 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
C-MI-GAN : Estimation of Conditional Mutual Information using MinMax formulation
May 17, 2020
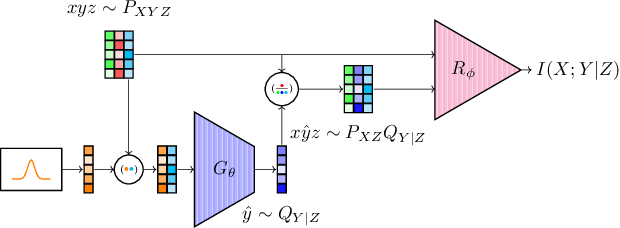
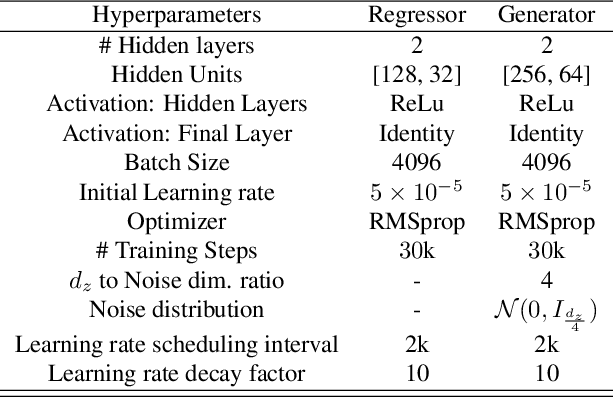
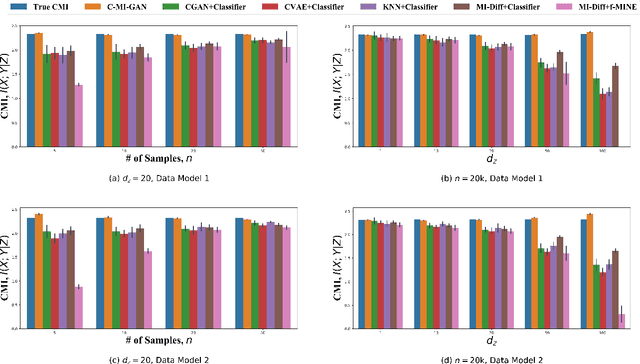
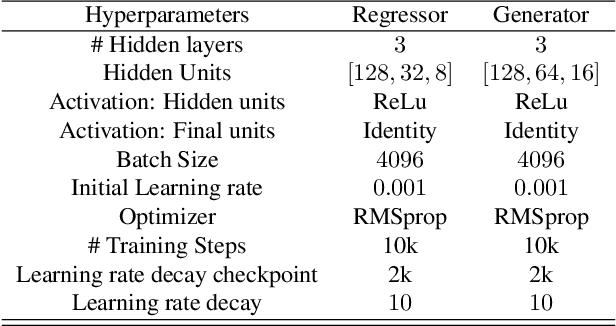
Estimation of information theoretic quantities such as mutual information and its conditional variant has drawn interest in recent times owing to their multifaceted applications. Newly proposed neural estimators for these quantities have overcome severe drawbacks of classical $k$NN-based estimators in high dimensions. In this work, we focus on conditional mutual information (CMI) estimation by utilizing its formulation as a minmax optimization problem. Such a formulation leads to a joint training procedure similar to that of generative adversarial networks. We find that our proposed estimator provides better estimates than the existing approaches on a variety of simulated data sets comprising linear and non-linear relations between variables. As an application of CMI estimation, we deploy our estimator for conditional independence (CI) testing on real data and obtain better results than state-of-the-art CI testers.
