 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CSN: Component-Supervised Network for Few-Shot Classification
Mar 15, 2022

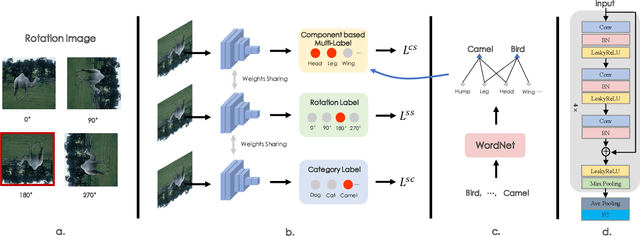

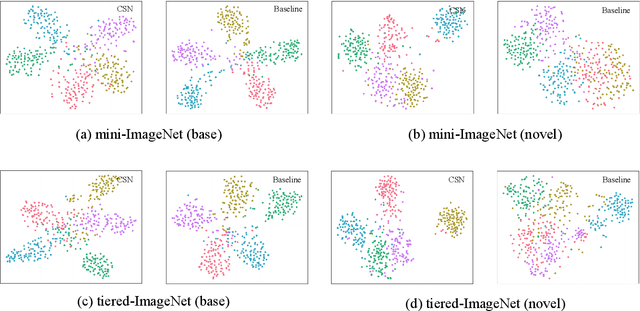
The few-shot classification (FSC) task has been a hot research topic in recent years. It aims to address the classification problem with insufficient labeled data on a cross-category basis. Typically, researchers pre-train a feature extractor with base data, then use it to extract the features of novel data and recognize them. Notably, the novel set only has a few annotated samples and has entirely different categories from the base set, which leads to that the pre-trained feature extractor can not adapt to the novel data flawlessly. We dub this problem as Feature-Extractor-Maladaptive (FEM) problem. Starting from the root cause of this problem, this paper presents a new scheme, Component-Supervised Network (CSN), to improve the performance of FSC. We believe that although the categories of base and novel sets are different, the composition of the sample's components is similar. For example, both cat and dog contain leg and head components. Actually, such entity components are intra-class stable. They have fine cross-category versatility and new category generalization. Therefore, we refer to WordNet, a dictionary commonly used in natural language processing, to collect component information of samples and construct a component-based auxiliary task to improve the adaptability of the feature extractor. We conduct experiments on two benchmark datasets (mini-ImageNet and tiered-ImageNet), the improvements of $0.9\%$-$5.8\%$ compared with state-of-the-arts have evaluated the efficiency of our CSN.
Affect Expression Behaviour Analysis in the Wild using Spatio-Channel Attention and Complementary Context Information
Oct 10, 2020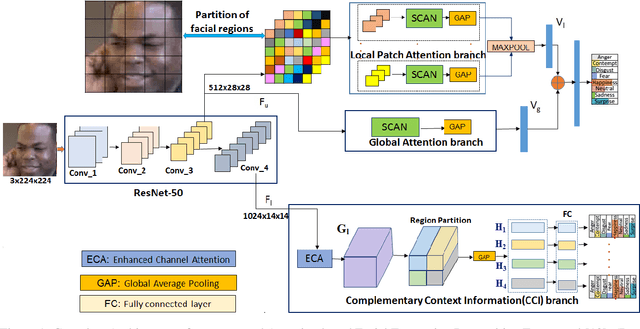
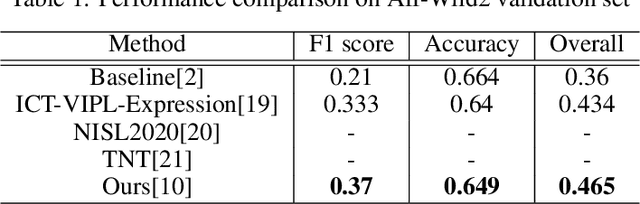
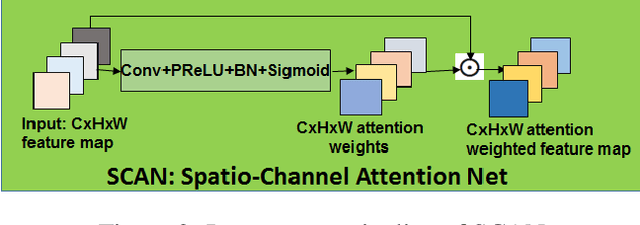

Facial expression recognition(FER) in the wild is crucial for building reliable human-computer interactive systems. However, current FER systems fail to perform well under various natural and un-controlled conditions. This report presents attention based framework used in our submission to expression recognition track of the Affective Behaviour Analysis in-the-wild (ABAW) 2020 competition. Spatial-channel attention net(SCAN) is used to extract local and global attentive features without seeking any information from landmark detectors. SCAN is complemented by a complementary context information(CCI) branch which uses efficient channel attention(ECA) to enhance the relevance of features. The performance of the model is validated on challenging Aff-Wild2 dataset for categorical expression classification.
