 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improve Convolutional Neural Network Pruning by Maximizing Filter Variety
Mar 11, 2022

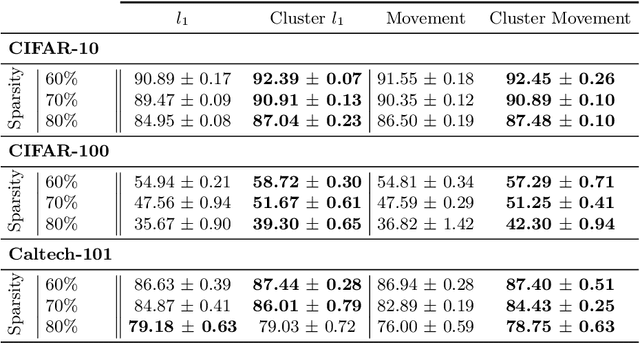

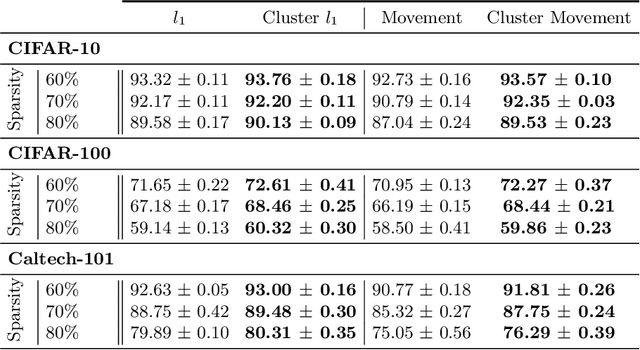
Neural network pruning is a widely used strategy for reducing model storage and computing requirements. It allows to lower the complexity of the network by introducing sparsity in the weights. Because taking advantage of sparse matrices is still challenging, pruning is often performed in a structured way, i.e. removing entire convolution filters in the case of ConvNets, according to a chosen pruning criteria. Common pruning criteria, such as l1-norm or movement, usually do not consider the individual utility of filters, which may lead to: (1) the removal of filters exhibiting rare, thus important and discriminative behaviour, and (2) the retaining of filters with redundant information. In this paper, we present a technique solving those two issues, and which can be appended to any pruning criteria. This technique ensures that the criteria of selection focuses on redundant filters, while retaining the rare ones, thus maximizing the variety of remaining filters. The experimental results, carried out on different datasets (CIFAR-10, CIFAR-100 and CALTECH-101) and using different architectures (VGG-16 and ResNet-18) demonstrate that it is possible to achieve similar sparsity levels while maintaining a higher performance when appending our filter selection technique to pruning criteria. Moreover, we assess the quality of the found sparse sub-networks by applying the Lottery Ticket Hypothesis and find that the addition of our method allows to discover better performing tickets in most cases
