 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semi-Supervised Convolutive NMF for Automatic Music Transcription
Feb 10, 2022
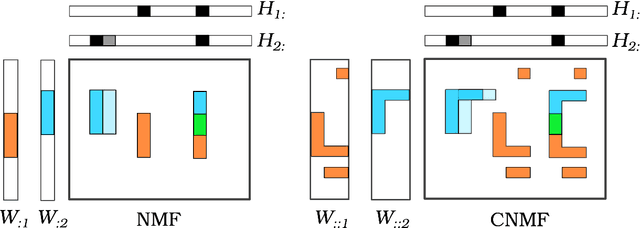
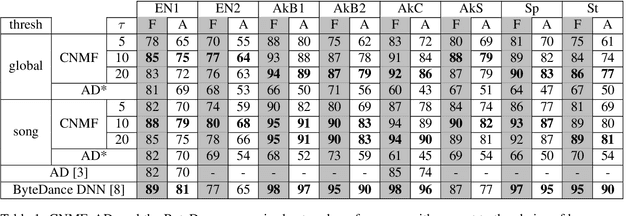
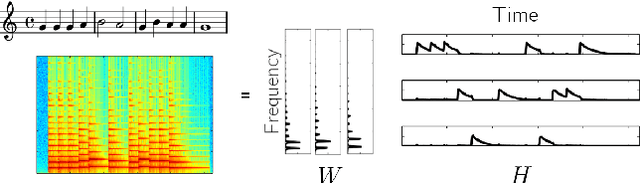
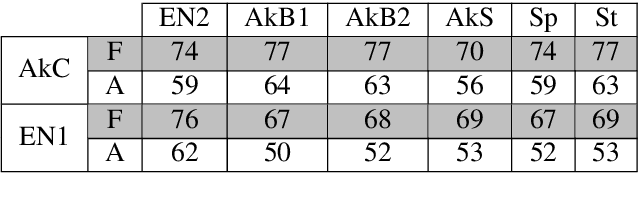
Automatic Music Transcription, which consists in transforming an audio recording of a musical performance into symbolic format, remains a difficult Music Information Retrieval task. In this work, we propose a semi-supervised approach using low-rank matrix factorization techniques, in particular Convolutive Nonnegative Matrix Factorization. In the semi-supervised setting, only a single recording of each individual notes is required. We show on the MAPS dataset that the proposed semi-supervised CNMF method performs better than state-of-the-art low-rank factorization techniques and a little worse than supervised deep learning state-of-the-art methods, while however suffering from generalization issues.
Information Acquisition Under Resource Limitations in a Noisy Environment
May 20, 2020We introduce a theoretical model of information acquisition under resource limitations in a noisy environment. An agent must guess the truth value of a given Boolean formula $\varphi$ after performing a bounded number of noisy tests of the truth values of variables in the formula. We observe that, in general, the problem of finding an optimal testing strategy for $\phi$ is hard, but we suggest a useful heuristic. The techniques we use also give insight into two apparently unrelated, but well-studied problems: (1) \emph{rational inattention}, that is, when it is rational to ignore pertinent information (the optimal strategy may involve hardly ever testing variables that are clearly relevant to $\phi$), and (2) what makes a formula hard to learn/remember.
