 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge-enriched Attention Network with Group-wise Semantic for Visual Storytelling
Mar 10, 2022
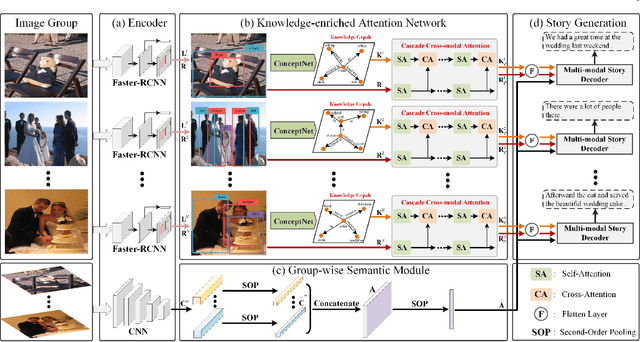
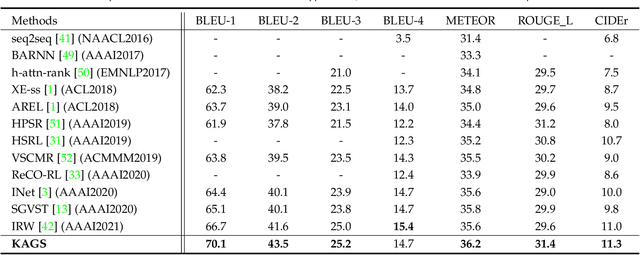
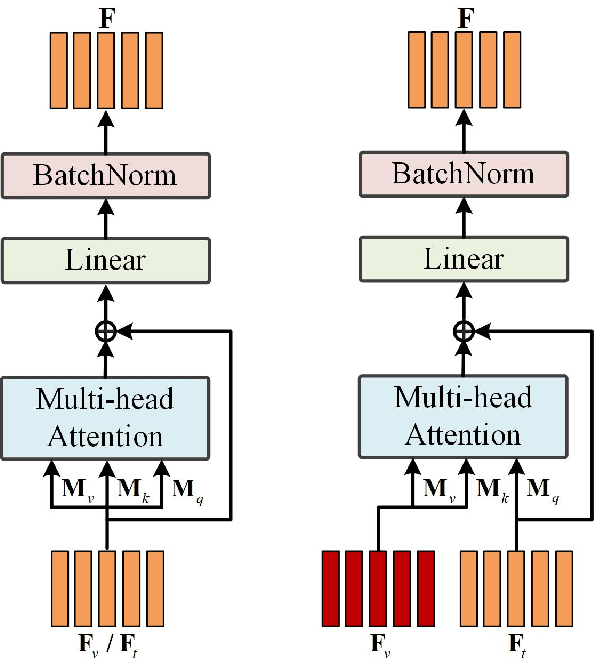
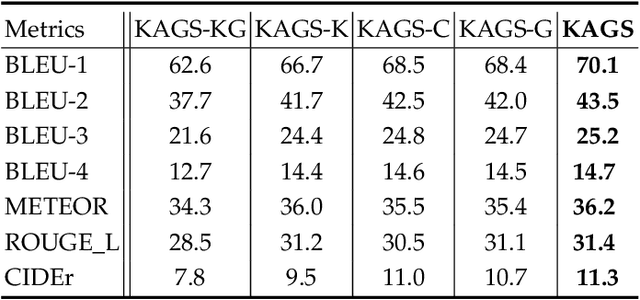
As a technically challenging topic, visual storytelling aims at generating an imaginary and coherent story with narrative multi-sentences from a group of relevant images. Existing methods often generate direct and rigid descriptions of apparent image-based contents, because they are not capable of exploring implicit information beyond images. Hence, these schemes could not capture consistent dependencies from holistic representation, impairing the generation of reasonable and fluent story. To address these problems, a novel knowledge-enriched attention network with group-wise semantic model is proposed. Three main novel components are designed and supported by substantial experiments to reveal practical advantages. First, a knowledge-enriched attention network is designed to extract implicit concepts from external knowledge system, and these concepts are followed by a cascade cross-modal attention mechanism to characterize imaginative and concrete representations. Second, a group-wise semantic module with second-order pooling is developed to explore the globally consistent guidance. Third, a unified one-stage story generation model with encoder-decoder structure is proposed to simultaneously train and infer the knowledge-enriched attention network, group-wise semantic module and multi-modal story generation decoder in an end-to-end fashion. Substantial experiments on the popular Visual Storytelling dataset with both objective and subjective evaluation metrics demonstrate the superior performance of the proposed scheme as compared with other state-of-the-art methods.