Preventing Information Leakage with Neural Architecture Search
Dec 18, 2019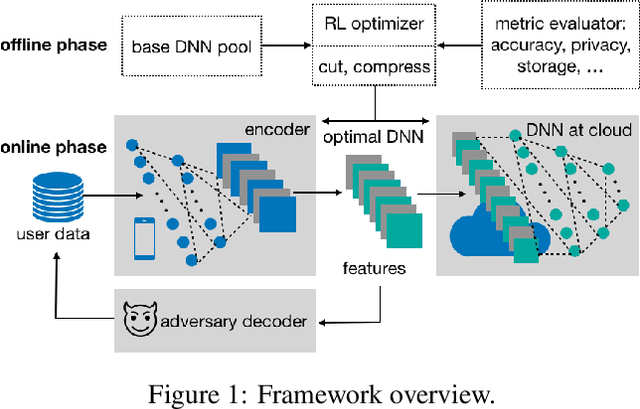
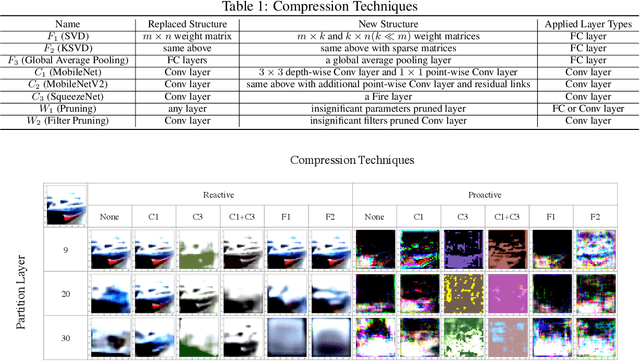
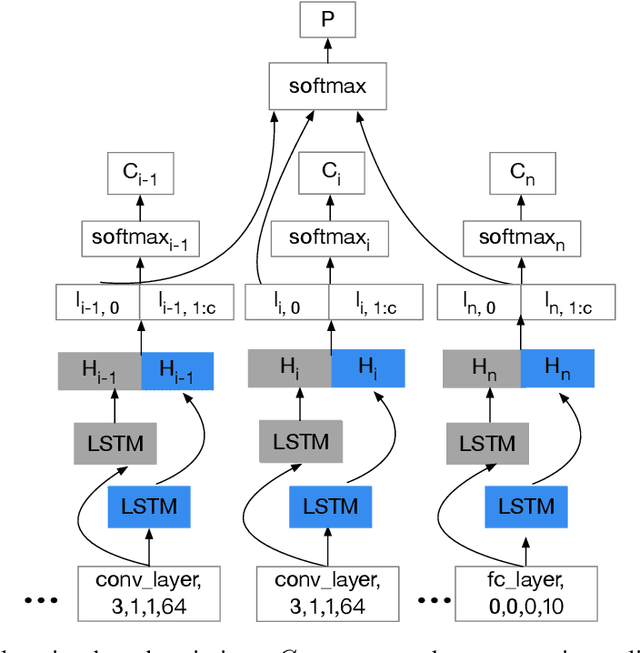
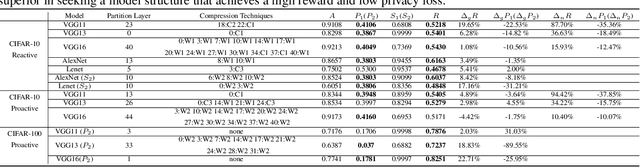
Powered by machine learning services in the cloud, numerous learning-driven mobile applications are gaining popularity in the market. As deep learning tasks are mostly computation-intensive, it has become a trend to process raw data on devices and send the neural network features to the cloud, whereas the part of the neural network residing in the cloud completes the task to return final results. However, there is always the potential for unexpected leakage with the release of features, with which an adversary could infer a significant amount of information about the original data. To address this problem, we propose a privacy-preserving deep learning framework on top of the mobile cloud infrastructure: the trained deep neural network is tailored to prevent information leakage through features while maintaining highly accurate results. In essence, we learn the strategy to prevent leakage by modifying the trained deep neural network against a generic opponent, who infers unintended information from released features and auxiliary data, while preserving the accuracy of the model as much as possible.
KINet: Keypoint Interaction Networks for Unsupervised Forward Modeling
Feb 18, 2022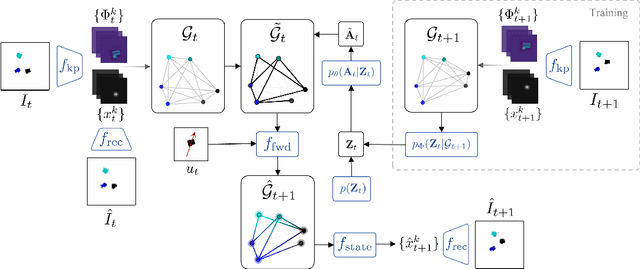
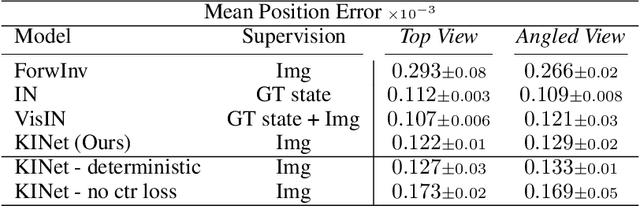
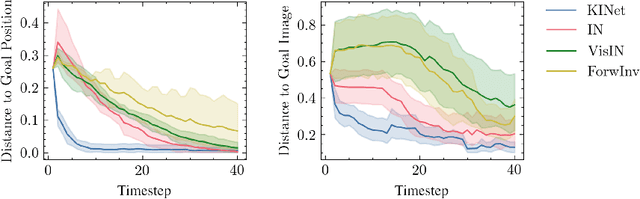
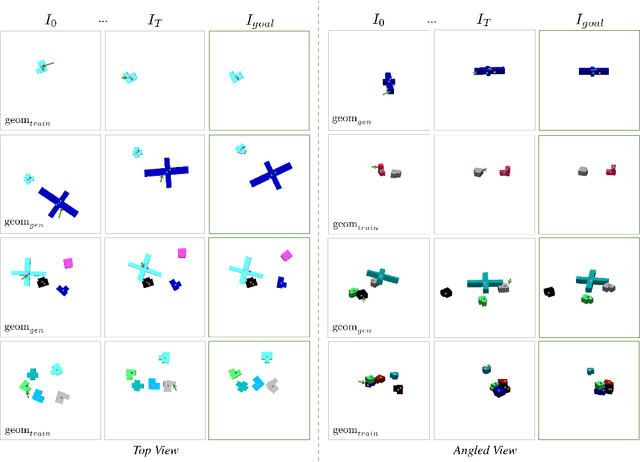
Object-centric representation is an essential abstraction for physical reasoning and forward prediction. Most existing approaches learn this representation through extensive supervision (e.g., object class and bounding box) although such ground-truth information is not readily accessible in reality. To address this, we introduce KINet (Keypoint