 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Convex Information Bottleneck Lagrangian
Jan 10, 2020
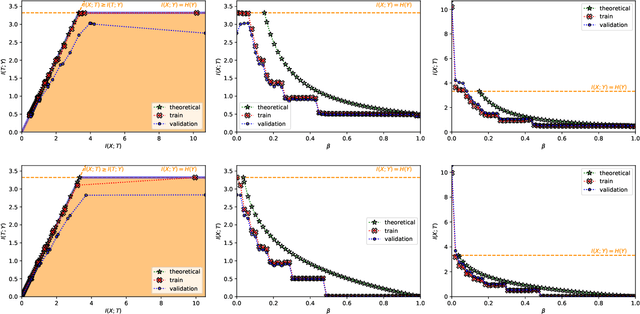
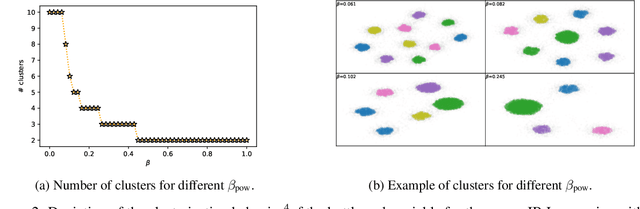
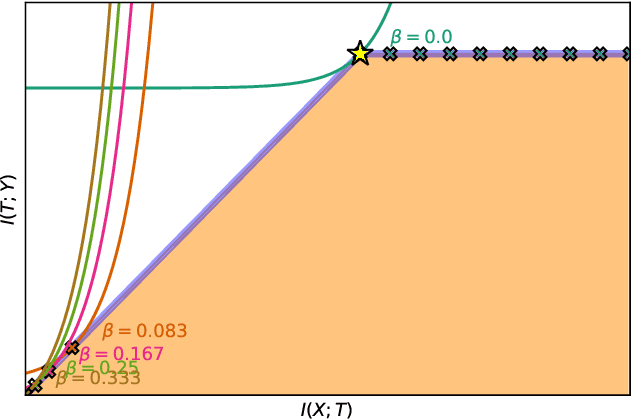
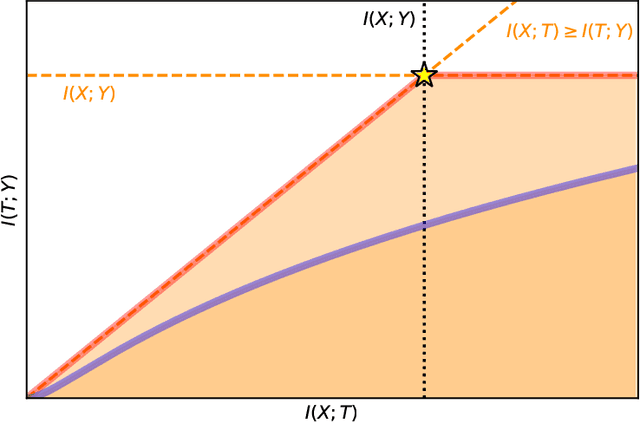
The information bottleneck (IB) problem tackles the issue of obtaining relevant compressed representations $T$ of some random variable $X$ for the task of predicting $Y$. It is defined as a constrained optimization problem which maximizes the information the representation has about the task, $I(T;Y)$, while ensuring that a certain level of compression $r$ is achieved (i.e., $ I(X;T) \leq r$). For practical reasons, the problem is usually solved by maximizing the IB Lagrangian (i.e., $\mathcal{L}_{\text{IB}}(T;\beta) = I(T;Y) - \beta I(X;T)$) for many values of $\beta \in [0,1]$. Then, the curve of maximal $I(T;Y)$ for a given $I(X;T)$ is drawn and a representation with the desired predictability and compression is selected. It is known when $Y$ is a deterministic function of $X$, the IB curve cannot be explored and another Lagrangian has been proposed to tackle this problem: the squared IB Lagrangian: $\mathcal{L}_{\text{sq-IB}}(T;\beta_{\text{sq}})=I(T;Y)-\beta_{\text{sq}}I(X;T)^2$. In this paper, we (i) present a general family of Lagrangians which allow for the exploration of the IB curve in all scenarios; (ii) provide the exact one-to-one mapping between the Lagrange multiplier and the desired compression rate $r$ for known IB curve shapes; and (iii) show we can approximately obtain a specific compression level with the convex IB Lagrangian for both known and unknown IB curve shapes. This eliminates the burden of solving the optimization problem for many values of the Lagrange multiplier. That is, we prove that we can solve the original constrained problem with a single optimization.
