 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Density Estimation from Schlieren Images through Machine Learning
Jan 13, 2022



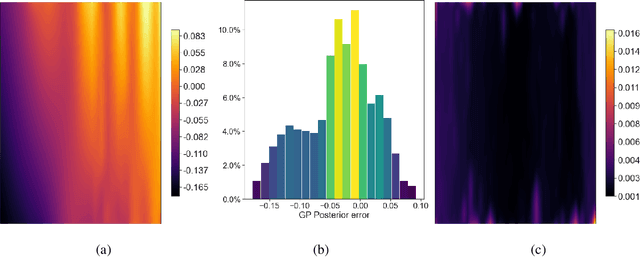
This study proposes a radically alternate approach for extracting quantitative information from schlieren images. The method uses a scaled, derivative enhanced Gaussian process model to obtain true density estimates from two corresponding schlieren images with the knife-edge at horizontal and vertical orientations. We illustrate our approach on schlieren images taken from a wind tunnel sting model, and a supersonic aircraft in flight.
Query Suggestion for Click-Absent Queries in Enterprise Search
Dec 28, 2021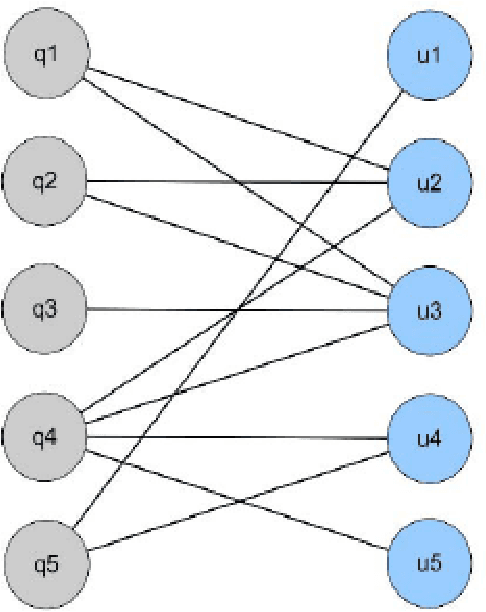
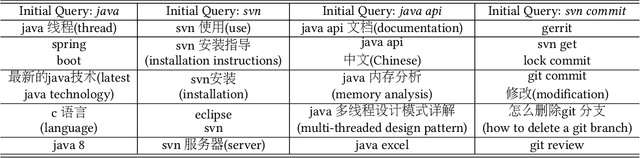
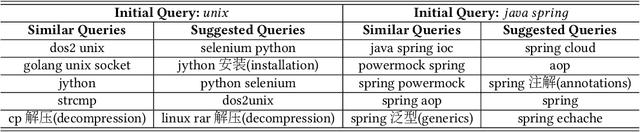
Creating alternative queries, also known as query suggestion, has been proved to be helpful on improving users' search experience. Owing to the suggestions, users could retrieve their information need more quickly and accurately. In many scenarios, these suggestions could be generated from the click-through logs by establishing a bipartite graph of the clicked query-document pairs. Most of the existing methods focused on click-existing queries which possess clicked information in the search logs, to suggest related queries using the co-clicked documents. In this paper, we propose a simple yet effective query suggestion method particularly for click-absent queries by ensuring semantic consistency without utilising any additional resources. Our experimental results show that the proposed technique generates comparatively good suggestions for click-absent queries on a real bilingual enterprise search log.
Graph Collaborative Reasoning
Dec 27, 2021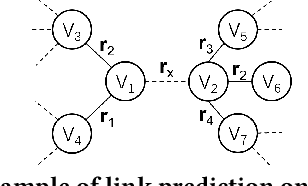


Graphs can represent relational information among entities and graph structures are widely used in many intelligent tasks such as search, recommendation, and question answering. However, most of the graph-structured data in practice suffers from incompleteness, and thus link prediction becomes an important research problem. Though many models are proposed for link prediction, the following two problems are still less explored: (1) Most methods model each link independently without making use of the rich information from relevant links, and (2) existing models are mostly designed based on associative learning and do not take reasoning into consideration. With these concerns, in this paper, we propose Graph Collaborative Reasoning (GCR), which can use the neighbor link information for relational reasoning on graphs from logical reasoning perspectives. We provide a simple approach to translate a graph structure into logical expressions, so that the link prediction task can be converted into a neural logic reasoning problem. We apply logical constrained neural modules to build the network architecture according to the logical expression and use back propagation to efficiently learn the model parameters, which bridges differentiable learning and symbolic reasoning in a unified architecture. To show the effectiveness of our work, we conduct experiments on graph-related tasks such as link prediction and recommendation based on commonly used benchmark datasets, and our graph collaborative reasoning approach achieves state-of-the-art performance.