Temporal Aggregation for Adaptive RGBT Tracking
Jan 22, 2022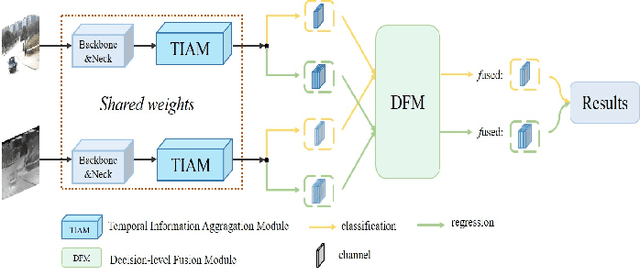
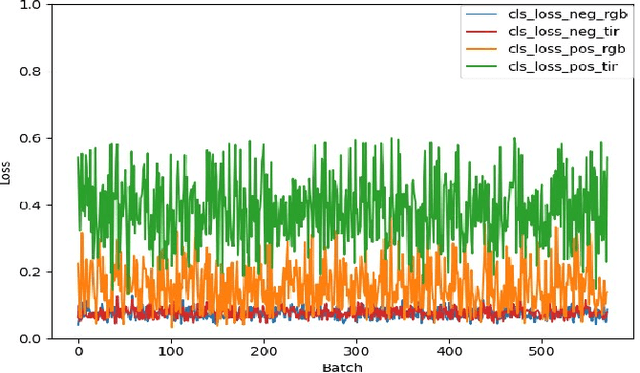
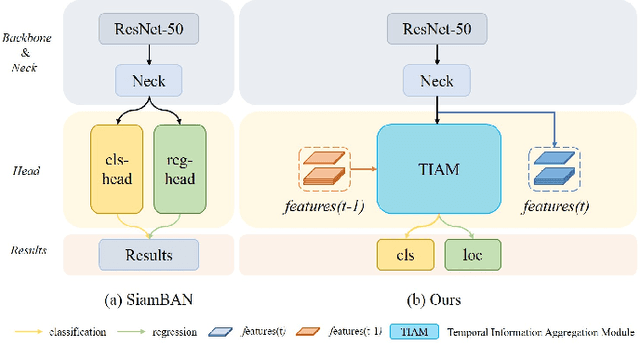
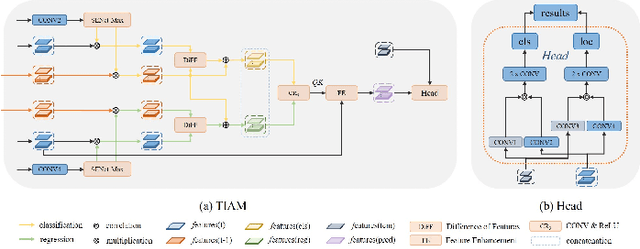
Visual object tracking with RGB and thermal infrared (TIR) spectra available, shorted in RGBT tracking, is a novel and challenging research topic which draws increasing attention nowadays. In this paper, we propose an RGBT tracker which takes spatio-temporal clues into account for robust appearance model learning, and simultaneously, constructs an adaptive fusion sub-network for cross-modal interactions. Unlike most existing RGBT trackers that implement object tracking tasks with only spatial information included, temporal information is further considered in this method. Specifically, different from traditional Siamese trackers, which only obtain one search image during the process of picking up template-search image pairs, an extra search sample adjacent to the original one is selected to predict the temporal transformation, resulting in improved robustness of tracking performance.As for multi-modal tracking, constrained to the limited RGBT datasets, the adaptive fusion sub-network is appended to our method at the decision level to reflect the complementary characteristics contained in two modalities. To design a thermal infrared assisted RGB tracker, the outputs of the classification head from the TIR modality are taken into consideration before the residual connection from the RGB modality. Extensive experimental results on three challenging datasets, i.e. VOT-RGBT2019, GTOT and RGBT210, verify the effectiveness of our method. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/TAAT}}.
