 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Survival of the strictest: Stable and unstable equilibria under regularized learning with partial information
Feb 04, 2021
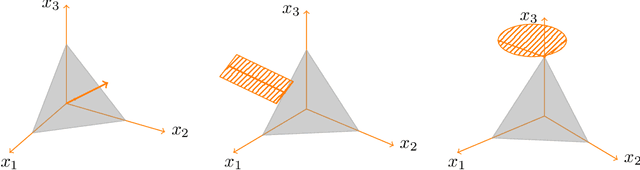
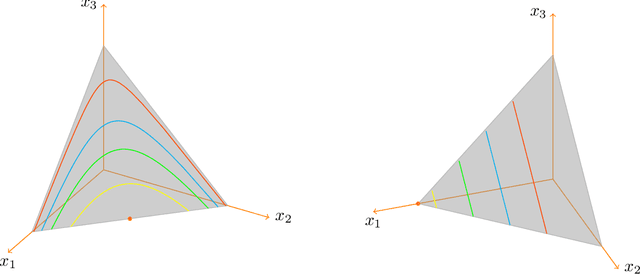
In this paper, we examine the Nash equilibrium convergence properties of no-regret learning in general N-player games. For concreteness, we focus on the archetypal follow the regularized leader (FTRL) family of algorithms, and we consider the full spectrum of uncertainty that the players may encounter - from noisy, oracle-based feedback, to bandit, payoff-based information. In this general context, we establish a comprehensive equivalence between the stability of a Nash equilibrium and its support: a Nash equilibrium is stable and attracting with arbitrarily high probability if and only if it is strict (i.e., each equilibrium strategy has a unique best response). This equivalence extends existing continuous-time versions of the folk theorem of evolutionary game theory to a bona fide algorithmic learning setting, and it provides a clear refinement criterion for the prediction of the day-to-day behavior of no-regret learning in games
A 3D Molecule Generative Model for Structure-Based Drug Design
Mar 20, 2022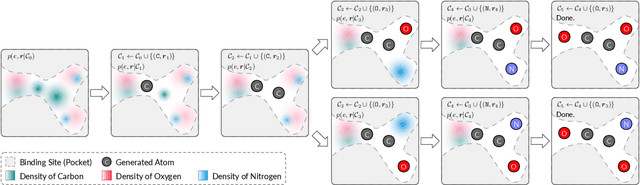
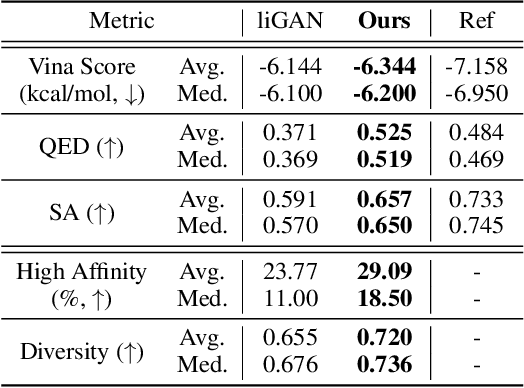
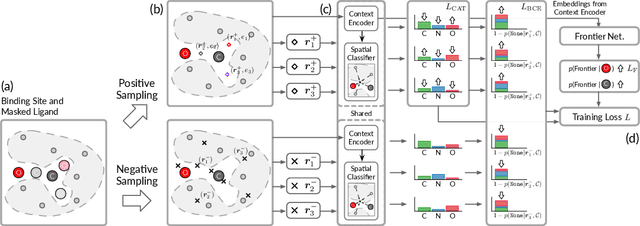
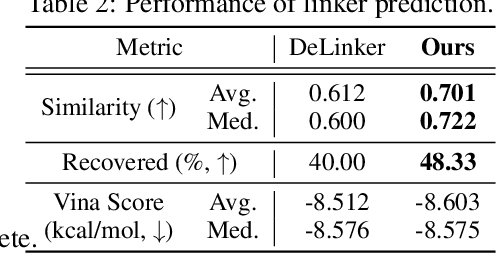
We study a fundamental problem in structure-based drug design -- generating molecules that bind to specific protein binding sites. While we have witnessed the great success of deep generative models in drug design, the existing methods are mostly string-based or graph-based. They are limited by the lack of spatial information and thus unable to be applied to structure-based design tasks. Particularly, such models have no or little knowledge of how molecules interact with their target proteins exactly in 3D space. In this paper, we propose a 3D generative model that generates molecules given a designated 3D protein binding site. Specifically, given a binding site as the 3D context, our model estimates the probability density of atom's occurrences in 3D space -- positions that are more likely to have atoms will be assigned higher probability. To generate 3D molecules, we propose an auto-regressive sampling scheme -- atoms are sampled sequentially from the learned distribution until there is no room for new atoms. Combined with this sampling scheme, our model can generate valid and diverse molecules, which could be applicable to various structure-based molecular design tasks such as molecule sampling and linker design. Experimental results demonstrate that molecules sampled from our model exhibit high binding affinity to specific targets and good drug properties such as drug-likeness even if the model is not explicitly optimized for them.
