 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Characterizing the organizational diversity of protein interaction networks across three domains of life
Mar 02, 2022

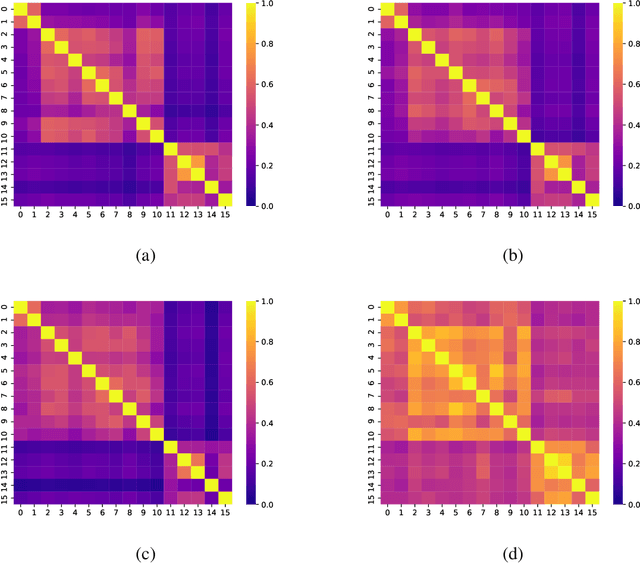
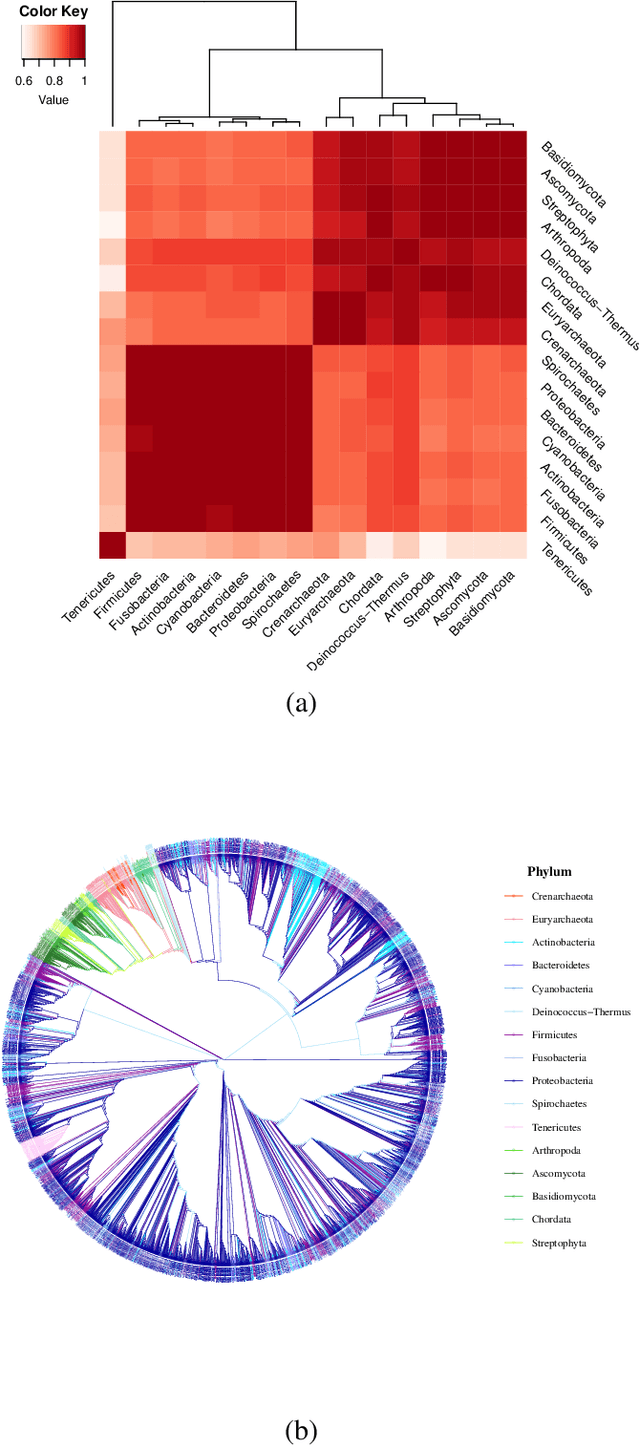
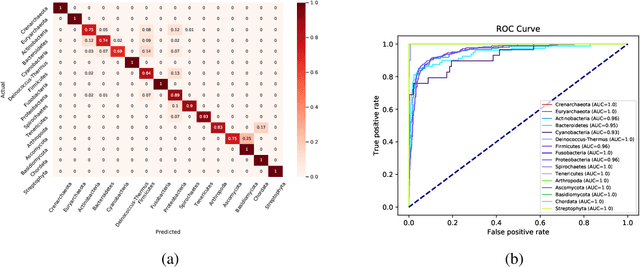
Networks exist everywhere in nature from the physical, chemical, biological or social worlds to the designed spheres. To explore, if there exists some higher-order organization that can be exploited to distinguish different types of networks, we study 4,738 protein interaction networks (PINs) belonging to 16 phyla encompassing all the three domains of life. Our method utilizes positional information of a network's nodes by appropriately normalizing the frequency of automorphic orbits appearing in the induced graphlets of sizes 2-5. There are some evolutionary constraints imposed on the network's topology which shape its local architecture as well as its behavior. According to these rules (features), each type of network occupies its respective position within a common network space. A deep neural network was trained on differentially expressed orbits resulting in a prediction accuracy of 85%. Our results indicate that nature has, probably, allocated a specific band of design space to various superfamilies of PINs.
