 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Generative Models for Downlink Channel Estimation in FDD Massive MIMO Systems
Mar 09, 2022
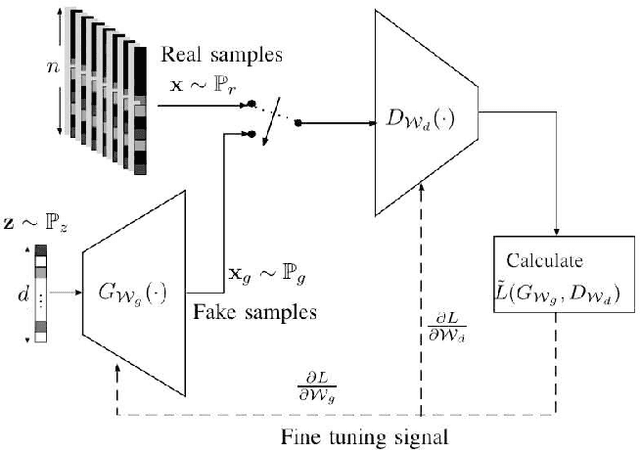
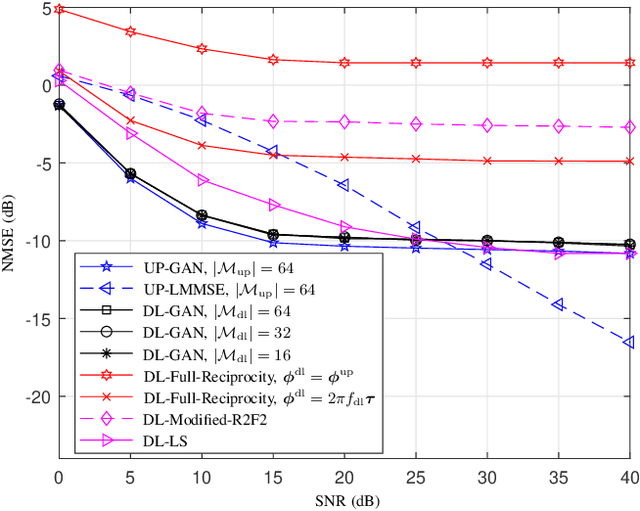
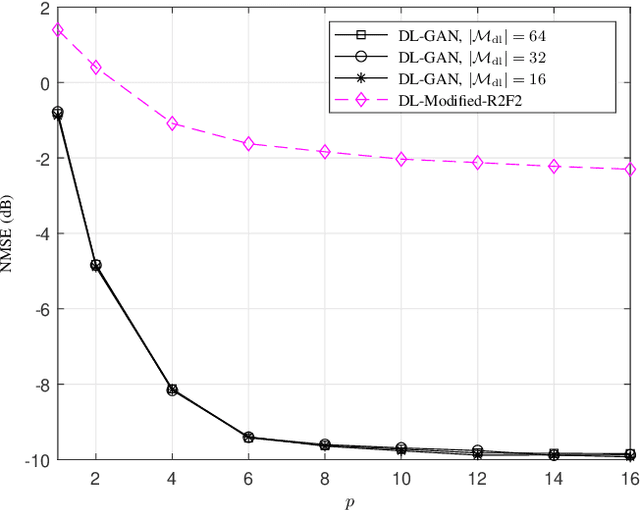
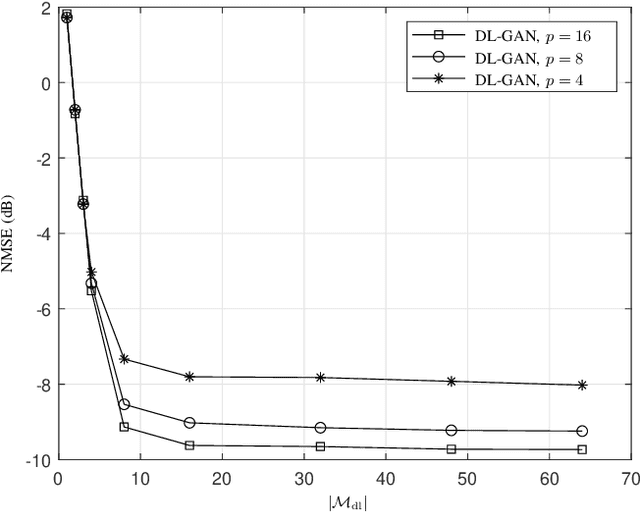
It is well accepted that acquiring downlink channel state information in frequency division duplexing (FDD) massive multiple-input multiple-output (MIMO) systems is challenging because of the large overhead in training and feedback. In this paper, we propose a deep generative model (DGM)-based technique to address this challenge. Exploiting the partial reciprocity of uplink and downlink channels, we first estimate the frequency-independent underlying channel parameters, i.e., the magnitudes of path gains, delays, angles-of-arrivals (AoAs) and angles-of-departures (AoDs), via uplink training, since these parameters are common in both uplink and downlink. Then, the frequency-specific underlying channel parameters, namely, the phase of each propagation path, are estimated via downlink training using a very short training signal. In the first step, we incorporate the underlying distribution of the channel parameters as a prior into our channel estimation algorithm. We use DGMs to learn this distribution. Simulation results indicate that our proposed DGM-based channel estimation technique outperforms, by a large gap, the conventional channel estimation techniques in practical ranges of signal-to-noise ratio (SNR). In addition, a near-optimal performance is achieved using only few downlink pilot measurements.
