 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding
Mar 02, 2022

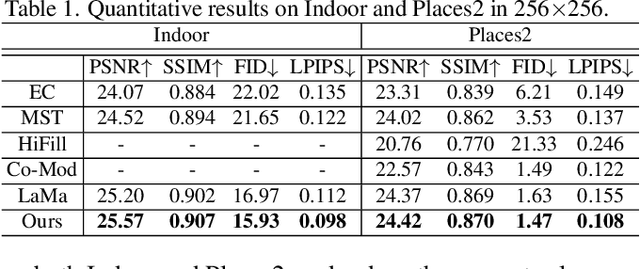
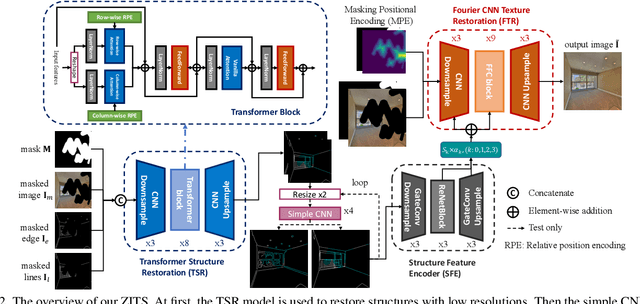
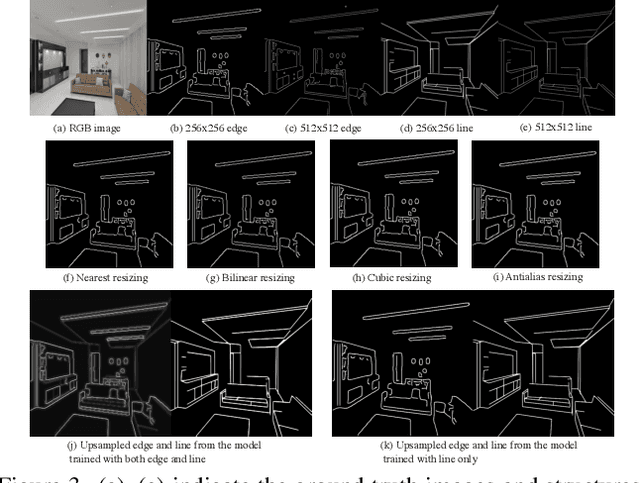
Image inpainting has made significant advances in recent years. However, it is still challenging to recover corrupted images with both vivid textures and reasonable structures. Some specific methods only tackle regular textures while losing holistic structures due to the limited receptive fields of convolutional neural networks (CNNs). On the other hand, attention-based models can learn better long-range dependency for the structure recovery, but they are limited by the heavy computation for inference with large image sizes. To address these issues, we propose to leverage an additional structure restorer to facilitate the image inpainting incrementally. The proposed model restores holistic image structures with a powerful attention-based transformer model in a fixed low-resolution sketch space. Such a grayscale space is easy to be upsampled to larger scales to convey correct structural information. Our structure restorer can be integrated with other pretrained inpainting models efficiently with the zero-initialized residual addition. Furthermore, a masking positional encoding strategy is utilized to improve the performance with large irregular masks. Extensive experiments on various datasets validate the efficacy of our model compared with other competitors. Our codes are released in https://github.com/DQiaole/ZITS_inpainting.