Deep learning-based conditional inpainting for restoration of artifact-affected 4D CT images
Mar 12, 2022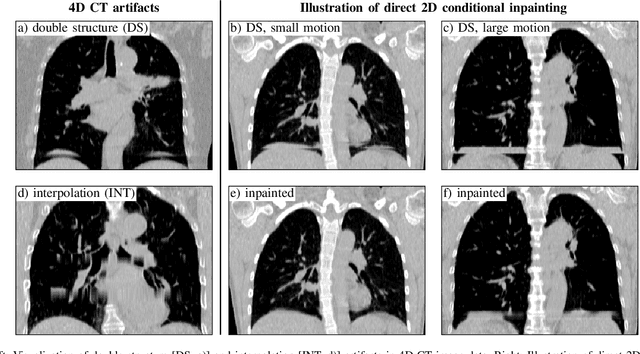
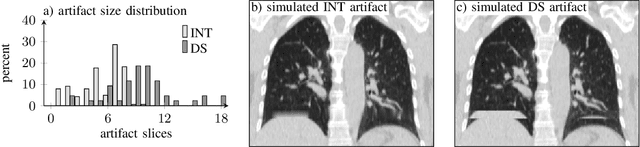
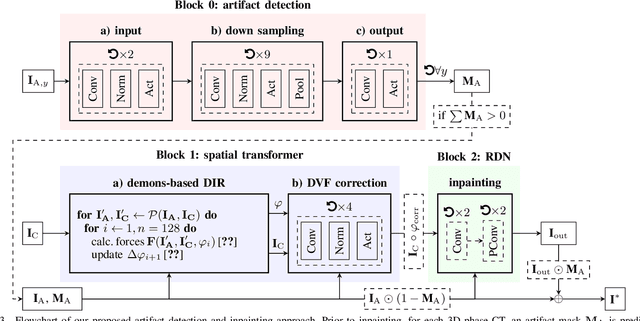
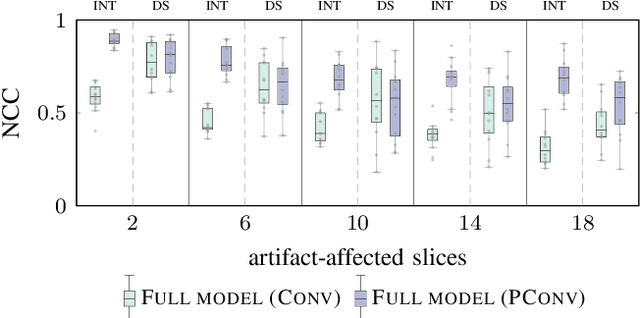
4D CT imaging is an essential component of radiotherapy of thoracic/abdominal tumors. 4D CT images are, however, often affected by artifacts that compromise treatment planning quality. In this work, deep learning (DL)-based conditional inpainting is proposed to restore anatomically correct image information of artifact-affected areas. The restoration approach consists of a two-stage process: DL-based detection of common interpolation (INT) and double structure (DS) artifacts, followed by conditional inpainting applied to the artifact areas. In this context, conditional refers to a guidance of the inpainting process by patient-specific image data to ensure anatomically reliable results. Evaluation is based on 65 in-house 4D CT data sets of lung cancer patients (48 with only slight artifacts, 17 with pronounced artifacts) and the publicly available DIRLab 4D CT data (independent external test set). Automated artifact detection revealed a ROC-AUC of 0.99 for INT and 0.97 for DS artifacts (in-house data). The proposed inpainting method decreased the average root mean squared error (RMSE) by 60% (DS) and 42% (INT) for the in-house evaluation data (simulated artifacts for the slight artifact data; original data were considered as ground truth for RMSE computation). For the external DIR-Lab data, the RMSE decreased by 65% and 36%, respectively. Applied to the pronounced artifact data group, on average 68% of the detectable artifacts were removed. The results highlight the potential of DL-based inpainting for the restoration of artifact-affected 4D CT data. Improved performance of conditional inpainting (compared to standard inpainting) illustrates the benefits of exploiting patient-specific prior knowledge.
