 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VISOLO: Grid-Based Space-Time Aggregation for Efficient Online Video Instance Segmentation
Dec 08, 2021
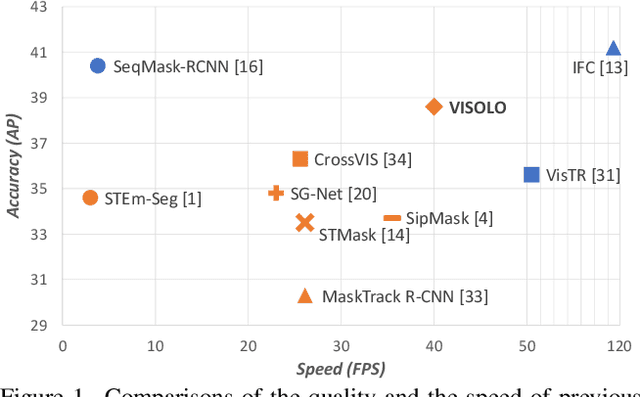
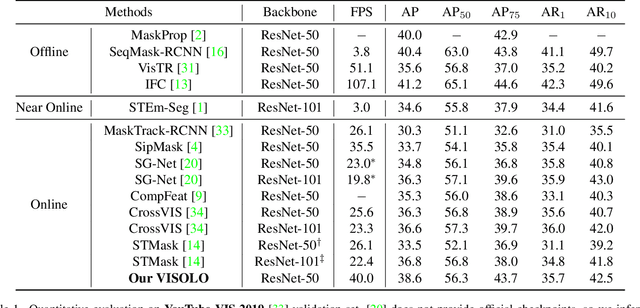
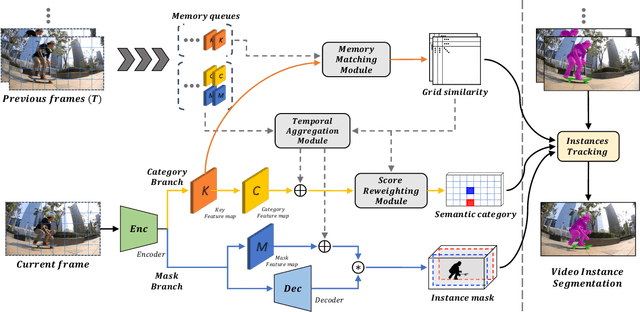
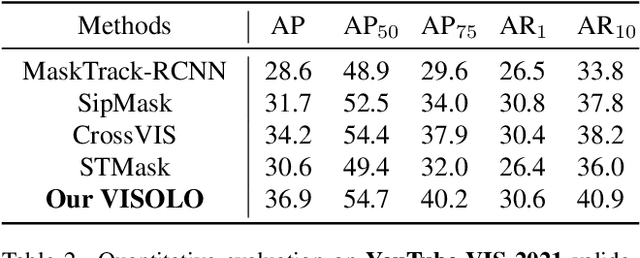
For online video instance segmentation (VIS), fully utilizing the information from previous frames in an efficient manner is essential for real-time applications. Most previous methods follow a two-stage approach requiring additional computations such as RPN and RoIAlign, and do not fully exploit the available information in the video for all subtasks in VIS. In this paper, we propose a novel single-stage framework for online VIS built based on the grid structured feature representation. The grid-based features allow us to employ fully convolutional networks for real-time processing, and also to easily reuse and share features within different components. We also introduce cooperatively operating modules that aggregate information from available frames, in order to enrich the features for all subtasks in VIS. Our design fully takes advantage of previous information in a grid form for all tasks in VIS in an efficient way, and we achieved the new state-of-the-art accuracy (38.6 AP and 36.9 AP) and speed (40.0 FPS) on YouTube-VIS 2019 and 2021 datasets among online VIS methods.
