 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Optimizing Information Loss Towards Robust Neural Networks
Aug 07, 2020
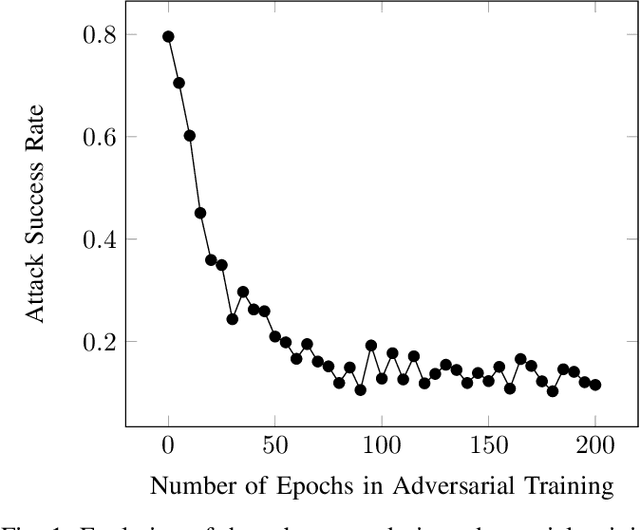
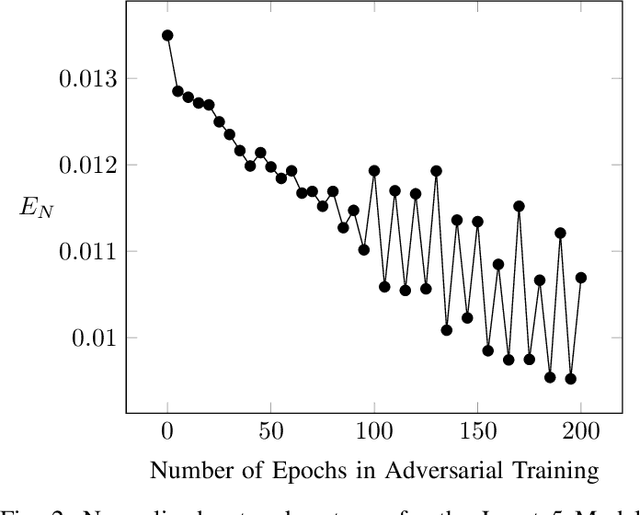
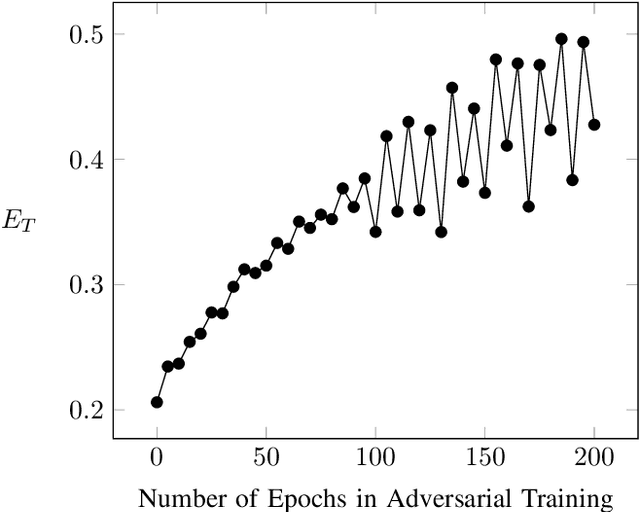
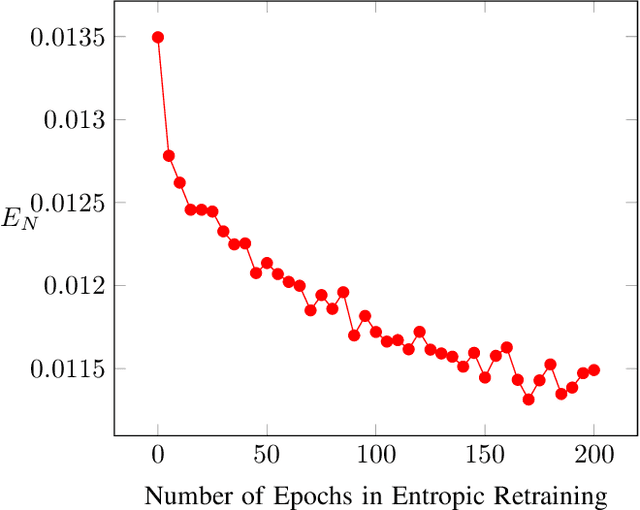
Neural Networks (NNs) are vulnerable to adversarial examples. Such inputs differ only slightly from their benign counterparts yet provoke misclassifications of the attacked NNs. The required perturbations to craft the examples are often negligible and even human imperceptible. To protect deep learning based system from such attacks, several countermeasures have been proposed with adversarial training still being considered the most effective. Here, NNs are iteratively retrained using adversarial examples forming a computational expensive and time consuming process often leading to a performance decrease. To overcome the downsides of adversarial training while still providing a high level of security, we present a new training approach we call entropic retraining. Based on an information-theoretic analysis, entropic retraining mimics the effects of adversarial training without the need of the laborious generation of adversarial examples. We empirically show that entropic retraining leads to a significant increase in NNs' security and robustness while only relying on the given original data. With our prototype implementation we validate and show the effectiveness of our approach for various NN architectures and data sets.