Confidence Calibration for Object Detection and Segmentation
Mar 02, 2022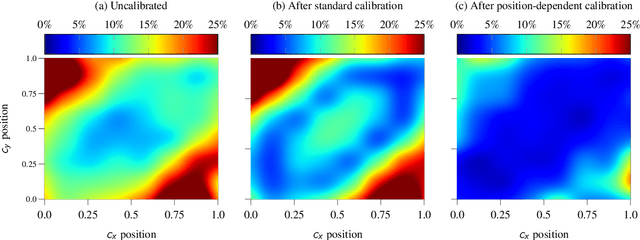
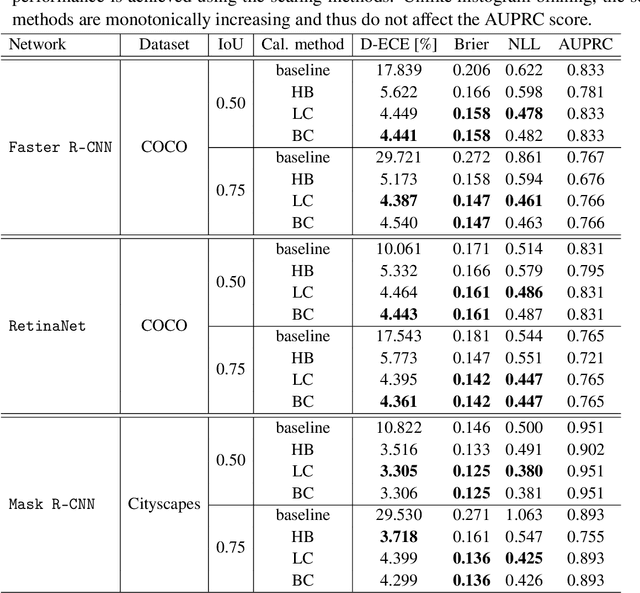
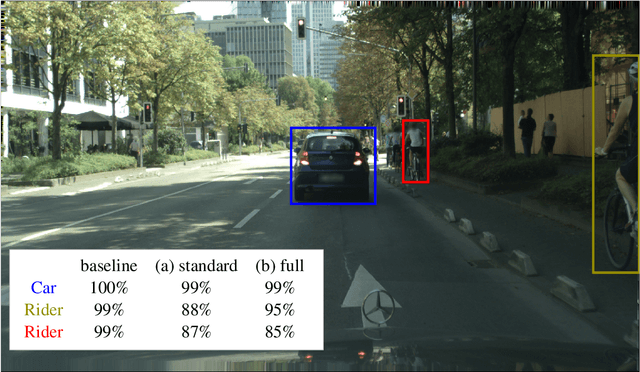
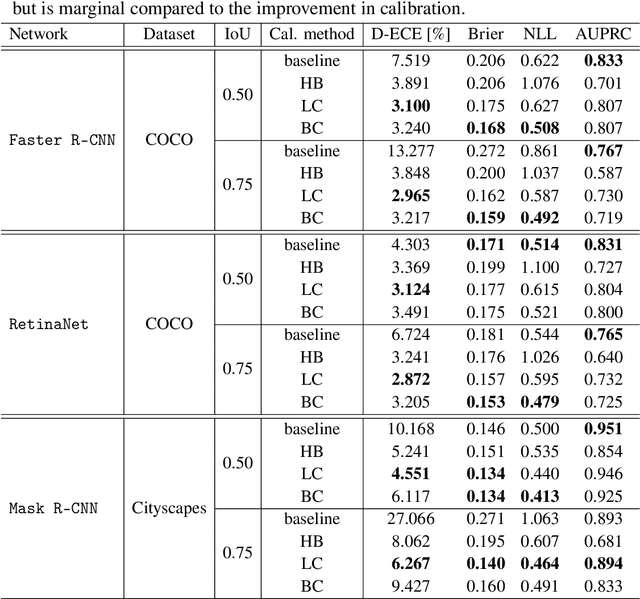
Calibrated confidence estimates obtained from neural networks are crucial, particularly for safety-critical applications such as autonomous driving or medical image diagnosis. However, although the task of confidence calibration has been investigated on classification problems, thorough investigations on object detection and segmentation problems are still missing. Therefore, we focus on the investigation of confidence calibration for object detection and segmentation models in this chapter. We introduce the concept of multivariate confidence calibration that is an extension of well-known calibration methods to the task of object detection and segmentation. This allows for an extended confidence calibration that is also aware of additional features such as bounding box/pixel position, shape information, etc. Furthermore, we extend the expected calibration error (ECE) to measure miscalibration of object detection and segmentation models. We examine several network architectures on MS COCO as well as on Cityscapes and show that especially object detection as well as instance segmentation models are intrinsically miscalibrated given the introduced definition of calibration. Using our proposed calibration methods, we have been able to improve calibration so that it also has a positive impact on the quality of segmentation masks as well.