Symphony: Composing Interactive Interfaces for Machine Learning
Feb 18, 2022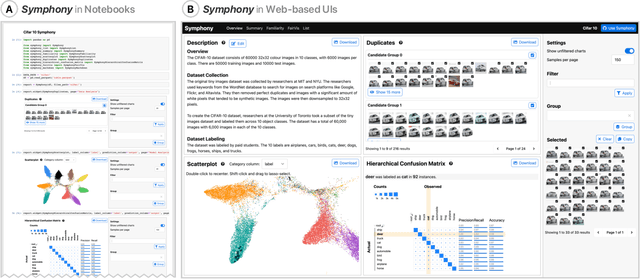
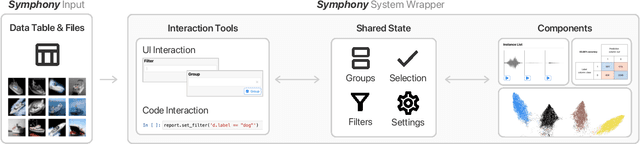
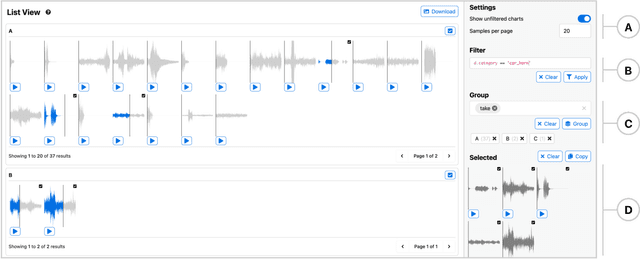
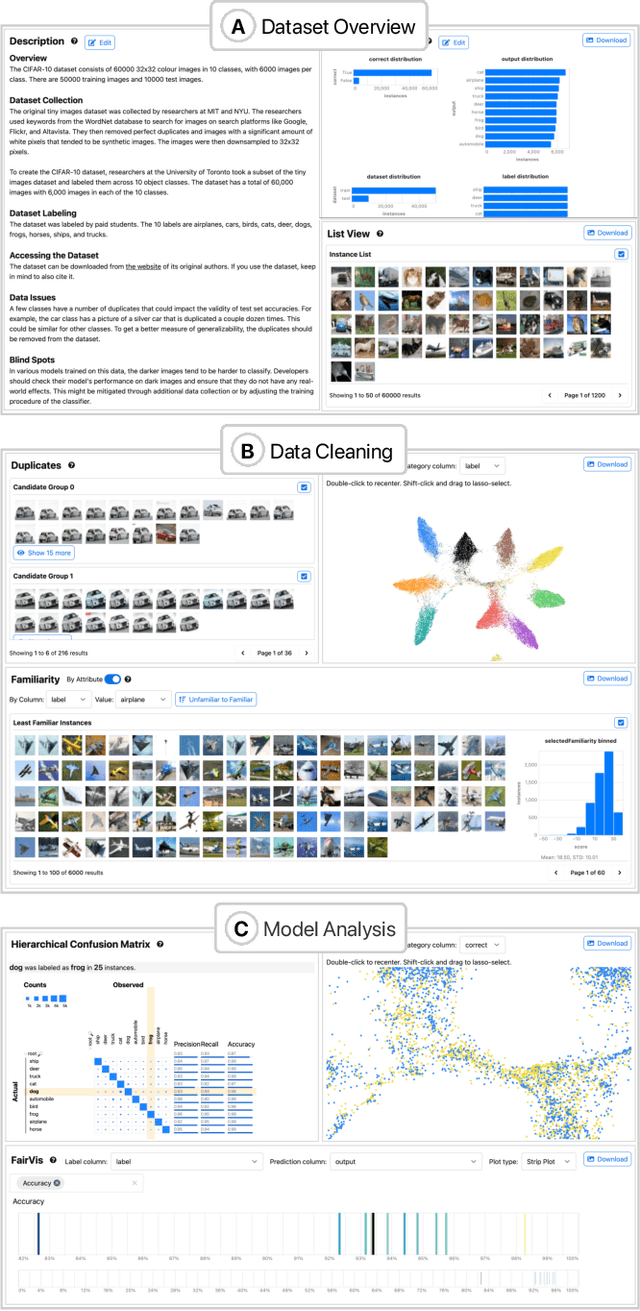
Interfaces for machine learning (ML), information and visualizations about models or data, can help practitioners build robust and responsible ML systems. Despite their benefits, recent studies of ML teams and our interviews with practitioners (n=9) showed that ML interfaces have limited adoption in practice. While existing ML interfaces are effective for specific tasks, they are not designed to be reused, explored, and shared by multiple stakeholders in cross-functional teams. To enable analysis and communication between different ML practitioners, we designed and implemented Symphony, a framework for composing interactive ML interfaces with task-specific, data-driven components that can be used across platforms such as computational notebooks and web dashboards. We developed Symphony through participatory design sessions with 10 teams (n=31), and discuss our findings from deploying Symphony to 3 production ML projects at Apple. Symphony helped ML practitioners discover previously unknown issues like data duplicates and blind spots in models while enabling them to share insights with other stakeholders.