Leveraging universality of jet taggers through transfer learning
Mar 11, 2022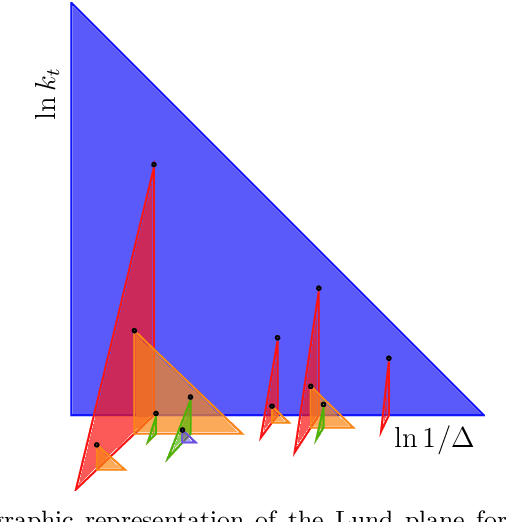
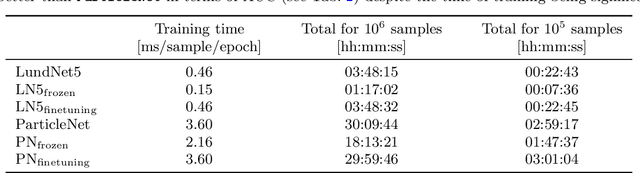
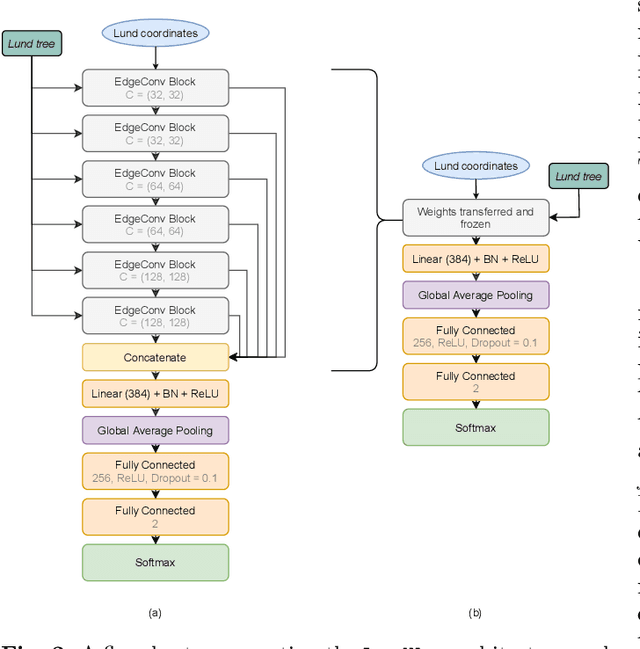

A significant challenge in the tagging of boosted objects via machine-learning technology is the prohibitive computational cost associated with training sophisticated models. Nevertheless, the universality of QCD suggests that a large amount of the information learnt in the training is common to different physical signals and experimental setups. In this article, we explore the use of transfer learning techniques to develop fast and data-efficient jet taggers that leverage such universality. We consider the graph neural networks LundNet and ParticleNet, and introduce two prescriptions to transfer an existing tagger into a new signal based either on fine-tuning all the weights of a model or alternatively on freezing a fraction of them. In the case of $W$-boson and top-quark tagging, we find that one can obtain reliable taggers using an order of magnitude less data with a corresponding speed-up of the training process. Moreover, while keeping the size of the training data set fixed, we observe a speed-up of the training by up to a factor of three. This offers a promising avenue to facilitate the use of such tools in collider physics experiments.