XAI for Transformers: Better Explanations through Conservative Propagation
Feb 15, 2022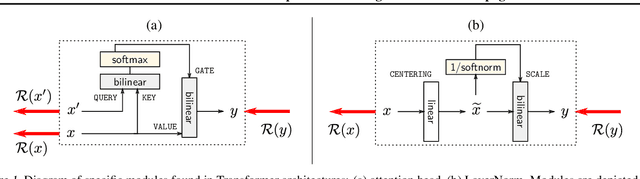
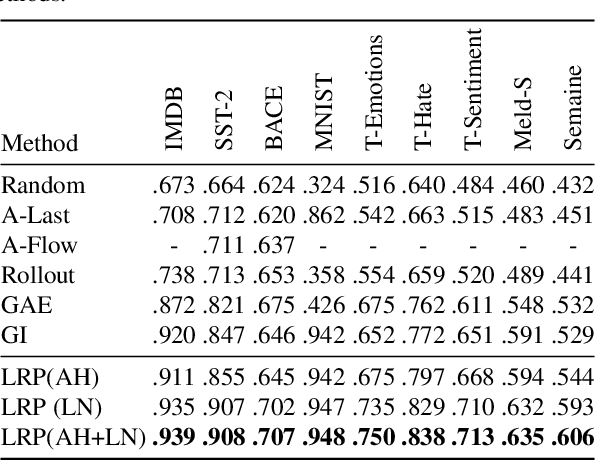
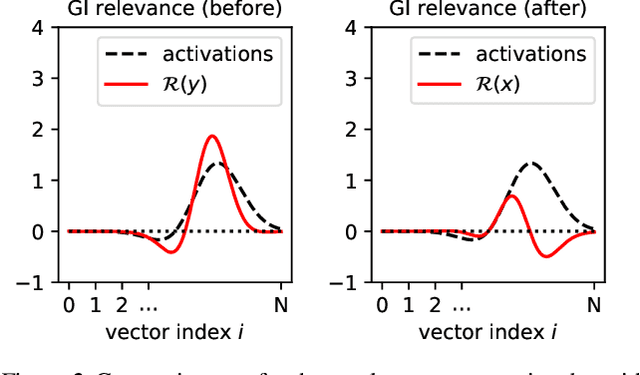
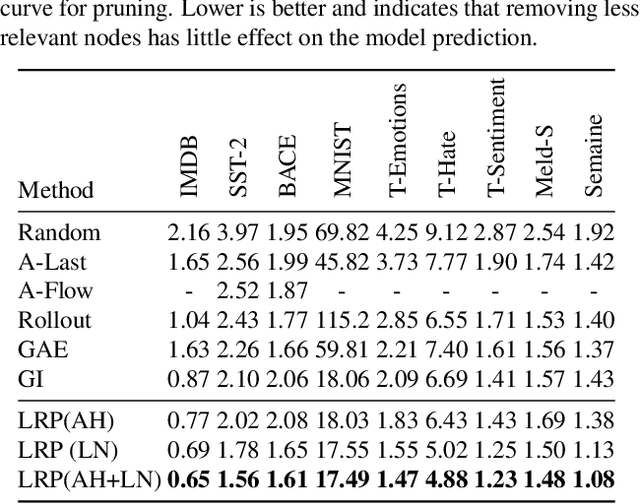
Transformers have become an important workhorse of machine learning, with numerous applications. This necessitates the development of reliable methods for increasing their transparency. Multiple interpretability methods, often based on gradient information, have been proposed. We show that the gradient in a Transformer reflects the function only locally, and thus fails to reliably identify the contribution of input features to the prediction. We identify Attention Heads and LayerNorm as main reasons for such unreliable explanations and propose a more stable way for propagation through these layers. Our proposal, which can be seen as a proper extension of the well-established LRP method to Transformers, is shown both theoretically and empirically to overcome the deficiency of a simple gradient-based approach, and achieves state-of-the-art explanation performance on a broad range of Transformer models and datasets.