Interaction Network) -- an end-to-end unsupervised framework to reason about object interactions in complex systems based on a keypoint representation. Using visual observations, our model learns to associate objects with keypoint coordinates and discovers a graph representation of the system as a set of keypoint embeddings and their relations. It then learns an action-conditioned forward model using contrastive estimation to predict future keypoint states. By learning to perform physical reasoning in the keypoint space, our model automatically generalizes to scenarios with a different number of objects, and novel object geometries. Experiments demonstrate the effectiveness of our model to accurately perform forward prediction and learn plannable object-centric representations which can also be used in downstream model-based control tasks.
Discrete-valued Preference Estimation with Graph Side Information
Mar 16, 2020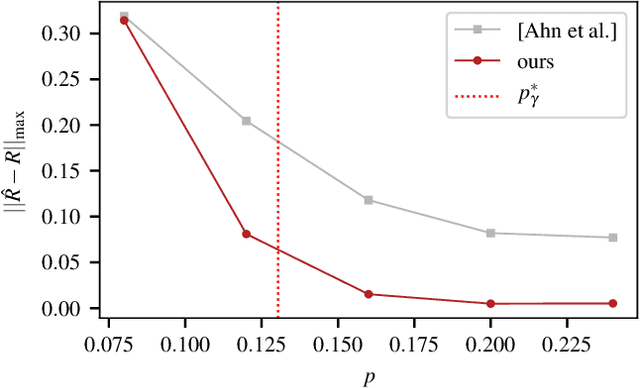
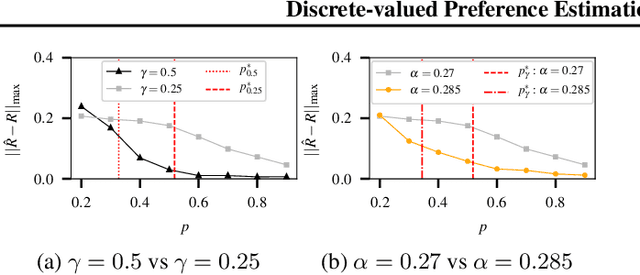
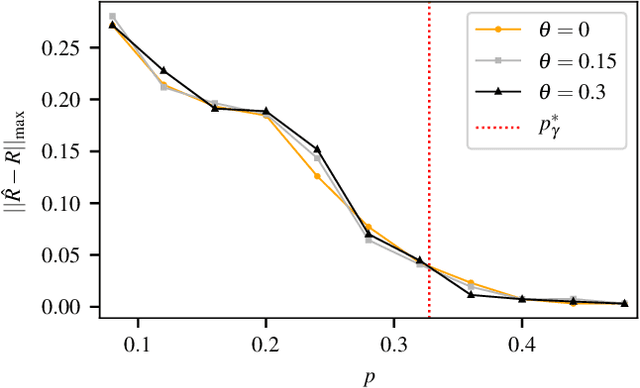
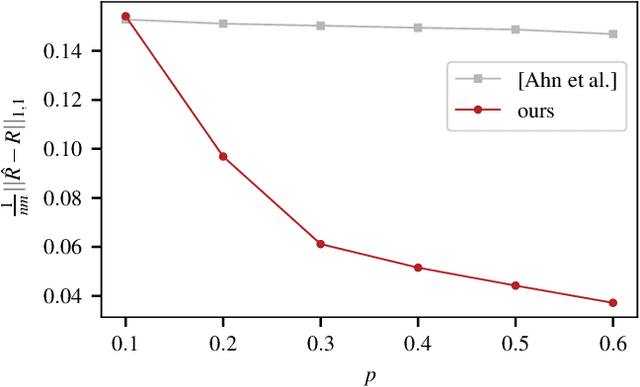
Incorporating graph side information into recommender systems has been widely used to better predict ratings, but relatively few works have focused on theoretical guarantees. Ahn et al. (2018) firstly characterized the optimal sample complexity in the presence of graph side information, but the results are limited due to strict, unrealistic assumptions made on the unknown preference matrix. In this work, we propose a new model in which the unknown preference matrix can have any discrete values, thereby relaxing the assumptions made in prior work. Under this new model, we fully characterize the optimal sample complexity and develop a computationally-efficient algorithm that matches the optimal sample complexity. We also show that our algorithm is robust to model errors, and it outperforms existing algorithms on both synthetic and real datasets.
