 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Compositional Atlas of Tractable Circuit Operations: From Simple Transformations to Complex Information-Theoretic Queries
Feb 11, 2021
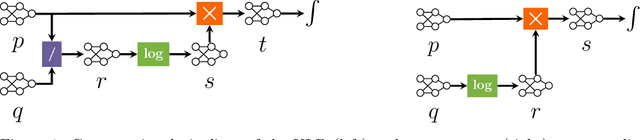

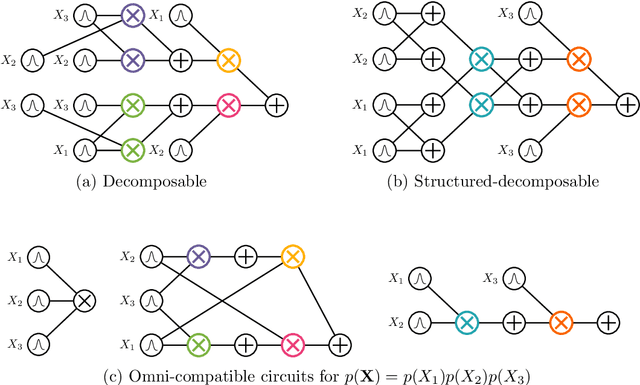
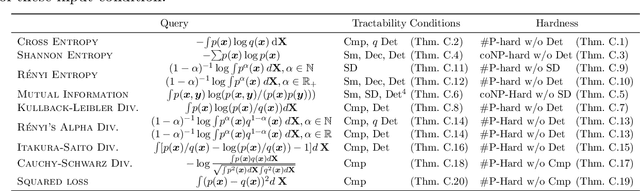
Circuit representations are becoming the lingua franca to express and reason about tractable generative and discriminative models. In this paper, we show how complex inference scenarios for these models that commonly arise in machine learning -- from computing the expectations of decision tree ensembles to information-theoretic divergences of deep mixture models -- can be represented in terms of tractable modular operations over circuits. Specifically, we characterize the tractability of a vocabulary of simple transformations -- sums, products, quotients, powers, logarithms, and exponentials -- in terms of sufficient structural constraints of the circuits they operate on, and present novel hardness results for the cases in which these properties are not satisfied. Building on these operations, we derive a unified framework for reasoning about tractable models that generalizes several results in the literature and opens up novel tractable inference scenarios.
Neural Architecture Search for Spiking Neural Networks
Jan 23, 2022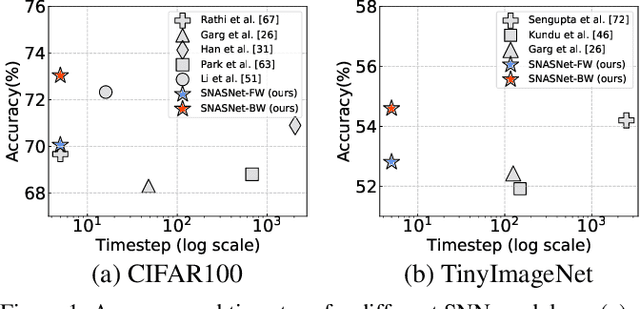
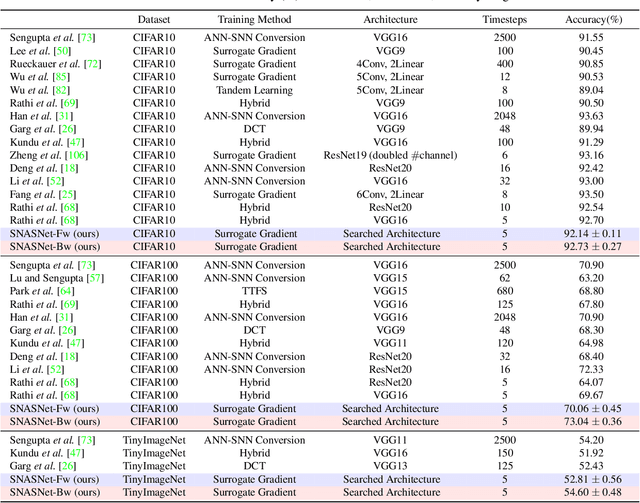
