 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust and Online LiDAR-inertial Initialization
Mar 01, 2022

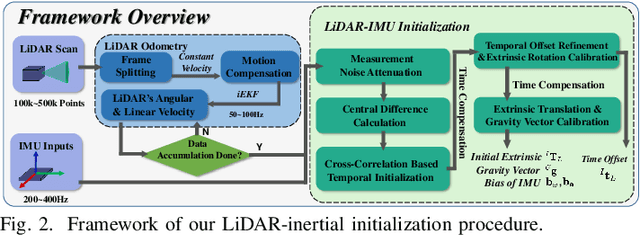

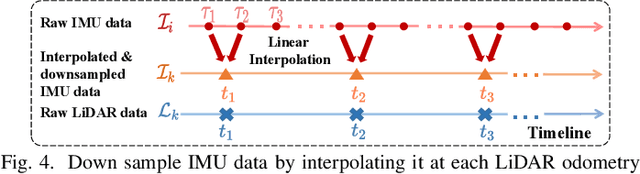
For most LiDAR-inertial odometry, accurate initial state, including temporal offset and extrinsic transformation between LiDAR and 6-axis IMUs, play a significant role and are often considered as prerequisites. However, such information may not be always available in customized LiDAR-inertial systems. In this paper, we propose a full and online LiDAR-inertial system initialization process that calibrates the temporal offset and extrinsic parameter between LiDARs and IMUs, and also the gravity vector and IMU bias by aligning the state estimated from LiDAR measurements with that measured by IMU. We implement the proposed method as an initialization module, which, if enabled, automatically detects the degree of excitation of the collected data and calibrate, on-the-fly, the temporal offset, extrinsic, gravity vector, and IMU bias, which are then used as high-quality initial state values for online LiDAR-inertial odometry systems. Experiments conducted with different types of LiDARs and LiDAR-inertial combinations show the robustness, adaptability and efficiency of our initialization method. The implementation of our LiDAR-inertial initialization procedure and test data are open-sourced on Github and also integrated into a state-of-the-art LiDAR-inertial odometry system FAST-LIO2.
Practical Mission Planning for Optimized UAV-Sensor Wireless Recharging
Mar 09, 2022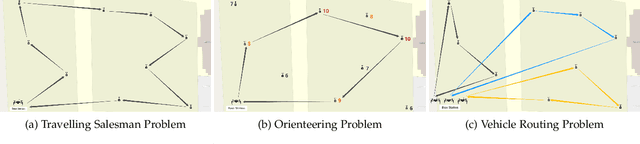
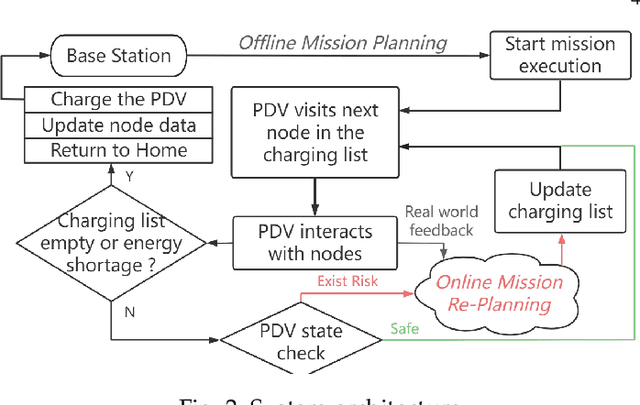
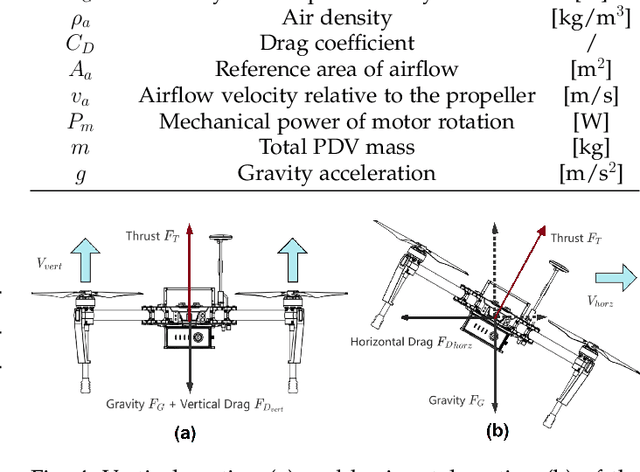
Recharging Internet of Things devices using autonomous robots is an attractive maintenance solution. Ensuring efficient and reliable performance of autonomous power delivery vehicles is very challenging in dynamic environments. Our work considers a hybrid Travelling Salesman Problem and Orienteering Problem scenario where the optimization objective is to jointly minimize discharged energy of the power delivery vehicle and maximize recharged energy of devices. This is decomposed as an NP-hard nonconvex optimization and nonlinear integer programming problem. Many studies have demonstrated satisfactory performance of heuristic algorithms' ability to solve specific