 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Exploratory Study of COVID-19 Information on Twitter in the Greater Region
Aug 12, 2020

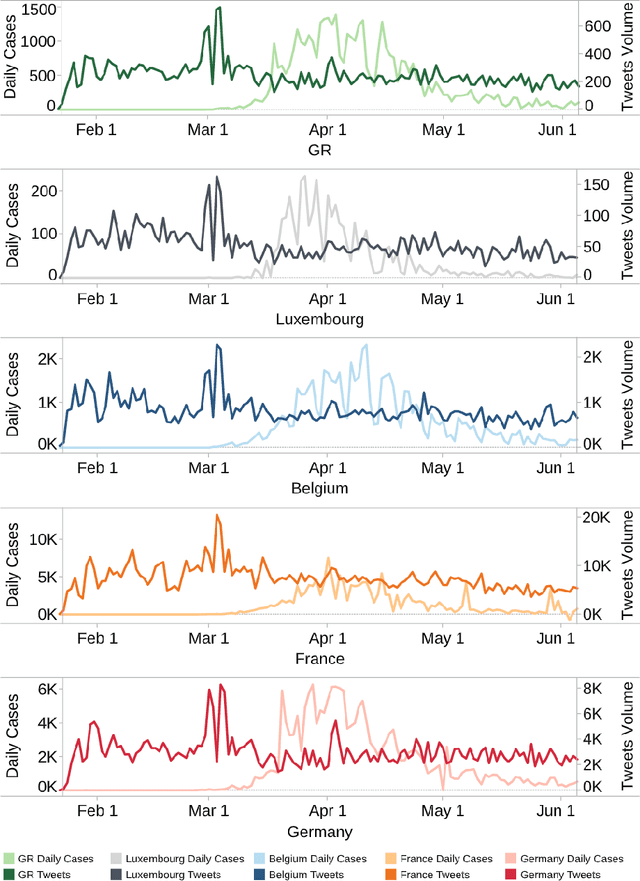
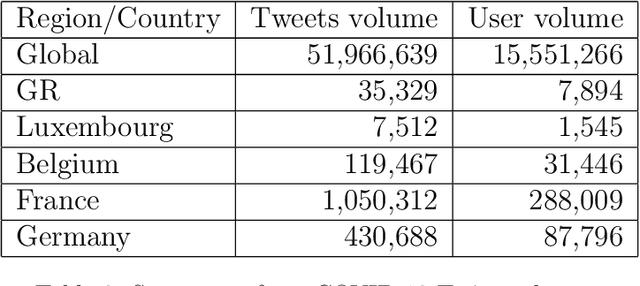
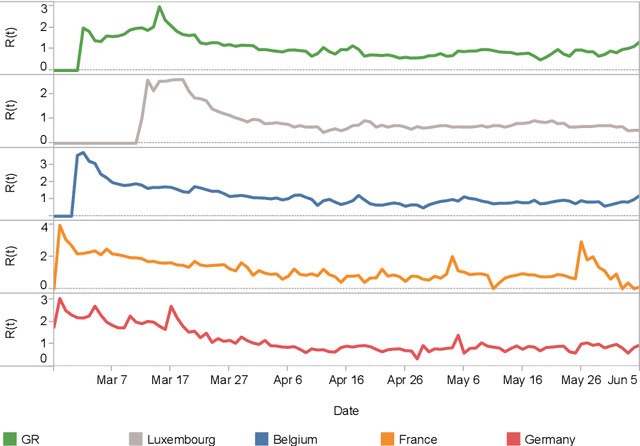
The outbreak of the Coronavirus disease (COVID-19) leads to an outbreak of pandemic information in major online social networks (OSNs). In the constantly changing situation, OSNs are becoming a critical conduit for people in expressing opinions and seek up-to-the-minute information. Thus, social behaviour on OSNs may become a predictor or reflection of reality. This paper aims to study the social behaviour of the public in the Greater Region (GR) and related countries based on Twitter information with machine learning and representation learning methods. We find that tweets volume only can be a predictor of outbreaks in a particular period of the pandemic. Moreover, we map out the evolution of public behaviour in each country from 2020/01/22 to 2020/06/05, figuring out the main differences in public behaviour between GR and related countries. Finally, we conclude that tweets volume of anti-contiguous measures may affect the effeteness of the government policy.