NICE-SLAM: Neural Implicit Scalable Encoding for SLAM
Dec 22, 2021
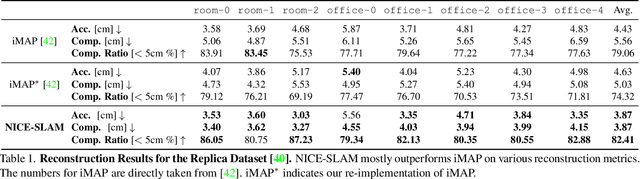
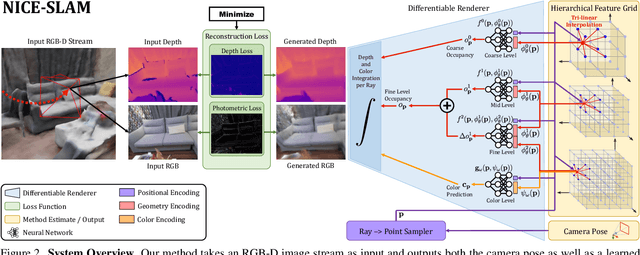
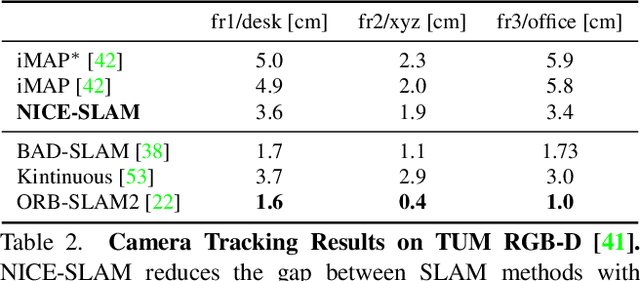
Neural implicit representations have recently shown encouraging results in various domains, including promising progress in simultaneous localization and mapping (SLAM). Nevertheless, existing methods produce over-smoothed scene reconstructions and have difficulty scaling up to large scenes. These limitations are mainly due to their simple fully-connected network architecture that does not incorporate local information in the observations. In this paper, we present NICE-SLAM, a dense SLAM system that incorporates multi-level local information by introducing a hierarchical scene representation. Optimizing this representation with pre-trained geometric priors enables detailed reconstruction on large indoor scenes. Compared to recent neural implicit SLAM systems, our approach is more scalable, efficient, and robust. Experiments on five challenging datasets demonstrate competitive results of NICE-SLAM in both mapping and tracking quality.
VGAER: graph neural network reconstruction based community detection
Jan 08, 2022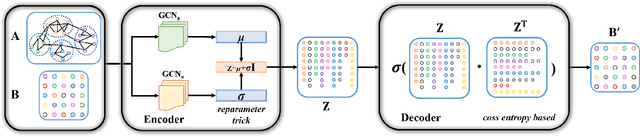
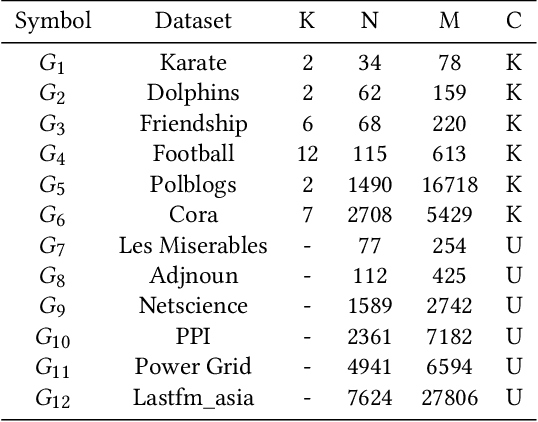
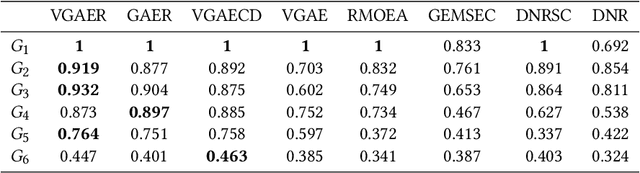
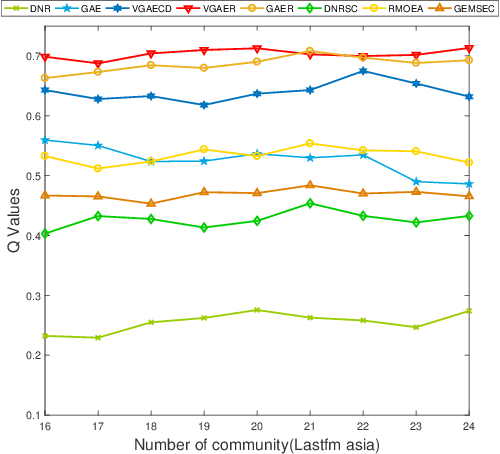
Community detection is a fundamental and important issue in network science, but there are only a few community detection algorithms based on graph neural networks, among which unsupervised algorithms are almost blank. By fusing the high-order modularity information with network features, this paper proposes a Variational Graph AutoEncoder Reconstruction based community detection VGAER for the first time, and gives its non-probabilistic version. They do not need any prior information. We have carefully designed corresponding input features, decoder, and downstream tasks based on the community detection task and these designs are concise, natural, and perform well (NMI values under our design are improved by 59.1% - 565.9%). Based on a series of experiments with wide range of datasets and advanced methods, VGAER has achieved superior performance and shows strong competitiveness and potential with a simpler design. Finally, we report the results of algorithm convergence analysis and t-SNE visualization, which clearly depicted the stable performance and powerful network modularity ability of VGAER. Our codes are available at https://github.com/qcydm/VGAER.
