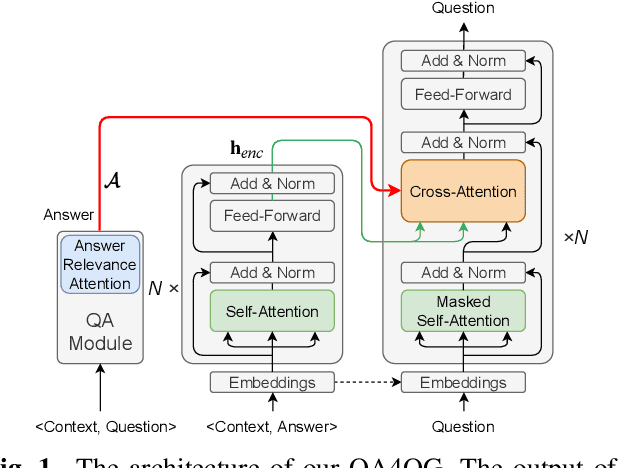
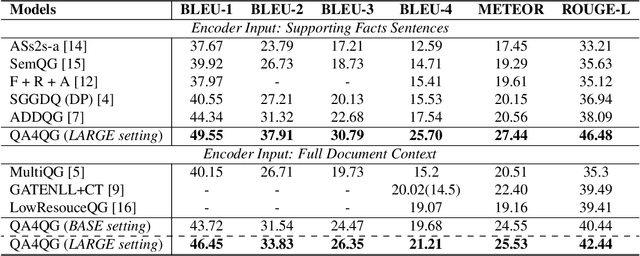
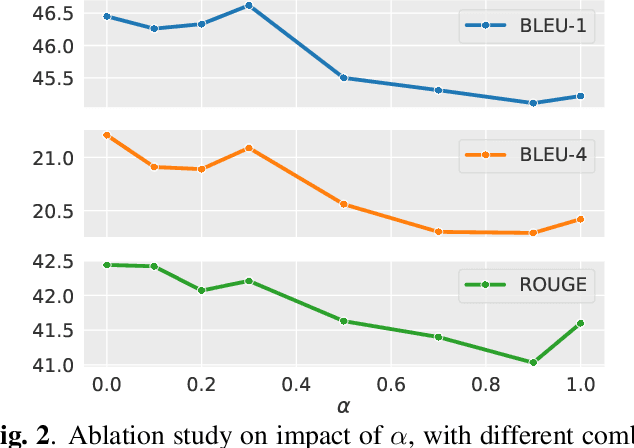
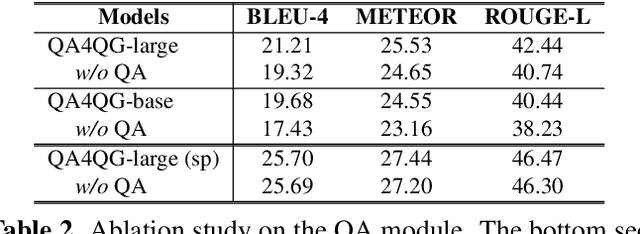
Multi-hop question generation (MQG) aims to generate complex questions which require reasoning over multiple pieces of information of the input passage. Most existing work on MQG has focused on exploring graph-based networks to equip the traditional Sequence-to-sequence framework with reasoning ability. However, these models do not take full advantage of the constraint between questions and answers. Furthermore, studies on multi-hop question answering (QA) suggest that Transformers can replace the graph structure for multi-hop reasoning. Therefore, in this work, we propose a novel framework, QA4QG, a QA-augmented BART-based framework for MQG. It augments the standard BART model with an additional multi-hop QA module to further constrain the generated question. Our results on the HotpotQA dataset show that QA4QG outperforms all state-of-the-art models, with an increase of 8 BLEU-4 and 8 ROUGE points compared to the best results previously reported. Our work suggests the advantage of introducing pre-trained language models and QA module for the MQG task.
