 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Does constituency analysis enhance domain-specific pre-trained BERT models for relation extraction?
Nov 25, 2021
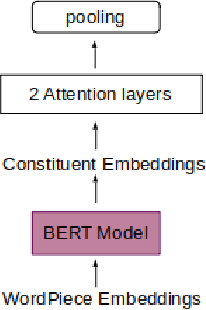
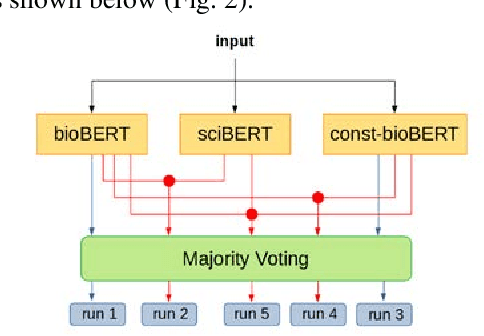
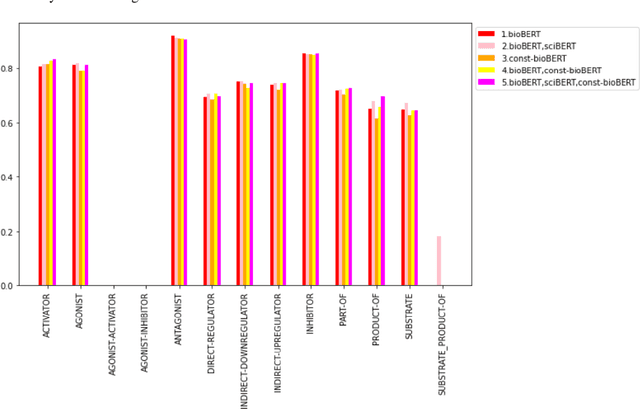
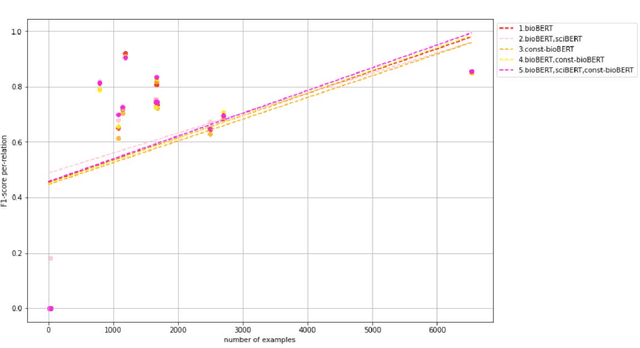
Recently many studies have been conducted on the topic of relation extraction. The DrugProt track at BioCreative VII provides a manually-annotated corpus for the purpose of the development and evaluation of relation extraction systems, in which interactions between chemicals and genes are studied. We describe the ensemble system that we used for our submission, which combines predictions of fine-tuned bioBERT, sciBERT and const-bioBERT models by majority voting. We specifically tested the contribution of syntactic information to relation extraction with BERT. We observed that adding constituentbased syntactic information to BERT improved precision, but decreased recall, since relations rarely seen in the train set were less likely to be predicted by BERT models in which the syntactic information is infused. Our code is available online [https://github.com/Maple177/drugprot-relation-extraction].