Training Characteristic Functions with Reinforcement Learning: XAI-methods play Connect Four
Feb 25, 2022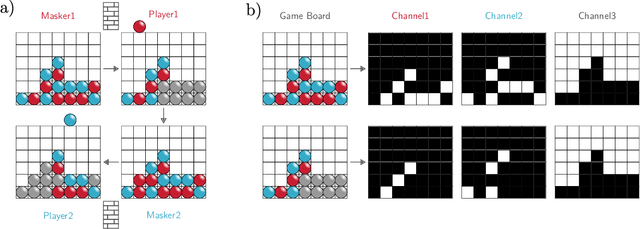
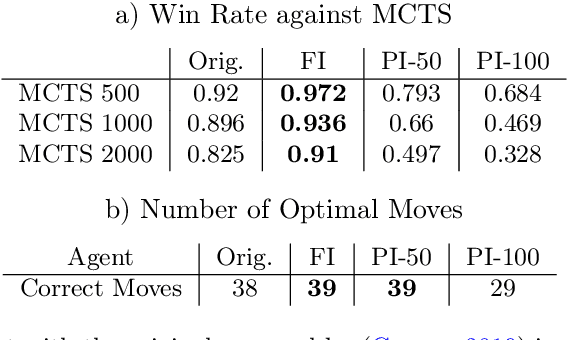

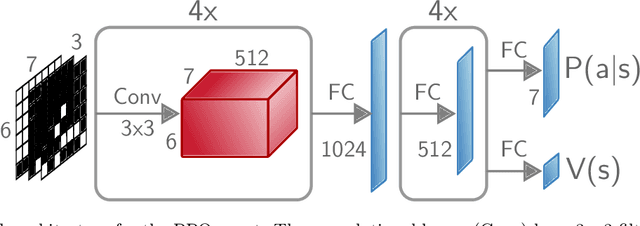
One of the goals of Explainable AI (XAI) is to determine which input components were relevant for a classifier decision. This is commonly know as saliency attribution. Characteristic functions (from cooperative game theory) are able to evaluate partial inputs and form the basis for theoretically "fair" attribution methods like Shapley values. Given only a standard classifier function, it is unclear how partial input should be realised. Instead, most XAI-methods for black-box classifiers like neural networks consider counterfactual inputs that generally lie off-manifold. This makes them hard to evaluate and easy to manipulate. We propose a setup to directly train characteristic functions in the form of neural networks to play simple two-player games. We apply this to the game of Connect Four by randomly hiding colour information from our agents during training. This has three advantages for comparing XAI-methods: It alleviates the ambiguity about how to realise partial input, makes off-manifold evaluation unnecessary and allows us to compare the methods by letting them play against each other.
