 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep-QPP: A Pairwise Interaction-based Deep Learning Model for Supervised Query Performance Prediction
Feb 15, 2022
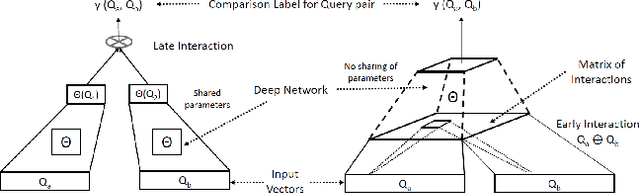
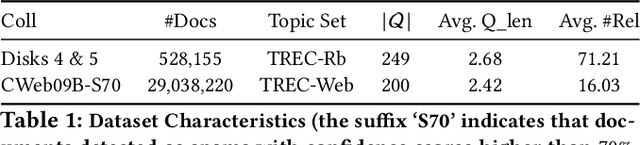
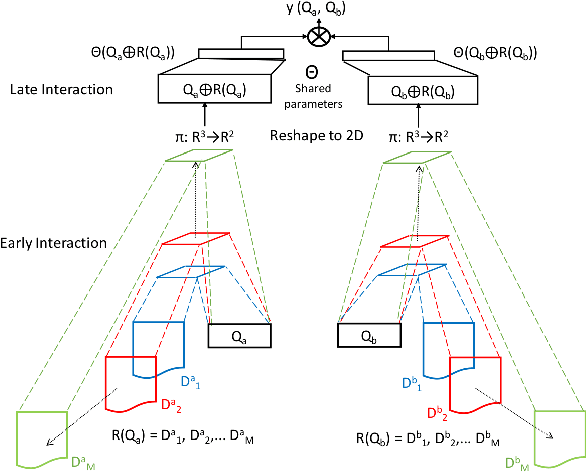
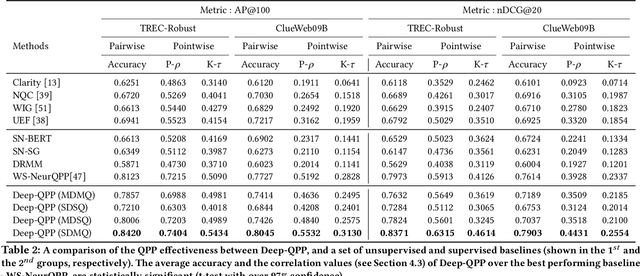
Motivated by the recent success of end-to-end deep neural models for ranking tasks, we present here a supervised end-to-end neural approach for query performance prediction (QPP). In contrast to unsupervised approaches that rely on various statistics of document score distributions, our approach is entirely data-driven. Further, in contrast to weakly supervised approaches, our method also does not rely on the outputs from different QPP estimators. In particular, our model leverages information from the semantic interactions between the terms of a query and those in the top-documents retrieved with it. The architecture of the model comprises multiple layers of 2D convolution filters followed by a feed-forward layer of parameters. Experiments on standard test collections demonstrate that our proposed supervised approach outperforms other state-of-the-art supervised and unsupervised approaches.
