 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Byzantine-Robust Decentralized Learning via Self-Centered Clipping
Feb 03, 2022
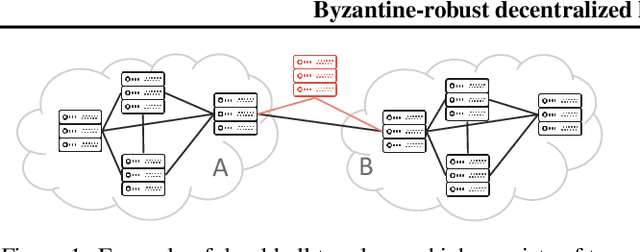
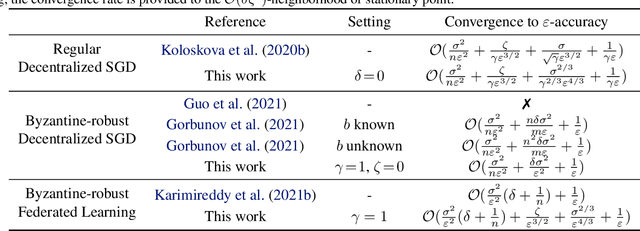
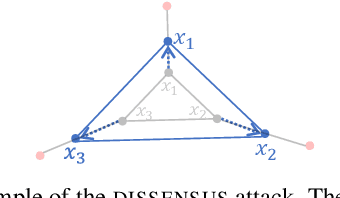
In this paper, we study the challenging task of Byzantine-robust decentralized training on arbitrary communication graphs. Unlike federated learning where workers communicate through a server, workers in the decentralized environment can only talk to their neighbors, making it harder to reach consensus. We identify a novel dissensus attack in which few malicious nodes can take advantage of information bottlenecks in the topology to poison the collaboration. To address these issues, we propose a Self-Centered Clipping (SCClip) algorithm for Byzantine-robust consensus and optimization, which is the first to provably converge to a $O(\delta_{\max}\zeta^2/\gamma^2)$ neighborhood of the stationary point for non-convex objectives under standard assumptions. Finally, we demonstrate the encouraging empirical performance of SCClip under a large number of attacks.
ConAM: Confidence Attention Module for Convolutional Neural Networks
Oct 27, 2021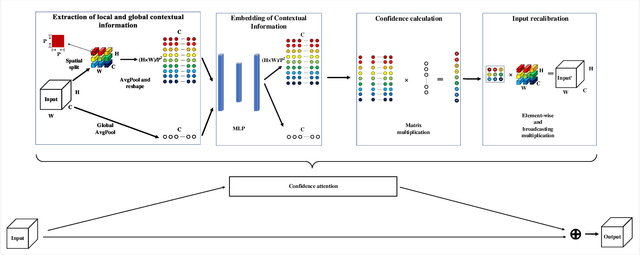

The so-called ``attention'' is an efficient mechanism to improve the performance of convolutional neural networks. It uses contextual information to recalibrate the input to strengthen the propagation of informative features. However, the majority of the attention mechanisms only consider either local or global contextual information, which is singular to extract features. Moreover, many existing mechanisms directly use the contextual information to recalibrate the input, which unilaterally enhances the propagation of the informative features, but does not suppress the useless ones. This paper proposes a new attention mechanism module based on the correlation between local and global contextual information and we name this correlation as confidence. The novel attention mechanism extracts the local and global contextual information simultaneously, and calculates the confidence between them, then uses this confidence to recalibrate the input pixels. The extraction of local and global contextual information increases the diversity of features. The recalibration with confidence suppresses useless information while enhancing the informative one with fewer parameters. We use CIFAR-10 and CIFAR-100 in our experiments and explore the performance of our method's components by sufficient ablation studies. Finally, we compare our method with a various state-of-the-art convolutional neural networks and the results show that our method completely surpasses these models. We implement ConAM with the Python library, Pytorch, and the code and models will be publicly available.