Analysis and Design of Partially Information- and Partially Parity-Coupled Turbo Codes
Dec 24, 2020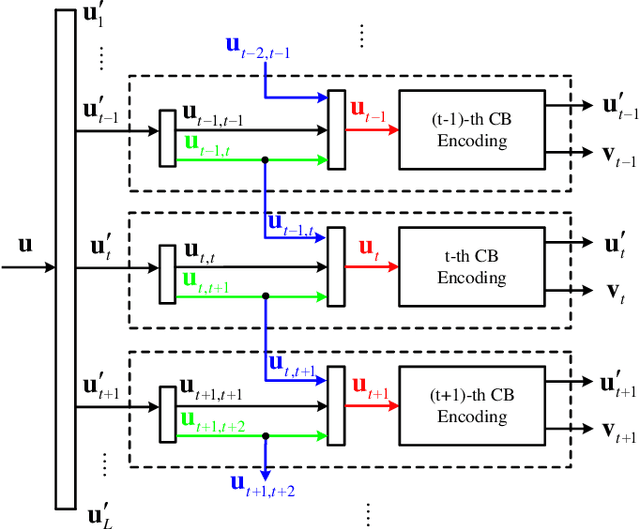
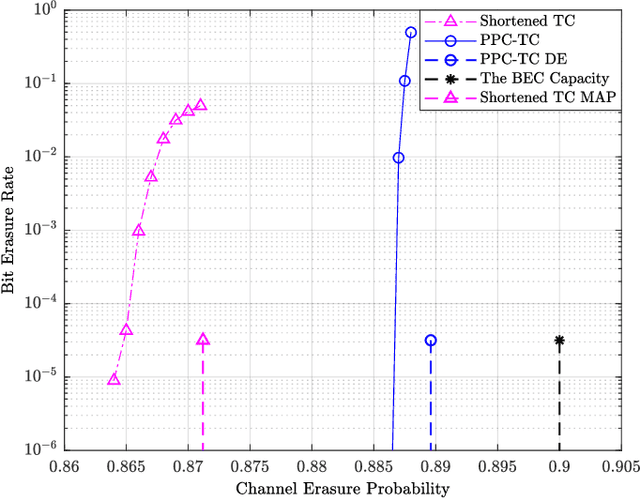
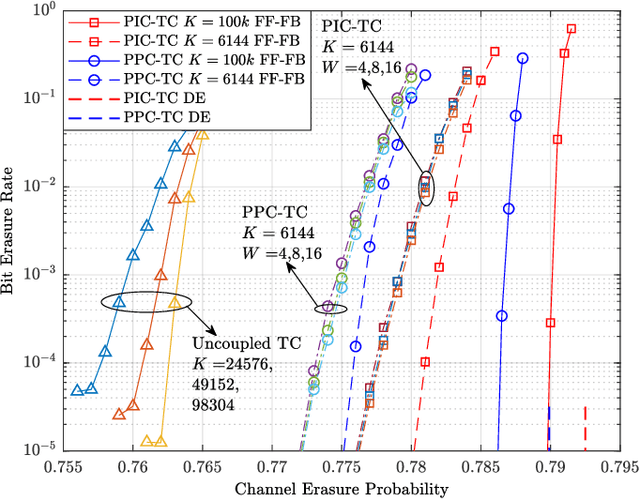
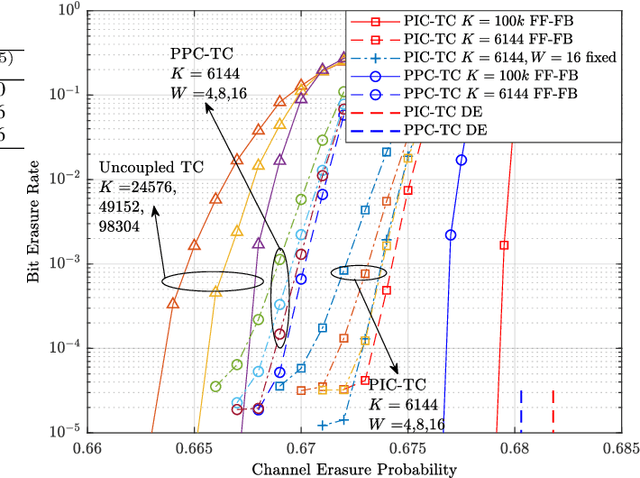
In this paper, we study a class of spatially coupled turbo codes, namely partially information- and partially parity-coupled turbo codes. This class of codes enjoy several advantages such as flexible code rate adjustment by varying the coupling ratio and the encoding and decoding architectures of the underlying component codes can remain unchanged. For this work, we first provide the construction methods for partially coupled turbo codes with coupling memory $m$ and study the corresponding graph models. We then derive the density evolution equations for the corresponding ensembles on the binary erasure channel to precisely compute their iterative decoding thresholds. Rate-compatible designs and their decoding thresholds are also provided, where the coupling and puncturing ratios are jointly optimized to achieve the largest decoding threshold for a given target code rate. Our results show that for a wide range of code rates, the proposed codes attain close-to-capacity performance and the decoding performance improves with increasing the coupling memory. In particular, the proposed partially parity-coupled turbo codes have thresholds within 0.0002 of the BEC capacity for rates ranging from $1/3$ to $9/10$, yielding an attractive way for constructing rate-compatible capacity-approaching channel codes.