Learning Conditional Invariance through Cycle Consistency
Nov 25, 2021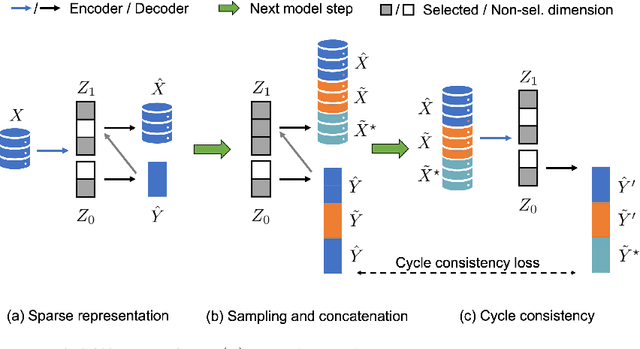
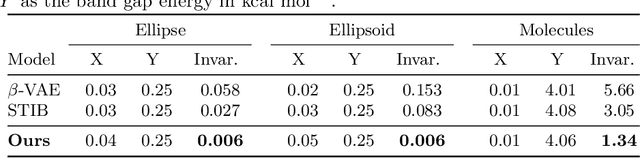
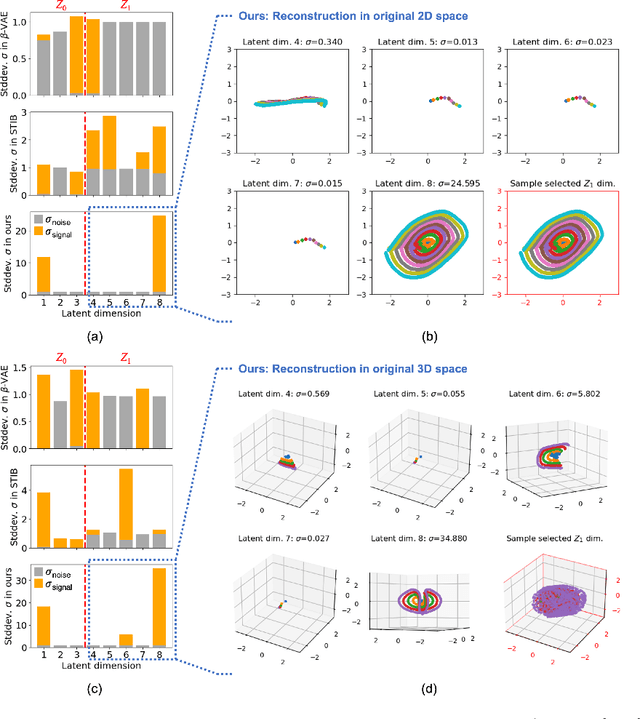
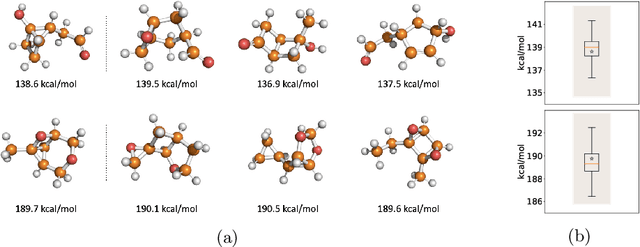
Identifying meaningful and independent factors of variation in a dataset is a challenging learning task frequently addressed by means of deep latent variable models. This task can be viewed as learning symmetry transformations preserving the value of a chosen property along latent dimensions. However, existing approaches exhibit severe drawbacks in enforcing the invariance property in the latent space. We address these shortcomings with a novel approach to cycle consistency. Our method involves two separate latent subspaces for the target property and the remaining input information, respectively. In order to enforce invariance as well as sparsity in the latent space, we incorporate semantic knowledge by using cycle consistency constraints relying on property side information. The proposed method is based on the deep information bottleneck and, in contrast to other approaches, allows using continuous target properties and provides inherent model selection capabilities. We demonstrate on synthetic and molecular data that our approach identifies more meaningful factors which lead to sparser and more interpretable models with improved invariance properties.
