 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Open Intent Detection
Mar 11, 2022
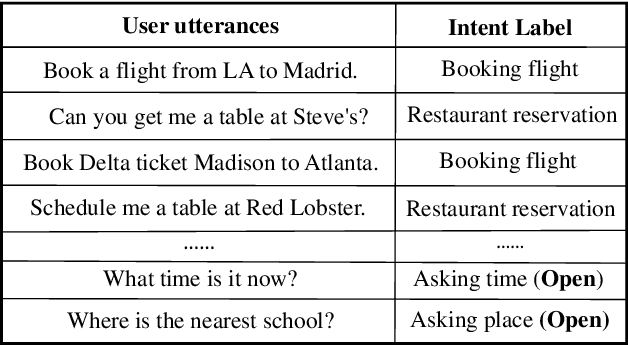

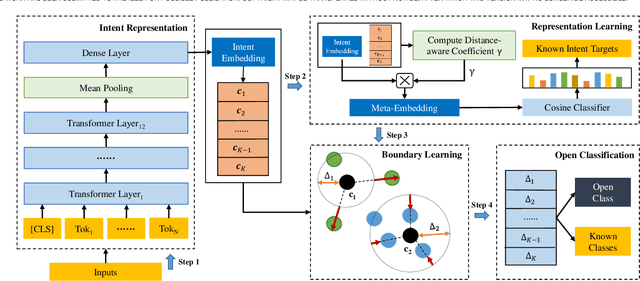
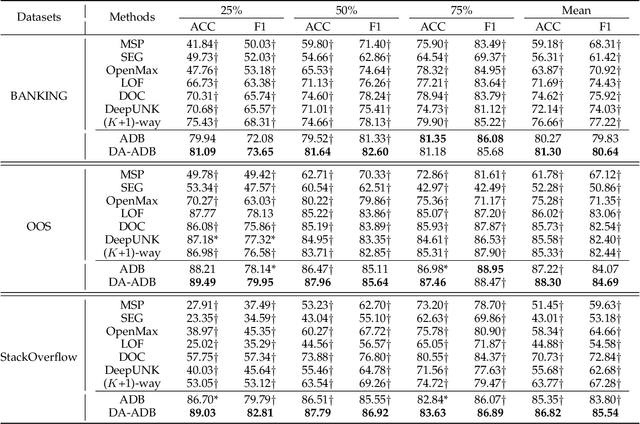
The open intent detection problem is presented in this paper, which aims to identify known intents and detect open intent in natural language understanding. Current methods have two core challenges. On the one hand, the existing methods have limitations in learning robust representations to detect the open intent without any prior knowledge. On the other hand, there lacks an effective approach to learning the specific and compact decision boundary to distinguish the known intents and the open intent. This paper introduces an original pipeline framework, DA-ADB, to address these issues, which successively learns discriminative intent features with distance-aware strategy and appropriate decision boundaries adaptive to the feature space for open intent detection. The proposed method first leverages distance information to enhance the distinguishing capability of the intent representations. Then, it obtains discriminative decision boundaries adaptive to the known intent feature space by balancing both the empirical and open space risks. Extensive experiments show the effectiveness of distance-aware and boundary learning strategies. Compared with the state-of-the-art methods, our method achieves substantial improvements on three benchmark intent datasets. It also yields robust performance with different proportions of labeled data and known categories.
End-to-end P300 BCI using Bayesian accumulation of Riemannian probabilities
Mar 15, 2022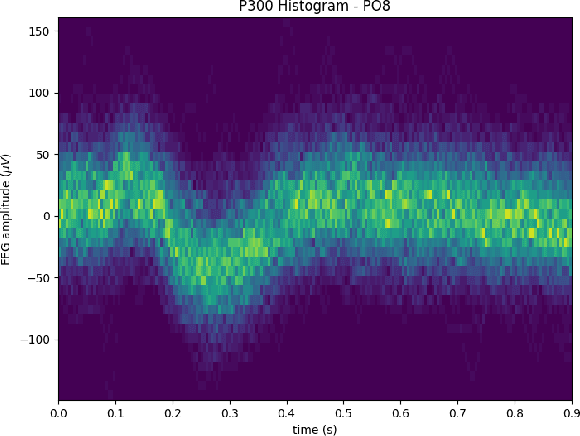
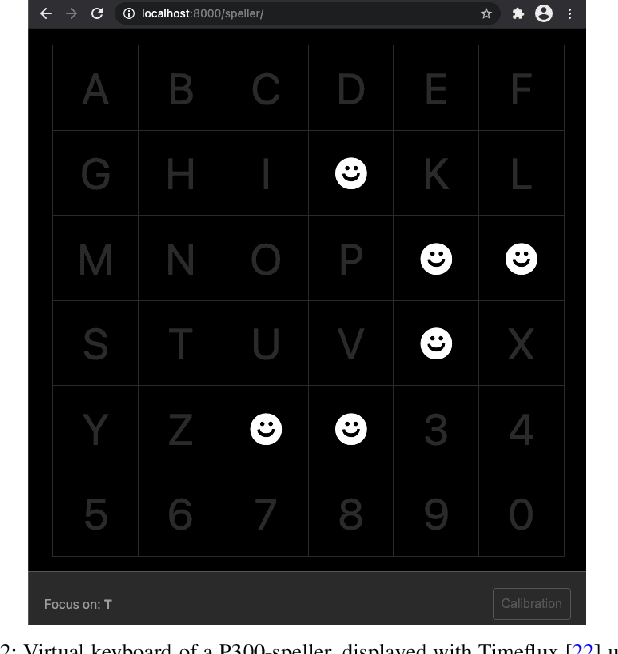
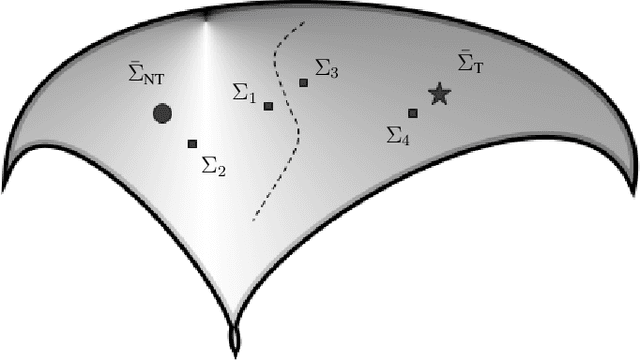
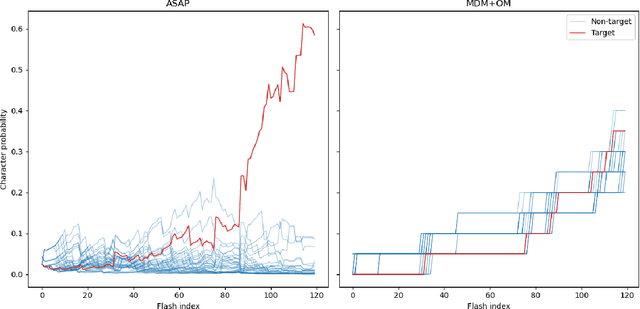
In brain-computer interfaces (BCI), most of the approaches based on event-related potential (ERP) focus on the detection of P300, aiming for single trial classification for a speller task. While this is an important objective, existing P300 BCI still require several repetitions to achieve a correct classification accuracy. Signal processing and machine learning advances in P300 BCI mostly revolve around the P300 detection part, leaving