Deep Understanding based Multi-Document Machine Reading Comprehension
Feb 25, 2022
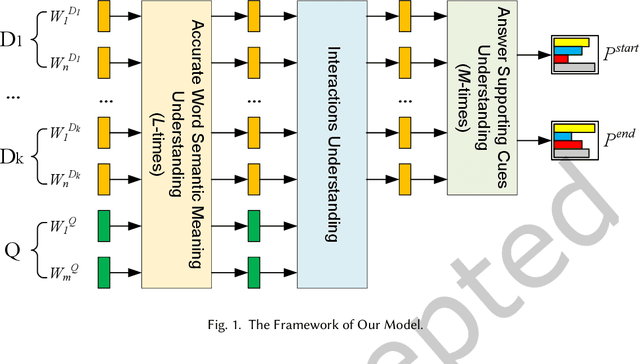
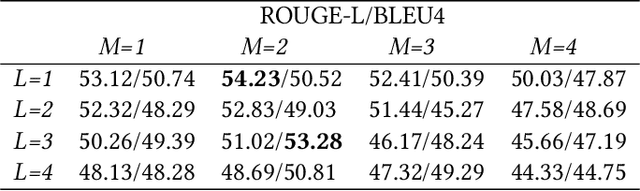
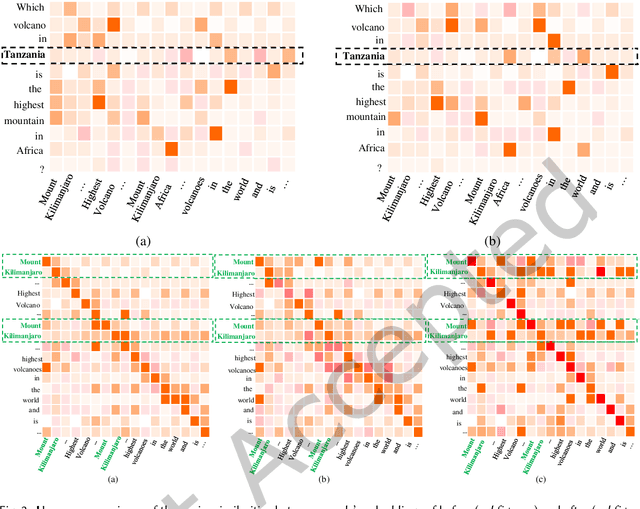
Most existing multi-document machine reading comprehension models mainly focus on understanding the interactions between the input question and documents, but ignore following two kinds of understandings. First, to understand the semantic meaning of words in the input question and documents from the perspective of each other. Second, to understand the supporting cues for a correct answer from the perspective of intra-document and inter-documents. Ignoring these two kinds of important understandings would make the models oversee some important information that may be helpful for inding correct answers. To overcome this deiciency, we propose a deep understanding based model for multi-document machine reading comprehension. It has three cascaded deep understanding modules which are designed to understand the accurate semantic meaning of words, the interactions between the input question and documents, and the supporting cues for the correct answer. We evaluate our model on two large scale benchmark datasets, namely TriviaQA Web and DuReader. Extensive experiments show that our model achieves state-of-the-art results on both datasets.
Robust Table Detection and Structure Recognition from Heterogeneous Document Images
Mar 17, 2022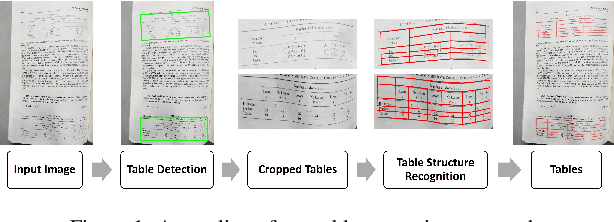
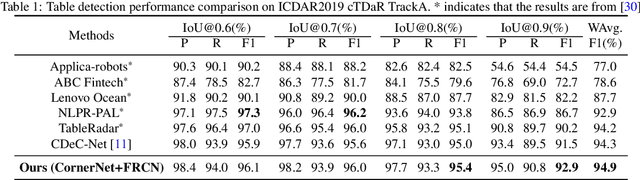
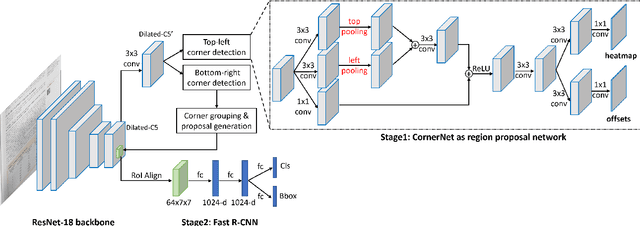

We introduce a new table detection and structure recognition approach named RobusTabNet to detect the boundaries of tables and reconstruct the cellular structure of the table from heterogeneous document images. For table detection, we propose to use CornerNet as a new region proposal network to generate higher quality table proposals for Faster R-CNN, which has significantly improved the localization accuracy of Faster R-CNN for table detection. Consequently, our table detection approach achieves state-of-the-art performance on three public table detection benchmarks, namely cTDaR TrackA, PubLayNet and IIIT-AR-13K, by only using a lightweight ResNet-18 backbone network. Furthermore, we propose a new split-and-merge based table structure recognition approach, in which a novel spatial CNN based separation line prediction module is proposed to split each detected table into a grid of cells, and a Grid CNN based cell merging module is applied to recover the spanning cells. As the spatial CNN module can effectively propagate contextual information across the whole table image, our table structure recognizer can robustly recognize tables with large blank spaces and geometrically distorted (even curved) tables. Thanks to these two techniques, our table structure recognition approach achieves state-of-the-art performance on three public benchmarks, including SciTSR, PubTabNet and cTDaR TrackB. Moreover, we have further demonstrated the advantages of our approach in recognizing tables with complex structures, large blank spaces, empty or spanning cells as well as geometrically distorted or even curved tables on a more challenging in-house dataset.