Improving Time Sensitivity for Question Answering over Temporal Knowledge Graphs
Mar 01, 2022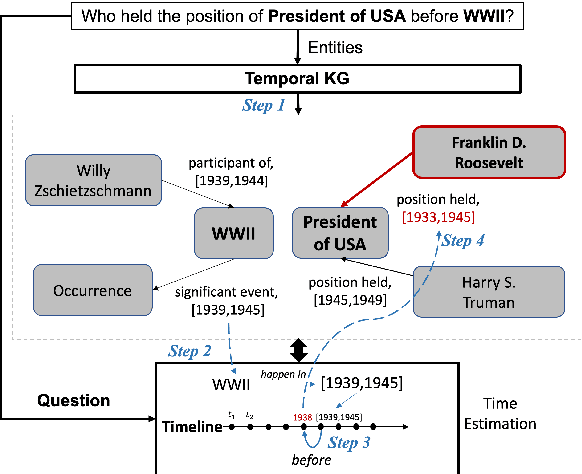
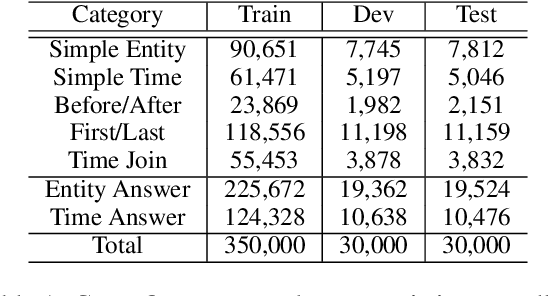
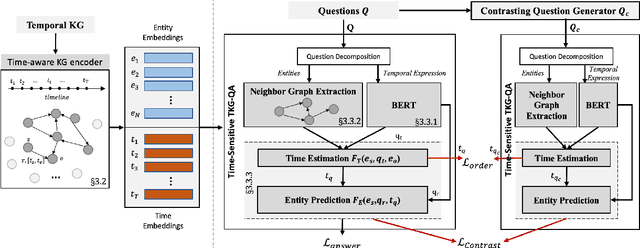
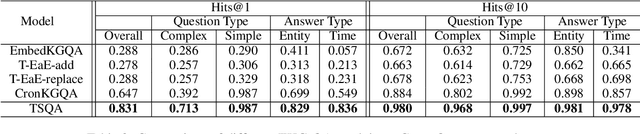
Question answering over temporal knowledge graphs (KGs) efficiently uses facts contained in a temporal KG, which records entity relations and when they occur in time, to answer natural language questions (e.g., "Who was the president of the US before Obama?"). These questions often involve three time-related challenges that previous work fail to adequately address: 1) questions often do not specify exact timestamps of interest (e.g., "Obama" instead of 2000); 2) subtle lexical differences in time relations (e.g., "before" vs "after"); 3) off-the-shelf temporal KG embeddings that previous work builds on ignore the temporal order of timestamps, which is crucial for answering temporal-order related questions. In this paper, we propose a time-sensitive question answering (TSQA) framework to tackle these problems. TSQA features a timestamp estimation module to infer the unwritten timestamp from the question. We also employ a time-sensitive KG encoder to inject ordering information into the temporal KG embeddings that TSQA is based on. With the help of techniques to reduce the search space for potential answers, TSQA significantly outperforms the previous state of the art on a new benchmark for question answering over temporal KGs, especially achieving a 32% (absolute) error reduction on complex questions that require multiple steps of reasoning over facts in the temporal KG.
* 10 pages, 2 figures
MISF: Multi-level Interactive Siamese Filtering for High-Fidelity Image Inpainting
Mar 12, 2022

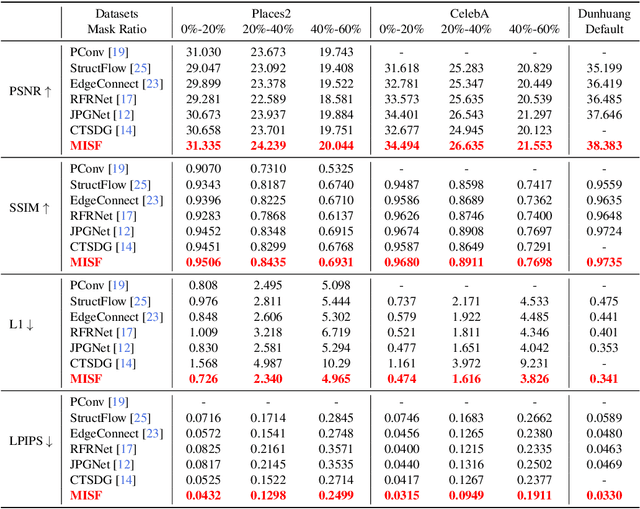
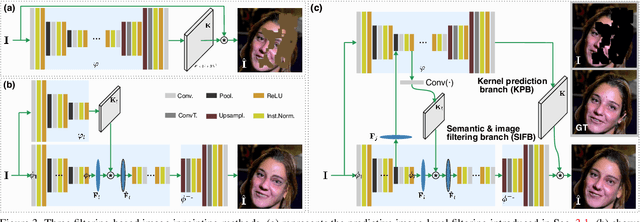
Although achieving significant progress, existing deep generative inpainting methods are far from real-world applications due to the low generalization across different scenes. As a result, the generated images usually contain artifacts or the filled pixels differ greatly from the ground truth. Image-level predictive filtering is a widely used image restoration technique, predicting suitable kernels adaptively according to different input scenes. Inspired by this inherent advantage, we explore the possibility of addressing image inpainting as a filtering task. To this end, we first study the advantages and challenges of image-level predictive filtering for image inpainting: the method can preserve local structures and avoid artifacts but fails to fill large missing areas. Then, we propose semantic filtering by conducting filtering on the deep feature level, which fills the missing semantic information but fails to recover the details. To address the issues while adopting the respective advantages, we propose a novel filtering technique, i.e., Multilevel Interactive Siamese Filtering (MISF), which contains two branches: kernel prediction branch (KPB) and semantic & image filtering branch (SIFB). These two branches are interactively linked: SIFB provides multi-level features for KPB while KPB predicts dynamic kernels for SIFB. As a result, the final method takes the advantage of effective semantic & image-level filling for high-fidelity inpainting. We validate our method on three challenging datasets, i.e., Dunhuang, Places2, and CelebA. Our method outperforms state-of-the-art baselines on four metrics, i.e., L1, PSNR, SSIM, and LPIPS. Please try the released code and model at https://github.com/tsingqguo/misf.