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
Mar 10, 2022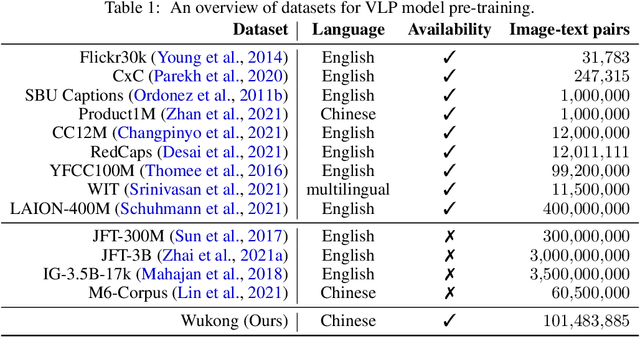
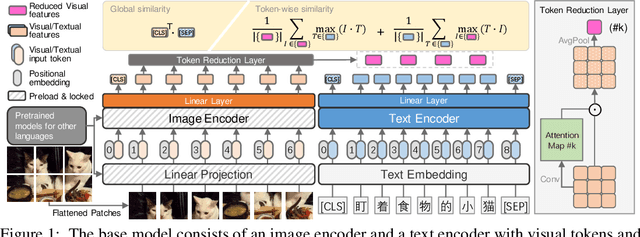


Vision-Language Pre-training (VLP) models have shown remarkable performance on various downstream tasks. Their success heavily relies on the scale of pre-trained cross-modal datasets. However, the lack of large-scale datasets and benchmarks in Chinese hinders the development of Chinese VLP models and broader multilingual applications. In this work, we release a large-scale Chinese cross-modal dataset named Wukong, containing 100 million Chinese image-text pairs from the web. Wukong aims to benchmark different multi-modal pre-training methods to facilitate the VLP research and community development. Furthermore, we release a group of models pre-trained with various image encoders (ViT-B/ViT-L/SwinT) and also apply advanced pre-training techniques into VLP such as locked-image text tuning, token-wise similarity in contrastive learning, and reduced-token interaction. Extensive experiments and a deep benchmarking of different downstream tasks are also provided. Experiments show that Wukong can serve as a promising Chinese pre-training dataset and benchmark for different cross-modal learning methods. For the zero-shot image classification task on 10 datasets, our model achieves an average accuracy of 73.03%. For the image-text retrieval task,our model achieves a mean recall of 71.6% on AIC-ICC which is 12.9% higher than the result of WenLan 2.0. More information can refer to https://wukong-dataset.github.io/wukong-dataset/.
Robust Table Detection and Structure Recognition from Heterogeneous Document Images
Mar 17, 2022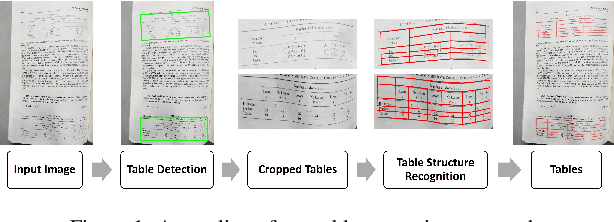
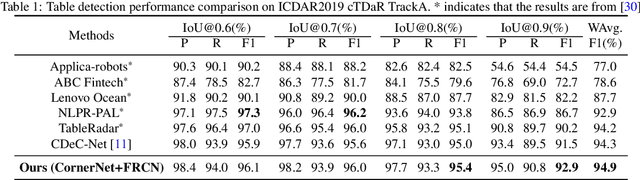
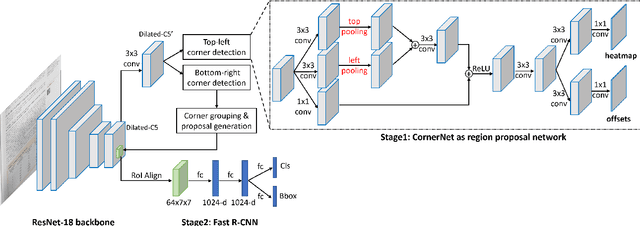

We introduce a new table detection and structure recognition approach named RobusTabNet to detect the boundaries of tables and reconstruct the cellular structure of the table from heterogeneous document images. For table detection, we propose to use CornerNet as a new region proposal network to generate higher quality table proposals for Faster R-CNN, which has significantly improved the localization accuracy of Faster R-CNN for table detection. Consequently, our table detection approach achieves state-of-the-art performance on three public table detection benchmarks, namely cTDaR TrackA, PubLayNet and IIIT-AR-13K, by only using a lightweight ResNet-18 backbone network. Furthermore, we propose a new split-and-merge based table structure recognition approach, in which a novel spatial CNN based separation line prediction module is proposed to split each detected table into a grid of cells, and a Grid CNN based cell merging module is applied to recover the spanning cells. As the spatial CNN module can effectively propagate contextual information across the whole table image, our table structure recognizer can robustly recognize tables with large blank spaces and geometrically distorted (even curved) tables. Thanks to these two techniques, our table structure recognition approach achieves state-of-the-art performance on three public benchmarks, including SciTSR, PubTabNet and cTDaR TrackB. Moreover, we have further demonstrated the advantages of our approach in recognizing tables with complex structures, large blank spaces, empty or spanning cells as well as geometrically distorted or even curved tables on a more challenging in-house dataset.