2D+3D facial expression recognition via embedded tensor manifold regularization
Jan 29, 2022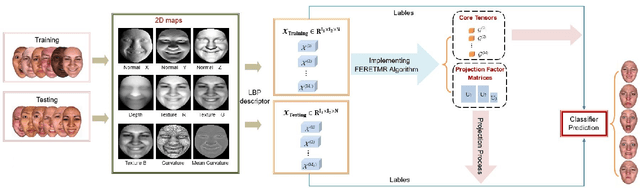
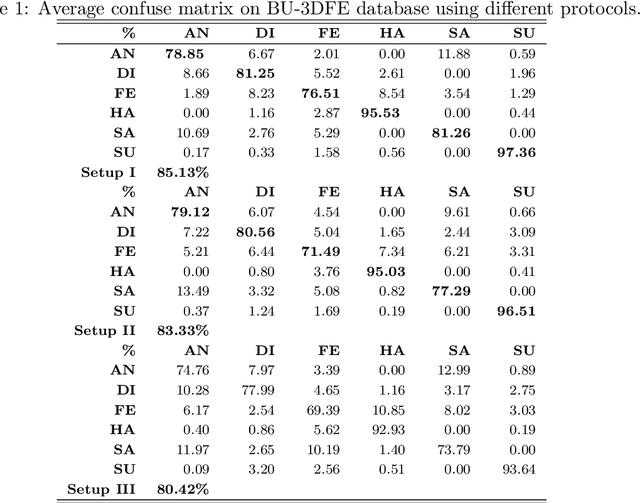
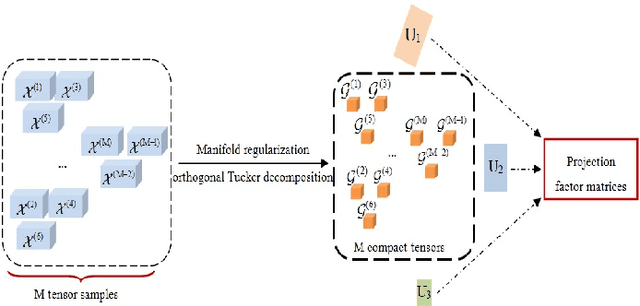
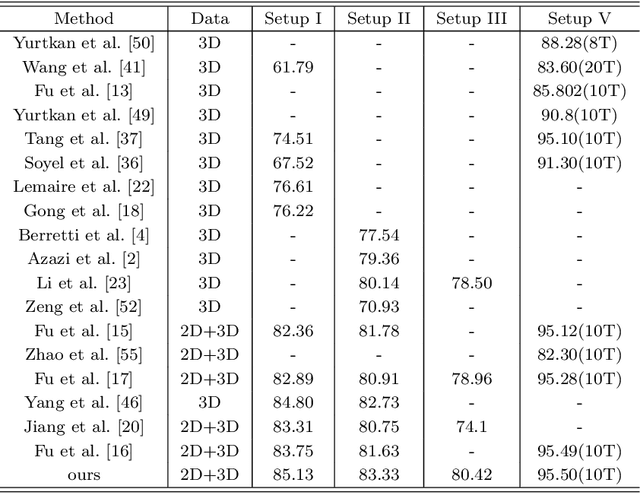
In this paper, a novel approach via embedded tensor manifold regularization for 2D+3D facial expression recognition (FERETMR) is proposed. Firstly, 3D tensors are constructed from 2D face images and 3D face shape models to keep the structural information and correlations. To maintain the local structure (geometric information) of 3D tensor samples in the low-dimensional tensors space during the dimensionality reduction, the $\ell_0$-norm of the core tensors and a tensor manifold regularization scheme embedded on core tensors are adopted via a low-rank truncated Tucker decomposition on the generated tensors. As a result, the obtained factor matrices will be used for facial expression classification prediction. To make the resulting tensor optimization more tractable, $\ell_1$-norm surrogate is employed to relax $\ell_0$-norm and hence the resulting tensor optimization problem has a nonsmooth objective function due to the $\ell_1$-norm and orthogonal constraints from the orthogonal Tucker decomposition. To efficiently tackle this tensor optimization problem, we establish the first-order optimality condition in terms of stationary points, and then design a block coordinate descent (BCD) algorithm with convergence analysis and the computational complexity. Numerical results on BU-3DFE database and Bosphorus databases demonstrate the effectiveness of our proposed approach.