Embedded Deep Bilinear Interactive Information and Selective Fusion for Multi-view Learning
Jul 13, 2020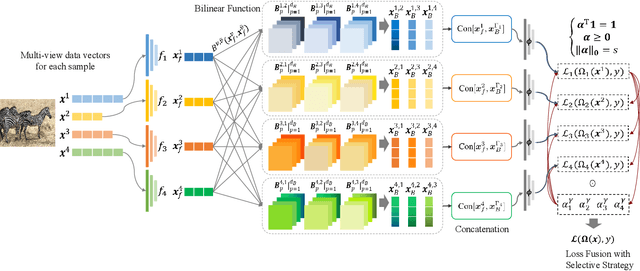
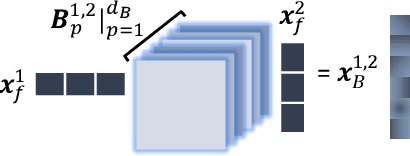
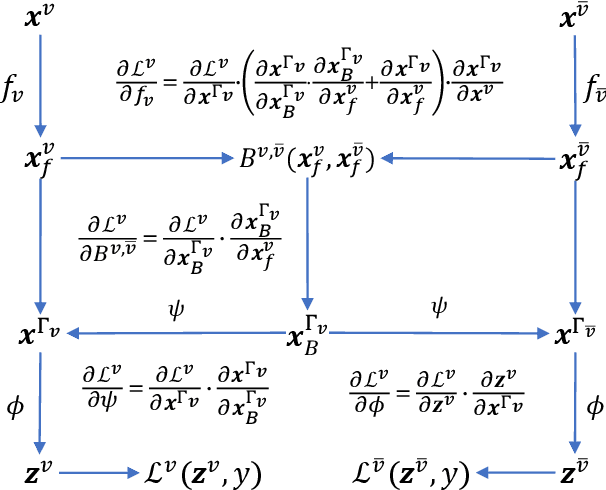
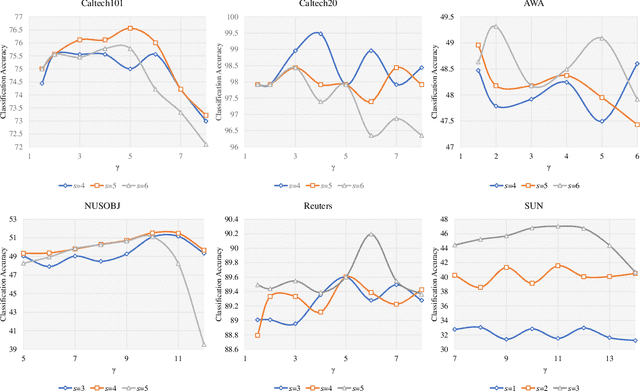
As a concrete application of multi-view learning, multi-view classification improves the traditional classification methods significantly by integrating various views optimally. Although most of the previous efforts have been demonstrated the superiority of multi-view learning, it can be further improved by comprehensively embedding more powerful cross-view interactive information and a more reliable multi-view fusion strategy in intensive studies. To fulfill this goal, we propose a novel multi-view learning framework to make the multi-view classification better aimed at the above-mentioned two aspects. That is, we seamlessly embed various intra-view information, cross-view multi-dimension bilinear interactive information, and a new view ensemble mechanism into a unified framework to make a decision via the optimization. In particular, we train different deep neural networks to learn various intra-view representations, and then dynamically learn multi-dimension bilinear interactive information from different bilinear similarities via the bilinear function between views. After that, we adaptively fuse the representations of multiple views by flexibly tuning the parameters of the view-weight, which not only avoids the trivial solution of weight but also provides a new way to select a few discriminative views that are beneficial to make a decision for the multi-view classification. Extensive experiments on six publicly available datasets demonstrate the effectiveness of the proposed method.