Energy Efficiency for Proactive Eavesdropping in Cooperative Cognitive Radio Networks
Jan 10, 2022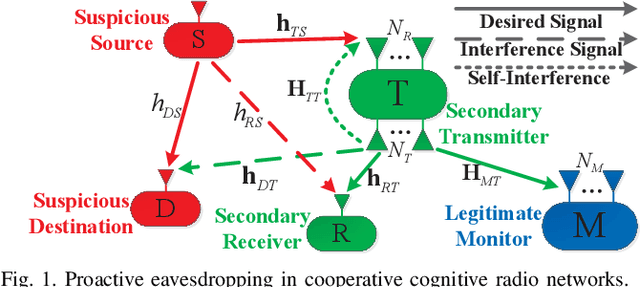
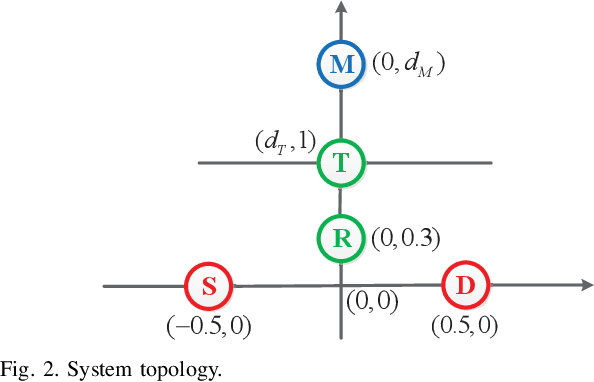
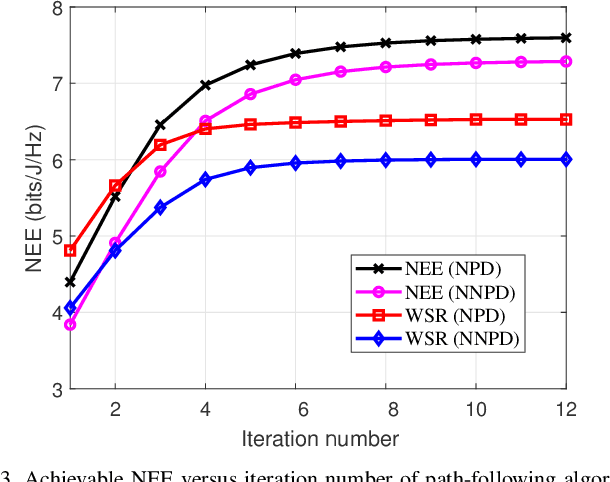
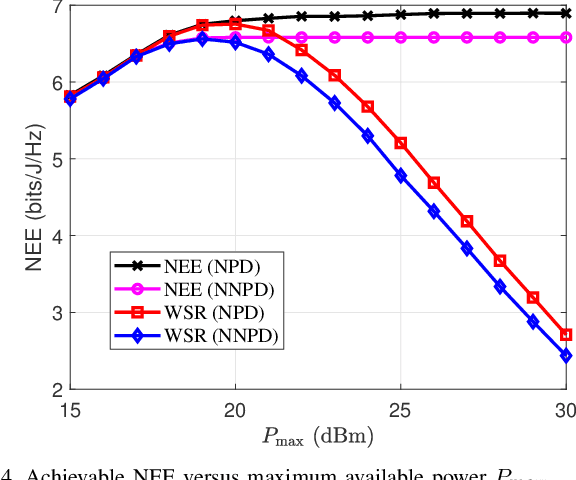
This paper investigates a distant proactive eavesdropping system in cooperative cognitive radio (CR) networks. Specifically, an amplify-and-forward (AF) full-duplex (FD) secondary transmitter assists to relay the received signal from suspicious users to legitimate monitor for wireless information surveillance. In return, the secondary transmitter is granted to share the spectrum belonging to the suspicious users for its own information transmission. To improve the eavesdropping, the transmitted secondary user's signal can also be used as a jamming signal to moderate the data rate of the suspicious link. We consider two cases, i.e., non-negligible processing delay (NNPD) and negligible processing delay (NPD) at secondary transmitter. Our target is to maximize network energy efficiency (NEE) via jointly optimizing the AF relay matrix and precoding vector at the secondary transmitter, as well as the receiver combining vector at monitor, subject to the maximum power constraint at the secondary transmitter and minimum data rate requirement of the secondary user. We also guarantee that the achievable data rate of the eavesdropping link should be no less than that of the suspicious link for efficient surveillance. Due to the non-convexity of the formulated NEE maximization problem, we develop an efficient path-following algorithm and a robust alternating optimization (AO) method as solutions under perfect and imperfect channel state information (CSI) conditions, respectively. We also analyze the convergence and computational complexity of the proposed schemes. Numerical results are provided to validate the effectiveness of our proposed schemes.