Instance-Dependent Regret Analysis of Kernelized Bandits
Mar 12, 2022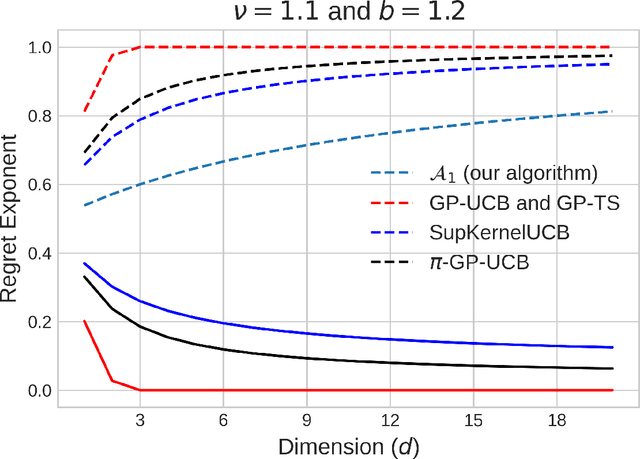
We study the kernelized bandit problem, that involves designing an adaptive strategy for querying a noisy zeroth-order-oracle to efficiently learn about the optimizer of an unknown function $f$ with a norm bounded by $M<\infty$ in a Reproducing Kernel Hilbert Space~(RKHS) associated with a positive definite kernel $K$. Prior results, working in a \emph{minimax framework}, have characterized the worst-case~(over all functions in the problem class) limits on regret achievable by \emph{any} algorithm, and have constructed algorithms with matching~(modulo polylogarithmic factors) worst-case performance for the \matern family of kernels. These results suffer from two drawbacks. First, the minimax lower bound gives no information about the limits of regret achievable by the commonly used algorithms on specific problem instances. Second, due to their worst-case nature, the existing upper bound analysis fails to adapt to easier problem instances within the function class. Our work takes steps to address both these issues. First, we derive \emph{instance-dependent} regret lower bounds for algorithms with uniformly~(over the function class) vanishing normalized cumulative regret. Our result, valid for all the practically relevant kernelized bandits algorithms, such as, GP-UCB, GP-TS and SupKernelUCB, identifies a fundamental complexity measure associated with every problem instance. We then address the second issue, by proposing a new minimax near-optimal algorithm which also adapts to easier problem instances.
Anomaly-resistant Graph Neural Networks via Neural Architecture Search
Nov 22, 2021
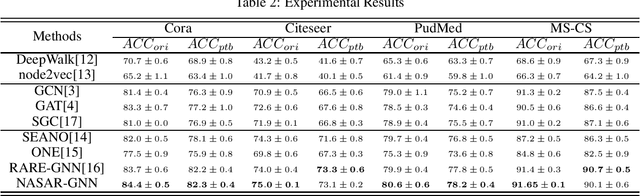
In general, Graph Neural Networks(GNN) have been using a message passing method to aggregate and summarize information about neighbors to express their information. Nonetheless, previous studies have shown that the performance of graph neural networks becomes vulnerable when there are abnormal nodes in the neighborhood due to this message passing method. In this paper, inspired by the Neural Architecture Search method, we present an algorithm that recognizes abnormal nodes and automatically excludes them from information aggregation. Experiments on various real worlds datasets show that our proposed Neural Architecture Search-based Anomaly Resistance Graph Neural Network (NASAR-GNN) is actually effective.