Simultaneous Transmit Diversity and Passive Beamforming with Large-Scale Intelligent Reflecting Surface
Feb 09, 2022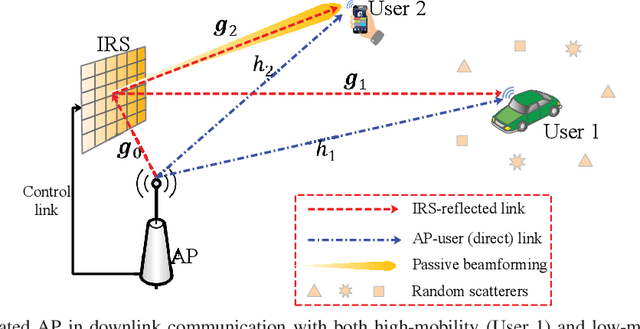
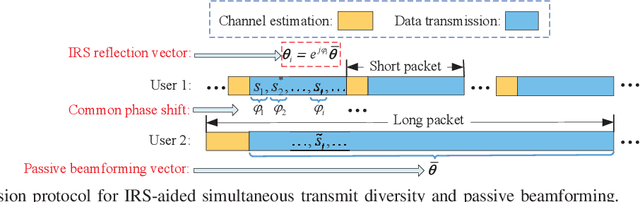
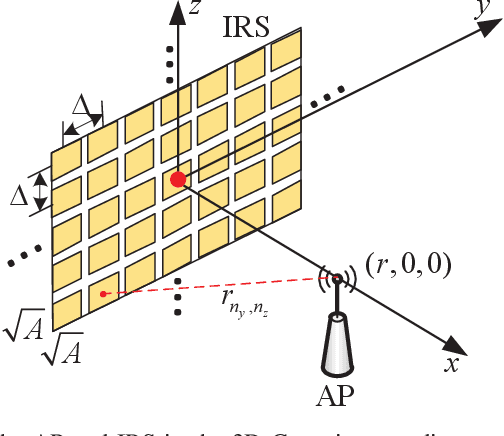
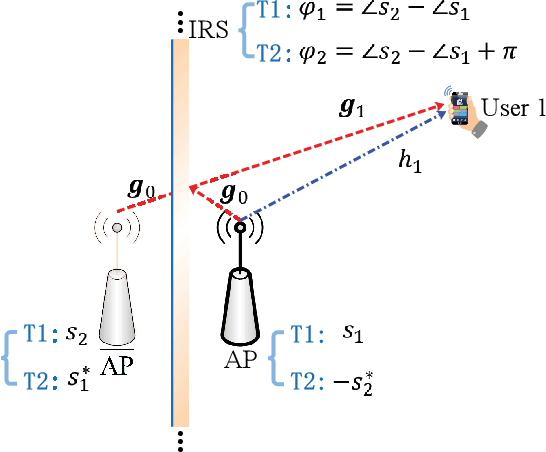
Intelligent reflecting surface (IRS) has emerged as a cost-effective solution to enhance wireless communication performance via passive signal reflection. Existing works on IRS have mainly focused on investigating IRS's passive beamforming/reflection design to boost the communication rate for users assuming that their channel state information (CSI) is fully or partially known. However, how to exploit IRS to improve the wireless transmission reliability without any CSI, which is typical in high-mobility/delay-sensitive communication scenarios, remains largely open. In this paper, we study a new IRS-aided communication system with the IRS integrated to its aided access point (AP) to achieve both functions of transmit diversity and passive beamforming simultaneously. Specifically, we first show an interesting result that the IRS's passive beamforming gain in any direction is invariant to the common phase-shift applied to all of its reflecting elements. Accordingly, we design the common phase-shift of IRS elements to achieve transmit diversity at the AP side without the need of any CSI of the users. In addition, we propose a practical method for the users to estimate the CSI at the receiver side for information decoding. Meanwhile, we show that the conventional passive beamforming gain of IRS can be retained for the other users with their CSI known at the AP. Furthermore, we derive the asymptotic performance of both IRS-aided transmit diversity and passive beamforming in closed-form, by considering the large-scale IRS with an infinite number of elements. Numerical results validate our analysis and show the performance gains of the proposed IRS-aided simultaneous transmit diversity and passive beamforming scheme over other benchmark schemes.