routing problems, however very few studies explore online updating (i.e., mission re-planning `on the fly') for such hybrid scenarios. In this paper, we present a novel lightweight and reliable mission planner that solves the problem by combining offline search and online reevaluation. We propose Rapid Online Metaheuristic-based Planner, ROMP, a multi-objective offline and online mission planner that can incorporate real-time state information from the power delivery vehicle and its local environment to deliver reliable, up-to-date and near-optimal mission planning. We supplement Guided Local Search (via Google OR-Tools) with a Black Hole-inspired algorithm. Our results show that the proposed solver improves the solution quality offered by Guided Local Search in most of the cases tested. We also demonstrate latency performance improvements by applying a parallelization strategy.
Retriever: Learning Content-Style Representation as a Token-Level Bipartite Graph
Feb 24, 2022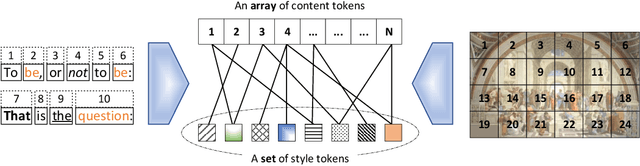
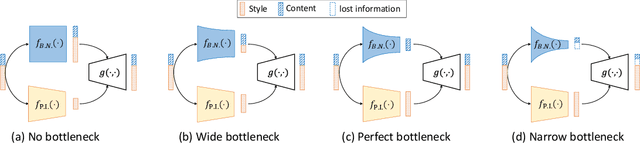

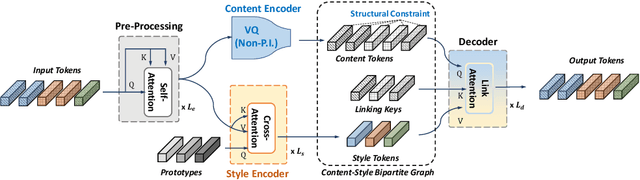
This paper addresses the unsupervised learning of content-style decomposed representation. We first give a definition of style and then model the content-style representation as a token-level bipartite graph. An unsupervised framework, named Retriever, is proposed to learn such representations. First, a cross-attention module is employed to retrieve permutation invariant (P.I.) information, defined as style, from the input data. Second, a vector quantization (VQ) module is used, together with man-induced constraints, to produce interpretable content tokens. Last, an innovative link attention module serves as the decoder to reconstruct data from the decomposed content and style, with the help of the linking keys. Being modal-agnostic, the proposed Retriever is evaluated in both speech and image domains. The state-of-the-art zero-shot voice conversion performance confirms the disentangling ability of our framework. Top performance is also achieved in the part discovery task for images, verifying the interpretability of our representation. In addition, the vivid part-based style transfer quality demonstrates the potential of Retriever to support various fascinating generative tasks. Project page at https://ydcustc.github.io/retriever-demo/.