Optimal Correlated Equilibria in General-Sum Extensive-Form Games: Fixed-Parameter Algorithms, Hardness, and Two-Sided Column-Generation
Mar 14, 2022
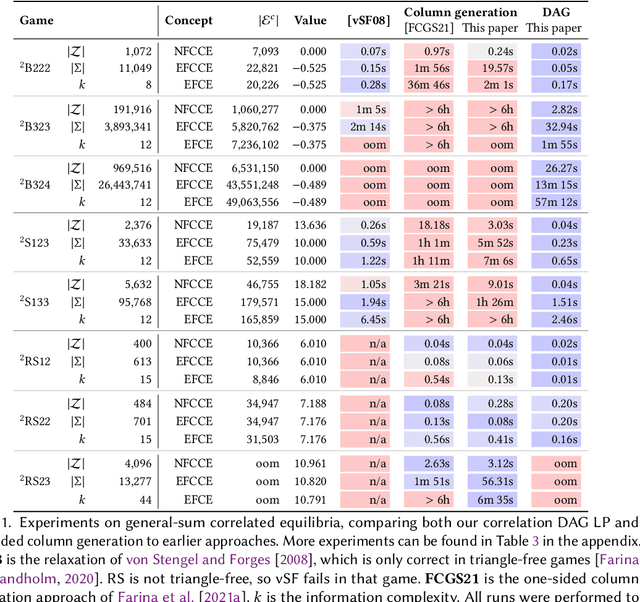
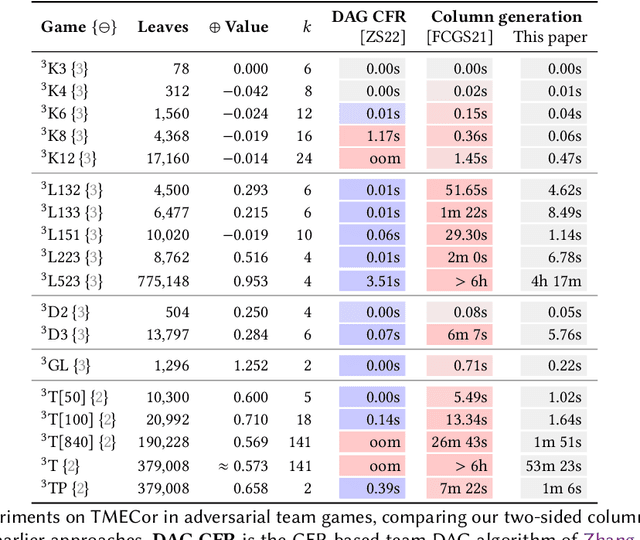
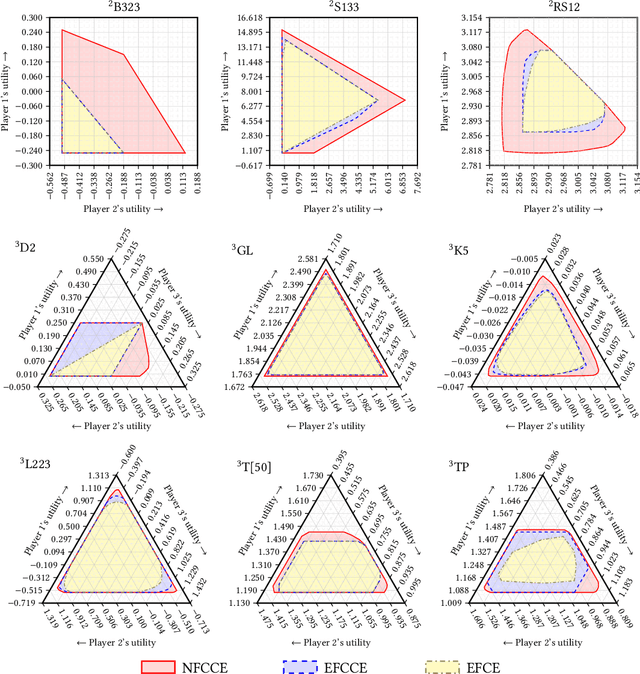
We study the problem of finding optimal correlated equilibria of various sorts: normal-form coarse correlated equilibrium (NFCCE), extensive-form coarse correlated equilibrium (EFCCE), and extensive-form correlated equilibrium (EFCE). This is NP-hard in the general case and has been studied in special cases, most notably triangle-free games, which include all two-player games with public chance moves. However, the general case is not well understood, and algorithms usually scale poorly. First, we introduce the correlation DAG, a representation of the space of correlated strategies whose size is dependent on the specific solution concept. It extends the team belief DAG of Zhang et al. to general-sum games. For each of the three solution concepts, its size depends exponentially only on a parameter related to the game's information structure. We also prove a fundamental complexity gap: while our size bounds for NFCCE are similar to those achieved in the case of team games by Zhang et al., this is impossible to achieve for the other two concepts under standard complexity assumptions. Second, we propose a two-sided column generation approach to compute optimal correlated strategies. Our algorithm improves upon the one-sided approach of Farina et al. by means of a new decomposition of correlated strategies which allows players to re-optimize their sequence-form strategies with respect to correlation plans which were previously added to the support. Our techniques outperform the prior state of the art for computing optimal general-sum correlated equilibria. For team games, the two-sided column generation approach vastly outperforms standard column generation approaches, making it the state of the art algorithm when the parameter is large. Along the way we also introduce two new benchmark games: a trick-taking game that emulates the endgame phase of the card game bridge, and a ride-sharing game.
