 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Driving Anomaly Detection Using Conditional Generative Adversarial Network
Mar 15, 2022
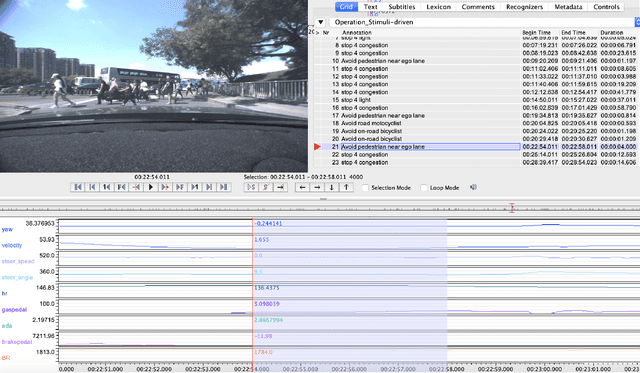
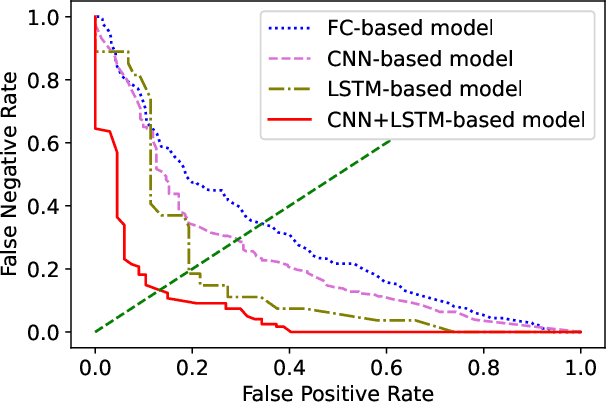
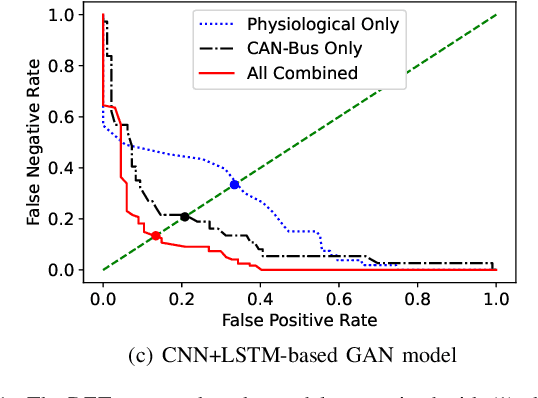
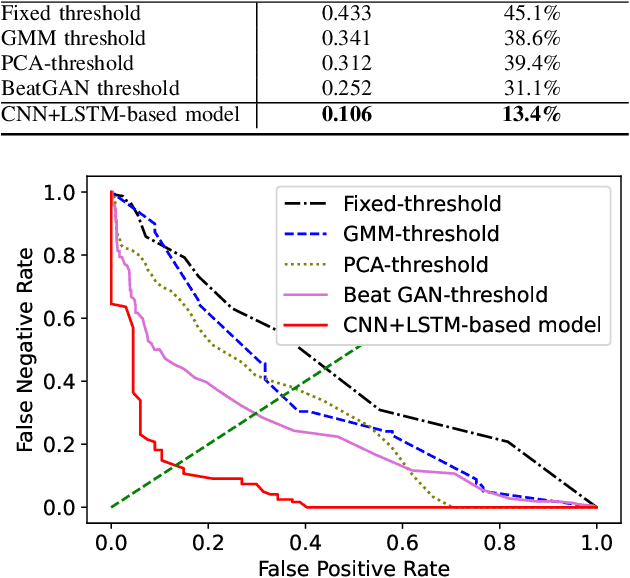
Anomaly driving detection is an important problem in advanced driver assistance systems (ADAS). It is important to identify potential hazard scenarios as early as possible to avoid potential accidents. This study proposes an unsupervised method to quantify driving anomalies using a conditional generative adversarial network (GAN). The approach predicts upcoming driving scenarios by conditioning the models on the previously observed signals. The system uses the difference of the output from the discriminator between the predicted and actual signals as a metric to quantify the anomaly degree of a driving segment. We take a driver-centric approach, considering physiological signals from the driver and controller area network-Bus (CAN-Bus) signals from the vehicle. The approach is implemented with convolutional neural networks (CNNs) to extract discriminative feature representations, and with long short-term memory (LSTM) cells to capture temporal information. The study is implemented and evaluated with the driving anomaly dataset (DAD), which includes 250 hours of naturalistic recordings manually annotated with driving events. The experimental results reveal that recordings annotated with events that are likely to be anomalous, such as avoiding on-road pedestrians and traffic rule violations, have higher anomaly scores than recordings without any event annotation. The results are validated with perceptual evaluations, where annotators are asked to assess the risk and familiarity of the videos detected with high anomaly scores. The results indicate that the driving segments with higher anomaly scores are more risky and less regularly seen on the road than other driving segments, validating the proposed unsupervised approach.