Robust Seatbelt Detection and Usage Recognition for Driver Monitoring Systems
Mar 02, 2022
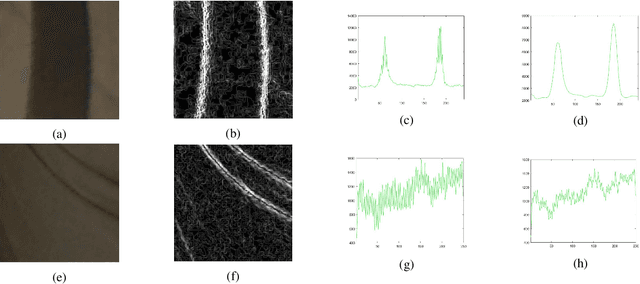
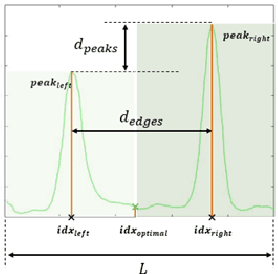
Wearing a seatbelt appropriately while driving can reduce serious crash-related injuries or deaths by about half. However, current seatbelt reminder system has multiple shortcomings, such as can be easily fooled by a "Seatbelt Warning Stopper", and cannot recognize incorrect usages for example seating in front of a buckled seatbelt or wearing a seatbelt under the arm. General seatbelt usage recognition has many challenges, to name a few, lacking of color information in Infrared (IR) cameras, strong distortion caused by wide Field of View (FoV) fisheye lens, low contrast between belt and its background, occlusions caused by hands or hair, and imaging blurry. In this paper, we introduce a novel general seatbelt detection and usage recognition framework to resolve the above challenges. Our method consists of three components: a local predictor, a global assembler, and a shape modeling process. Our approach can be applied to the driver in the Driver Monitoring System (DMS) or general passengers in the Occupant Monitoring System (OMS) for various camera modalities. Experiment results on both DMS and OMS are provided to demonstrate the accuracy and robustness of the proposed approach.
MetAug: Contrastive Learning via Meta Feature Augmentation
Mar 10, 2022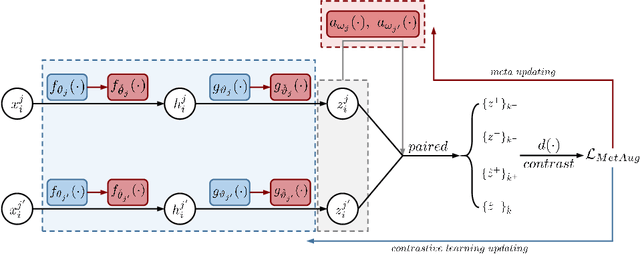
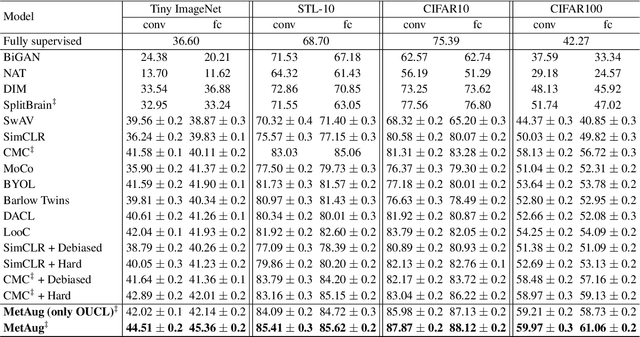
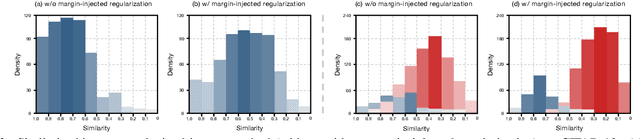
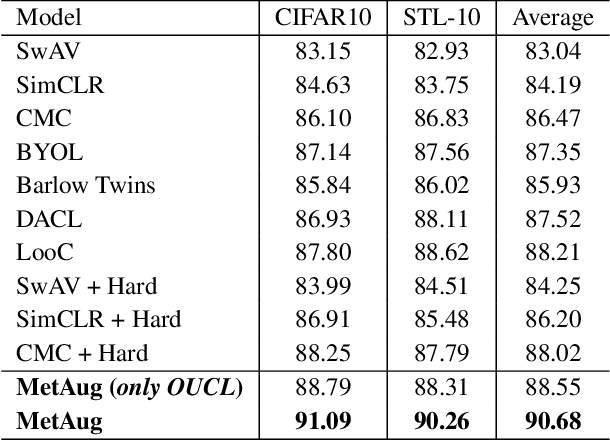
What matters for contrastive learning? We argue that contrastive learning heavily relies on informative features, or "hard" (positive or negative) features. Early works include more informative features by applying complex data augmentations and large batch size or memory bank, and recent works design elaborate sampling approaches to explore informative features. The key challenge toward exploring such features is that the source multi-view data is generated by applying random data augmentations, making it infeasible to always add useful information in the augmented data. Consequently, the informativeness of features learned from such augmented data is limited. In response, we propose to directly augment the features in latent space, thereby learning discriminative representations without