Open-Ended Reinforcement Learning with Neural Reward Functions
Feb 16, 2022
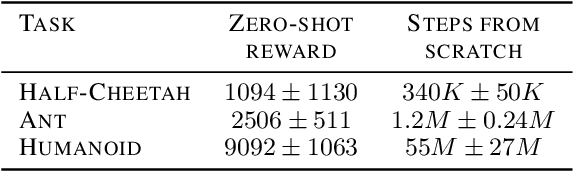
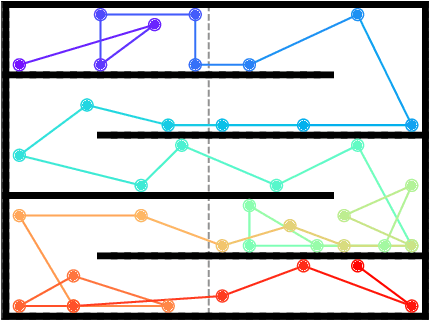
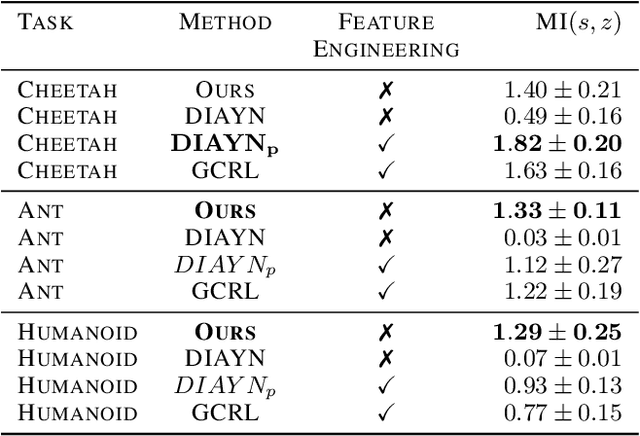
Inspired by the great success of unsupervised learning in Computer Vision and Natural Language Processing, the Reinforcement Learning community has recently started to focus more on unsupervised discovery of skills. Most current approaches, like DIAYN or DADS, optimize some form of mutual information objective. We propose a different approach that uses reward functions encoded by neural networks. These are trained iteratively to reward more complex behavior. In high-dimensional robotic environments our approach learns a wide range of interesting skills including front-flips for Half-Cheetah and one-legged running for Humanoid. In the pixel-based Montezuma's Revenge environment our method also works with minimal changes and it learns complex skills that involve interacting with items and visiting diverse locations. A web version of this paper which shows animations for the different skills is available in https://as.inf.ethz.ch/research/open_ended_RL/main.html
DeepFGS: Fine-Grained Scalable Coding for Learned Image Compression
Jan 04, 2022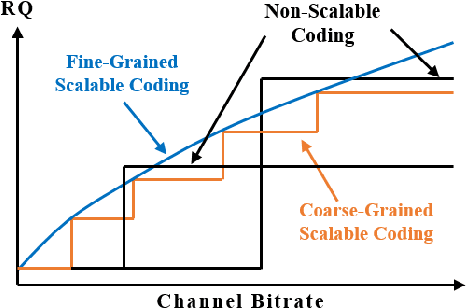

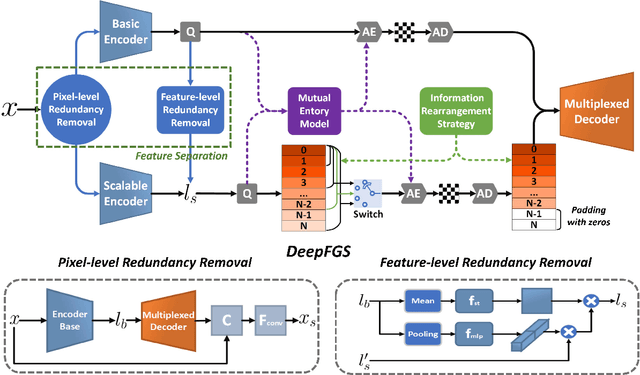
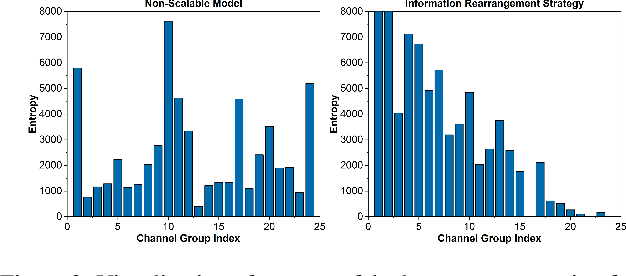
Scalable coding, which can adapt to channel bandwidth variation, performs well in today's complex network environment. However, the existing scalable compression methods face two challenges: reduced compression performance and insufficient scalability. In this paper, we propose the first learned fine-grained scalable image compression model (DeepFGS) to overcome the above two shortcomings. Specifically, we introduce a feature separation backbone to divide the image information into basic and scalable features, then redistribute the features channel by channel through an information rearrangement strategy. In this way, we can generate a continuously scalable bitstream via one-pass encoding. In addition, we reuse the decoder to