TIGGER: Scalable Generative Modelling for Temporal Interaction Graphs
Mar 08, 2022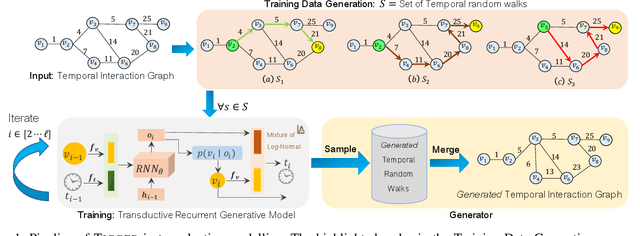
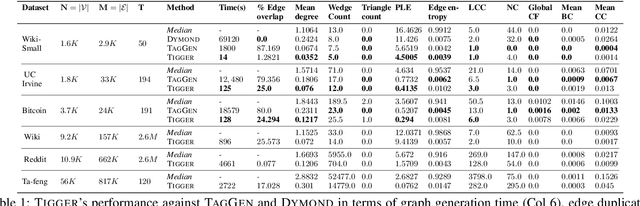

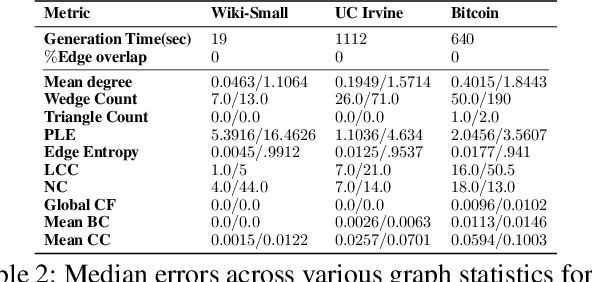
There has been a recent surge in learning generative models for graphs. While impressive progress has been made on static graphs, work on generative modeling of temporal graphs is at a nascent stage with significant scope for improvement. First, existing generative models do not scale with either the time horizon or the number of nodes. Second, existing techniques are transductive in nature and thus do not facilitate knowledge transfer. Finally, due to relying on one-to-one node mapping from source to the generated graph, existing models leak node identity information and do not allow up-scaling/down-scaling the source graph size. In this paper, we bridge these gaps with a novel generative model called TIGGER. TIGGER derives its power through a combination of temporal point processes with auto-regressive modeling enabling both transductive and inductive variants. Through extensive experiments on real datasets, we establish TIGGER generates graphs of superior fidelity, while also being up to 3 orders of magnitude faster than the state-of-the-art.
Developing a Trusted Human-AI Network for Humanitarian Benefit
Dec 07, 2021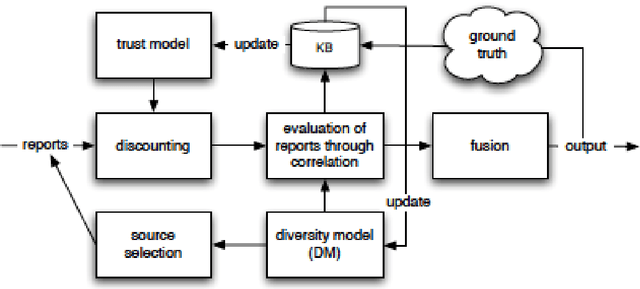
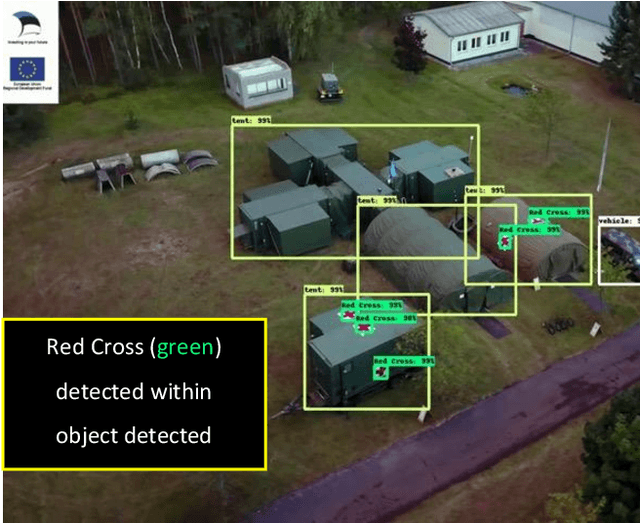

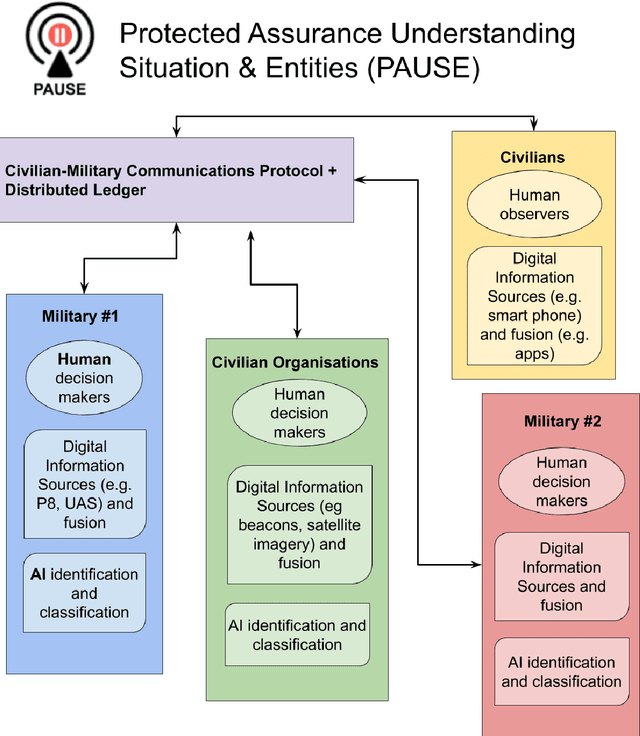
Humans and artificial intelligences (AI) will increasingly participate digitally and physically in conflicts, yet there is a lack of trusted communications across agents and platforms. For example, humans in disasters and conflict already use messaging and social media to share information, however, international humanitarian relief organisations treat this information as unverifiable and untrustworthy. AI may reduce the 'fog-of-war' and improve outcomes, however