Do You Do Yoga? Understanding Twitter Users' Types and Motivations using Social and Textual Information
Jan 27, 2021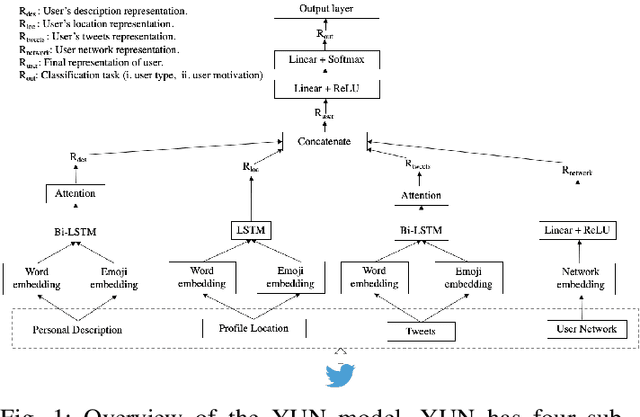
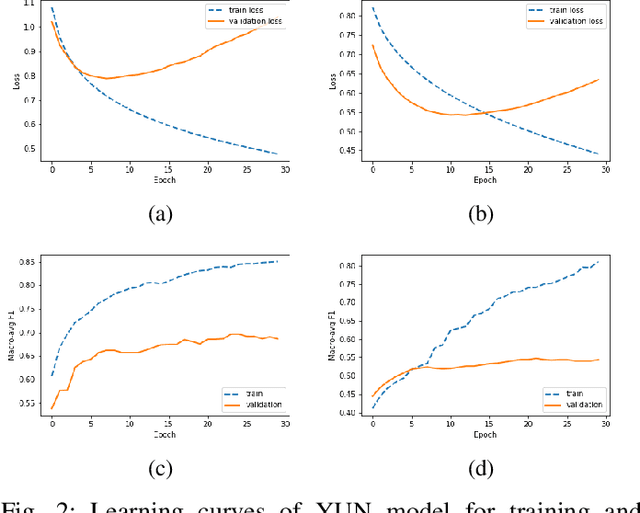
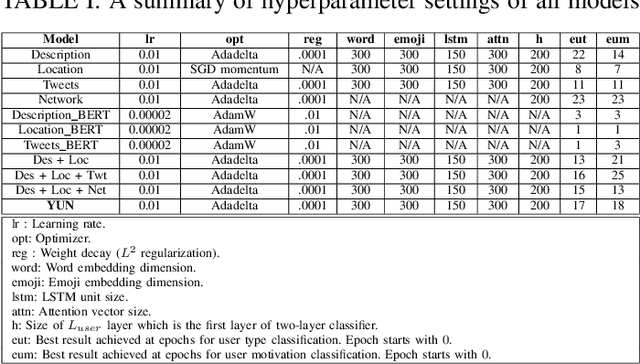
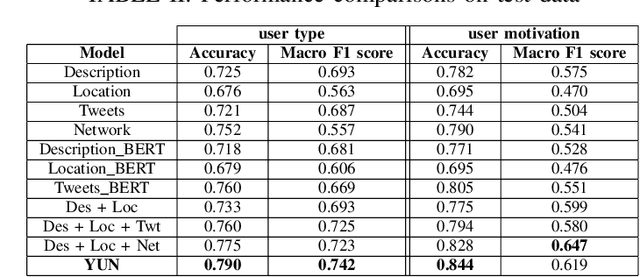
Leveraging social media data to understand people's lifestyle choices is an exciting domain to explore but requires a multiview formulation of the data. In this paper, we propose a joint embedding model based on the fusion of neural networks with attention mechanism by incorporating social and textual information of users to understand their activities and motivations. We use well-being related tweets from Twitter, focusing on 'Yoga'. We demonstrate our model on two downstream tasks: (i) finding user type such as either practitioner or promotional (promoting yoga studio/gym), other; (ii) finding user motivation i.e. health benefit, spirituality, love to tweet/retweet about yoga but do not practice yoga.
