 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Does constituency analysis enhance domain-specific pre-trained BERT models for relation extraction?
Nov 25, 2021
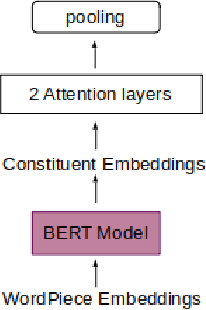
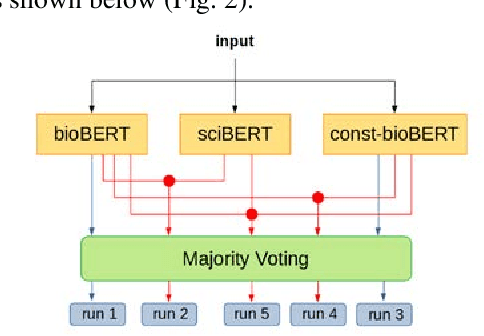
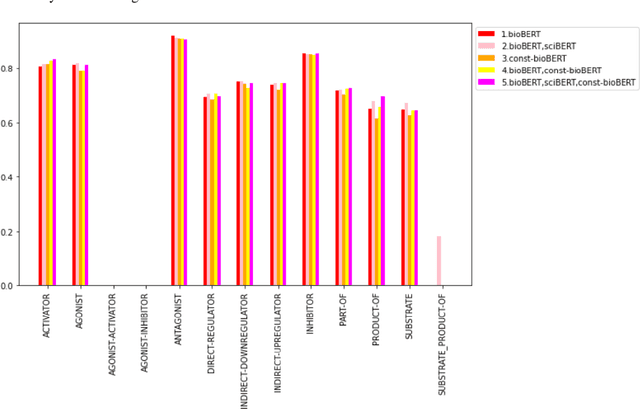
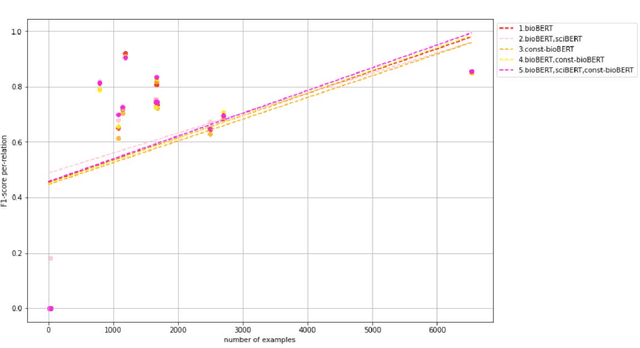
Recently many studies have been conducted on the topic of relation extraction. The DrugProt track at BioCreative VII provides a manually-annotated corpus for the purpose of the development and evaluation of relation extraction systems, in which interactions between chemicals and genes are studied. We describe the ensemble system that we used for our submission, which combines predictions of fine-tuned bioBERT, sciBERT and const-bioBERT models by majority voting. We specifically tested the contribution of syntactic information to relation extraction with BERT. We observed that adding constituentbased syntactic information to BERT improved precision, but decreased recall, since relations rarely seen in the train set were less likely to be predicted by BERT models in which the syntactic information is infused. Our code is available online [https://github.com/Maple177/drugprot-relation-extraction].
Phase-based Information for Voice Pathology Detection
Jan 02, 2020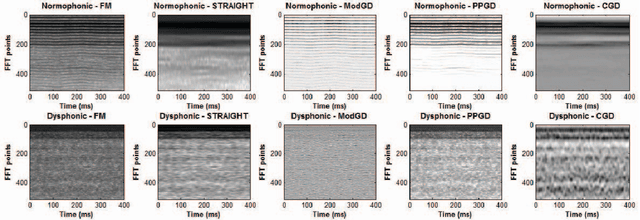


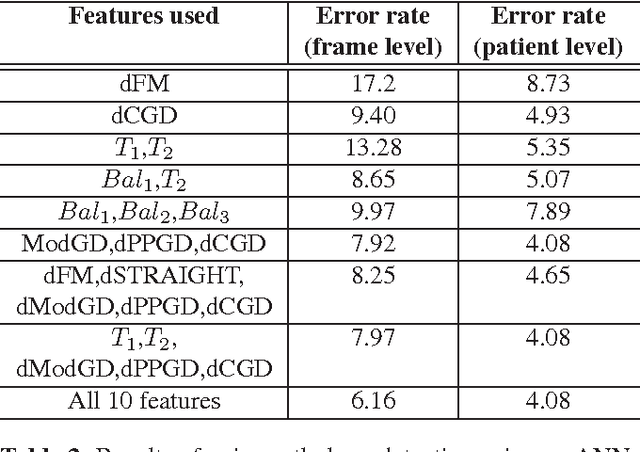
In most current approaches of speech processing, information is extracted from the magnitude spectrum. However recent perceptual studies have underlined the importance of the phase component. The goal of this paper is to investigate the potential of using phase-based features for automatically detecting voice disorders. It is shown that group delay functions are appropriate for characterizing irregularities in the phonation. Besides the respect of the mixed-phase model of speech is discussed. The proposed phase-based features are evaluated and compared to other parameters derived from the magnitude spectrum. Both streams are shown to be interestingly complementary. Furthermore phase-based features turn out to convey a great amount of relevant information, leading to high discrimination performance.