Tractable Fragments of Temporal Sequences of Topological Information
Jul 15, 2020
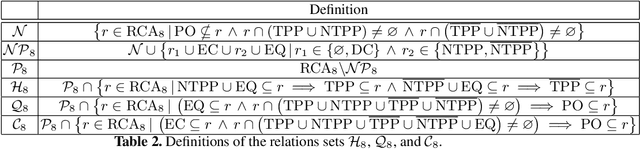

In this paper, we focus on qualitative temporal sequences of topological information. We firstly consider the context of topological temporal sequences of length greater than 3 describing the evolution of regions at consecutive time points. We show that there is no Cartesian subclass containing all the basic relations and the universal relation for which the algebraic closure decides satisfiability. However, we identify some tractable subclasses, by giving up the relations containing the non-tangential proper part relation and not containing the tangential proper part relation. We then formalize an alternative semantics for temporal sequences. We place ourselves in the context of the topological temporal sequences describing the evolution of regions on a partition of time (i.e. an alternation of instants and intervals). In this context, we identify large tractable fragments.
DeepTx: Deep Learning Beamforming with Channel Prediction
Feb 16, 2022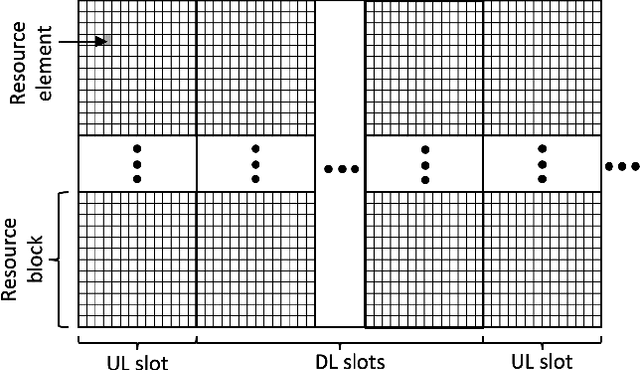