AI implementations are often brittle, have a narrow scope of application and wide ethical risks. Meanwhile, human error causes significant civilian harms even by combatants committed to complying with international humanitarian law. AI offers an opportunity to help reduce the tragedy of war and deliver humanitarian aid to those who need it. In this paper we consider the integration of a communications protocol (the 'Whiteflag protocol'), distributed ledger technology, and information fusion with artificial intelligence (AI), to improve conflict communications called 'Protected Assurance Understanding Situation and Entities' (PAUSE). Such a trusted human-AI communication network could provide accountable information exchange regarding protected entities, critical infrastructure; humanitarian signals and status updates for humans and machines in conflicts.
An Indirect Rate-Distortion Characterization for Semantic Sources: General Model and the Case of Gaussian Observation
Jan 29, 2022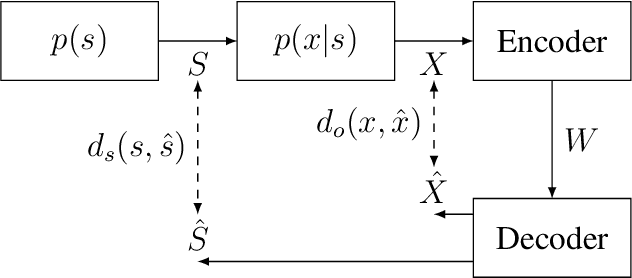
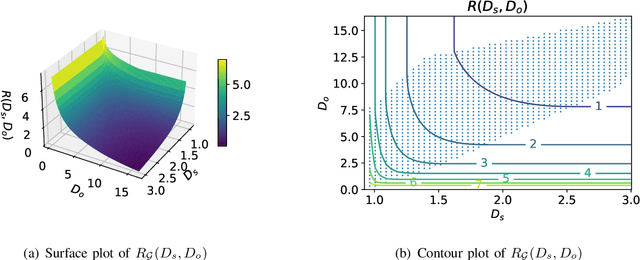
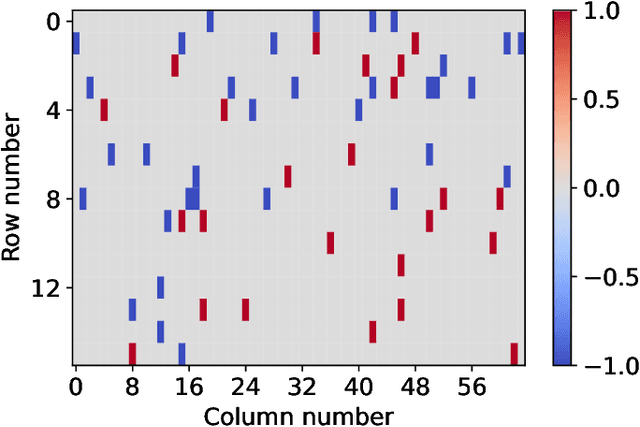
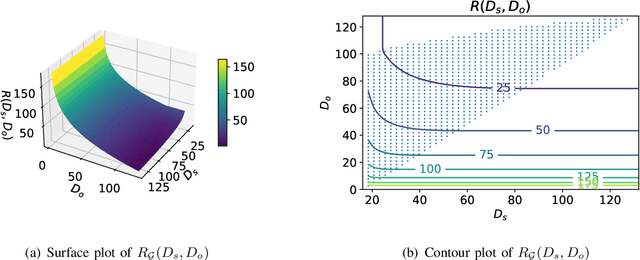
A new source model, which consists of an intrinsic state part and an extrinsic observation part, is proposed and its information-theoretic characterization, namely its rate-distortion function, is defined and analyzed. Such a source model is motivated by the recent surge of interest in the semantic aspect of information: the intrinsic state corresponds to the semantic feature of the source, which in general is not observable but can only be inferred from the extrinsic observation. There are two distortion measures, one between the intrinsic state and its reproduction, and the other between the extrinsic observation and its reproduction. Under a given code rate, the tradeoff between these two distortion measures is characterized by the rate-distortion