Differentially Private Community Detection for Stochastic Block Models
Jan 31, 2022
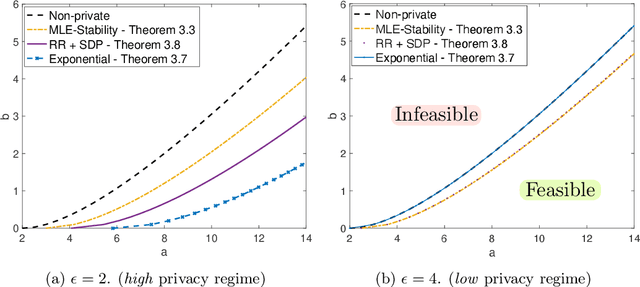
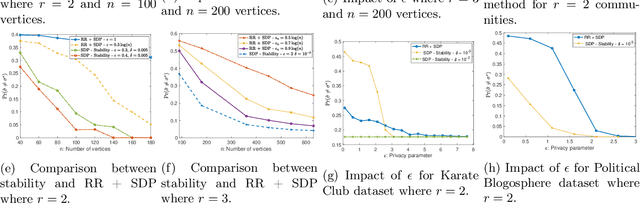

The goal of community detection over graphs is to recover underlying labels/attributes of users (e.g., political affiliation) given the connectivity between users (represented by adjacency matrix of a graph). There has been significant recent progress on understanding the fundamental limits of community detection when the graph is generated from a stochastic block model (SBM). Specifically, sharp information theoretic limits and efficient algorithms have been obtained for SBMs as a function of $p$ and $q$, which represent the intra-community and inter-community connection probabilities. In this paper, we study the community detection problem while preserving the privacy of the individual connections (edges) between the vertices. Focusing on the notion of $(\epsilon, \delta)$-edge differential privacy (DP), we seek to understand the fundamental tradeoffs between $(p, q)$, DP budget $(\epsilon, \delta)$, and computational efficiency for exact recovery of the community labels. To this end, we present and analyze the associated information-theoretic tradeoffs for three broad classes of differentially private community recovery mechanisms: a) stability based mechanism; b) sampling based mechanisms; and c) graph perturbation mechanisms. Our main findings are that stability and sampling based mechanisms lead to a superior tradeoff between $(p,q)$ and the privacy budget $(\epsilon, \delta)$; however this comes at the expense of higher computational complexity. On the other hand, albeit low complexity, graph perturbation mechanisms require the privacy budget $\epsilon$ to scale as $\Omega(\log(n))$ for exact recovery. To the best of our knowledge, this is the first work to study the impact of privacy constraints on the fundamental limits for community detection.
Dual-Branched Spatio-temporal Fusion Network for Multi-horizon Tropical Cyclone Track Forecast
Feb 27, 2022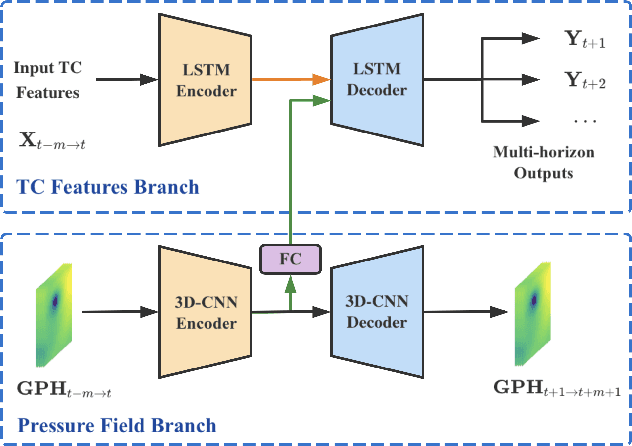
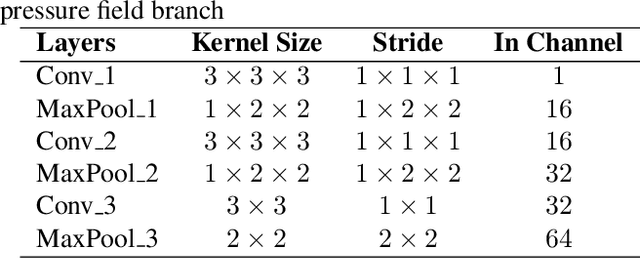
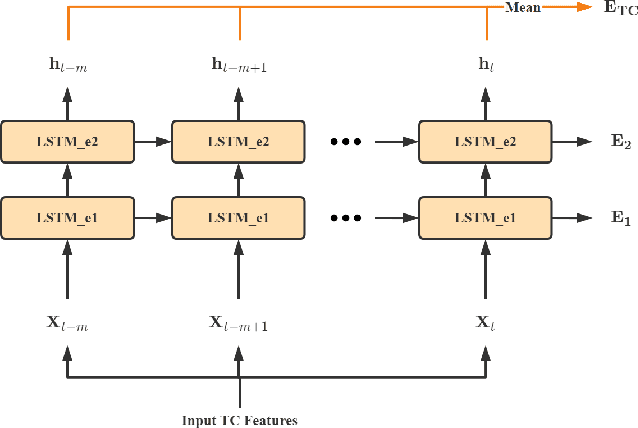
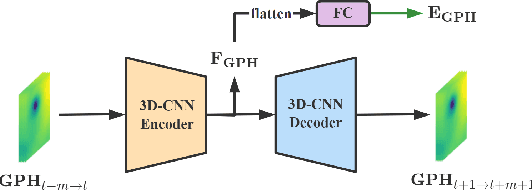
Tropical cyclone (TC) is an extreme tropical weather system and its trajectory can be described by a variety of spatio-temporal data. Effective mining of these data is the key to accurate TCs track forecasting. However, existing methods face the problem that the model complexity is too high or it is difficult to efficiently extract features from multi-modal data. In this paper, we propose the Dual-Branched spatio-temporal Fusion Network (DBF-Net) -- a novel multi-horizon tropical cyclone track forecasting model which fuses the multi-modal features efficiently. DBF-Net contains a TC features branch that extracts temporal features from 1D inherent features of TCs and a pressure field branch that extracts spatio-temporal features from reanalysis 2D pressure field. Through the encoder-decoder-based architecture and efficient feature fusion, DBF-Net can fully mine the information of the two types of data, and achieve good TCs track prediction results. Extensive experiments on historical TCs track data in the Northwest Pacific show that our DBF-Net achieves significant improvement compared with existing statistical and deep learning TCs track forecast methods.
