 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Recurrent Neural Network with Multi-scale Bi-directional Propagation for Video Deblurring
Dec 09, 2021


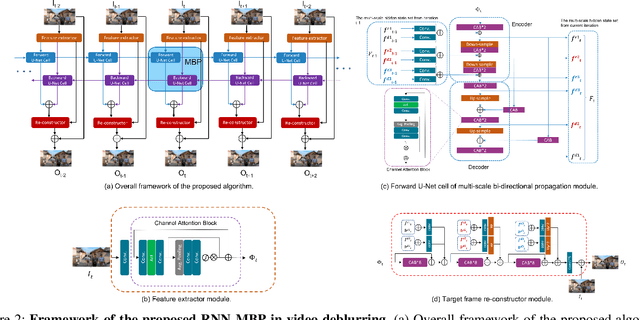
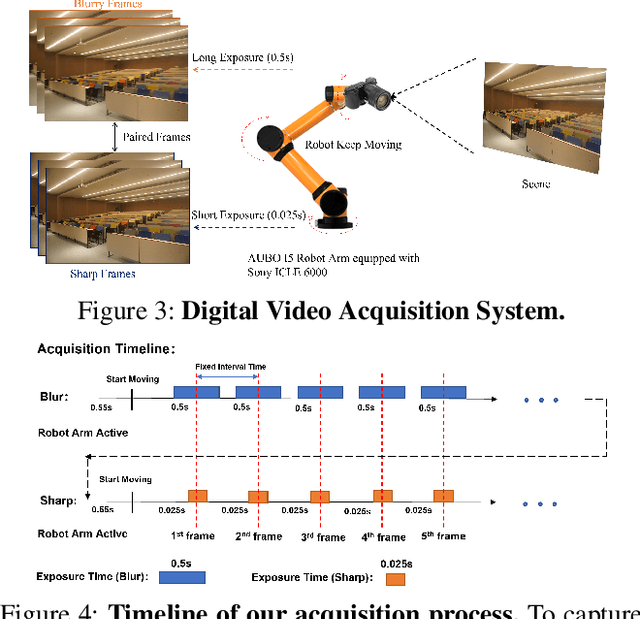
The success of the state-of-the-art video deblurring methods stems mainly from implicit or explicit estimation of alignment among the adjacent frames for latent video restoration. However, due to the influence of the blur effect, estimating the alignment information from the blurry adjacent frames is not a trivial task. Inaccurate estimations will interfere the following frame restoration. Instead of estimating alignment information, we propose a simple and effective deep Recurrent Neural Network with Multi-scale Bi-directional Propagation (RNN-MBP) to effectively propagate and gather the information from unaligned neighboring frames for better video deblurring. Specifically, we build a Multi-scale Bi-directional Propagation~(MBP) module with two U-Net RNN cells which can directly exploit the inter-frame information from unaligned neighboring hidden states by integrating them in different scales. Moreover, to better evaluate the proposed algorithm and existing state-of-the-art methods on real-world blurry scenes, we also create a Real-World Blurry Video Dataset (RBVD) by a well-designed Digital Video Acquisition System (DVAS) and use it as the training and evaluation dataset. Extensive experimental results demonstrate that the proposed RBVD dataset effectively improves the performance of existing algorithms on real-world blurry videos, and the proposed algorithm performs favorably against the state-of-the-art methods on three typical benchmarks. The code is available at https://github.com/XJTU-CVLAB-LOWLEVEL/RNN-MBP.