An AI-based Approach for Tracing Content Requirements in Financial Documents
Oct 28, 2021

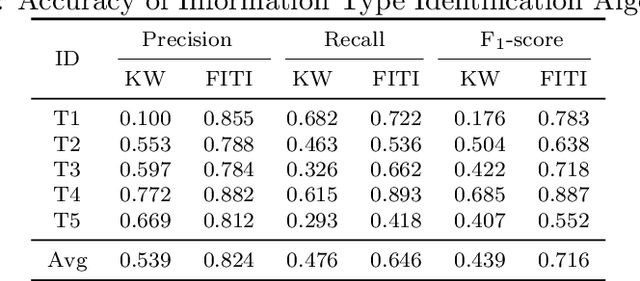
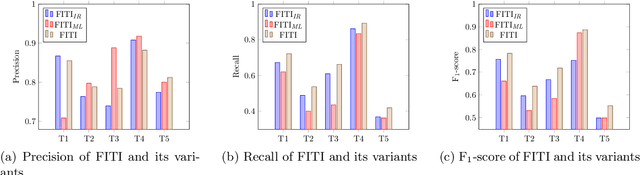
The completeness (in terms of content) of financial documents is a fundamental requirement for investment funds. To ensure completeness, financial regulators spend a huge amount of time for carefully checking every financial document based on the relevant content requirements, which prescribe the information types to be included in financial documents (e.g., the description of shares' issue conditions). Although several techniques have been proposed to automatically detect certain types of information in documents in various application domains, they provide limited support to help regulators automatically identify the text chunks related to financial information types, due to the complexity of financial documents and the diversity of the sentences characterizing an information type. In this paper, we propose FITI, an artificial intelligence (AI)-based method for tracing content requirements in financial documents. Given a new financial document, FITI selects a set of candidate sentences for efficient information type identification. Then, FITI uses a combination of rule-based and data-centric approaches, by leveraging information retrieval (IR) and machine learning (ML) techniques that analyze the words, sentences, and contexts related to an information type, to rank candidate sentences. Finally, using a list of indicator phrases related to each information type, a heuristic-based selector, which considers both the sentence ranking and the domain-specific phrases, determines a list of sentences corresponding to each information type. We evaluated FITI by assessing its effectiveness in tracing financial content requirements in 100 financial documents. Experimental results show that FITI provides accurate identification with average precision and recall values of 0.824 and 0.646, respectively. Furthermore, FITI can detect about 80% of missing information types in financial documents.
Learning to Detect Instance-level Salient Objects Using Complementary Image Labels
Nov 19, 2021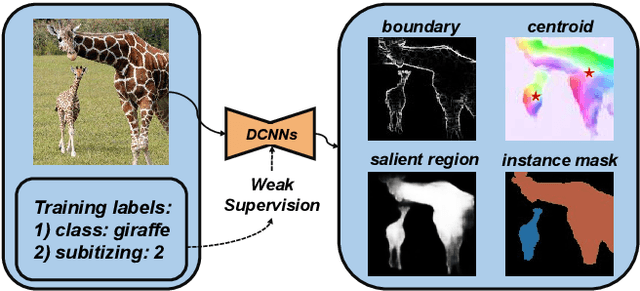
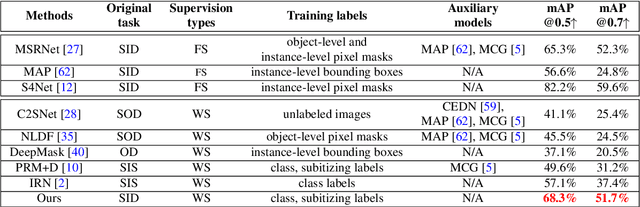
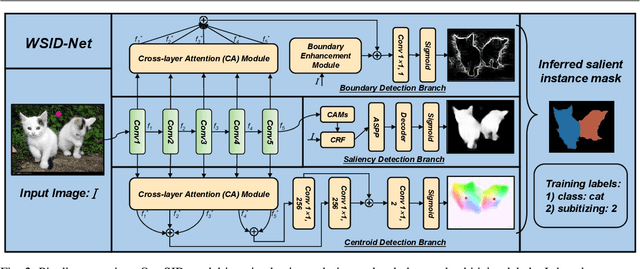
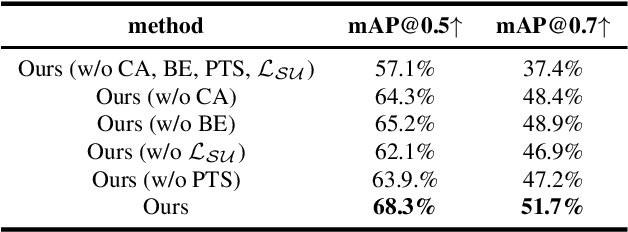
Existing salient instance detection (SID) methods typically learn from pixel-level annotated datasets. In this paper, we present the first weakly-supervised approach to the SID problem. Although weak supervision has been considered in general saliency detection, it is mainly based on using class labels for object localization. However, it is non-trivial to use only class labels to learn instance-aware saliency information, as salient instances with high semantic affinities may not be easily separated by the labels. As the subitizing information provides an instant judgement on the number of salient items, it is naturally related to detecting salient instances and may help separate instances of the same class while grouping different parts of the same instance. Inspired by this observation, we propose to use class and subitizing labels as weak supervision for the SID problem. We propose a novel weakly-supervised network with three branches: a Saliency Detection Branch leveraging class consistency information to locate candidate objects; a Boundary Detection Branch exploiting class discrepancy information to delineate object boundaries; and a Centroid Detection Branch using subitizing information to detect salient instance centroids. This complementary information is then fused to produce a salient instance map. To facilitate the learning process, we further propose a progressive training scheme to reduce label noise and the corresponding noise learned by the model, via reciprocating the model with progressive salient instance prediction and model refreshing. Our extensive evaluations show that the proposed method plays favorably against carefully designed baseline methods adapted from related tasks.