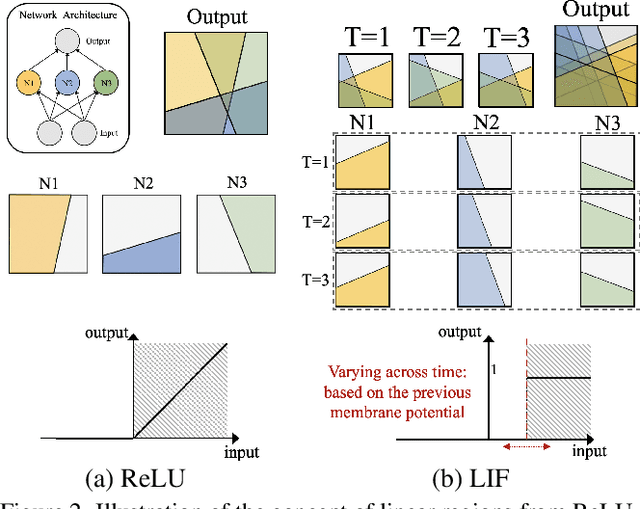
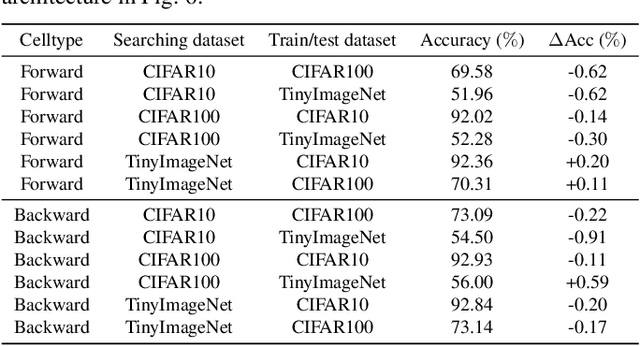
Spiking Neural Networks (SNNs) have gained huge attention as a potential energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their inherent high-sparsity activation. However, most prior SNN methods use ANN-like architectures (e.g., VGG-Net or ResNet), which could provide sub-optimal performance for temporal sequence processing of binary information in SNNs. To address this, in this paper, we introduce a novel Neural Architecture Search (NAS) approach for finding better SNN architectures. Inspired by recent NAS approaches that find the optimal architecture from activation patterns at initialization, we select the architecture that can represent diverse spike activation patterns across different data samples without training. Furthermore, to leverage the temporal correlation among the spikes, we search for feed forward connections as well as backward connections (i.e., temporal feedback connections) between layers. Interestingly, SNASNet found by our search algorithm achieves higher performance with backward connections, demonstrating the importance of designing SNN architecture for suitably using temporal information. We conduct extensive experiments on three image recognition benchmarks where we show that SNASNet achieves state-of-the-art performance with significantly lower timesteps (5 timesteps).