Personalized Keyphrase Detection using Speaker and Environment Information
Apr 28, 2021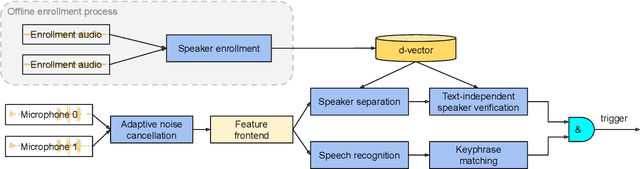
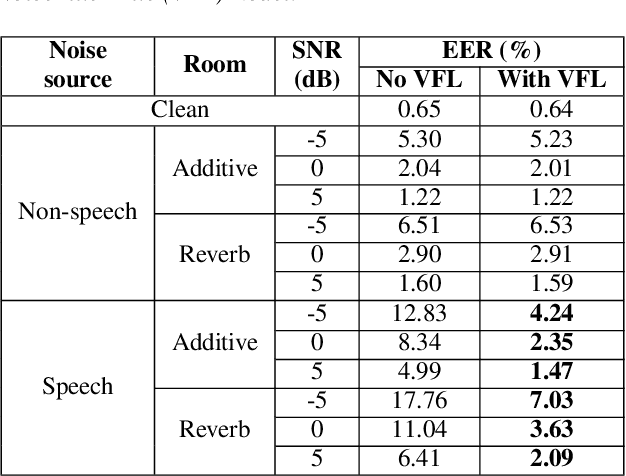
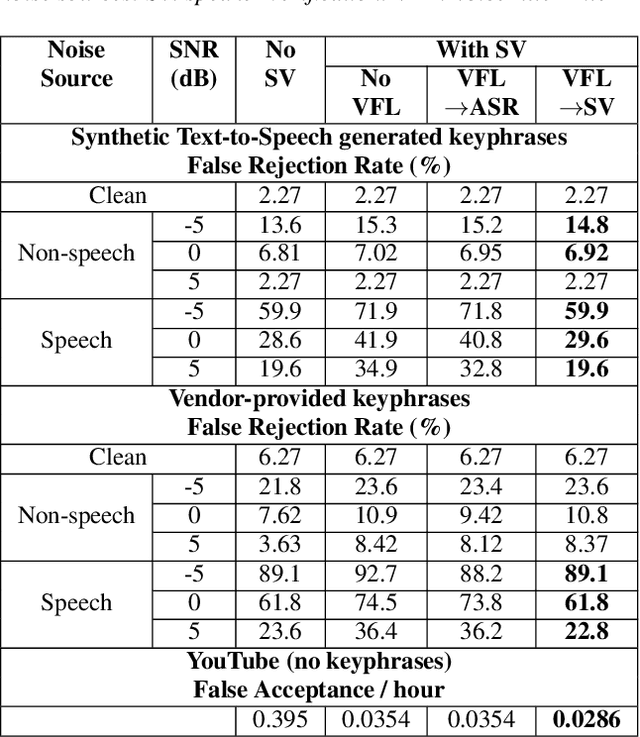
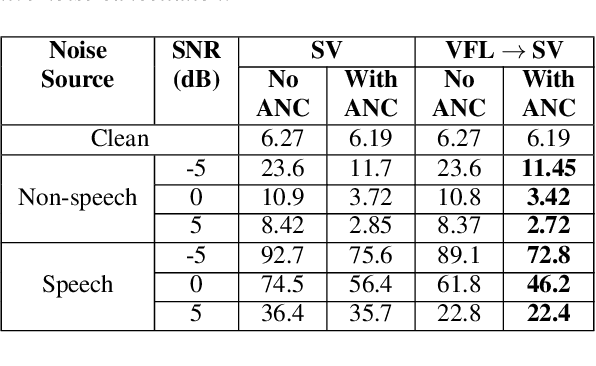
In this paper, we introduce a streaming keyphrase detection system that can be easily customized to accurately detect any phrase composed of words from a large vocabulary. The system is implemented with an end-to-end trained automatic speech recognition (ASR) model and a text-independent speaker verification model. To address the challenge of detecting these keyphrases under various noisy conditions, a speaker separation model is added to the feature frontend of the speaker verification model, and an adaptive noise cancellation (ANC) algorithm is included to exploit cross-microphone noise coherence. Our experiments show that the text-independent speaker verification model largely reduces the false triggering rate of the keyphrase detection, while the speaker separation model and adaptive noise cancellation largely reduce false rejections.