Structurally Diverse Sampling Reduces Spurious Correlations in Semantic Parsing Datasets
Mar 16, 2022
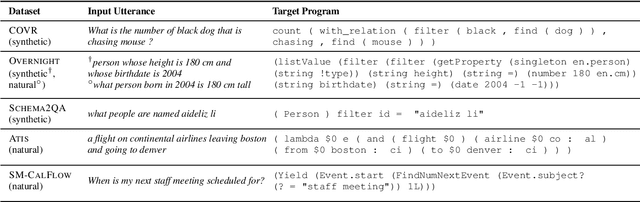
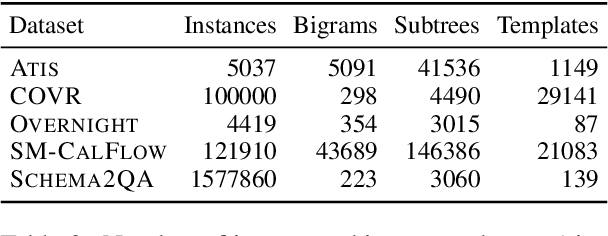
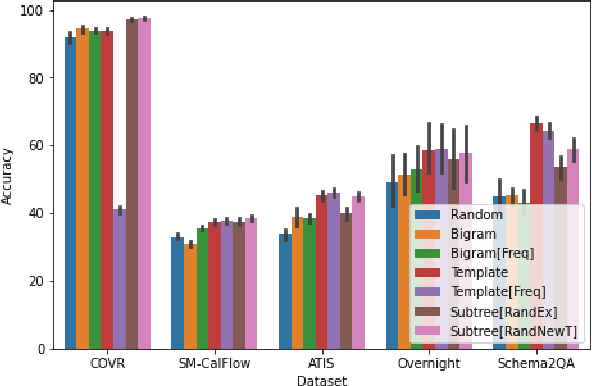
A rapidly growing body of research has demonstrated the inability of NLP models to generalize compositionally and has tried to alleviate it through specialized architectures, training schemes, and data augmentation, among other approaches. In this work, we study a different relatively under-explored approach: sampling diverse train sets that encourage compositional generalization. We propose a novel algorithm for sampling a structurally diverse set of instances from a labeled instance pool with structured outputs. Evaluating on 5 semantic parsing datasets of varying complexity, we show that our algorithm performs competitively with or better than prior algorithms in not only compositional template splits but also traditional IID splits of all but the least structurally diverse datasets. In general, we find that diverse train sets lead to better generalization than random training sets of the same size in 9 out of 10 dataset-split pairs, with over 10% absolute improvement in 5, providing further evidence to their sample efficiency. Moreover, we show that structural diversity also makes for more comprehensive test sets that require diverse training to succeed on. Finally, we use information theory to show that reduction in spurious correlations between substructures may be one reason why diverse training sets improve generalization.