Self-supervised HDR Imaging from Motion and Exposure Cues
Mar 23, 2022
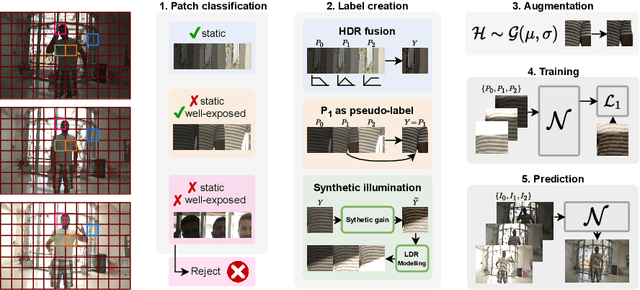
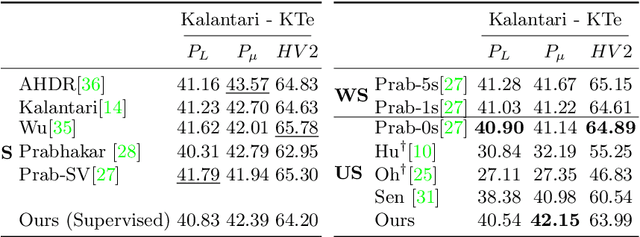
Recent High Dynamic Range (HDR) techniques extend the capabilities of current cameras where scenes with a wide range of illumination can not be accurately captured with a single low-dynamic-range (LDR) image. This is generally accomplished by capturing several LDR images with varying exposure values whose information is then incorporated into a merged HDR image. While such approaches work well for static scenes, dynamic scenes pose several challenges, mostly related to the difficulty of finding reliable pixel correspondences. Data-driven approaches tackle the problem by learning an end-to-end mapping with paired LDR-HDR training data, but in practice generating such HDR ground-truth labels for dynamic scenes is time-consuming and requires complex procedures that assume control of certain dynamic elements of the scene (e.g. actor pose) and repeatable lighting conditions (stop-motion capturing). In this work, we propose a novel self-supervised approach for learnable HDR estimation that alleviates the need for HDR ground-truth labels. We propose to leverage the internal statistics of LDR images to create HDR pseudo-labels. We separately exploit static and well-exposed parts of the input images, which in conjunction with synthetic illumination clipping and motion augmentation provide high quality training examples. Experimental results show that the HDR models trained using our proposed self-supervision approach achieve performance competitive with those trained under full supervision, and are to a large extent superior to previous methods that equally do not require any supervision.
Model-agnostic out-of-distribution detection using combined statistical tests
Mar 02, 2022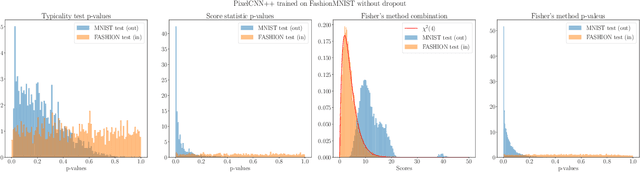
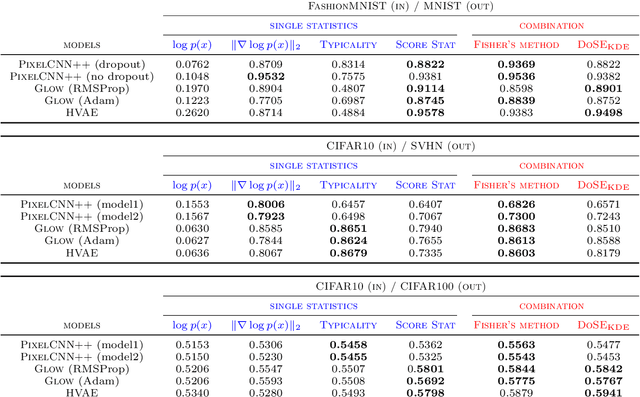
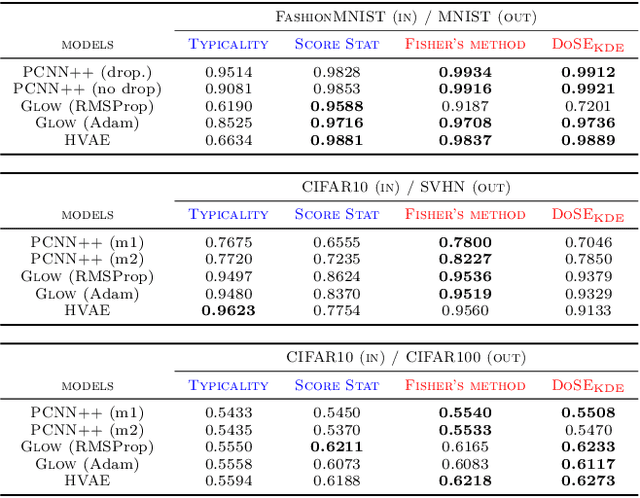
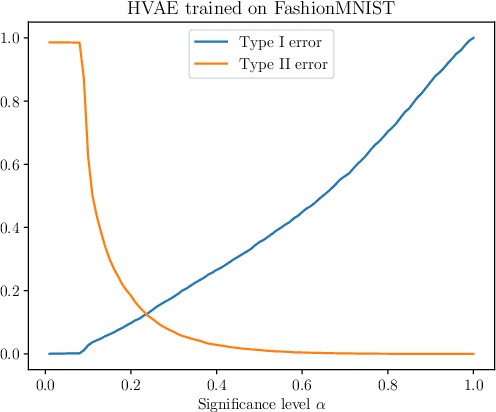
We present simple methods for out-of-distribution detection using a trained generative model. These techniques, based on classical statistical tests, are model-agnostic in the sense that they can be applied to any differentiable generative model. The idea is to combine a classical parametric test (Rao's score test) with the recently introduced typicality test. These two test statistics are both theoretically well-founded and exploit different sources of information based on the likelihood for the typicality test and its gradient for the score test. We show that combining them using Fisher's method overall leads to a more accurate out-of-distribution test. We also discuss the benefits of casting out-of-distribution detection as a statistical testing problem, noting in particular that false positive rate control can be valuable for practical out-of-distribution detection. Despite their simplicity and generality, these methods can be competitive with model-specific out-of-distribution detection algorithms without any assumptions on the out-distribution.