A Low-Complexity Location-Based Hybrid Multiple Access and Relay Selection in V2X Multicast Communications
Jan 20, 2022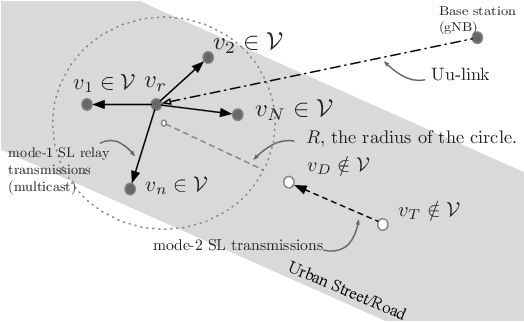
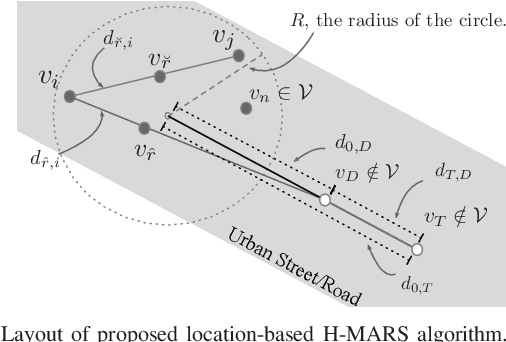
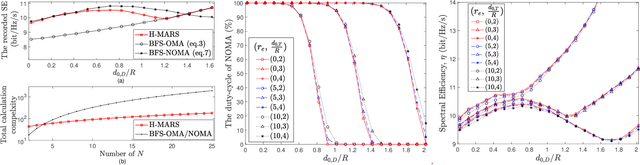

This study investigated relay-assisted mode 1 sidelink (SL) multicast transmission, which encounters interference from mode 2 SL transmission, for use in low-latency vehicle-to-everything communications. To accommodate mode 1--mode 2 SL traffic, we use the hybrid multiple access (MA) approach, which combines orthogonal MA (OMA) and nonorthogonal MA (NOMA) schemes. We introduce a low-complexity location-based hybrid MA algorithm and its associated relay selection that can be used when SL channel state information is unavailable.
Continuous Self-Localization on Aerial Images Using Visual and Lidar Sensors
Mar 07, 2022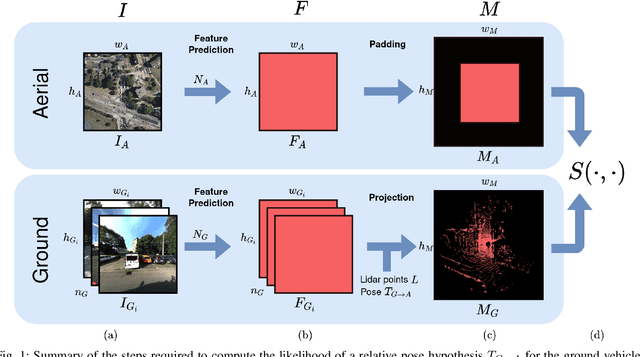
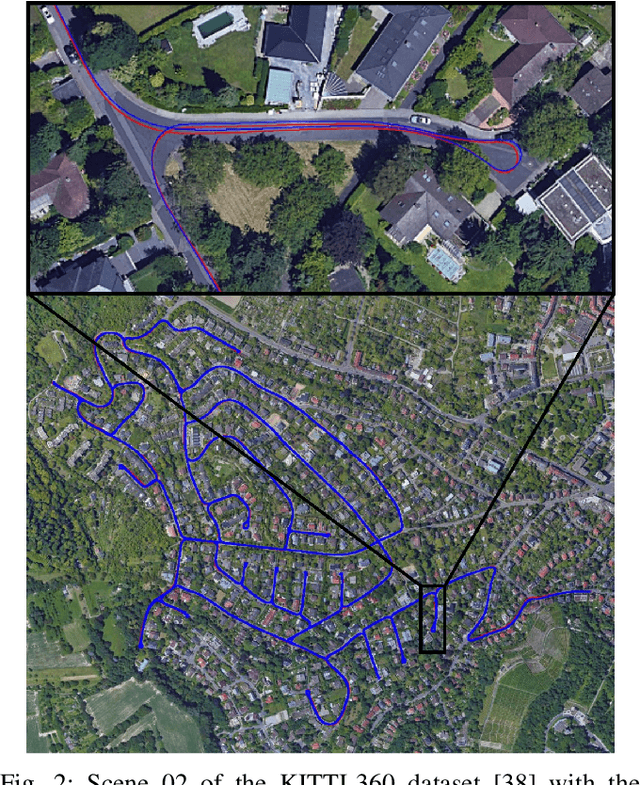
This paper proposes a novel method for geo-tracking, i.e. continuous metric self-localization in outdoor environments by registering a vehicle's sensor information with aerial imagery of an unseen target region. Geo-tracking methods offer the potential to supplant noisy signals from global navigation satellite systems (GNSS) and expensive and hard to maintain prior maps that are typically used for this purpose. The proposed geo-tracking method aligns data from on-board cameras and lidar sensors with geo-registered orthophotos to continuously localize a vehicle. We train a model in a metric learning setting to extract visual features from ground and aerial images. The ground features are projected into a top-down perspective via the lidar points and are matched with the aerial features to determine