Recovering Geometric Information with Learned Texture Perturbations
Jan 20, 2020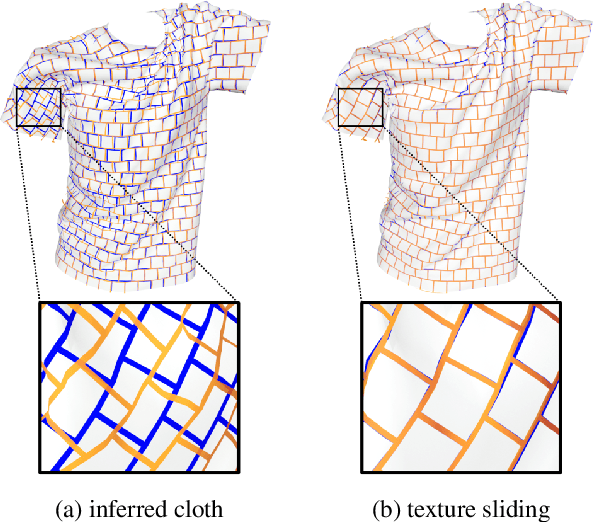
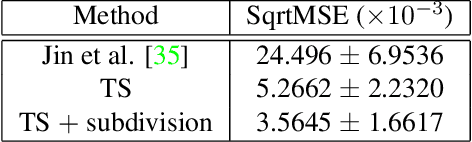
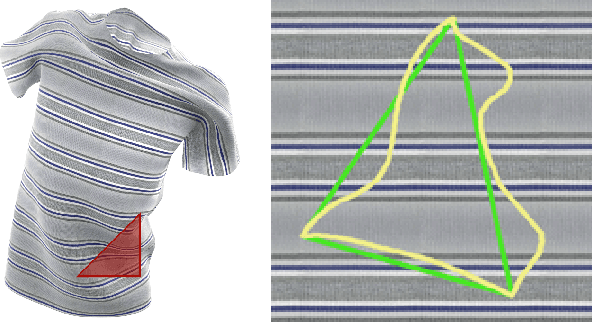

Regularization is used to avoid overfitting when training a neural network; unfortunately, this reduces the attainable level of detail hindering the ability to capture high-frequency information present in the training data. Even though various approaches may be used to re-introduce high-frequency detail, it typically does not match the training data and is often not time coherent. In the case of network inferred cloth, these sentiments manifest themselves via either a lack of detailed wrinkles or unnaturally appearing and/or time incoherent surrogate wrinkles. Thus, we propose a general strategy whereby high-frequency information is procedurally embedded into low-frequency data so that when the latter is smeared out by the network the former still retains its high-frequency detail. We illustrate this approach by learning texture coordinates which when smeared do not in turn smear out the high-frequency detail in the texture itself but merely smoothly distort it. Notably, we prescribe perturbed texture coordinates that are subsequently used to correct the over-smoothed appearance of inferred cloth, and correcting the appearance from multiple camera views naturally recovers lost geometric information.