Gaussian Imagination in Bandit Learning
Jan 06, 2022
Assuming distributions are Gaussian often facilitates computations that are otherwise intractable. We consider an agent who is designed to attain a low information ratio with respect to a bandit environment with a Gaussian prior distribution and a Gaussian likelihood function, but study the agent's performance when applied instead to a Bernoulli bandit. We establish a bound on the increase in Bayesian regret when an agent interacts with the Bernoulli bandit, relative to an information-theoretic bound satisfied with the Gaussian bandit. If the Gaussian prior distribution and likelihood function are sufficiently diffuse, this increase grows with the square-root of the time horizon, and thus the per-timestep increase vanishes. Our results formalize the folklore that so-called Bayesian agents remain effective when instantiated with diffuse misspecified distributions.
Active Bayesian Multi-class Mapping from Range and Semantic Segmentation Observations
Dec 08, 2021
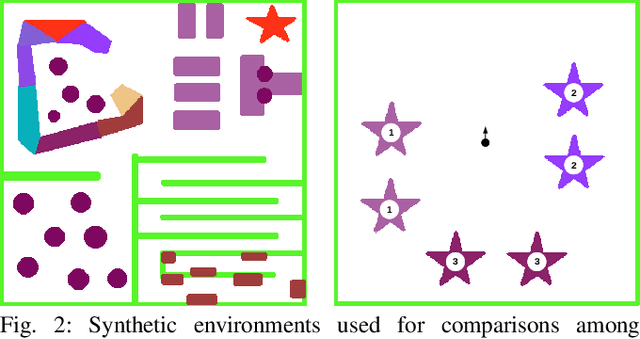
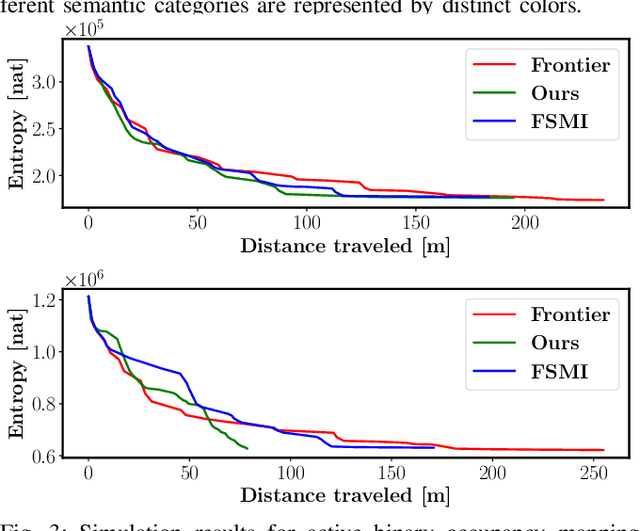
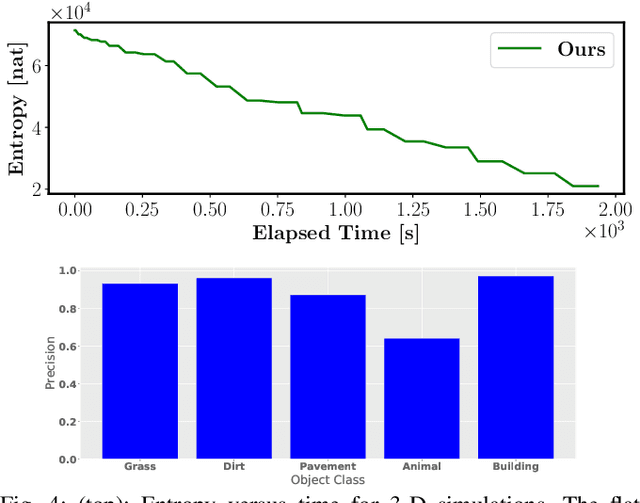
The demand for robot exploration in unstructured and unknown environments has recently grown substantially thanks to the host of inexpensive sensing and edge-computing solutions. In order to come closer to full autonomy, robots need to process the measurement stream in real-time, which calls for efficient exploration strategies. Information-based exploration techniques, such as Cauchy-Schwarz quadratic mutual information (CSQMI) and fast Shannon mutual information (FSMI), have successfully achieved active binary occupancy mapping with range measurements. However, as we envision robots performing complex tasks specified with semantically meaningful objects, it is necessary to capture semantic categories in the measurements, map representation, and exploration objective. In this work we propose a Bayesian multi-class mapping algorithm utilizing range-category measurements, as well as a closed-form efficiently computable lower bound for the Shannon mutual information between the multi-class map and the measurements. The bound allows rapid evaluation of many potential