reduce the parameters and computational complexity of DeepFGS. Experiments demonstrate that our DeepFGS outperforms all learning-based scalable image compression models and conventional scalable image codecs in PSNR and MS-SSIM metrics. To the best of our knowledge, our DeepFGS is the first exploration of learned fine-grained scalable coding, which achieves the finest scalability compared with learning-based methods.
REX: Reasoning-aware and Grounded Explanation
Mar 11, 2022

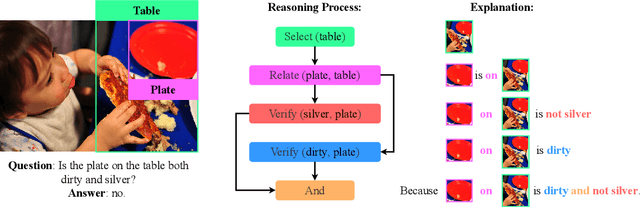

Effectiveness and interpretability are two essential properties for trustworthy AI systems. Most recent studies in visual reasoning are dedicated to improving the accuracy of predicted answers, and less attention is paid to explaining the rationales behind the decisions. As a result, they commonly take advantage of spurious biases instead of actually reasoning on the visual-textual data, and have yet developed the capability to explain their decision making by considering key information from both modalities. This paper aims to close the gap from three distinct perspectives: first, we define a new type of multi-modal explanations that explain the decisions by progressively traversing the reasoning process and grounding keywords in the images. We develop a functional program to sequentially execute different reasoning steps and construct a new dataset with 1,040,830 multi-modal explanations. Second, we identify the critical need to tightly couple important components across the visual and textual modalities for explaining the decisions, and propose a novel explanation generation method that explicitly models the pairwise correspondence between words and regions of interest. It improves the visual grounding capability by a considerable margin, resulting in enhanced interpretability and reasoning performance. Finally, with our new data and method, we perform extensive analyses to study the effectiveness of our explanation under different settings, including multi-task learning and transfer learning. Our code and data are available at https://github.com/szzexpoi/rex.