Boosting Entity Mention Detection for Targetted Twitter Streams with Global Contextual Embeddings
Jan 28, 2022
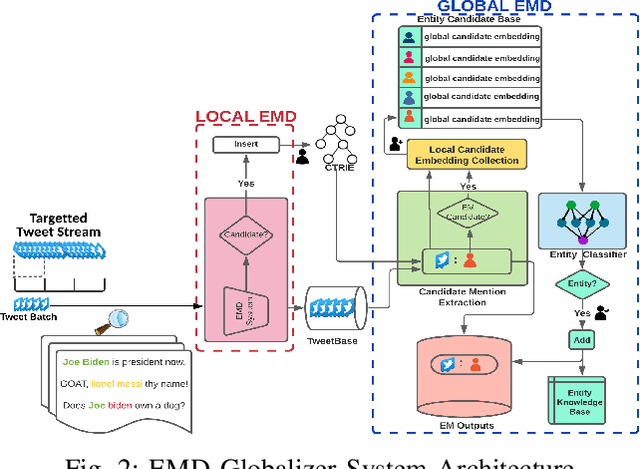
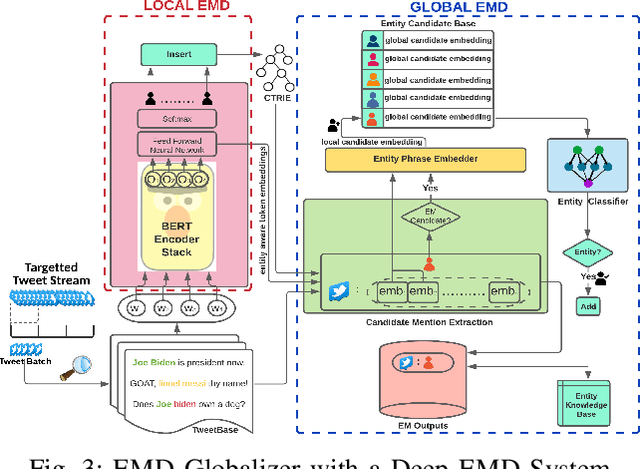
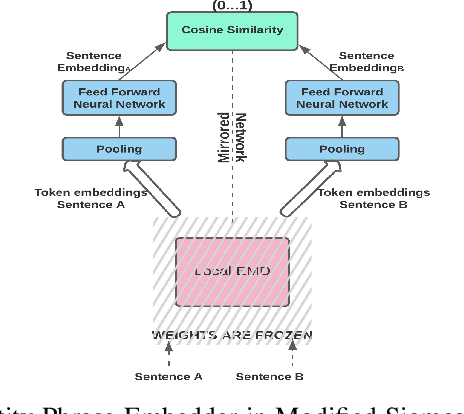
Microblogging sites, like Twitter, have emerged as ubiquitous sources of information. Two important tasks related to the automatic extraction and analysis of information in Microblogs are Entity Mention Detection (EMD) and Entity Detection (ED). The state-of-the-art EMD systems aim to model the non-literary nature of microblog text by training upon offline static datasets. They extract a combination of surface-level features -- orthographic, lexical, and semantic -- from individual messages for noisy text modeling and entity extraction. But given the constantly evolving nature of microblog streams, detecting all entity mentions from such varying yet limited context of short messages remains a difficult problem. To this end, we propose a framework named EMD Globalizer, better suited for the execution of EMD learners on microblog streams. It deviates from the processing of isolated microblog messages by existing EMD systems, where learned knowledge from the immediate context of a message is used to suggest entities. After an initial extraction of entity candidates by an EMD system, the proposed framework leverages occurrence mining to find additional candidate mentions that are missed during this first detection. Aggregating the local contextual representations of these mentions, a global embedding is drawn from the collective context of an entity candidate within a stream. The global embeddings are then utilized to separate entities within the candidates from false positives. All mentions of said entities from the stream are produced in the framework's final outputs. Our experiments show that EMD Globalizer can enhance the effectiveness of all existing EMD systems that we tested (on average by 25.61%) with a small additional computational overhead.
