 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Local Feature Learning for 3D Point Cloud Processing using Unary-Pairwise Attention
Mar 01, 2022
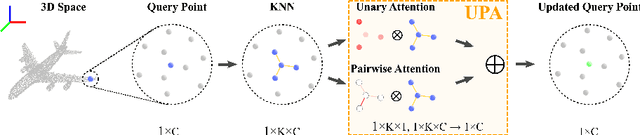
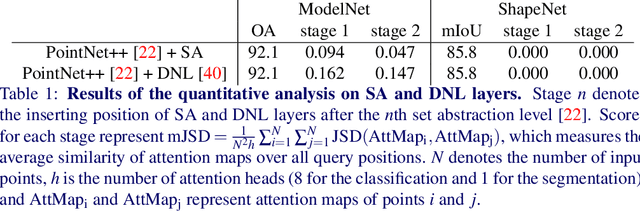
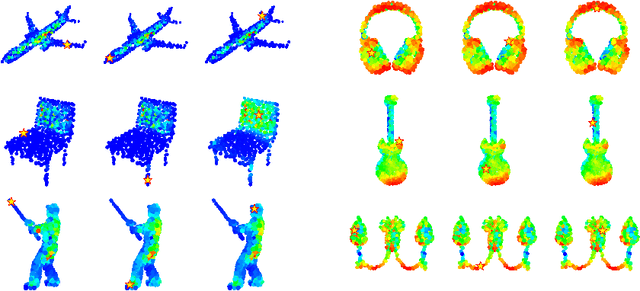
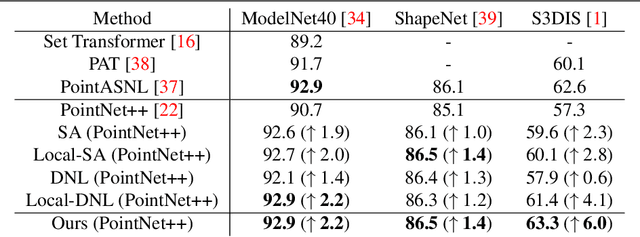
We present a simple but effective attention named the unary-pairwise attention (UPA) for modeling the relationship between 3D point clouds. Our idea is motivated by the analysis that the standard self-attention (SA) that operates globally tends to produce almost the same attention maps for different query positions, revealing difficulties for learning query-independent and query-dependent information jointly. Therefore, we reformulate the SA and propose query-independent (Unary) and query-dependent (Pairwise) components to facilitate the learning of both terms. In contrast to the SA, the UPA ensures query dependence via operating locally. Extensive experiments show that the UPA outperforms the SA consistently on various point cloud understanding tasks including shape classification, part segmentation, and scene segmentation. Moreover, simply equipping the popular PointNet++ method with the UPA even outperforms or is on par with the state-of-the-art attention-based approaches. In addition, the UPA systematically boosts the performance of both standard and modern networks when it is integrated into them as a compositional module.
Deep Co-supervision and Attention Fusion Strategy for Automatic COVID-19 Lung Infection Segmentation on CT Images
Dec 20, 2021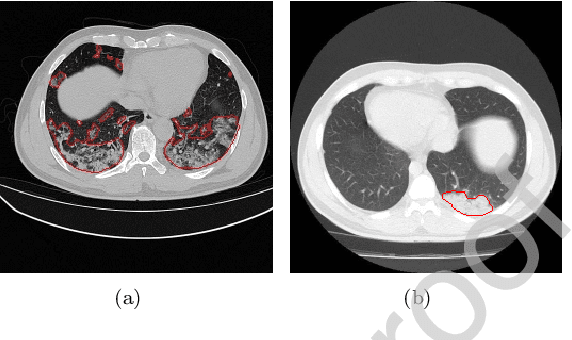
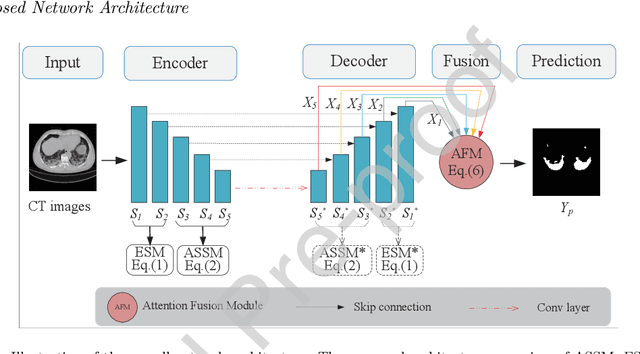
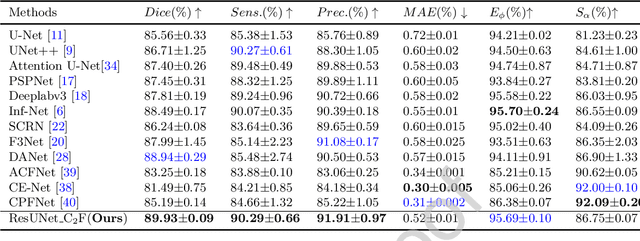
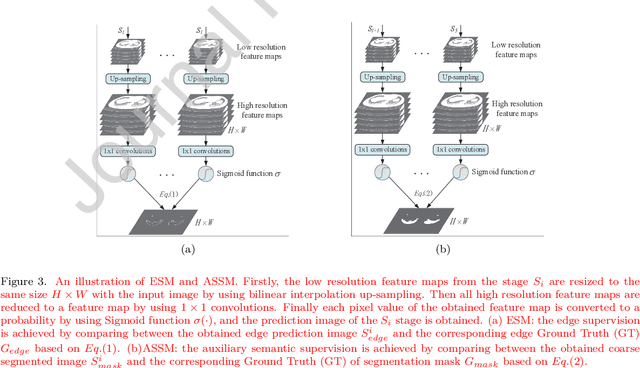
Due to the irregular shapes,various sizes and indistinguishable boundaries between the normal and infected tissues, it is still a challenging task to accurately segment the infected lesions of COVID-19 on CT images. In this paper, a novel segmentation scheme is proposed for the infections of COVID-19 by enhancing supervised information and fusing multi-scale feature maps of different levels based on the encoder-decoder architecture. To this end, a deep collaborative supervision (Co-supervision) scheme