Bringing Rolling Shutter Images Alive with Dual Reversed Distortion
Mar 12, 2022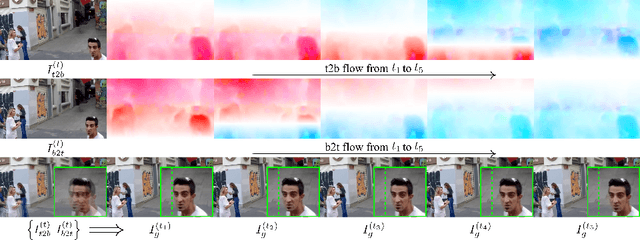

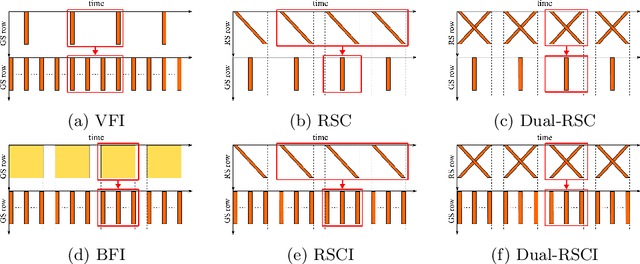
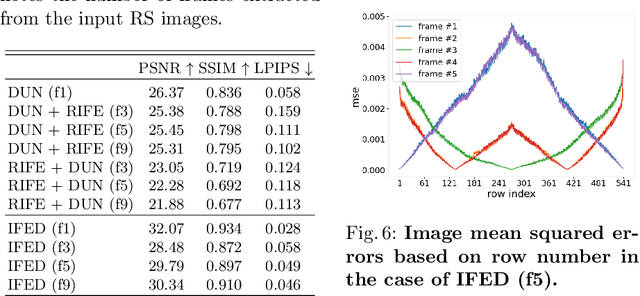
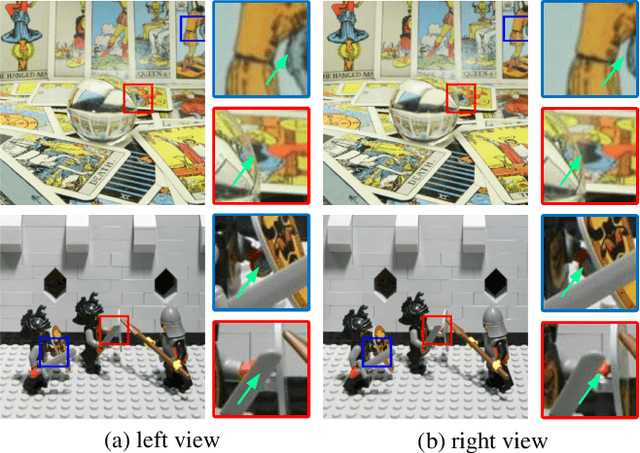
Rolling shutter (RS) distortion can be interpreted as the result of picking a row of pixels from instant global shutter (GS) frames over time during the exposure of the RS camera. This means that the information of each instant GS frame is partially, yet sequentially, embedded into the row-dependent distortion. Inspired by this fact, we address the challenging task of reversing this process, i.e., extracting undistorted GS frames from images suffering from RS distortion. However, since RS distortion is coupled with other factors such as readout settings and the relative velocity of scene elements to the camera, models that only exploit the geometric correlation between temporally adjacent images suffer from poor generality in processing data with different readout settings and dynamic scenes with both camera motion and object motion. In this paper, instead of two consecutive frames, we propose to exploit a pair of images captured by dual RS cameras with reversed RS directions for this highly challenging task. Grounded on the symmetric and complementary nature of dual reversed distortion, we develop a novel end-to-end model, IFED, to generate dual optical flow sequence through iterative learning of the velocity field during the RS time. Extensive experimental results demonstrate that IFED is superior to naive cascade schemes, as well as the state-of-the-art which utilizes adjacent RS images. Most importantly, although it is trained on a synthetic dataset, IFED is shown to be effective at retrieving GS frame sequences from real-world RS distorted images of dynamic scenes.