Point2Seq: Detecting 3D Objects as Sequences
Mar 25, 2022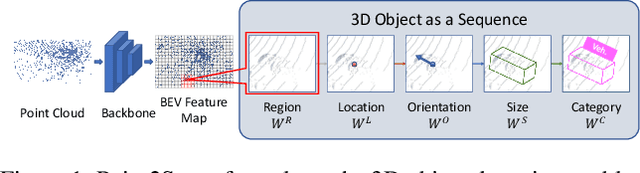
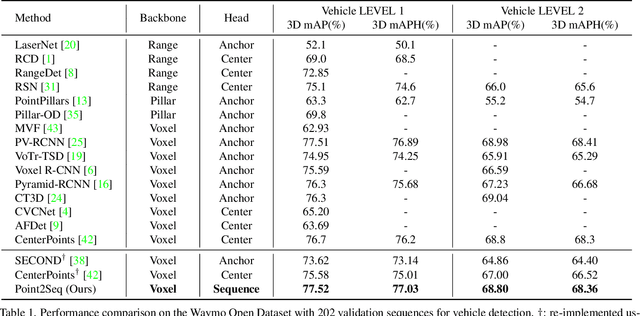
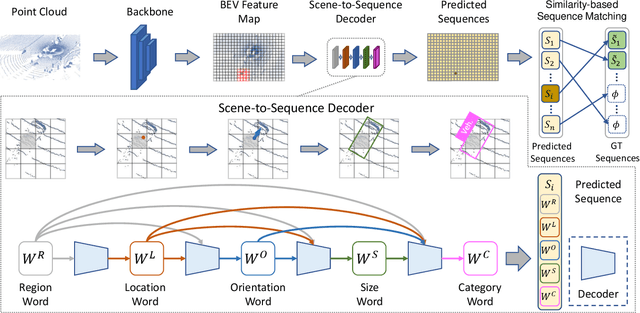
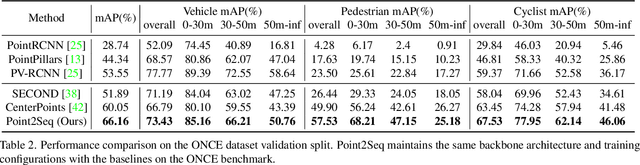
We present a simple and effective framework, named Point2Seq, for 3D object detection from point clouds. In contrast to previous methods that normally {predict attributes of 3D objects all at once}, we expressively model the interdependencies between attributes of 3D objects, which in turn enables a better detection accuracy. Specifically, we view each 3D object as a sequence of words and reformulate the 3D object detection task as decoding words from 3D scenes in an auto-regressive manner. We further propose a lightweight scene-to-sequence decoder that can auto-regressively generate words conditioned on features from a 3D scene as well as cues from the preceding words. The predicted words eventually constitute a set of sequences that completely describe the 3D objects in the scene, and all the predicted sequences are then automatically assigned to the respective ground truths through similarity-based sequence matching. Our approach is conceptually intuitive and can be readily plugged upon most existing 3D-detection backbones without adding too much computational overhead; the sequential decoding paradigm we proposed, on the other hand, can better exploit information from complex 3D scenes with the aid of preceding predicted words. Without bells and whistles, our method significantly outperforms previous anchor- and center-based 3D object detection frameworks, yielding the new state of the art on the challenging ONCE dataset as well as the Waymo Open Dataset. Code is available at \url{https://github.com/ocNflag/point2seq}.