robot trajectories for autonomous exploration and mapping. Furthermore, we develop a compressed representation of 3-D environments with semantic labels based on OcTree data structure, where each voxel maintains a categorical distribution over object classes. The proposed 3-D representation facilitates fast computation of Shannon mutual information between the semantic Octomap and the measurements using Run-Length Encoding (RLE) of range-category observation rays. We compare our method against frontier-based and FSMI exploration and apply it in a variety of simulated and real-world experiments.
CTDS: Centralized Teacher with Decentralized Student for Multi-Agent Reinforcement Learning
Mar 16, 2022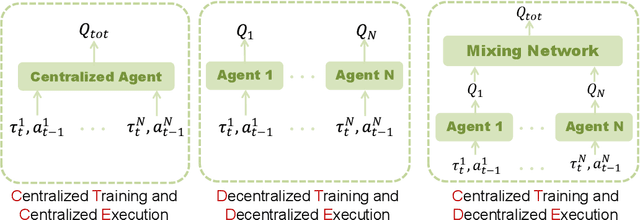
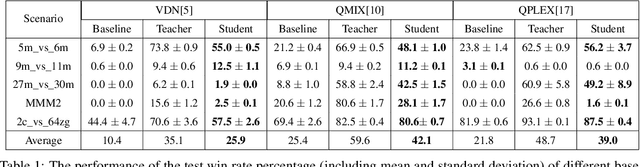
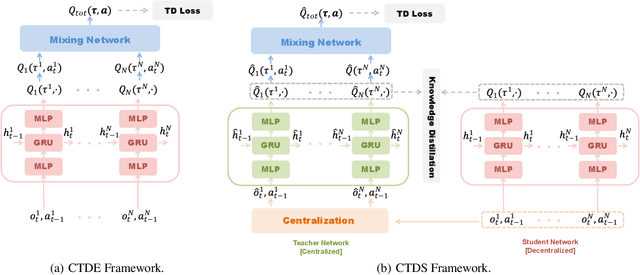

Due to the partial observability and communication constraints in many multi-agent reinforcement learning (MARL) tasks, centralized training with decentralized execution (CTDE) has become one of the most widely used MARL paradigms. In CTDE, centralized information is dedicated to learning the allocation of the team reward with a mixing network, while the learning of individual Q-values is usually based on local observations. The insufficient utility of global observation will degrade performance in challenging environments. To this end, this work proposes a novel Centralized Teacher with Decentralized Student (CTDS) framework, which consists of a teacher model and a student model. Specifically, the teacher model allocates the team reward by learning individual Q-values conditioned on global observation, while the student model utilizes the partial observations to approximate the Q-values estimated by the teacher model. In this way, CTDS balances the full utilization of global observation during training and the feasibility of decentralized execution for online inference. Our CTDS framework is generic which is ready to be applied upon existing CTDE methods to boost their performance. We conduct experiments on a challenging set of StarCraft II micromanagement tasks to test the effectiveness of our method and the results show that CTDS outperforms the existing value-based MARL methods.