function, which is solved via the indirect rate-distortion theory and is termed as the semantic rate-distortion function of the source. As an application of the general model and its analysis, the case of Gaussian extrinsic observation is studied, assuming a linear relationship between the intrinsic state and the extrinsic observation, under a quadratic distortion structure. The semantic rate-distortion function is shown to be the solution of a convex programming programming with respect to an error covariance matrix, and a reverse water-filling type of solution is provided when the model further satisfies a diagonalizability condition.
Rubik's Cube Operator: A Plug And Play Permutation Module for Better Arranging High Dimensional Industrial Data in Deep Convolutional Processes
Mar 24, 2022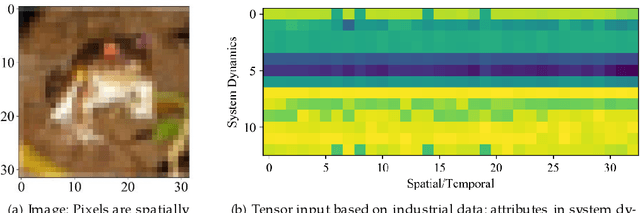
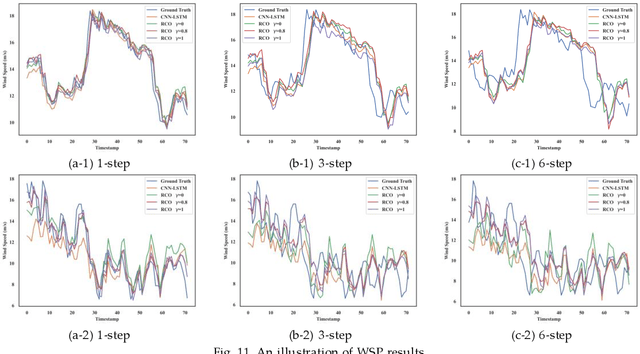
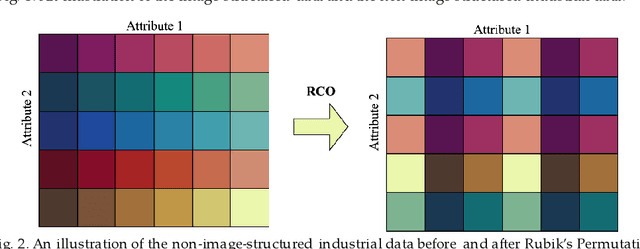
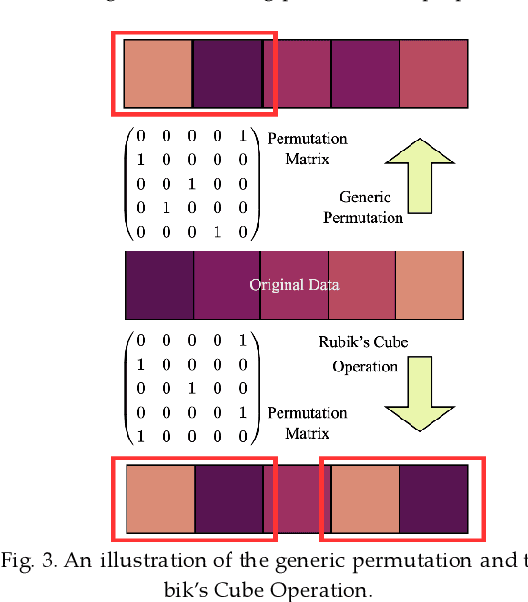
The convolutional neural network (CNN) has been widely applied to process the industrial data based tensor input, which integrates data records of distributed industrial systems from the spatial, temporal, and system dynamics aspects. However, unlike images, information in the industrial data based tensor is not necessarily spatially ordered. Thus, directly applying CNN is ineffective. To tackle such issue, we propose a plug and play module, the Rubik's Cube Operator (RCO), to adaptively permutate the data organization of the industrial data based tensor to an optimal or suboptimal order of attributes before being processed by CNNs, which can be updated with subsequent CNNs together via the gradient-based optimizer. The proposed RCO maintains K binary and right stochastic permutation matrices to permutate attributes of K axes of the input industrial data based tensor. A novel learning process is proposed to enable learning permutation matrices