the relative pose between vehicle and orthophoto. Our method is the first to utilize on-board cameras in an end-to-end differentiable model for metric self-localization on unseen orthophotos. It exhibits strong generalization, is robust to changes in the environment and requires only geo-poses as ground truth. We evaluate our approach on the KITTI-360 dataset and achieve a mean absolute position error (APE) of 0.94m. We further compare with previous approaches on the KITTI odometry dataset and achieve state-of-the-art results on the geo-tracking task.
Non-Linear Spectral Dimensionality Reduction Under Uncertainty
Feb 09, 2022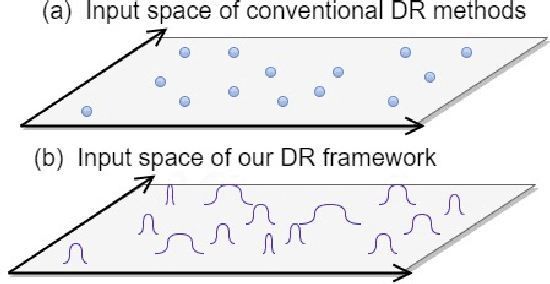
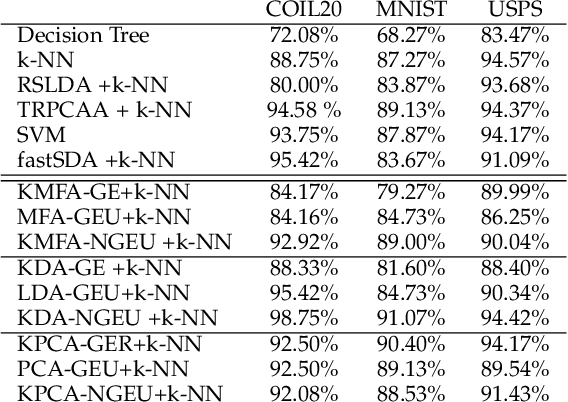
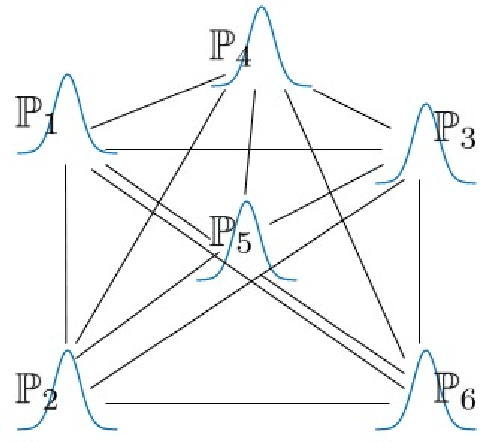
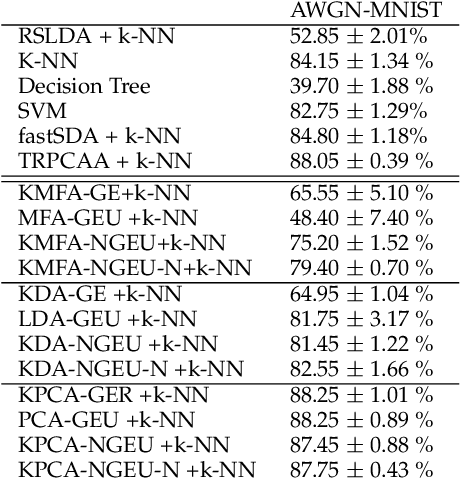
In this paper, we consider the problem of non-linear dimensionality reduction under uncertainty, both from a theoretical and algorithmic perspectives. Since real-world data usually contain measurements with uncertainties and artifacts, the input space in the proposed framework consists of probability distributions to model the uncertainties associated with each sample. We propose a new dimensionality reduction framework, called NGEU, which leverages uncertainty information and directly extends several traditional approaches, e.g., KPCA, MDA/KMFA, to receive as inputs the probability distributions instead of the original data. We show that the proposed NGEU formulation exhibits a global closed-form solution, and we analyze, based on the Rademacher complexity, how the underlying uncertainties theoretically affect the generalization ability of the framework. Empirical results on different datasets show the effectiveness of the proposed framework.