Vertical Federated Principal Component Analysis and Its Kernel Extension on Feature-wise Distributed Data
Mar 03, 2022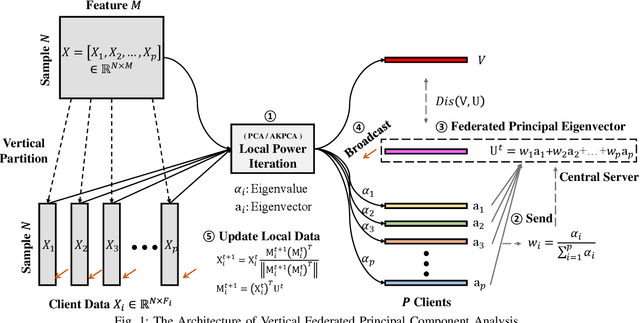
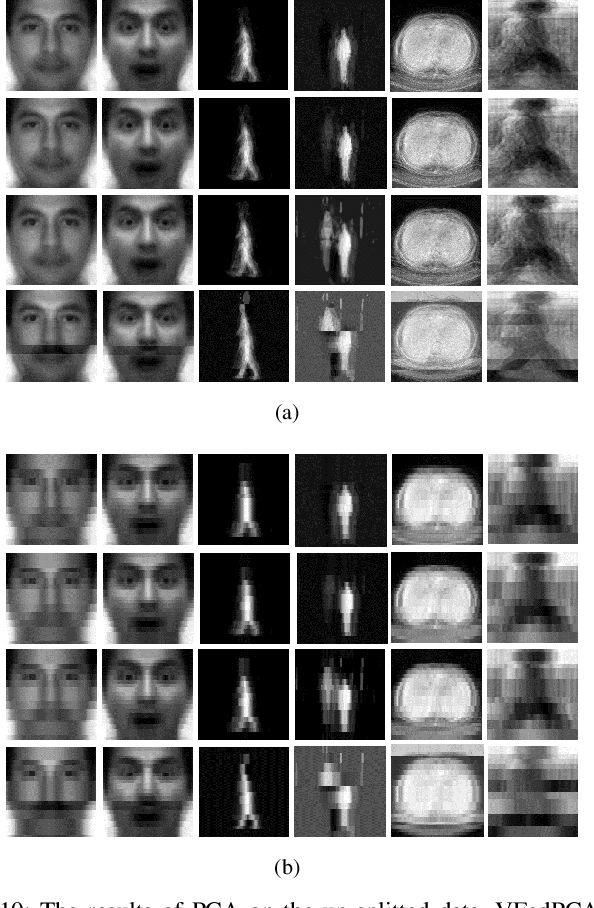
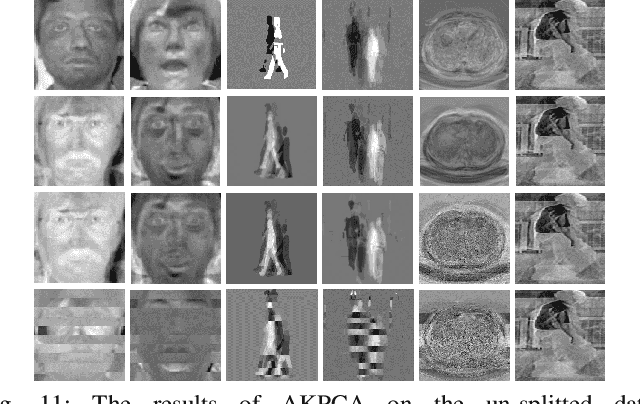

Despite enormous research interest and rapid application of federated learning (FL) to various areas, existing studies mostly focus on supervised federated learning under the horizontally partitioned local dataset setting. This paper will study the unsupervised FL under the vertically partitioned dataset setting. Accordingly, we propose the federated principal component analysis for vertically partitioned dataset (VFedPCA) method, which reduces the dimensionality across the joint datasets over all the clients and extracts the principal component feature information for downstream data analysis. We further take advantage of the nonlinear dimensionality reduction and propose the vertical federated advanced kernel principal component analysis (VFedAKPCA) method, which can effectively and collaboratively model the nonlinear nature existing in many real datasets. In addition, we study two communication topologies. The first is a server-client topology where a semi-trusted server coordinates the federated training, while the second is the fully-decentralized topology which further eliminates the requirement of