Conditional Drums Generation using Compound Word Representations
Feb 21, 2022
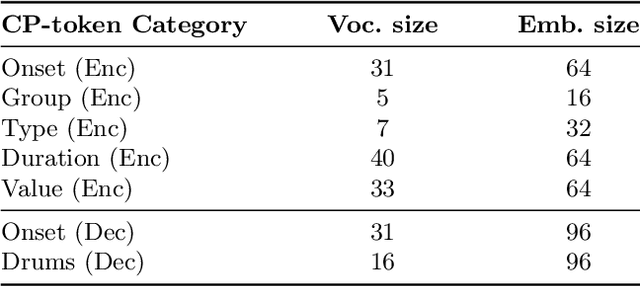
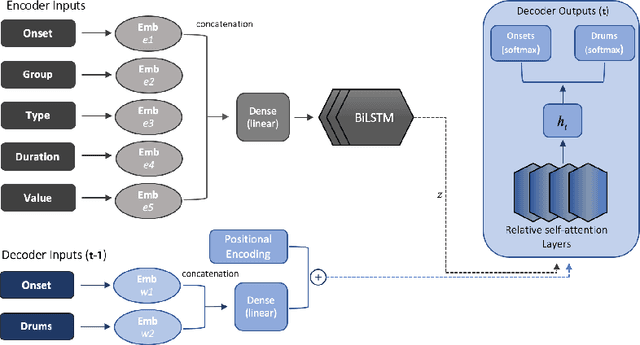
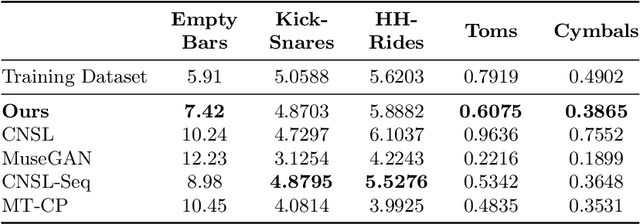
The field of automatic music composition has seen great progress in recent years, specifically with the invention of transformer-based architectures. When using any deep learning model which considers music as a sequence of events with multiple complex dependencies, the selection of a proper data representation is crucial. In this paper, we tackle the task of conditional drums generation using a novel data encoding scheme inspired by the Compound Word representation, a tokenization process of sequential data. Therefore, we present a sequence-to-sequence architecture where a Bidirectional Long short-term memory (BiLSTM) Encoder receives information about the conditioning parameters (i.e., accompanying tracks and musical attributes), while a Transformer-based Decoder with relative global attention produces the generated drum sequences. We conducted experiments to thoroughly compare the effectiveness of our method to several baselines. Quantitative evaluation shows that our model is able to generate drums sequences that have similar statistical distributions and characteristics to the training corpus. These features include syncopation, compression ratio, and symmetry among others. We also verified, through a listening test, that generated drum sequences sound pleasant, natural and coherent while they "groove" with the given accompaniment.