is proposed to guide the network learning the features of edges and semantics. More specifically, an Edge Supervised Module (ESM) is firstly designed to highlight low-level boundary features by incorporating the edge supervised information into the initial stage of down-sampling. Meanwhile, an Auxiliary Semantic Supervised Module (ASSM) is proposed to strengthen high-level semantic information by integrating mask supervised information into the later stage. Then an Attention Fusion Module (AFM) is developed to fuse multiple scale feature maps of different levels by using an attention mechanism to reduce the semantic gaps between high-level and low-level feature maps. Finally, the effectiveness of the proposed scheme is demonstrated on four various COVID-19 CT datasets. The results show that the proposed three modules are all promising. Based on the baseline (ResUnet), using ESM, ASSM, or AFM alone can respectively increase Dice metric by 1.12\%, 1.95\%,1.63\% in our dataset, while the integration by incorporating three models together can rise 3.97\%. Compared with the existing approaches in various datasets, the proposed method can obtain better segmentation performance in some main metrics, and can achieve the best generalization and comprehensive performance.
Learning to Evolve on Dynamic Graphs
Nov 13, 2021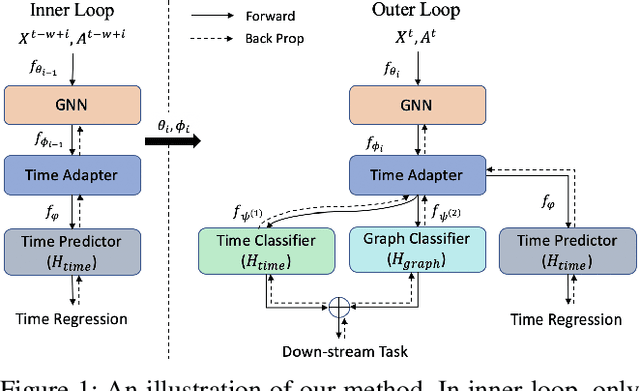

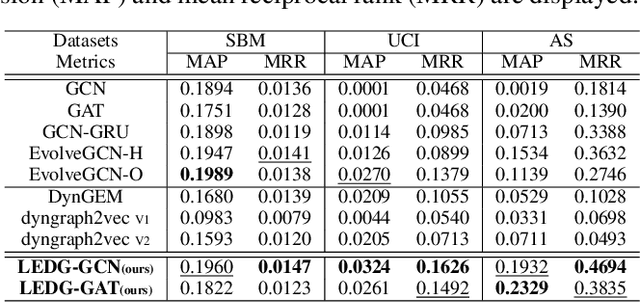
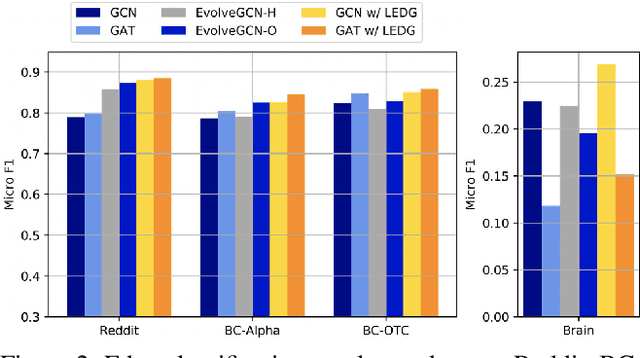
Representation learning in dynamic graphs is a challenging problem because the topology of graph and node features vary at different time. This requires the model to be able to effectively capture both graph topology information and temporal information. Most existing works are built on recurrent neural networks (RNNs), which are used to exact temporal information of dynamic graphs, and thus they inherit the same drawbacks of RNNs. In this paper, we propose Learning to Evolve on Dynamic Graphs (LEDG) - a novel algorithm that jointly learns graph information and time information. Specifically, our approach utilizes gradient-based meta-learning to learn updating strategies that have better generalization ability than RNN on snapshots. It is model-agnostic and thus can train any message passing based graph neural network (GNN) on dynamic graphs. To enhance the representation power, we disentangle the embeddings into time embeddings and graph intrinsic embeddings. We conduct experiments on various datasets and down-stream tasks, and the experimental results validate the effectiveness of our method.