Deep Graph Clustering via Dual Correlation Reduction
Dec 29, 2021



Deep graph clustering, which aims to reveal the underlying graph structure and divide the nodes into different groups, has attracted intensive attention in recent years. However, we observe that, in the process of node encoding, existing methods suffer from representation collapse which tends to map all data into the same representation. Consequently, the discriminative capability of the node representation is limited, leading to unsatisfied clustering performance. To address this issue, we propose a novel self-supervised deep graph clustering method termed Dual Correlation Reduction Network (DCRN) by reducing information correlation in a dual manner. Specifically, in our method, we first design a siamese network to encode samples. Then by forcing the cross-view sample correlation matrix and cross-view feature correlation matrix to approximate two identity matrices, respectively, we reduce the information correlation in the dual-level, thus improving the discriminative capability of the resulting features. Moreover, in order to alleviate representation collapse caused by over-smoothing in GCN, we introduce a propagation regularization term to enable the network to gain long-distance information with the shallow network structure. Extensive experimental results on six benchmark datasets demonstrate the effectiveness of the proposed DCRN against the existing state-of-the-art methods.
Metastatic Cancer Outcome Prediction with Injective Multiple Instance Pooling
Mar 09, 2022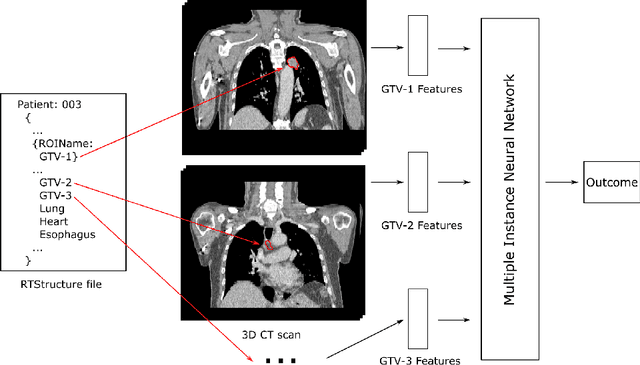
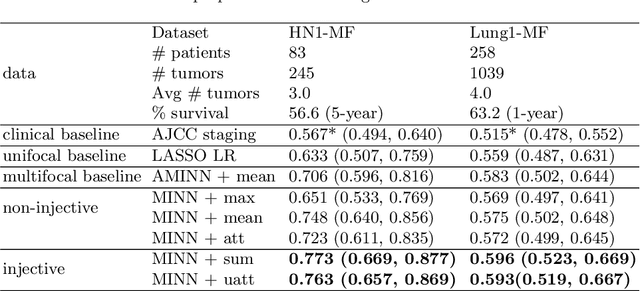
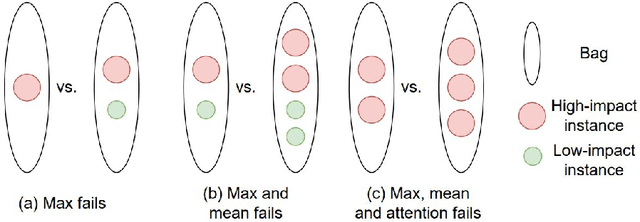
Cancer stage is a large determinant of patient prognosis and management in many cancer types, and is often assessed using medical imaging modalities, such as CT and MRI. These medical images contain rich information that can be explored to stratify patients within each stage group to further improve prognostic algorithms. Although the majority of cancer deaths result from metastatic and multifocal disease, building imaging biomarkers for patients with multiple tumors has been a challenging task due to the lack of annotated datasets and standard study framework. In this paper, we process two public datasets to set up a benchmark cohort of 341 patient in total for studying outcome prediction of multifocal metastatic cancer. We identify the lack of expressiveness in common multiple instance classification networks and propose two injective multiple instance pooling functions that are better suited to outcome prediction. Our results show that multiple instance learning with injective pooling functions can achieve state-of-the-art performance in the non-small-cell lung cancer CT and head and neck CT outcome prediction benchmarking tasks. We will release the processed multifocal datasets, our code and the intermediate files i.e. extracted radiomic features to support further transparent and reproducible research.