A Gating Model for Bias Calibration in Generalized Zero-shot Learning
Mar 08, 2022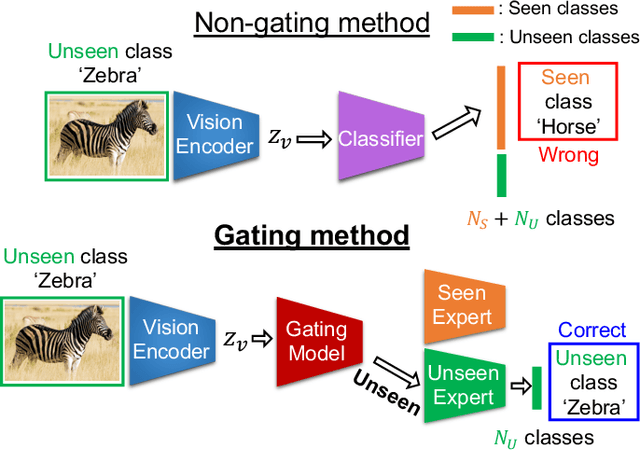
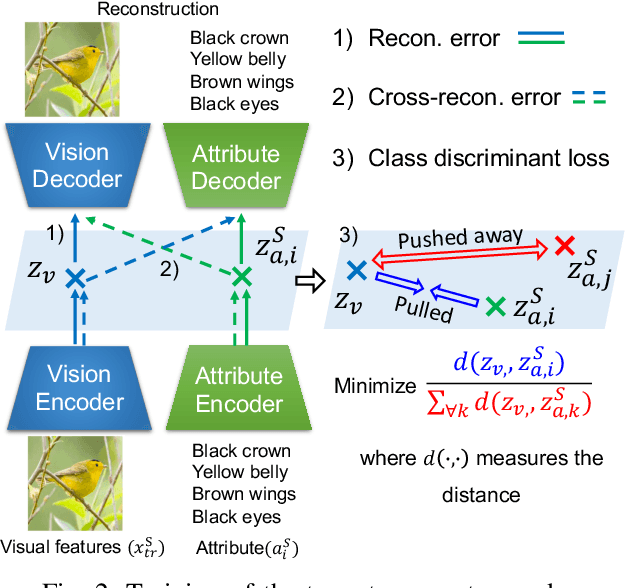
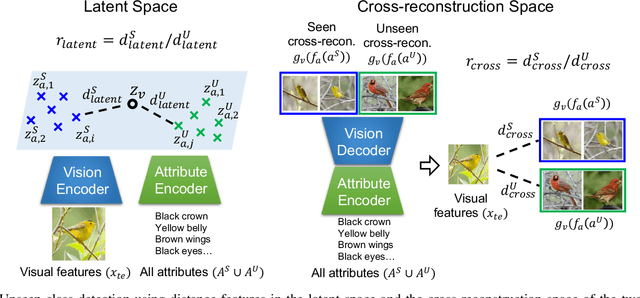

Generalized zero-shot learning (GZSL) aims at training a model that can generalize to unseen class data by only using auxiliary information. One of the main challenges in GZSL is a biased model prediction toward seen classes caused by overfitting on only available seen class data during training. To overcome this issue, we propose a two-stream autoencoder-based gating model for GZSL. Our gating model predicts whether the query data is from seen classes or unseen classes, and utilizes separate seen and unseen experts to predict the class independently from each other. This framework avoids comparing the biased prediction scores for seen classes with the prediction scores for unseen classes. In particular, we measure the distance between visual and attribute representations in the latent space and the cross-reconstruction space of the autoencoder. These distances are utilized as complementary features to characterize unseen classes at different levels of data abstraction. Also, the two-stream autoencoder works as a unified framework for the gating model and the unseen expert, which makes the proposed method computationally efficient. We validate our proposed method in four benchmark image recognition datasets. In comparison with other state-of-the-art methods, we achieve the best harmonic mean accuracy in SUN and AWA2, and the second best in CUB and AWA1. Furthermore, our base model requires at least 20% less number of model parameters than state-of-the-art methods relying on generative models.