Uncertainty-Aware Multi-View Representation Learning
Jan 15, 2022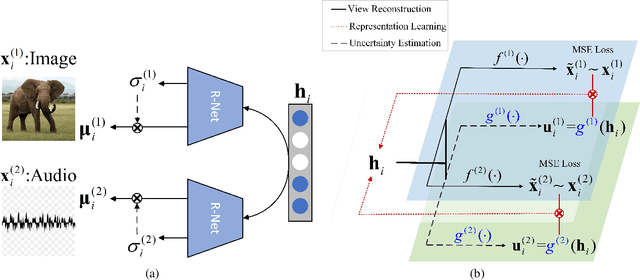
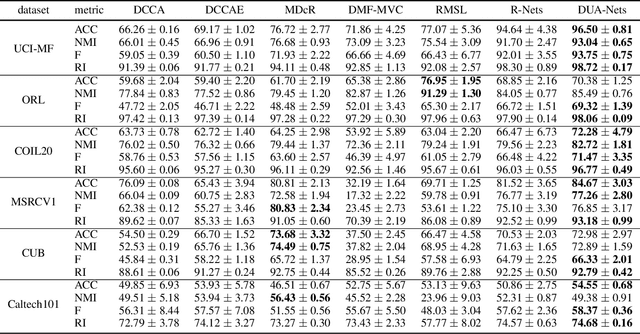
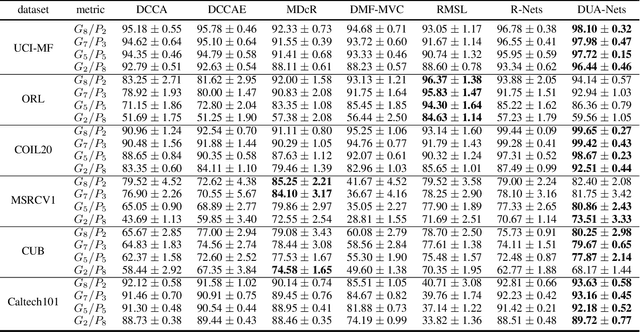
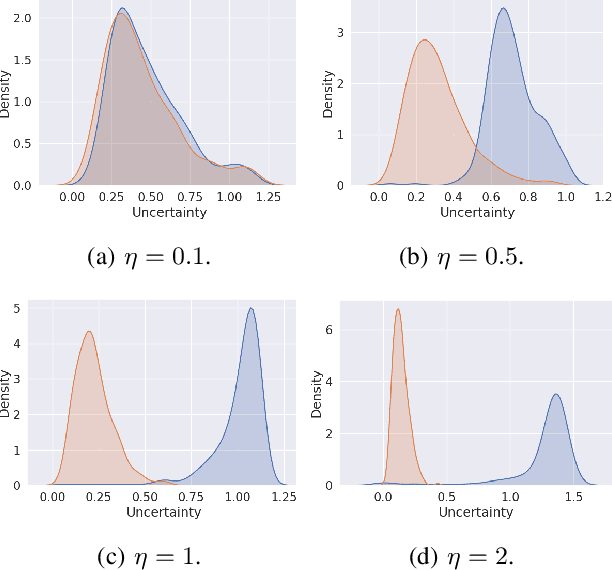
Learning from different data views by exploring the underlying complementary information among them can endow the representation with stronger expressive ability. However, high-dimensional features tend to contain noise, and furthermore, the quality of data usually varies for different samples (even for different views), i.e., one view may be informative for one sample but not the case for another. Therefore, it is quite challenging to integrate multi-view noisy data under unsupervised setting. Traditional multi-view methods either simply treat each view with equal importance or tune the weights of different views to fixed values, which are insufficient to capture the dynamic noise in multi-view data. In this work, we devise a novel unsupervised multi-view learning approach, termed as Dynamic Uncertainty-Aware Networks (DUA-Nets). Guided by the uncertainty of data estimated from the generation perspective, intrinsic information from multiple views is integrated to obtain noise-free representations. Under the help of uncertainty, DUA-Nets weigh each view of individual sample according to data quality so that the high-quality samples (or views) can be fully exploited while the effects from the noisy samples (or views) will be alleviated. Our model achieves superior performance in extensive experiments and shows the robustness to noisy data.