the server by allowing clients themselves to communicate with their neighbors. Extensive experiments conducted on five types of real-world datasets corroborate the efficacy of VFedPCA and VFedAKPCA under the vertically partitioned FL setting. Code is available at: https://github.com/juyongjiang/VFedPCA-VFedAKPCA
Leveraging vague prior information in general models via iteratively constructed Gamma-minimax estimators
Dec 10, 2020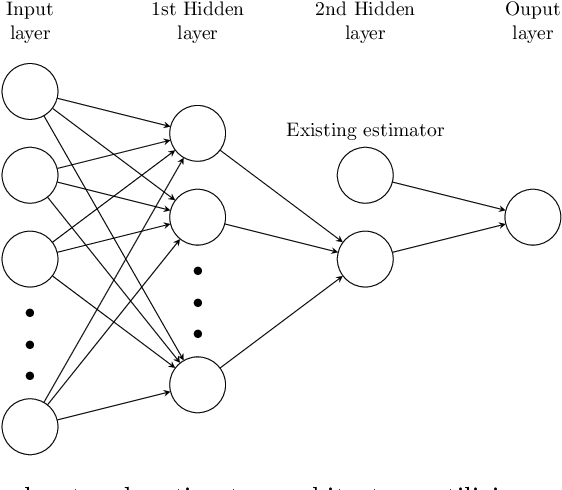

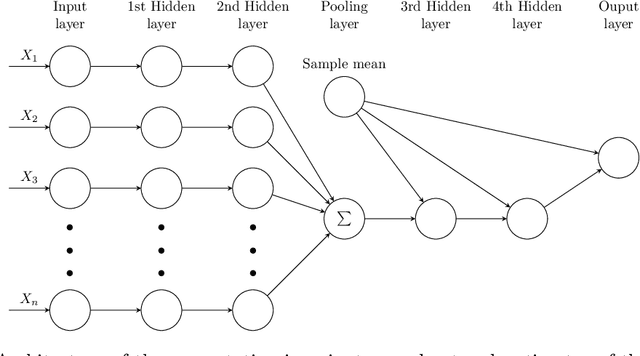
Gamma-minimax estimation is an approach to incorporate prior information into an estimation procedure when it is implausible to specify one particular prior distribution. In this approach, we aim for an estimator that minimizes the worst-case Bayes risk over a set $\Gamma$ of prior distributions. Traditionally, Gamma-minimax estimation is defined for parametric models. In this paper, we define Gamma-minimaxity for general models and propose iterative algorithms with convergence guarantees to compute Gamma-minimax estimators for a general model space and a set of prior distributions constrained by generalized moments. We also propose encoding the space of candidate estimators by neural networks to enable flexible estimation. We illustrate our method in two settings, namely entropy estimation and a problem that arises in biodiversity studies.