Human Activity Recognition Using 3D Orthogonally-projected EfficientNet on Radar Time-Range-Doppler Signature
Nov 24, 2021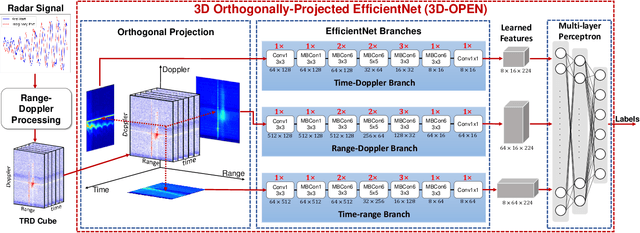
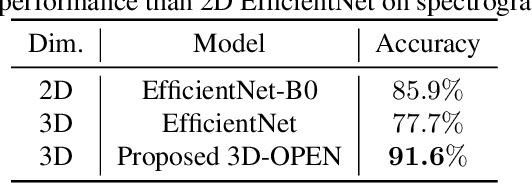
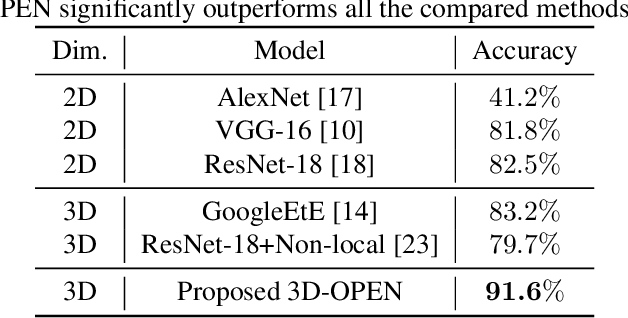
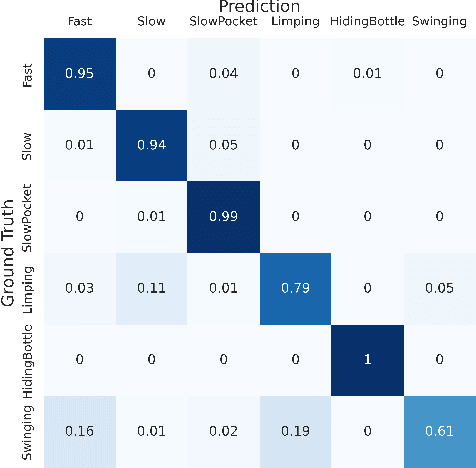
In radar activity recognition, 2D signal representations such as spectrogram, cepstrum and cadence velocity diagram are often utilized, while range information is often neglected. In this work, we propose to utilize the 3D time-range-Doppler (TRD) representation, and design a 3D Orthogonally-Projected EfficientNet (3D-OPEN) to effectively capture the discriminant information embedded in the 3D TRD cubes for accurate classification. The proposed model aggregates the discriminant information from three orthogonal planes projected from the 3D feature space. It alleviates the difficulty of 3D CNNs in exploiting sparse semantic abstractions directly from the high-dimensional 3D representation. The proposed method is evaluated on the Millimeter-Wave Radar Walking Dataset. It significantly and consistently outperforms the state-of-the-art methods for radar activity recognition.
Numeric Encoding Options with Automunge
Feb 22, 2022

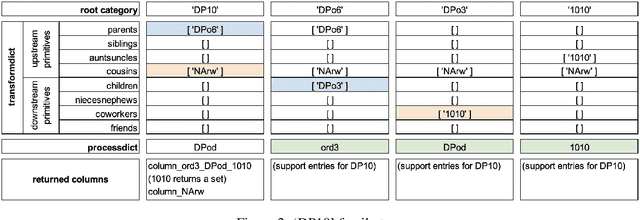
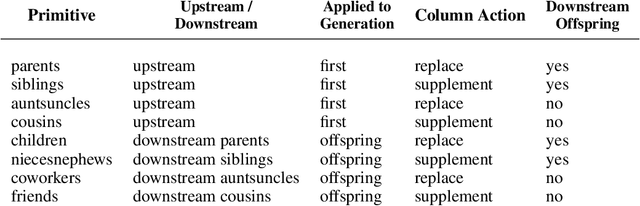
Mainstream practice in machine learning with tabular data may take for granted that any feature engineering beyond scaling for numeric sets is superfluous in context of deep neural networks. This paper will offer arguments for potential benefits of extended encodings of numeric streams in deep learning by way of a survey of options for numeric transformations as available in the Automunge open source python library platform for tabular data pipelines, where transformations may be applied to distinct columns in "family tree" sets with generations and branches of derivations. Automunge transformation options include normalization, binning, noise injection, derivatives, and more. The aggregation of these methods into family tree sets of transformations are demonstrated for use to present numeric features to machine learning in multiple configurations of varying information content, as may be applied to encode numeric sets of unknown interpretation. Experiments demonstrate the realization of a novel generalized solution to data augmentation by noise injection for tabular learning, as may materially benefit model performance in applications with underserved training data.