LIAF-Net: Leaky Integrate and Analog Fire Network for Lightweight and Efficient Spatiotemporal Information Processing
Nov 12, 2020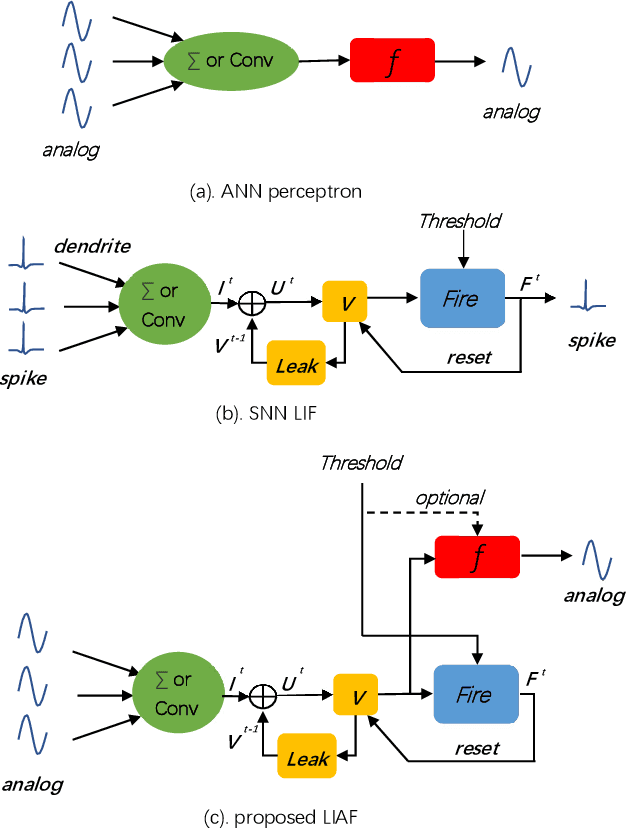
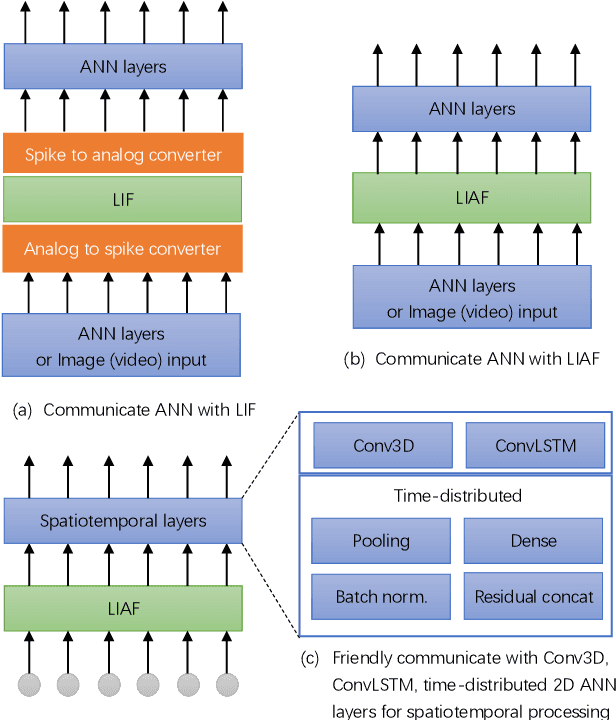
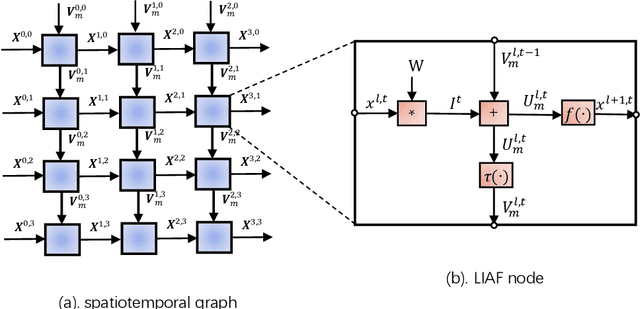
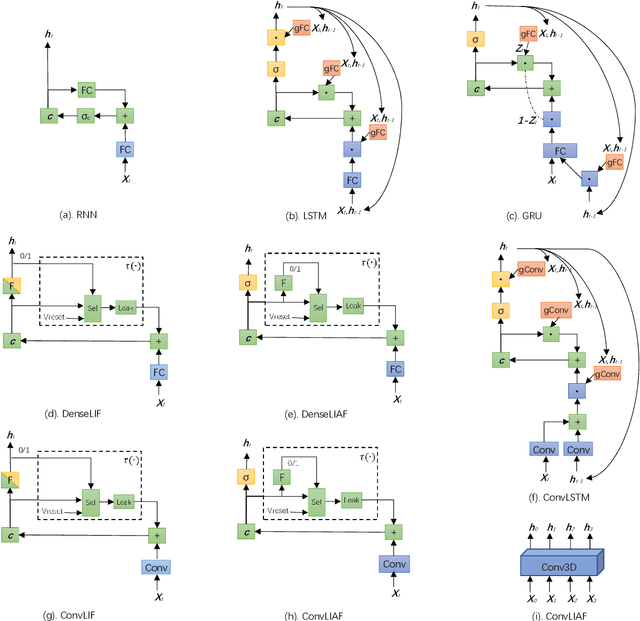
Spiking neural networks (SNNs) based on Leaky Integrate and Fire (LIF) model have been applied to energy-efficient temporal and spatiotemporal processing tasks. Thanks to the bio-plausible neuronal dynamics and simplicity, LIF-SNN benefits from event-driven processing, however, usually faces the embarrassment of reduced performance. This may because in LIF-SNN the neurons transmit information via spikes. To address this issue, in this work, we propose a Leaky Integrate and Analog Fire (LIAF) neuron model, so that analog values can be transmitted among neurons, and a deep network termed as LIAF-Net is built on it for efficient spatiotemporal processing. In the temporal domain, LIAF follows the traditional LIF dynamics to maintain its temporal processing capability. In the spatial domain, LIAF is able to integrate spatial information through convolutional integration or fully-connected integration. As a spatiotemporal layer, LIAF can also be used with traditional artificial neural network (ANN) layers jointly. Experiment results indicate that LIAF-Net achieves comparable performance to Gated Recurrent Unit (GRU) and Long short-term memory (LSTM) on bAbI Question Answering (QA) tasks, and achieves state-of-the-art performance on spatiotemporal Dynamic Vision Sensor (DVS) datasets, including