Boosted Ensemble Learning based on Randomized NNs for Time Series Forecasting
Mar 02, 2022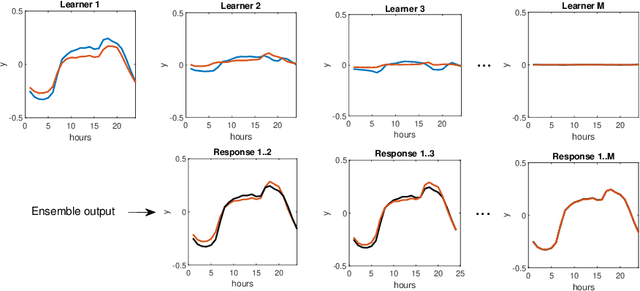
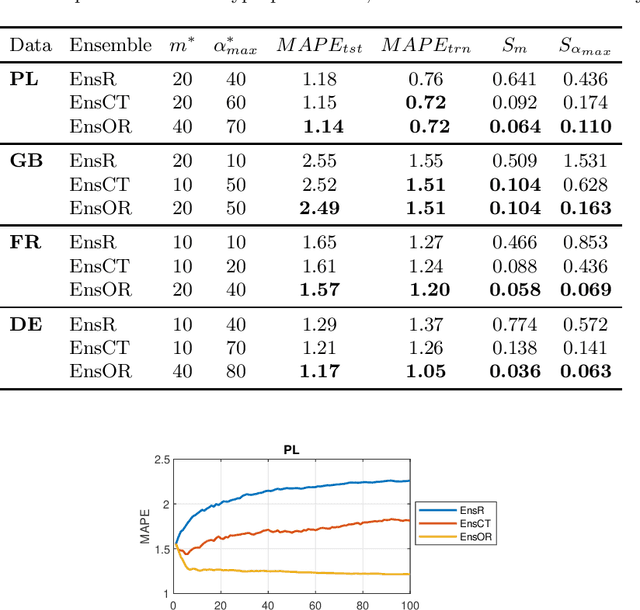
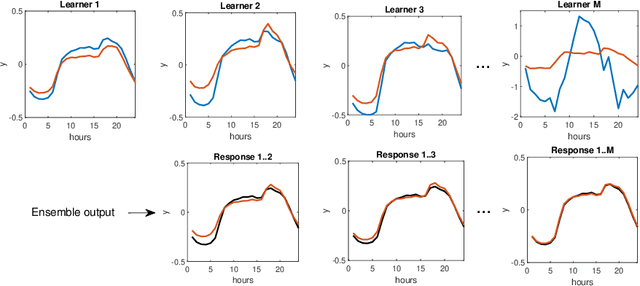
Time series forecasting is a challenging problem particularly when a time series expresses multiple seasonality, nonlinear trend and varying variance. In this work, to forecast complex time series, we propose ensemble learning which is based on randomized neural networks, and boosted in three ways. These comprise ensemble learning based on residuals, corrected targets and opposed response. The latter two methods are employed to ensure similar forecasting tasks are solved by all ensemble members, which justifies the use of exactly the same base models at all stages of ensembling. Unification of the tasks for all members simplifies ensemble learning and leads to increased forecasting accuracy. This was confirmed in an experimental study involving forecasting time series with triple seasonality, in which we compare our three variants of ensemble boosting. The strong points of the proposed ensembles based on RandNNs are extremely rapid training and pattern-based time series representation, which extracts relevant information from time series.