Towards Web Phishing Detection Limitations and Mitigation
Apr 03, 2022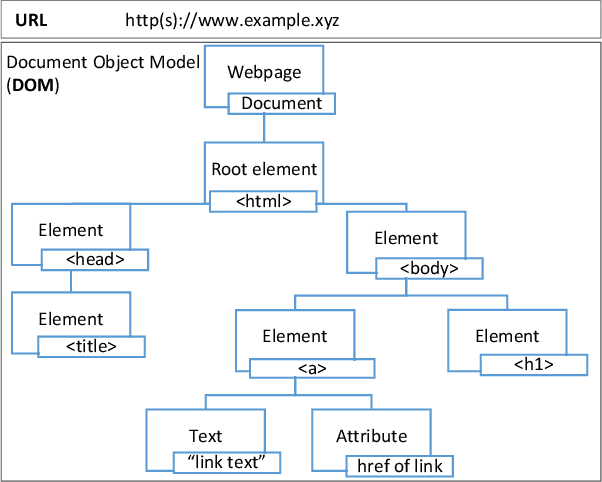

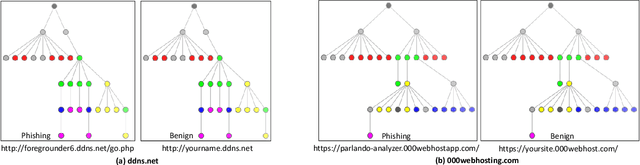
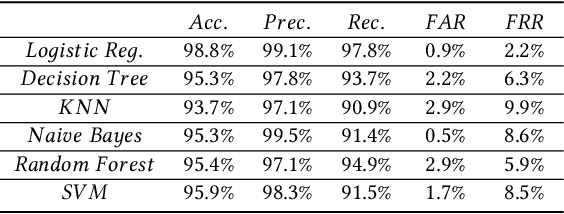
Web phishing remains a serious cyber threat responsible for most data breaches. Machine Learning (ML)-based anti-phishing detectors are seen as an effective countermeasure, and are increasingly adopted by web-browsers and software products. However, with an average of 10K phishing links reported per hour to platforms such as PhishTank and VirusTotal (VT), the deficiencies of such ML-based solutions are laid bare. We first explore how phishing sites bypass ML-based detection with a deep dive into 13K phishing pages targeting major brands such as Facebook. Results show successful evasion is caused by: (1) use of benign services to obscure phishing URLs; (2) high similarity between the HTML structures of phishing and benign pages; (3) hiding the ultimate phishing content within Javascript and running such scripts only on the client; (4) looking beyond typical credentials and credit cards for new content such as IDs and documents; (5) hiding phishing content until after human interaction. We attribute the root cause to the dependency of ML-based models on the vertical feature space (webpage content). These solutions rely only on what phishers present within the page itself. Thus, we propose Anti-SubtlePhish, a more resilient model based on logistic regression. The key augmentation is the inclusion of a horizontal feature space, which examines correlation variables between the final render of suspicious pages against what trusted services have recorded (e.g., PageRank). To defeat (1) and (2), we correlate information between WHOIS, PageRank, and page analytics. To combat (3), (4) and (5), we correlate features after rendering the page. Experiments with 100K phishing/benign sites show promising accuracy (98.8%). We also obtained 100% accuracy against 0-day phishing pages that were manually crafted, comparing well to the 0% recorded by VT vendors over the first four days.