Dynamic Rectification Knowledge Distillation
Jan 27, 2022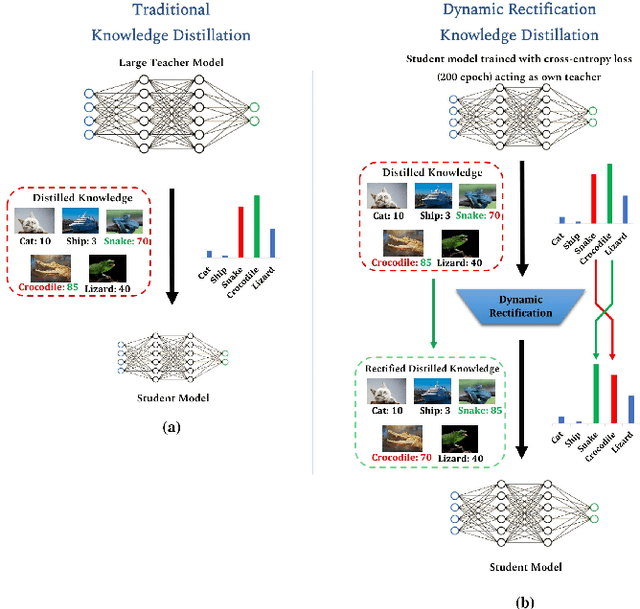
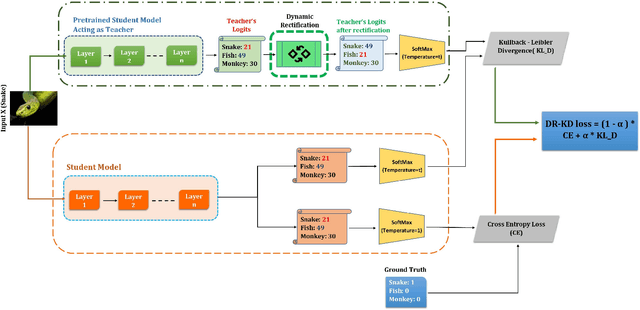
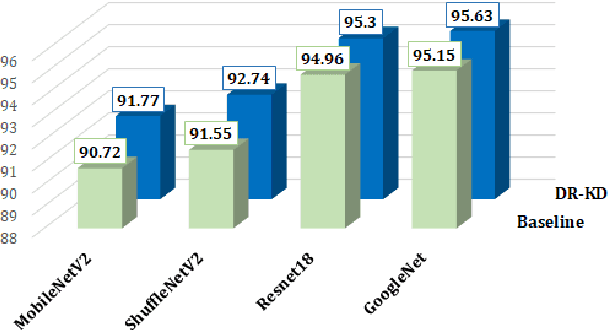
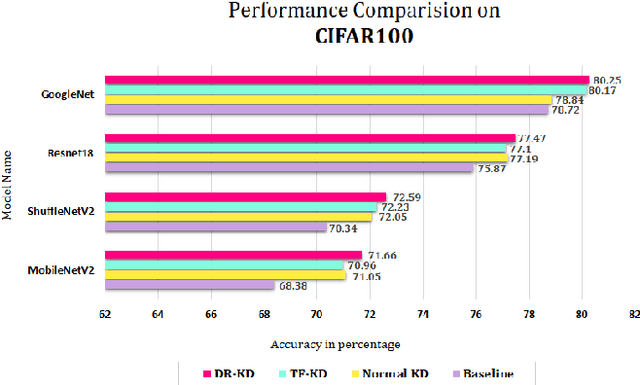
Knowledge Distillation is a technique which aims to utilize dark knowledge to compress and transfer information from a vast, well-trained neural network (teacher model) to a smaller, less capable neural network (student model) with improved inference efficiency. This approach of distilling knowledge has gained popularity as a result of the prohibitively complicated nature of such cumbersome models for deployment on edge computing devices. Generally, the teacher models used to teach smaller student models are cumbersome in nature and expensive to train. To eliminate the necessity for a cumbersome teacher model completely, we propose a simple yet effective knowledge distillation framework that we termed Dynamic Rectification Knowledge Distillation (DR-KD). Our method transforms the student into its own teacher, and if the self-teacher makes wrong predictions while distilling information, the error is rectified prior to the knowledge being distilled. Specifically, the teacher targets are dynamically tweaked by the agency of ground-truth while distilling the knowledge gained from traditional training. Our proposed DR-KD performs remarkably well in the absence of a sophisticated cumbersome teacher model and achieves comparable performance to existing state-of-the-art teacher-free knowledge distillation frameworks when implemented by a low-cost dynamic mannered teacher. Our approach is all-encompassing and can be utilized for any deep neural network training that requires categorization or object recognition. DR-KD enhances the test accuracy on Tiny ImageNet by 2.65% over prominent baseline models, which is significantly better than any other knowledge distillation approach while requiring no additional training costs.