NavDreams: Towards Camera-Only RL Navigation Among Humans
Mar 23, 2022
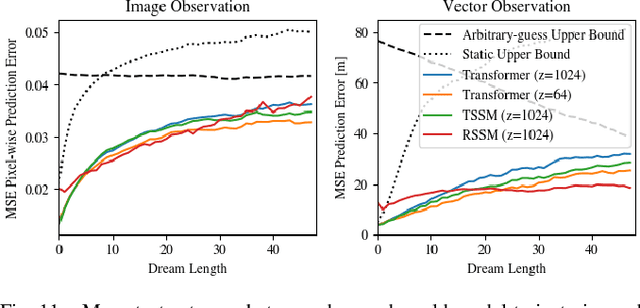
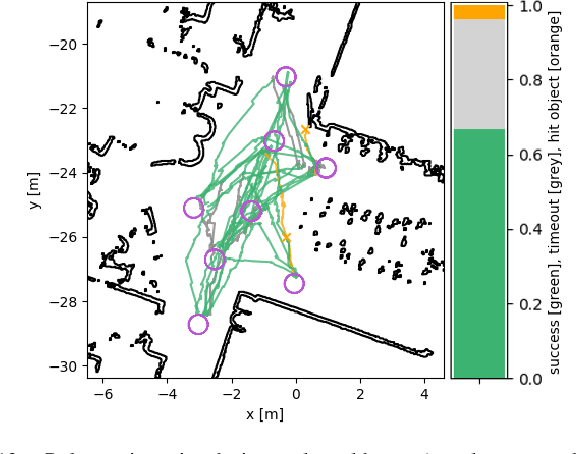
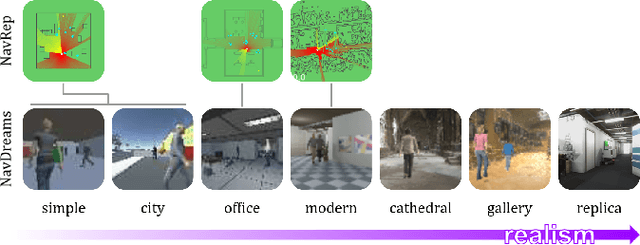
Autonomously navigating a robot in everyday crowded spaces requires solving complex perception and planning challenges. When using only monocular image sensor data as input, classical two-dimensional planning approaches cannot be used. While images present a significant challenge when it comes to perception and planning, they also allow capturing potentially important details, such as complex geometry, body movement, and other visual cues. In order to successfully solve the navigation task from only images, algorithms must be able to model the scene and its dynamics using only this channel of information. We investigate whether the world model concept, which has shown state-of-the-art results for modeling and learning policies in Atari games as well as promising results in 2D LiDAR-based crowd navigation, can also be applied to the camera-based navigation problem. To this end, we create simulated environments where a robot must navigate past static and moving humans without colliding in order to reach its goal. We find that state-of-the-art methods are able to achieve success in solving the navigation problem, and can generate dream-like predictions of future image-sequences which show consistent geometry and moving persons. We are also able to show that policy performance in our high-fidelity sim2real simulation scenario transfers to the real world by testing the policy on a real robot. We make our simulator, models and experiments available at https://github.com/danieldugas/NavDreams.