Coloring the Blank Slate: Pre-training Imparts a Hierarchical Inductive Bias to Sequence-to-sequence Models
Mar 17, 2022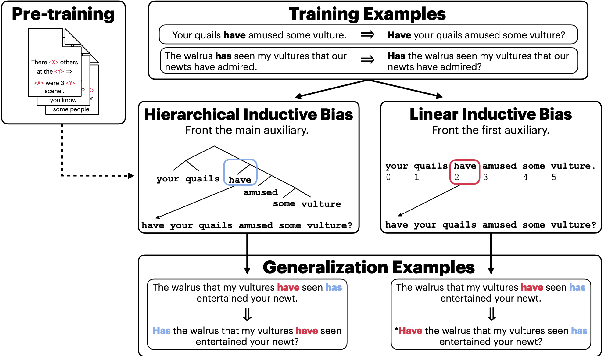


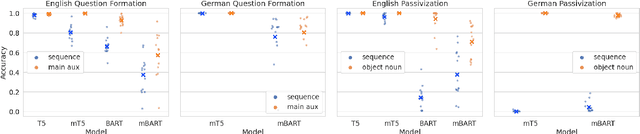
Relations between words are governed by hierarchical structure rather than linear ordering. Sequence-to-sequence (seq2seq) models, despite their success in downstream NLP applications, often fail to generalize in a hierarchy-sensitive manner when performing syntactic transformations - for example, transforming declarative sentences into questions. However, syntactic evaluations of seq2seq models have only observed models that were not pre-trained on natural language data before being trained to perform syntactic transformations, in spite of the fact that pre-training has been found to induce hierarchical linguistic generalizations in language models; in other words, the syntactic capabilities of seq2seq models may have been greatly understated. We address this gap using the pre-trained seq2seq models T5 and BART, as well as their multilingual variants mT5 and mBART. We evaluate whether they generalize hierarchically on two transformations in two languages: question formation and passivization in English and German. We find that pre-trained seq2seq models generalize hierarchically when performing syntactic transformations, whereas models trained from scratch on syntactic transformations do not. This result presents evidence for the learnability of hierarchical syntactic information from non-annotated natural language text while also demonstrating that seq2seq models are capable of syntactic generalization, though only after exposure to much more language data than human learners receive.
TARexp: A Python Framework for Technology-Assisted Review Experiments
Feb 23, 2022
Technology-assisted review (TAR) is an important industrial application of information retrieval (IR) and machine learning (ML). While a small TAR research community exists, the complexity of TAR software and workflows is a major barrier to entry. Drawing on past open source TAR efforts, as well as design patterns from the IR and ML open source software, we present an open source Python framework for conducting experiments on TAR algorithms. Key characteristics of this framework are declarative representations of workflows and experiment plans, the ability for components to play variable numbers of workflow roles, and state maintenance and restart capabilities. Users can draw on reference implementations of standard TAR algorithms while incorporating novel components to explore their research interests. The framework is available at https://github.com/eugene-yang/tarexp.
Generalized Bayesian Additive Regression Trees Models: Beyond Conditional Conjugacy
Feb 20, 2022

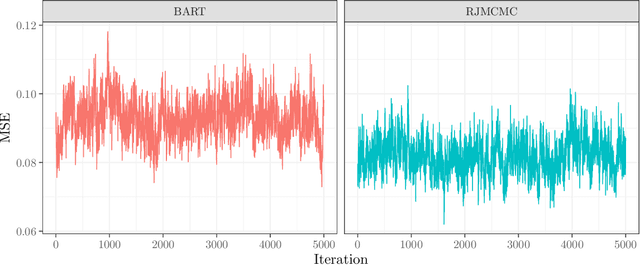
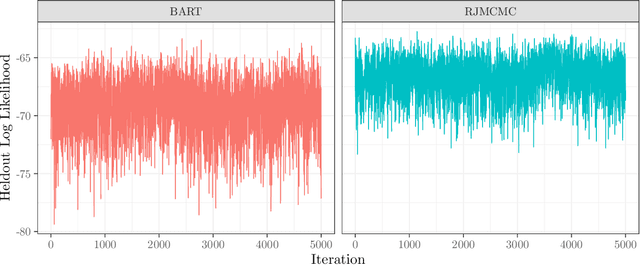
Bayesian additive regression trees have seen increased interest in recent years due to their ability to combine machine learning techniques with principled uncertainty quantification. The Bayesian backfitting algorithm used to fit BART models, however, limits their application to a small class of models for which conditional conjugacy exists. In this article, we greatly expand the domain of applicability of BART to arbitrary \emph{generalized BART} models by introducing a very simple, tuning-parameter-free, reversible jump Markov chain Monte Carlo algorithm. Our algorithm requires only that the user be able to compute the likelihood and (optionally) its gradient and Fisher information. The potential applications are very broad; we consider examples in survival analysis, structured heteroskedastic regression, and gamma shape regression.