An Analysis of Complex-Valued CNNs for RF Data-Driven Wireless Device Classification
Feb 20, 2022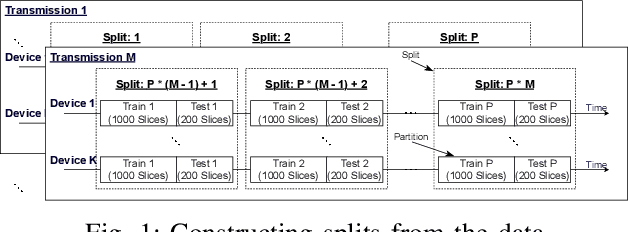
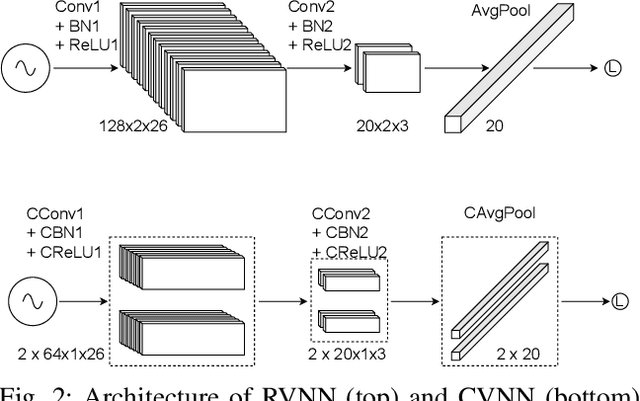
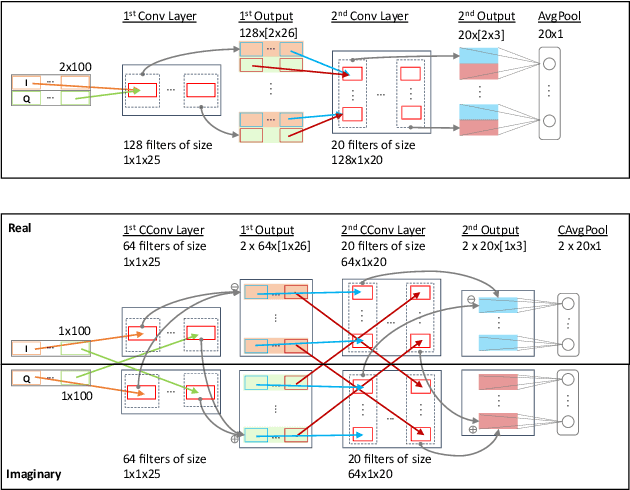
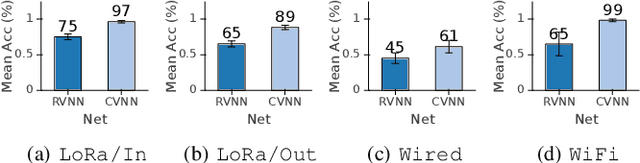
Recent deep neural network-based device classification studies show that complex-valued neural networks (CVNNs) yield higher classification accuracy than real-valued neural networks (RVNNs). Although this improvement is (intuitively) attributed to the complex nature of the input RF data (i.e., IQ symbols), no prior work has taken a closer look into analyzing such a trend in the context of wireless device identification. Our study provides a deeper understanding of this trend using real LoRa and WiFi RF datasets. We perform a deep dive into understanding the impact of (i) the input representation/type and (ii) the architectural layer of the neural network. For the input representation, we considered the IQ as well as the polar coordinates both partially and fully. For the architectural layer, we considered a series of ablation experiments that eliminate parts of the CVNN components. Our results show that CVNNs consistently outperform RVNNs counterpart in the various scenarios mentioned above, indicating that CVNNs are able to make better use of the joint information provided via the in-phase (I) and quadrature (Q) components of the signal.