LFW-Beautified: A Dataset of Face Images with Beautification and Augmented Reality Filters
Mar 11, 2022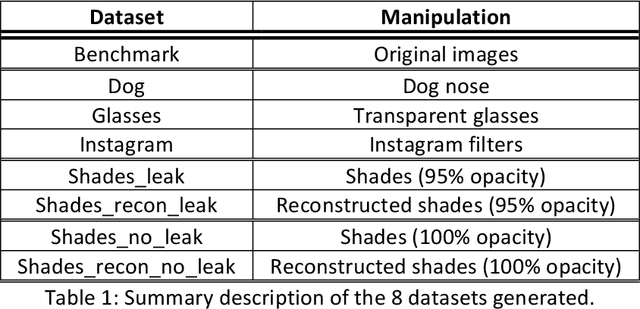
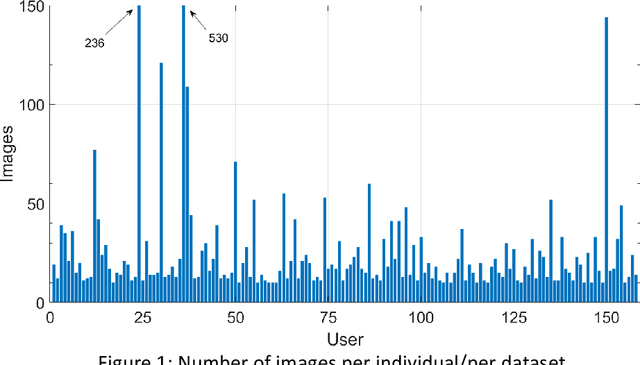


Selfie images enjoy huge popularity in social media. The same platforms centered around sharing this type of images offer filters to beautify them or incorporate augmented reality effects. Studies suggests that filtered images attract more views and engagement. Selfie images are also in increasing use in security applications due to mobiles becoming data hubs for many transactions. Also, video conference applications, boomed during the pandemic, include such filters. Such filters may destroy biometric features that would allow person recognition or even detection of the face itself, even if such commodity applications are not necessarily used to compromise facial systems. This could also affect subsequent investigations like crimes in social media, where automatic analysis is usually necessary given the amount of information posted in social sites or stored in devices or cloud repositories. To help in counteracting such issues, we contribute with a database of facial images that includes several manipulations. It includes image enhancement filters (which mostly modify contrast and lightning) and augmented reality filters that incorporate items like animal noses or glasses. Additionally, images with sunglasses are processed with a reconstruction network trained to learn to reverse such modifications. This is because obfuscating the eye region has been observed in the literature to have the highest impact on the accuracy of face detection or recognition. We start from the popular Labeled Faces in the Wild (LFW) database, to which we apply different modifications, generating 8 datasets. Each dataset contains 4,324 images of size 64 x 64, with a total of 34,592 images. The use of a public and widely employed face dataset allows for replication and comparison. The created database is available at https://github.com/HalmstadUniversityBiometrics/LFW-Beautified
Modeling and hexahedral meshing of arterial networks from centerlines
Jan 20, 2022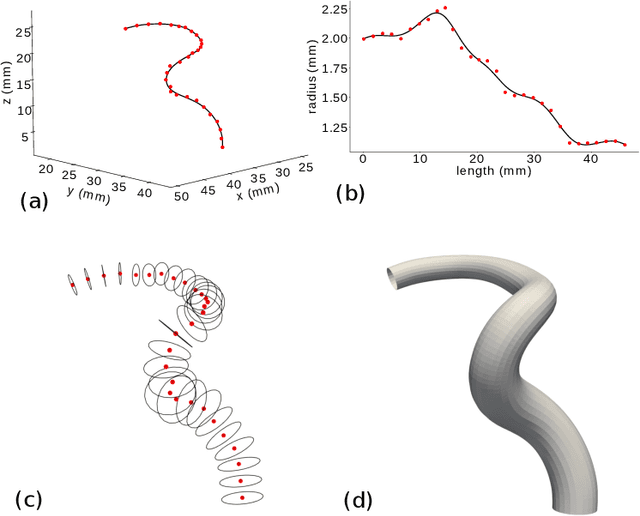

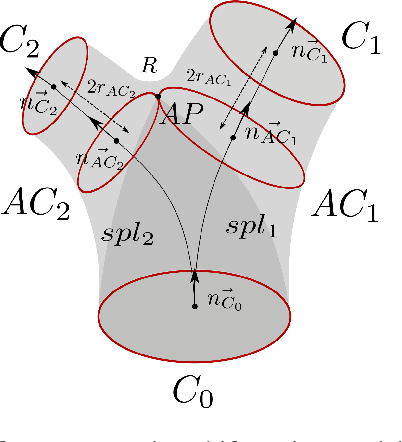
Computational fluid dynamics (CFD) simulation provides valuable information on blood flow from the vascular geometry. However, it requires to extract accurate models of arteries from low resolution medical images, which remains challenging. Centerline-based representation is widely used to model large vascular networks with small vessels, as it enables manual editing and encodes the topological information. In this work, we propose an automatic method to generate an hexahedral mesh suitable for CFD directly from centerlines. The proposed method is an improvement of the state-of-the-art in terms of robustness, mesh quality and reproductibility. Both the modeling and meshing tasks are addressed. A new vessel model based on penalized splines is proposed to overcome the limitations inherent to the centerline representation, such as noise and sparsity. Bifurcations are reconstructed using a physiologically accurate parametric model that we extended to planar n-furcations. Finally, a volume mesh with structured, hexahedral and flow oriented cells is produced from the proposed vascular network model. The proposed method offers a better robustness and mesh quality than the state-of-the-art methods. As it combines both modeling and meshing techniques, it can be applied to edit the geometry and topology of vascular models effortlessly to study the impact on hemodynamics. We demonstrate the efficiency of our method by entirely meshing a dataset of 60 cerebral vascular networks. 92\% of the vessels and 83\% of the bifurcations where mesh without defects needing manual intervention, despite the challenging aspect of the input data. The source code will be released publicly.