A Unified Framework for Generic, Query-Focused, Privacy Preserving and Update Summarization using Submodular Information Measures
Oct 12, 2020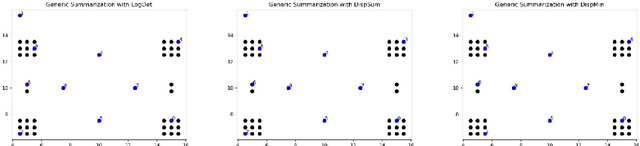
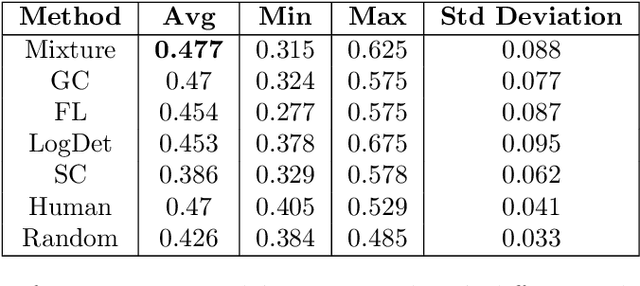
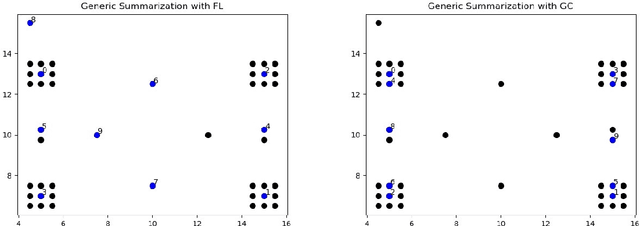
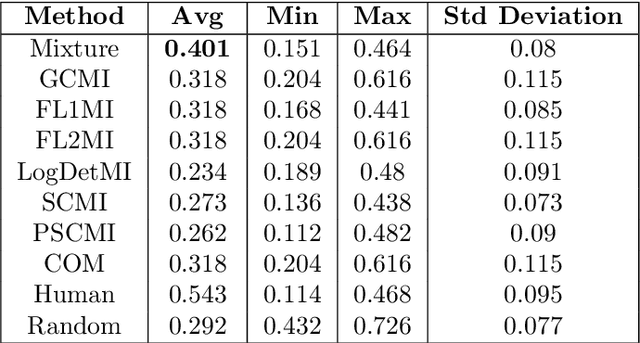
We study submodular information measures as a rich framework for generic, query-focused, privacy sensitive, and update summarization tasks. While past work generally treats these problems differently ({\em e.g.}, different models are often used for generic and query-focused summarization), the submodular information measures allow us to study each of these problems via a unified approach. We first show that several previous query-focused and update summarization techniques have, unknowingly, used various instantiations of the aforesaid submodular information measures, providing evidence for the benefit and naturalness of these models. We then carefully study and demonstrate the modelling capabilities of the proposed functions in different settings and empirically verify our findings on both a synthetic dataset and an existing real-world image collection dataset (that has been extended by adding concept annotations to each image making it suitable for this task) and will be publicly released. We employ a max-margin framework to learn a mixture model built using the proposed instantiations of submodular information measures and demonstrate the effectiveness of our approach. While our experiments are in the context of image summarization, our framework is generic and can be easily extended to other summarization settings (e.g., videos or documents).
