 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Density Estimation from Schlieren Images through Machine Learning
Jan 13, 2022



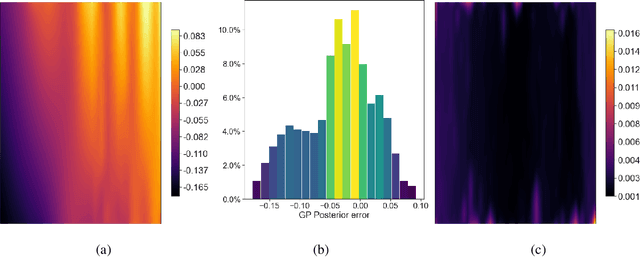
This study proposes a radically alternate approach for extracting quantitative information from schlieren images. The method uses a scaled, derivative enhanced Gaussian process model to obtain true density estimates from two corresponding schlieren images with the knife-edge at horizontal and vertical orientations. We illustrate our approach on schlieren images taken from a wind tunnel sting model, and a supersonic aircraft in flight.
DeLoRes: Decorrelating Latent Spaces for Low-Resource Audio Representation Learning
Mar 25, 2022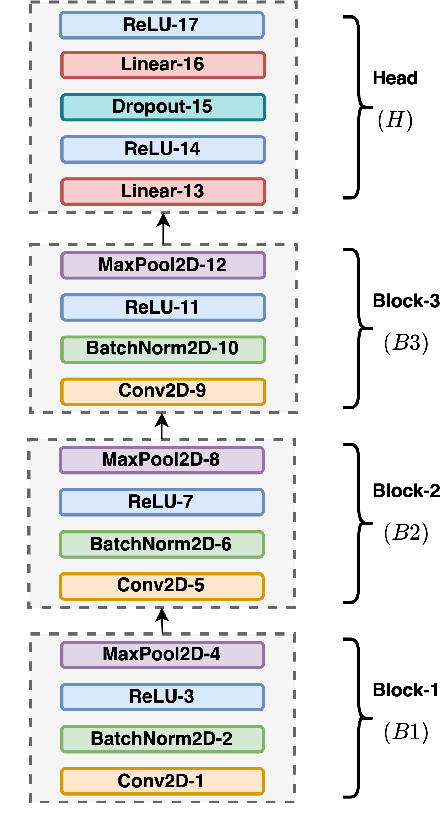
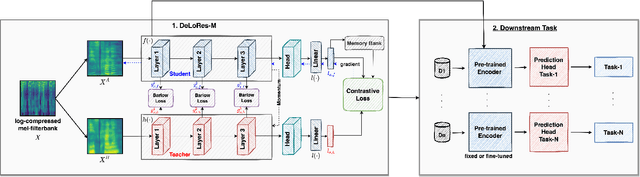
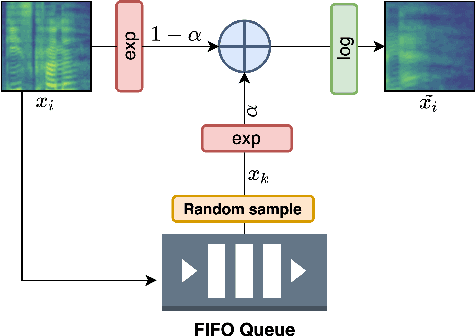
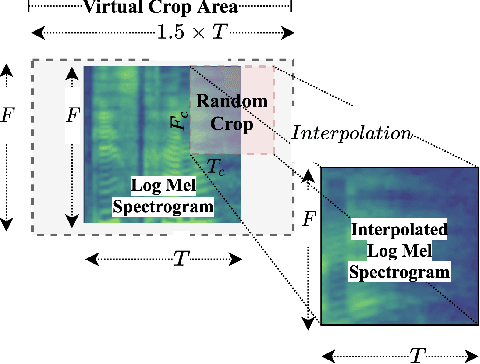
Inspired by the recent progress in self-supervised learning for computer vision, in this paper, through the DeLoRes learning framework, we introduce two new general-purpose audio representation learning approaches, the DeLoRes-S and DeLoRes-M. Our main objective is to make our network learn representations in a resource-constrained setting (both data and compute), that can generalize well across a diverse set of downstream tasks. Inspired from the Barlow Twins objective function, we propose to learn embeddings that are invariant to distortions of an input audio sample, while making sure that they contain non-redundant information about the sample. To achieve this, we measure the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of an audio segment sampled from an audio file and make it as close to the identity matrix as possible. We call this the DeLoRes learning framework, which we employ in different fashions with the DeLoRes-S and DeLoRes-M. We use a combination of a small subset of the large-scale AudioSet dataset and FSD50K for self-supervised learning and are able to learn with less than half the parameters compared to state-of-the-art algorithms. For evaluation, we transfer these learned representations to 11 downstream classification tasks, including speech, music, and animal sounds, and achieve state-of-the-art results on 7 out of 11 tasks on linear evaluation with DeLoRes-M and show competitive results with DeLoRes-S, even when pre-trained using only a fraction of the total data when compared to prior art. Our transfer learning evaluation setup also shows extremely competitive results for both DeLoRes-S and DeLoRes-M, with DeLoRes-M achieving state-of-the-art in 4 tasks.