Speech watermarking: a solution for authentication of forensic audio digital recordings
Feb 23, 2022
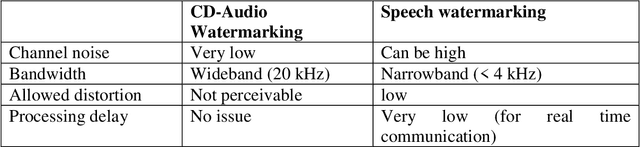
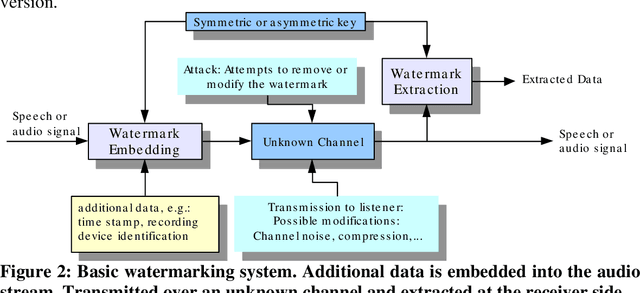
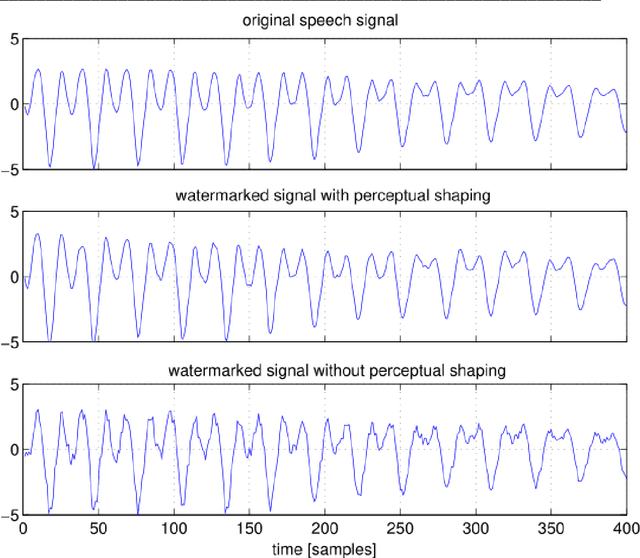
In this paper we discuss the problem of authentication of forensic audio when using digital recordings. Although forensic audio has been addressed in several papers the existing approaches are focused on analog magnetic recordings, which are becoming old-fashion due to the large amount of digital recorders available on the market (optical, solid-state, hard disks, etc). We present an approach based on digital signal processing that consist of spread spectrum techniques for speech watermarking. This approach presents the advantage that the authentication is based on the signal itself rather than the recording support. Thus, it is valid for whatever recording device. In addition, our proposal permits the introduction of relevant information such as recording date and time and all the relevant data (this is not possible with classical systems). Our experimental results reveal that the speech watermarking procedure does not interfere in a significant way with the posterior forensic speaker identification.
* 14 pages
A deep Q-learning method for optimizing visual search strategies in backgrounds of dynamic noise
Jan 28, 2022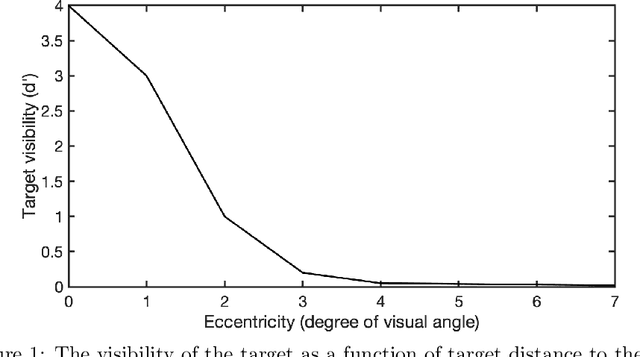
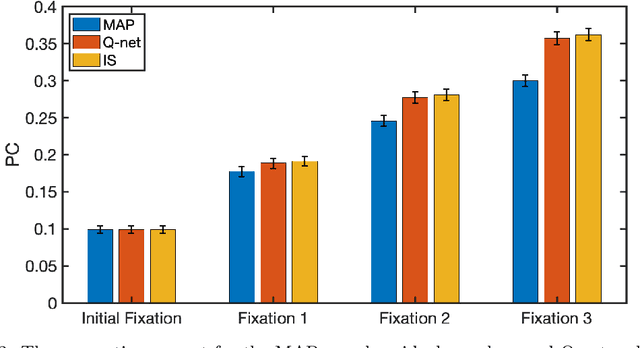
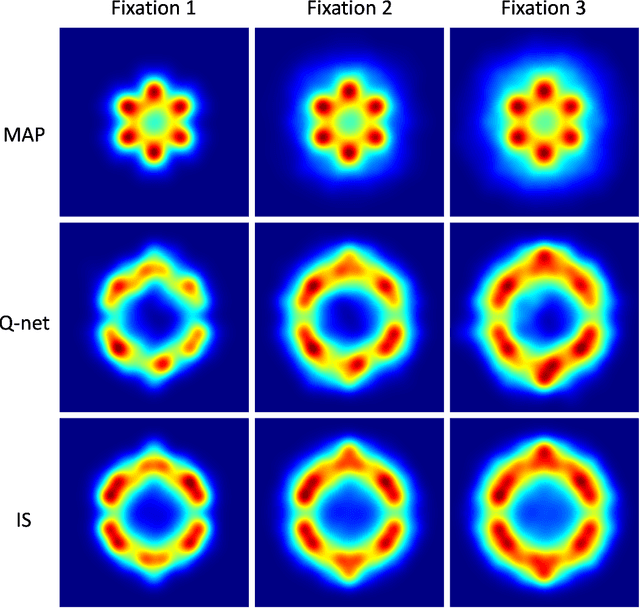
Humans process visual information with varying resolution (foveated visual system) and explore images by orienting through eye movements the high-resolution fovea to points of interest. The Bayesian ideal searcher (IS) that employs complete knowledge of task-relevant information optimizes eye movement strategy and achieves the optimal search performance. The IS can be employed as an important tool to evaluate the optimality of human eye movements, and potentially provide guidance to improve human observer visual search strategies. Najemnik and Geisler (2005) derived an IS for backgrounds of