Unsupervised domain adaptation with exploring more statistics and discriminative information
Mar 26, 2020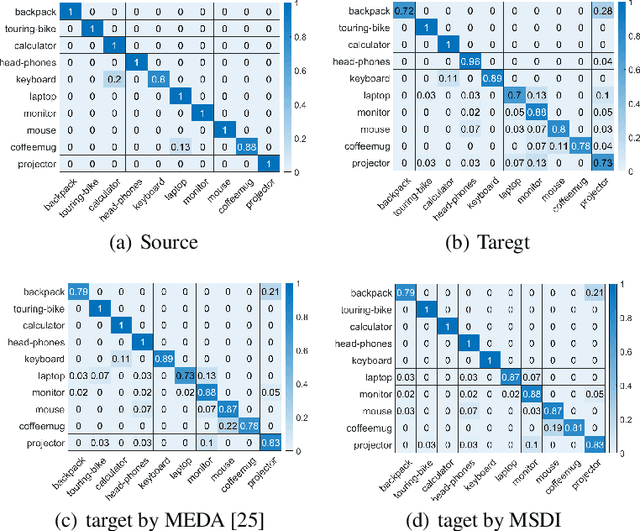
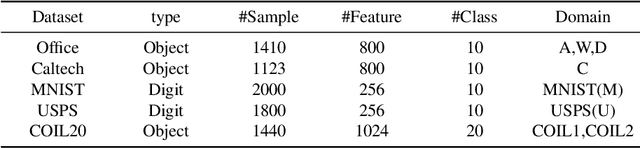
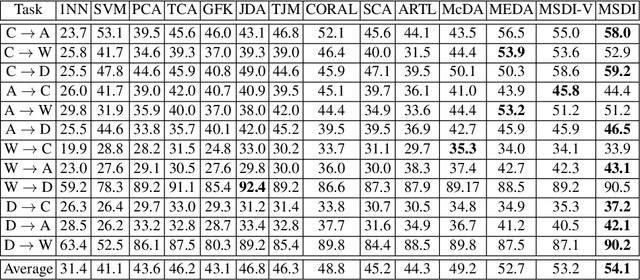
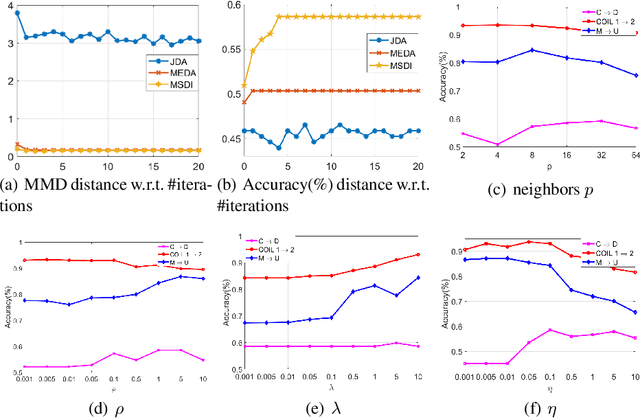
Unsupervised domain adaptation aims at transferring knowledge from the labeled source domain to the unlabeled target domain. Previous methods mainly learn a domain-invariant feature transformation, where the cross-domain discrepancy can be reduced. Maximum Mean Discrepancy(MMD) is the most popular statistic to measure domain discrepancy. However, these methods may suffer from two challenges. 1) MMD-based methods only measure the first-order statistic information across domains, while other useful information such as second-order statistic information has been ignored. 2) The classifier trained on the source domain may confuse to distinguish the correct class from a similar class, and the phenomenon is called class confusion. In this paper, we propose a method called \emph{Unsupervised domain adaptation with exploring more statistics and discriminative information}(MSDI), which tackle these two problems in the principle of structural risk minimization. We adopt the recently proposed statistic called MMCD to measure domain discrepancy which can capture both first-order and second-order statistics simultaneously in RKHS. Besides, we proposed to learn more discriminative features to avoid class confusion, where the inner of the classifier predictions with their transposes are used to reflect the confusion relationship between different classes. Moreover, we minimizing source empirical risk and adopt manifold regularization to explore geometry information in the target domain. MSDI learns a domain-invariant classifier in a unified learning framework incorporating the above objectives. We conduct comprehensive experiments on five real-world datasets and the results verify the effectiveness of the proposed method.