Semi-parametric Makeup Transfer via Semantic-aware Correspondence
Mar 04, 2022
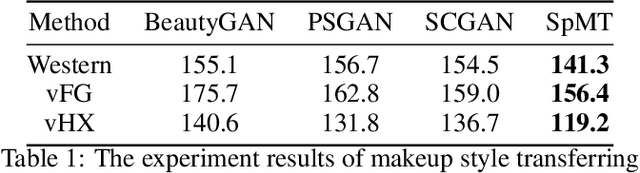
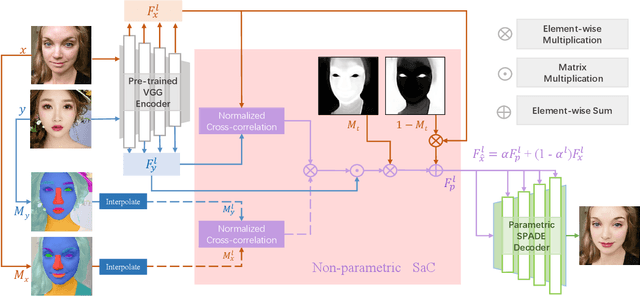
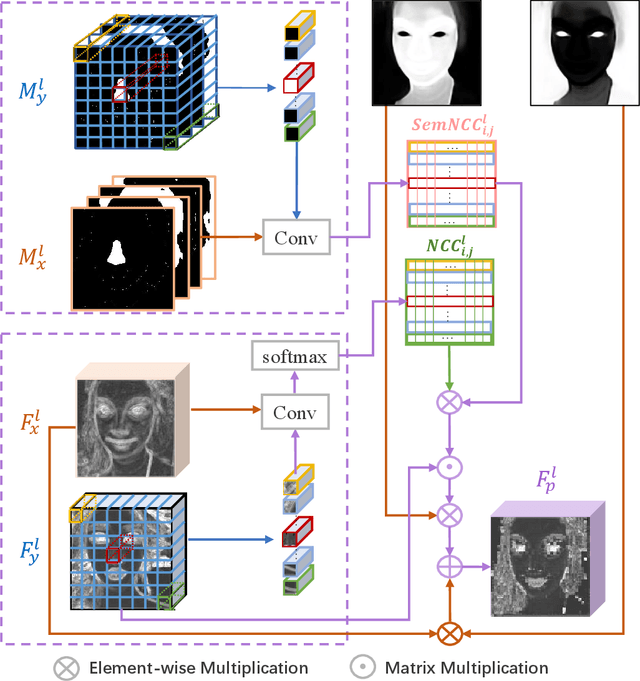
The large discrepancy between the source non-makeup image and the reference makeup image is one of the key challenges in makeup transfer. Conventional approaches for makeup transfer either learn disentangled representation or perform pixel-wise correspondence in a parametric way between two images. We argue that non-parametric techniques have a high potential for addressing the pose, expression, and occlusion discrepancies. To this end, this paper proposes a \textbf{S}emi-\textbf{p}arametric \textbf{M}akeup \textbf{T}ransfer (SpMT) method, which combines the reciprocal strengths of non-parametric and parametric mechanisms. The non-parametric component is a novel \textbf{S}emantic-\textbf{a}ware \textbf{C}orrespondence (SaC) module that explicitly reconstructs content representation with makeup representation under the strong constraint of component semantics. The reconstructed representation is desired to preserve the spatial and identity information of the source image while "wearing" the makeup of the reference image. The output image is synthesized via a parametric decoder that draws on the reconstructed representation. Extensive experiments demonstrate the superiority of our method in terms of visual quality, robustness, and flexibility. Code and pre-trained model are available at \url{https://github.com/AnonymScholar/SpMT.