the character classification out of the scope. To reduce the number of repetitions while maintaining a good character classification, it is critical to embrace the full classification problem. We introduce an end-to-end pipeline, starting from feature extraction, and is composed of an ERP-level classification using probabilistic Riemannian MDM which feeds a character-level classification using Bayesian accumulation of confidence across trials. Whereas existing approaches only increase the confidence of a character when it is flashed, our new pipeline, called Bayesian accumulation of Riemannian probabilities (ASAP), update the confidence of each character after each flash. We provide the proper derivation and theoretical reformulation of this Bayesian approach for a seamless processing of information from signal to BCI characters. We demonstrate that our approach performs significantly better than standard methods on public P300 datasets.
HyperPrompt: Prompt-based Task-Conditioning of Transformers
Mar 01, 2022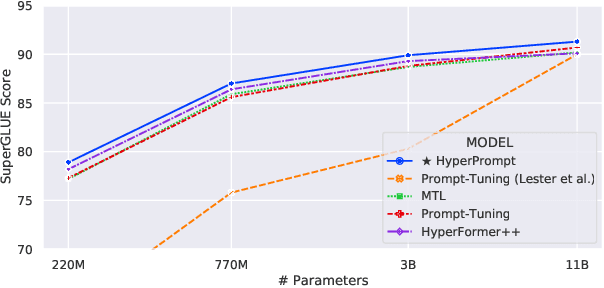

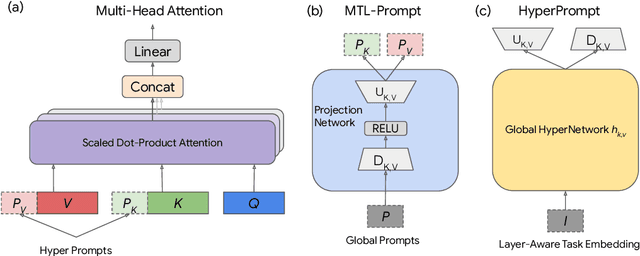
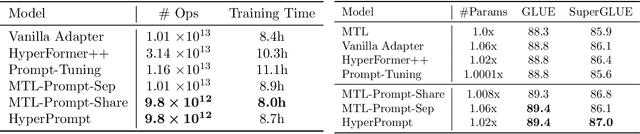
Prompt-Tuning is a new paradigm for finetuning pre-trained language models in a parameter-efficient way. Here, we explore the use of HyperNetworks to generate hyper-prompts: we propose HyperPrompt, a novel architecture for prompt-based task-conditioning of self-attention in Transformers. The hyper-prompts are end-to-end learnable via generation by a HyperNetwork. HyperPrompt allows the network to learn task-specific feature maps where the hyper-prompts serve as task global memories for the queries to attend to, at the same time enabling flexible information sharing among tasks. We show that HyperPrompt is competitive against strong multi-task learning baselines with as few as $0.14\%$ of additional task-conditioning parameters, achieving great parameter and computational efficiency. Through extensive empirical experiments, we demonstrate that HyperPrompt can achieve superior performances over strong T5 multi-task learning baselines and parameter-efficient adapter variants including Prompt-Tuning and HyperFormer++ on Natural Language Understanding benchmarks of GLUE and SuperGLUE across many model sizes.