TAE: A Semi-supervised Controllable Behavior-aware Trajectory Generator and Predictor
Mar 02, 2022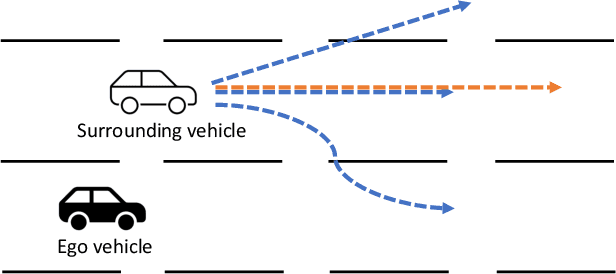
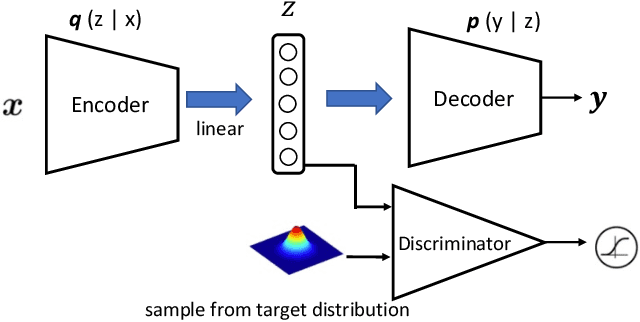
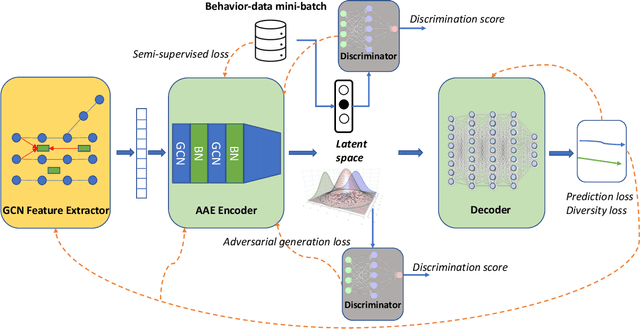
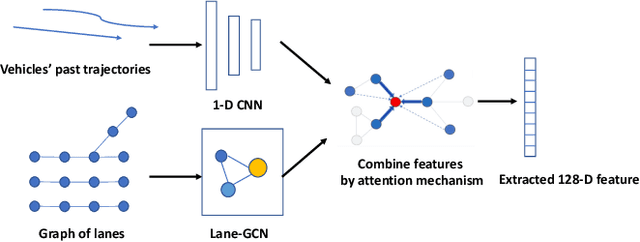
Trajectory generation and prediction are two interwoven tasks that play important roles in planner evaluation and decision making for intelligent vehicles. Most existing methods focus on one of the two and are optimized to directly output the final generated/predicted trajectories, which only contain limited information for critical scenario augmentation and safe planning. In this work, we propose a novel behavior-aware Trajectory Autoencoder (TAE) that explicitly models drivers' behavior such as aggressiveness and intention in the latent space, using semi-supervised adversarial autoencoder and domain knowledge in transportation. Our model addresses trajectory generation and prediction in a unified architecture and benefits both tasks: the model can generate diverse, controllable and realistic trajectories to enhance planner optimization in safety-critical and long-tailed scenarios, and it can provide prediction of critical behavior in addition to the final trajectories for decision making. Experimental results demonstrate that our method achieves promising performance on both trajectory generation and prediction.