TaxoCom: Topic Taxonomy Completion with Hierarchical Discovery of Novel Topic Clusters
Jan 19, 2022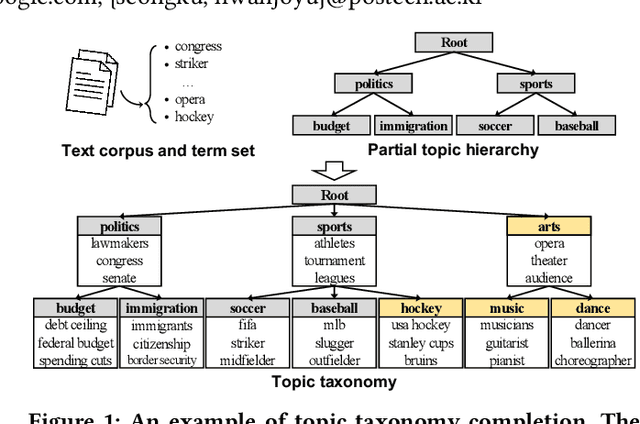
Topic taxonomies, which represent the latent topic (or category) structure of document collections, provide valuable knowledge of contents in many applications such as web search and information filtering. Recently, several unsupervised methods have been developed to automatically construct the topic taxonomy from a text corpus, but it is challenging to generate the desired taxonomy without any prior knowledge. In this paper, we study how to leverage the partial (or incomplete) information about the topic structure as guidance to find out the complete topic taxonomy. We propose a novel framework for topic taxonomy completion, named TaxoCom, which recursively expands the topic taxonomy by discovering novel sub-topic clusters of terms and documents. To effectively identify novel topics within a hierarchical topic structure, TaxoCom devises its embedding and clustering techniques to be closely-linked with each other: (i) locally discriminative embedding optimizes the text embedding space to be discriminative among known (i.e., given) sub-topics, and (ii) novelty adaptive clustering assigns terms into either one of the known sub-topics or novel sub-topics. Our comprehensive experiments on two real-world datasets demonstrate that TaxoCom not only generates the high-quality topic taxonomy in terms of term coherency and topic coverage but also outperforms all other baselines for a downstream task.