CPPF: Towards Robust Category-Level 9D Pose Estimation in the Wild
Mar 27, 2022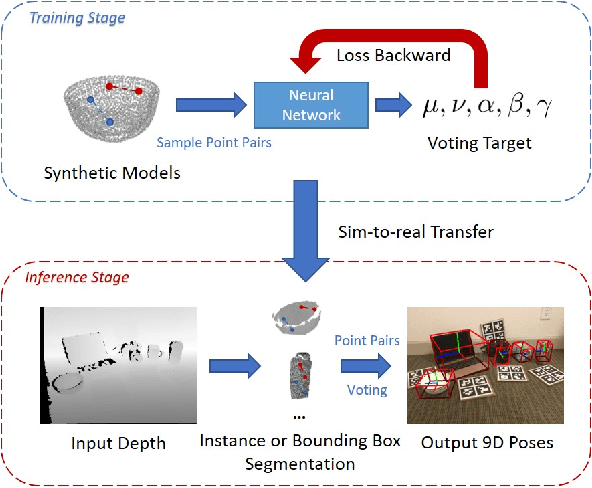
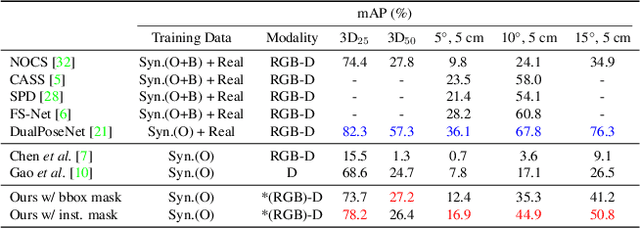
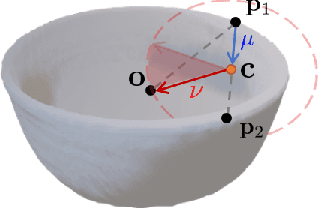
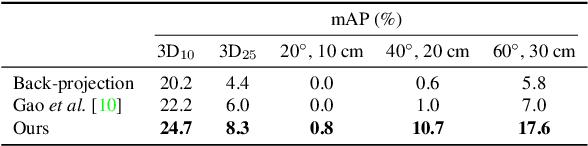
In this paper, we tackle the problem of category-level 9D pose estimation in the wild, given a single RGB-D frame. Using supervised data of real-world 9D poses is tedious and erroneous, and also fails to generalize to unseen scenarios. Besides, category-level pose estimation requires a method to be able to generalize to unseen objects at test time, which is also challenging. Drawing inspirations from traditional point pair features (PPFs), in this paper, we design a novel Category-level PPF (CPPF) voting method to achieve accurate, robust and generalizable 9D pose estimation in the wild. To obtain robust pose estimation, we sample numerous point pairs on an object, and for each pair our model predicts necessary SE(3)-invariant voting statistics on object centers, orientations and scales. A novel coarse-to-fine voting algorithm is proposed to eliminate noisy point pair samples and generate final predictions from the population. To get rid of false positives in the orientation voting process, an auxiliary binary disambiguating classification task is introduced for each sampled point pair. In order to detect objects in the wild, we carefully design our sim-to-real pipeline by training on synthetic point clouds only, unless objects have ambiguous poses in geometry. Under this circumstance, color information is leveraged to disambiguate these poses. Results on standard benchmarks show that our method is on par with current state of the arts with real-world training data. Extensive experiments further show that our method is robust to noise and gives promising results under extremely challenging scenarios. Our code is available on https://github.com/qq456cvb/CPPF.