PercepNet+: A Phase and SNR Aware PercepNet for Real-Time Speech Enhancement
Mar 04, 2022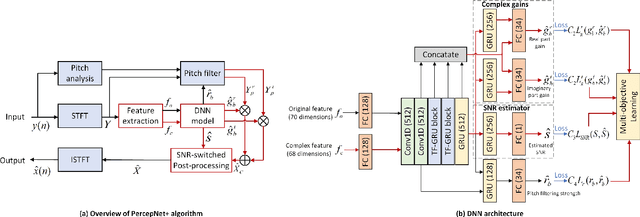
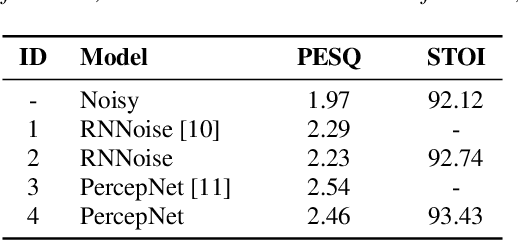
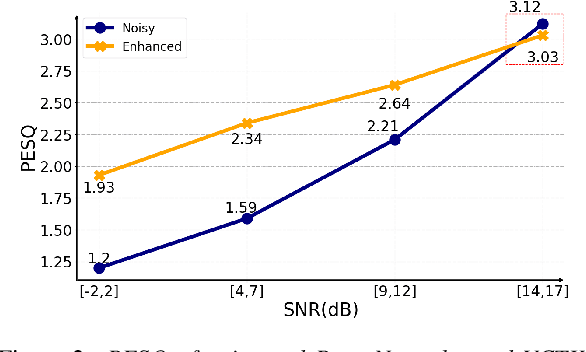
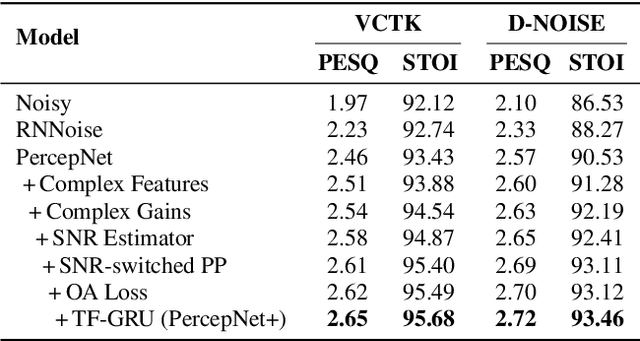
PercepNet, a recent extension of the RNNoise, an efficient, high-quality and real-time full-band speech enhancement technique, has shown promising performance in various public deep noise suppression tasks. This paper proposes a new approach, named PercepNet+, to further extend the PercepNet with four significant improvements. First, we introduce a phase-aware structure to leverage the phase information into PercepNet, by adding the complex features and complex subband gains as the deep network input and output respectively. Then, a signal-to-noise ratio (SNR) estimator and an SNR switched post-processing are specially designed to alleviate the over attenuation (OA) that appears in high SNR conditions of the original PercepNet. Moreover, the GRU layer is replaced by TF-GRU to model both temporal and frequency dependencies. Finally, we propose to integrate the loss of complex subband gain, SNR, pitch filtering strength, and an OA loss in a multi-objective learning manner to further improve the speech enhancement performance. Experimental results show that, the proposed PercepNet+ outperforms the original PercepNet significantly in terms of both PESQ and STOI, without increasing the model size too much.