PillarGrid: Deep Learning-based Cooperative Perception for 3D Object Detection from Onboard-Roadside LiDAR
Mar 12, 2022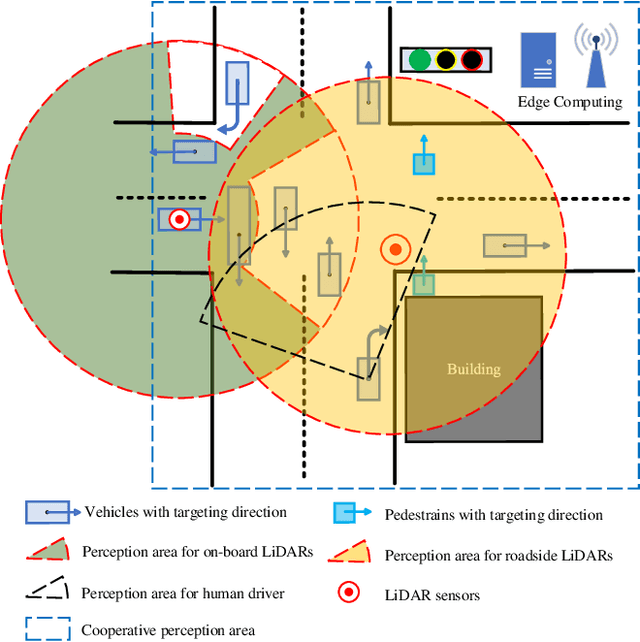
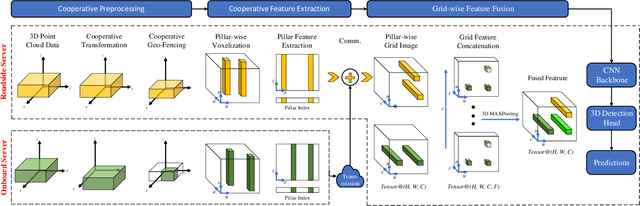
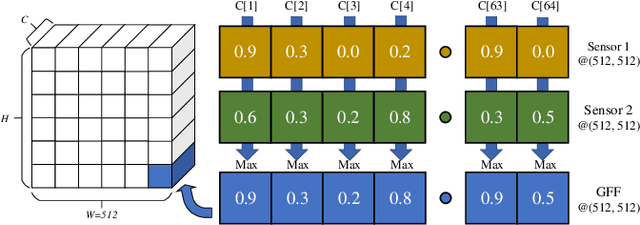
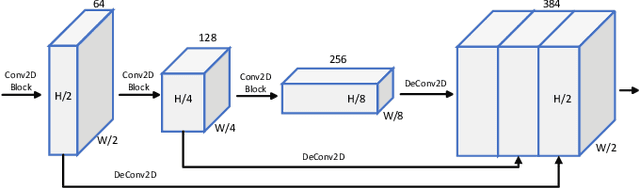
3D object detection plays a fundamental role in enabling autonomous driving, which is regarded as the significant key to unlocking the bottleneck of contemporary transportation systems from the perspectives of safety, mobility, and sustainability. Most of the state-of-the-art (SOTA) object detection methods from point clouds are developed based on a single onboard LiDAR, whose performance will be inevitably limited by the range and occlusion, especially in dense traffic scenarios. In this paper, we propose \textit{PillarGrid}, a novel cooperative perception method fusing information from multiple 3D LiDARs (both on-board and roadside), to enhance the situation awareness for connected and automated vehicles (CAVs). PillarGrid consists of four main phases: 1) cooperative preprocessing of point clouds, 2) pillar-wise voxelization and feature extraction, 3) grid-wise deep fusion of features from multiple sensors, and 4) convolutional neural network (CNN)-based augmented 3D object detection. A novel cooperative perception platform is developed for model training and testing. Extensive experimentation shows that PillarGrid outperforms the SOTA single-LiDAR-based 3D object detection methods with respect to both accuracy and range by a large margin.