from data, where the Gumbel-Softmax is employed to reparameterize elements of permutation matrices, and the soft regularization loss is proposed and added to the task-specific loss to ensure the feature diversity of the permuted data. We verify the effectiveness of the proposed RCO via considering two representative learning tasks processing industrial data via CNNs, the wind power prediction (WPP) and the wind speed prediction (WSP) from the renewable energy domain. Computational experiments are conducted based on four datasets collected from different wind farms and the results demonstrate that the proposed RCO can improve the performance of CNN based networks significantly.
An Online Semantic Mapping System for Extending and Enhancing Visual SLAM
Mar 08, 2022



We present a real-time semantic mapping approach for mobile vision systems with a 2D to 3D object detection pipeline and rapid data association for generated landmarks. Besides the semantic map enrichment the associated detections are further introduced as semantic constraints into a simultaneous localization and mapping (SLAM) system for pose correction purposes. This way, we are able generate additional meaningful information that allows to achieve higher-level tasks, while simultaneously leveraging the view-invariance of object detections to improve the accuracy and the robustness of the odometry estimation. We propose tracklets of locally associated object observations to handle ambiguous and false predictions and an uncertainty-based greedy association scheme for an accelerated processing time. Our system reaches real-time capabilities with an average iteration duration of 65~ms and is able to improve the pose estimation of a state-of-the-art SLAM by up to 68% on a public dataset. Additionally, we implemented our approach as a modular ROS package that makes it straightforward for integration in arbitrary graph-based SLAM methods.