XAI for Transformers: Better Explanations through Conservative Propagation
Feb 15, 2022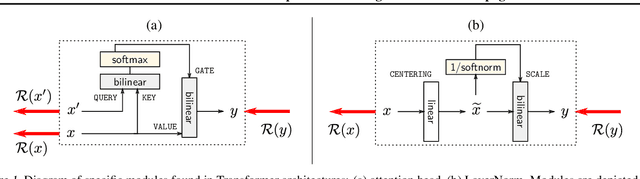
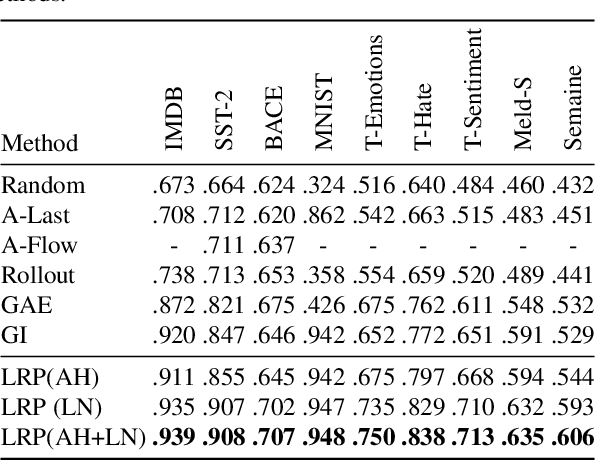
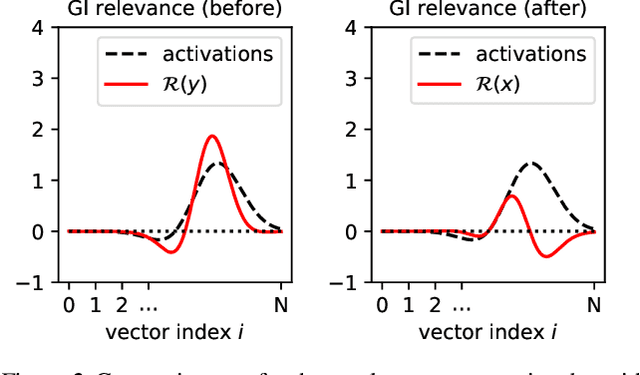
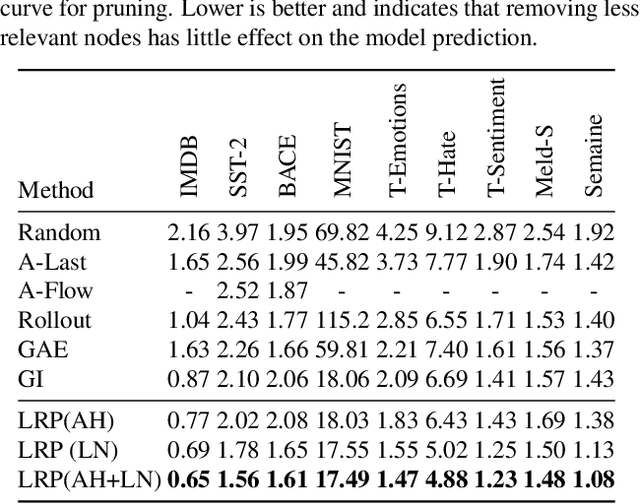
Transformers have become an important workhorse of machine learning, with numerous applications. This necessitates the development of reliable methods for increasing their transparency. Multiple interpretability methods, often based on gradient information, have been proposed. We show that the gradient in a Transformer reflects the function only locally, and thus fails to reliably identify the contribution of input features to the prediction. We identify Attention Heads and LayerNorm as main reasons for such unreliable explanations and propose a more stable way for propagation through these layers. Our proposal, which can be seen as a proper extension of the well-established LRP method to Transformers, is shown both theoretically and empirically to overcome the deficiency of a simple gradient-based approach, and achieves state-of-the-art explanation performance on a broad range of Transformer models and datasets.