Semantic Annotation and Querying Framework based on Semi-structured Ayurvedic Text
Feb 01, 2022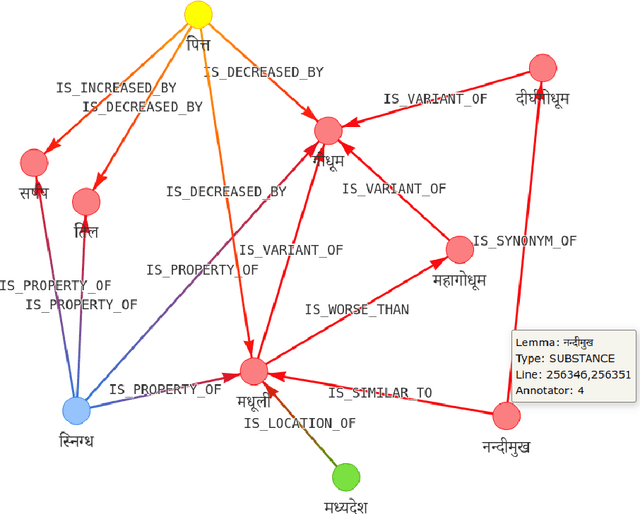

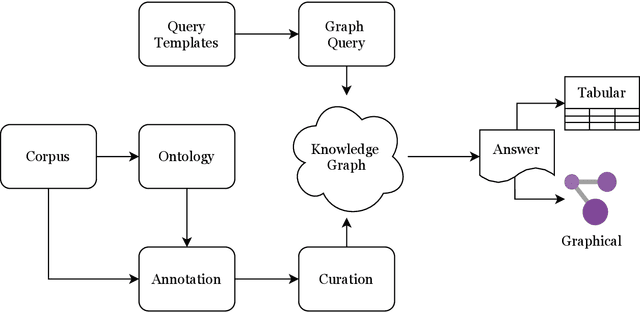

Knowledge bases (KB) are an important resource in a number of natural language processing (NLP) and information retrieval (IR) tasks, such as semantic search, automated question-answering etc. They are also useful for researchers trying to gain information from a text. Unfortunately, however, the state-of-the-art in Sanskrit NLP does not yet allow automated construction of knowledge bases due to unavailability or lack of sufficient accuracy of tools and methods. Thus, in this work, we describe our efforts on manual annotation of Sanskrit text for the purpose of knowledge graph (KG) creation. We choose the chapter Dhanyavarga from Bhavaprakashanighantu of the Ayurvedic text Bhavaprakasha for annotation. The constructed knowledge graph contains 410 entities and 764 relationships. Since Bhavaprakashanighantu is a technical glossary text that describes various properties of different substances, we develop an elaborate ontology to capture the semantics of the entity and relationship types present in the text. To query the knowledge graph, we design 31 query templates that cover most of the common question patterns. For both manual annotation and querying, we customize the Sangrahaka framework previously developed by us. The entire system including the dataset is available from https://sanskrit.iitk.ac.in/ayurveda/ . We hope that the knowledge graph that we have created through manual annotation and subsequent curation will help in development and testing of NLP tools in future as well as studying of the Bhavaprakasanighantu text.