A Data-Augmentation Is Worth A Thousand Samples: Exact Quantification From Analytical Augmented Sample Moments
Feb 16, 2022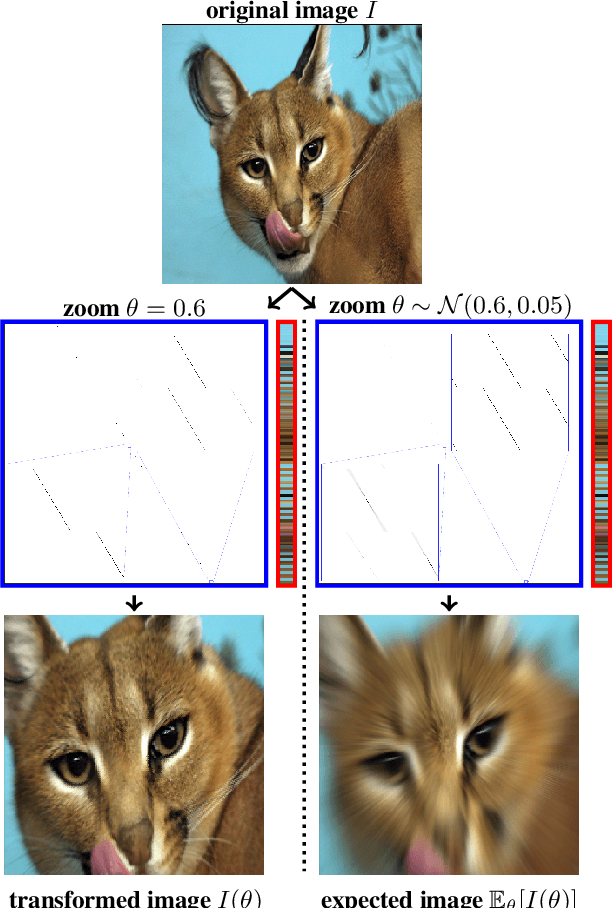
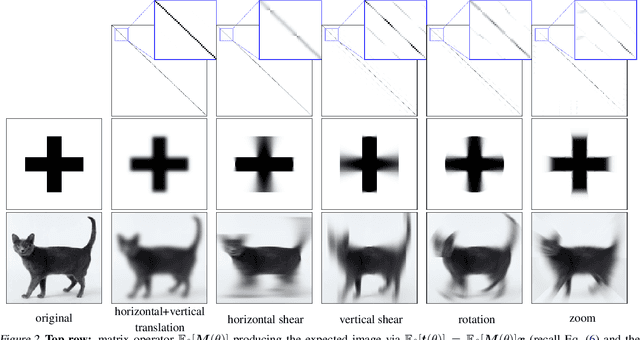
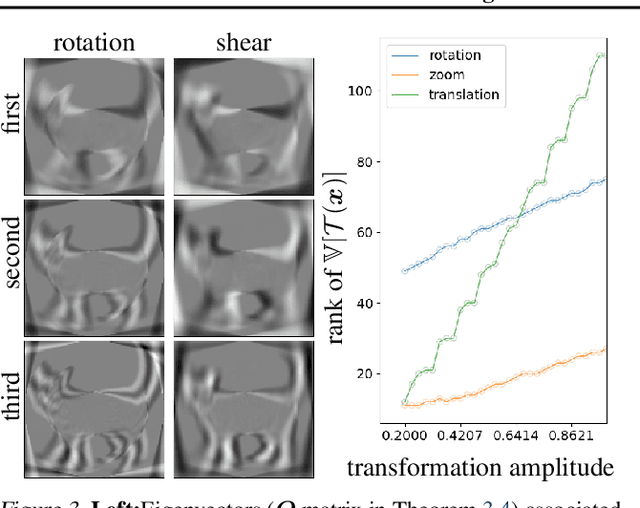
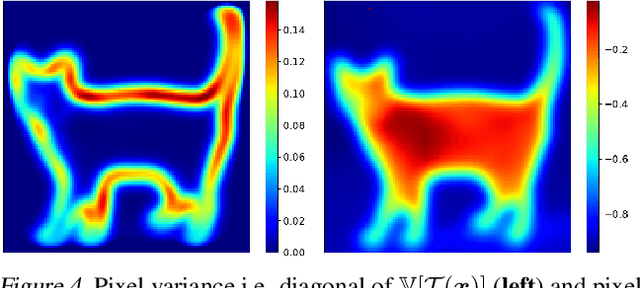
Data-Augmentation (DA) is known to improve performance across tasks and datasets. We propose a method to theoretically analyze the effect of DA and study questions such as: how many augmented samples are needed to correctly estimate the information encoded by that DA? How does the augmentation policy impact the final parameters of a model? We derive several quantities in close-form, such as the expectation and variance of an image, loss, and model's output under a given DA distribution. Those derivations open new avenues to quantify the benefits and limitations of DA. For example, we show that common DAs require tens of thousands of samples for the loss at hand to be correctly estimated and for the model training to converge. We show that for a training loss to be stable under DA sampling, the model's saliency map (gradient of the loss with respect to the model's input) must align with the smallest eigenvector of the sample variance under the considered DA augmentation, hinting at a possible explanation on why models tend to shift their focus from edges to textures.
Symbol repetition in interstellar communications: methods and observations
Feb 25, 2022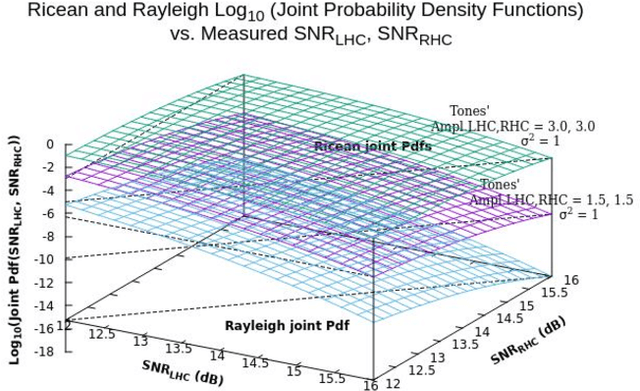