Change Detection Meets Visual Question Answering
Dec 12, 2021
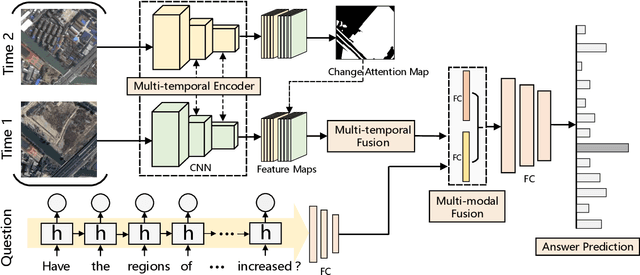

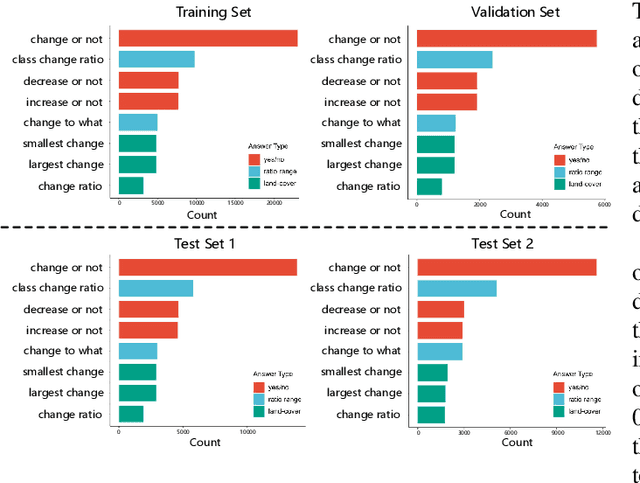
The Earth's surface is continually changing, and identifying changes plays an important role in urban planning and sustainability. Although change detection techniques have been successfully developed for many years, these techniques are still limited to experts and facilitators in related fields. In order to provide every user with flexible access to change information and help them better understand land-cover changes, we introduce a novel task: change detection-based visual question answering (CDVQA) on multi-temporal aerial images. In particular, multi-temporal images can be queried to obtain high level change-based information according to content changes between two input images. We first build a CDVQA dataset including multi-temporal image-question-answer triplets using an automatic question-answer generation method. Then, a baseline CDVQA framework is devised in this work, and it contains four parts: multi-temporal feature encoding, multi-temporal fusion, multi-modal fusion, and answer prediction. In addition, we also introduce a change enhancing module to multi-temporal feature encoding, aiming at incorporating more change-related information. Finally, effects of different backbones and multi-temporal fusion strategies are studied on the performance of CDVQA task. The experimental results provide useful insights for developing better CDVQA models, which are important for future research on this task. We will make our dataset and code publicly available.
Multiagent Evaluation under Incomplete Information
Oct 30, 2019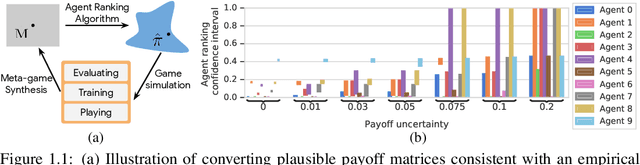
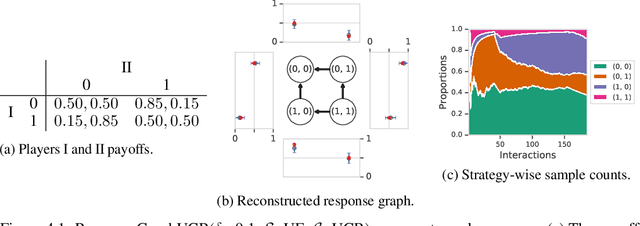
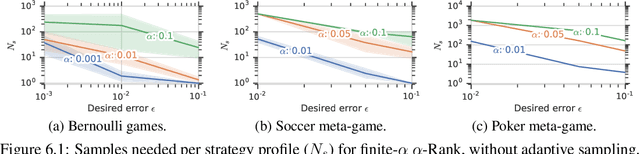