Transfer Learning of Graph Neural Networks with Ego-graph Information Maximization
Sep 11, 2020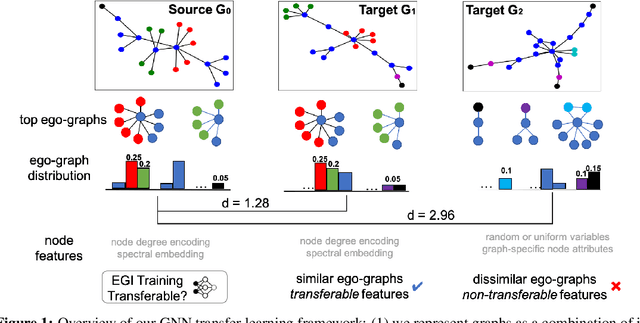
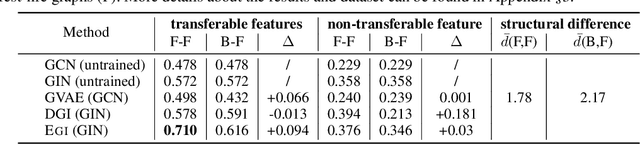
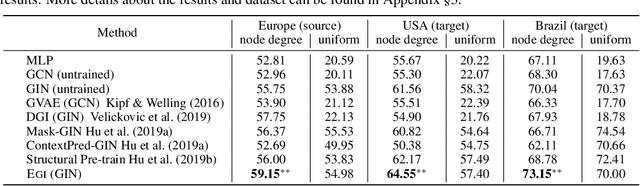
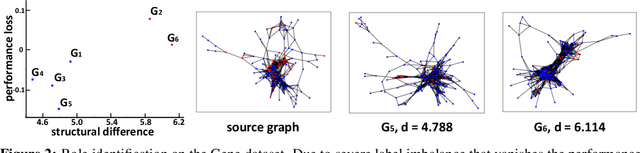
Graph neural networks (GNNs) have been shown with superior performance in various applications, but training dedicated GNNs can be costly for large-scale graphs. Some recent work started to study the pre-training of GNNs. However, none of them provide theoretical insights into the design of their frameworks, or clear requirements and guarantees towards the transferability of GNNs. In this work, we establish a theoretically grounded and practically useful framework for the transfer learning of GNNs. Firstly, we propose a novel view towards the essential graph information and advocate the capturing of it as the goal of transferable GNN training, which motivates the design of Ours, a novel GNN framework based on ego-graph information maximization to analytically achieve this goal. Secondly, we specify the requirement of structure-respecting node features as the GNN input, and derive a rigorous bound of GNN transferability based on the difference between the local graph Laplacians of the source and target graphs. Finally, we conduct controlled synthetic experiments to directly justify our theoretical conclusions. Extensive experiments on real-world networks towards role identification show consistent results in the rigorously analyzed setting of direct-transfering, while those towards large-scale relation prediction show promising results in the more generalized and practical setting of transfering with fine-tuning.
CSN: Component-Supervised Network for Few-Shot Classification
Mar 15, 2022
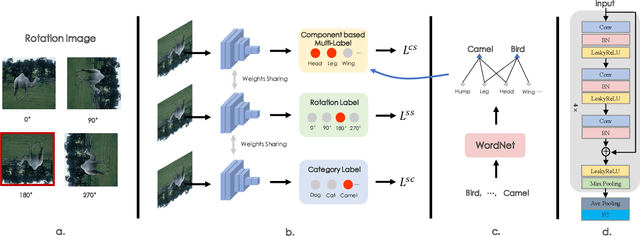

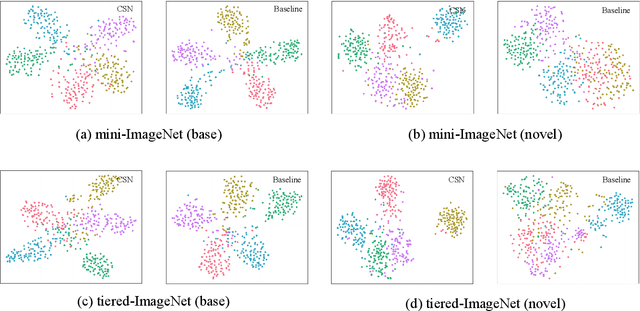
The few-shot classification (FSC) task has been a hot research topic in recent years. It aims to address the classification problem with insufficient labeled data on a cross-category basis. Typically, researchers pre-train a feature extractor with base data, then use it to extract the features of novel data and recognize them. Notably, the novel set only has a few annotated samples and has entirely different categories from the base set, which leads to that the pre-trained feature extractor can not adapt to the novel data flawlessly. We dub this problem as Feature-Extractor-Maladaptive (FEM) problem. Starting from the root cause of this problem, this paper presents a new scheme, Component-Supervised Network (CSN), to improve the performance of FSC. We believe that although the categories of base and novel sets are different, the composition of the sample's components is similar. For example, both cat and dog contain leg and head components. Actually, such entity components are intra-class stable. They have fine cross-category versatility and new category generalization. Therefore, we refer to WordNet, a dictionary commonly used in natural language processing, to collect component information of samples and construct a component-based auxiliary task to improve the adaptability of the feature extractor. We conduct experiments on two benchmark datasets (mini-ImageNet and tiered-ImageNet), the improvements of $0.9\%$-$5.8\%$ compared with state-of-the-arts have evaluated the efficiency of our CSN.