Decontextualized I3D ConvNet for ultra-distance runners performance analysis at a glance
Mar 13, 2022
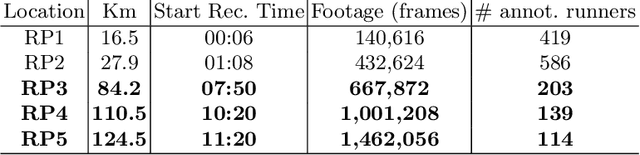
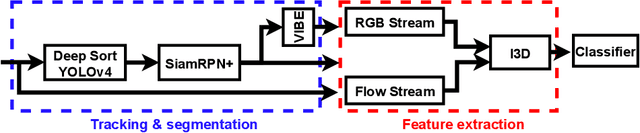

In May 2021, the site runnersworld.com published that participation in ultra-distance races has increased by 1,676% in the last 23 years. Moreover, nearly 41% of those runners participate in more than one race per year. The development of wearable devices has undoubtedly contributed to motivating participants by providing performance measures in real-time. However, we believe there is room for improvement, particularly from the organizers point of view. This work aims to determine how the runners performance can be quantified and predicted by considering a non-invasive technique focusing on the ultra-running scenario. In this sense, participants are captured when they pass through a set of locations placed along the race track. Each footage is considered an input to an I3D ConvNet to extract the participant's running gait in our work. Furthermore, weather and illumination capture conditions or occlusions may affect these footages due to the race staff and other runners. To address this challenging task, we have tracked and codified the participant's running gait at some RPs and removed the context intending to ensure a runner-of-interest proper evaluation. The evaluation suggests that the features extracted by an I3D ConvNet provide enough information to estimate the participant's performance along the different race tracks.
Mitigating cold start problems in drug-target affinity prediction with interaction knowledge transferring
Jan 16, 2022
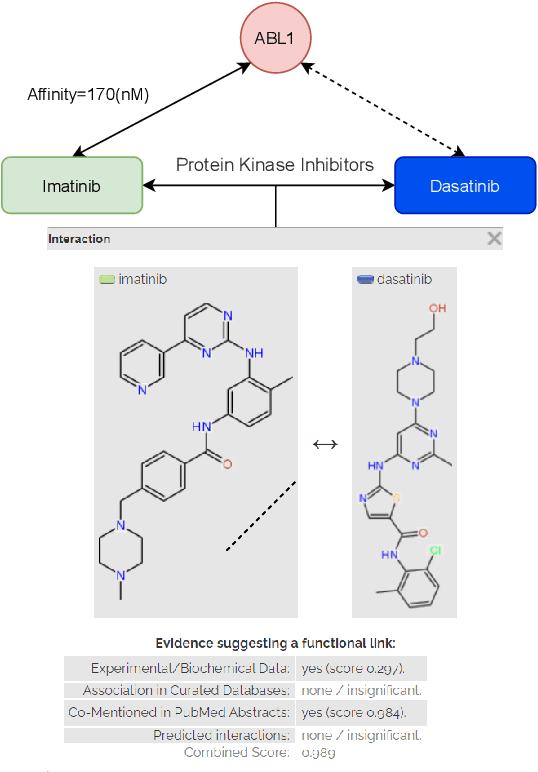
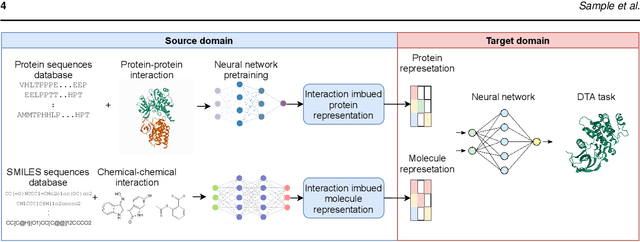
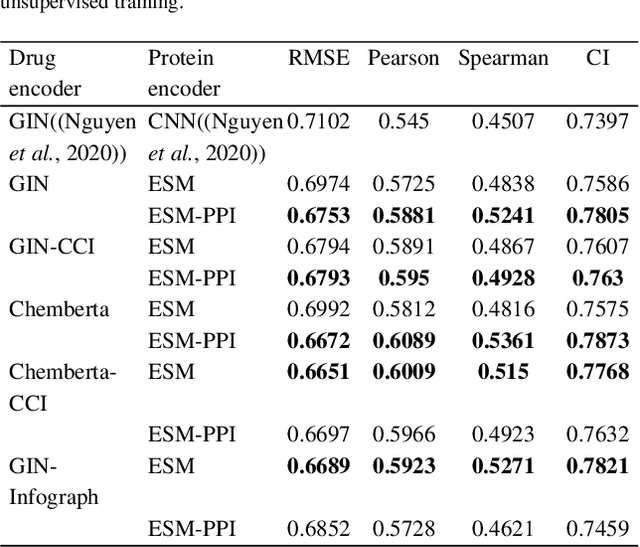