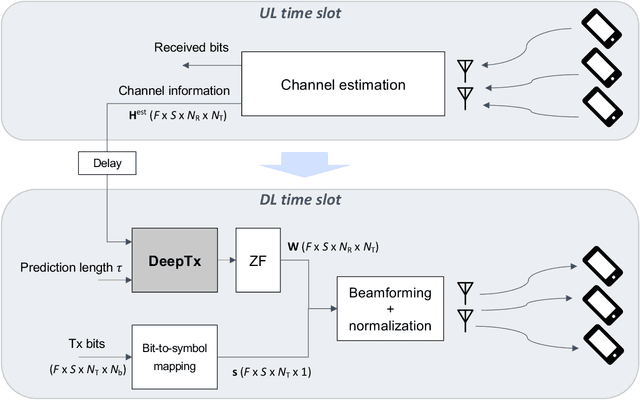
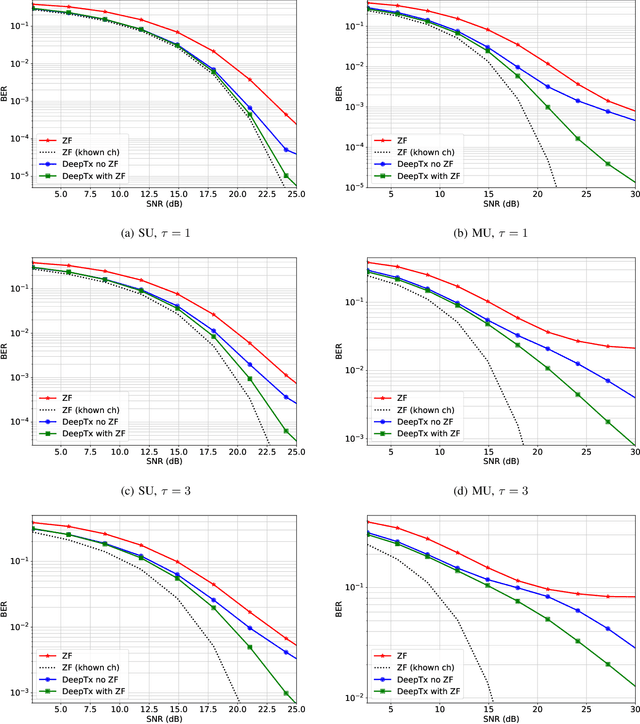
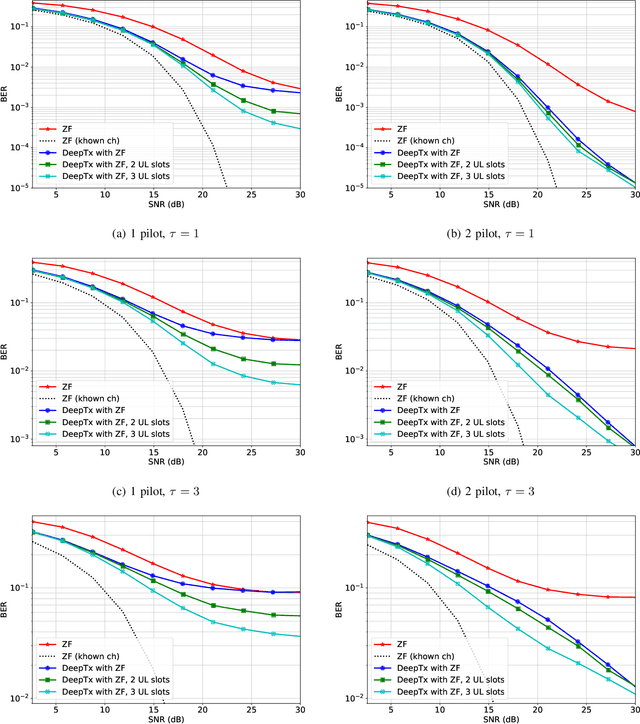
Machine learning algorithms have recently been considered for many tasks in the field of wireless communications. Previously, we have proposed the use of a deep fully convolutional neural network (CNN) for receiver processing and shown it to provide considerable performance gains. In this study, we focus on machine learning algorithms for the transmitter. In particular, we consider beamforming and propose a CNN which, for a given uplink channel estimate as input, outputs downlink channel information to be used for beamforming. The CNN is trained in a supervised manner considering both uplink and downlink transmissions with a loss function that is based on UE receiver performance. The main task of the neural network is to predict the channel evolution between uplink and downlink slots, but it can also learn to handle inefficiencies and errors in the whole chain, including the actual beamforming phase. The provided numerical experiments demonstrate the improved beamforming performance.