Dense Dual-Attention Network for Light Field Image Super-Resolution
Oct 23, 2021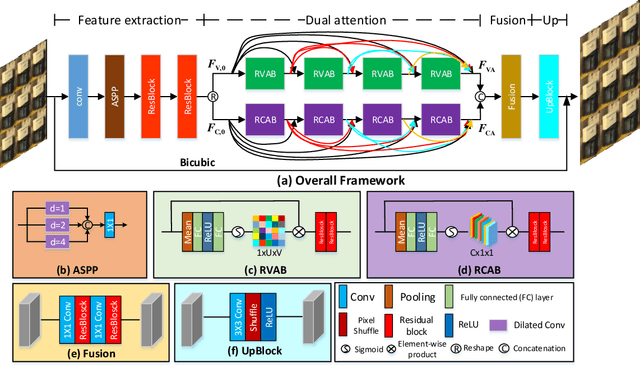
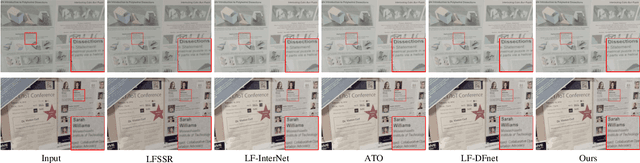

Light field (LF) images can be used to improve the performance of image super-resolution (SR) because both angular and spatial information is available. It is challenging to incorporate distinctive information from different views for LF image SR. Moreover, the long-term information from the previous layers can be weakened as the depth of network increases. In this paper, we propose a dense dual-attention network for LF image SR. Specifically, we design a view attention module to adaptively capture discriminative features across different views and a channel attention module to selectively focus on informative information across all channels. These two modules are fed to two branches and stacked separately in a chain structure for adaptive fusion of hierarchical features and distillation of valid information. Meanwhile, a dense connection is used to fully exploit multi-level information. Extensive experiments demonstrate that our dense dual-attention mechanism can capture informative information across views and channels to improve SR performance. Comparative results show the advantage of our method over state-of-the-art methods on public datasets.
'Moving On' -- Investigating Inventors' Ethnic Origins Using Supervised Learning
Jan 03, 2022
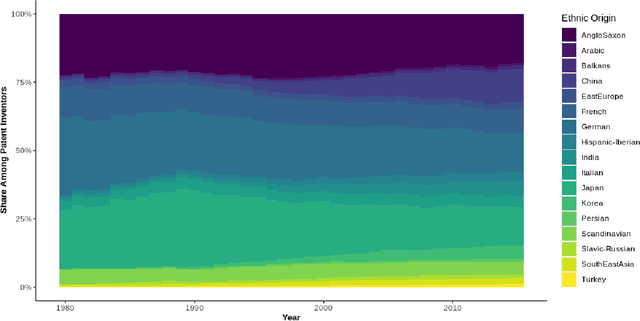
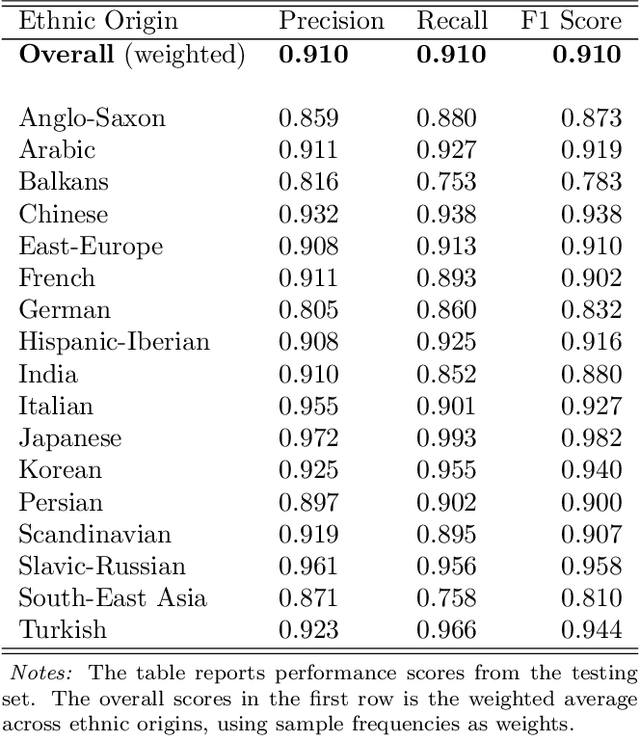
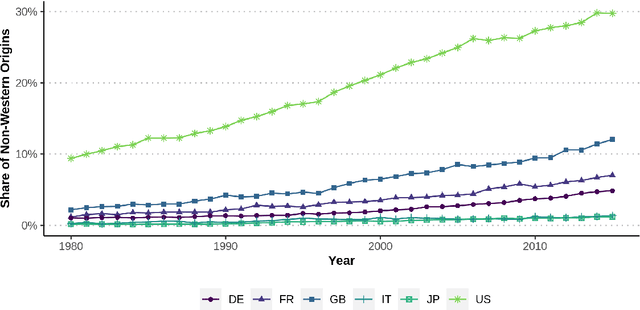
Patent data provides rich information about technical inventions, but does not disclose the ethnic origin of inventors. In this paper, I use supervised learning techniques to infer this information. To do so, I construct a dataset of 95'202 labeled names and train an artificial recurrent neural network with long-short-term memory (LSTM) to predict ethnic origins based on names. The trained network achieves an overall