Motivation: Predicting the drug-target interaction is crucial for drug discovery as well as drug repurposing. Machine learning is commonly used in drug-target affinity (DTA) problem. However, machine learning model faces the cold-start problem where the model performance drops when predicting the interaction of a novel drug or target. Previous works try to solve the cold start problem by learning the drug or target representation using unsupervised learning. While the drug or target representation can be learned in an unsupervised manner, it still lacks the interaction information, which is critical in drug-target interaction. Results: To incorporate the interaction information into the drug and protein interaction, we proposed using transfer learning from chemical-chemical interaction (CCI) and protein-protein interaction (PPI) task to drug-target interaction task. The representation learned by CCI and PPI tasks can be transferred smoothly to the DTA task due to the similar nature of the tasks. The result on the drug-target affinity datasets shows that our proposed method has advantages compared to other pretraining methods in the DTA task.
Neural Hierarchical Factorization Machines for User's Event Sequence Analysis
Dec 31, 2021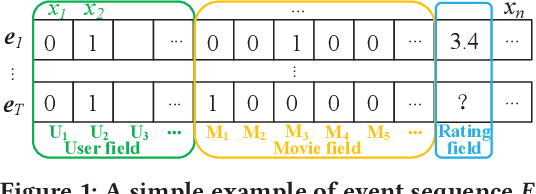
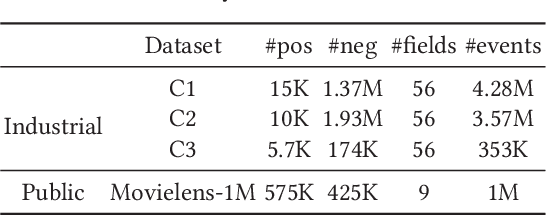
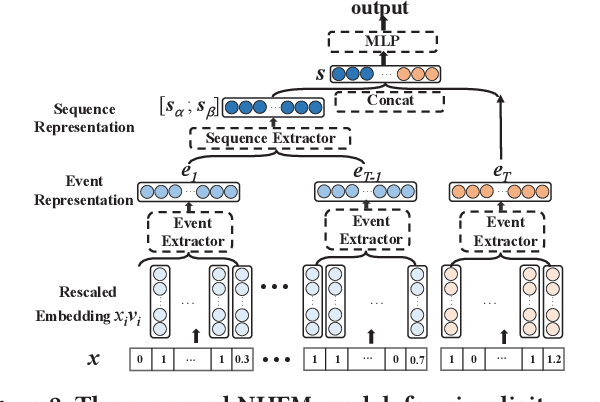
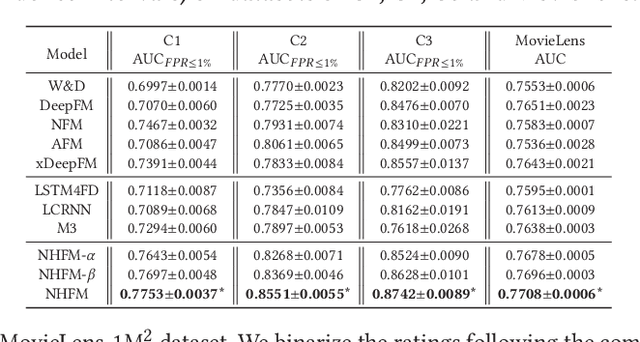
Many prediction tasks of real-world applications need to model multi-order feature interactions in user's event sequence for better detection performance. However, existing popular solutions usually suffer two key issues: 1) only focusing on feature interactions and failing to capture the sequence influence; 2) only focusing on sequence information, but ignoring internal feature relations of each event, thus failing to extract a better event representation. In this paper, we consider a two-level structure for capturing the hierarchical information over user's event sequence: 1) learning effective feature interactions based event representation; 2) modeling the sequence representation of user's historical events. Experimental results on both industrial and public datasets clearly demonstrate that our model achieves significantly better performance compared with state-of-the-art baselines.