Retrieval-Augmented Reinforcement Learning
Mar 09, 2022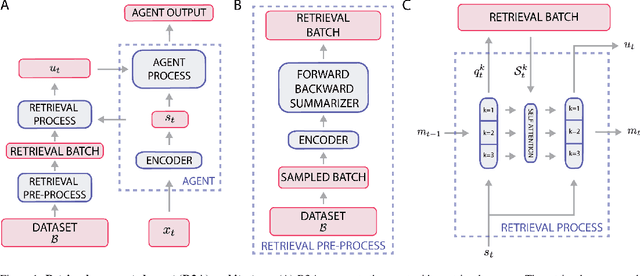

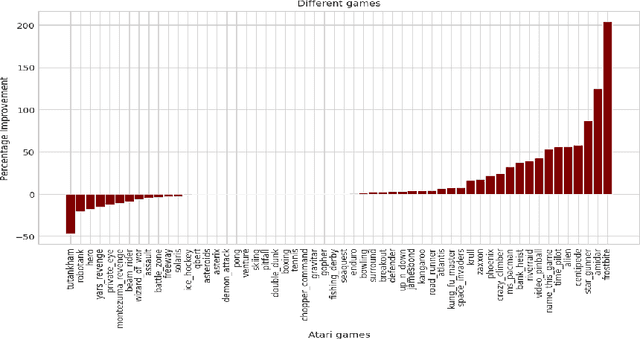
Most deep reinforcement learning (RL) algorithms distill experience into parametric behavior policies or value functions via gradient updates. While effective, this approach has several disadvantages: (1) it is computationally expensive, (2) it can take many updates to integrate experiences into the parametric model, (3) experiences that are not fully integrated do not appropriately influence the agent's behavior, and (4) behavior is limited by the capacity of the model. In this paper we explore an alternative paradigm in which we train a network to map a dataset of past experiences to optimal behavior. Specifically, we augment an RL agent with a retrieval process (parameterized as a neural network) that has direct access to a dataset of experiences. This dataset can come from the agent's past experiences, expert demonstrations, or any other relevant source. The retrieval process is trained to retrieve information from the dataset that may be useful in the current context, to help the agent achieve its goal faster and more efficiently. We integrate our method into two different RL agents: an offline DQN agent and an online R2D2 agent. In offline multi-task problems, we show that the retrieval-augmented DQN agent avoids task interference and learns faster than the baseline DQN agent. On Atari, we show that retrieval-augmented R2D2 learns significantly faster than the baseline R2D2 agent and achieves higher scores. We run extensive ablations to measure the contributions of the components of our proposed method.
Real-time automatic polyp detection in colonoscopy using feature enhancement module and spatiotemporal similarity correlation unit
Jan 25, 2022Automatic detection of polyps is challenging because different polyps vary greatly, while the changes between polyps and their analogues are small. The state-of-the-art methods are based on convolutional neural networks (CNNs). However, they may fail due to lack of training data, resulting in high rates of missed detection and false positives (FPs). In order to solve these problems, our method combines the two-dimensional (2-D) CNN-based real-time object detector network with spatiotemporal information. Firstly, we use a 2-D detector network to detect static images and frames, and based on the detector network, we propose two feature enhancement modules-the FP Relearning Module (FPRM) to make the detector network learning more about the features of FPs for higher precision, and the Image Style Transfer Module (ISTM) to enhance the features of polyps for sensitivity improvement. In video detection, we integrate spatiotemporal information, which uses Structural Similarity (SSIM) to measure the similarity between video frames. Finally, we propose the Inter-frame Similarity Correlation Unit (ISCU) to combine the results obtained by the detector network and frame similarity to make the final decision. We verify our method on both private databases and publicly available databases. Experimental results show that these modules and units provide a performance improvement compared with the baseline method. Comparison with the state-of-the-art methods shows that the proposed method outperforms the existing ones which can meet real-time constraints. It's demonstrated that our method provides a performance improvement in sensitivity, precision and specificity, and has great potential to be applied in clinical colonoscopy.