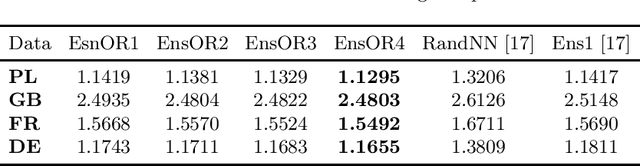
Asymmetric Hash Code Learning for Remote Sensing Image Retrieval
Jan 15, 2022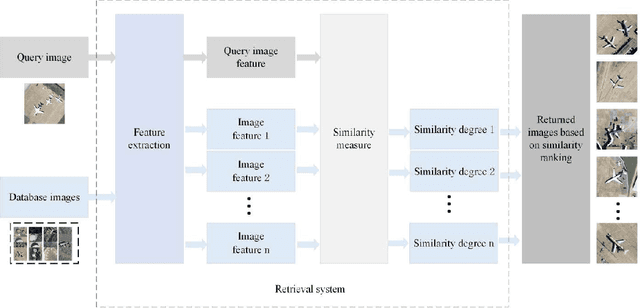
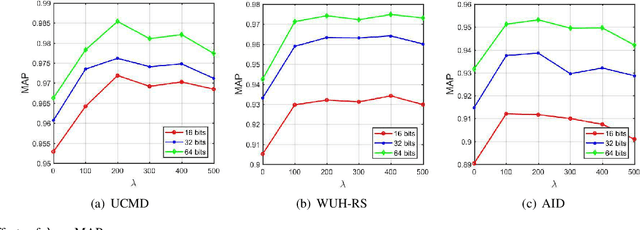
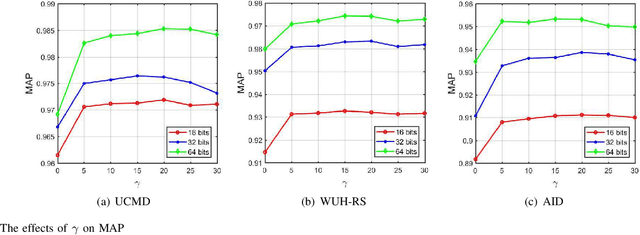
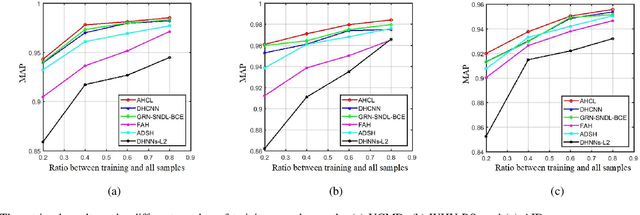
Remote sensing image retrieval (RSIR), aiming at searching for a set of similar items to a given query image, is a very important task in remote sensing applications. Deep hashing learning as the current mainstream method has achieved satisfactory retrieval performance. On one hand, various deep neural networks are used to extract semantic features of remote sensing images. On the other hand, the hashing techniques are subsequently adopted to map the high-dimensional deep features to the low-dimensional binary codes. This kind of methods attempts to learn one hash function for both the query and database samples in a symmetric way. However, with the number of database samples increasing, it is typically time-consuming to generate the hash codes of large-scale database images. In this paper, we propose a novel deep hashing method, named asymmetric hash code learning (AHCL), for RSIR. The proposed AHCL generates the hash codes of query and database images in an asymmetric way. In more detail, the hash codes of query images are obtained by binarizing the output of the network, while the hash codes of database images are directly learned by solving the designed objective function. In addition, we combine the semantic information of each image and the similarity information of pairs of images as supervised information to train a deep hashing network, which improves the representation ability of deep features and hash codes. The experimental results on three public datasets demonstrate that the proposed method outperforms symmetric methods in terms of retrieval accuracy and efficiency. The source code is available at https://github.com/weiweisong415/Demo AHCL for TGRS2022.
Direct Bézier-Based Trajectory Planner for Improved Local Exploration of Unknown Environments
Mar 02, 2022
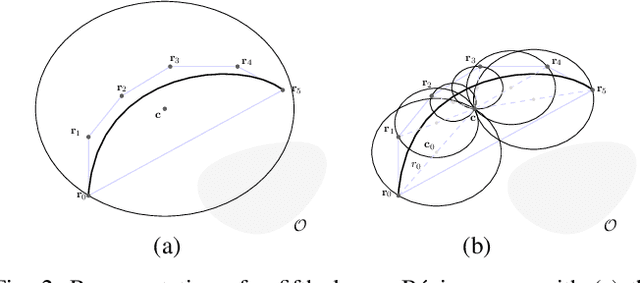

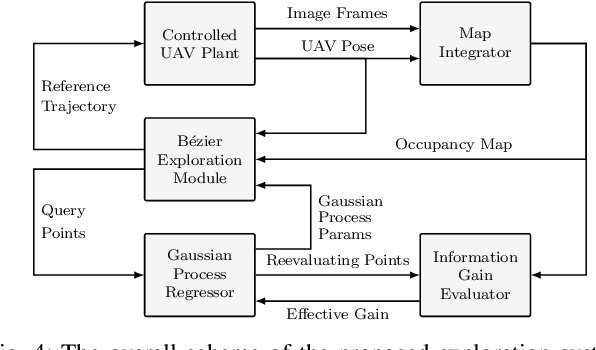
Autonomous exploration is an essential capability for mobile robots, as the majority of their applications require the ability to efficiently collect information about their surroundings. In the literature, there are several approaches, ranging from frontier-based methods to hybrid solutions involving the ability to plan both local and global exploring paths, but only few of them focus on improving local exploration by properly tuning the planned trajectory, often leading to "stop-and-go" like behaviors. In this work we propose a novel RRT-inspired B\'ezier-based next-best-view trajectory planner able to deal with the problem of fast local exploration. Gaussian process inference is used to guarantee fast exploration gain retrieval while still being consistent with the exploration task. The proposed approach is compared with other available state-of-the-art algorithms and tested in a real-world scenario. The implemented code is publicly released as open-source code to encourage further developments and benchmarking.