A.I. and Data-Driven Mobility at Volkswagen Financial Services AG
Feb 09, 2022

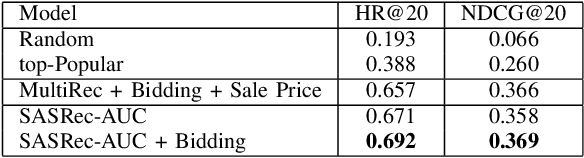
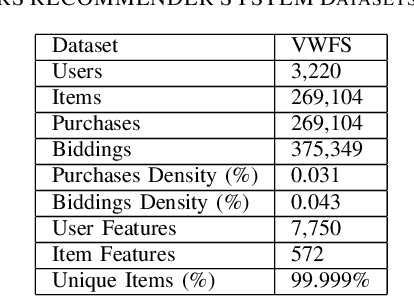
Machine learning is being widely adapted in industrial applications owing to the capabilities of commercially available hardware and rapidly advancing research. Volkswagen Financial Services (VWFS), as a market leader in vehicle leasing services, aims to leverage existing proprietary data and the latest research to enhance existing and derive new business processes. The collaboration between Information Systems and Machine Learning Lab (ISMLL) and VWFS serves to realize this goal. In this paper, we propose methods in the fields of recommender systems, object detection, and forecasting that enable data-driven decisions for the vehicle life-cycle at VWFS.
VGAER: graph neural network reconstruction based community detection
Jan 19, 2022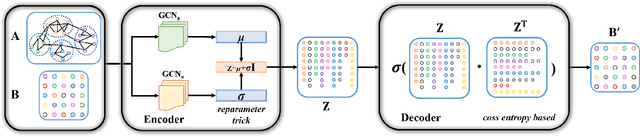
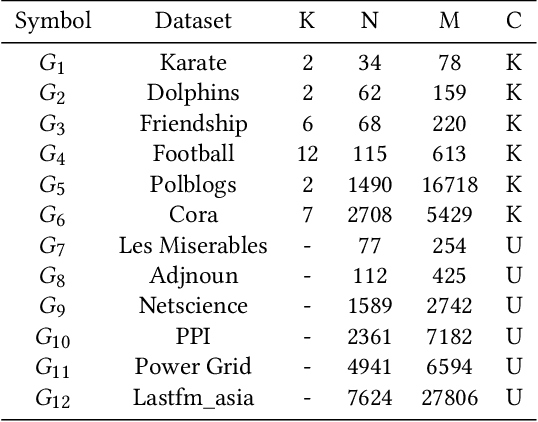
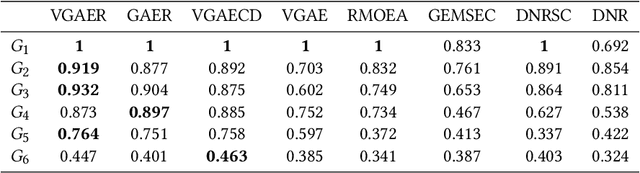
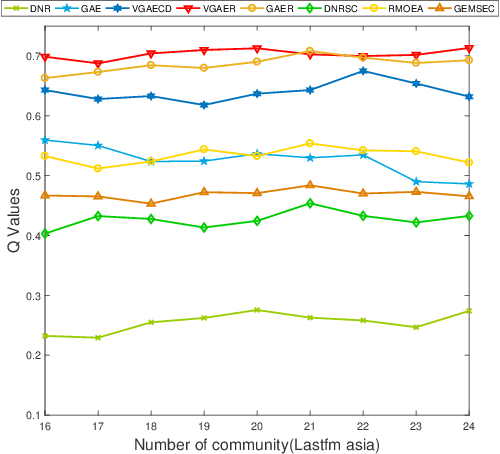
Community detection is a fundamental and important issue in network science, but there are only a few community detection algorithms based on graph neural networks, among which unsupervised algorithms are almost blank. By fusing the high-order modularity information with network features, this paper proposes a Variational Graph AutoEncoder Reconstruction based community detection VGAER for the first time, and gives its non-probabilistic version. They do not need any prior information. We have carefully designed corresponding input features, decoder, and downstream tasks based on the community detection task and these designs are concise, natural, and perform well (NMI values under our design are improved by 59.1% - 565.9%). Based on a series of experiments with wide range of datasets and advanced methods, VGAER has achieved superior performance and shows strong competitiveness and potential with a simpler design. Finally, we report the results of algorithm convergence analysis and t-SNE visualization, which clearly depicted the stable performance and powerful network modularity ability of VGAER. Our codes are available at https://github.com/qcydm/VGAER.