Learning Perspective Deformation in X-Ray Transmission Imaging
Feb 13, 2022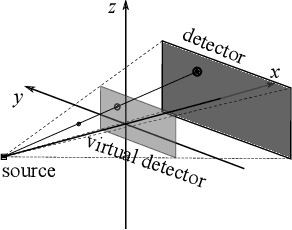

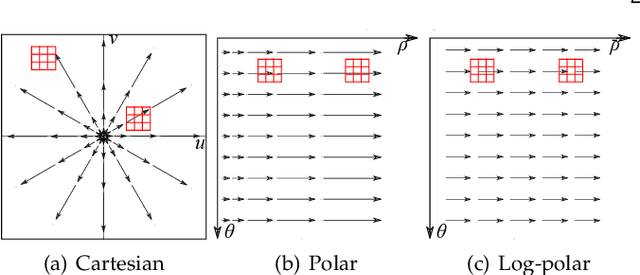

In cone-beam X-ray transmission imaging, due to the divergence of X-rays, imaged structures with different depths have different magnification factors on an X-ray detector, which results in perspective deformation. Perspective deformation causes difficulty in direct, accurate geometric assessments of anatomical structures. In this work, to reduce perspective deformation in X-ray images acquired from regular cone-beam computed tomography (CBCT) systems, we investigate on learning perspective deformation, i.e., converting perspective projections into orthogonal projections. Directly converting a single perspective projection image into an orthogonal projection image is extremely challenging due to the lack of depth information. Therefore, we propose to utilize one additional perspective projection, a complementary (180-degree) or orthogonal (90-degree) view, to provide a certain degree of depth information. Furthermore, learning perspective deformation in different spatial domains is investigated. Our proposed method is evaluated on numerical spherical bead phantoms as well as patients' chest and head X-ray data. The experiments on numerical bead phantom data demonstrate that learning perspective deformation in polar coordinates has significant advantages over learning in Cartesian coordinates, as root-mean-square error (RMSE) decreases from 5.31 to 1.40, while learning in log-polar coordinates has no further considerable improvement (RMSE = 1.85). In addition, using a complementary view (RMSE = 1.40) is better than an orthogonal view (RMSE = 3.87). The experiments on patients' chest and head data demonstrate that learning perspective deformation using dual complementary views is also applicable in anatomical X-ray data, allowing accurate cardiothoracic ratio measurements in chest X-ray images and cephalometric analysis in synthetic cephalograms from cone-beam X-ray projections.