Two-Stage Architectural Fine-Tuning with Neural Architecture Search using Early-Stopping in Image Classification
Feb 18, 2022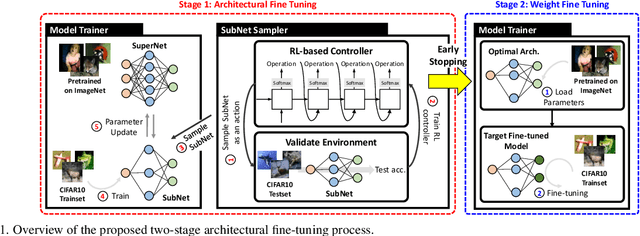

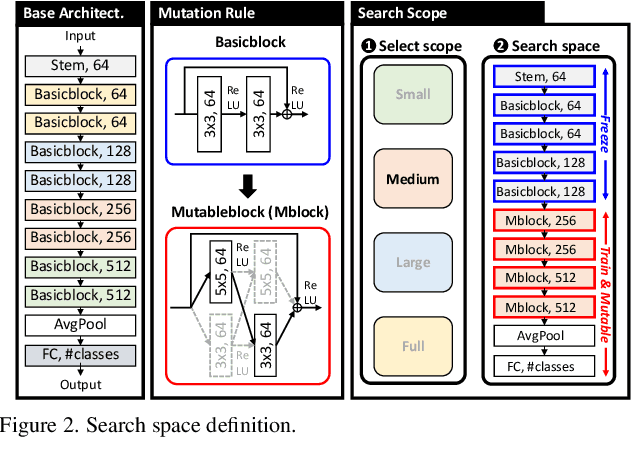
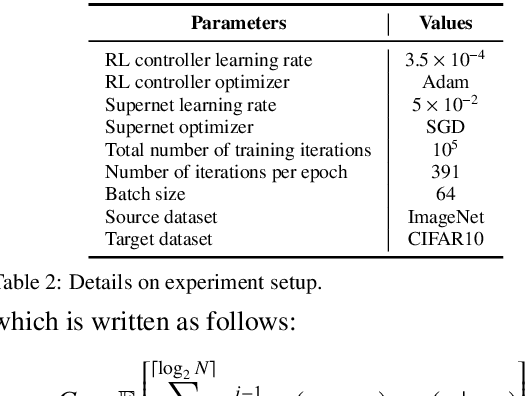
Deep neural networks (NN) perform well in various tasks (e.g., computer vision) because of the convolutional neural networks (CNN). However, the difficulty of gathering quality data in the industry field hinders the practical use of NN. To cope with this issue, the concept of transfer learning (TL) has emerged, which leverages the fine-tuning of NNs trained on large-scale datasets in data-scarce situations. Therefore, this paper suggests a two-stage architectural fine-tuning method for image classification, inspired by the concept of neural architecture search (NAS). One of the main ideas of our proposed method is a mutation with base architectures, which reduces the search cost by using given architectural information. Moreover, an early-stopping is also considered which directly reduces NAS costs. Experimental results verify that our proposed method reduces computational and searching costs by up to 28.2% and 22.3%, compared to existing methods.
Dense Voxel Fusion for 3D Object Detection
Mar 02, 2022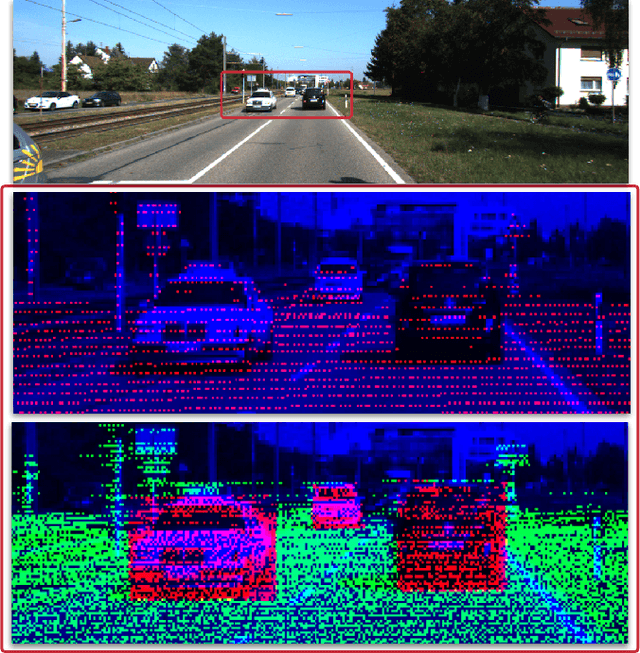
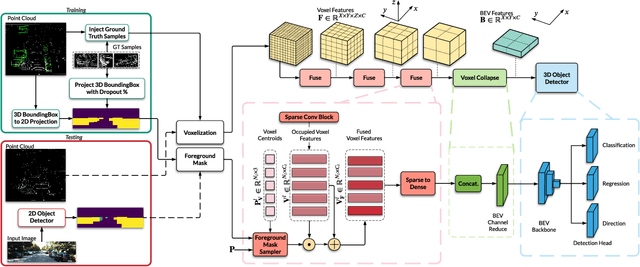
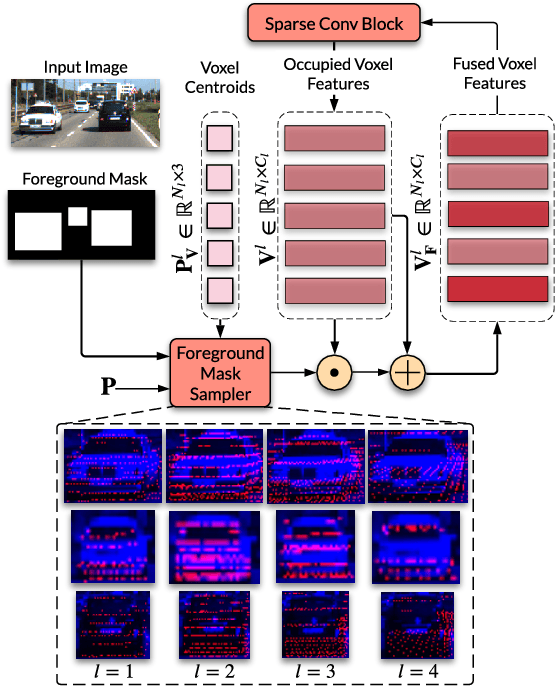