Attribute Surrogates Learning and Spectral Tokens Pooling in Transformers for Few-shot Learning
Mar 17, 2022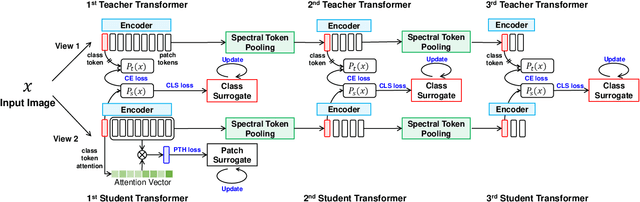
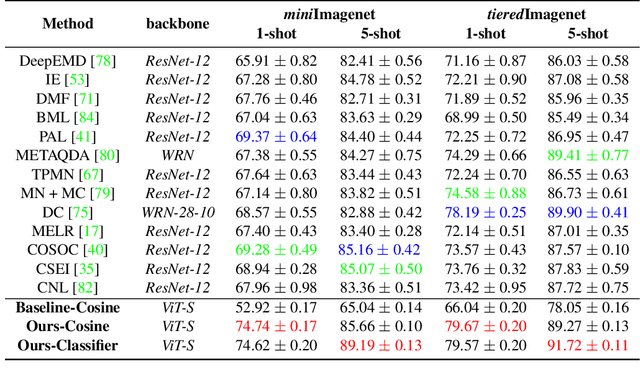
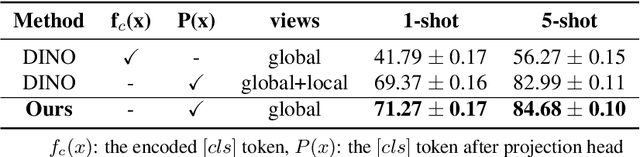

This paper presents new hierarchically cascaded transformers that can improve data efficiency through attribute surrogates learning and spectral tokens pooling. Vision transformers have recently been thought of as a promising alternative to convolutional neural networks for visual recognition. But when there is no sufficient data, it gets stuck in overfitting and shows inferior performance. To improve data efficiency, we propose hierarchically cascaded transformers that exploit intrinsic image structures through spectral tokens pooling and optimize the learnable parameters through latent attribute surrogates. The intrinsic image structure is utilized to reduce the ambiguity between foreground content and background noise by spectral tokens pooling. And the attribute surrogate learning scheme is designed to benefit from the rich visual information in image-label pairs instead of simple visual concepts assigned by their labels. Our Hierarchically Cascaded Transformers, called HCTransformers, is built upon a self-supervised learning framework DINO and is tested on several popular few-shot learning benchmarks. In the inductive setting, HCTransformers surpass the DINO baseline by a large margin of 9.7% 5-way 1-shot accuracy and 9.17% 5-way 5-shot accuracy on miniImageNet, which demonstrates HCTransformers are efficient to extract discriminative features. Also, HCTransformers show clear advantages over SOTA few-shot classification methods in both 5-way 1-shot and 5-way 5-shot settings on four popular benchmark datasets, including miniImageNet, tieredImageNet, FC100, and CIFAR-FS. The trained weights and codes are available at https://github.com/StomachCold/HCTransformers.