ViF-SD2E: A Robust Weakly-Supervised Method for Neural Decoding
Dec 02, 2021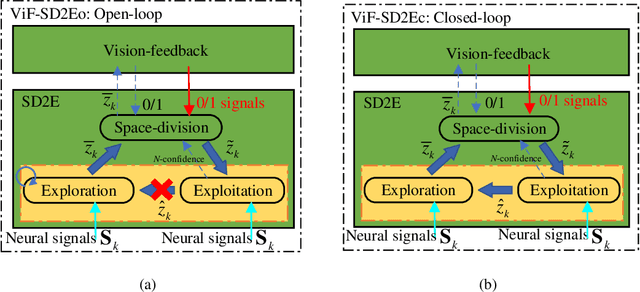
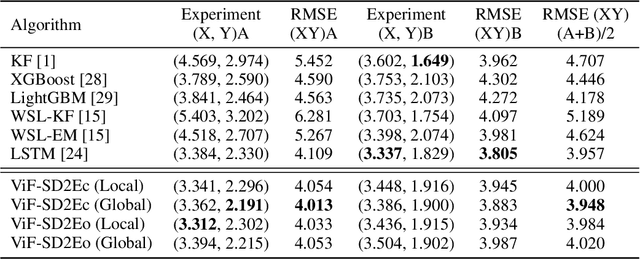
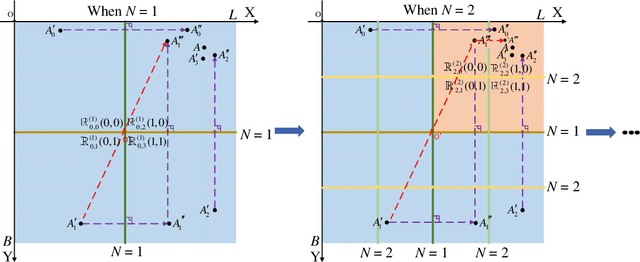
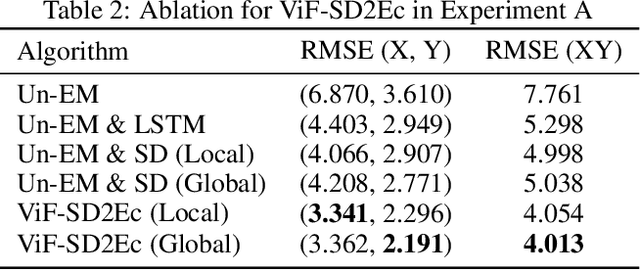
Neural decoding plays a vital role in the interaction between the brain and outside world. In this paper, we directly decode the movement track of the finger based on the neural signals of a macaque. The supervised regression methods may over-fit to actual labels contained with noise and require high labeling cost, while unsupervised approaches often have unsatisfactory accuracy. Besides, the spatial and temporal information are often ignored or not well exploited in these works. This motivates us to propose a robust weakly-supervised method termed ViF-SD2E for neural decoding. In particular, ViF-SD2E consists of a space-division (SD) module and a exploration-exploitation (2E) strategy, to effectively exploit both the spatial information of the outside world and temporal information of neural activity, where the SD2E output is compared with the weak 0/1 vision-feedback (ViF) label for training. Extensive experiments demonstrate the effectiveness of our method, which can be sometimes comparable to the supervised counterparts.