KC-TSS: An Algorithm for Heterogeneous Robot Teams Performing Resilient Target Search
Mar 02, 2022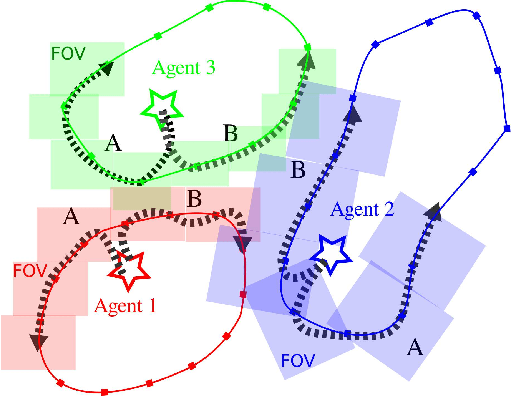
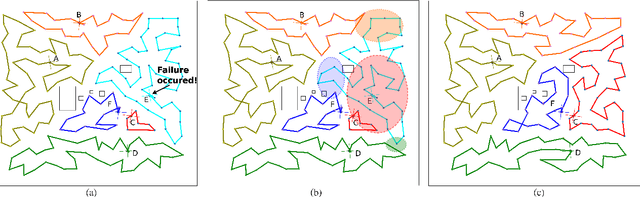
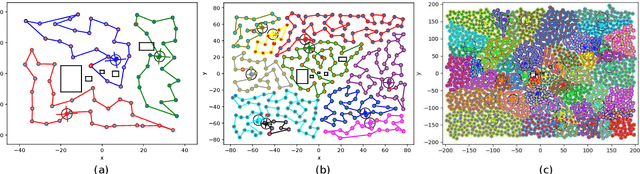
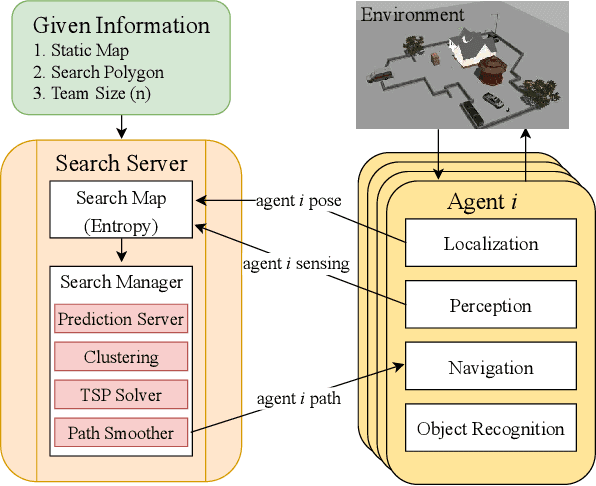
This paper proposes KC-TSS: K-Clustered-Traveling Salesman Based Search, a failure resilient path planning algorithm for heterogeneous robot teams performing target search in human environments. We separate the sample path generation problem into Heterogeneous Clustering and multiple Traveling Salesman Problems. This allows us to provide high-quality candidate paths (i.e. minimal backtracking, overlap) to an Information-Theoretic utility function for each agent. First, we generate waypoint candidates from map knowledge and a target prediction model. All of these candidates are clustered according to the number of agents and their ability to cover space, or coverage competency. Each agent solves a Traveling Salesman Problem (TSP) instance over their assigned cluster and then candidates are fed to a utility function for path selection. We perform extensive Gazebo simulations and preliminary deployment of real robots in indoor search and simulated rescue scenarios with static targets. We compare our proposed method against a state-of-the-art algorithm and show that ours is able to outperform it in mission time. Our method provides resilience in the event of single or multi teammate failure by recomputing global team plans online.