Green Machine Learning via Augmented Gaussian Processes and Multi-Information Source Optimization
Jun 25, 2020
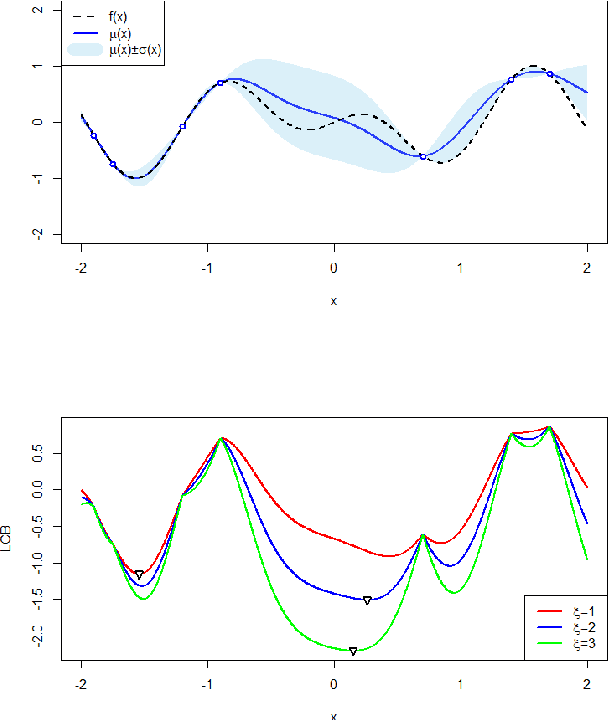
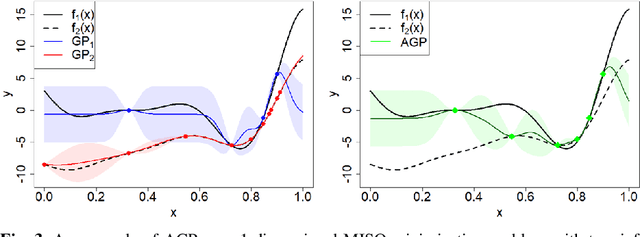
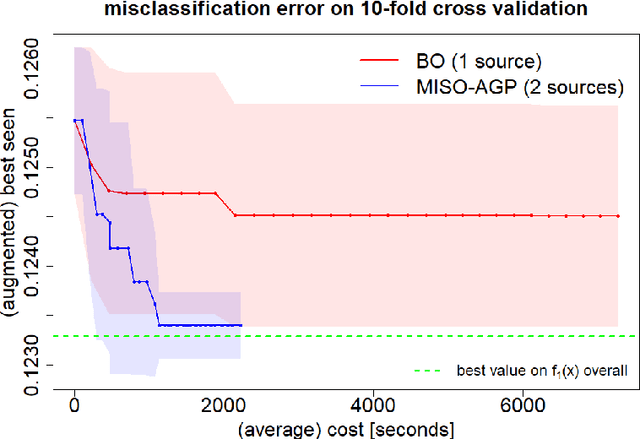
Searching for accurate Machine and Deep Learning models is a computationally expensive and awfully energivorous process. A strategy which has been gaining recently importance to drastically reduce computational time and energy consumed is to exploit the availability of different information sources, with different computational costs and different "fidelity", typically smaller portions of a large dataset. The multi-source optimization strategy fits into the scheme of Gaussian Process based Bayesian Optimization. An Augmented Gaussian Process method exploiting multiple information sources (namely, AGP-MISO) is proposed. The Augmented Gaussian Process is trained using only "reliable" information among available sources. A novel acquisition function is defined according to the Augmented Gaussian Process. Computational results are reported related to the optimization of the hyperparameters of a Support Vector Machine (SVM) classifier using two sources: a large dataset - the most expensive one - and a smaller portion of it. A comparison with a traditional Bayesian Optimization approach to optimize the hyperparameters of the SVM classifier on the large dataset only is reported.