spatial 1/f noise. The corresponding template responses follow Gaussian distributions and the optimal search strategy can be analytically determined. However, the computation of the IS can be intractable when considering more realistic and complex backgrounds such as medical images. Modern reinforcement learning methods, successfully applied to obtain optimal policy for a variety of tasks, do not require complete knowledge of the background generating functions and can be potentially applied to anatomical backgrounds. An important first step is to validate the optimality of the reinforcement learning method. In this study, we investigate the ability of a reinforcement learning method that employs Q-network to approximate the IS. We demonstrate that the search strategy corresponding to the Q-network is consistent with the IS search strategy. The findings show the potential of the reinforcement learning with Q-network approach to estimate optimal eye movement planning with real anatomical backgrounds.
X-Learner: Learning Cross Sources and Tasks for Universal Visual Representation
Mar 16, 2022
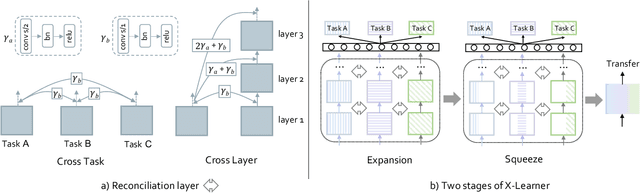
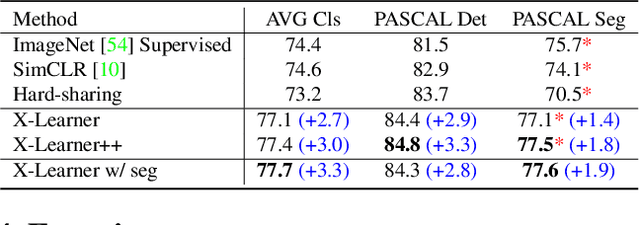
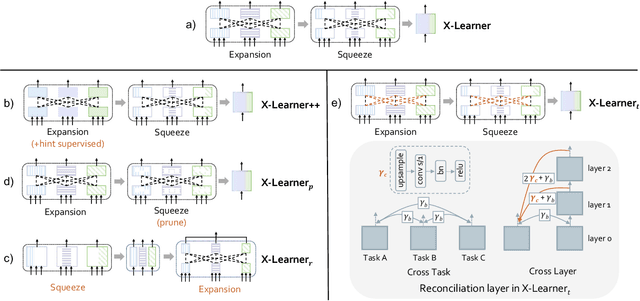
In computer vision, pre-training models based on largescale supervised learning have been proven effective over the past few years. However, existing works mostly focus on learning from individual task with single data source (e.g., ImageNet for classification or COCO for detection). This restricted form limits their generalizability and usability due to the lack of vast semantic information from various tasks and data sources. Here, we demonstrate that jointly learning from heterogeneous tasks and multiple data sources contributes to universal visual representation, leading to better transferring results of various downstream tasks. Thus, learning how to bridge the gaps among different tasks and data sources is the key, but it still remains an open question. In this work, we propose a representation learning framework called X-Learner, which learns the universal feature of multiple vision tasks supervised by various sources, with expansion and squeeze stage: 1) Expansion Stage: X-Learner learns the task-specific feature to alleviate task interference and enrich the representation by reconciliation layer. 