Efficient Long-Range Attention Network for Image Super-resolution
Mar 13, 2022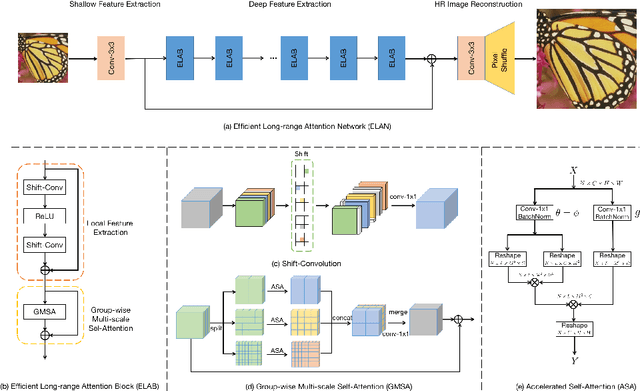
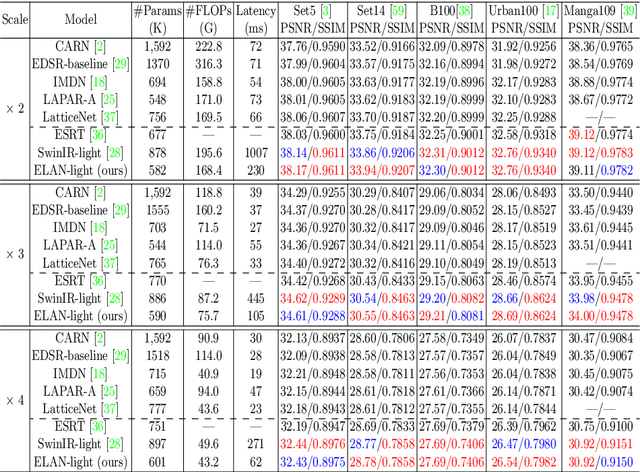
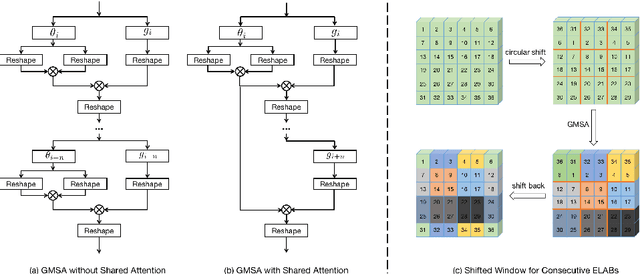
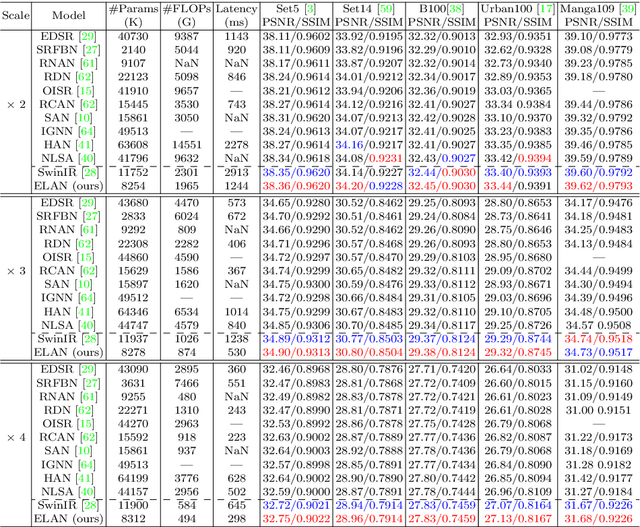
Recently, transformer-based methods have demonstrated impressive results in various vision tasks, including image super-resolution (SR), by exploiting the self-attention (SA) for feature extraction. However, the computation of SA in most existing transformer based models is very expensive, while some employed operations may be redundant for the SR task. This limits the range of SA computation and consequently the SR performance. In this work, we propose an efficient long-range attention network (ELAN) for image SR. Specifically, we first employ shift convolution (shift-conv) to effectively extract the image local structural information while maintaining the same level of complexity as 1x1 convolution, then propose a group-wise multi-scale self-attention (GMSA) module, which calculates SA on non-overlapped groups of features using different window sizes to exploit the long-range image dependency. A highly efficient long-range attention block (ELAB) is then built by simply cascading two shift-conv with a GMSA module, which is further accelerated by using a shared attention mechanism. Without bells and whistles, our ELAN follows a fairly simple design by sequentially cascading the ELABs. Extensive experiments demonstrate that ELAN obtains even better results against the transformer-based SR models but with significantly less complexity. The source code can be found at https://github.com/xindongzhang/ELAN.