Personalized Execution Time Optimization for the Scheduled Jobs
Mar 11, 2022
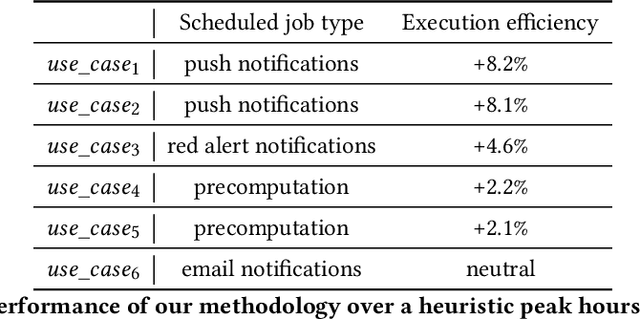
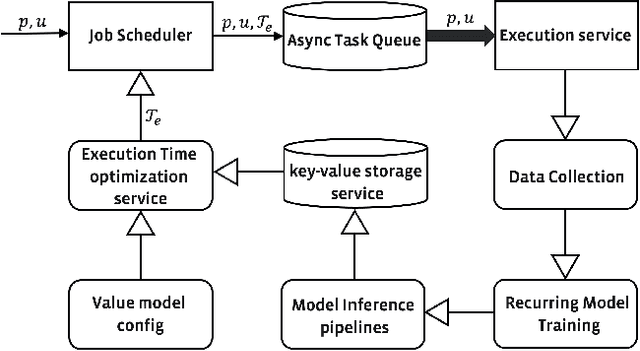

Scheduled batch jobs have been widely used on the asynchronous computing platforms to execute various enterprise applications, including the scheduled notifications and the candidate computation for the modern recommender systems. It is important to deliver or update the information to the users at the right time to maintain the user experience and the execution impact. However, it is challenging to provide a versatile execution time optimization solution for the user-basis scheduled jobs to satisfy various product scenarios while maintaining reasonable infrastructure resource consumption. In this paper, we describe how we apply a pointwise learning-to-rank approach plus a "best time policy" in the best time selection. In addition, we propose a value model approach to efficiently leverage multiple streams of user activity signals in our scheduling decisions of the execution time. Our optimization approach has been successfully tested with production traffic that serves billions of users per day, with statistically significant improvements in various product metrics, including the notifications and content candidate generation. To the best of our knowledge, our study represents the first ML-based multi-tenant solution to the execution time optimization problem for the scheduled jobs at a large industrial scale.