MNIST-DVS, CIFAR10-DVS and DVS128 Gesture, with much less number of synaptic weights and computational overhead compared with traditional networks built by LSTM, GRU, Convolutional LSTM (ConvLSTM) or 3D convolution (Conv3D). Compared with traditional LIF-SNN, LIAF-Net also shows dramatic accuracy gain on all these experiments. In conclusion, LIAF-Net provides a framework combining the advantages of both ANNs and SNNs for lightweight and efficient spatiotemporal information processing.
ClueGraphSum: Let Key Clues Guide the Cross-Lingual Abstractive Summarization
Mar 09, 2022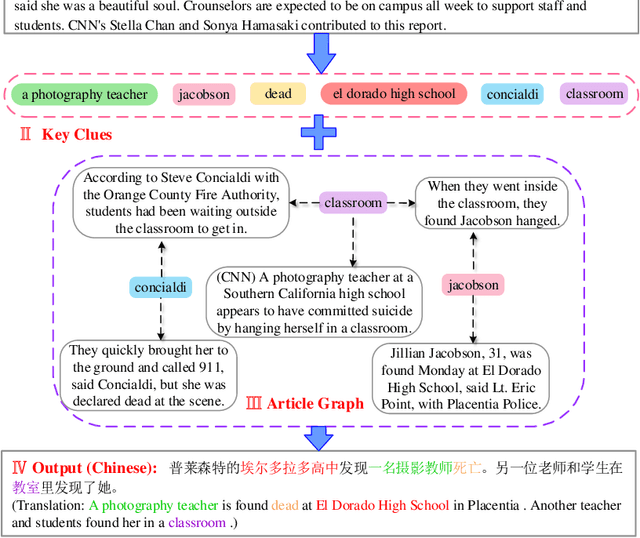
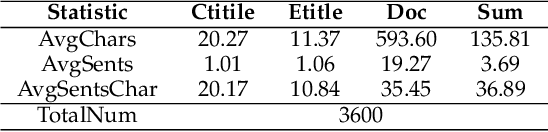
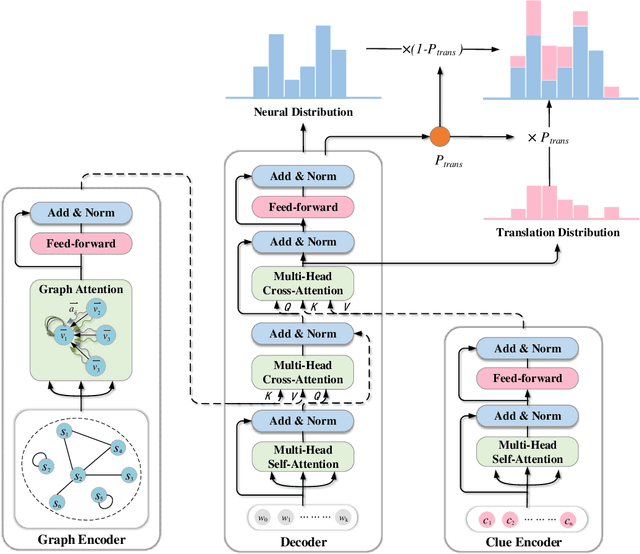
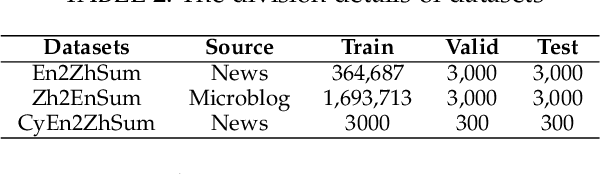
Cross-Lingual Summarization (CLS) is the task to generate a summary in one language for an article in a different language. Previous studies on CLS mainly take pipeline methods or train the end-to-end model using the translated parallel data. However, the quality of generated cross-lingual summaries needs more further efforts to improve, and the model performance has never been evaluated on the hand-written CLS dataset. Therefore, we first propose a clue-guided cross-lingual abstractive summarization method to improve the quality of cross-lingual summaries, and then construct a novel hand-written CLS dataset for evaluation. Specifically, we extract keywords, named entities, etc. of the input article as key clues for summarization and then design a clue-guided algorithm to transform an article into a graph with less noisy sentences. One Graph encoder