* This paper has been accepted by Biomedical Signal Processing and Control. Please cite the paper as Xu, J., Zhao, R., Yu, Y., Zhang, Q., Bian, X., Wang, J., Ge, Z., Qian, D., 2021. Real-time automatic polyp detection in colonoscopy using feature enhancement module and spatiotemporal similarity correlation unit. Biomedical Signal Processing and Control 66, 102503
Dependence model assessment and selection with DecoupleNets
Feb 07, 2022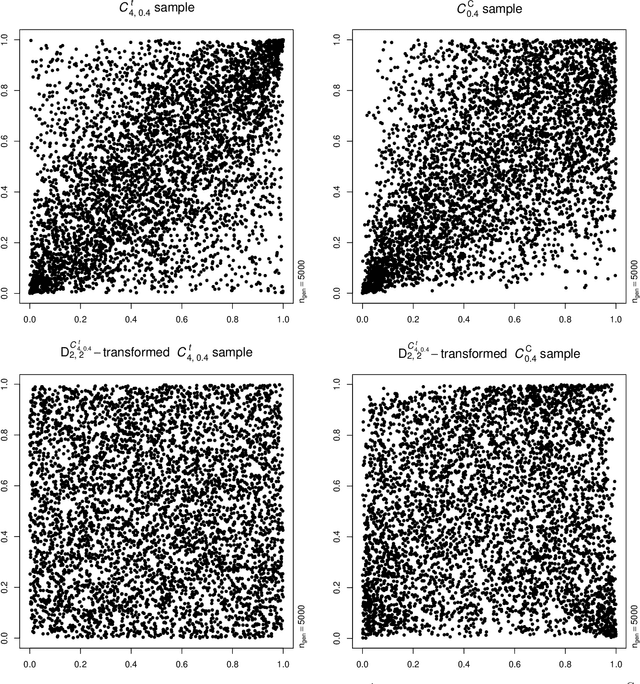
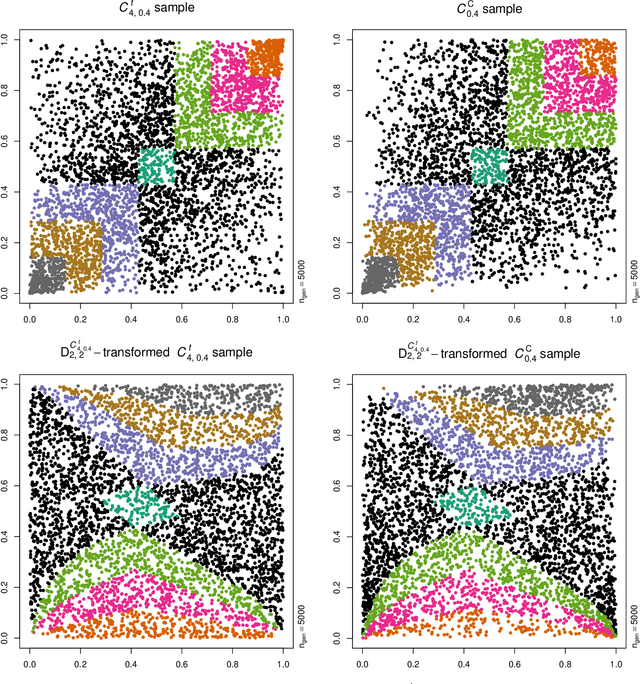
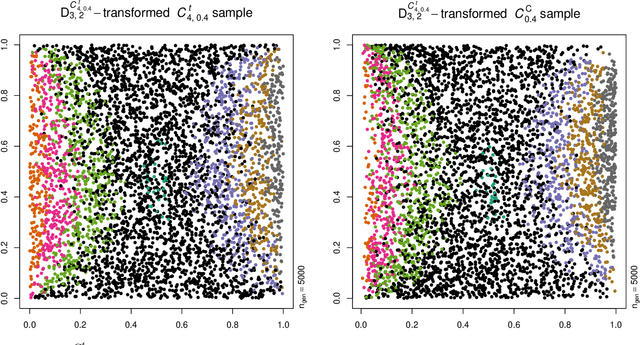

Neural networks are suggested for learning a map from $d$-dimensional samples with any underlying dependence structure to multivariate uniformity in $d'$ dimensions. This map, termed DecoupleNet, is used for dependence model assessment and selection. If the data-generating dependence model was known, and if it was among the few analytically tractable ones, one such transformation for $d'=d$ is Rosenblatt's transform. DecoupleNets only require an available sample and are applicable to $d'<d$, in particular $d'=2$. This allows for simpler model assessment and selection without loss of information, both numerically and, because $d'=2$, graphically. Through simulation studies based on data from various copulas, the feasibility and validity of this novel approach is demonstrated. Applications to real world data illustrate its usefulness for model assessment and selection.