InsCon:Instance Consistency Feature Representation via Self-Supervised Learning
Mar 15, 2022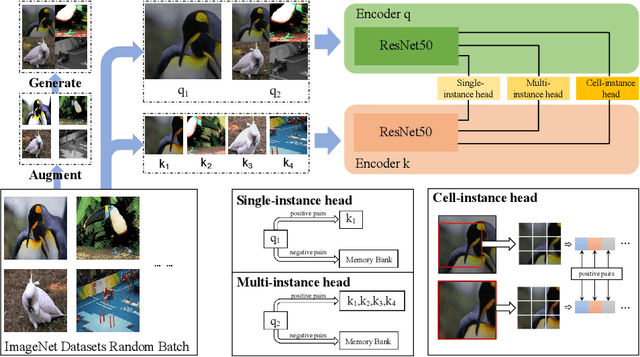
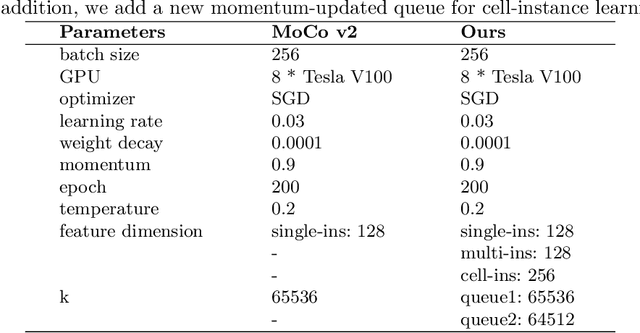
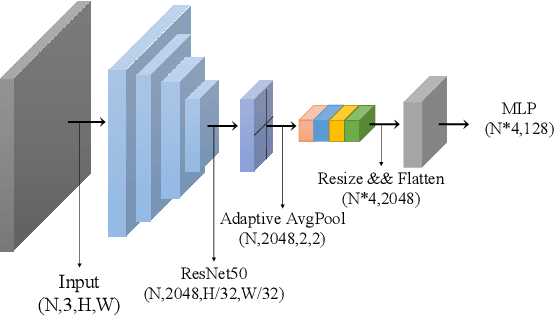
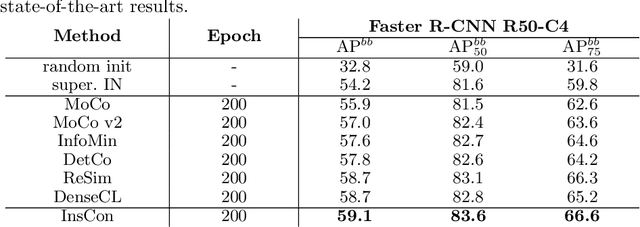
Feature representation via self-supervised learning has reached remarkable success in image-level contrastive learning, which brings impressive performances on image classification tasks. While image-level feature representation mainly focuses on contrastive learning in single instance, it ignores the objective differences between pretext and downstream prediction tasks such as object detection and instance segmentation. In order to fully unleash the power of feature representation on downstream prediction tasks, we propose a new end-to-end self-supervised framework called InsCon, which is devoted to capturing multi-instance information and extracting cell-instance features for object recognition and localization. On the one hand, InsCon builds a targeted learning paradigm that applies multi-instance images as input, aligning the learned feature between corresponding instance views, which makes it more appropriate for multi-instance recognition tasks. On the other hand, InsCon introduces the pull and push of cell-instance, which utilizes cell consistency to enhance fine-grained feature representation for precise boundary localization. As a result, InsCon learns multi-instance consistency on semantic feature representation and cell-instance consistency on spatial feature representation. Experiments demonstrate the method we proposed surpasses MoCo v2 by 1.1% AP^{bb} on COCO object detection and 1.0% AP^{mk} on COCO instance segmentation using Mask R-CNN R50-FPN network structure with 90k iterations, 2.1% APbb on PASCAL VOC objection detection using Faster R-CNN R50-C4 network structure with 24k iterations.