Two-Stage Architectural Fine-Tuning with Neural Architecture Search using Early-Stopping in Image Classification
Feb 18, 2022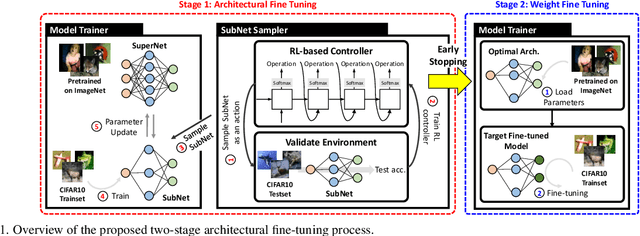

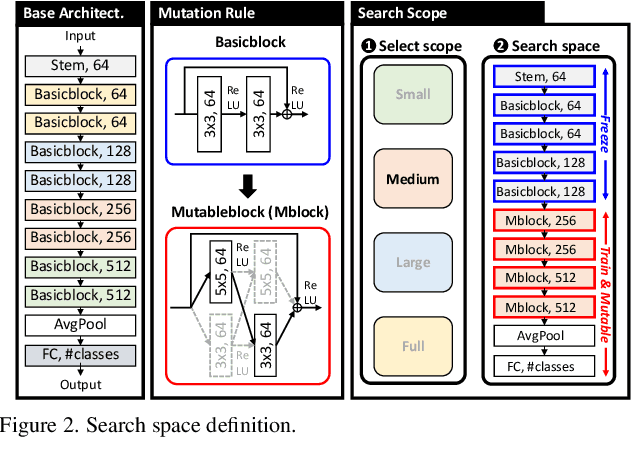
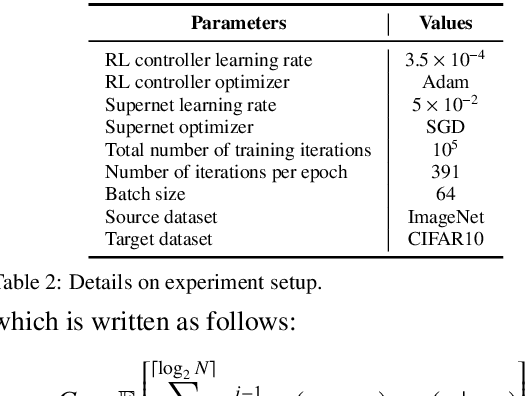
Deep neural networks (NN) perform well in various tasks (e.g., computer vision) because of the convolutional neural networks (CNN). However, the difficulty of gathering quality data in the industry field hinders the practical use of NN. To cope with this issue, the concept of transfer learning (TL) has emerged, which leverages the fine-tuning of NNs trained on large-scale datasets in data-scarce situations. Therefore, this paper suggests a two-stage architectural fine-tuning method for image classification, inspired by the concept of neural architecture search (NAS). One of the main ideas of our proposed method is a mutation with base architectures, which reduces the search cost by using given architectural information. Moreover, an early-stopping is also considered which directly reduces NAS costs. Experimental results verify that our proposed method reduces computational and searching costs by up to 28.2% and 22.3%, compared to existing methods.