GISNet: Graph-Based Information Sharing Network For Vehicle Trajectory Prediction
Mar 22, 2020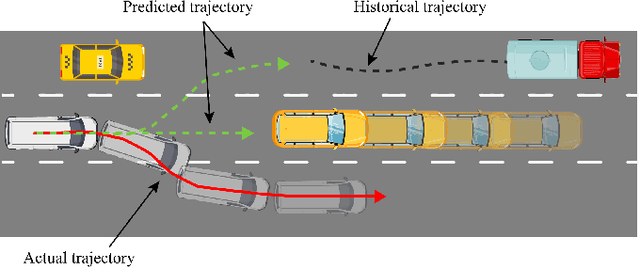
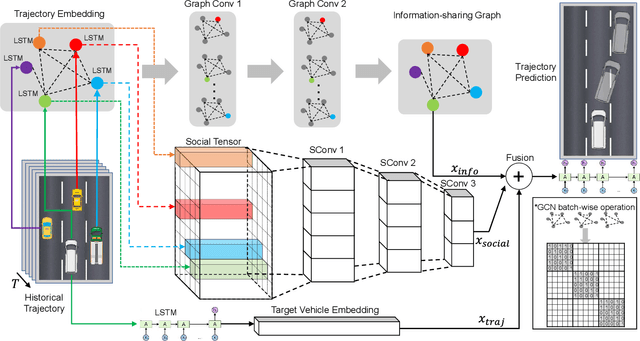
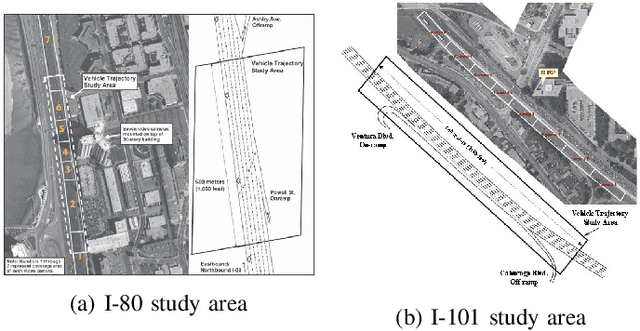
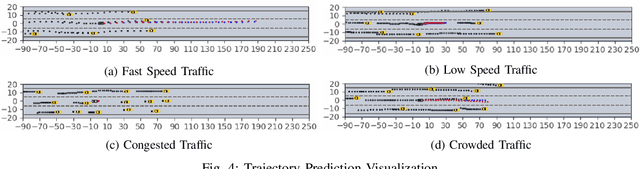
The trajectory prediction is a critical and challenging problem in the design of an autonomous driving system. Many AI-oriented companies, such as Google Waymo, Uber and DiDi, are investigating more accurate vehicle trajectory prediction algorithms. However, the prediction performance is governed by lots of entangled factors, such as the stochastic behaviors of surrounding vehicles, historical information of self-trajectory, and relative positions of neighbors, etc. In this paper, we propose a novel graph-based information sharing network (GISNet) that allows the information sharing between the target vehicle and its surrounding vehicles. Meanwhile, the model encodes the historical trajectory information of all the vehicles in the scene. Experiments are carried out on the public NGSIM US-101 and I-80 Dataset and the prediction performance is measured by the Root Mean Square Error (RMSE). The quantitative and qualitative experimental results show that our model significantly improves the trajectory prediction accuracy, by up to 50.00%, compared to existing models.