is built to learn sentence semantics and article structures and one Clue encoder is built to encode and translate key clues, ensuring the information of important parts are reserved in the generated summary. These two encoders are connected by one decoder to directly learn cross-lingual semantics. Experimental results show that our method has stronger robustness for longer inputs and substantially improves the performance over the strong baseline, achieving an improvement of 8.55 ROUGE-1 (English-to-Chinese summarization) and 2.13 MoverScore (Chinese-to-English summarization) scores over the existing SOTA.
Competing in a Complex Hidden Role Game with Information Set Monte Carlo Tree Search
May 14, 2020

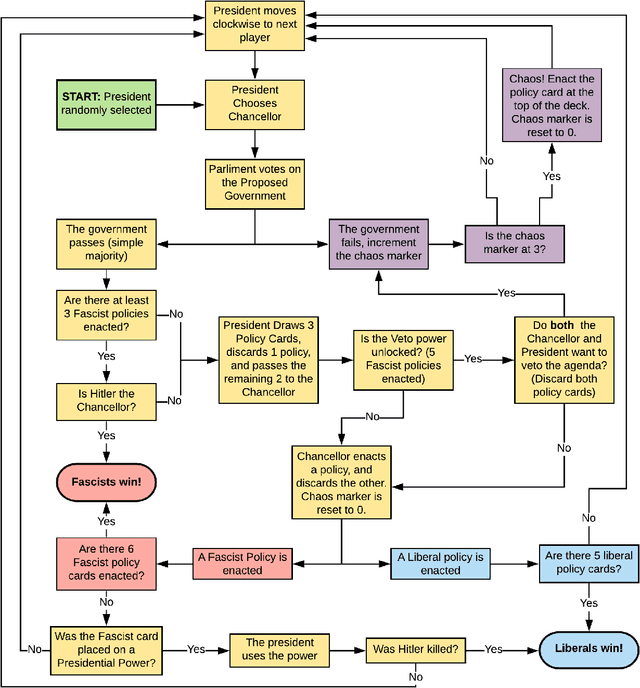

Advances in intelligent game playing agents have led to successes in perfect information games like Go and imperfect information games like Poker. The Information Set Monte Carlo Tree Search (ISMCTS) family of algorithms outperforms previous algorithms using Monte Carlo methods in imperfect information games. In this paper, Single Observer Information Set Monte Carlo Tree Search (SO-ISMCTS) is applied to Secret Hitler, a popular social deduction board game that combines traditional hidden role mechanics with the randomness of a card deck. This combination leads to a more complex information model than the hidden role and card deck mechanics alone. It is shown in 10108 simulated games that SO-ISMCTS plays as well as simpler rule based agents, and demonstrates the potential of ISMCTS algorithms in complicated information set domains.