Physics-Informed Graph Learning: A Survey
Feb 22, 2022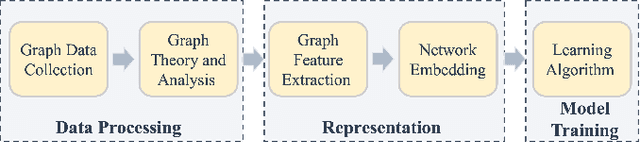
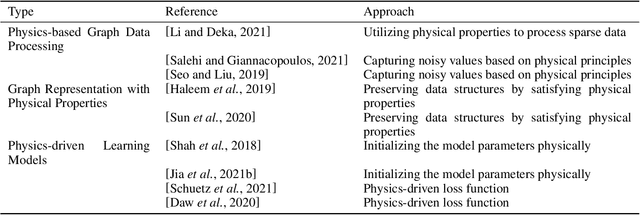
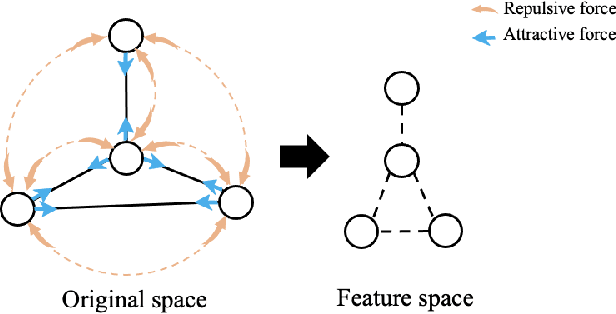
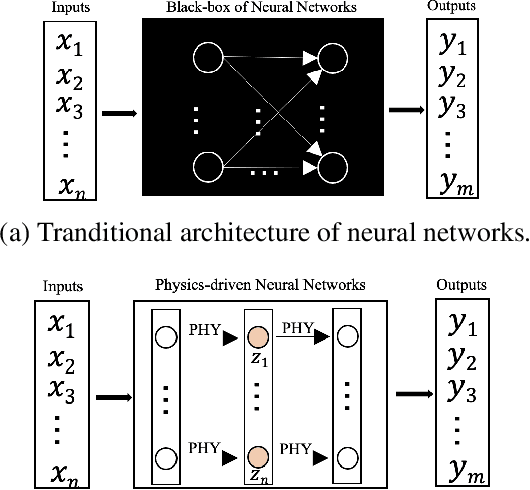
An expeditious development of graph learning in recent years has found innumerable applications in several diversified fields. Of the main associated challenges are the volume and complexity of graph data. A lot of research has been evolving around the preservation of graph data in a low dimensional space. The graph learning models suffer from the inability to maintain original graph information. In order to compensate for this inability, physics-informed graph learning (PIGL) is emerging. PIGL incorporates physics rules while performing graph learning, which enables numerous potentials. This paper presents a systematic review of PIGL methods. We begin with introducing a unified framework of graph learning models, and then examine existing PIGL methods in relation to the unified framework. We also discuss several future challenges for PIGL. This survey paper is expected to stimulate innovative research and development activities pertaining to PIGL.