ES-dRNN with Dynamic Attention for Short-Term Load Forecasting
Mar 02, 2022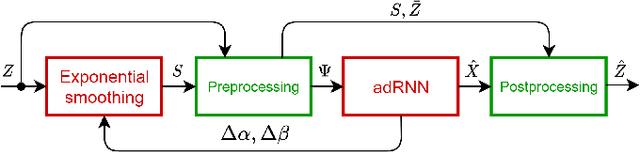
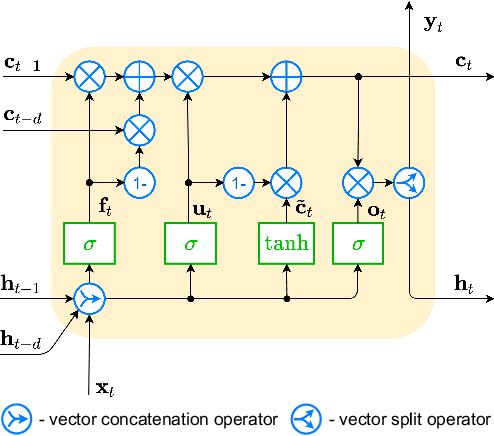
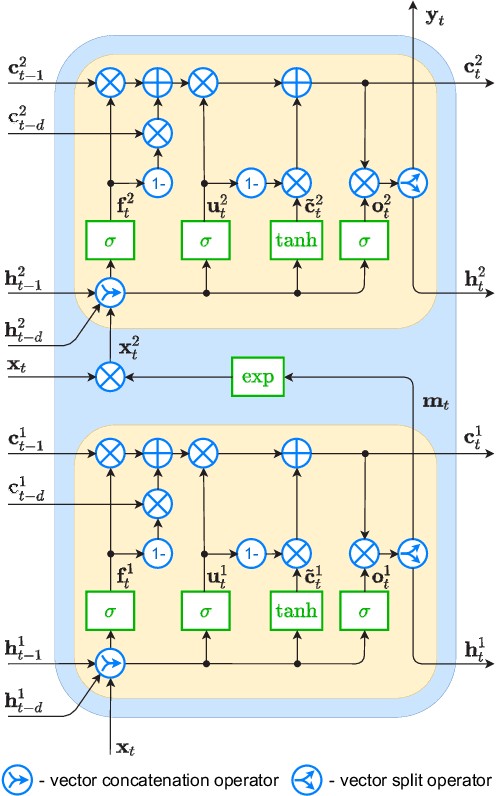
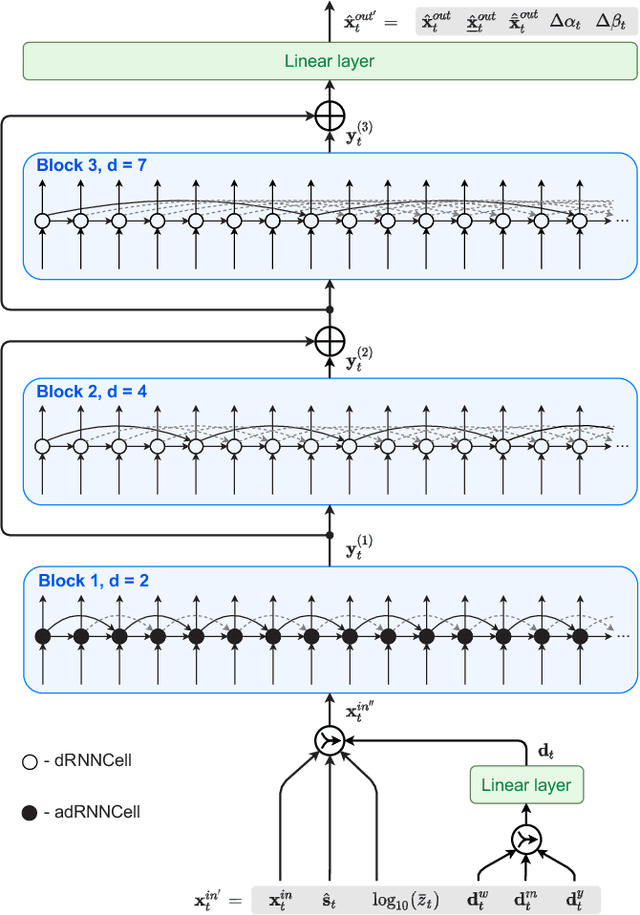
Short-term load forecasting (STLF) is a challenging problem due to the complex nature of the time series expressing multiple seasonality and varying variance. This paper proposes an extension of a hybrid forecasting model combining exponential smoothing and dilated recurrent neural network (ES-dRNN) with a mechanism for dynamic attention. We propose a new gated recurrent cell -- attentive dilated recurrent cell, which implements an attention mechanism for dynamic weighting of input vector components. The most relevant components are assigned greater weights, which are subsequently dynamically fine-tuned. This attention mechanism helps the model to select input information and, along with other mechanisms implemented in ES-dRNN, such as adaptive time series processing, cross-learning, and multiple dilation, leads to a significant improvement in accuracy when compared to well-established statistical and state-of-the-art machine learning forecasting models. This was confirmed in the extensive experimental study concerning STLF for 35 European countries.