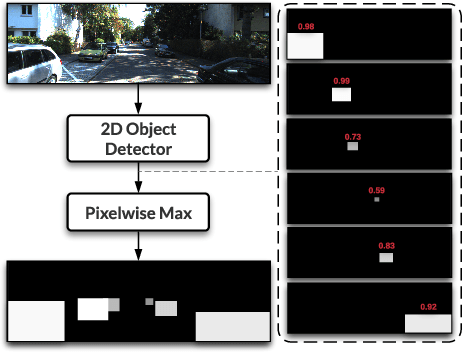
Camera and LiDAR sensor modalities provide complementary appearance and geometric information useful for detecting 3D objects for autonomous vehicle applications. However, current fusion models underperform state-of-art LiDAR-only methods on 3D object detection benchmarks. Our proposed solution, Dense Voxel Fusion (DVF) is a sequential fusion method that generates multi-scale multi-modal dense voxel feature representations, improving expressiveness in low point density regions. To enhance multi-modal learning, we train directly with ground truth 2D bounding box labels, avoiding noisy, detector-specific, 2D predictions. Additionally, we use LiDAR ground truth sampling to simulate missed 2D detections and to accelerate training convergence. Both DVF and the multi-modal training approaches can be applied to any voxel-based LiDAR backbone without introducing additional learnable parameters. DVF outperforms existing sparse fusion detectors, ranking $1^{st}$ among all published fusion methods on KITTI's 3D car detection benchmark at the time of submission and significantly improves 3D vehicle detection performance of voxel-based methods on the Waymo Open Dataset. We also show that our proposed multi-modal training strategy results in better generalization compared to training using erroneous 2D predictions.
Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding
Mar 02, 2022
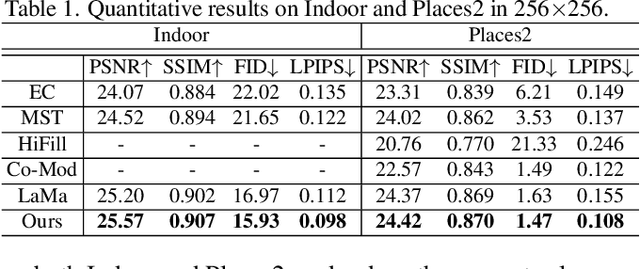
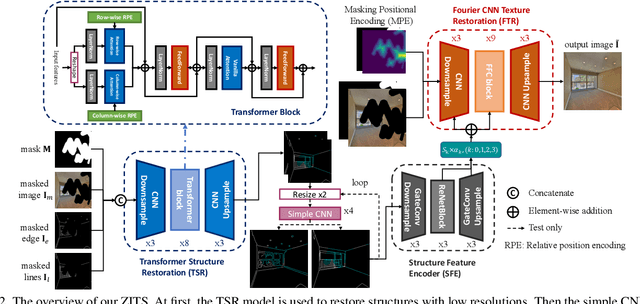
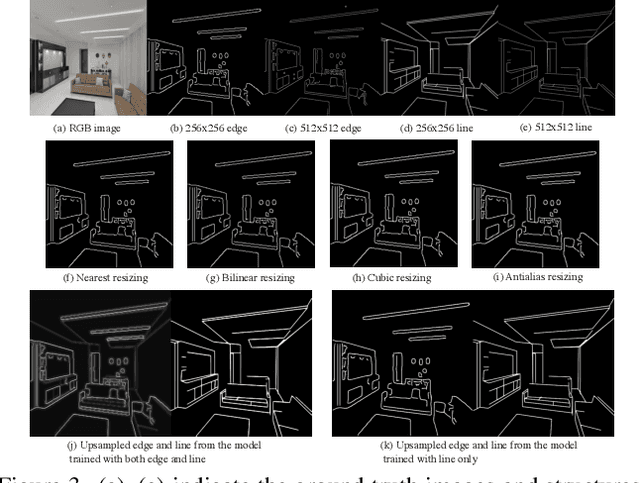
Image inpainting has made significant advances in recent years. However, it is still challenging to recover corrupted images with both vivid textures and reasonable structures. Some specific methods only tackle regular textures while losing holistic structures due to the limited receptive fields of convolutional neural networks (CNNs). On the other hand, attention-based models can learn better long-range dependency for the structure recovery, but they are limited by the heavy computation for inference with large image sizes. To address these issues, we propose to leverage an additional structure restorer to facilitate the image inpainting incrementally. The proposed model restores holistic image structures with a powerful attention-based transformer model in a fixed low-resolution sketch space. Such a grayscale space is easy to be upsampled to larger scales to convey correct structural information. Our structure restorer can be integrated with other pretrained inpainting models efficiently with the zero-initialized residual addition. Furthermore, a masking positional encoding strategy is utilized to improve the performance with large irregular masks. Extensive experiments on various datasets validate the efficacy of our model compared with other competitors. Our codes are released in https://github.com/DQiaole/ZITS_inpainting.
Deep Generative model with Hierarchical Latent Factors for Time Series Anomaly Detection
Feb 25, 2022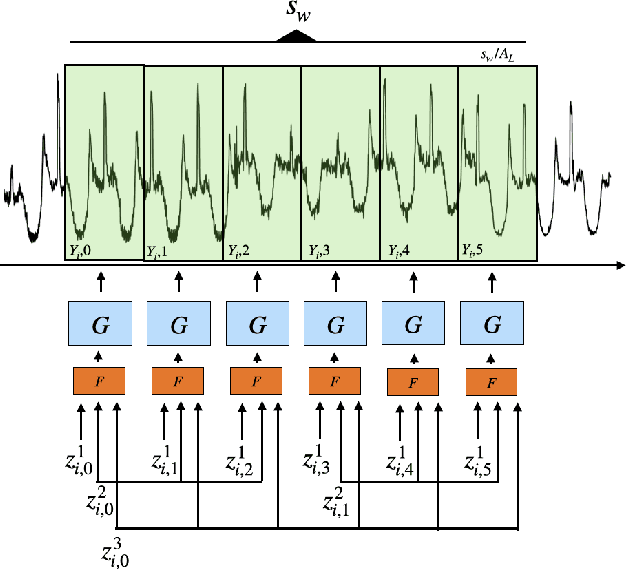
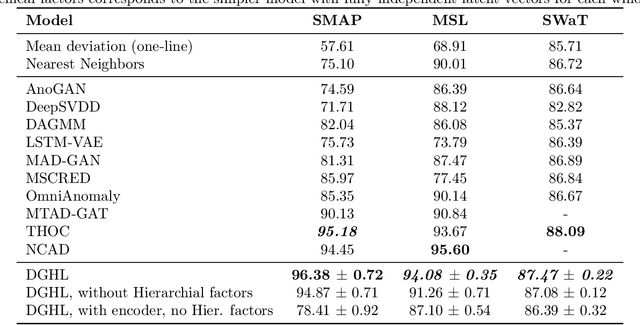
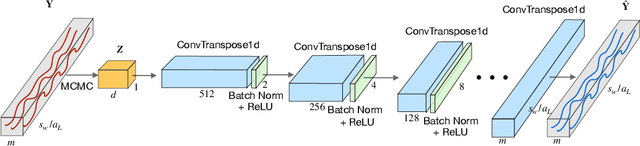
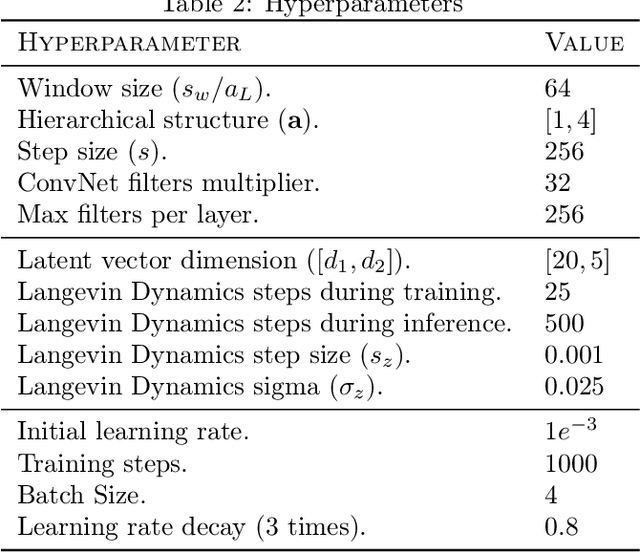
Multivariate time series anomaly detection has become an active area of research in recent years, with Deep Learning models outperforming previous approaches on benchmark datasets. Among reconstruction-based models, most previous work has focused on Variational Autoencoders and Generative Adversarial Networks. This work presents DGHL, a new family of generative models for time series anomaly detection, trained by maximizing the observed likelihood by posterior sampling and alternating back-propagation. A top-down Convolution Network maps a novel hierarchical