Exact Community Recovery over Signed Graphs
Feb 22, 2022
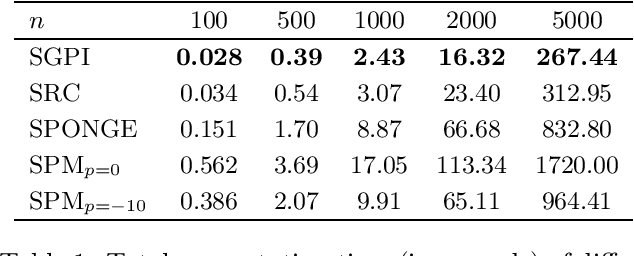

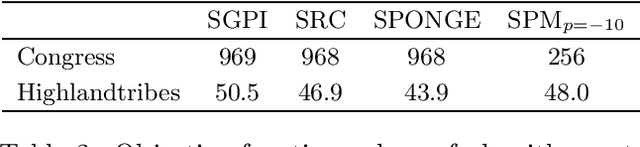
Signed graphs encode similarity and dissimilarity relationships among different entities with positive and negative edges. In this paper, we study the problem of community recovery over signed graphs generated by the signed stochastic block model (SSBM) with two equal-sized communities. Our approach is based on the maximum likelihood estimation (MLE) of the SSBM. Unlike many existing approaches, our formulation reveals that the positive and negative edges of a signed graph should be treated unequally. We then propose a simple two-stage iterative algorithm for solving the regularized MLE. It is shown that in the logarithmic degree regime, the proposed algorithm can exactly recover the underlying communities in nearly-linear time at the information-theoretic limit. Numerical results on both synthetic and real data are reported to validate and complement our theoretical developments and demonstrate the efficacy of the proposed method.
Challenges and Opportunities in Rapid Epidemic Information Propagation with Live Knowledge Aggregation from Social Media
Nov 09, 2020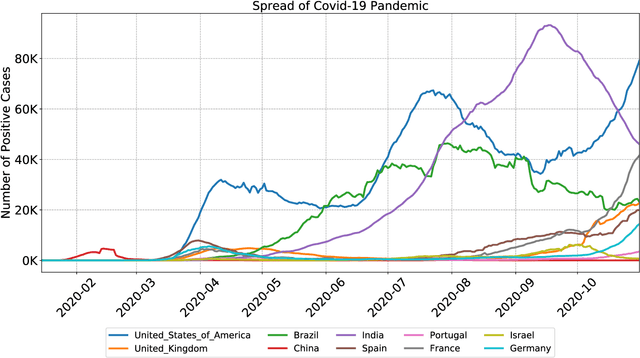
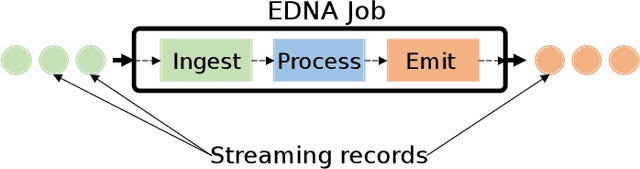
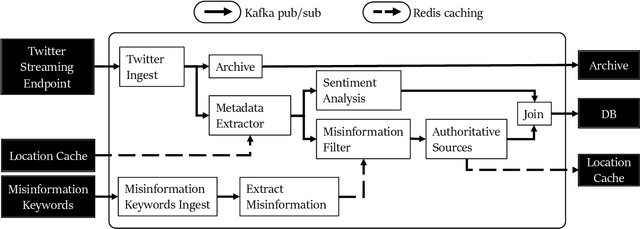
A rapidly evolving situation such as the COVID-19 pandemic is a significant challenge for AI/ML models because of its unpredictability. %The most reliable indicator of the pandemic spreading has been the number of test positive cases. However, the tests are both incomplete (due to untested asymptomatic cases) and late (due the lag from the initial contact event, worsening symptoms, and test results). Social media can complement physical test data due to faster and higher coverage, but they present a different challenge: significant amounts of noise, misinformation and disinformation. We believe that social media can become good indicators of pandemic, provided two conditions are met. The first (True Novelty) is the capture of new, previously unknown, information from unpredictably evolving situations. The second (Fact vs. Fiction) is the distinction of verifiable facts from misinformation and disinformation. Social media information that satisfy those two conditions are called live knowledge. We apply evidence-based knowledge acquisition (EBKA) approach to collect, filter, and update live knowledge through the integration of social media sources with authoritative sources. Although limited in quantity, the reliable training data from authoritative sources enable the filtering of misinformation as well as capturing truly new information. We describe the EDNA/LITMUS tools that implement EBKA, integrating social media such as Twitter and Facebook with authoritative sources such as WHO and CDC, creating and updating live knowledge on the COVID-19 pandemic.