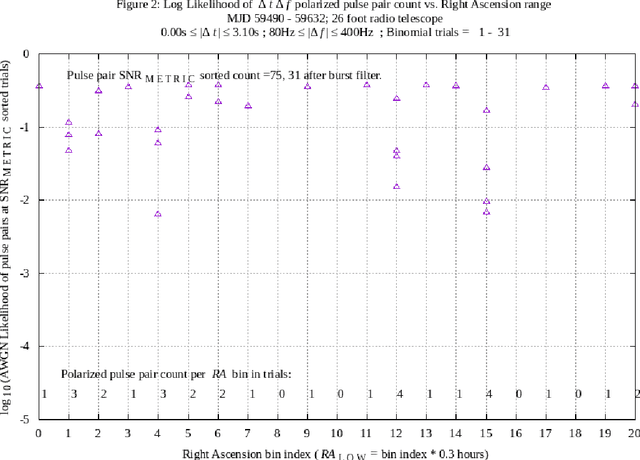
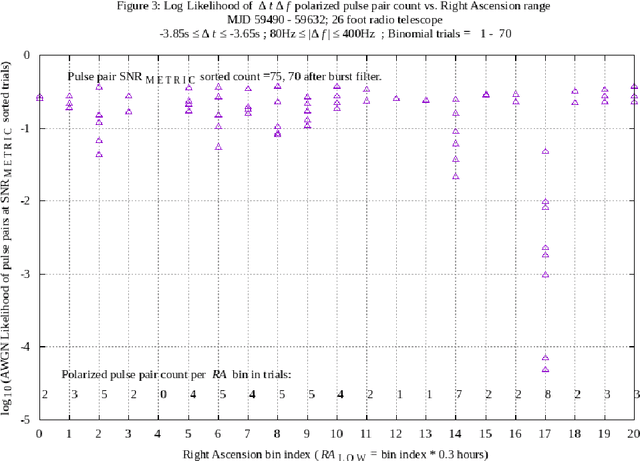
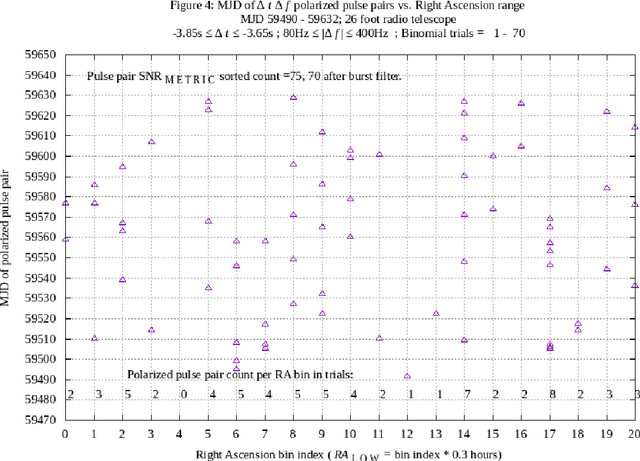
Discoverable interstellar communication signals are expected to exhibit al least one signal characteristic clearly distinct from random noise. A hypothesis is proposed that radio telescope received signals may contain transmitted delta-t delta-f opposite circular polarized pulse pairs, conveying a combination of information content and discovery methods, including symbol repetition. Hypothetical signals are experimentally measured using a 26 foot diameter radio telescope, a chosen matched filter receiver, and machine post processing system. Measurements are expected to present likelihoods explained by an Additive White Gaussian Noise model, augmented to reduce radio frequency interference. In addition, measurements are expected to present no significant differences across a population of Right Ascension ranges, during long duration experiments. The hypothesis and experimental methods described in this paper are based on multiple radio telescope delta-t delta-f polarized pulse pair experiments previously reported. (ref. arXiv:2105.03727, arXiv:2106.10168). In the current work, a Right Ascension filter spans twenty-one 0.3 hour Right Ascension bins over a 0 to 6.3 hr range, during a 143 day experiment. Apparent symbol repetition is measured and analyzed. The 5.25 plus or minus 0.15 hr Right Ascension, -7.6 degree plus or minus 1 degree Declination celestial direction has been associated with anomalous observations in previous work, and continues to present anomalies, having unknown cause.