A New Design of Cache-aided Multiuser Private Information Retrieval with Uncoded Prefetching
Feb 02, 2021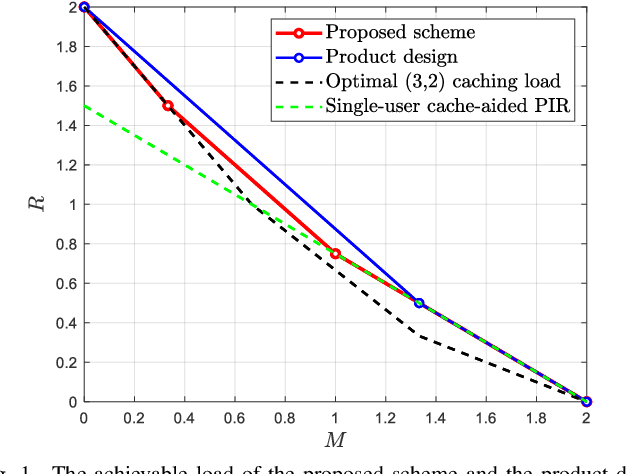
In the problem of cache-aided multiuser private information retrieval (MuPIR), a set of $K_{\rm u}$ cache-equipped users wish to privately download a set of messages from $N$ distributed databases each holding a library of $K$ messages. The system works in two phases: {\it cache placement (prefetching) phase} in which the users fill up their cache memory, and {\it private delivery phase} in which the users' demands are revealed and they download an answer from each database so that the their desired messages can be recovered while each individual database learns nothing about the identities of the requested messages. The goal is to design the placement and the private delivery phases such that the \emph{load}, which is defined as the total number of downloaded bits normalized by the message size, is minimized given any user memory size. This paper considers the MuPIR problem with two messages, arbitrary number of users and databases where uncoded prefetching is assumed, i.e., the users directly copy some bits from the library as their cached contents. We propose a novel MuPIR scheme inspired by the Maddah-Ali and Niesen (MAN) coded caching scheme. The proposed scheme achieves lower load than any existing schemes, especially the product design (PD), and is shown to be optimal within a factor of $8$ in general and exactly optimal at very high or low memory regime.
Distantly-Supervised Neural Relation Extraction with Side Information using BERT
Apr 29, 2020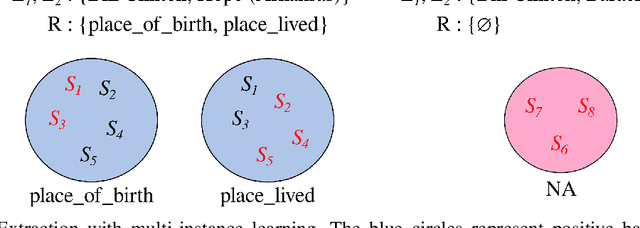
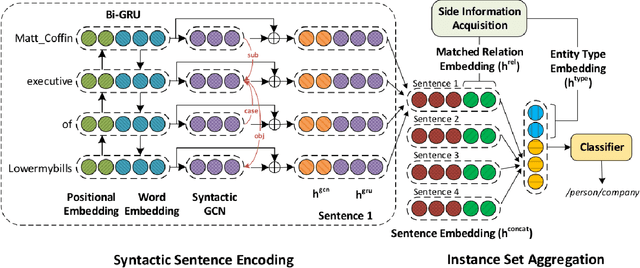
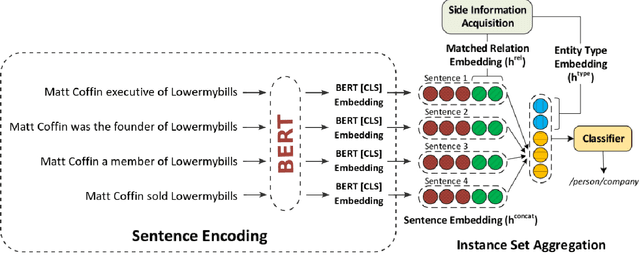
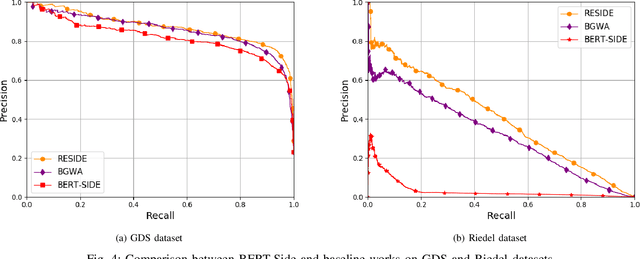
Relation extraction (RE) consists in categorizing the relationship between entities in a sentence. A recent paradigm to develop relation extractors is Distant Supervision (DS), which allows the automatic creation of new datasets by taking an alignment between a text corpus and a Knowledge Base (KB). KBs can sometimes also provide additional information to the RE task. One of the methods that adopt this strategy is the RESIDE model, which proposes a distantly-supervised neural relation extraction using side information from KBs. Considering that this method outperformed state-of-the-art baselines, in this paper, we propose a related approach to RESIDE also using additional side information, but