OPAL: Occlusion Pattern Aware Loss for Unsupervised Light Field Disparity Estimation
Mar 09, 2022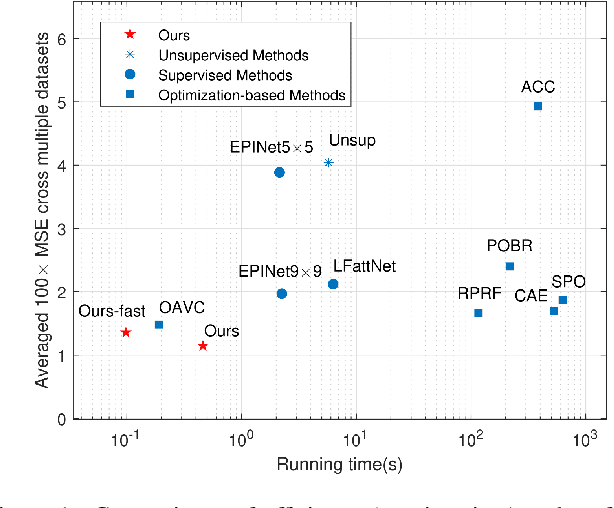
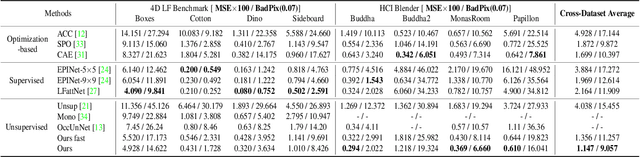
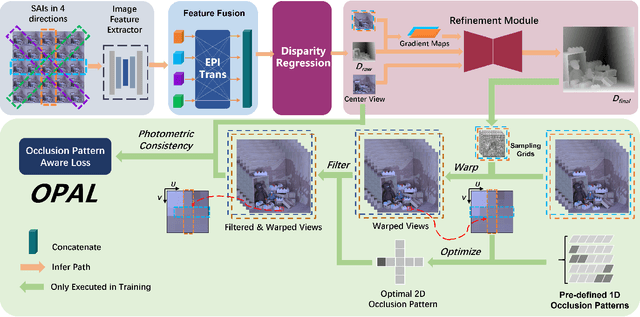
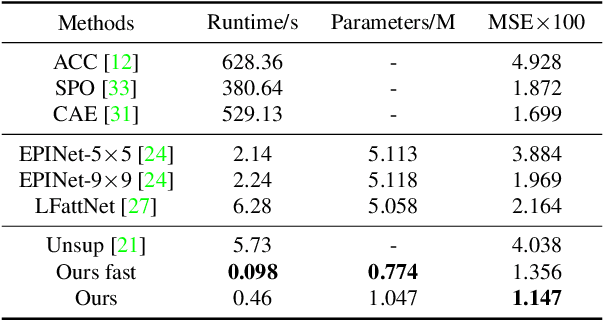
Light field disparity estimation is an essential task in computer vision with various applications. Although supervised learning-based methods have achieved both higher accuracy and efficiency than traditional optimization-based methods, the dependency on ground-truth disparity for training limits the overall generalization performance not to say for real-world scenarios where the ground-truth disparity is hard to capture. In this paper, we argue that unsupervised methods can achieve comparable accuracy, but, more importantly, much higher generalization capacity and efficiency than supervised methods. Specifically, we present the Occlusion Pattern Aware Loss, named OPAL, which successfully extracts and encodes the general occlusion patterns inherent in the light field for loss calculation. OPAL enables: i) accurate and robust estimation by effectively handling occlusions without using any ground-truth information for training and ii) much efficient performance by significantly reducing the network parameters required for accurate inference. Besides, a transformer-based network and a refinement module are proposed for achieving even more accurate results. Extensive experiments demonstrate our method not only significantly improves the accuracy compared with the SOTA unsupervised methods, but also possesses strong generalization capacity, even for real-world data, compared with supervised methods. Our code will be made publicly available.