2) Squeeze Stage: X-Learner condenses the model to a reasonable size and learns the universal and generalizable representation for various tasks transferring. Extensive experiments demonstrate that X-Learner achieves strong performance on different tasks without extra annotations, modalities and computational costs compared to existing representation learning methods. Notably, a single X-Learner model shows remarkable gains of 3.0%, 3.3% and 1.8% over current pretrained models on 12 downstream datasets for classification, object detection and semantic segmentation.
MITI: SLAM Benchmark for Laparoscopic Surgery
Feb 23, 2022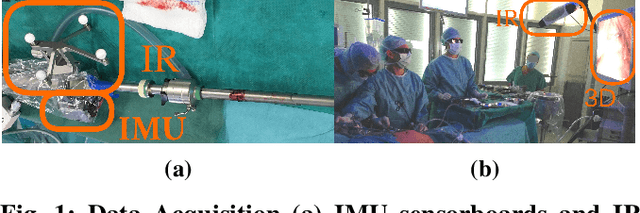
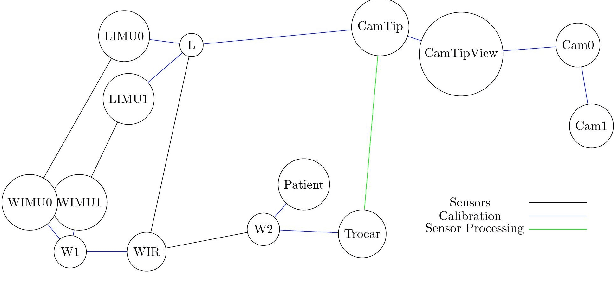

We propose a new benchmark for evaluating stereoscopic visual-inertial computer vision algorithms (SLAM/ SfM/ 3D Reconstruction/ Visual-Inertial Odometry) for minimally invasive surgical (MIS) interventions in the abdomen. Our MITI Dataset available at [https://mediatum.ub.tum.de/1621941] provides all the necessary data by a complete recording of a handheld surgical intervention at Research Hospital Rechts der Isar of TUM. It contains multimodal sensor information from IMU, stereoscopic video, and infrared (IR) tracking as ground truth for evaluation. Furthermore, calibration for the stereoscope, accelerometer, magnetometer, the rigid transformations in the sensor setup, and time-offsets are available. We wisely chose a suitable intervention that contains very few cutting and tissue deformation and shows a full scan of the abdomen with a handheld camera such that it is ideal for testing SLAM algorithms. Intending to promote the progress of visual-inertial algorithms designed for MIS application, we hope that our clinical training dataset helps and enables researchers to enhance algorithms.