Hard Example Guided Hashing for Image Retrieval
Dec 27, 2021

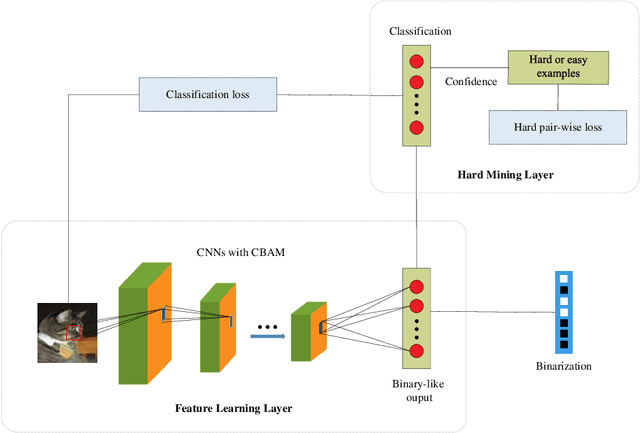

Compared with the traditional hashing methods, deep hashing methods generate hash codes with rich semantic information and greatly improves the performances in the image retrieval field. However, it is unsatisfied for current deep hashing methods to predict the similarity of hard examples. It exists two main factors affecting the ability of learning hard examples, which are weak key features extraction and the shortage of hard examples. In this paper, we give a novel end-to-end model to extract the key feature from hard examples and obtain hash code with the accurate semantic information. In addition, we redesign a hard pair-wise loss function to assess the hard degree and update penalty weights of examples. It effectively alleviates the shortage problem in hard examples. Experimental results on CIFAR-10 and NUS-WIDE demonstrate that our model outperformances the mainstream hashing-based image retrieval methods.
A Learning Based Framework for Handling Uncertain Lead Times in Multi-Product Inventory Management
Mar 09, 2022
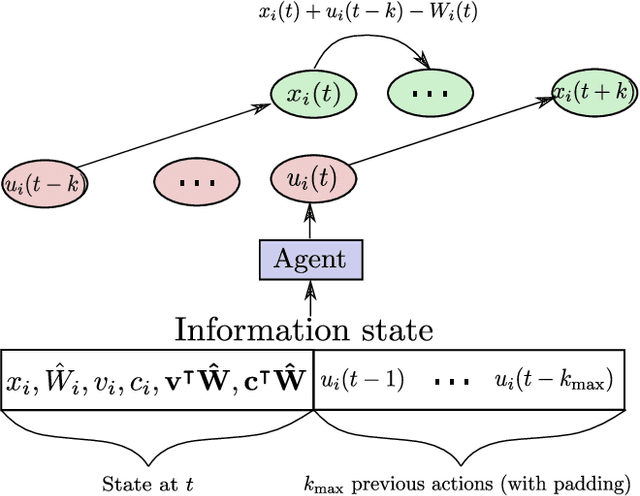
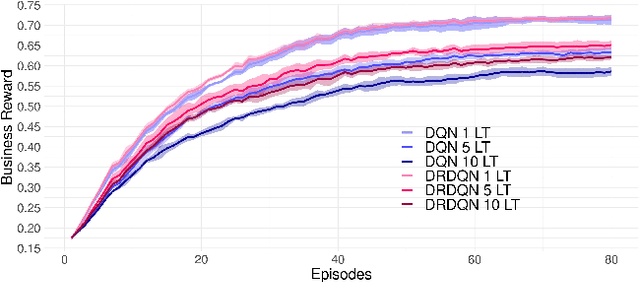
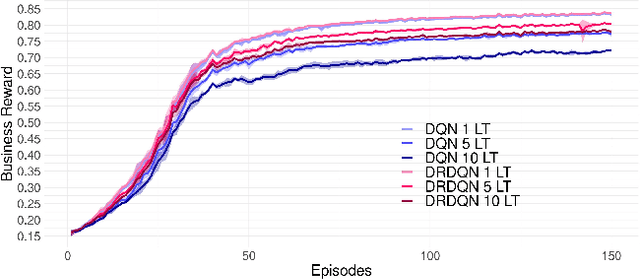
Most existing literature on supply chain and inventory management consider stochastic demand processes with zero or constant lead times. While it is true that in certain niche scenarios, uncertainty in lead times can be ignored, most real-world scenarios exhibit stochasticity in lead times. These random fluctuations can be caused due to uncertainty in arrival of raw materials at the manufacturer's end, delay in transportation, an unforeseen surge in demands, and switching to a different vendor, to name a few. Stochasticity in lead times is known to severely degrade the performance in an inventory management system, and it is only fair to abridge this gap in supply chain system through a principled approach. Motivated by the recently introduced delay-resolved deep Q-learning (DRDQN) algorithm, this paper develops a reinforcement learning based paradigm for handling uncertainty in lead times (\emph{action delay}). Through empirical evaluations, it is further shown that the inventory management with uncertain lead times is not only equivalent to that of delay in information sharing across multiple echelons (\emph{observation delay}), a model trained to handle one kind of delay is capable to handle delays of another kind without requiring to be retrained. Finally, we apply the delay-resolved framework to scenarios comprising of multiple products subjected to stochasticity in lead times, and elucidate how the delay-resolved framework negates the effect of any delay to achieve near-optimal performance.