a large amount of input data. We perform a meta learning technique to build the augmentation generator that updates its network parameters by considering the performance of the encoder. However, insufficient input data may lead the encoder to learn collapsed features and therefore malfunction the augmentation generator. A new margin-injected regularization is further added in the objective function to avoid the encoder learning a degenerate mapping. To contrast all features in one gradient back-propagation step, we adopt the proposed optimization-driven unified contrastive loss instead of the conventional contrastive loss. Empirically, our method achieves state-of-the-art results on several benchmark datasets.
Information-Theoretic Bounds on Transfer Generalization Gap Based on Jensen-Shannon Divergence
Oct 13, 2020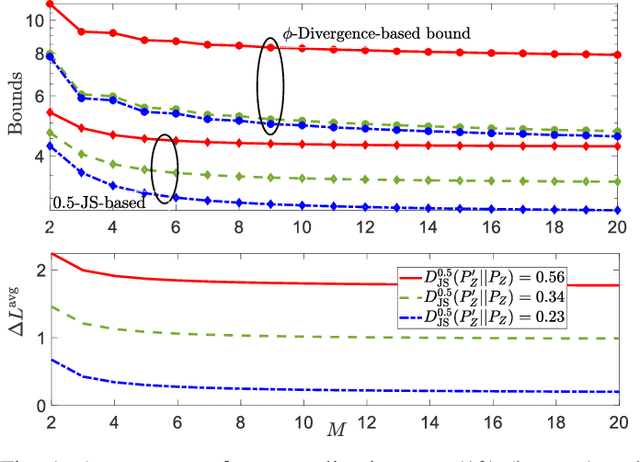
In transfer learning, training and testing data sets are drawn from different data distributions. The transfer generalization gap is the difference between the population loss on the target data distribution and the training loss. The training data set generally includes data drawn from both source and target distributions. This work presents novel information-theoretic upper bounds on the average transfer generalization gap that capture (i) the domain shift between the target data distribution $P'_Z$ and and the source distribution $P_Z$ through Nielsen's family of $\alpha$-Jensen-Shannon (JS) divergences $D_{JS}^{\alpha}(P'_Z || P_Z)$; and (ii) the sensitivity of the transfer learner output $W$ to each individual sample of the data set $Z_i$ via the mutual information $I(W;Z_i)$. The $\alpha$-JS divergence is bounded even when the support of $P_Z$ is not included in that of $P'_Z$ . This contrasts the Kullback- Leibler (KL) divergence $D_{KL}(P_Z||P'_Z)$-based bounds of Wu et al. [1], which are vacuous under this assumption. Moreover, the obtained bounds hold for unbounded loss functions with bounded cumulant generating functions, unlike the $\phi$-divergence based bound of Wu et al. We also obtain new upper bounds on the average transfer excess risk in terms of the $\alpha$-JS divergence for empirical weighted risk minimization (EWRM), which minimizes the weighted average training losses over source and target data sets. Finally, we provide a numerical example to illustrate the merits of the introduced bounds.