One-bit Submission for Locally Private Quasi-MLE: Its Asymptotic Normality and Limitation
Feb 15, 2022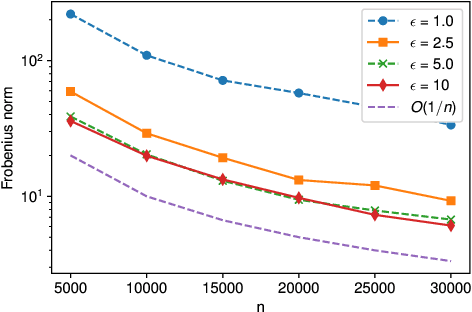
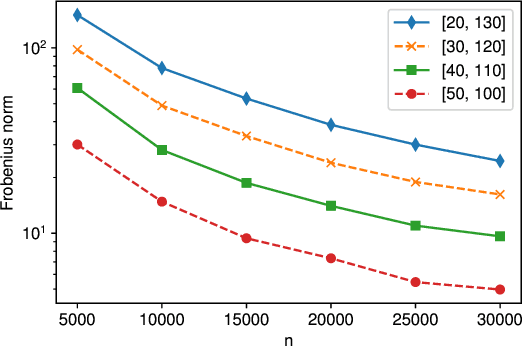
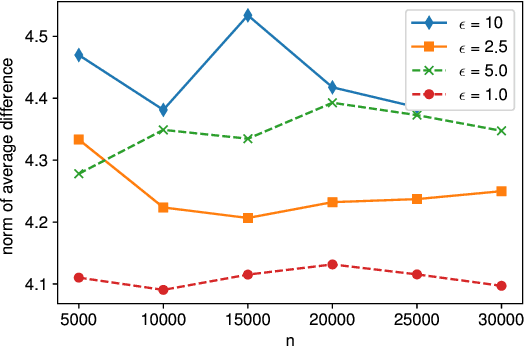
Local differential privacy~(LDP) is an information-theoretic privacy definition suitable for statistical surveys that involve an untrusted data curator. An LDP version of quasi-maximum likelihood estimator~(QMLE) has been developed, but the existing method to build LDP QMLE is difficult to implement for a large-scale survey system in the real world due to long waiting time, expensive communication cost, and the boundedness assumption of derivative of a log-likelihood function. We provided an alternative LDP protocol without those issues, which is potentially much easily deployable to a large-scale survey. We also provided sufficient conditions for the consistency and asymptotic normality and limitations of our protocol. Our protocol is less burdensome for the users, and the theoretical guarantees cover more realistic cases than those for the existing method.
State-of-the-art in speaker recognition
Feb 23, 2022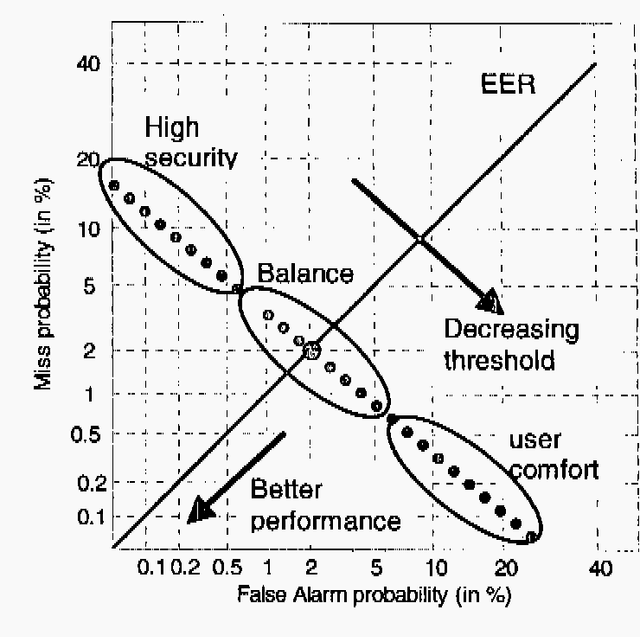