Retrieval Augmented Classification for Long-Tail Visual Recognition
Feb 22, 2022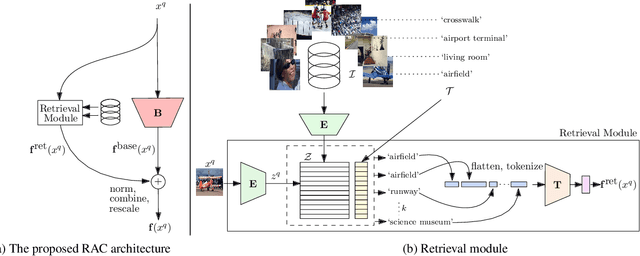
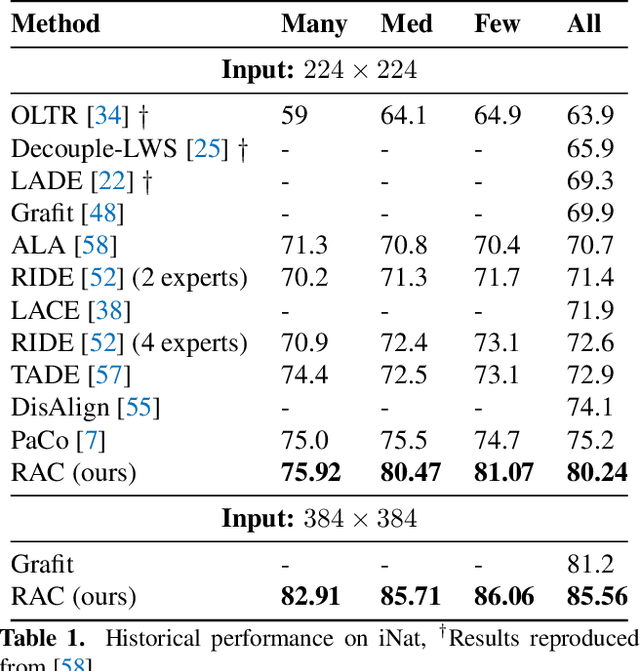
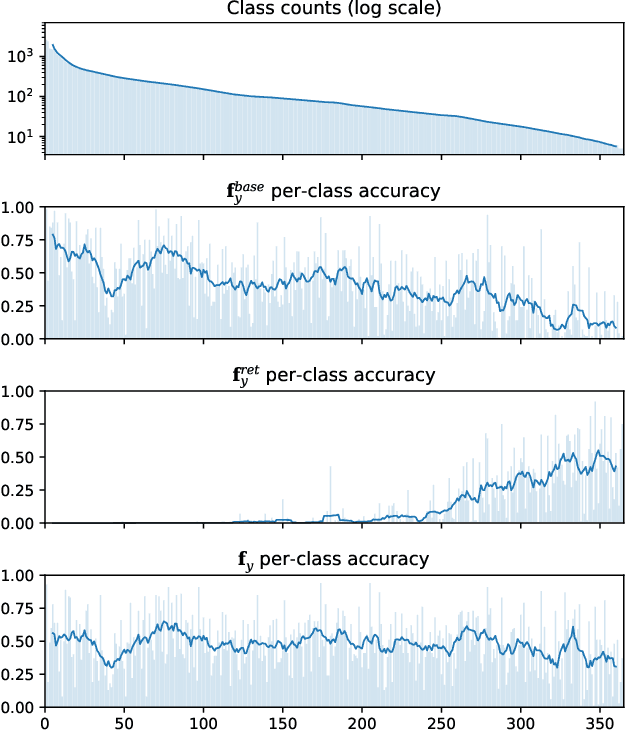
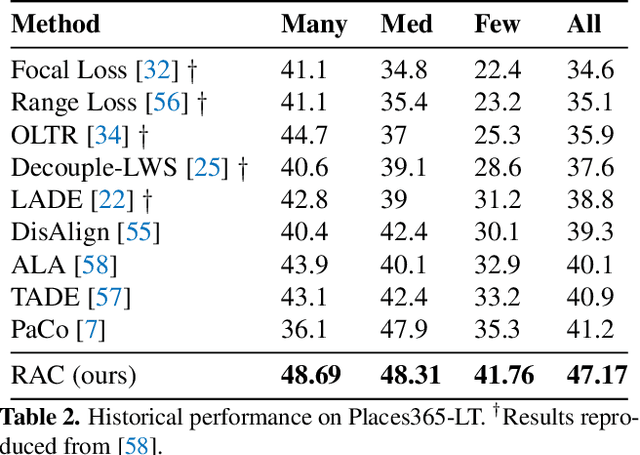
We introduce Retrieval Augmented Classification (RAC), a generic approach to augmenting standard image classification pipelines with an explicit retrieval module. RAC consists of a standard base image encoder fused with a parallel retrieval branch that queries a non-parametric external memory of pre-encoded images and associated text snippets. We apply RAC to the problem of long-tail classification and demonstrate a significant improvement over previous state-of-the-art on Places365-LT and iNaturalist-2018 (14.5% and 6.7% respectively), despite using only the training datasets themselves as the external information source. We demonstrate that RAC's retrieval module, without prompting, learns a high level of accuracy on tail classes. This, in turn, frees the base encoder to focus on common classes, and improve its performance thereon. RAC represents an alternative approach to utilizing large, pretrained models without requiring fine-tuning, as well as a first step towards more effectively making use of external memory within common computer vision architectures.