* 19 pages including appendix
Unsupervised Anomaly Detection from Time-of-Flight Depth Images
Mar 02, 2022

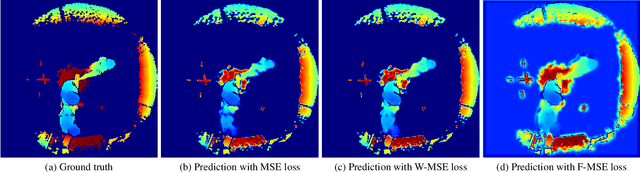
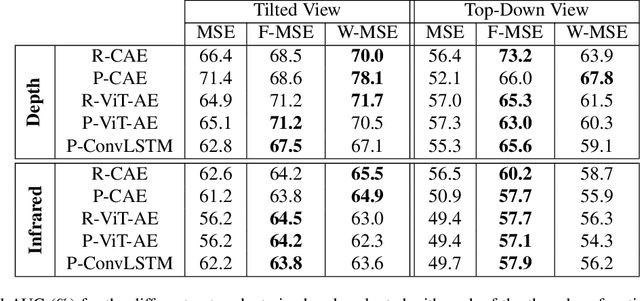
Video anomaly detection (VAD) addresses the problem of automatically finding anomalous events in video data. The primary data modalities on which current VAD systems work on are monochrome or RGB images. Using depth data in this context instead is still hardly explored in spite of depth images being a popular choice in many other computer vision research areas and the increasing availability of inexpensive depth camera hardware. We evaluate the application of existing autoencoder-based methods on depth video and propose how the advantages of using depth data can be leveraged by integration into the loss function. Training is done unsupervised using normal sequences without need for any additional annotations. We show that depth allows easy extraction of auxiliary information for scene analysis in the form of a foreground mask and demonstrate its beneficial effect on the anomaly detection performance through evaluation on a large public dataset, for which we are also the first ones to present results on.
Generalized Spectral Clustering for Directed and Undirected Graphs
Mar 07, 2022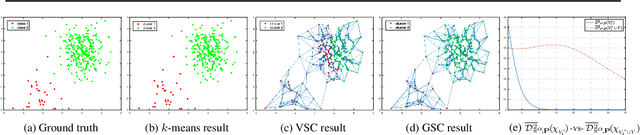
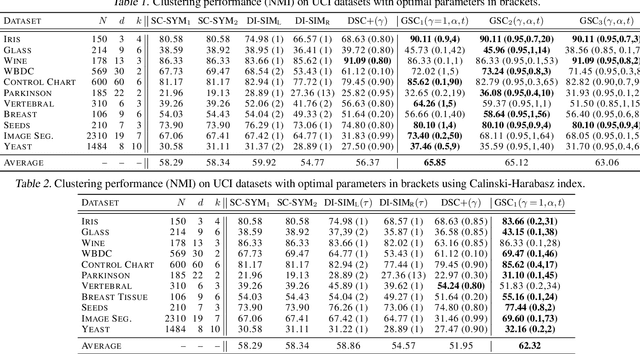
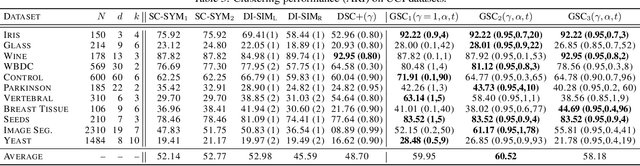
Spectral clustering is a popular approach for clustering undirected graphs, but its extension to directed graphs (digraphs) is much more challenging. A typical workaround is to naively symmetrize the adjacency matrix of the directed graph, which can however lead to discarding valuable information carried by edge directionality. In this paper, we present a generalized spectral clustering framework that can address both directed and undirected graphs. Our approach is based on the spectral relaxation of a new functional that we introduce as the generalized Dirichlet energy of a graph function, with respect to an arbitrary positive regularizing measure on the graph edges. We also propose a practical parametrization of the regularizing measure constructed from the iterated powers of the natural random walk on the graph. We present theoretical arguments to explain the efficiency of our framework in the challenging setting of unbalanced classes. Experiments using directed K-NN graphs constructed from real datasets show that our graph partitioning method performs consistently well in all cases, while outperforming existing approaches in most of them.