CapsNet for Medical Image Segmentation
Mar 16, 2022

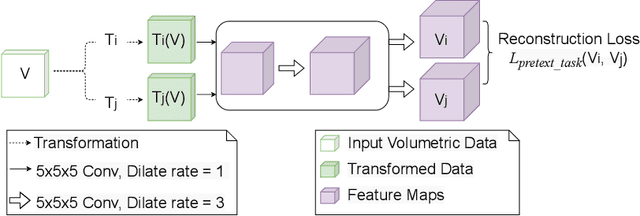
Convolutional Neural Networks (CNNs) have been successful in solving tasks in computer vision including medical image segmentation due to their ability to automatically extract features from unstructured data. However, CNNs are sensitive to rotation and affine transformation and their success relies on huge-scale labeled datasets capturing various input variations. This network paradigm has posed challenges at scale because acquiring annotated data for medical segmentation is expensive, and strict privacy regulations. Furthermore, visual representation learning with CNNs has its own flaws, e.g., it is arguable that the pooling layer in traditional CNNs tends to discard positional information and CNNs tend to fail on input images that differ in orientations and sizes. Capsule network (CapsNet) is a recent new architecture that has achieved better robustness in representation learning by replacing pooling layers with dynamic routing and convolutional strides, which has shown potential results on popular tasks such as classification, recognition, segmentation, and natural language processing. Different from CNNs, which result in scalar outputs, CapsNet returns vector outputs, which aim to preserve the part-whole relationships. In this work, we first introduce the limitations of CNNs and fundamentals of CapsNet. We then provide recent developments of CapsNet for the task of medical image segmentation. We finally discuss various effective network architectures to implement a CapsNet for both 2D images and 3D volumetric medical image segmentation.
Which side are you on? Insider-Outsider classification in conspiracy-theoretic social media
Mar 08, 2022
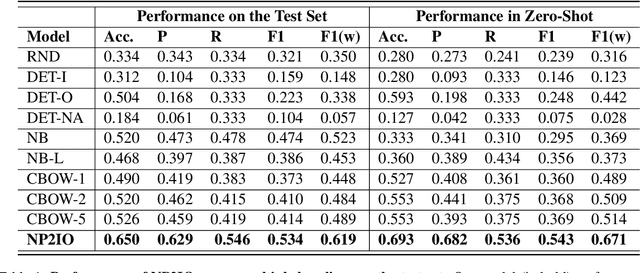
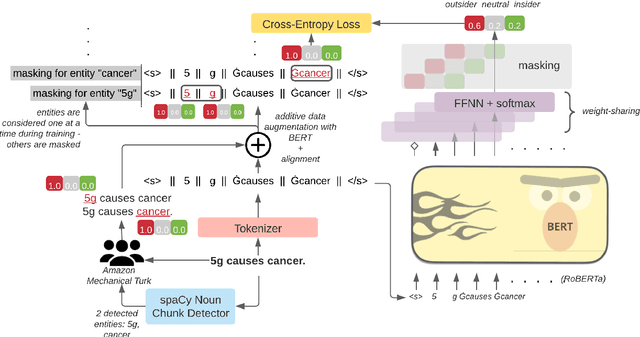
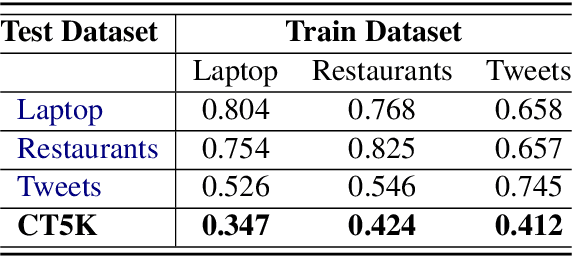
Social media is a breeding ground for threat narratives and related conspiracy theories. In these, an outside group threatens the integrity of an inside group, leading to the emergence of sharply defined group identities: Insiders -- agents with whom the authors identify and Outsiders -- agents who threaten the insiders. Inferring the members of these groups constitutes a challenging new NLP task: (i) Information is distributed over many poorly-constructed posts; (ii) Threats and threat agents are highly contextual, with the same post potentially having multiple agents assigned to membership in either group; (iii) An agent's identity is often implicit and transitive; and (iv) Phrases used to imply Outsider status often do not follow common negative sentiment patterns. To address these challenges, we define a novel Insider-Outsider classification task. Because we are not aware of any appropriate existing datasets or attendant models, we introduce a labeled dataset (CT5K) and design a model (NP2IO) to address this task. NP2IO leverages pretrained language modeling to classify Insiders and Outsiders. NP2IO is shown to be robust, generalizing to noun phrases not seen during training, and exceeding the performance of non-trivial baseline models by $20\%$.