Video Summarization Based on Video-text Representation
Jan 07, 2022
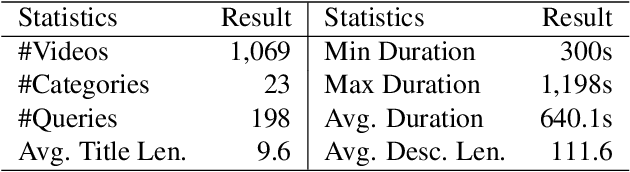
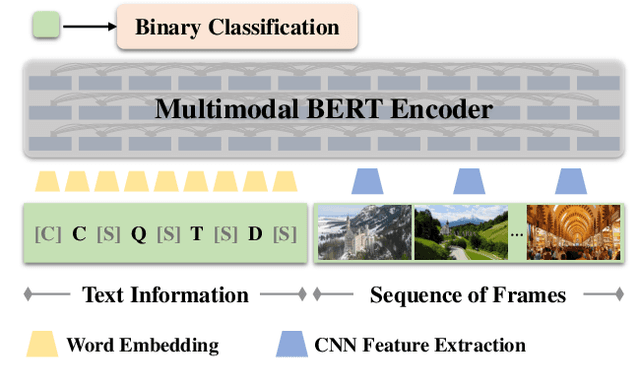
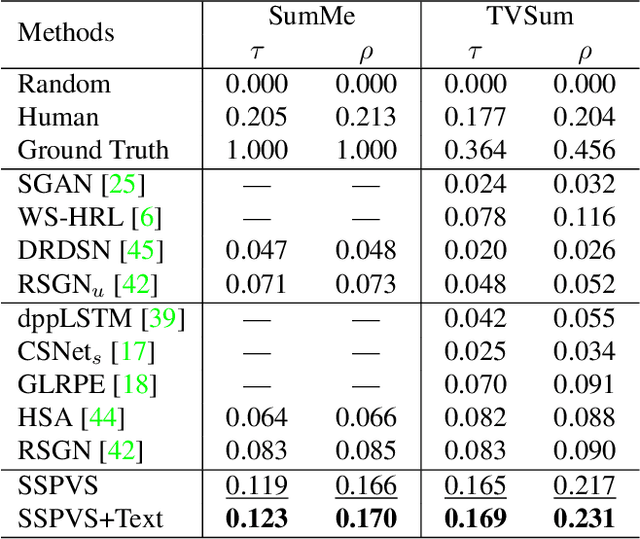
Modern video summarization methods are based on deep neural networks which require a large amount of annotated data for training. However, existing datasets for video summarization are small-scale, easily leading to over-fitting of the deep models. Considering that the annotation of large-scale datasets is time-consuming, we propose a multimodal self-supervised learning framework to obtain semantic representations of videos, which benefits the video summarization task. Specifically, we explore the semantic consistency between the visual information and text information of videos, for the self-supervised pretraining of a multimodal encoder on a newly-collected dataset of video-text pairs. Additionally, we introduce a progressive video summarization method, where the important content in a video is pinpointed progressively to generate better summaries. Finally, an objective evaluation framework is proposed to measure the quality of video summaries based on video classification. Extensive experiments have proved the effectiveness and superiority of our method in rank correlation coefficients, F-score, and the proposed objective evaluation compared to the state of the art.
Large-scale Stochastic Optimization of NDCG Surrogates for Deep Learning with Provable Convergence
Feb 24, 2022

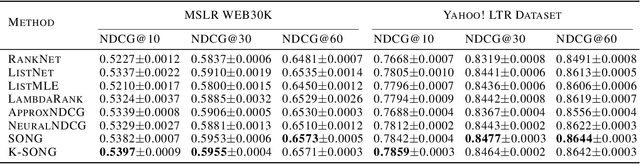

NDCG, namely Normalized Discounted Cumulative Gain, is a widely used ranking metric in information retrieval and machine learning. However, efficient and provable stochastic methods for maximizing NDCG are still lacking, especially for deep models. In this paper, we propose a principled approach to optimize NDCG and its top-$K$ variant. First, we formulate a novel compositional optimization problem for optimizing the NDCG surrogate, and a novel bilevel compositional optimization problem for optimizing the top-$K$ NDCG surrogate. Then, we develop efficient stochastic algorithms with provable convergence guarantees for the non-convex objectives. Different from existing NDCG optimization methods, the per-iteration complexity of our algorithms scales with the mini-batch size instead of the number of total items. To improve the effectiveness for deep learning, we further propose practical strategies by using initial warm-up and stop gradient operator. Experimental results on multiple datasets demonstrate that our methods outperform prior ranking approaches in terms of NDCG. To the best of our knowledge, this is the first time that stochastic algorithms are proposed to optimize NDCG with a provable convergence guarantee.