Human and Machine Action Prediction Independent of Object Information
Apr 22, 2020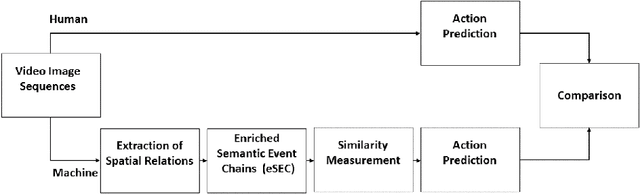
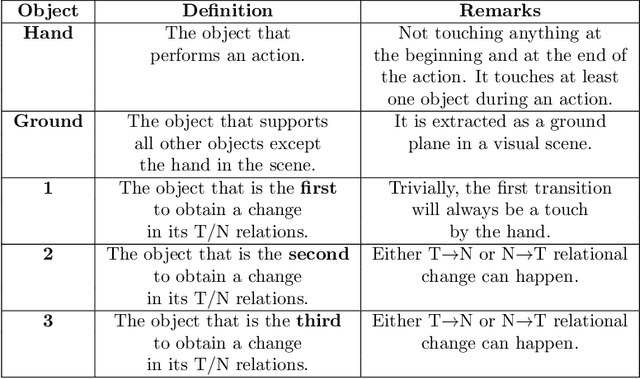

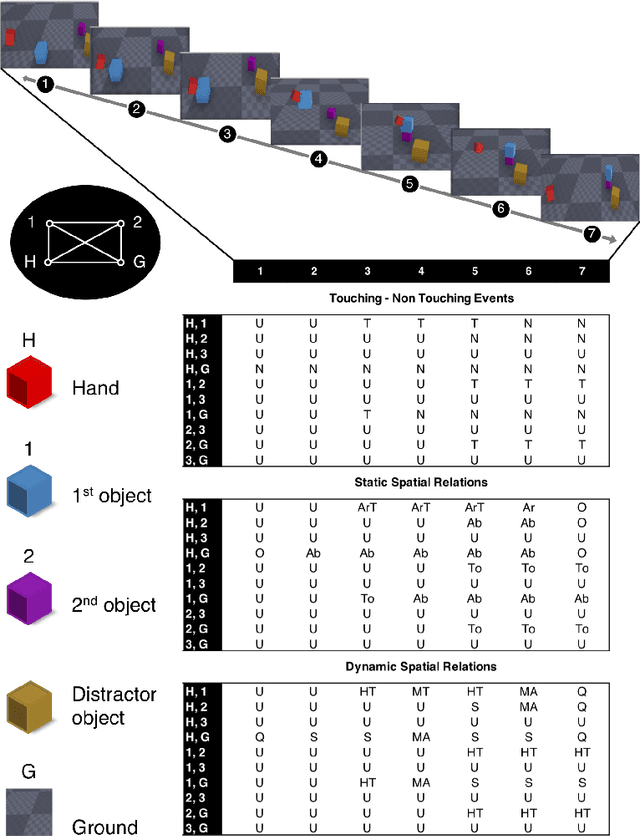
Predicting other people's action is key to successful social interactions, enabling us to adjust our own behavior to the consequence of the others' future actions. Studies on action recognition have focused on the importance of individual visual features of objects involved in an action and its context. Humans, however, recognize actions on unknown objects or even when objects are imagined (pantomime). Other cues must thus compensate the lack of recognizable visual object features. Here, we focus on the role of inter-object relations that change during an action. We designed a virtual reality setup and tested recognition speed for 10 different manipulation actions on 50 subjects. All objects were abstracted by emulated cubes so the actions could not be inferred using object information. Instead, subjects had to rely only on the information that comes from the changes in the spatial relations that occur between those cubes. In spite of these constraints, our results show the subjects were able to predict actions in, on average, less than 64% of the action's duration. We employed a computational model -an enriched Semantic Event Chain (eSEC)- incorporating the information of spatial relations, specifically (a) objects' touching/untouching, (b) static spatial relations between objects and (c) dynamic spatial relations between objects. Trained on the same actions as those observed by subjects, the model successfully predicted actions even better than humans. Information theoretical analysis shows that eSECs optimally use individual cues, whereas humans presumably mostly rely on a mixed-cue strategy, which takes longer until recognition. Providing a better cognitive basis of action recognition may, on one hand improve our understanding of related human pathologies and, on the other hand, also help to build robots for conflict-free human-robot cooperation. Our results open new avenues here.
Community detection and percolation of information in a geometric setting
Jun 28, 2020We make the first steps towards generalizing the theory of stochastic block models, in the sparse regime, towards a model where the discrete community structure is replaced by an underlying geometry. We consider a geometric random graph over a homogeneous metric space where the probability of two vertices to be connected is an arbitrary function of the distance. We give sufficient conditions under which the locations can be recovered (up to an isomorphism of the space) in the sparse regime. Moreover, we define a geometric counterpart of the model of flow of information on trees, due to Mossel and Peres, in which one considers a branching random walk on a sphere and the goal is to recover the location of the root based on the locations of leaves. We give some sufficient conditions for percolation and for non-percolation of information in this model.