MT-UDA: Towards Unsupervised Cross-modality Medical Image Segmentation with Limited Source Labels
Mar 23, 2022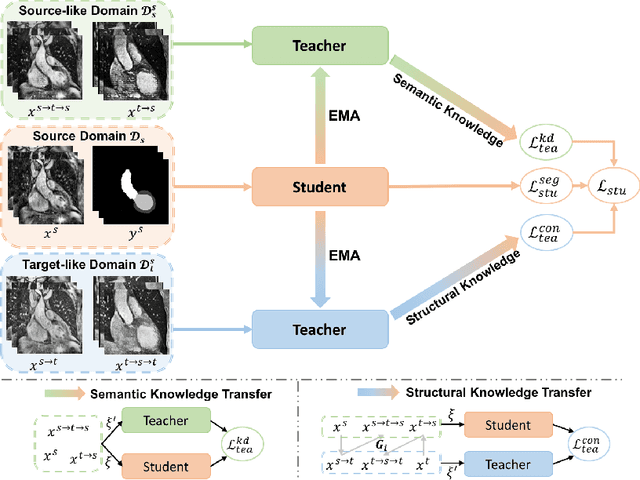
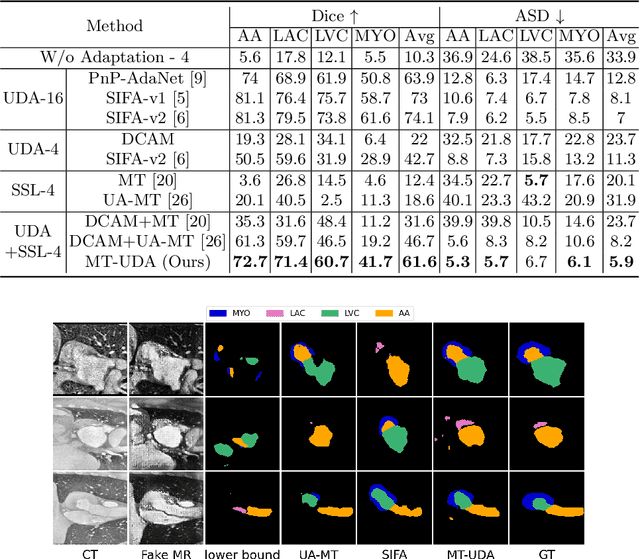
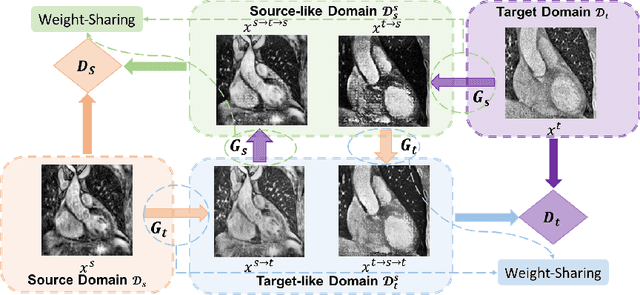
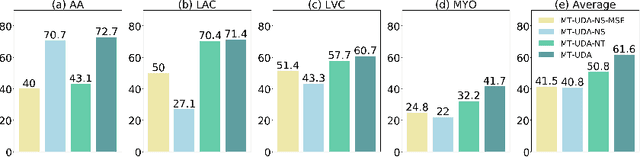
The success of deep convolutional neural networks (DCNNs) benefits from high volumes of annotated data. However, annotating medical images is laborious, expensive, and requires human expertise, which induces the label scarcity problem. Especially when encountering the domain shift, the problem becomes more serious. Although deep unsupervised domain adaptation (UDA) can leverage well-established source domain annotations and abundant target domain data to facilitate cross-modality image segmentation and also mitigate the label paucity problem on the target domain, the conventional UDA methods suffer from severe performance degradation when source domain annotations are scarce. In this paper, we explore a challenging UDA setting - limited source domain annotations. We aim to investigate how to efficiently leverage unlabeled data from the source and target domains with limited source annotations for cross-modality image segmentation. To achieve this, we propose a new label-efficient UDA framework, termed MT-UDA, in which the student model trained with limited source labels learns from unlabeled data of both domains by two teacher models respectively in a semi-supervised manner. More specifically, the student model not only distills the intra-domain semantic knowledge by encouraging prediction consistency but also exploits the inter-domain anatomical information by enforcing structural consistency. Consequently, the student model can effectively integrate the underlying knowledge beneath available data resources to mitigate the impact of source label scarcity and yield improved cross-modality segmentation performance. We evaluate our method on MM-WHS 2017 dataset and demonstrate that our approach outperforms the state-of-the-art methods by a large margin under the source-label scarcity scenario.