Incorporating Commonsense Knowledge into Story Ending Generation via Heterogeneous Graph Networks
Jan 29, 2022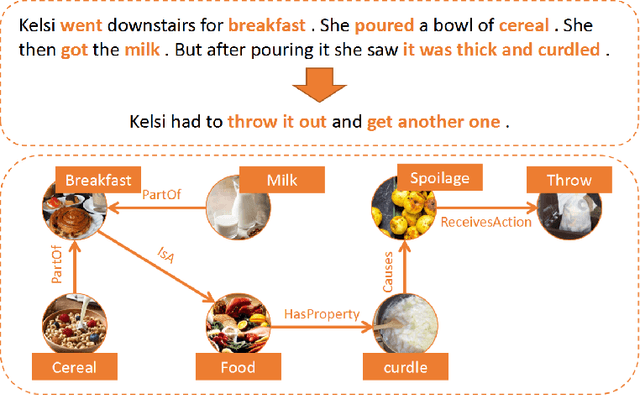

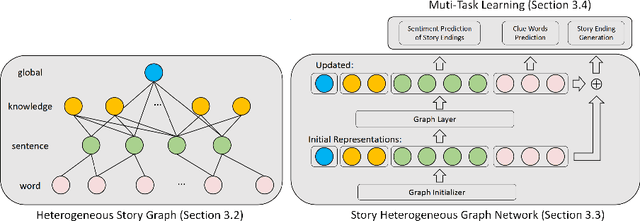
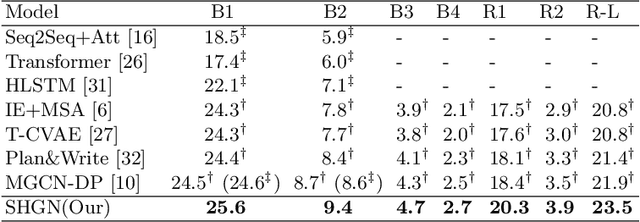
Story ending generation is an interesting and challenging task, which aims to generate a coherent and reasonable ending given a story context. The key challenges of the task lie in how to comprehend the story context sufficiently and handle the implicit knowledge behind story clues effectively, which are still under-explored by previous work. In this paper, we propose a Story Heterogeneous Graph Network (SHGN) to explicitly model both the information of story context at different granularity levels and the multi-grained interactive relations among them. In detail, we consider commonsense knowledge, words and sentences as three types of nodes. To aggregate non-local information, a global node is also introduced. Given this heterogeneous graph network, the node representations are updated through graph propagation, which adequately utilizes commonsense knowledge to facilitate story comprehension. Moreover, we design two auxiliary tasks to implicitly capture the sentiment trend and key events lie in the context. The auxiliary tasks are jointly optimized with the primary story ending generation task in a multi-task learning strategy. Extensive experiments on the ROCStories Corpus show that the developed model achieves new state-of-the-art performances. Human study further demonstrates that our model generates more reasonable story endings.
Domain Generalization via Frequency-based Feature Disentanglement and Interaction
Jan 20, 2022
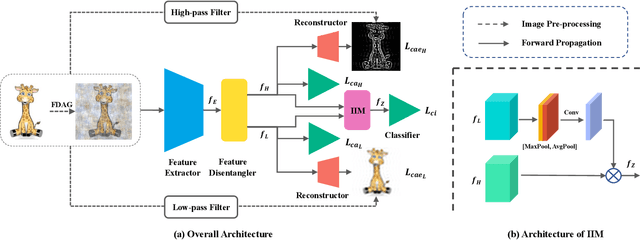
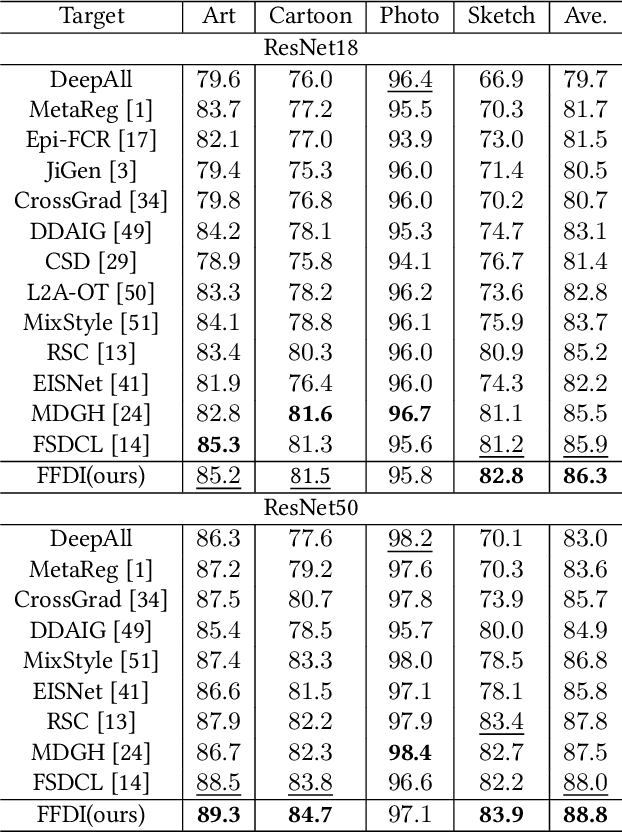
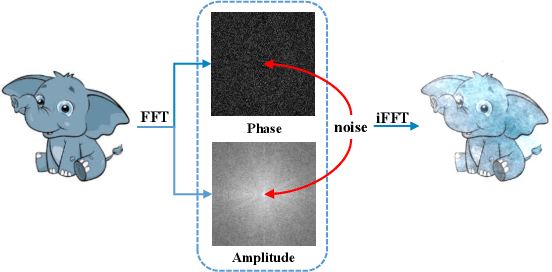
Data out-of-distribution is a meta-challenge for all statistical learning algorithms that strongly rely on the i.i.d. assumption. It leads to unavoidable labor costs and confidence crises in realistic applications. For that, domain generalization aims at mining domain-irrelevant knowledge from multiple source domains that can generalize to unseen target domains with unknown distributions. In this paper, leveraging the image frequency domain, we uniquely work with two key observations: (i) the high-frequency information of images depict object edge structure, which is naturally consistent across different domains, and (ii) the low-frequency component retains object smooth structure but are much more domain-specific. Motivated by these insights, we introduce (i) an encoder-decoder structure