performance of 91% across 17 ethnic origins. I use this model to classify and investigate the ethnic origins of 2.68 million inventors and provide novel descriptive evidence regarding their ethnic origin composition over time and across countries and technological fields. The global ethnic origin composition has become more diverse over the last decades, which was mostly due to a relative increase of Asian origin inventors. Furthermore, the prevalence of foreign-origin inventors is especially high in the USA, but has also increased in other high-income economies. This increase was mainly driven by an inflow of non-western inventors into emerging high-technology fields for the USA, but not for other high-income countries.
SOInter: A Novel Deep Energy Based Interpretation Method for Explaining Structured Output Models
Feb 20, 2022
We propose a novel interpretation technique to explain the behavior of structured output models, which learn mappings between an input vector to a set of output variables simultaneously. Because of the complex relationship between the computational path of output variables in structured models, a feature can affect the value of output through other ones. We focus on one of the outputs as the target and try to find the most important features utilized by the structured model to decide on the target in each locality of the input space. In this paper, we assume an arbitrary structured output model is available as a black box and argue how considering the correlations between output variables can improve the explanation performance. The goal is to train a function as an interpreter for the target output variable over the input space. We introduce an energy-based training process for the interpreter function, which effectively considers the structural information incorporated into the model to be explained. The effectiveness of the proposed method is confirmed using a variety of simulated and real data sets.