Ensemble plasticity and network adaptability in SNNs
Mar 11, 2022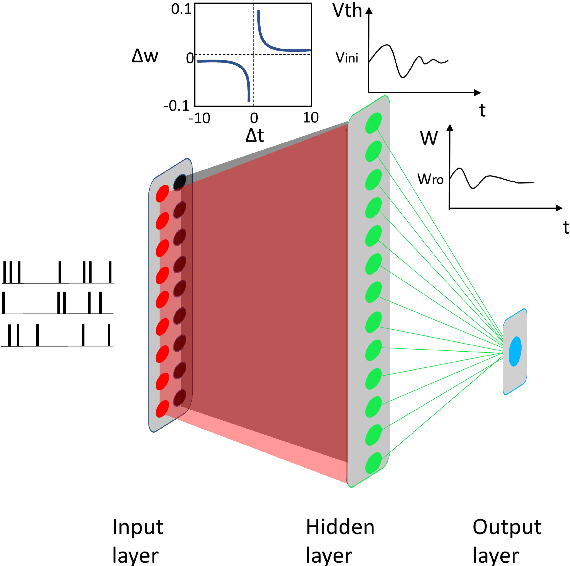
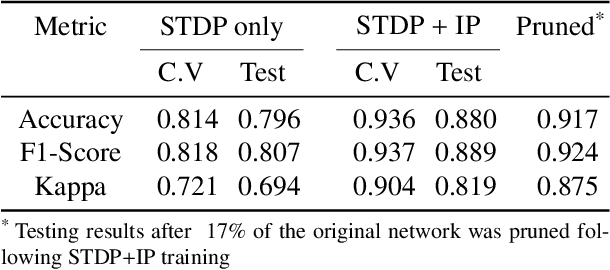
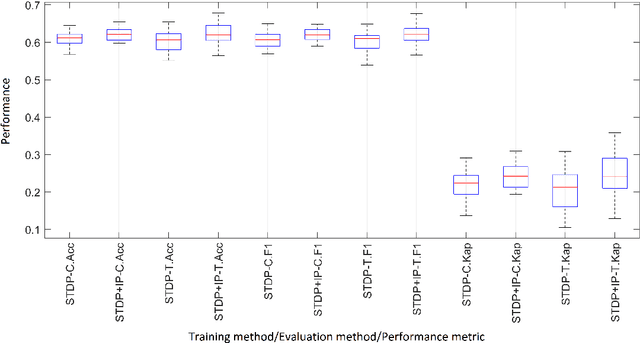
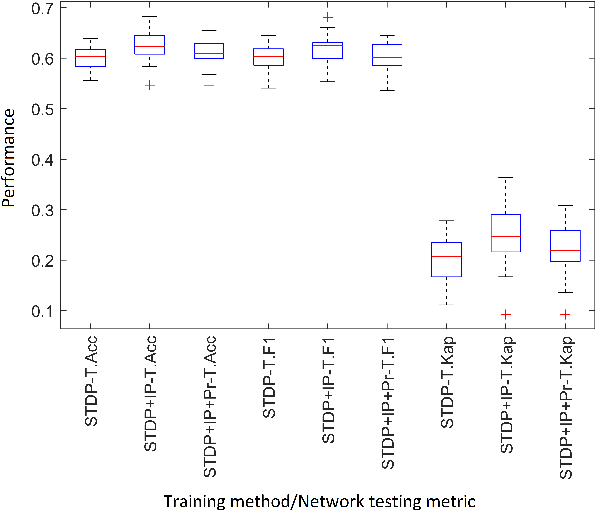
Artificial Spiking Neural Networks (ASNNs) promise greater information processing efficiency because of discrete event-based (i.e., spike) computation. Several Machine Learning (ML) applications use biologically inspired plasticity mechanisms as unsupervised learning techniques to increase the robustness of ASNNs while preserving efficiency. Spike Time Dependent Plasticity (STDP) and Intrinsic Plasticity (IP) (i.e., dynamic spiking threshold adaptation) are two such mechanisms that have been combined to form an ensemble learning method. However, it is not clear how this ensemble learning should be regulated based on spiking activity. Moreover, previous studies have attempted threshold based synaptic pruning following STDP, to increase inference efficiency at the cost of performance in ASNNs. However, this type of structural adaptation, that employs individual weight mechanisms, does not consider spiking activity for pruning which is a better representation of input stimuli. We envisaged that plasticity-based spike-regulation and spike-based pruning will result in ASSNs that perform better in low resource situations. In this paper, a novel ensemble learning method based on entropy and network activation is introduced, which is amalgamated with a spike-rate neuron pruning technique, operated exclusively using spiking activity. Two electroencephalography (EEG) datasets are used as the input for classification experiments with a three-layer feed forward ASNN trained using one-pass learning. During the learning process, we observed neurons assembling into a hierarchy of clusters based on spiking rate. It was discovered that pruning lower spike-rate neuron clusters resulted in increased generalization or a predictable decline in performance.