DFTR: Depth-supervised Hierarchical Feature Fusion Transformer for Salient Object Detection
Mar 12, 2022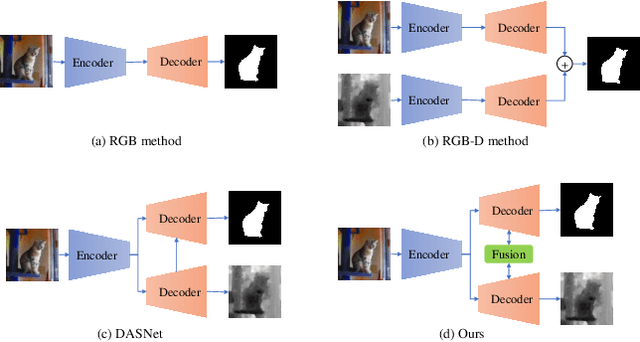
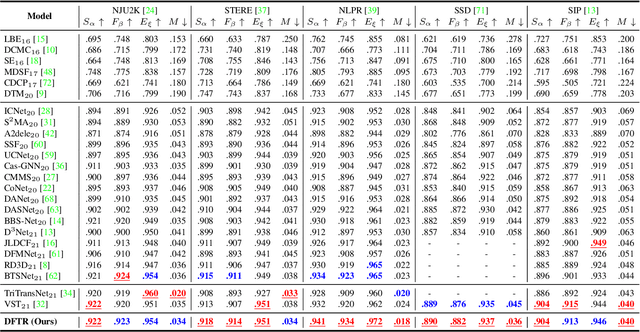
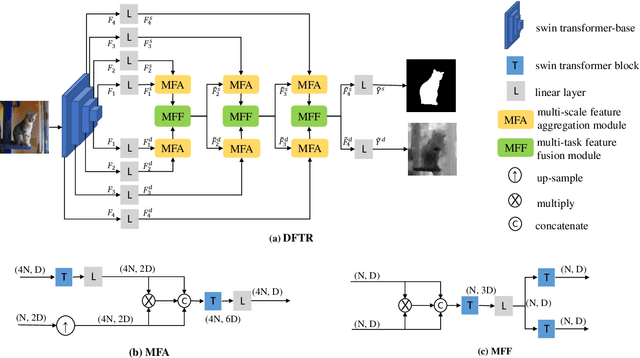
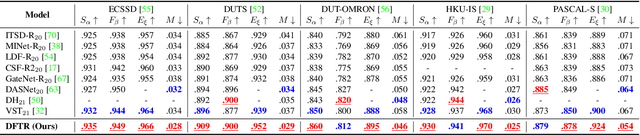
Automated salient object detection (SOD) plays an increasingly crucial role in many computer vision applications. Although existing frameworks achieve impressive SOD performances especially with the development of deep learning techniques, their performances still have room for improvement. In this work, we propose a novel pure Transformer-based SOD framework, namely Depth-supervised hierarchical feature Fusion TRansformer (DFTR), to further improve the accuracy of both RGB and RGB-D SOD. The proposed DFTR involves three primary improvements: 1) The backbone of feature encoder is switched from a convolutional neural network to a Swin Transformer for more effective feature extraction; 2) We propose a multi-scale feature aggregation (MFA) module to fully exploit the multi-scale features encoded by the Swin Transformer in a coarse-to-fine manner; 3) Following recent studies, we formulate an auxiliary task of depth map prediction and use the ground-truth depth maps as extra supervision signals for network learning. To enable bidirectional information flow between saliency and depth branches, a novel multi-task feature fusion (MFF) module is integrated into our DFTR. We extensively evaluate the proposed DFTR on ten benchmarking datasets. Experimental results show that our DFTR consistently outperforms the existing state-of-the-art methods for both RGB and RGB-D SOD tasks. The code and model will be released.
Multi-Scale Adaptive Network for Single Image Denoising
Mar 08, 2022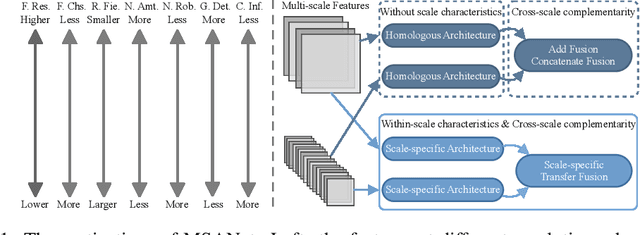
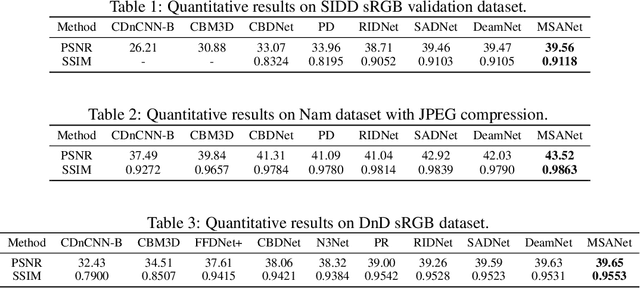
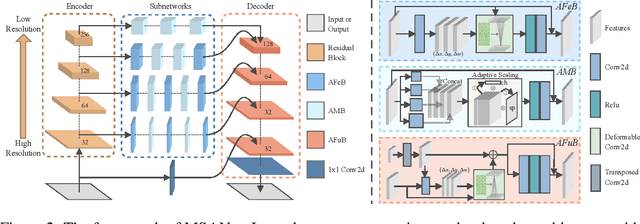

Multi-scale architectures have shown effectiveness in a variety of tasks including single image denoising, thanks to appealing cross-scale complementarity. However, existing methods treat different scale features equally without considering their scale-specific characteristics, i.e., the within-scale characteristics are ignored. In this paper, we reveal this missing piece for multi-scale architecture design and accordingly propose a novel Multi-Scale Adaptive Network (MSANet) for single image denoising. To be specific, MSANet simultaneously embraces the within-scale characteristics and the cross-scale complementarity thanks to three novel neural blocks, i.e., adaptive feature block (AFeB), adaptive multi-scale block (AMB), and adaptive fusion block (AFuB). In brief, AFeB is designed to adaptively select details and filter noises, which is highly expected for fine-grained features. AMB could enlarge the receptive field and aggregate the multi-scale information, which is designed to satisfy the demands of both fine- and coarse-grained features. AFuB devotes to adaptively sampling and transferring the features from one scale to another scale, which is used to fuse the features with varying characteristics from coarse to fine. Extensive experiments on both three real and six synthetic noisy image datasets show the superiority of MSANet compared with 12 methods.