Inline Detection of DGA Domains Using Side Information
Mar 12, 2020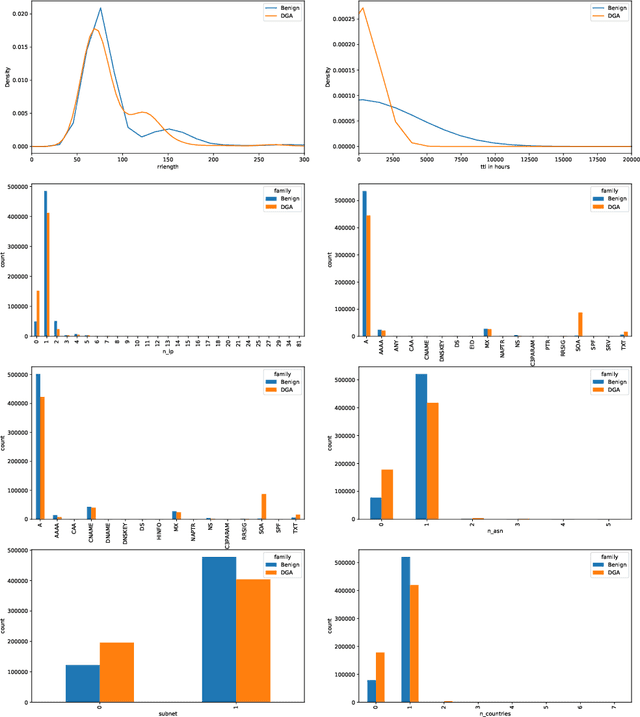


Malware applications typically use a command and control (C&C) server to manage bots to perform malicious activities. Domain Generation Algorithms (DGAs) are popular methods for generating pseudo-random domain names that can be used to establish a communication between an infected bot and the C&C server. In recent years, machine learning based systems have been widely used to detect DGAs. There are several well known state-of-the-art classifiers in the literature that can detect DGA domain names in real-time applications with high predictive performance. However, these DGA classifiers are highly vulnerable to adversarial attacks in which adversaries purposely craft domain names to evade DGA detection classifiers. In our work, we focus on hardening DGA classifiers against adversarial attacks. To this end, we train and evaluate state-of-the-art deep learning and random forest (RF) classifiers for DGA detection using side information that is harder for adversaries to manipulate than the domain name itself. Additionally, the side information features are selected such that they are easily obtainable in practice to perform inline DGA detection. The performance and robustness of these models is assessed by exposing them to one day of real-traffic data as well as domains generated by adversarial attack algorithms. We found that the DGA classifiers that rely on both the domain name and side information have high performance and are more robust against adversaries.
Long Document Summarization with Top-down and Bottom-up Inference
Mar 15, 2022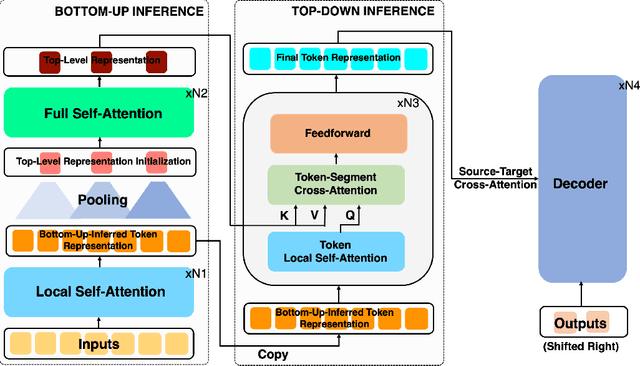
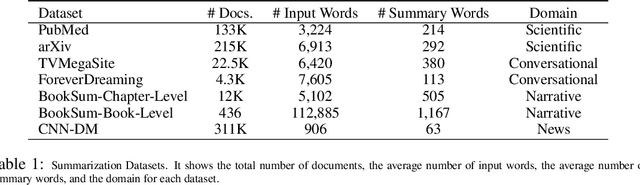
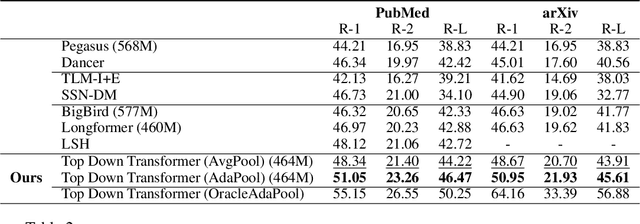

Text summarization aims to condense long documents and retain key information. Critical to the success of a summarization model is the faithful inference of latent representations of words or tokens in the source documents. Most recent models infer the latent representations with a transformer encoder, which is purely bottom-up. Also, self-attention-based inference models face the challenge of quadratic complexity with respect to sequence length. We propose a principled inference framework to improve summarization models on these two aspects. Our framework assumes a hierarchical latent structure of a document where the top-level captures the long range dependency at a coarser time scale and the bottom token level preserves the details. Critically, this hierarchical structure enables token representations to be updated in both a bottom-up and top-down manner. In the bottom-up pass, token representations are inferred with local self-attention to leverage its efficiency. Top-down correction is then applied to allow tokens to capture long-range dependency. We demonstrate the effectiveness of the proposed framework on a diverse set of summarization datasets, including narrative, conversational, scientific documents and news. Our model achieves (1) competitive or better performance on short documents with higher memory and compute efficiency, compared to full attention transformers, and (2) state-of-the-art performance on a wide range of long document summarization benchmarks, compared to recent efficient transformers. We also show that our model can summarize an entire book and achieve competitive performance using $0.27\%$ parameters (464M vs. 175B) and much less training data, compared to a recent GPT-3-based model. These results indicate the general applicability and benefits of the proposed framework.