Morphological Analysis of Japanese Hiragana Sentences using the BI-LSTM CRF Model
Jan 10, 2022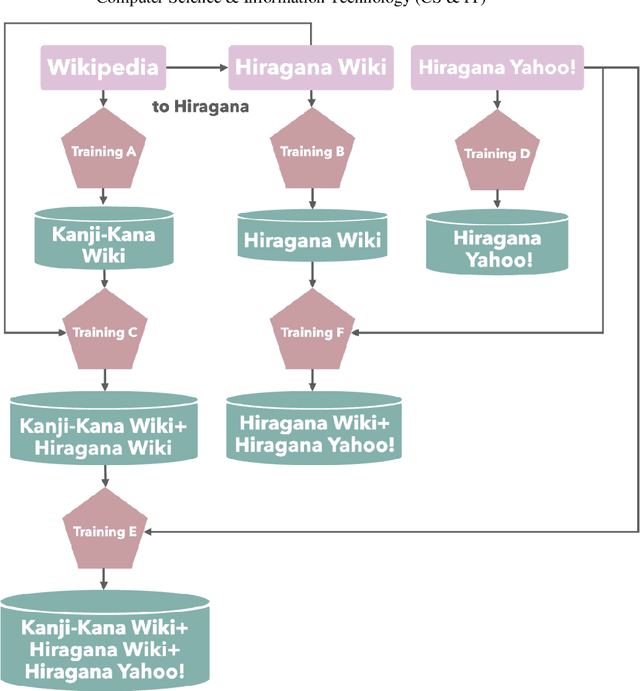

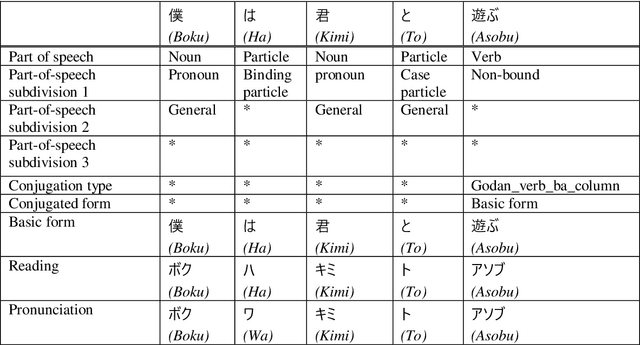
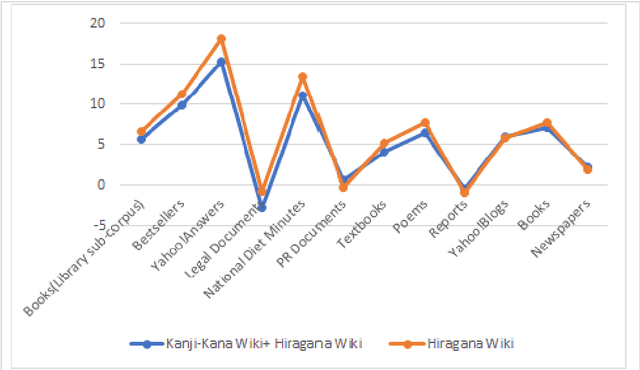
This study proposes a method to develop neural models of the morphological analyzer for Japanese Hiragana sentences using the Bi-LSTM CRF model. Morphological analysis is a technique that divides text data into words and assigns information such as parts of speech. This technique plays an essential role in downstream applications in Japanese natural language processing systems because the Japanese language does not have word delimiters between words. Hiragana is a type of Japanese phonogramic characters, which is used for texts for children or people who cannot read Chinese characters. Morphological analysis of Hiragana sentences is more difficult than that of ordinary Japanese sentences because there is less information for dividing. For morphological analysis of Hiragana sentences, we demonstrated the effectiveness of fine-tuning using a model based on ordinary Japanese text and examined the influence of training data on texts of various genres.
DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
Jan 10, 2022
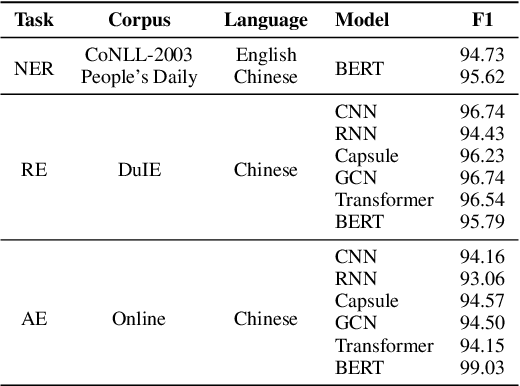
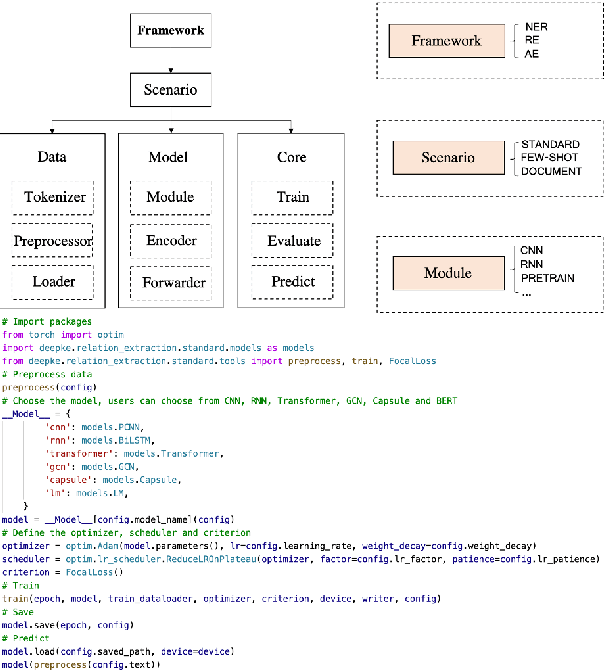
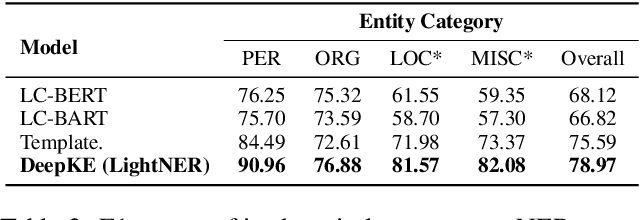
We present a new open-source and extensible knowledge extraction toolkit, called DeepKE (Deep learning based Knowledge Extraction), supporting standard fully supervised, low-resource few-shot and document-level scenarios. DeepKE implements various information extraction tasks, including named entity recognition, relation extraction and attribute extraction. With a unified framework, DeepKE allows developers and researchers to customize datasets and models to extract information from unstructured texts according to their requirements. Specifically, DeepKE not only provides various functional modules and model implementation for different tasks and scenarios but also organizes all components by consistent frameworks to maintain sufficient modularity and extensibility. Besides, we present an online platform in \url{http://deepke.zjukg.cn/} for real-time extraction of various tasks. DeepKE has been equipped with Google Colab tutorials and comprehensive documents for beginners. We release the source code at \url{https://github.com/zjunlp/DeepKE}, with a demo video.
Artificial Intelligence and Auction Design
Feb 12, 2022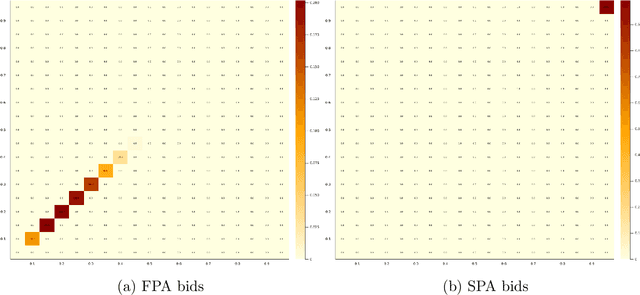
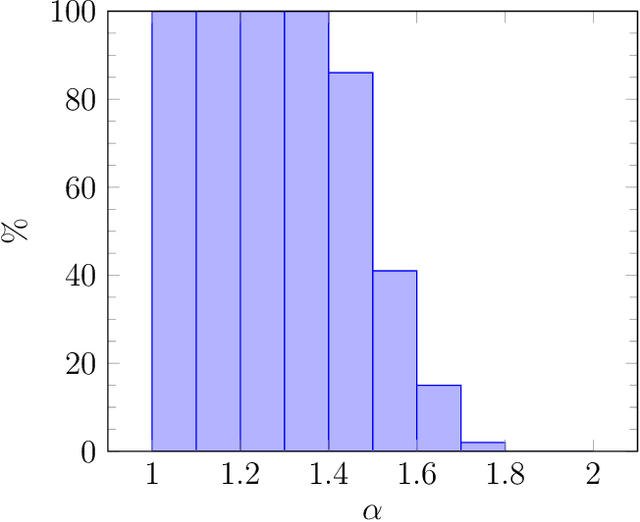
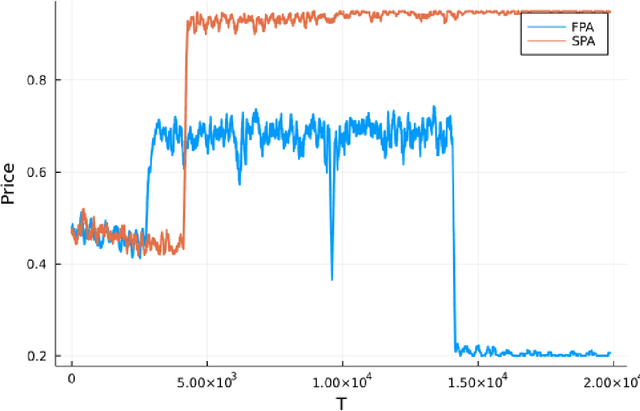
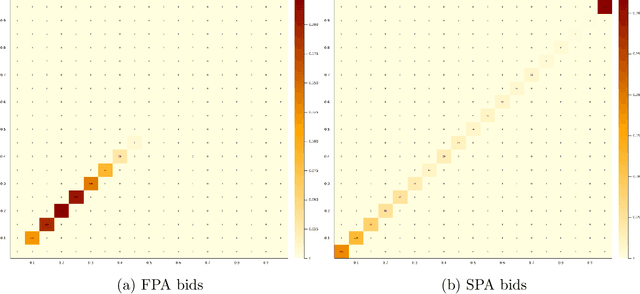