Implicit LiDAR Network: LiDAR Super-Resolution via Interpolation Weight Prediction
Mar 12, 2022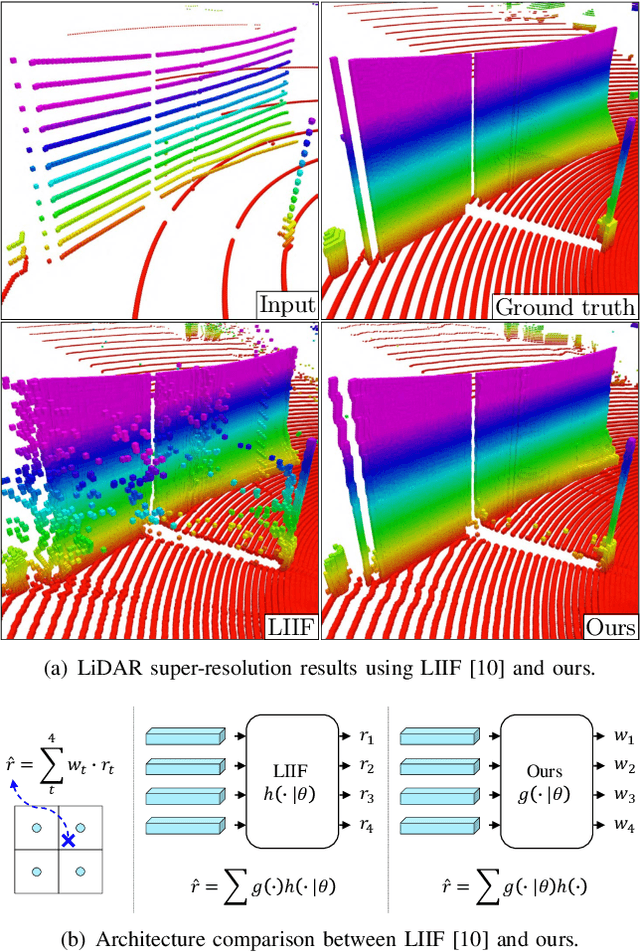
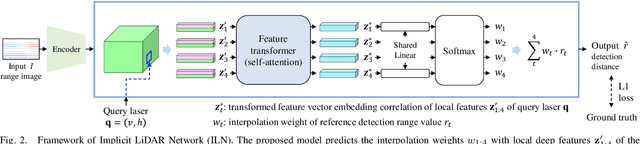
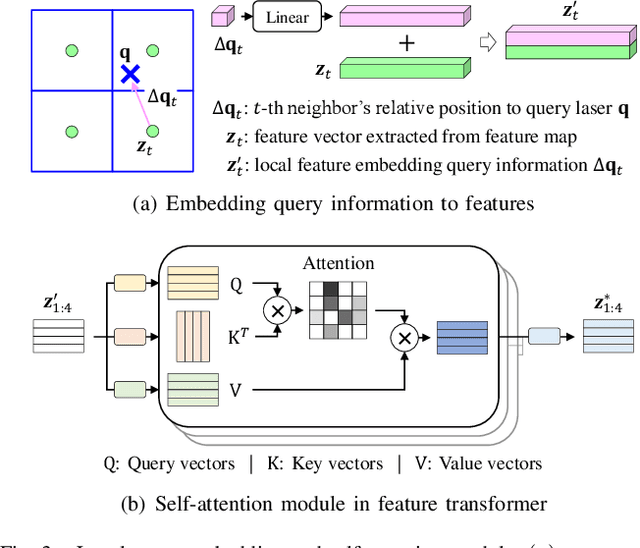
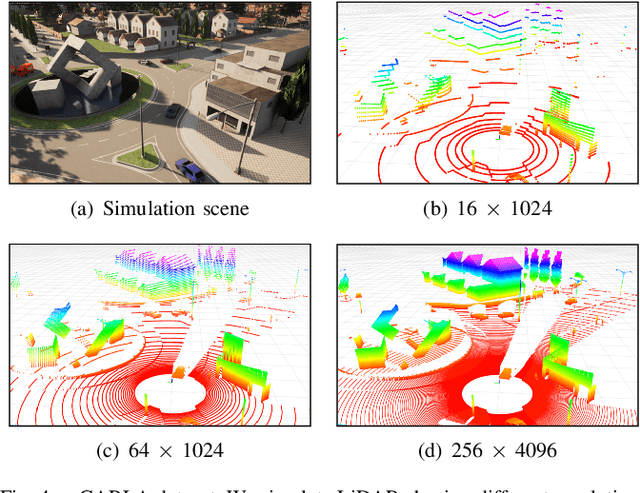
Super-resolution of LiDAR range images is crucial to improving many downstream tasks such as object detection, recognition, and tracking. While deep learning has made a remarkable advances in super-resolution techniques, typical convolutional architectures limit upscaling factors to specific output resolutions in training. Recent work has shown that a continuous representation of an image and learning its implicit function enable almost limitless upscaling. However, the detailed approach, predicting values (depths) for neighbor pixels in the input and then linearly interpolating them, does not best fit the LiDAR range images since it does not fill the unmeasured details but creates a new image with regression in a high-dimensional space. In addition, the linear interpolation blurs sharp edges providing important boundary information of objects in 3-D points. To handle these problems, we propose a novel network, Implicit LiDAR Network (ILN), which learns not the values per pixels but weights in the interpolation so that the superresolution can be done by blending the input pixel depths but with non-linear weights. Also, the weights can be considered as attentions from the query to the neighbor pixels, and thus an attention module in the recent Transformer architecture can be leveraged. Our experiments with a novel large-scale synthetic dataset demonstrate that the proposed network reconstructs more accurately than the state-of-the-art methods, achieving much faster convergence in training.