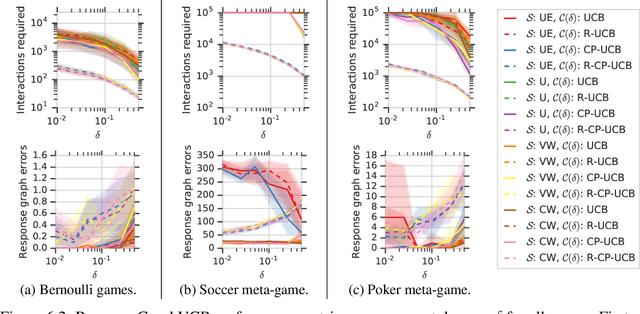
This paper investigates the evaluation of learned multiagent strategies in the incomplete information setting, which plays a critical role in ranking and training of agents. Traditionally, researchers have relied on Elo ratings for this purpose, with recent works also using methods based on Nash equilibria. Unfortunately, Elo is unable to handle intransitive agent interactions, and other techniques are restricted to zero-sum, two-player settings or are limited by the fact that the Nash equilibrium is intractable to compute. Recently, a ranking method called {\alpha}-Rank, relying on a new graph-based game-theoretic solution concept, was shown to tractably apply to general games. However, evaluations based on Elo or {\alpha}-Rank typically assume noise-free game outcomes, despite the data often being collected from noisy simulations, making this assumption unrealistic in practice. This paper investigates multiagent evaluation in the incomplete information regime, involving general-sum many-player games with noisy outcomes. We derive sample complexity guarantees required to confidently rank agents in this setting. We propose adaptive algorithms for accurate ranking, provide correctness and sample complexity guarantees, then introduce a means of connecting uncertainties in noisy match outcomes to uncertainties in rankings. We evaluate the performance of these approaches in several domains, including Bernoulli games, a soccer meta-game, and Kuhn poker.
Image Difference Captioning with Pre-training and Contrastive Learning
Feb 09, 2022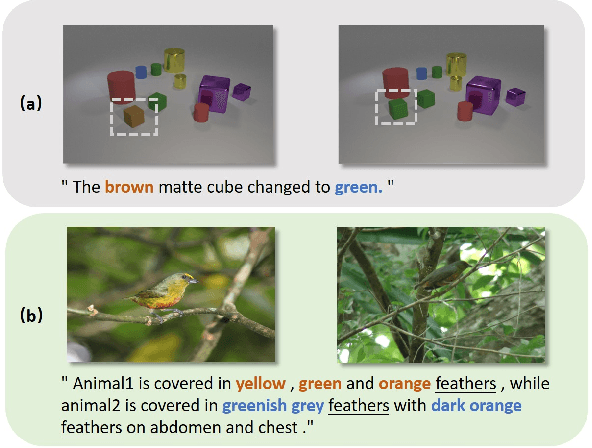
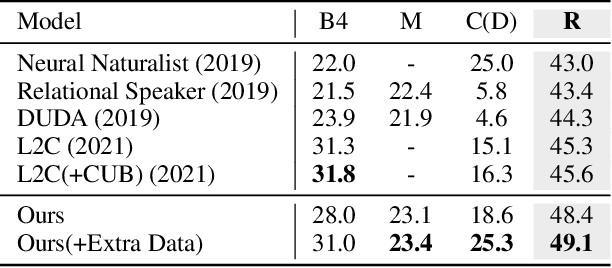
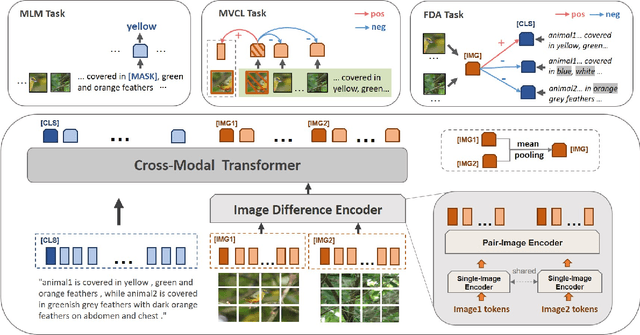
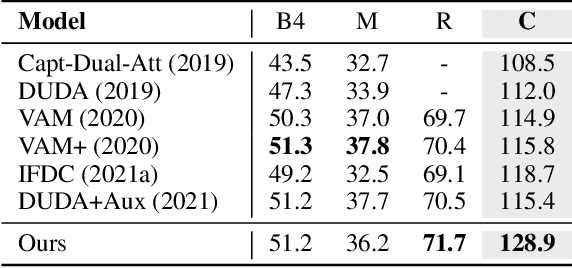