Zero-Shot Sketch Based Image Retrieval using Graph Transformer
Jan 25, 2022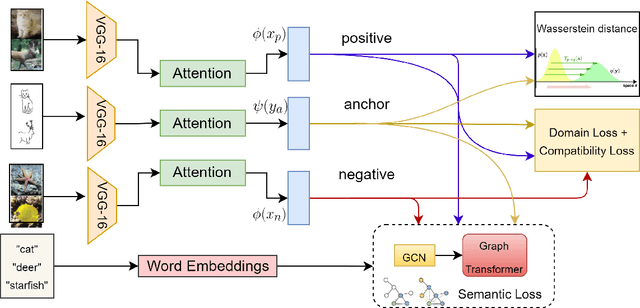
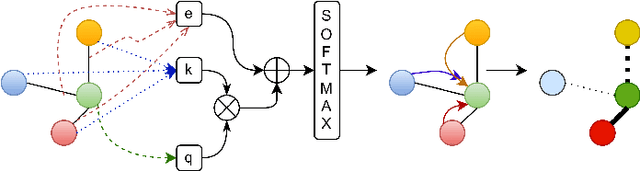

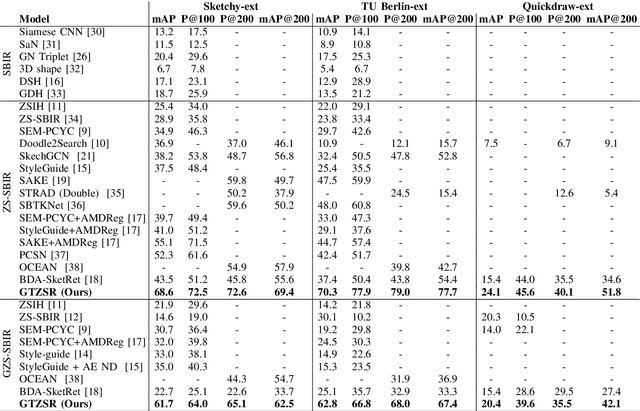
The performance of a zero-shot sketch-based image retrieval (ZS-SBIR) task is primarily affected by two challenges. The substantial domain gap between image and sketch features needs to be bridged, while at the same time the side information has to be chosen tactfully. Existing literature has shown that varying the semantic side information greatly affects the performance of ZS-SBIR. To this end, we propose a novel graph transformer based zero-shot sketch-based image retrieval (GTZSR) framework for solving ZS-SBIR tasks which uses a novel graph transformer to preserve the topology of the classes in the semantic space and propagates the context-graph of the classes within the embedding features of the visual space. To bridge the domain gap between the visual features, we propose minimizing the Wasserstein distance between images and sketches in a learned domain-shared space. We also propose a novel compatibility loss that further aligns the two visual domains by bridging the domain gap of one class with respect to the domain gap of all other classes in the training set. Experimental results obtained on the extended Sketchy, TU-Berlin, and QuickDraw datasets exhibit sharp improvements over the existing state-of-the-art methods in both ZS-SBIR and generalized ZS-SBIR.