Reinforcement Learning Based Query Vertex Ordering Model for Subgraph Matching
Jan 25, 2022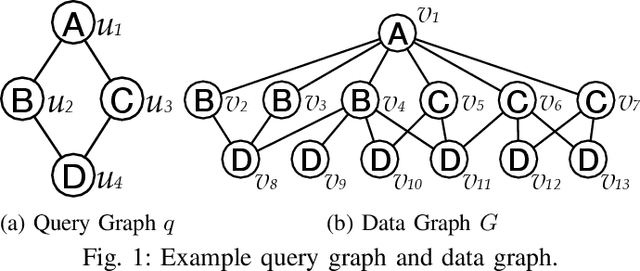
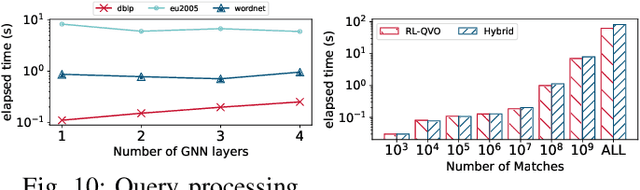
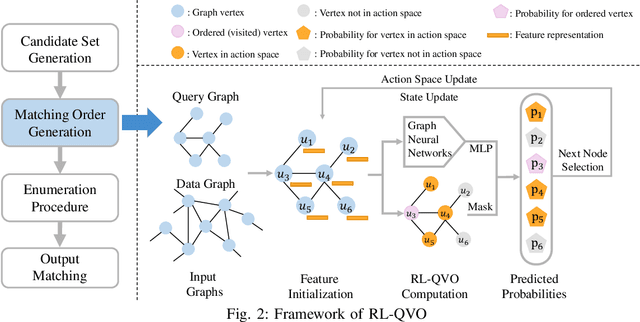
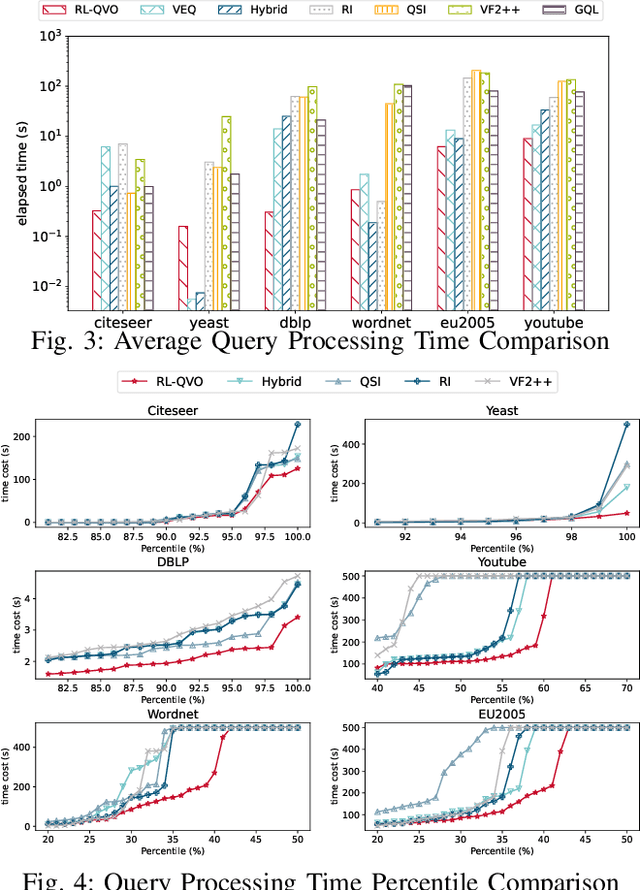
Subgraph matching is a fundamental problem in various fields that use graph structured data. Subgraph matching algorithms enumerate all isomorphic embeddings of a query graph q in a data graph G. An important branch of matching algorithms exploit the backtracking search approach which recursively extends intermediate results following a matching order of query vertices. It has been shown that the matching order plays a critical role in time efficiency of these backtracking based subgraph matching algorithms. In recent years, many advanced techniques for query vertex ordering (i.e., matching order generation) have been proposed to reduce the unpromising intermediate results according to the preset heuristic rules. In this paper, for the first time we apply the Reinforcement Learning (RL) and Graph Neural Networks (GNNs) techniques to generate the high-quality matching order for subgraph matching algorithms. Instead of using the fixed heuristics to generate the matching order, our model could capture and make full use of the graph information, and thus determine the query vertex order with the adaptive learning-based rule that could significantly reduces the number of redundant enumerations. With the help of the reinforcement learning framework, our model is able to consider the long-term benefits rather than only consider the local information at current ordering step.Extensive experiments on six real-life data graphs demonstrate that our proposed matching order generation technique could reduce up to two orders of magnitude of query processing time compared to the state-of-the-art algorithms.