The Image Difference Captioning (IDC) task aims to describe the visual differences between two similar images with natural language. The major challenges of this task lie in two aspects: 1) fine-grained visual differences that require learning stronger vision and language association and 2) high-cost of manual annotations that leads to limited supervised data. To address these challenges, we propose a new modeling framework following the pre-training-finetuning paradigm. Specifically, we design three self-supervised tasks and contrastive learning strategies to align visual differences and text descriptions at a fine-grained level. Moreover, we propose a data expansion strategy to utilize extra cross-task supervision information, such as data for fine-grained image classification, to alleviate the limitation of available supervised IDC data. Extensive experiments on two IDC benchmark datasets, CLEVR-Change and Birds-to-Words, demonstrate the effectiveness of the proposed modeling framework. The codes and models will be released at https://github.com/yaolinli/IDC.
Task-Adaptive Feature Transformer with Semantic Enrichment for Few-Shot Segmentation
Feb 14, 2022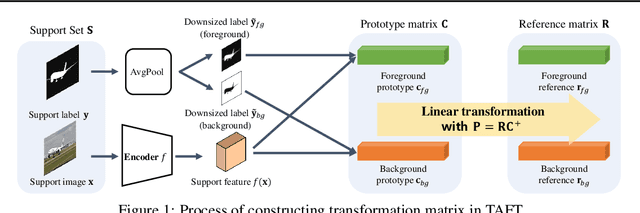
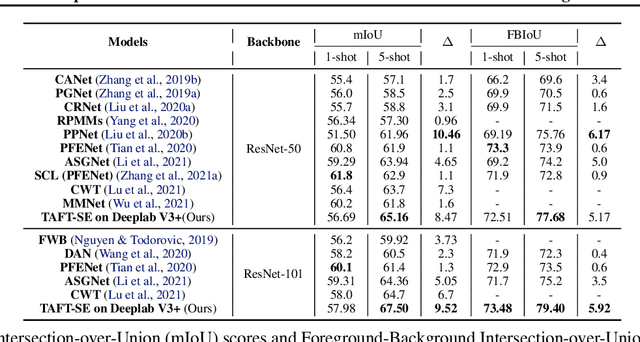
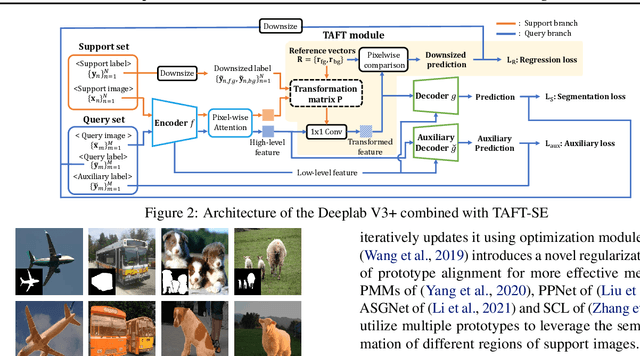
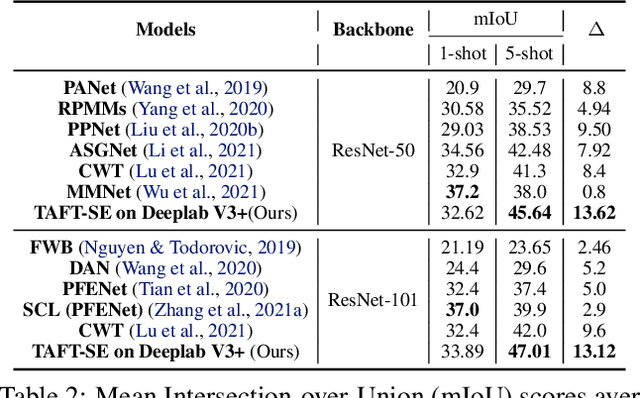
Few-shot learning allows machines to classify novel classes using only a few labeled samples. Recently, few-shot segmentation aiming at semantic segmentation on low sample data has also seen great interest. In this paper, we propose a learnable module that can be placed on top of existing segmentation networks for performing few-shot segmentation. This module, called the task-adaptive feature transformer (TAFT), linearly transforms task-specific high-level features to a