NURD: Negative-Unlabeled Learning for Online Datacenter Straggler Prediction
Mar 16, 2022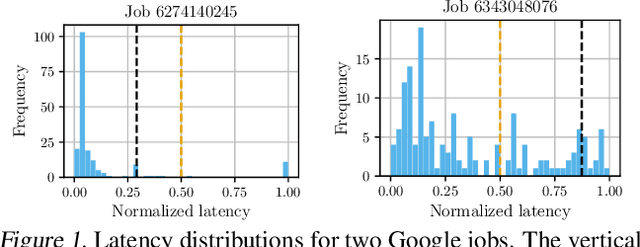


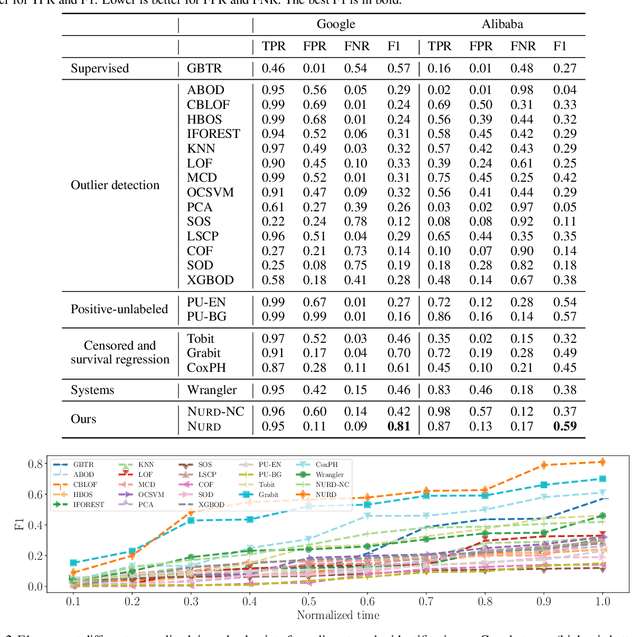
Datacenters execute large computational jobs, which are composed of smaller tasks. A job completes when all its tasks finish, so stragglers -- rare, yet extremely slow tasks -- are a major impediment to datacenter performance. Accurately predicting stragglers would enable proactive intervention, allowing datacenter operators to mitigate stragglers before they delay a job. While much prior work applies machine learning to predict computer system performance, these approaches rely on complete labels -- i.e., sufficient examples of all possible behaviors, including straggling and non-straggling -- or strong assumptions about the underlying latency distributions -- e.g., whether Gaussian or not. Within a running job, however, none of this information is available until stragglers have revealed themselves when they have already delayed the job. To predict stragglers accurately and early without labeled positive examples or assumptions on latency distributions, this paper presents NURD, a novel Negative-Unlabeled learning approach with Reweighting and Distribution-compensation that only trains on negative and unlabeled streaming data. The key idea is to train a predictor using finished tasks of non-stragglers to predict latency for unlabeled running tasks, and then reweight each unlabeled task's prediction based on a weighting function of its feature space. We evaluate NURD on two production traces from Google and Alibaba, and find that compared to the best baseline approach, NURD produces 2--11 percentage point increases in the F1 score in terms of prediction accuracy, and 4.7--8.8 percentage point improvements in job completion time.