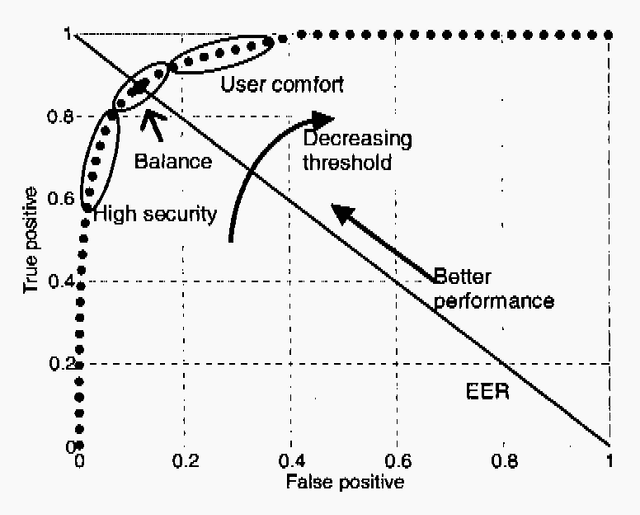
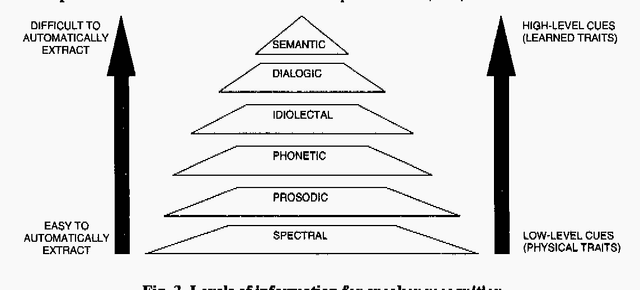
Recent advances in speech technologies have produced new tools that can be used to improve the performance and flexibility of speaker recognition While there are few degrees of freedom or alternative methods when using fingerprint or iris identification techniques, speech offers much more flexibility and different levels for performing recognition: the system can force the user to speak in a particular manner, different for each attempt to enter. Also with voice input the system has other degrees of freedom, such as the use of knowledge/codes that only the user knows, or dialectical/semantical traits that are difficult to forge. This paper offers and overview of the state of the art in speaker recognition, with special emphasis on the pros and contras, and the current research lines. The current research lines include improved classification systems, and the use of high level information by means of probabilistic grammars. In conclusion, speaker recognition is far away from being a technology where all the possibilities have already been explored.
* 7 pages. arXiv admin note: text overlap with arXiv:2202.11459