Similarity-based prediction of Ejection Fraction in Heart Failure Patients
Mar 14, 2022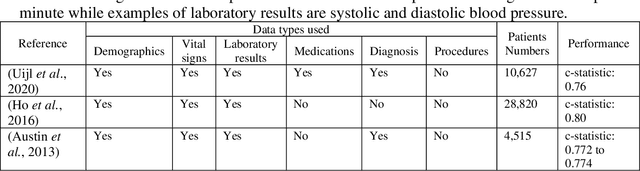
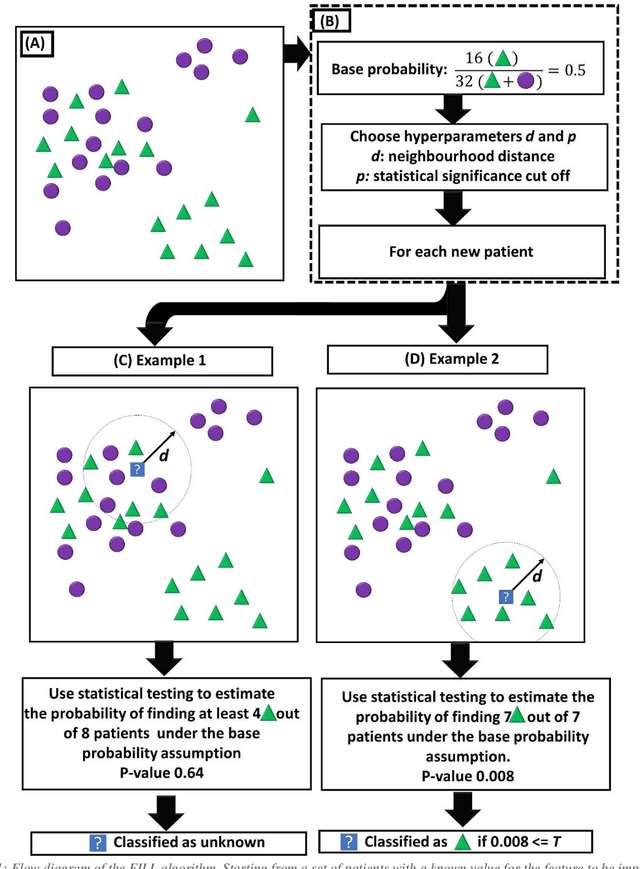


Biomedical research is increasingly employing real world evidence (RWE) to foster discoveries of novel clinical phenotypes and to better characterize long term effect of medical treatments. However, due to limitations inherent in the collection process, RWE often lacks key features of patients, particularly when these features cannot be directly encoded using data standards such as ICD-10. Here we propose a novel data-driven statistical machine learning approach, named Feature Imputation via Local Likelihood (FILL), designed to infer missing features by exploiting feature similarity between patients. We test our method using a particularly challenging problem: differentiating heart failure patients with reduced versus preserved ejection fraction (HFrEF and HFpEF respectively). The complexity of the task stems from three aspects: the two share many common characteristics and treatments, only part of the relevant diagnoses may have been recorded, and the information on ejection fraction is often missing from RWE datasets. Despite these difficulties, our method is shown to be capable of inferring heart failure patients with HFpEF with a precision above 80% when considering multiple scenarios across two RWE datasets containing 11,950 and 10,051 heart failure patients. This is an improvement when compared to classical approaches such as logistic regression and random forest which were only able to achieve a precision < 73%. Finally, this approach allows us to analyse which features are commonly associated with HFpEF patients. For example, we found that specific diagnostic codes for atrial fibrillation and personal history of long-term use of anticoagulants are often key in identifying HFpEF patients.
Parallel MCMC Without Embarrassing Failures
Feb 22, 2022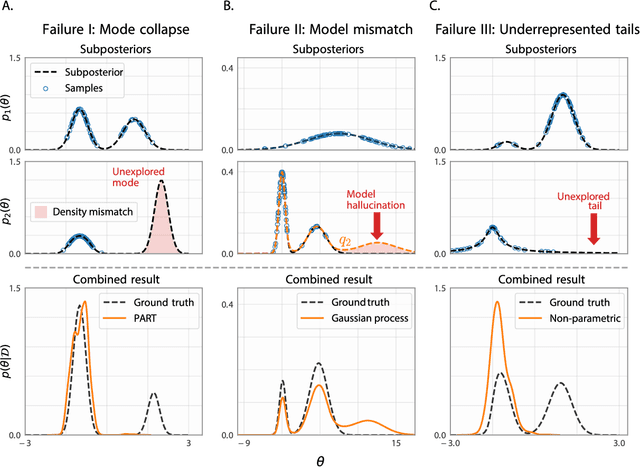
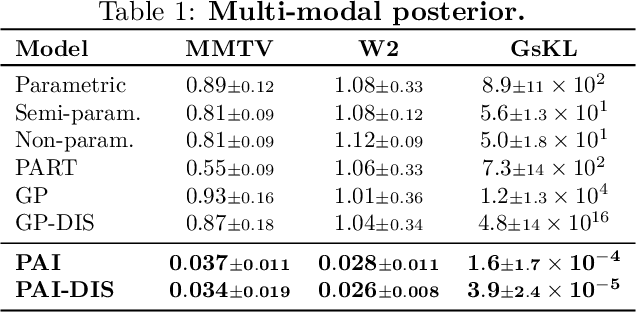
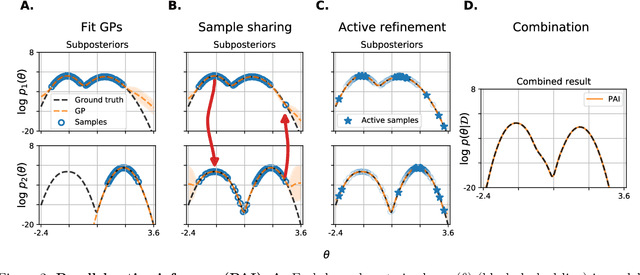
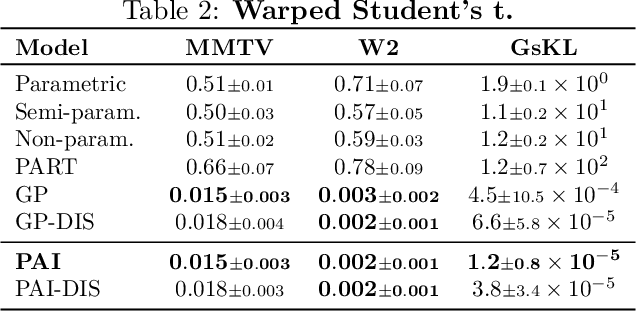