DeepTx: Deep Learning Beamforming with Channel Prediction
Feb 21, 2022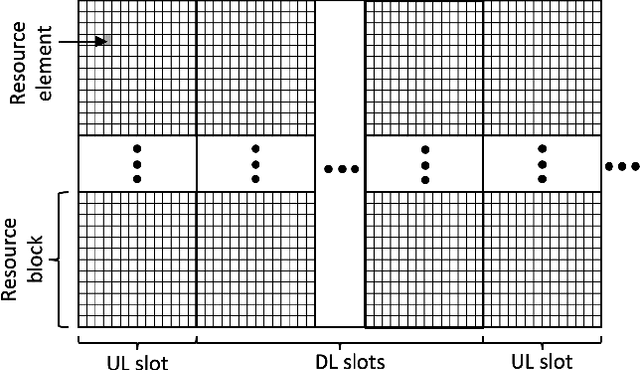
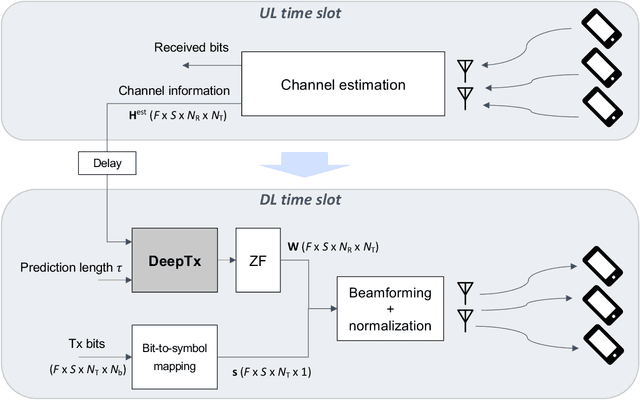
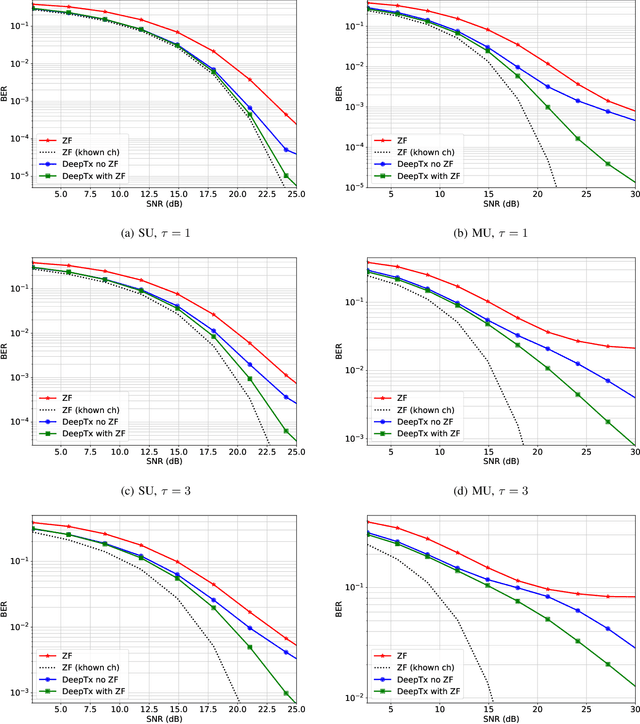
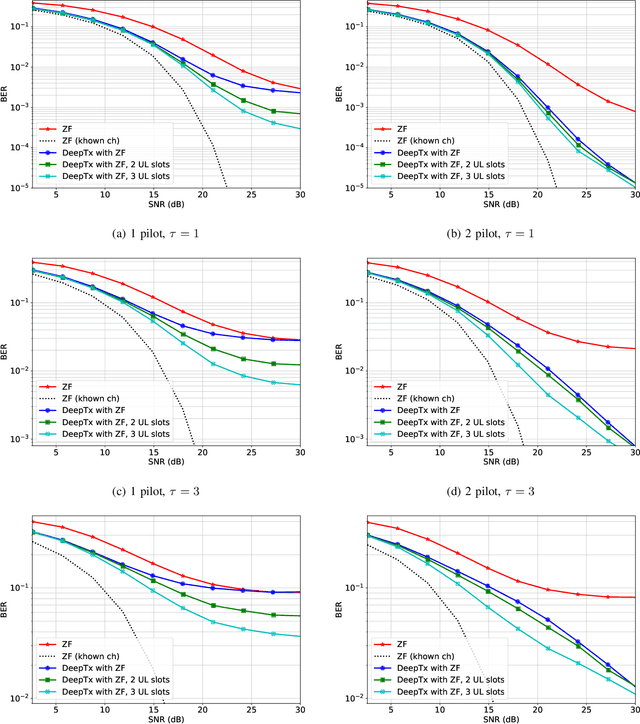
Machine learning algorithms have recently been considered for many tasks in the field of wireless communications. Previously, we have proposed the use of a deep fully convolutional neural network (CNN) for receiver processing and shown it to provide considerable performance gains. In this study, we focus on machine learning algorithms for the transmitter. In particular, we consider beamforming and propose a CNN which, for a given uplink channel estimate as input, outputs downlink channel information to be used for beamforming. The CNN is trained in a supervised manner considering both uplink and downlink transmissions with a loss function that is based on UE receiver performance. The main task of the neural network is to predict the channel evolution between uplink and downlink slots, but it can also learn to handle inefficiencies and errors in the whole chain, including the actual beamforming phase. The provided numerical experiments demonstrate the improved beamforming performance.