for high-frequency and low-frequency feature disentangling, (ii) an information interaction mechanism that ensures helpful knowledge from both two parts can cooperate effectively, and (iii) a novel data augmentation technique that works on the frequency domain for encouraging robustness of the network. The proposed method obtains state-of-the-art results on three widely used domain generalization benchmarks (Digit-DG, Office-Home, and PACS).
Graph Representation Learning via Contrasting Cluster Assignments
Dec 15, 2021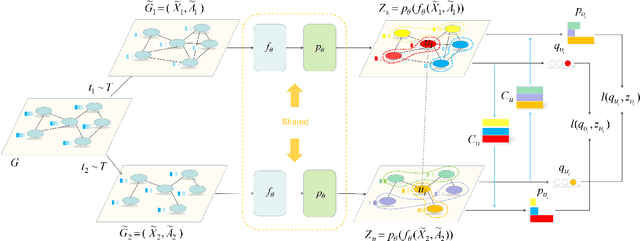
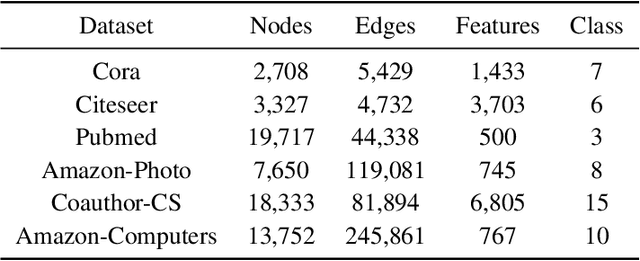
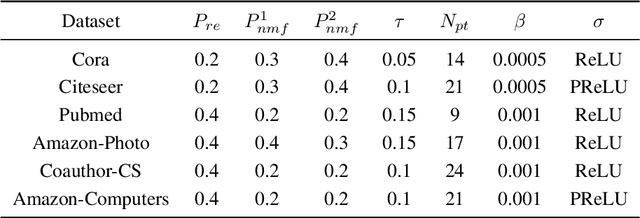
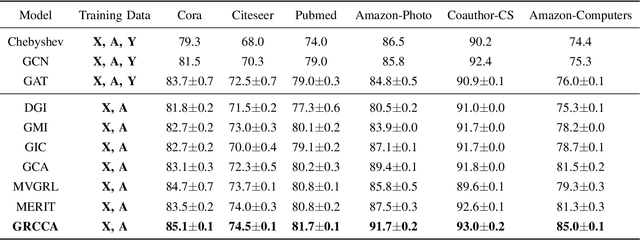
With the rise of contrastive learning, unsupervised graph representation learning has been booming recently, even surpassing the supervised counterparts in some machine learning tasks. Most of existing contrastive models for graph representation learning either focus on maximizing mutual information between local and global embeddings, or primarily depend on contrasting embeddings at node level. However, they are still not exquisite enough to comprehensively explore the local and global views of network topology. Although the former considers local-global relationship, its coarse global information leads to grudging cooperation between local and global views. The latter pays attention to node-level feature alignment, so that the role of global view appears inconspicuous. To avoid falling into these two extreme cases, we propose a novel unsupervised graph representation model by contrasting cluster assignments, called as GRCCA. It is motivated to make good use of local and global information synthetically through combining clustering algorithms and contrastive learning. This not only facilitates the contrastive effect, but also provides the more high-quality graph information. Meanwhile, GRCCA further excavates cluster-level information, which make it get insight to the elusive association between nodes beyond graph topology. Specifically, we first generate two augmented graphs with distinct graph augmentation strategies, then employ clustering algorithms to obtain their cluster assignments and prototypes respectively. The proposed GRCCA further compels the identical nodes from different augmented graphs to recognize their cluster assignments mutually by minimizing a cross entropy loss. To demonstrate its effectiveness, we compare with the state-of-the-art models in three different downstream tasks. The experimental results show that GRCCA has strong competitiveness in most tasks.