simplifying the sentence encoding with BERT embeddings. Through experiments, we show the effectiveness of the proposed method in Google Distant Supervision and Riedel datasets concerning the BGWA and RESIDE baseline methods. Although Area Under the Curve is decreased because of unbalanced datasets, P@N results have shown that the use of BERT as sentence encoding allows superior performance to baseline methods.
Best Practices and Scoring System on Reviewing A.I. based Medical Imaging Papers: Part 1 Classification
Feb 03, 2022
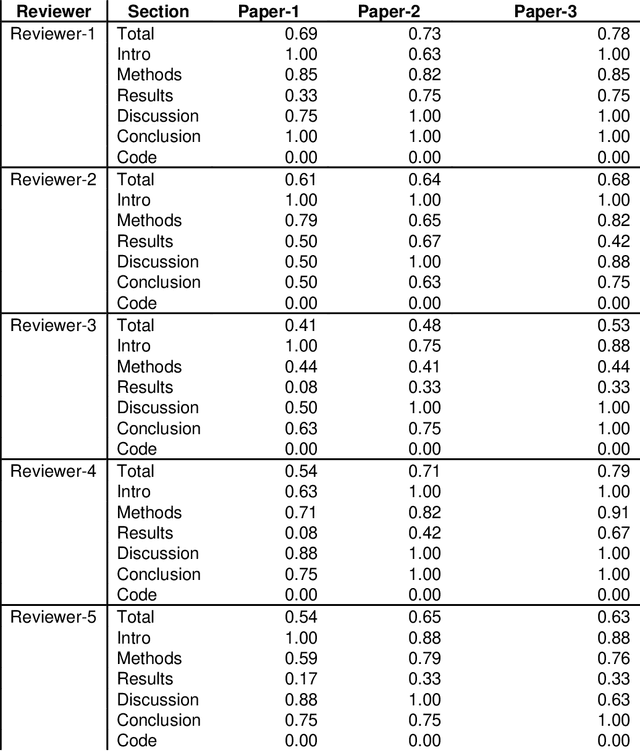
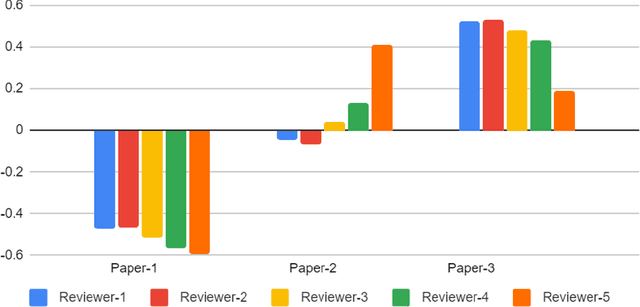
With the recent advances in A.I. methodologies and their application to medical imaging, there has been an explosion of related research programs utilizing these techniques to produce state-of-the-art classification performance. Ultimately, these research programs culminate in submission of their work for consideration in peer reviewed journals. To date, the criteria for acceptance vs. rejection is often subjective; however, reproducible science requires reproducible review. The Machine Learning Education Sub-Committee of SIIM has identified a knowledge gap and a serious need to establish guidelines for reviewing these studies. Although there have been several recent papers with this goal, this present work is written from the machine learning practitioners standpoint. In this series, the committee will address the best practices to be followed in an A.I.-based study and present the required sections in terms of examples and discussion of what should be included to make the studies cohesive, reproducible, accurate, and self-contained. This first entry in the series focuses on the task of image classification. Elements such as dataset curation, data pre-processing steps, defining an appropriate reference standard, data partitioning, model architecture and training are discussed. The sections are presented as they would be detailed in a typical manuscript, with content describing the necessary information that should be included to make sure the study is of sufficient quality to be considered for publication. The goal of this series is to provide resources to not only help improve the review process for A.I.-based medical imaging papers, but to facilitate a standard for the information that is presented within all components of the research study. We hope to provide quantitative metrics in what otherwise may be a qualitative review process.