Leveraging Pre-trained BERT for Audio Captioning
Mar 06, 2022
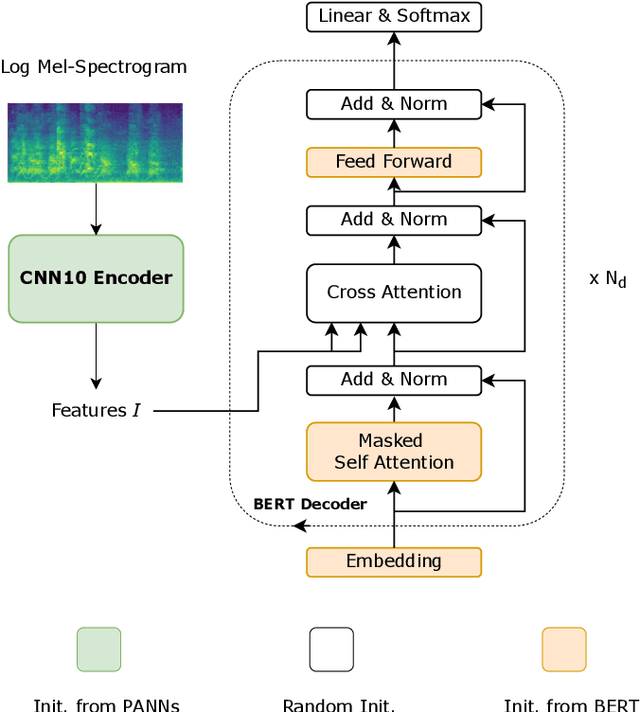
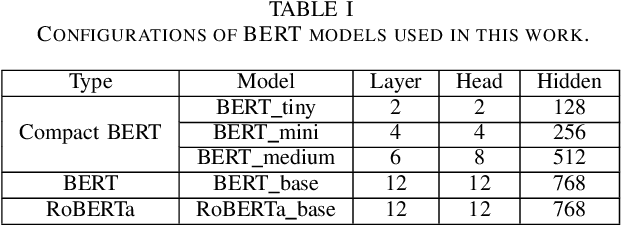
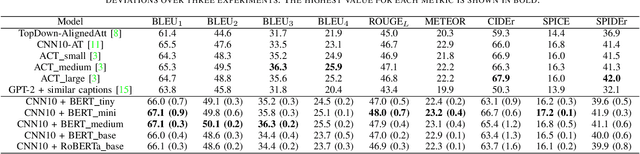
Audio captioning aims at using natural language to describe the content of an audio clip. Existing audio captioning systems are generally based on an encoder-decoder architecture, in which acoustic information is extracted by an audio encoder and then a language decoder is used to generate the captions. Training an audio captioning system often encounters the problem of data scarcity. Transferring knowledge from pre-trained audio models such as Pre-trained Audio Neural Networks (PANNs) have recently emerged as a useful method to mitigate this issue. However, there is less attention on exploiting pre-trained language models for the decoder, compared with the encoder. BERT is a pre-trained language model that has been extensively used in Natural Language Processing (NLP) tasks. Nevertheless, the potential of BERT as the language decoder for audio captioning has not been investigated. In this study, we demonstrate the efficacy of the pre-trained BERT model for audio captioning. Specifically, we apply PANNs as the encoder and initialize the decoder from the public pre-trained BERT models. We conduct an empirical study on the use of these BERT models for the decoder in the audio captioning model. Our models achieve competitive results with the existing audio captioning methods on the AudioCaps dataset.