latent space to time series windows, exploiting temporal dynamics to encode information efficiently. Despite relying on posterior sampling, it is computationally more efficient than current approaches, with up to 10x shorter training times than RNN based models. Our method outperformed current state-of-the-art models on four popular benchmark datasets. Finally, DGHL is robust to variable features between entities and accurate even with large proportions of missing values, settings with increasing relevance with the advent of IoT. We demonstrate the superior robustness of DGHL with novel occlusion experiments in this literature. Our code is available at https://github.com/cchallu/dghl.
Regulatory Compliance through Doc2Doc Information Retrieval: A case study in EU/UK legislation where text similarity has limitations
Jan 26, 2021
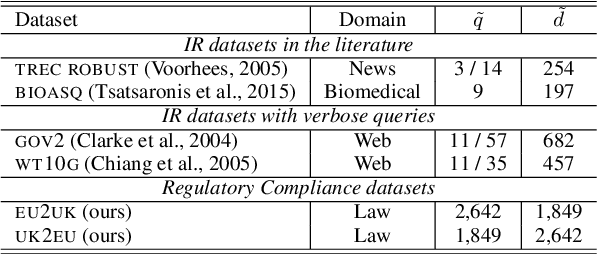
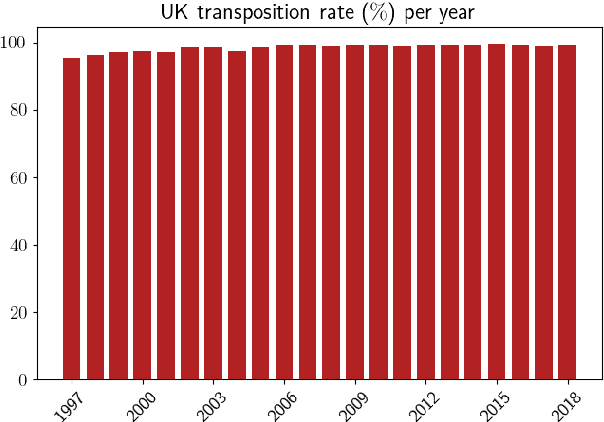

Major scandals in corporate history have urged the need for regulatory compliance, where organizations need to ensure that their controls (processes) comply with relevant laws, regulations, and policies. However, keeping track of the constantly changing legislation is difficult, thus organizations are increasingly adopting Regulatory Technology (RegTech) to facilitate the process. To this end, we introduce regulatory information retrieval (REG-IR), an application of document-to-document information retrieval (DOC2DOC IR), where the query is an entire document making the task more challenging than traditional IR where the queries are short. Furthermore, we compile and release two datasets based on the relationships between EU directives and UK legislation. We experiment on these datasets using a typical two-step pipeline approach comprising a pre-fetcher and a neural re-ranker. Experimenting with various pre-fetchers from BM25 to k nearest neighbors over representations from several BERT models, we show that fine-tuning a BERT model on an in-domain classification task produces the best representations for IR. We also show that neural re-rankers under-perform due to contradicting supervision, i.e., similar query-document pairs with opposite labels. Thus, they are biased towards the pre-fetcher's score. Interestingly, applying a date filter further improves the performance, showcasing the importance of the time dimension.