set of task agnostic features well-suited to conducting few-shot segmentation. The task-conditioned feature transformation allows an effective utilization of the semantic information in novel classes to generate tight segmentation masks. We also propose a semantic enrichment (SE) module that utilizes a pixel-wise attention module for high-level feature and an auxiliary loss from an auxiliary segmentation network conducting the semantic segmentation for all training classes. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets confirm that the added modules successfully extend the capability of existing segmentators to yield highly competitive few-shot segmentation performances.
Incremental Mining of Frequent Serial Episodes Considering Multiple Occurrence
Feb 03, 2022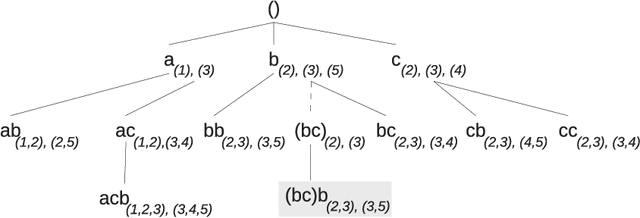
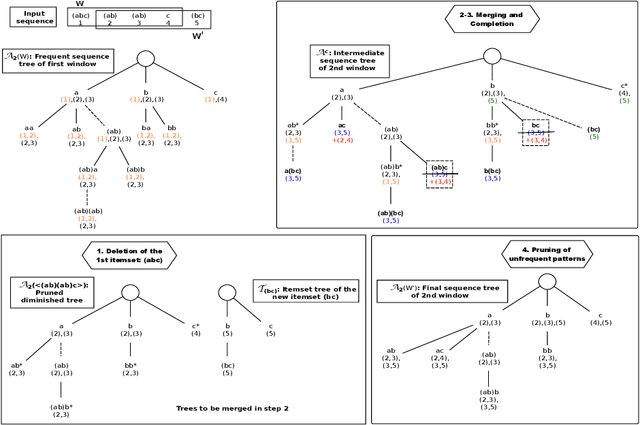
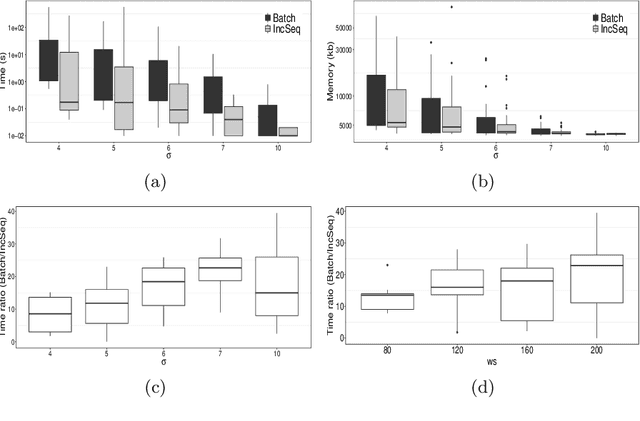

The need to analyze information from streams arises in a variety of applications. One of the fundamental research directions is to mine sequential patterns over data streams. Current studies mine series of items based on the existence of the pattern in transactions but pay no attention to the series of itemsets and their multiple occurrences. The pattern over a window of itemsets stream and their multiple occurrences, however, provides additional capability to recognize the essential characteristics of the patterns and the inter-relationships among them that are unidentifiable by the existing items and existence based studies. In this paper, we study such a new sequential pattern mining problem and propose a corresponding efficient sequential miner with novel strategies to prune search space efficiently. Experiments on both real and synthetic data show the utility of our approach.