Adaptive Cholesky Gaussian Processes
Feb 23, 2022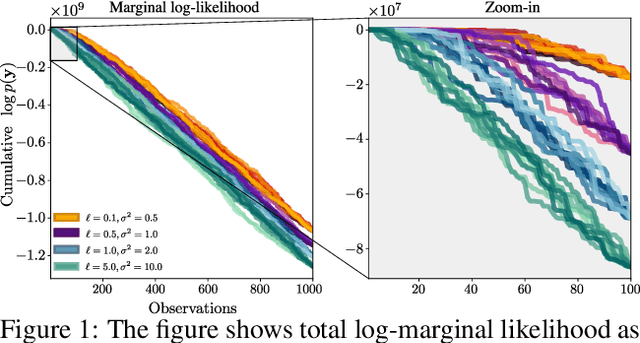
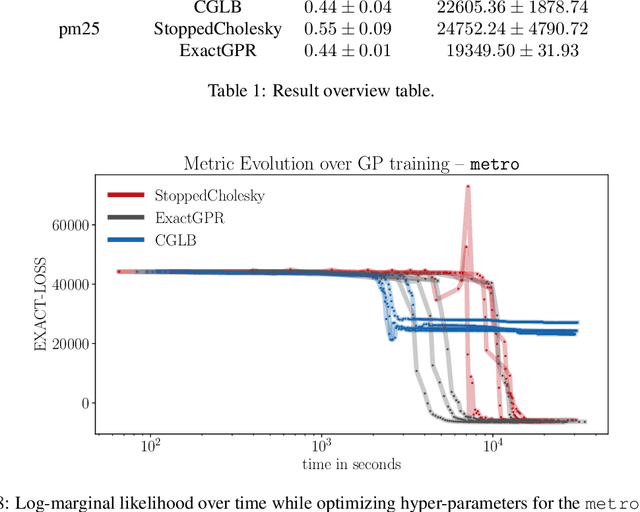
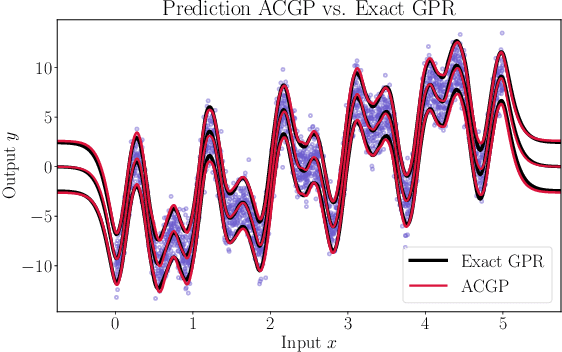
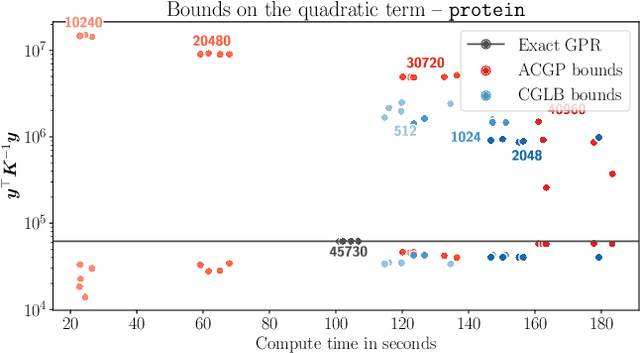
We present a method to fit exact Gaussian process models to large datasets by considering only a subset of the data. Our approach is novel in that the size of the subset is selected on the fly during exact inference with little computational overhead. From an empirical observation that the log-marginal likelihood often exhibits a linear trend once a sufficient subset of a dataset has been observed, we conclude that many large datasets contain redundant information that only slightly affects the posterior. Based on this, we provide probabilistic bounds on the full model evidence that can identify such subsets. Remarkably, these bounds are largely composed of terms that appear in intermediate steps of the standard Cholesky decomposition, allowing us to modify the algorithm to adaptively stop the decomposition once enough data have been observed. Empirically, we show that our method can be directly plugged into well-known inference schemes to fit exact Gaussian process models to large datasets.