Weakly-Supervised Semantic Segmentation with Visual Words Learning and Hybrid Pooling
Feb 10, 2022
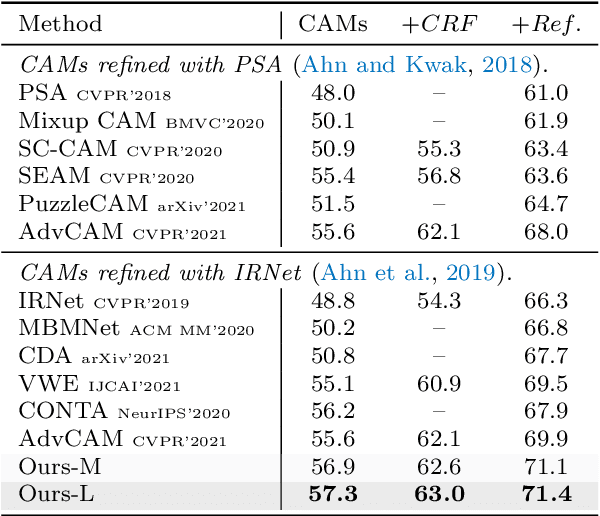
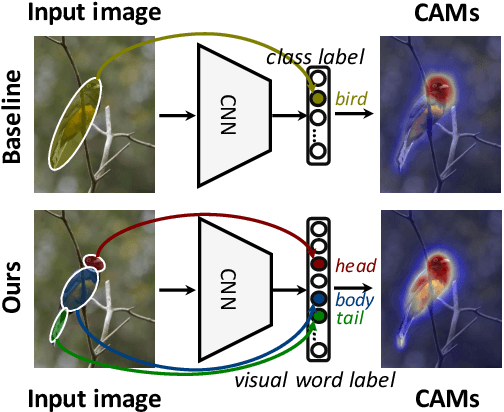
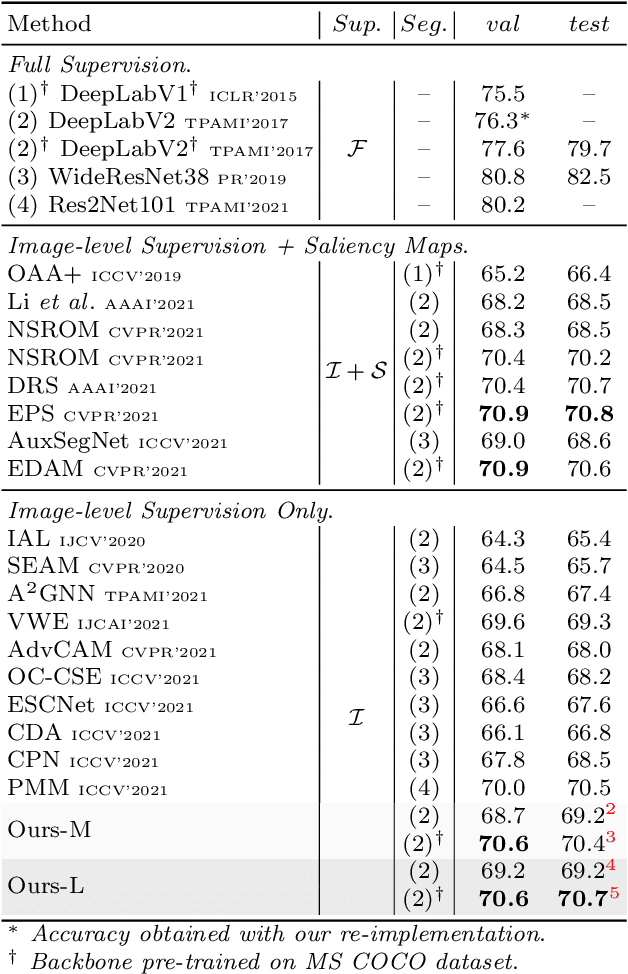
Weakly-Supervised Semantic Segmentation (WSSS) methods with image-level labels generally train a classification network to generate the Class Activation Maps (CAMs) as the initial coarse segmentation labels. However, current WSSS methods still perform far from satisfactorily because their adopted CAMs 1) typically focus on partial discriminative object regions and 2) usually contain useless background regions. These two problems are attributed to the sole image-level supervision and aggregation of global information when training the classification networks. In this work, we propose the visual words learning module and hybrid pooling approach, and incorporate them in the classification network to mitigate the above problems. In the visual words learning module, we counter the first problem by enforcing the classification network to learn fine-grained visual word labels so that more object extents could be discovered. Specifically, the visual words are learned with a codebook, which could be updated via two proposed strategies, i.e. learning-based strategy and memory-bank strategy. The second drawback of CAMs is alleviated with the proposed hybrid pooling, which incorporates the global average and local discriminative information to simultaneously ensure object completeness