Information-theoretic analysis for transfer learning
May 19, 2020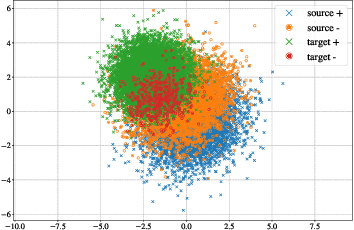
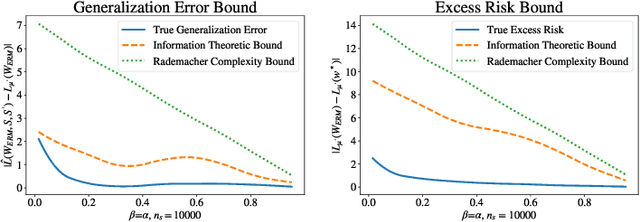
Transfer learning, or domain adaptation, is concerned with machine learning problems in which training and testing data come from possibly different distributions (denoted as $\mu$ and $\mu'$, respectively). In this work, we give an information-theoretic analysis on the generalization error and the excess risk of transfer learning algorithms, following a line of work initiated by Russo and Zhou. Our results suggest, perhaps as expected, that the Kullback-Leibler (KL) divergence $D(mu||mu')$ plays an important role in characterizing the generalization error in the settings of domain adaptation. Specifically, we provide generalization error upper bounds for general transfer learning algorithms and extend the results to a specific empirical risk minimization (ERM) algorithm where data from both distributions are available in the training phase. We further apply the method to iterative, noisy gradient descent algorithms, and obtain upper bounds which can be easily calculated, only using parameters from the learning algorithms. A few illustrative examples are provided to demonstrate the usefulness of the results. In particular, our bound is tighter in specific classification problems than the bound derived using Rademacher complexity.
Learning Representations of Entities and Relations
Jan 31, 2022
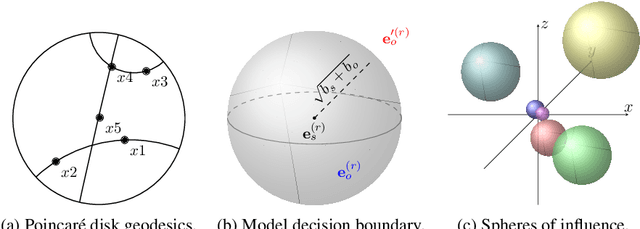
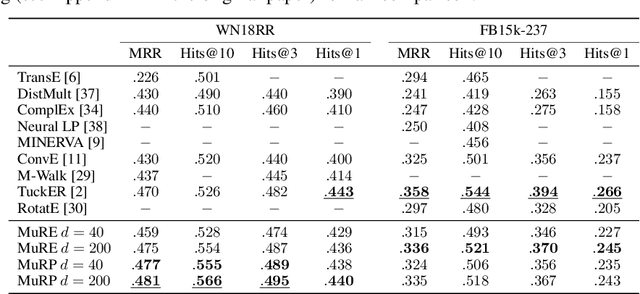
Encoding facts as representations of entities and binary relationships between them, as learned by knowledge graph representation models, is useful for various tasks, including predicting new facts, question answering, fact checking and information retrieval. The focus of this thesis is on (i) improving knowledge graph representation with the aim of tackling the link prediction task; and (ii) devising a theory on how semantics can be captured in the geometry of relation representations. Most knowledge graphs are very incomplete and manually adding new information is costly, which drives the development of methods which can automatically infer missing facts. The first contribution of this thesis is HypER, a convolutional