FusionCount: Efficient Crowd Counting via Multiscale Feature Fusion
Feb 28, 2022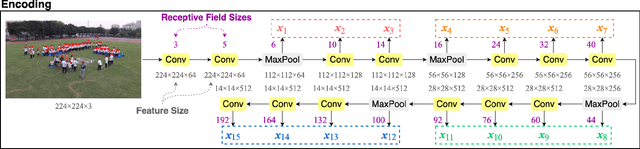
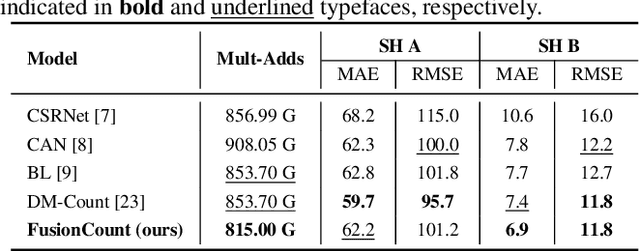
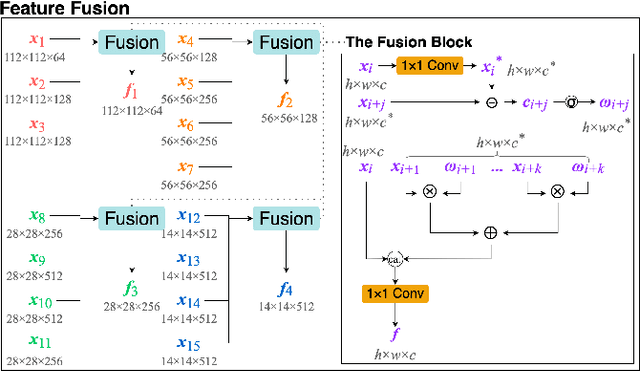

State-of-the-art crowd counting models follow an encoder-decoder approach. Images are first processed by the encoder to extract features. Then, to account for perspective distortion, the highest-level feature map is fed to extra components to extract multiscale features, which are the input to the decoder to generate crowd densities. However, in these methods, features extracted at earlier stages during encoding are underutilised, and the multiscale modules can only capture a limited range of receptive fields, albeit with considerable computational cost. This paper proposes a novel crowd counting architecture (FusionCount), which exploits the adaptive fusion of a large majority of encoded features instead of relying on additional extraction components to obtain multiscale features. Thus, it can cover a more extensive scope of receptive field sizes and lower the computational cost. We also introduce a new channel reduction block, which can extract saliency information during decoding and further enhance the model's performance. Experiments on two benchmark databases demonstrate that our model achieves state-of-the-art results with reduced computational complexity.
Look Closer: Bridging Egocentric and Third-Person Views with Transformers for Robotic Manipulation
Jan 20, 2022
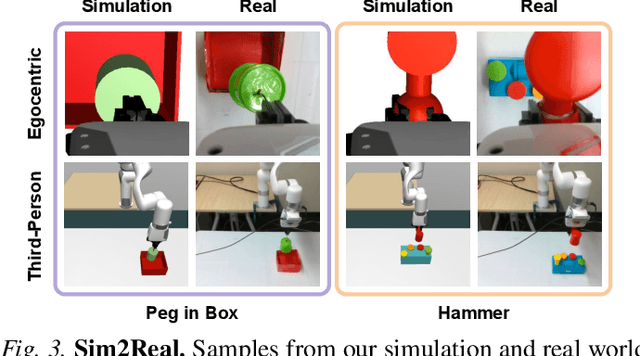
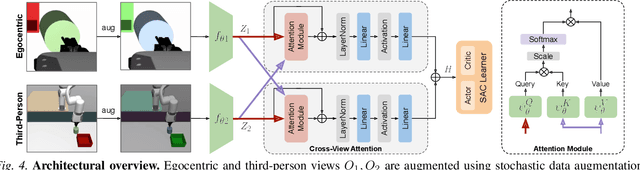

Learning to solve precision-based manipulation tasks from visual feedback using Reinforcement Learning (RL) could drastically reduce the engineering efforts required by traditional robot systems. However, performing fine-grained motor control from visual inputs alone is challenging, especially with a static third-person camera as often used in previous work. We propose a setting for robotic manipulation in which the agent receives visual feedback from both a third-person camera and an egocentric camera mounted on the robot's wrist. While the third-person camera is static, the egocentric camera enables the robot to actively control its vision to aid in precise manipulation. To fuse visual information from both cameras effectively, we additionally propose to use Transformers with a cross-view attention mechanism that models spatial attention from one view to another (and vice-versa), and use the learned features as input to an RL policy. Our method improves learning over strong single-view and multi-view baselines, and successfully transfers to a set of challenging manipulation tasks on a real robot with uncalibrated cameras, no access to state information, and a high degree of task variability. In a hammer manipulation task, our method succeeds in 75% of trials versus 38% and 13% for multi-view and single-view baselines, respectively.