Do Perceived Gender Biases in Retrieval Results Affect Relevance Judgements?
Mar 03, 2022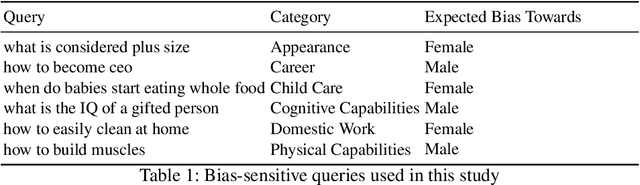
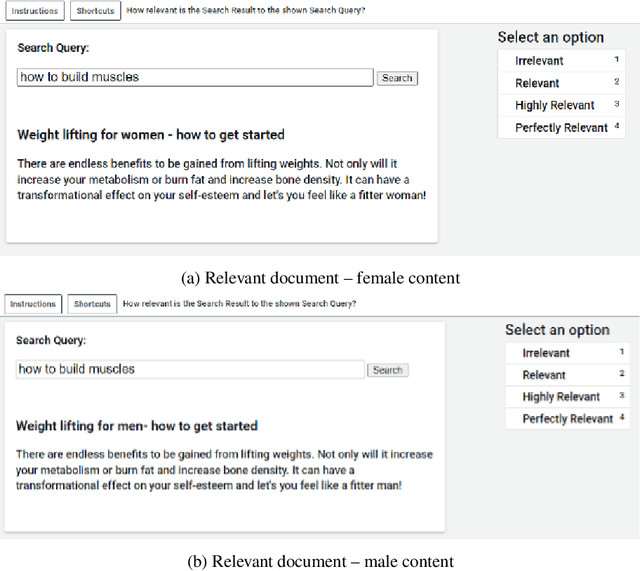
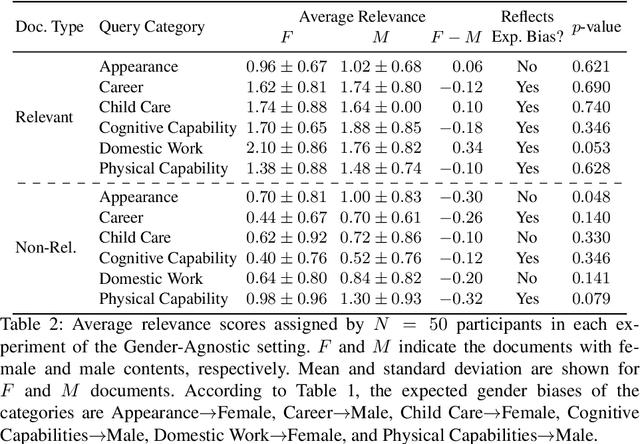
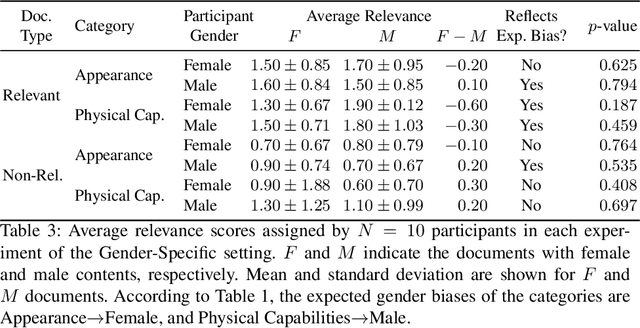
This work investigates the effect of gender-stereotypical biases in the content of retrieved results on the relevance judgement of users/annotators. In particular, since relevance in information retrieval (IR) is a multi-dimensional concept, we study whether the value and quality of the retrieved documents for some bias-sensitive queries can be judged differently when the content of the documents represents different genders. To this aim, we conduct a set of experiments where the genders of the participants are known as well as experiments where the participants genders are not specified. The set of experiments comprise of retrieval tasks, where participants perform a rated relevance judgement for different search query and search result document compilations. The shown documents contain different gender indications and are either relevant or non-relevant to the query. The results show the differences between the average judged relevance scores among documents with various gender contents. Our work initiates further research on the connection of the perception of gender stereotypes in users with their judgements and effects on IR systems, and aim to raise awareness about the possible biases in this domain.