Image Separation with Side Information: A Connected Auto-Encoders Based Approach
Sep 16, 2020
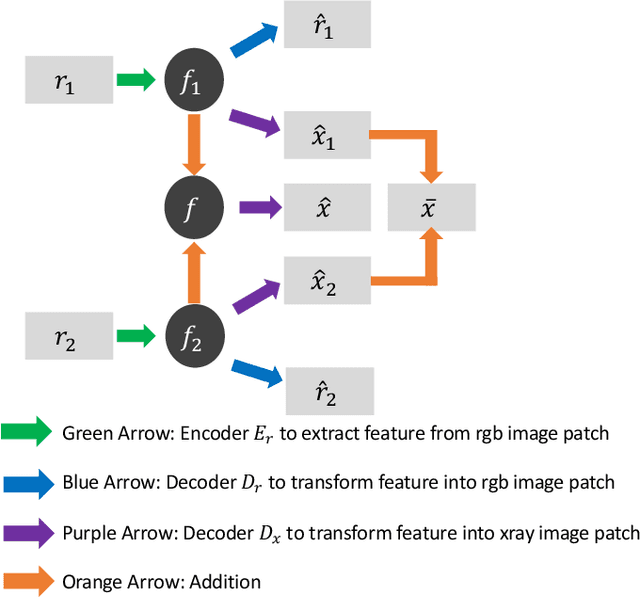
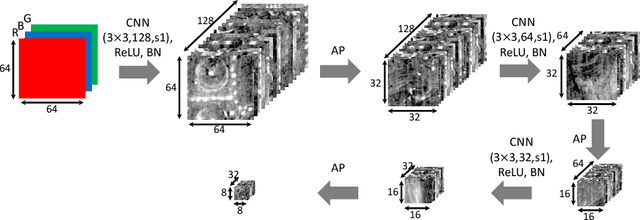
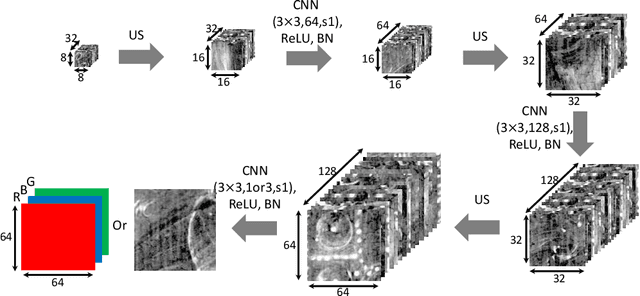
X-radiography (X-ray imaging) is a widely used imaging technique in art investigation. It can provide information about the condition of a painting as well as insights into an artist's techniques and working methods, often revealing hidden information invisible to the naked eye. In this paper, we deal with the problem of separating mixed X-ray images originating from the radiography of double-sided paintings. Using the visible color images (RGB images) from each side of the painting, we propose a new Neural Network architecture, based upon 'connected' auto-encoders, designed to separate the mixed X-ray image into two simulated X-ray images corresponding to each side. In this proposed architecture, the convolutional auto encoders extract features from the RGB images. These features are then used to (1) reproduce both of the original RGB images, (2) reconstruct the hypothetical separated X-ray images, and (3) regenerate the mixed X-ray image. The algorithm operates in a totally self-supervised fashion without requiring a sample set that contains both the mixed X-ray images and the separated ones. The methodology was tested on images from the double-sided wing panels of the \textsl{Ghent Altarpiece}, painted in 1432 by the brothers Hubert and Jan van Eyck. These tests show that the proposed approach outperforms other state-of-the-art X-ray image separation methods for art investigation applications.