Interpretable Prediction of Lung Squamous Cell Carcinoma Recurrence With Self-supervised Learning
Mar 23, 2022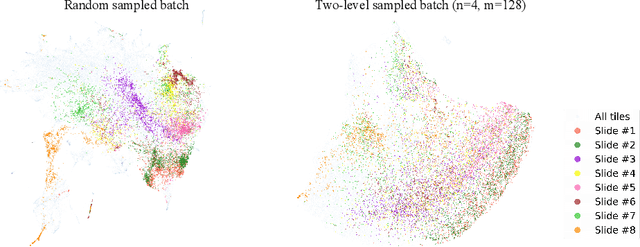
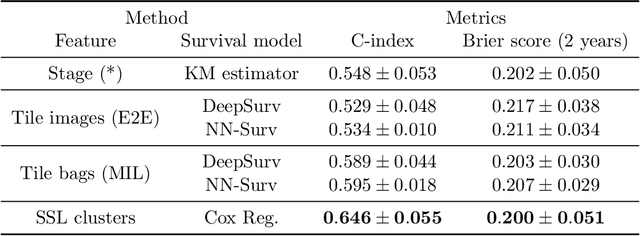
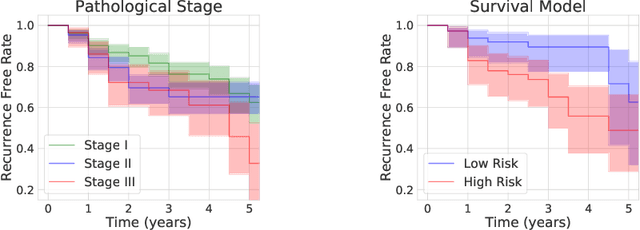

Lung squamous cell carcinoma (LSCC) has a high recurrence and metastasis rate. Factors influencing recurrence and metastasis are currently unknown and there are no distinct histopathological or morphological features indicating the risks of recurrence and metastasis in LSCC. Our study focuses on the recurrence prediction of LSCC based on H&E-stained histopathological whole-slide images (WSI). Due to the small size of LSCC cohorts in terms of patients with available recurrence information, standard end-to-end learning with various convolutional neural networks for this task tends to overfit. Also, the predictions made by these models are hard to interpret. Histopathology WSIs are typically very large and are therefore processed as a set of smaller tiles. In this work, we propose a novel conditional self-supervised learning (SSL) method to learn representations of WSI at the tile level first, and leverage clustering algorithms to identify the tiles with similar histopathological representations. The resulting representations and clusters from self-supervision are used as features of a survival model for recurrence prediction at the patient level. Using two publicly available datasets from TCGA and CPTAC, we show that our LSCC recurrence prediction survival model outperforms both LSCC pathological stage-based approach and machine learning baselines such as multiple instance learning. The proposed method also enables us to explain the recurrence histopathological risk factors via the derived clusters. This can help pathologists derive new hypotheses regarding morphological features associated with LSCC recurrence.
Improving Disentangled Text Representation Learning with Information-Theoretic Guidance
Jun 06, 2020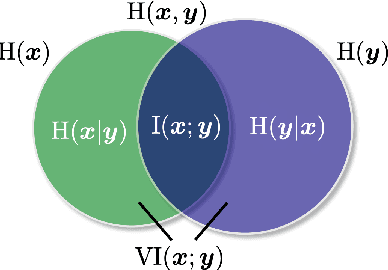
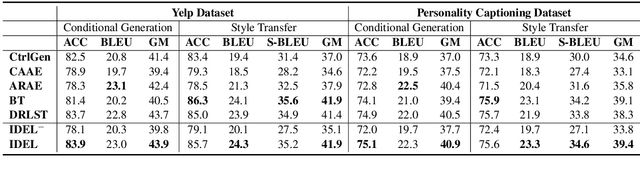
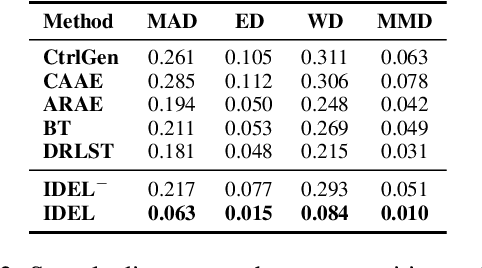
Learning disentangled representations of natural language is essential for many NLP tasks, e.g., conditional text generation, style transfer, personalized dialogue systems, etc. Similar problems have been studied extensively for other forms of data, such as images and videos. However, the discrete nature of natural language makes the disentangling of textual representations more challenging (e.g., the manipulation over the data space cannot be easily achieved). Inspired by information theory, we propose a novel method that effectively manifests disentangled representations of text, without any supervision on semantics. A new mutual information upper bound is derived and leveraged to measure dependence between style and content. By minimizing this upper bound, the proposed method induces style and content embeddings into two independent low-dimensional spaces. Experiments on both conditional text generation and text-style transfer demonstrate the high quality of our disentangled representation in terms of content and style preservation.