Retrieval-Augmented Reinforcement Learning
Mar 09, 2022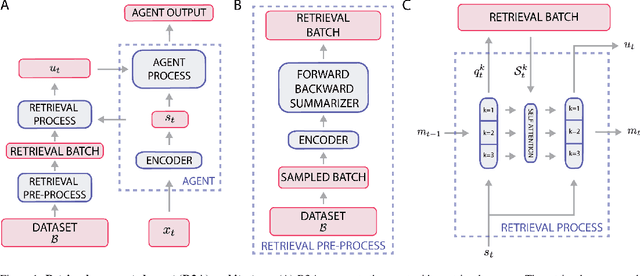

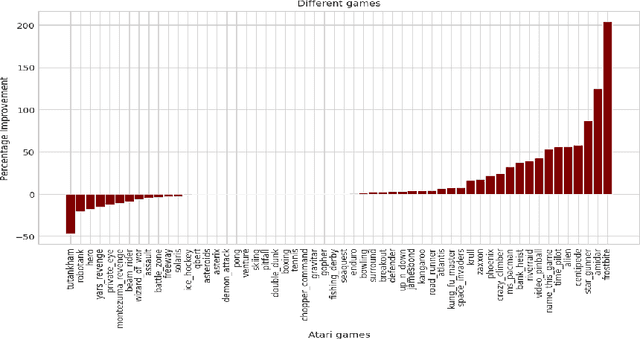
Most deep reinforcement learning (RL) algorithms distill experience into parametric behavior policies or value functions via gradient updates. While effective, this approach has several disadvantages: (1) it is computationally expensive, (2) it can take many updates to integrate experiences into the parametric model, (3) experiences that are not fully integrated do not appropriately influence the agent's behavior, and (4) behavior is limited by the capacity of the model. In this paper we explore an alternative paradigm in which we train a network to map a dataset of past experiences to optimal behavior. Specifically, we augment an RL agent with a retrieval process (parameterized as a neural network) that has direct access to a dataset of experiences. This dataset can come from the agent's past experiences, expert demonstrations, or any other relevant source. The retrieval process is trained to retrieve information from the dataset that may be useful in the current context, to help the agent achieve its goal faster and more efficiently. We integrate our method into two different RL agents: an offline DQN agent and an online R2D2 agent. In offline multi-task problems, we show that the retrieval-augmented DQN agent avoids task interference and learns faster than the baseline DQN agent. On Atari, we show that retrieval-augmented R2D2 learns significantly faster than the baseline R2D2 agent and achieves higher scores. We run extensive ablations to measure the contributions of the components of our proposed method.
Deep learning-based conditional inpainting for restoration of artifact-affected 4D CT images
Mar 12, 2022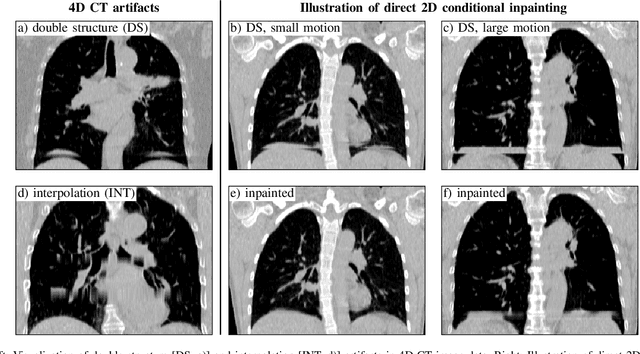
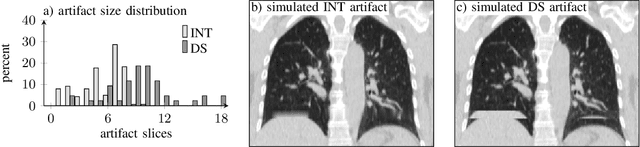
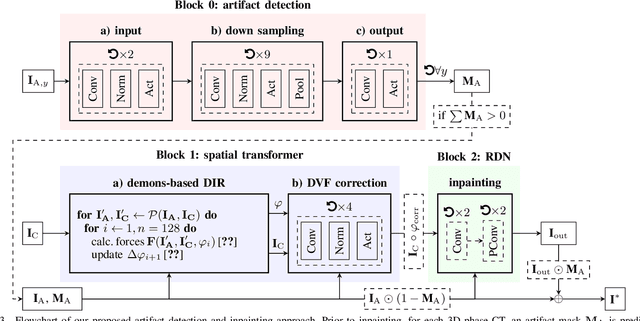
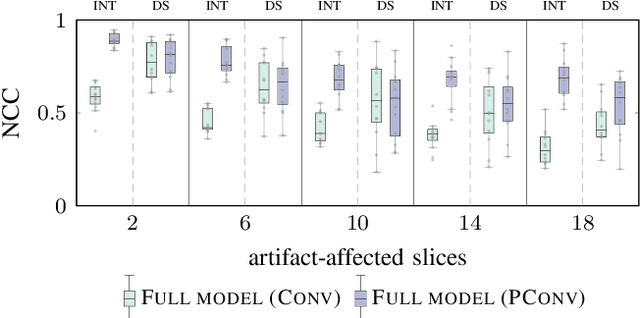
4D CT imaging is an essential component of radiotherapy of thoracic/abdominal tumors. 4D CT images are, however, often affected by artifacts that compromise treatment planning quality. In this work, deep learning (DL)-based conditional inpainting is proposed to restore anatomically correct image information of artifact-affected areas. The restoration approach consists of a two-stage process: DL-based detection of common interpolation (INT) and double structure (DS) artifacts, followed by conditional inpainting applied to the artifact areas. In this context, conditional refers to a guidance of the inpainting process by patient-specific image data to ensure anatomically reliable results. Evaluation is based on 65 in-house 4D CT data sets of lung cancer patients (48 with only slight artifacts, 17 with pronounced artifacts) and the publicly available DIRLab 4D CT data (independent external test set). Automated artifact detection revealed a ROC-AUC of 0.99 for INT and 0.97 for DS artifacts (in-house data). The proposed inpainting method decreased the average root mean squared error (RMSE) by 60% (DS) and 42% (INT) for the in-house evaluation data (simulated artifacts for the slight artifact data; original data were considered as ground truth for RMSE computation). For the external DIR-Lab data, the RMSE decreased by 65% and 36%, respectively. Applied to the pronounced artifact data group, on average 68% of the detectable artifacts were removed. The results highlight the potential of DL-based inpainting for the restoration of artifact-affected 4D CT data. Improved performance of conditional inpainting (compared to standard inpainting) illustrates the benefits of exploiting patient-specific prior knowledge.