Contrastive Enhancement Using Latent Prototype for Few-Shot Segmentation
Mar 08, 2022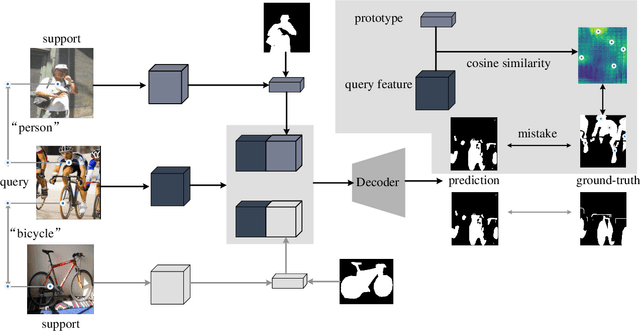
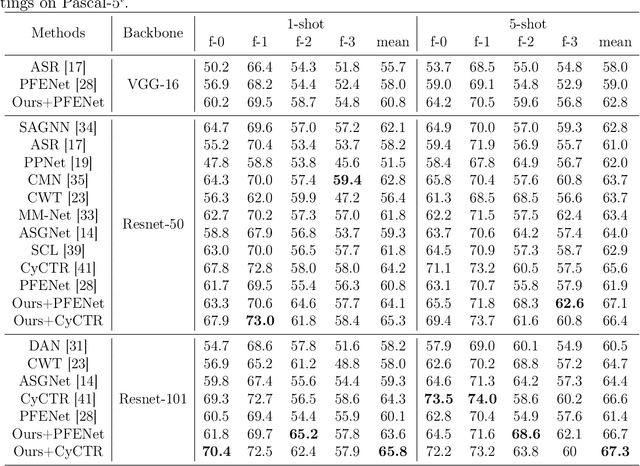
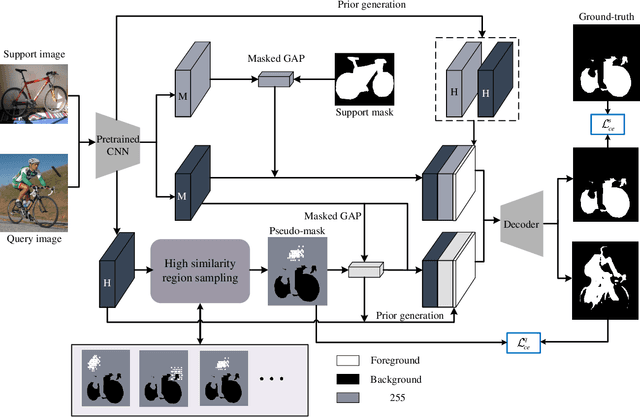
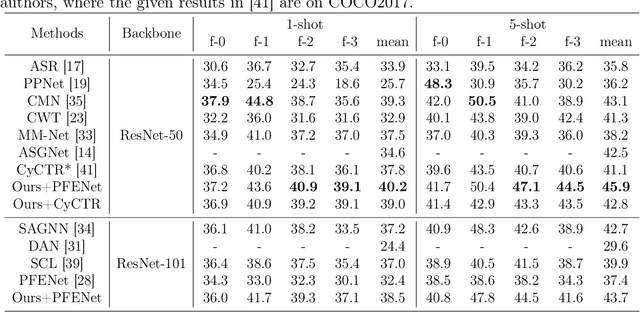
Few-shot segmentation enables the model to recognize unseen classes with few annotated examples. Most existing methods adopt prototype learning architecture, where support prototype vectors are expanded and concatenated with query features to perform conditional segmentation. However, such framework potentially focuses more on query features while may neglect the similarity between support and query features. This paper proposes a contrastive enhancement approach using latent prototypes to leverage latent classes and raise the utilization of similarity information between prototype and query features. Specifically, a latent prototype sampling module is proposed to generate pseudo-mask and novel prototypes based on features similarity. The module conveniently conducts end-to-end learning and has no strong dependence on clustering numbers like cluster-based method. Besides, a contrastive enhancement module is developed to drive models to provide different predictions with the same query features. Our method can be used as an auxiliary module to flexibly integrate into other baselines for a better segmentation performance. Extensive experiments show our approach remarkably improves the performance of state-of-the-art methods for 1-shot and 5-shot segmentation, especially outperforming baseline by 5.9% and 7.3% for 5-shot task on Pascal-5^i and COCO-20^i. Source code is available at https://github.com/zhaoxiaoyu1995/CELP-Pytorch