Multi-modal Attention Network for Stock Movements Prediction
Jan 14, 2022
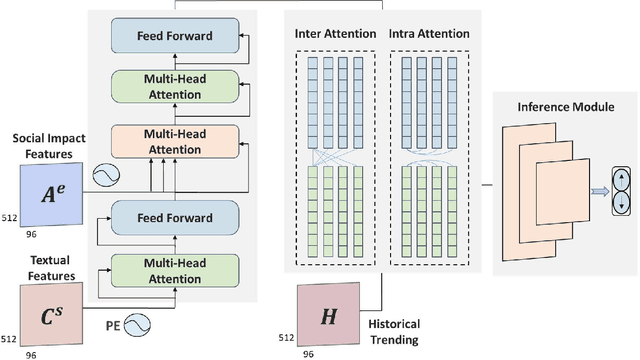
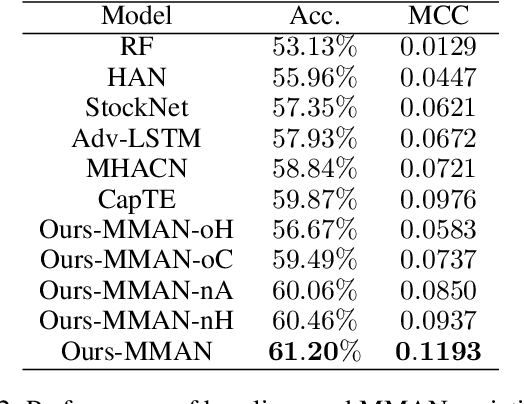
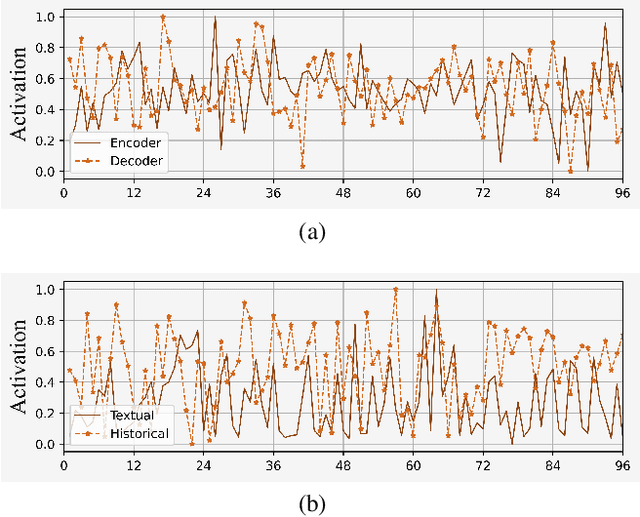
Stock prices move as piece-wise trending fluctuation rather than a purely random walk. Traditionally, the prediction of future stock movements is based on the historical trading record. Nowadays, with the development of social media, many active participants in the market choose to publicize their strategies, which provides a window to glimpse over the whole market's attitude towards future movements by extracting the semantics behind social media. However, social media contains conflicting information and cannot replace historical records completely. In this work, we propose a multi-modality attention network to reduce conflicts and integrate semantic and numeric features to predict future stock movements comprehensively. Specifically, we first extract semantic information from social media and estimate their credibility based on posters' identity and public reputation. Then we incorporate the semantic from online posts and numeric features from historical records to make the trading strategy. Experimental results show that our approach outperforms previous methods by a significant margin in both prediction accuracy (61.20\%) and trading profits (9.13\%). It demonstrates that our method improves the performance of stock movements prediction and informs future research on multi-modality fusion towards stock prediction.