Motivated by online advertising auctions, we study auction design in repeated auctions played by simple Artificial Intelligence algorithms (Q-learning). We find that first-price auctions with no additional feedback lead to tacit-collusive outcomes (bids lower than values), while second-price auctions do not. We show that the difference is driven by the incentive in first-price auctions to outbid opponents by just one bid increment. This facilitates re-coordination on low bids after a phase of experimentation. We also show that providing information about lowest bid to win, as introduced by Google at the time of switch to first-price auctions, increases competitiveness of auctions.
What and How Are We Reporting in HRI? A Review and Recommendations for Reporting Recruitment, Compensation, and Gender
Jan 22, 2022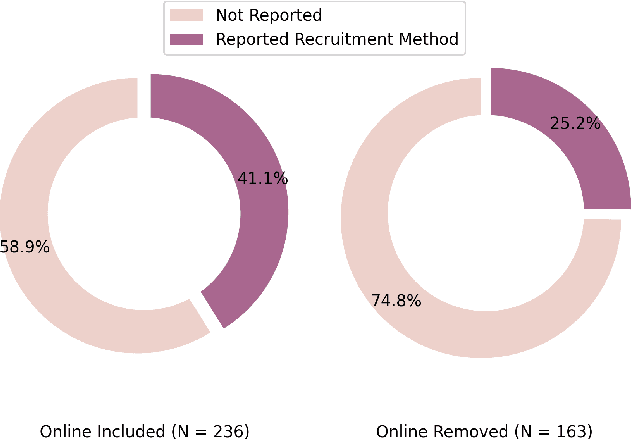
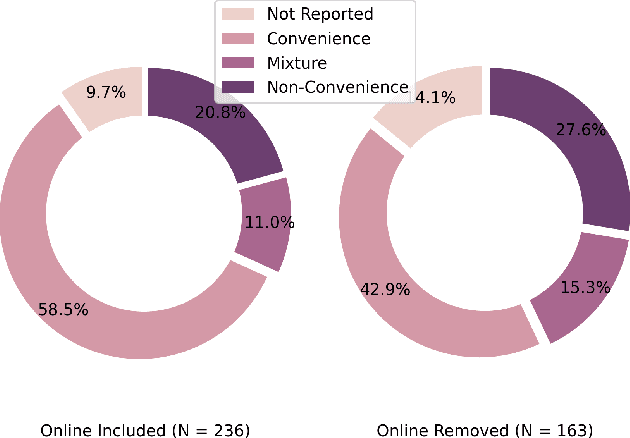
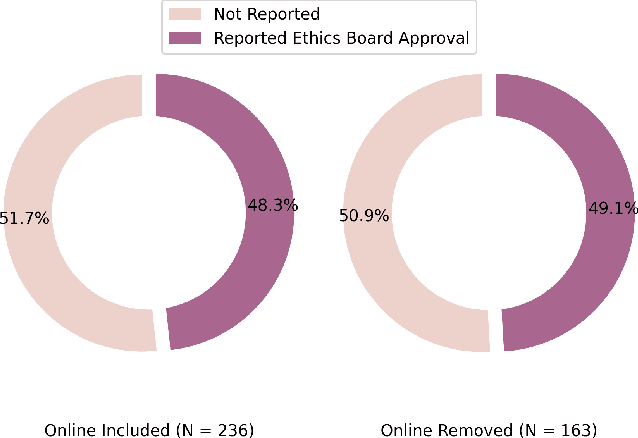
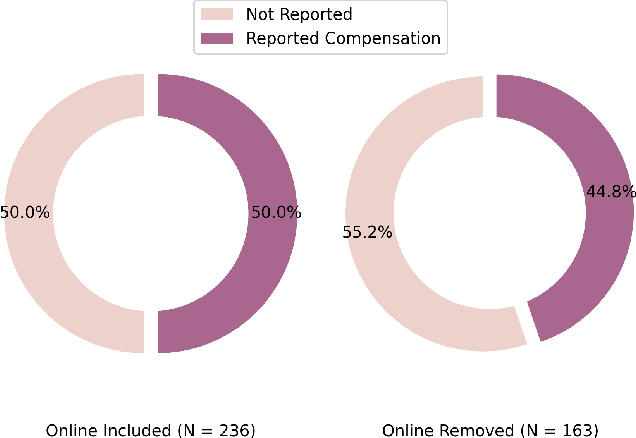
Study reproducibility and generalizability of results to broadly inclusive populations is crucial in any research. Previous meta-analyses in HRI have focused on the consistency of reported information from papers in various categories. However, members of the HRI community have noted that much of the information needed for reproducible and generalizable studies is not found in published papers. We address this issue by surveying the reported study metadata over the past three years (2019 through 2021) of the main proceedings of the International Conference on Human-Robot Interaction (HRI) as well as alt.HRI. Based on the analysis results, we propose a set of recommendations for the HRI community that follow the longer-standing reporting guidelines from human-computer interaction (HCI), psychology, and other fields most related to HRI. Finally, we examine three key areas for user study reproducibility: recruitment details, participant compensation, and participant gender. We find a lack of