AD-NEGF: An End-to-End Differentiable Quantum Transport Simulator for Sensitivity Analysis and Inverse Problems
Feb 10, 2022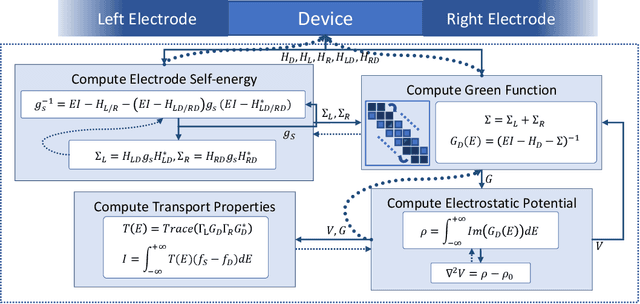
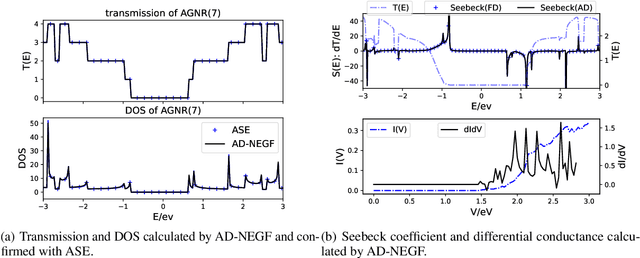
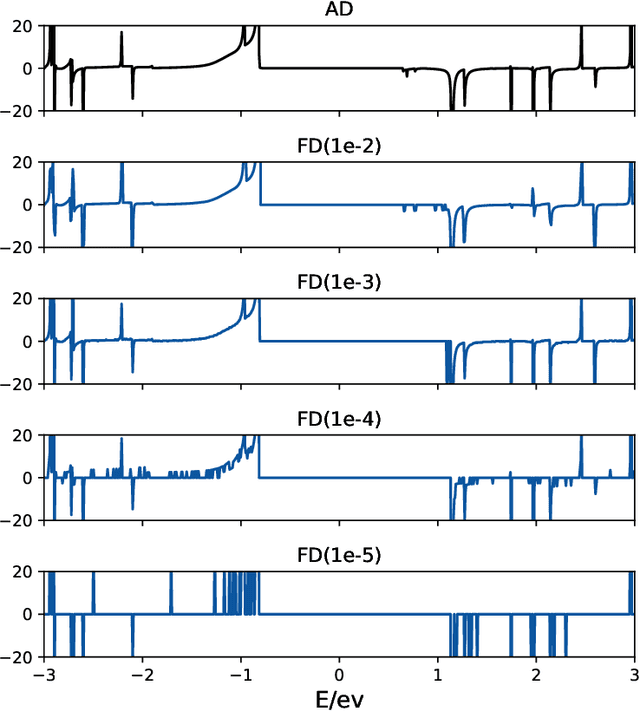
Since proposed in the 70s, the Non-Equilibrium Green Function (NEGF) method has been recognized as a standard approach to quantum transport simulations. Although it achieves superiority in simulation accuracy, the tremendous computational cost makes it unbearable for high-throughput simulation tasks such as sensitivity analysis, inverse design, etc. In this work, we propose AD-NEGF, to our best knowledge the first end-to-end differentiable NEGF model for quantum transport simulations. We implement the entire numerical process in PyTorch, and design customized backward pass with implicit layer techniques, which provides gradient information at an affordable cost while guaranteeing the correctness of the forward simulation. The proposed model is validated with applications in calculating differential physical quantities, empirical parameter fitting, and doping optimization, which demonstrates its capacity to accelerate the material design process by conducting gradient-based parameter optimization.