ViF-SD2E: A Robust Weakly-Supervised Method for Neural Decoding
Dec 02, 2021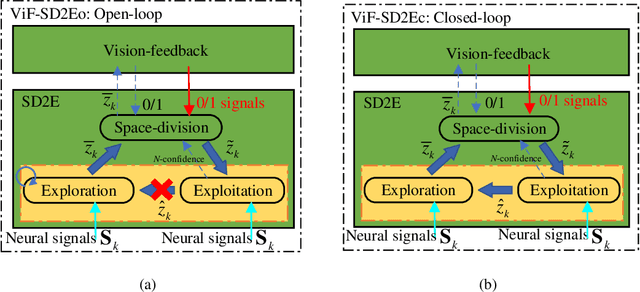
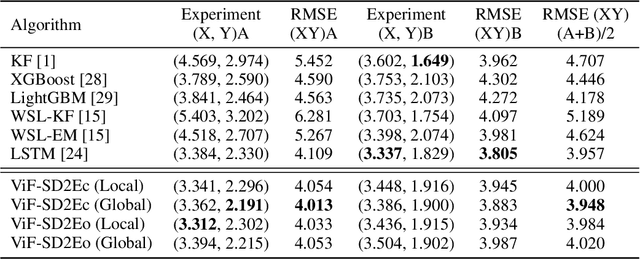
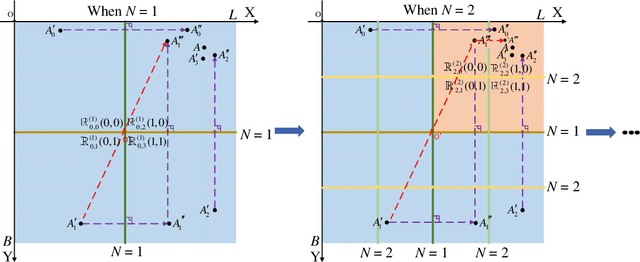
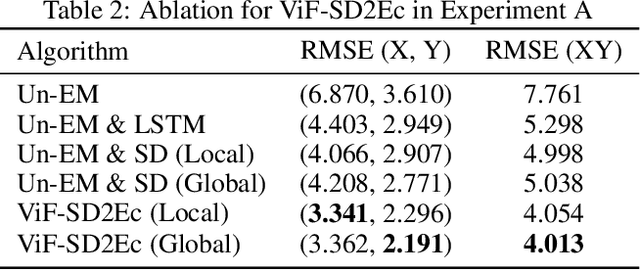
Neural decoding plays a vital role in the interaction between the brain and outside world. In this paper, we directly decode the movement track of the finger based on the neural signals of a macaque. The supervised regression methods may over-fit to actual labels contained with noise and require high labeling cost, while unsupervised approaches often have unsatisfactory accuracy. Besides, the spatial and temporal information are often ignored or not well exploited in these works. This motivates us to propose a robust weakly-supervised method termed ViF-SD2E for neural decoding. In particular, ViF-SD2E consists of a space-division (SD) module and a exploration-exploitation (2E) strategy, to effectively exploit both the spatial information of the outside world and temporal information of neural activity, where the SD2E output is compared with the weak 0/1 vision-feedback (ViF) label for training. Extensive experiments demonstrate the effectiveness of our method, which can be sometimes comparable to the supervised counterparts.