Topic Driven Adaptive Network for Cross-Domain Sentiment Classification
Nov 28, 2021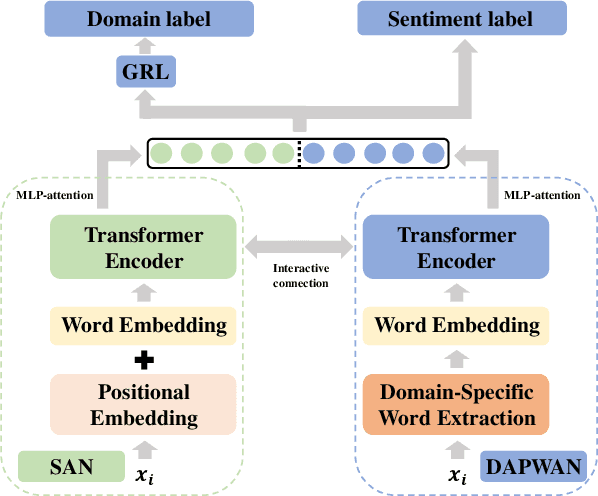
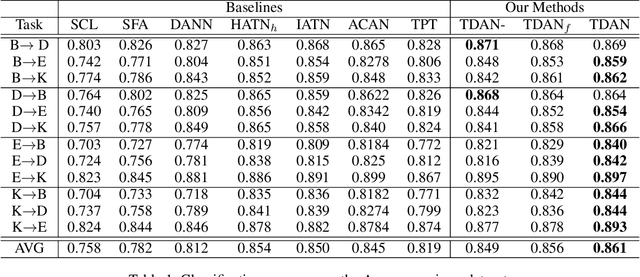
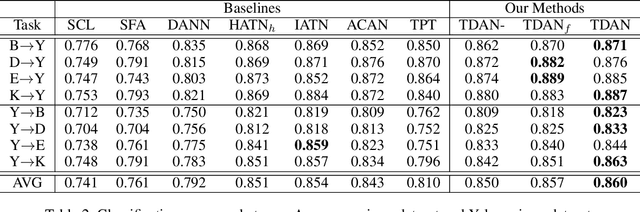

Cross-domain sentiment classification has been a hot spot these years, which aims to learn a reliable classifier using labeled data from the source domain and evaluate it on the target domain. In this vein, most approaches utilized domain adaptation that maps data from different domains into a common feature space. To further improve the model performance, several methods targeted to mine domain-specific information were proposed. However, most of them only utilized a limited part of domain-specific information. In this study, we first develop a method of extracting domain-specific words based on the topic information. Then, we propose a Topic Driven Adaptive Network (TDAN) for cross-domain sentiment classification. The network consists of two sub-networks: semantics attention network and domain-specific word attention network, the structures of which are based on transformers. These sub-networks take different forms of input and their outputs are fused as the feature vector. Experiments validate the effectiveness of our TDAN on sentiment classification across domains.