Prediction of speech intelligibility with DNN-based performance measures
Mar 17, 2022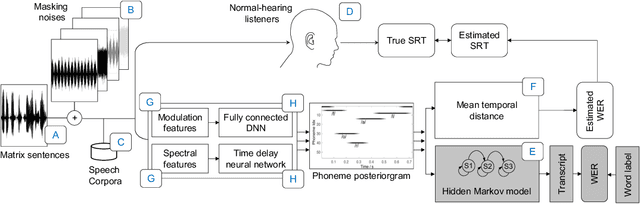


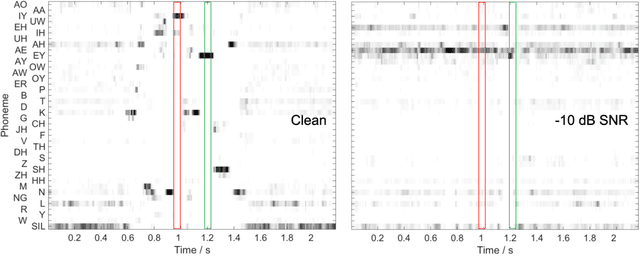
This paper presents a speech intelligibility model based on automatic speech recognition (ASR), combining phoneme probabilities from deep neural networks (DNN) and a performance measure that estimates the word error rate from these probabilities. This model does not require the clean speech reference nor the word labels during testing as the ASR decoding step, which finds the most likely sequence of words given phoneme posterior probabilities, is omitted. The model is evaluated via the root-mean-squared error between the predicted and observed speech reception thresholds from eight normal-hearing listeners. The recognition task consists of identifying noisy words from a German matrix sentence test. The speech material was mixed with eight noise maskers covering different modulation types, from speech-shaped stationary noise to a single-talker masker. The prediction performance is compared to five established models and an ASR-model using word labels. Two combinations of features and networks were tested. Both include temporal information either at the feature level (amplitude modulation filterbanks and a feed-forward network) or captured by the architecture (mel-spectrograms and a time-delay deep neural network, TDNN). The TDNN model is on par with the DNN while reducing the number of parameters by a factor of 37; this optimization allows parallel streams on dedicated hearing aid hardware as a forward-pass can be computed within the 10ms of each frame. The proposed model performs almost as well as the label-based model and produces more accurate predictions than the baseline models.
MGA-VQA: Multi-Granularity Alignment for Visual Question Answering
Jan 25, 2022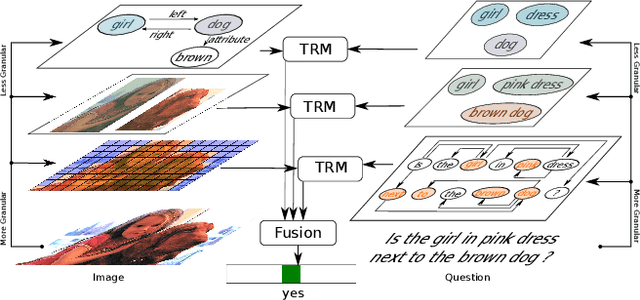
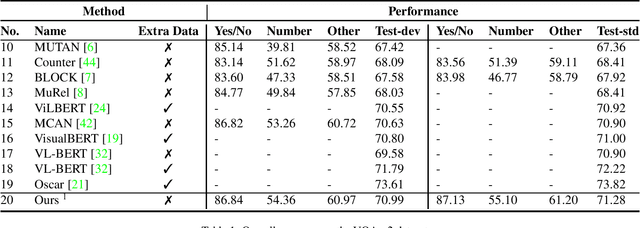
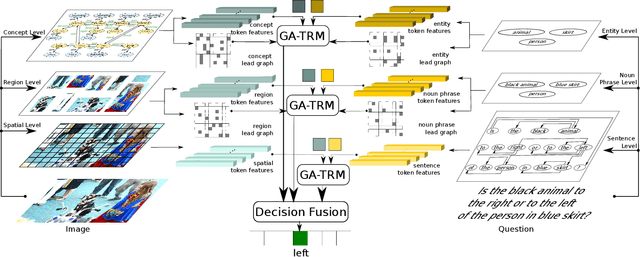

Learning to answer visual questions is a challenging task since the multi-modal inputs are within two feature spaces. Moreover, reasoning in visual question answering requires the model to understand both image and question, and align them in the same space, rather than simply memorize statistics about the question-answer pairs. Thus, it is essential to find component connections between different modalities and within each modality to achieve better attention. Previous works learned attention weights directly on the features. However, the improvement is limited since these two modality features are in two domains: image features are highly diverse, lacking structure and grammatical rules as language, and natural language features have a higher probability of missing detailed information. To better learn the attention between visual and text, we focus on how to construct input stratification and embed structural information to improve the alignment between different level components. We propose Multi-Granularity Alignment architecture for Visual Question Answering task (MGA-VQA), which learns intra- and inter-modality correlations by multi-granularity alignment, and outputs the final result by the decision fusion module. In contrast to previous works, our model splits alignment into different levels to achieve learning better correlations without needing additional data and annotations. The experiments on the VQA-v2 and GQA datasets demonstrate that our model significantly outperforms non-pretrained state-of-the-art methods on both datasets without extra pretraining data and annotations. Moreover, it even achieves better results over the pre-trained methods on GQA.