The Biosensor based on electrochemical dynamics of fermentation in yeast Saccharomyces Cerevisiae
Feb 07, 2022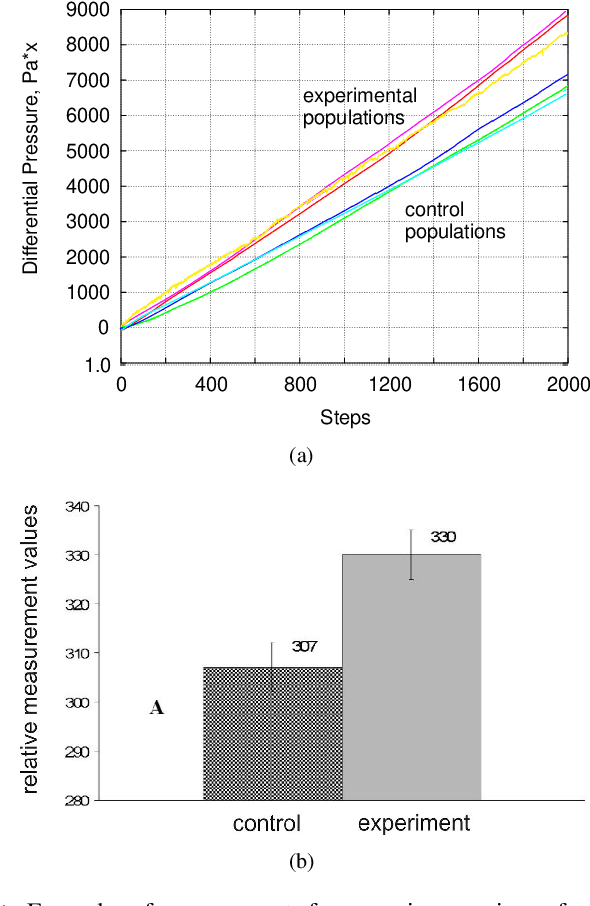
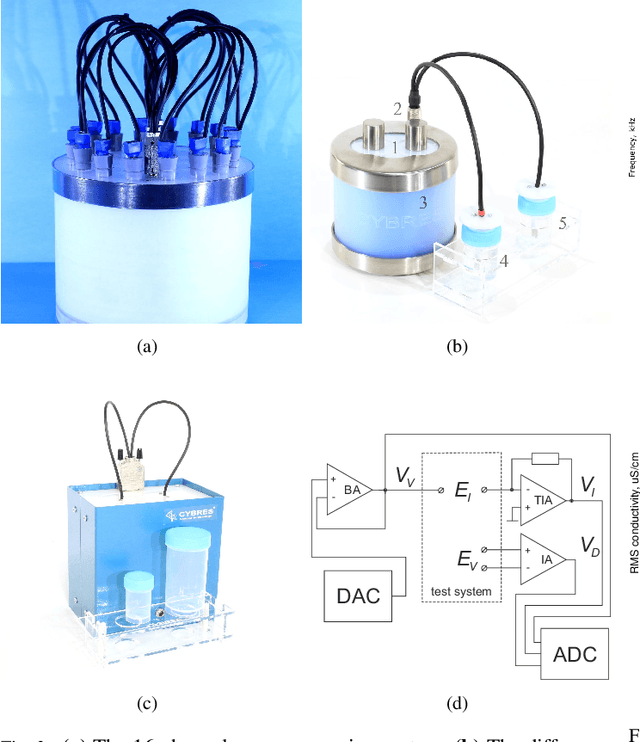
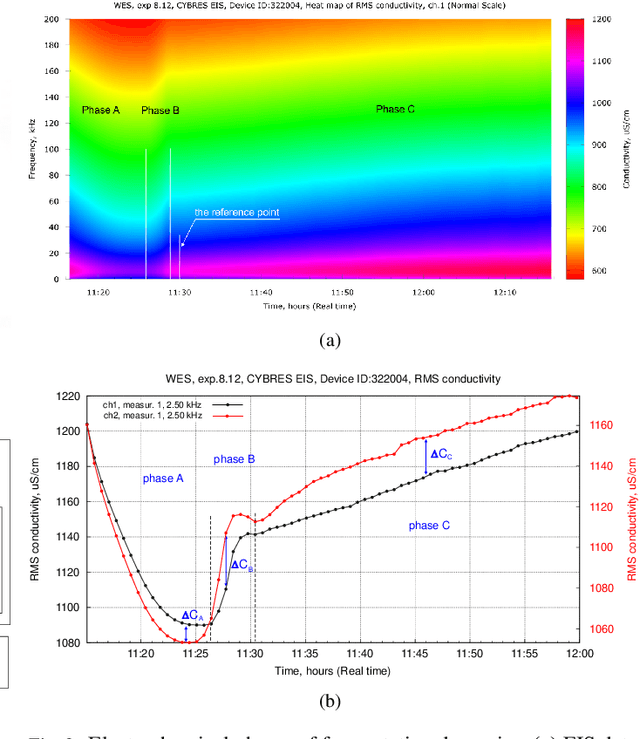
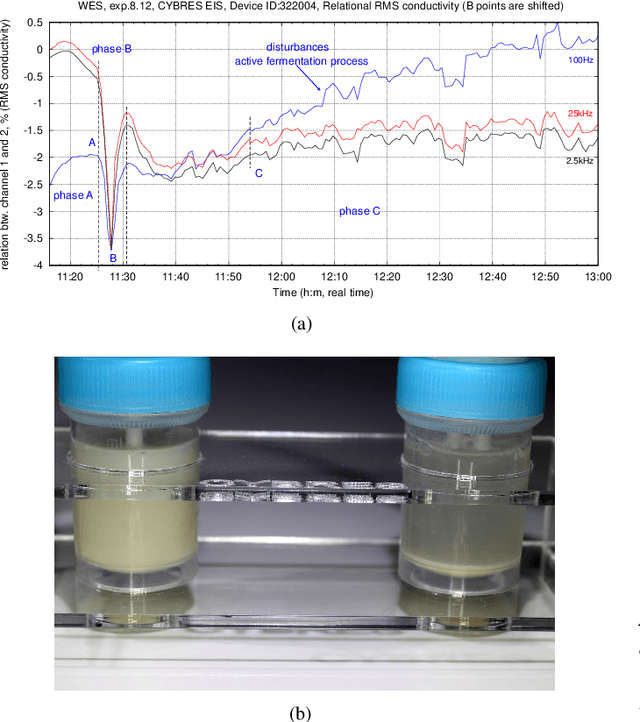
The zymase activity of the yeast Saccharomyces Cerevisiae is sensitive to environmental parameters and is therefore used as a microbiological sensor for water quality assessment, ecotoxicological characterization or environmental monitoring. Comparing to bacterial bioluminescence approach, this method has no toxicity, excludes usage of genetically modified microorganisms, and enables low-cost express analysis. This work focuses on measuring the yeast fermentation dynamics based on multichannel pressure sensing and electrochemical impedance spectroscopy (EIS). Measurement results are compared with each other in terms of accuracy, reproducibility and ease of use in the field conditions. It has been shown that EIS provides more information about ionic dynamics of metabolic processes and requires less complex measurements. The conducted experiments demonstrated the sensitivity of this approach for assessing biophotonic phenomena, non-chemical water treatments and impact of environmental stressors.
Classroom Slide Narration System
Jan 21, 2022

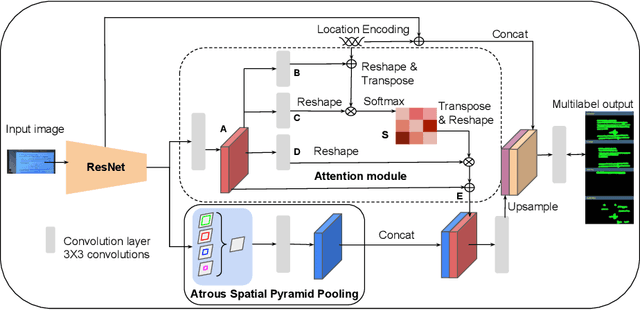
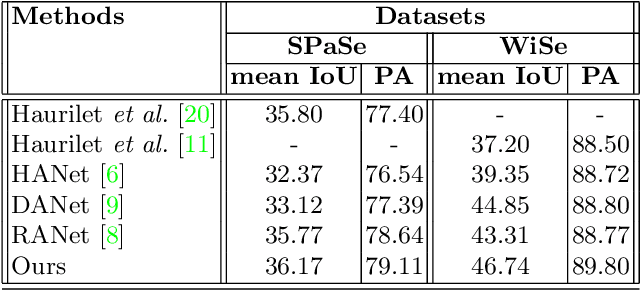
Slide presentations are an effective and efficient tool used by the teaching community for classroom communication. However, this teaching model can be challenging for blind and visually impaired (VI) students. The VI student required personal human assistance for understand the presented slide. This shortcoming motivates us to design a Classroom Slide Narration System (CSNS) that generates audio descriptions corresponding to the slide content. This problem poses as an image-to-markup language generation task. The initial step is to extract logical regions such as title, text, equation, figure, and table from the slide image. In the classroom slide images, the logical regions are distributed based on the location of the image. To utilize the location of the logical regions for slide image segmentation, we propose the architecture, Classroom Slide Segmentation Network (CSSN). The unique attributes of this architecture differs from most other semantic segmentation networks. Publicly available benchmark datasets such as WiSe and SPaSe are used to validate the performance of our segmentation architecture. We obtained 9.54 segmentation accuracy improvement in WiSe dataset. We extract content (information) from the slide using four well-established modules such as optical character recognition (OCR), figure classification, equation description, and table structure recognizer. With this information, we build a Classroom Slide Narration System (CSNS) to help VI students understand the slide content. The users have given better feedback on the quality output of the proposed CSNS in comparison to existing systems like Facebooks Automatic Alt-Text (AAT) and Tesseract.