reporting within each of these study metadata categories: of the 236 studies, 139 studies failed to report recruitment method, 118 studies failed to report compensation, and 62 studies failed to report gender data. This analysis therefore provides guidance about specific types of needed reporting improvements for HRI.
Metal Artifact Reduction with Intra-Oral Scan Data for 3D Low Dose Maxillofacial CBCT Modeling
Feb 08, 2022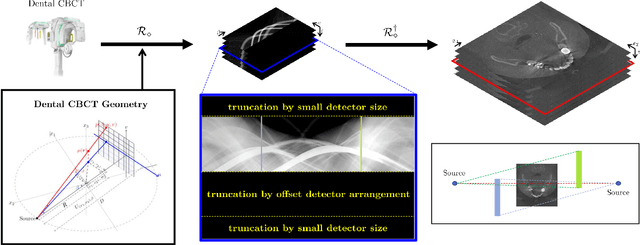
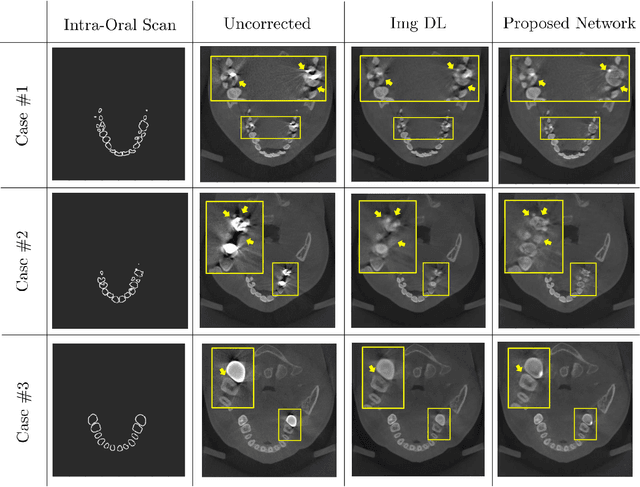
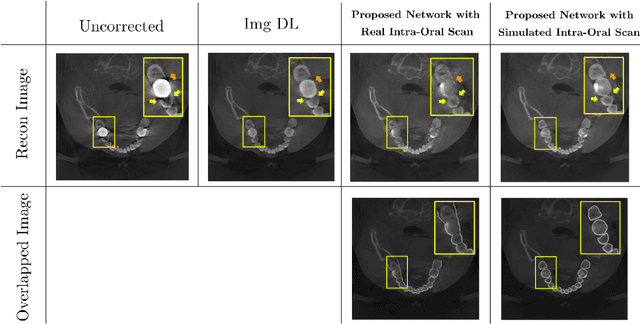
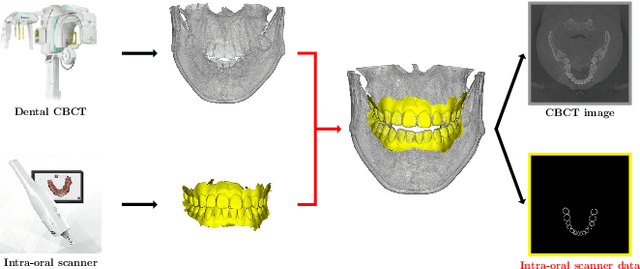
Low-dose dental cone beam computed tomography (CBCT) has been increasingly used for maxillofacial modeling. However, the presence of metallic inserts, such as implants, crowns, and dental filling, causes severe streaking and shading artifacts in a CBCT image and loss of the morphological structures of the teeth, which consequently prevents accurate segmentation of bones. A two-stage metal artifact reduction method is proposed for accurate 3D low-dose maxillofacial CBCT modeling, where a key idea is to utilize explicit tooth shape prior information from intra-oral scan data whose acquisition does not require any extra radiation exposure. In the first stage, an image-to-image deep learning network is employed to mitigate metal-related artifacts. To improve the learning ability, the proposed network is designed to take advantage of the intra-oral scan data as side-inputs and perform multi-task learning of auxiliary tooth segmentation. In the second stage, a 3D maxillofacial model is constructed by segmenting the bones from the dental CBCT image corrected in the first stage. For accurate bone segmentation, weighted thresholding is