Information Extraction of Clinical Trial Eligibility Criteria
Jun 16, 2020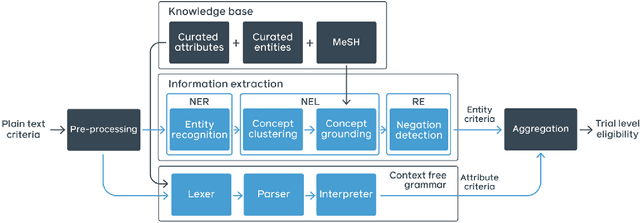
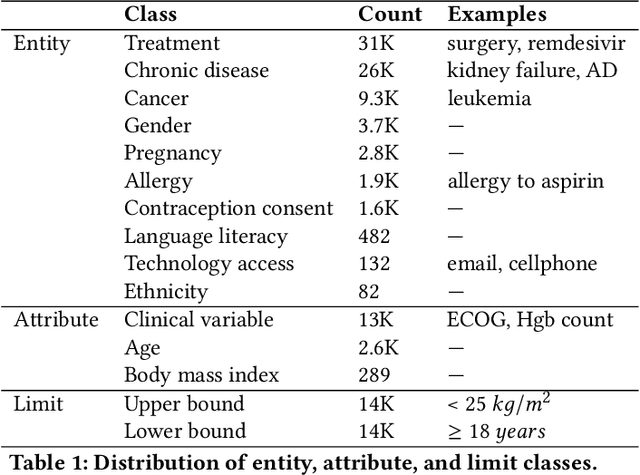
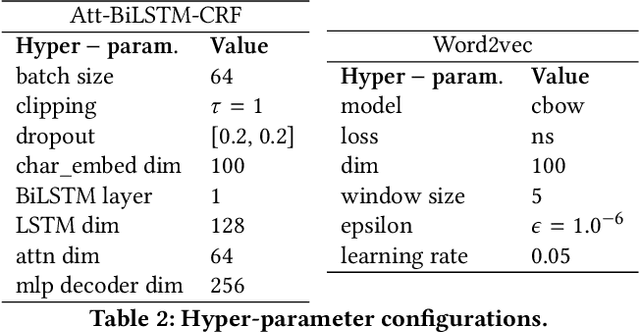
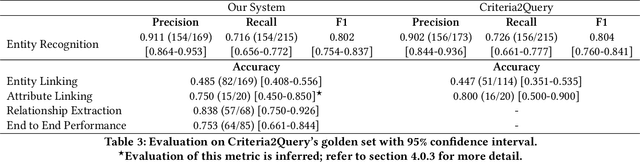
Clinical trials predicate subject eligibility on a diversity of criteria ranging from patient demographics to food allergies. Trials post their requirements as semantically complex, unstructured free-text. Formalizing trial criteria to a computer-interpretable syntax would facilitate eligibility determination. In this paper, we investigate an information extraction (IE) approach for grounding criteria from trials in ClinicalTrials(dot)gov to a shared knowledge base. We frame the problem as a novel knowledge base population task, and implement a solution combining machine learning and context free grammar. To our knowledge, this work is the first criteria extraction system to apply attention-based conditional random field architecture for named entity recognition (NER), and word2vec embedding clustering for named entity linking (NEL). We release the resources and core components of our system on GitHub at https://github.com/facebookresearch/Clinical-Trial-Parser. Finally, we report our per module and end to end performances; we conclude that our system is competitive with Criteria2Query, which we view as the current state-of-the-art in criteria extraction.