Embarrassingly parallel Markov Chain Monte Carlo (MCMC) exploits parallel computing to scale Bayesian inference to large datasets by using a two-step approach. First, MCMC is run in parallel on (sub)posteriors defined on data partitions. Then, a server combines local results. While efficient, this framework is very sensitive to the quality of subposterior sampling. Common sampling problems such as missing modes or misrepresentation of low-density regions are amplified -- instead of being corrected -- in the combination phase, leading to catastrophic failures. In this work, we propose a novel combination strategy to mitigate this issue. Our strategy, Parallel Active Inference (PAI), leverages Gaussian Process (GP) surrogate modeling and active learning. After fitting GPs to subposteriors, PAI (i) shares information between GP surrogates to cover missing modes; and (ii) uses active sampling to individually refine subposterior approximations. We validate PAI in challenging benchmarks, including heavy-tailed and multi-modal posteriors and a real-world application to computational neuroscience. Empirical results show that PAI succeeds where previous methods catastrophically fail, with a small communication overhead.
Continuous Self-Localization on Aerial Images Using Visual and Lidar Sensors
Mar 07, 2022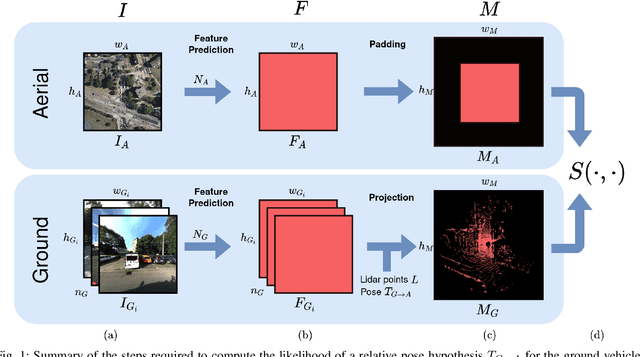
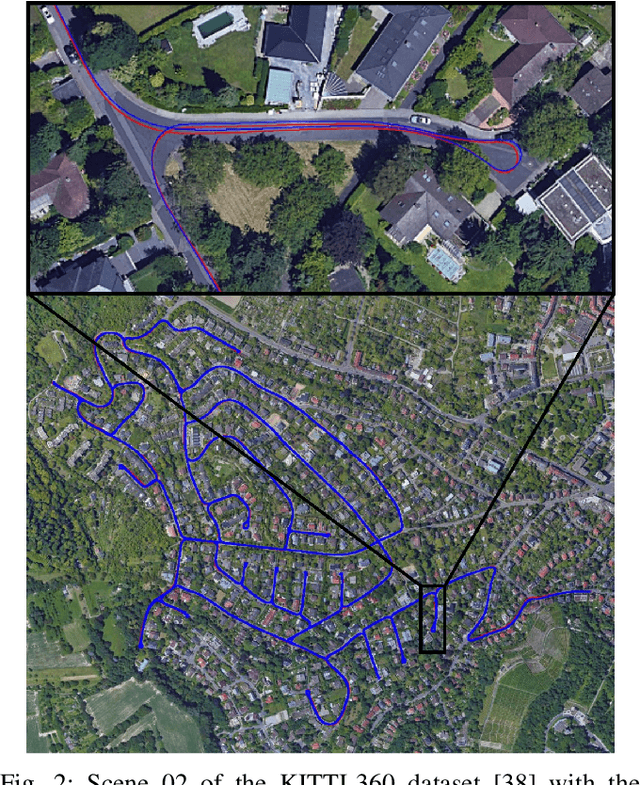
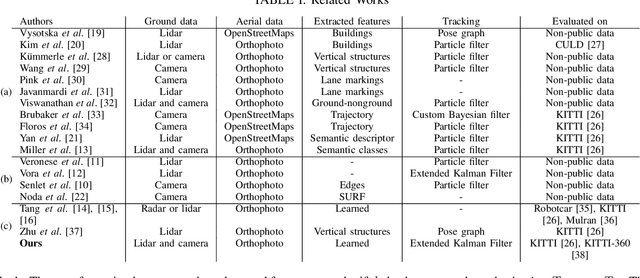
This paper proposes a novel method for geo-tracking, i.e. continuous metric self-localization in outdoor environments by registering a vehicle's sensor information with aerial imagery of an unseen target region. Geo-tracking methods offer the potential to supplant noisy signals from global navigation satellite systems (GNSS) and expensive and hard to maintain prior maps that are typically used for this purpose. The proposed geo-tracking method aligns data from on-board cameras and lidar sensors with geo-registered orthophotos to continuously localize a vehicle. We train a model in a metric learning setting to extract visual features from ground and aerial images. The ground features are projected into a top-down perspective via the lidar points and are matched with the aerial features to determine the relative pose between vehicle and orthophoto. Our method is the first to utilize on-board cameras in an end-to-end differentiable model for metric self-localization on unseen orthophotos. It exhibits strong generalization, is robust to changes in the environment and requires only geo-poses as ground truth. We evaluate our approach on the KITTI-360 dataset and achieve a mean absolute position error (APE) of 0.94m. We further compare with previous approaches on the KITTI odometry dataset and achieve state-of-the-art results on the geo-tracking task.