MetAug: Contrastive Learning via Meta Feature Augmentation
Mar 10, 2022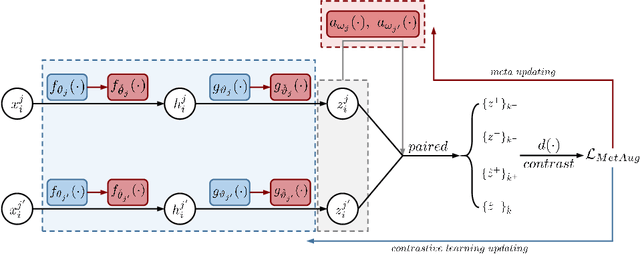
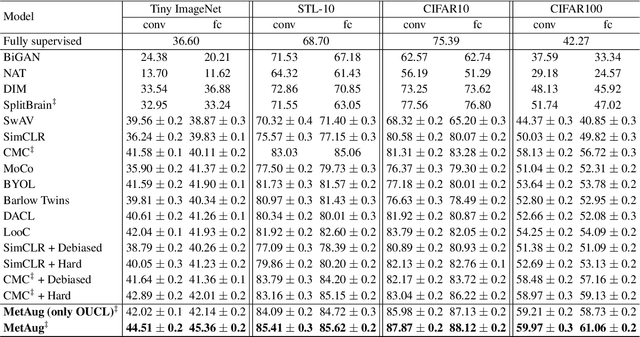
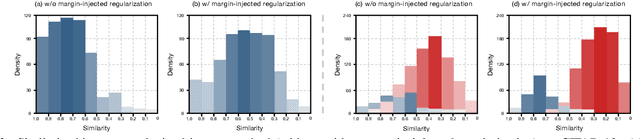
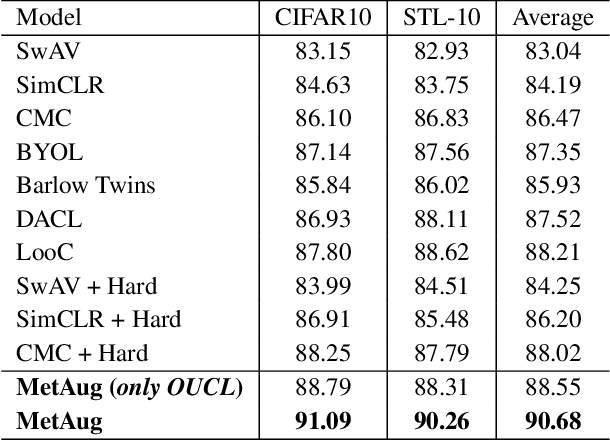
What matters for contrastive learning? We argue that contrastive learning heavily relies on informative features, or "hard" (positive or negative) features. Early works include more informative features by applying complex data augmentations and large batch size or memory bank, and recent works design elaborate sampling approaches to explore informative features. The key challenge toward exploring such features is that the source multi-view data is generated by applying random data augmentations, making it infeasible to always add useful information in the augmented data. Consequently, the informativeness of features learned from such augmented data is limited. In response, we propose to directly augment the features in latent space, thereby learning discriminative representations without a large amount of input data. We perform a meta learning technique to build the augmentation generator that updates its network parameters by considering the performance of the encoder. However, insufficient input data may lead the encoder to learn collapsed features and therefore malfunction the augmentation generator. A new margin-injected regularization is further added in the objective function to avoid the encoder learning a degenerate mapping. To contrast all features in one gradient back-propagation step, we adopt the proposed optimization-driven unified contrastive loss instead of the conventional contrastive loss. Empirically, our method achieves state-of-the-art results on several benchmark datasets.