Wavelet-Attention CNN for Image Classification
Jan 23, 2022

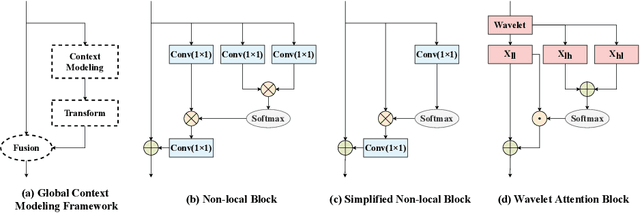

The feature learning methods based on convolutional neural network (CNN) have successfully produced tremendous achievements in image classification tasks. However, the inherent noise and some other factors may weaken the effectiveness of the convolutional feature statistics. In this paper, we investigate Discrete Wavelet Transform (DWT) in the frequency domain and design a new Wavelet-Attention (WA) block to only implement attention in the high-frequency domain. Based on this, we propose a Wavelet-Attention convolutional neural network (WA-CNN) for image classification. Specifically, WA-CNN decomposes the feature maps into low-frequency and high-frequency components for storing the structures of the basic objects, as well as the detailed information and noise, respectively. Then, the WA block is leveraged to capture the detailed information in the high-frequency domain with different attention factors but reserves the basic object structures in the low-frequency domain. Experimental results on CIFAR-10 and CIFAR-100 datasets show that our proposed WA-CNN achieves significant improvements in classification accuracy compared to other related networks. Specifically, based on MobileNetV2 backbones, WA-CNN achieves 1.26% Top-1 accuracy improvement on the CIFAR-10 benchmark and 1.54% Top-1 accuracy improvement on the CIFAR-100 benchmark.
Cross-lingual Information Retrieval with BERT
Apr 24, 2020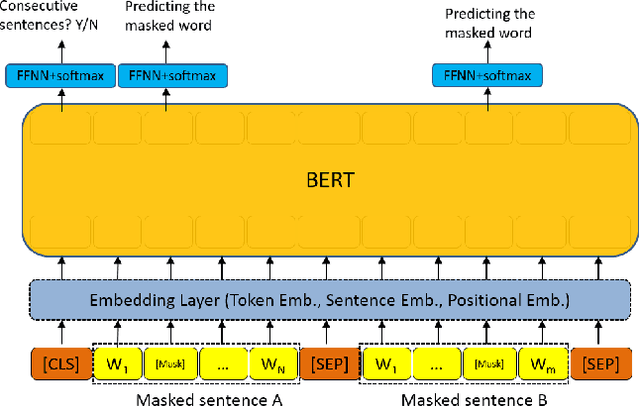

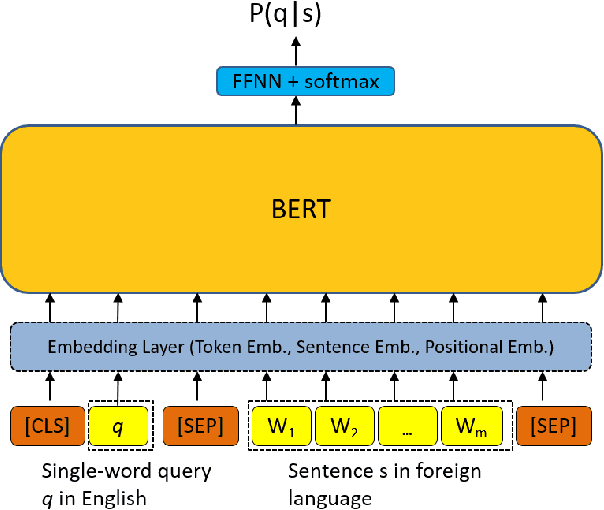
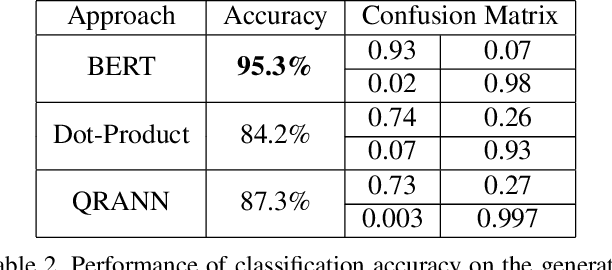
Multiple neural language models have been developed recently, e.g., BERT and XLNet, and achieved impressive results in various NLP tasks including sentence classification, question answering and document ranking. In this paper, we explore the use of the popular bidirectional language model, BERT, to model and learn the relevance between English queries and foreign-language documents in the task of cross-lingual information retrieval. A deep relevance matching model based on BERT is introduced and trained by finetuning a pretrained multilingual BERT model with weak supervision, using home-made CLIR training data derived from parallel corpora. Experimental results of the retrieval of Lithuanian documents against short English queries show that our model is effective and outperforms the competitive baseline approaches.