applied, wherein the weighting region is determined depending on the geometry of the intra-oral scan data. Because acquiring a paired training dataset of metal-artifact-free and metal artifact-affected dental CBCT images is challenging in clinical practice, an automatic method of generating a realistic dataset according to the CBCT physics model is introduced. Numerical simulations and clinical experiments show the feasibility of the proposed method, which takes advantage of tooth surface information from intra-oral scan data in 3D low dose maxillofacial CBCT modeling.
A unified 3D framework for Organs at Risk Localization and Segmentation for Radiation Therapy Planning
Mar 01, 2022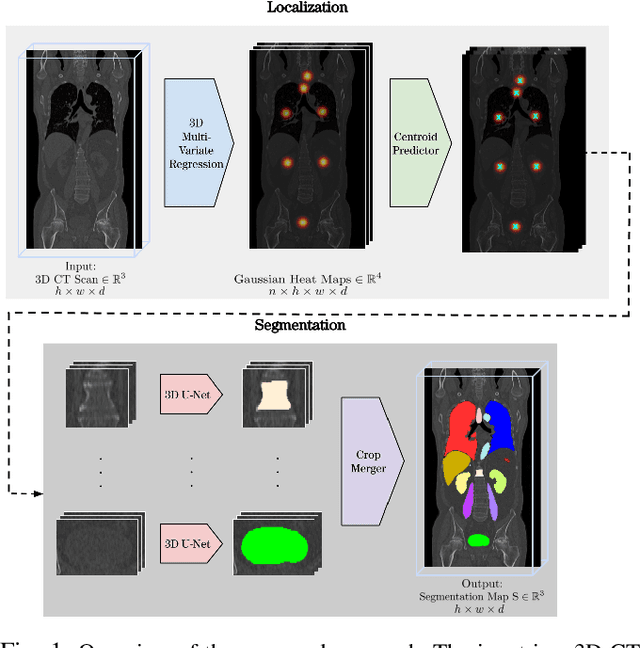
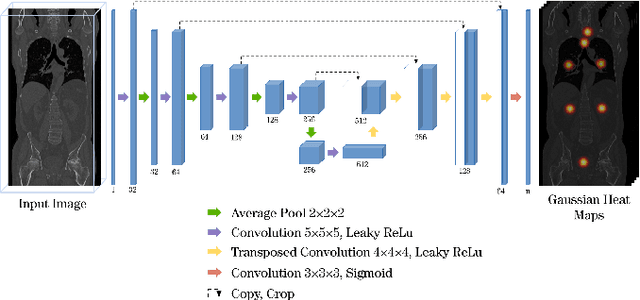
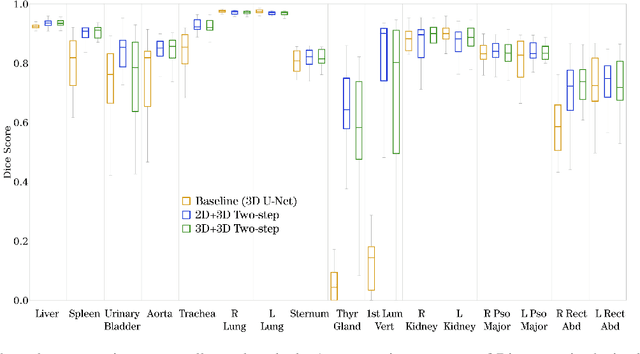
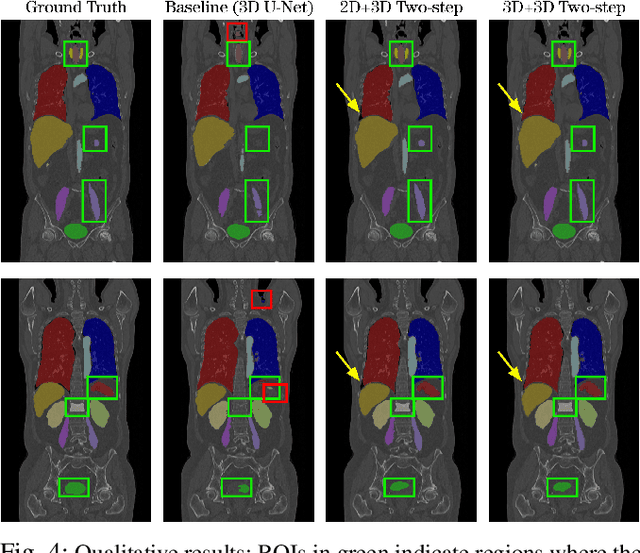
Automatic localization and segmentation of organs-at-risk (OAR) in CT are essential pre-processing steps in medical image analysis tasks, such as radiation therapy planning. For instance, the segmentation of OAR surrounding tumors enables the maximization of radiation to the tumor area without compromising the healthy tissues. However, the current medical workflow requires manual delineation of OAR, which is prone to errors and is annotator-dependent. In this work, we aim to introduce a unified 3D pipeline for OAR localization-segmentation rather than novel localization or segmentation architectures. To the best of our knowledge, our proposed framework fully enables the exploitation of 3D context information inherent in medical imaging. In the first step, a 3D multi-variate regression network predicts organs' centroids and bounding boxes. Secondly, 3D organ-specific segmentation networks are leveraged to generate a multi-organ segmentation map. Our method achieved an overall Dice score of $0.9260\pm 0.18 \%$ on the VISCERAL dataset containing CT scans with varying fields of view and multiple organs.
Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing
Mar 11, 2022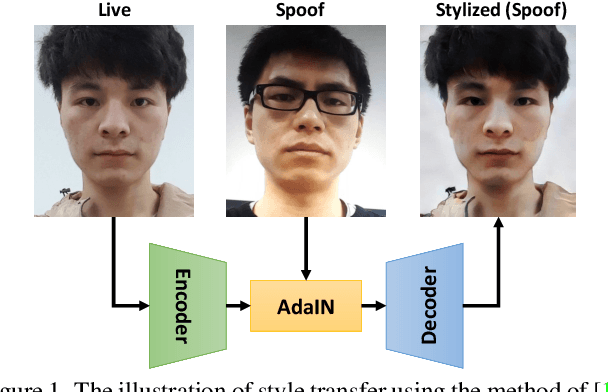
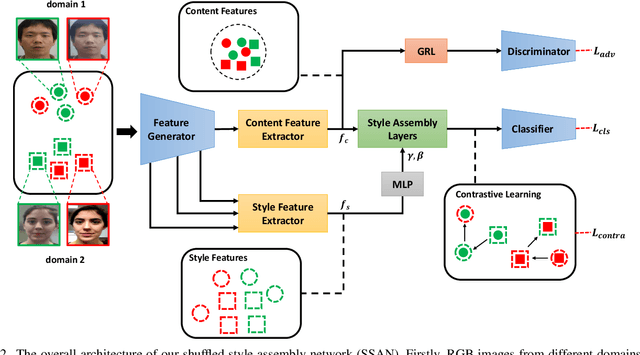
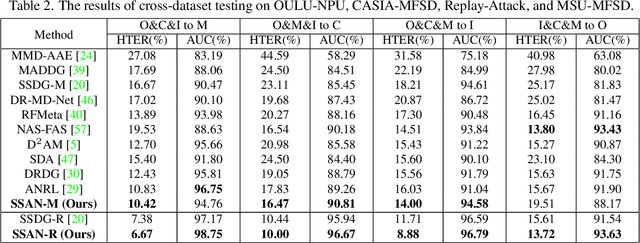
With diverse presentation attacks emerging continually, generalizable face anti-spoofing (FAS) has drawn growing attention. Most existing methods implement domain generalization (DG) on the complete representations. However, different image statistics may have unique properties for the FAS tasks. In this work, we separate the complete representation into content and style ones. A novel Shuffled Style Assembly Network (SSAN) is proposed to extract and reassemble different content and style features for a stylized feature space. Then, to obtain a generalized representation, a contrastive learning strategy is developed to emphasize liveness-related style information while suppress the domain-specific one. Finally, the representations of the correct assemblies are used to distinguish between living and spoofing during the inferring. On the other hand, despite the decent performance, there still exists a gap between academia and industry, due to the difference in data quantity and distribution. Thus, a new large-scale benchmark for FAS is built up to further evaluate the performance of algorithms in reality. Both qualitative and quantitative results on existing and proposed benchmarks demonstrate the effectiveness of our methods. The codes will be available at https://github.com/wangzhuo2019/SSAN.