model which simplifies and improves upon the link prediction performance of the existing convolutional state-of-the-art model ConvE and can be mathematically explained in terms of constrained tensor factorisation. The second contribution is TuckER, a relatively straightforward linear model, which, at the time of its introduction, obtained state-of-the-art link prediction performance across standard datasets. The third contribution is MuRP, first multi-relational graph representation model embedded in hyperbolic space. MuRP outperforms all existing models and its Euclidean counterpart MuRE in link prediction on hierarchical knowledge graph relations whilst requiring far fewer dimensions. Despite the development of a large number of knowledge graph representation models with gradually increasing predictive performance, relatively little is known of the latent structure they learn. We generalise recent theoretical understanding of how semantic relations of similarity, paraphrase and analogy are encoded in the geometric interactions of word embeddings to how more general relations, as found in knowledge graphs, can be encoded in their representations.
IPD:An Incremental Prototype based DBSCAN for large-scale data with cluster representatives
Feb 16, 2022
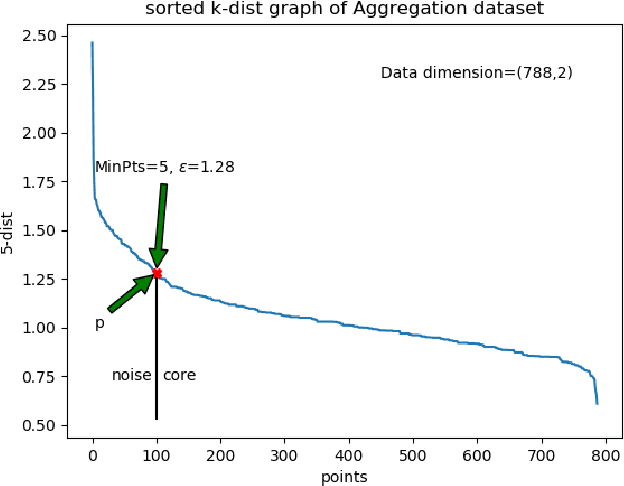
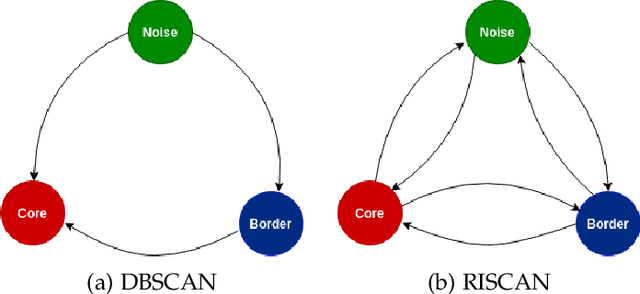
DBSCAN is a fundamental density-based clustering technique that identifies any arbitrary shape of the clusters. However, it becomes infeasible while handling big data. On the other hand, centroid-based clustering is important for detecting patterns in a dataset since unprocessed data points can be labeled to their nearest centroid. However, it can not detect non-spherical clusters. For a large data, it is not feasible to store and compute labels of every samples. These can be done as and when the information is required. The purpose can be accomplished when clustering act as a tool to identify cluster representatives and query is served by assigning cluster labels of nearest representative. In this paper, we propose an Incremental Prototype-based DBSCAN (IPD) algorithm which is designed to identify arbitrary-shaped clusters for large-scale data. Additionally, it chooses a set of representatives for each cluster.