Quantifying Privacy Risks of Masked Language Models Using Membership Inference Attacks
Mar 08, 2022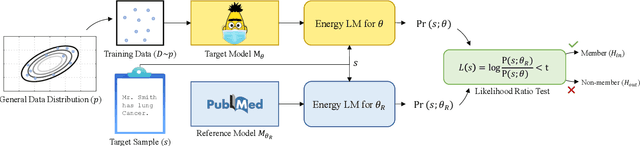


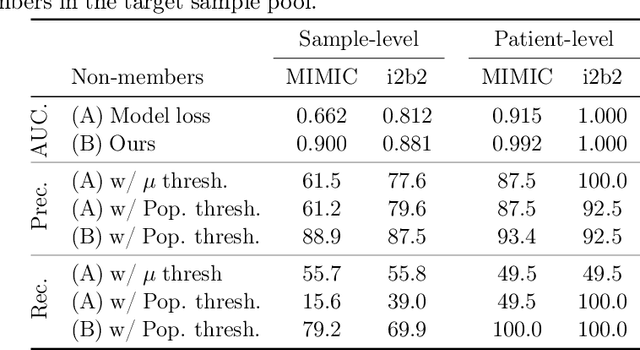
The wide adoption and application of Masked language models~(MLMs) on sensitive data (from legal to medical) necessitates a thorough quantitative investigation into their privacy vulnerabilities -- to what extent do MLMs leak information about their training data? Prior attempts at measuring leakage of MLMs via membership inference attacks have been inconclusive, implying the potential robustness of MLMs to privacy attacks. In this work, we posit that prior attempts were inconclusive because they based their attack solely on the MLM's model score. We devise a stronger membership inference attack based on likelihood ratio hypothesis testing that involves an additional reference MLM to more accurately quantify the privacy risks of memorization in MLMs. We show that masked language models are extremely susceptible to likelihood ratio membership inference attacks: Our empirical results, on models trained on medical notes, show that our attack improves the AUC of prior membership inference attacks from 0.66 to an alarmingly high 0.90 level, with a significant improvement in the low-error region: at 1% false positive rate, our attack is 51X more powerful than prior work.
Adaptive n-ary Activation Functions for Probabilistic Boolean Logic
Mar 16, 2022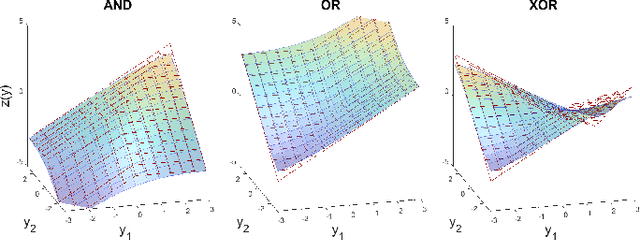
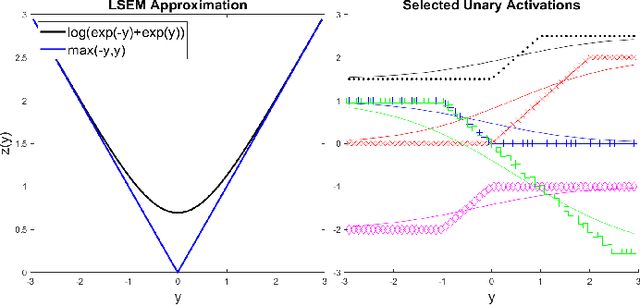