Mitigating Misinformation Spread on Blockchain Enabled Social Media Networks
Feb 09, 2022
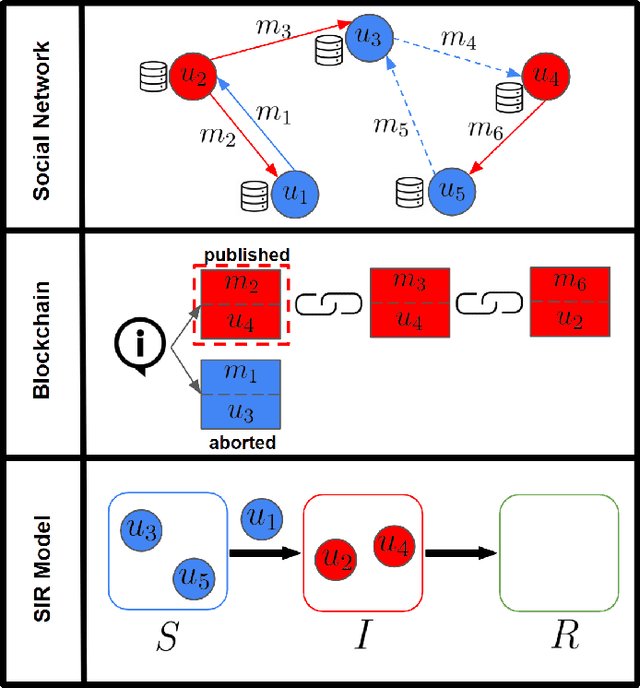
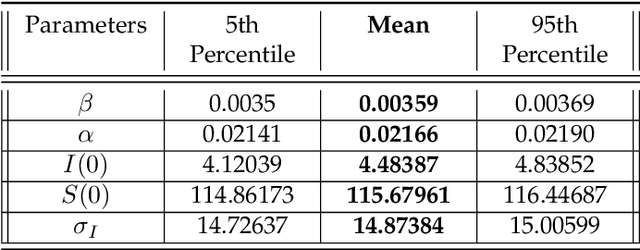
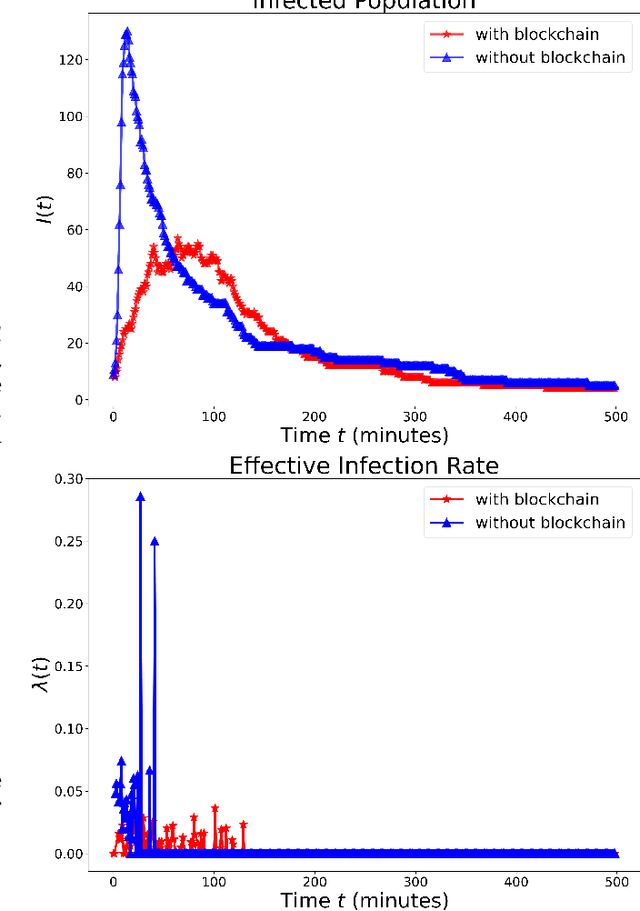
The paper develops a blockchain protocol for a social media network (BE-SMN) to mitigate the spread of misinformation. BE-SMN is derived based on the information transmission-time distribution by modeling the misinformation transmission as double-spend attacks on blockchain. The misinformation distribution is then incorporated into the SIR (Susceptible, Infectious, or Recovered) model, which substitutes the single rate parameter in the traditional SIR model. Then, on a multi-community network, we study the propagation of misinformation numerically and show that the proposed blockchain enabled social media network outperforms the baseline network in flattening the curve of the infected population.