and reduce background regions. We evaluated our methods on PASCAL VOC 2012 and MS COCO 2014 datasets. Without any extra saliency prior, our method achieved 70.6% and 70.7% mIoU on the $val$ and $test$ set of PASCAL VOC dataset, respectively, and 36.2% mIoU on the $val$ set of MS COCO dataset, which significantly surpassed the performance of state-of-the-art WSSS methods.
Speech-Based Emotion Recognition using Neural Networks and Information Visualization
Oct 28, 2020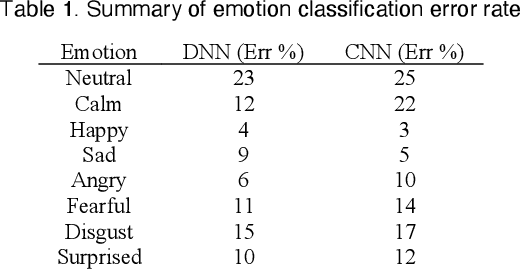
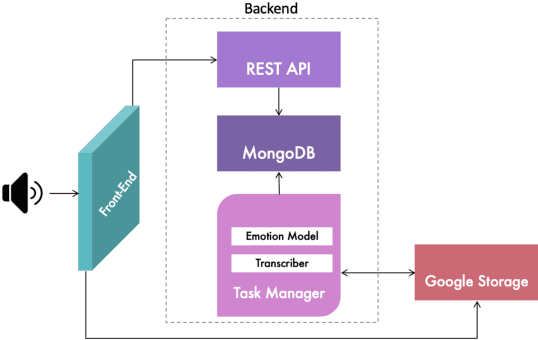
Emotions recognition is commonly employed for health assessment. However, the typical metric for evaluation in therapy is based on patient-doctor appraisal. This process can fall into the issue of subjectivity, while also requiring healthcare professionals to deal with copious amounts of information. Thus, machine learning algorithms can be a useful tool for the classification of emotions. While several models have been developed in this domain, there is a lack of userfriendly representations of the emotion classification systems for therapy. We propose a tool which enables users to take speech samples and identify a range of emotions (happy, sad, angry, surprised, neutral, clam, disgust, and fear) from audio elements through a machine learning model. The dashboard is designed based on local therapists' needs for intuitive representations of speech data in order to gain insights and informative analyses of their sessions with their patients.