Tensor-based Channel Tracking for RIS-Empowered Multi-User MIMO Wireless Systems
Feb 16, 2022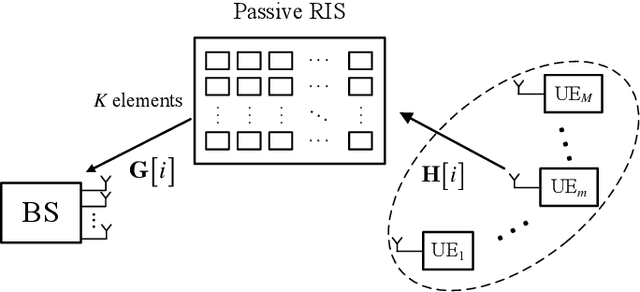
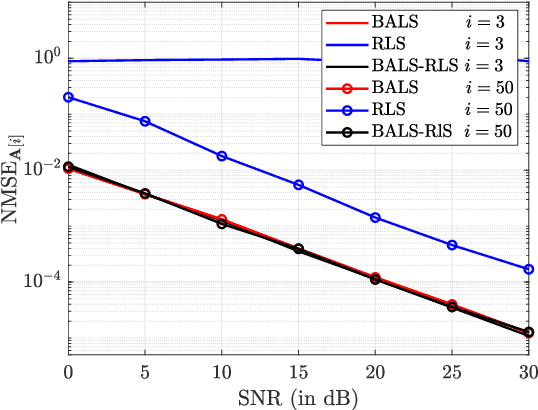
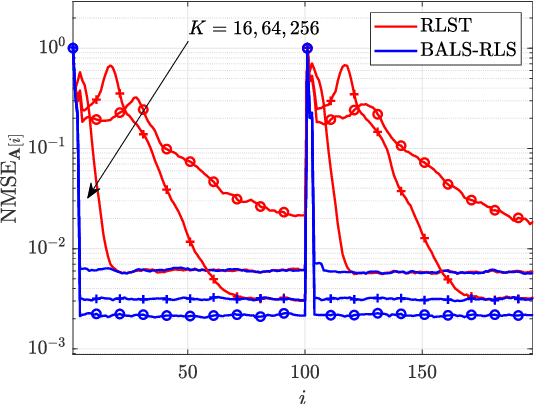
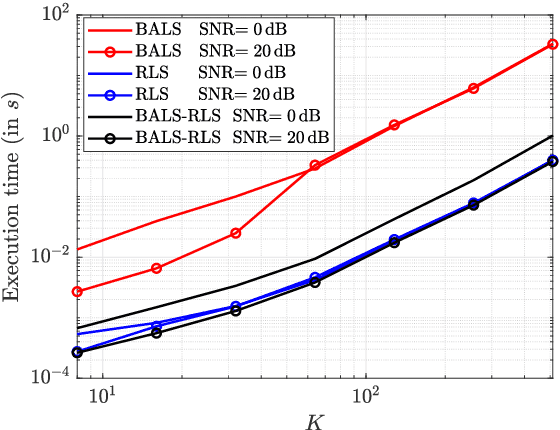
The accurate estimation of Channel State Information (CSI) is of crucial importance for the successful operation of Multiple-Input Multiple-Output (MIMO) communication systems, especially in a Multi-User (MU) time-varying environment and when employing the emerging technology of Reconfigurable Intelligent Surfaces (RISs). Their predominantly passive nature renders the estimation of the channels involved in the user-RIS-base station link a quite challenging problem. Moreover, the time-varying nature of most of the realistic wireless channels drives up the cost of real-time channel tracking significantly, especially when RISs of massive size are deployed. In this paper, we develop a channel tracking scheme for the uplink of RIS-enabled MU MIMO systems in the presence of channel fading. The starting point is a tensor representation of the received signal and we rely on its PARAllel FACtor (PARAFAC) analysis to both get the initial estimate and track the channel time variation. Simulation results for various system settings are reported, which validate the feasibility and effectiveness of the proposed channel tracking approach.