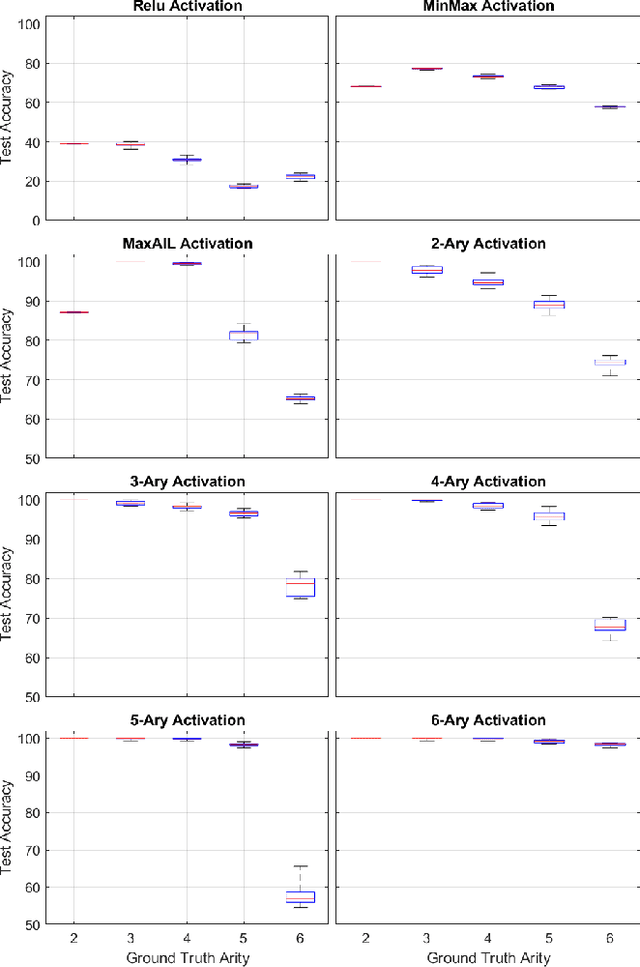
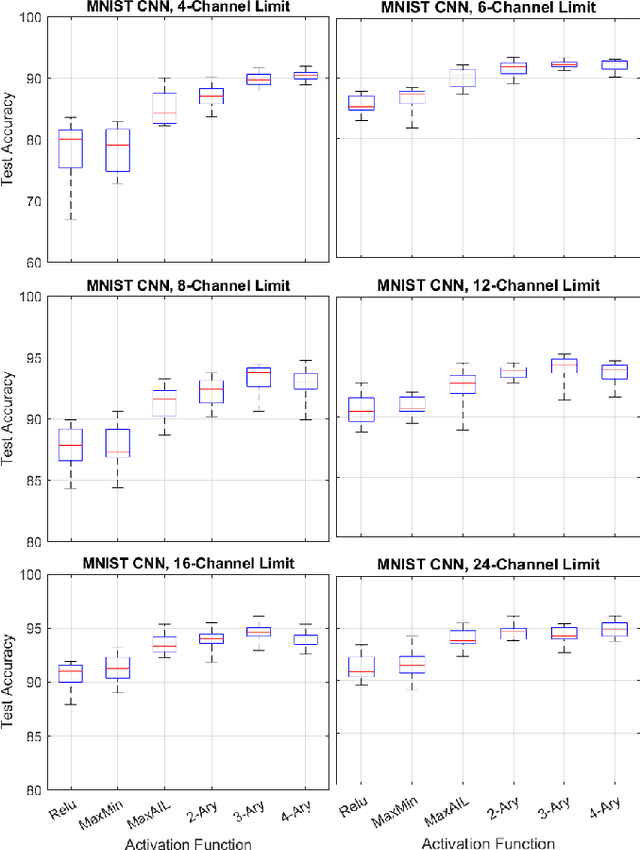
Balancing model complexity against the information contained in observed data is the central challenge to learning. In order for complexity-efficient models to exist and be discoverable in high dimensions, we require a computational framework that relates a credible notion of complexity to simple parameter representations. Further, this framework must allow excess complexity to be gradually removed via gradient-based optimization. Our n-ary, or n-argument, activation functions fill this gap by approximating belief functions (probabilistic Boolean logic) using logit representations of probability. Just as Boolean logic determines the truth of a consequent claim from relationships among a set of antecedent propositions, probabilistic formulations generalize predictions when antecedents, truth tables, and consequents all retain uncertainty. Our activation functions demonstrate the ability to learn arbitrary logic, such as the binary exclusive disjunction (p xor q) and ternary conditioned disjunction ( c ? p : q ), in a single layer using an activation function of matching or greater arity. Further, we represent belief tables using a basis that directly associates the number of nonzero parameters to the effective arity of the belief function, thus capturing a concrete relationship between logical complexity and efficient parameter representations. This opens optimization approaches to reduce logical complexity by inducing parameter sparsity.