ARM: Any-Time Super-Resolution Method
Mar 21, 2022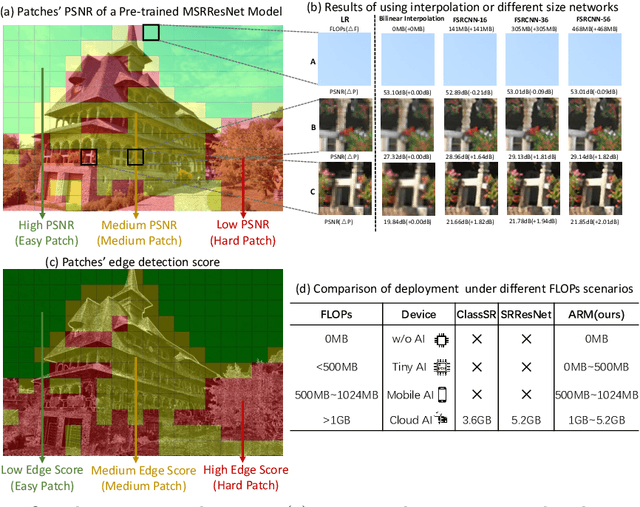
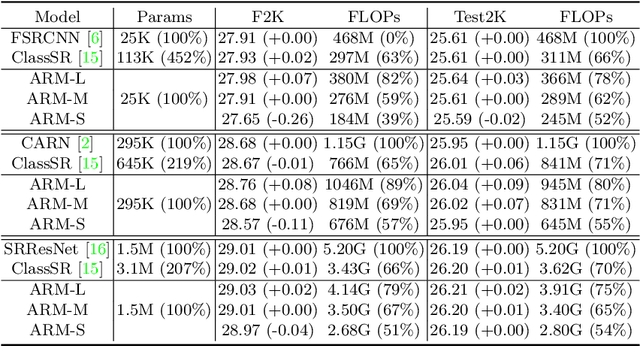

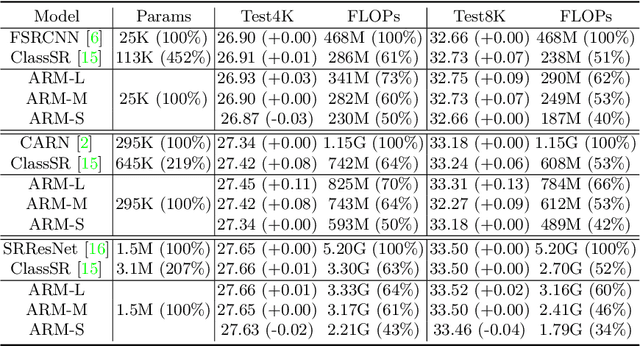
This paper proposes an Any-time super-Resolution Method (ARM) to tackle the over-parameterized single image super-resolution (SISR) models. Our ARM is motivated by three observations: (1) The performance of different image patches varies with SISR networks of different sizes. (2) There is a tradeoff between computation overhead and performance of the reconstructed image. (3) Given an input image, its edge information can be an effective option to estimate its PSNR. Subsequently, we train an ARM supernet containing SISR subnets of different sizes to deal with image patches of various complexity. To that effect, we construct an Edge-to-PSNR lookup table that maps the edge score of an image patch to the PSNR performance for each subnet, together with a set of computation costs for the subnets. In the inference, the image patches are individually distributed to different subnets for a better computation-performance tradeoff. Moreover, each SISR subnet shares weights of the ARM supernet, thus no extra parameters are introduced. The setting of multiple subnets can well adapt the computational cost of SISR model to the dynamically available hardware resources, allowing the SISR task to be in service at any time. Extensive experiments on resolution datasets of different sizes with popular SISR networks as backbones verify the effectiveness and the versatility of our ARM. The source code is available at \url{https://github.com/chenbong/ARM-Net}.