* IEEE Vis 2020 Abstract
Semi-Supervised Convolutive NMF for Automatic Music Transcription
Feb 10, 2022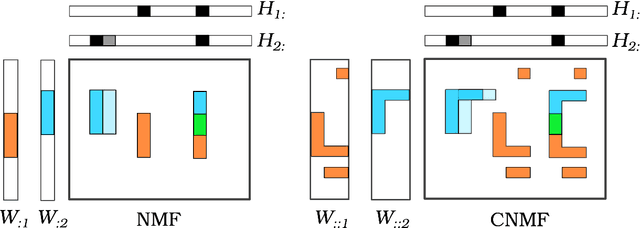
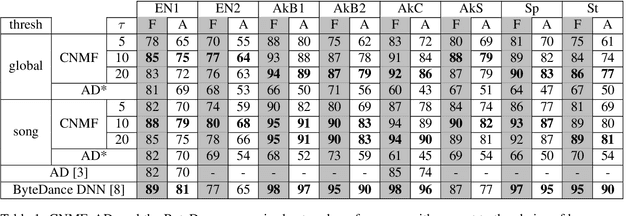
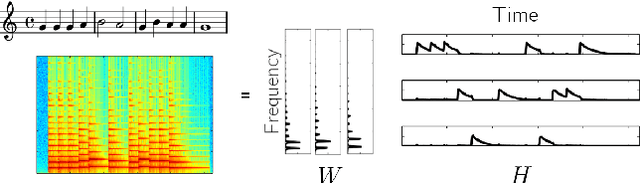
Automatic Music Transcription, which consists in transforming an audio recording of a musical performance into symbolic format, remains a difficult Music Information Retrieval task. In this work, we propose a semi-supervised approach using low-rank matrix factorization techniques, in particular Convolutive Nonnegative Matrix Factorization. In the semi-supervised setting, only a single recording of each individual notes is required. We show on the MAPS dataset that the proposed semi-supervised CNMF method performs better than state-of-the-art low-rank factorization techniques and a little worse than supervised deep learning state-of-the-art methods, while however suffering from generalization issues.
2D+3D facial expression recognition via embedded tensor manifold regularization
Jan 29, 2022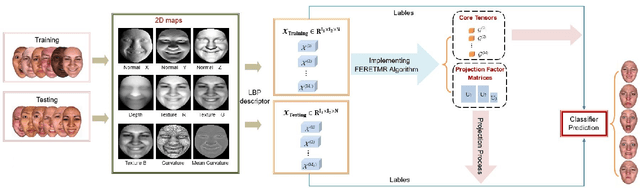
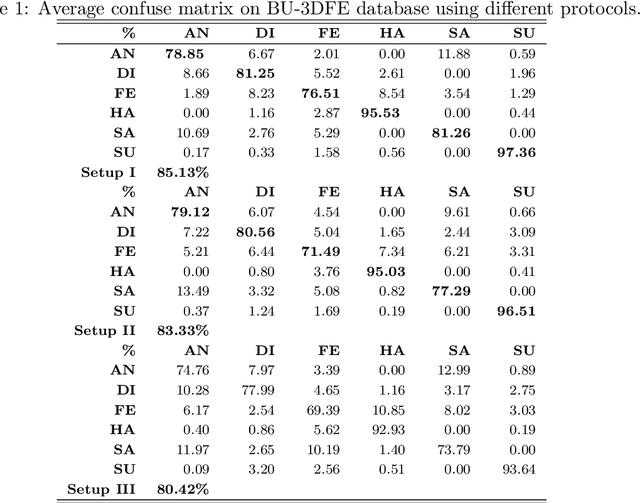
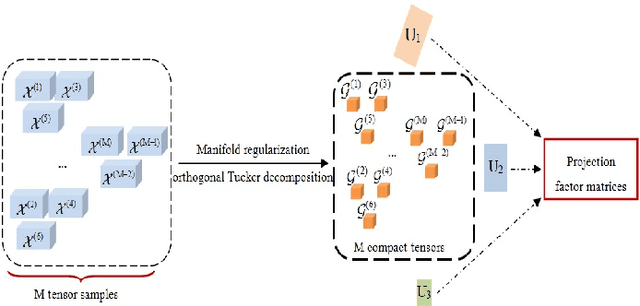
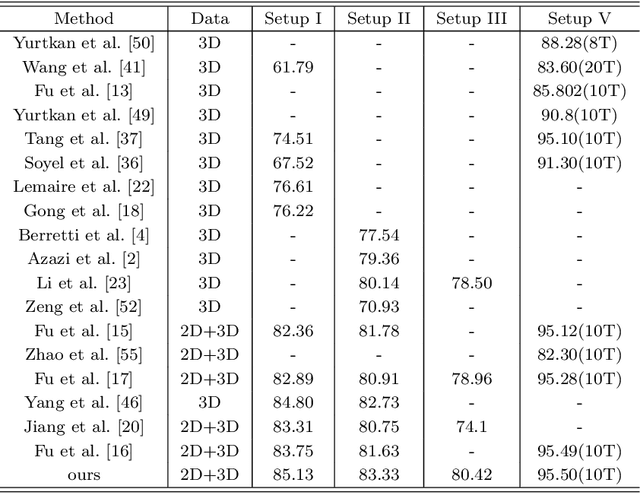
In this paper, a novel approach via embedded tensor manifold regularization for 2D+3D facial expression recognition (FERETMR) is proposed. Firstly, 3D tensors are constructed from 2D face images and 3D face shape models to keep the structural information and correlations. To maintain the local structure (geometric information) of 3D tensor samples in the low-dimensional tensors space during the dimensionality reduction, the $\ell_0$-norm of the core tensors and a tensor manifold regularization scheme embedded on core tensors are adopted via a low-rank truncated Tucker decomposition on the generated tensors. As a result, the obtained factor matrices will be used for facial expression classification prediction. To make the