* Accept by MICCAI 2021, code at: https://github.com/jacobzhaoziyuan/MT-UDA
Understanding Approximate Fisher Information for Fast Convergence of Natural Gradient Descent in Wide Neural Networks
Oct 02, 2020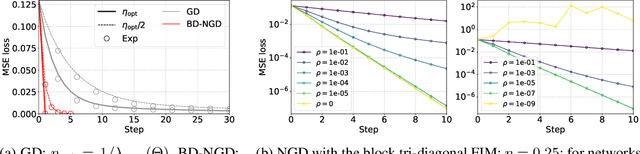
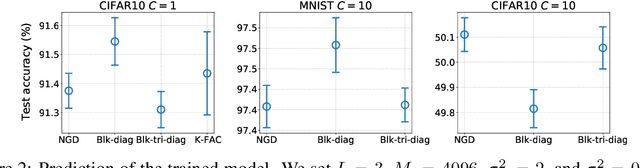
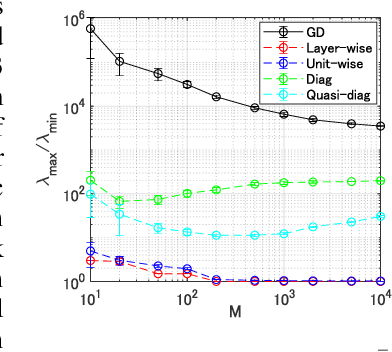
Natural Gradient Descent (NGD) helps to accelerate the convergence of gradient descent dynamics, but it requires approximations in large-scale deep neural networks because of its high computational cost. Empirical studies have confirmed that some NGD methods with approximate Fisher information converge sufficiently fast in practice. Nevertheless, it remains unclear from the theoretical perspective why and under what conditions such heuristic approximations work well. In this work, we reveal that, under specific conditions, NGD with approximate Fisher information achieves the same fast convergence to global minima as exact NGD. We consider deep neural networks in the infinite-width limit, and analyze the asymptotic training dynamics of NGD in function space via the neural tangent kernel. In the function space, the training dynamics with the approximate Fisher information are identical to those with the exact Fisher information, and they converge quickly. The fast convergence holds in layer-wise approximations; for instance, in block diagonal approximation where each block corresponds to a layer as well as in block tri-diagonal and K-FAC approximations. We also find that a unit-wise approximation achieves the same fast convergence under some assumptions. All of these different approximations have an isotropic gradient in the function space, and this plays a fundamental role in achieving the same convergence properties in training. Thus, the current study gives a novel and unified theoretical foundation with which to understand NGD methods in deep learning.