EMGSE: Acoustic/EMG Fusion for Multimodal Speech Enhancement
Feb 14, 2022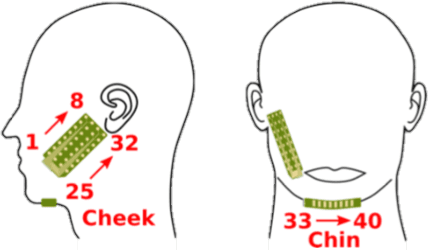
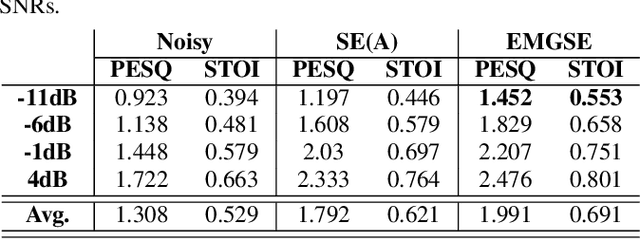
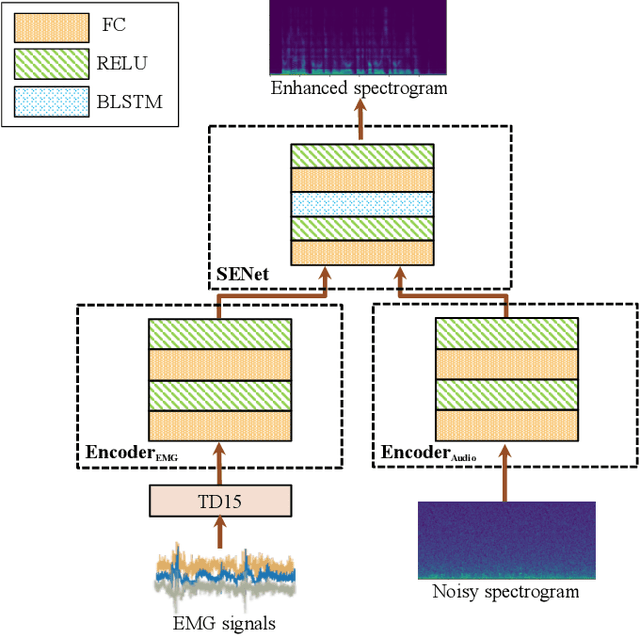
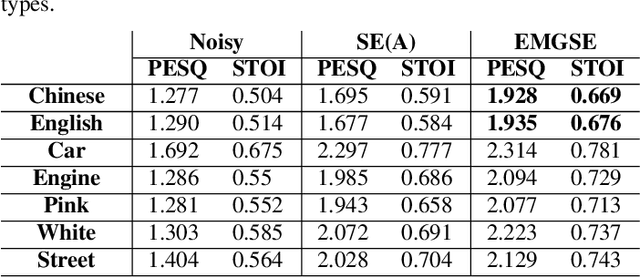
Multimodal learning has been proven to be an effective method to improve speech enhancement (SE) performance, especially in challenging situations such as low signal-to-noise ratios, speech noise, or unseen noise types. In previous studies, several types of auxiliary data have been used to construct multimodal SE systems, such as lip images, electropalatography, or electromagnetic midsagittal articulography. In this paper, we propose a novel EMGSE framework for multimodal SE, which integrates audio and facial electromyography (EMG) signals. Facial EMG is a biological signal containing articulatory movement information, which can be measured in a non-invasive way. Experimental results show that the proposed EMGSE system can achieve better performance than the audio-only SE system. The benefits of fusing EMG signals with acoustic signals for SE are notable under challenging circumstances. Furthermore, this study reveals that cheek EMG is sufficient for SE.