resulting tensor optimization more tractable, $\ell_1$-norm surrogate is employed to relax $\ell_0$-norm and hence the resulting tensor optimization problem has a nonsmooth objective function due to the $\ell_1$-norm and orthogonal constraints from the orthogonal Tucker decomposition. To efficiently tackle this tensor optimization problem, we establish the first-order optimality condition in terms of stationary points, and then design a block coordinate descent (BCD) algorithm with convergence analysis and the computational complexity. Numerical results on BU-3DFE database and Bosphorus databases demonstrate the effectiveness of our proposed approach.
TIGGER: Scalable Generative Modelling for Temporal Interaction Graphs
Mar 08, 2022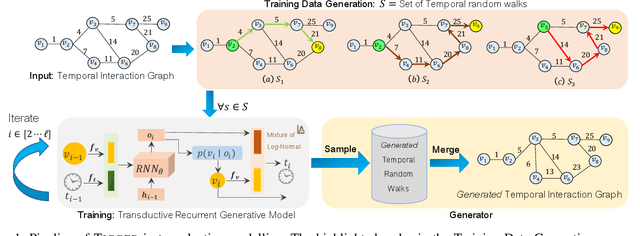
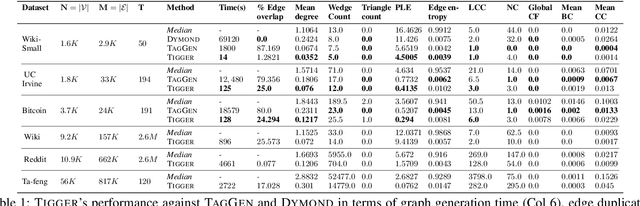

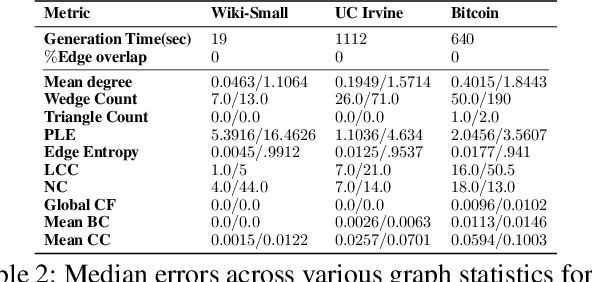
There has been a recent surge in learning generative models for graphs. While impressive progress has been made on static graphs, work on generative modeling of temporal graphs is at a nascent stage with significant scope for improvement. First, existing generative models do not scale with either the time horizon or the number of nodes. Second, existing techniques are transductive in nature and thus do not facilitate knowledge transfer. Finally, due to relying on one-to-one node mapping from source to the generated graph, existing models leak node identity information and do not allow up-scaling/down-scaling the source graph size. In this paper, we bridge these gaps with a novel generative model called TIGGER. TIGGER derives its power through a combination of temporal point processes with auto-regressive modeling enabling both transductive and inductive variants. Through extensive experiments on real datasets, we establish TIGGER generates graphs of superior fidelity, while also being up to 3 orders of magnitude faster than the state-of-the-art.