TwistSLAM: Constrained SLAM in Dynamic Environment
Feb 24, 2022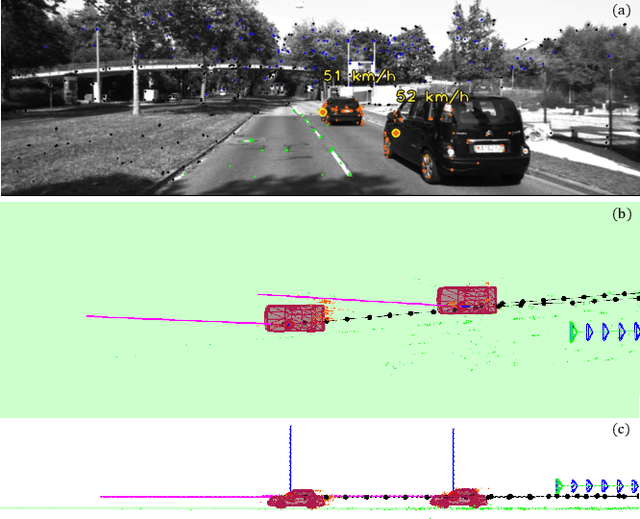
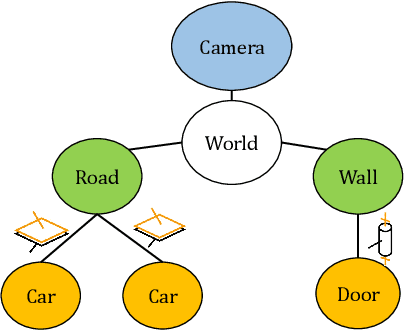
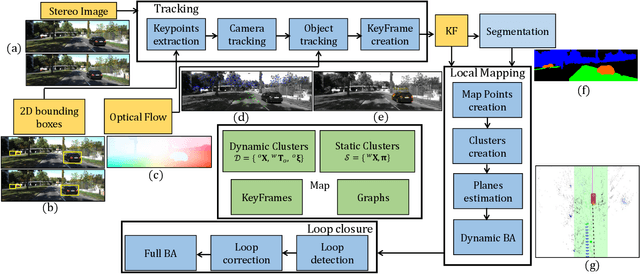
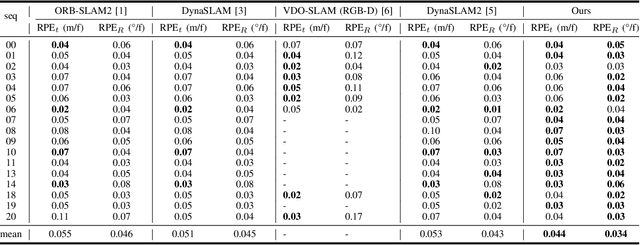
Moving objects are present in most scenes of our life. However they can be very problematic for classical SLAM algorithms that assume the scene to be rigid. This assumption limits the applicability of those algorithms as they are unable to accurately estimate the camera pose and world structure in many scenarios. Some SLAM systems have been proposed to detect and mask out dynamic objects, making the static scene assumption valid. However this information can allow the system to track objects within the scene, while tracking the camera, which can be crucial for some applications. In this paper we present TwistSLAM a semantic, dynamic, stereo SLAM system that can track dynamic objects in the scene. Our algorithm creates clusters of points according to their semantic class. It uses the static parts of the environment to robustly localize the camera and tracks the remaining objects. We propose a new formulation for the tracking and the bundle adjustment to take in account the characteristics of mechanical joints between clusters to constrain and improve their pose estimation. We evaluate our approach on several sequences from a public dataset and show that we improve camera and object tracking compared to state of the art.