AWSnet: An Auto-weighted Supervision Attention Network for Myocardial Scar and Edema Segmentation in Multi-sequence Cardiac Magnetic Resonance Images
Jan 14, 2022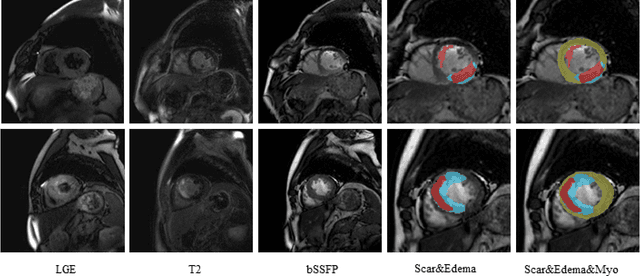
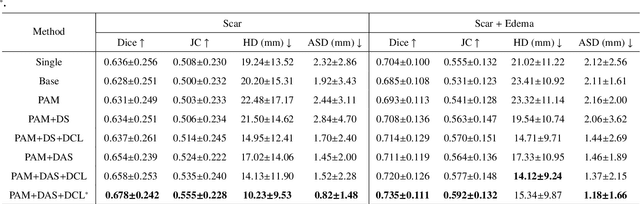
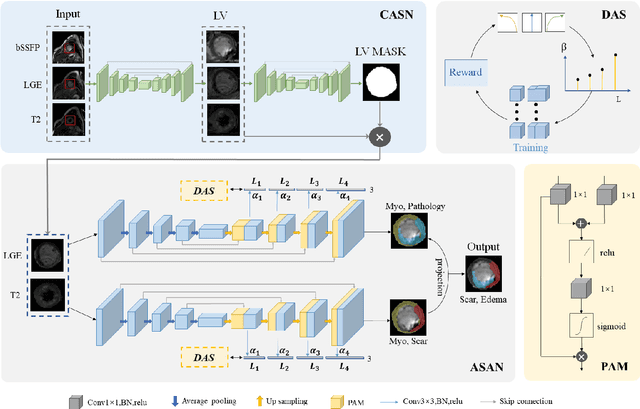
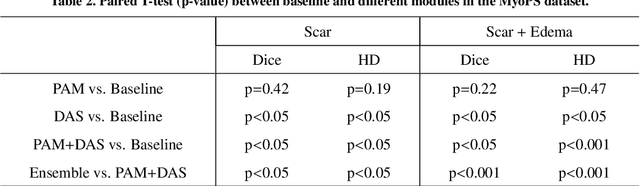
Multi-sequence cardiac magnetic resonance (CMR) provides essential pathology information (scar and edema) to diagnose myocardial infarction. However, automatic pathology segmentation can be challenging due to the difficulty of effectively exploring the underlying information from the multi-sequence CMR data. This paper aims to tackle the scar and edema segmentation from multi-sequence CMR with a novel auto-weighted supervision framework, where the interactions among different supervised layers are explored under a task-specific objective using reinforcement learning. Furthermore, we design a coarse-to-fine framework to boost the small myocardial pathology region segmentation with shape prior knowledge. The coarse segmentation model identifies the left ventricle myocardial structure as a shape prior, while the fine segmentation model integrates a pixel-wise attention strategy with an auto-weighted supervision model to learn and extract salient pathological structures from the multi-sequence CMR data. Extensive experimental results on a publicly available dataset from Myocardial pathology segmentation combining multi-sequence CMR (MyoPS 2020) demonstrate our method can achieve promising performance compared with other state-of-the-art methods. Our method is promising in advancing the myocardial pathology assessment on multi-sequence CMR data. To motivate the community, we have made our code publicly available via https://github.com/soleilssss/AWSnet/tree/master.