 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Social Learning under Randomized Collaborations
Jan 26, 2022
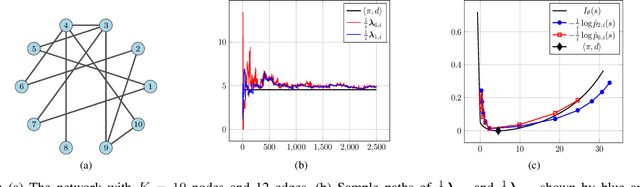
We study a social learning scheme where at every time instant, each agent chooses to receive information from one of its neighbors at random. We show that under this sparser communication scheme, the agents learn the truth eventually and the asymptotic convergence rate remains the same as the standard algorithms which use more communication resources. We also derive large deviation estimates of the log-belief ratios for a special case where each agent replaces its belief with that of the chosen neighbor.
An Audio-Visual Attention Based Multimodal Network for Fake Talking Face Videos Detection
Mar 10, 2022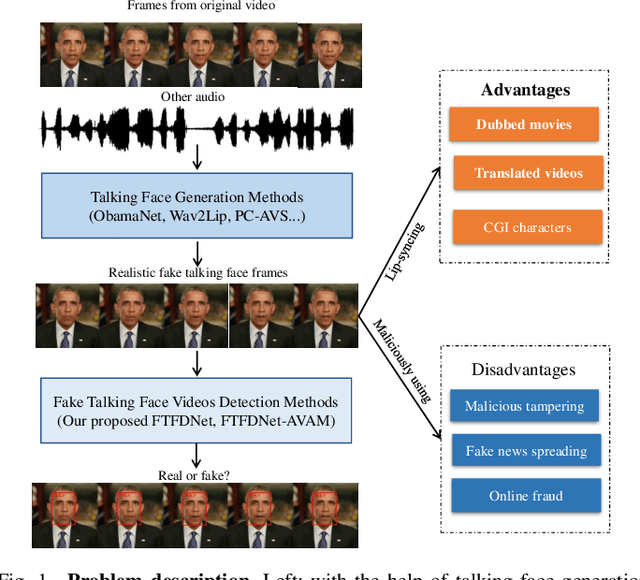

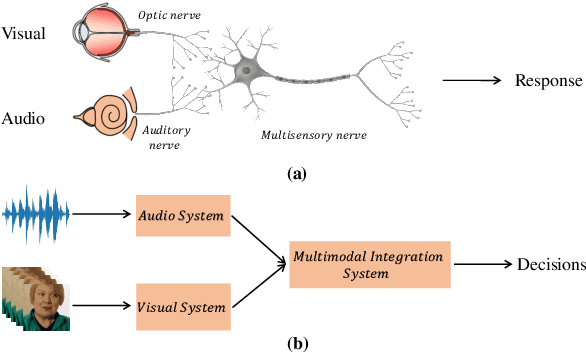
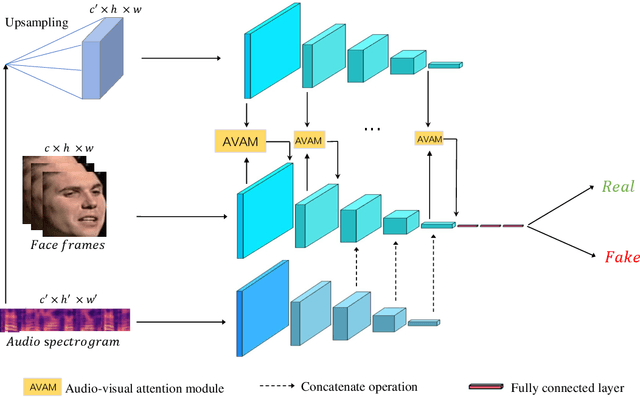
DeepFake based digital facial forgery is threatening the public media security, especially when lip manipulation has been used in talking face generation, the difficulty of fake video detection is further improved. By only changing lip shape to match the given speech, the facial features of identity is hard to be discriminated in such fake talking face videos. Together with the lack of attention on audio stream as the prior knowledge, the detection failure of fake talking face generation also becomes inevitable. Inspired by the decision-making mechanism of human multisensory perception system, which enables the auditory information to enhance post-sensory visual evidence for informed decisions output, in this study, a fake talking face detection framework FTFDNet is proposed by incorporating audio and visual representation to achieve more accurate fake talking face videos detection. Furthermore, an audio-visual attention mechanism (AVAM) is proposed to discover more informative features, which can be seamlessly integrated into any audio-visual CNN architectures by modularization. With the additional AVAM, the proposed FTFDNet is able to achieve a better detection performance on the established dataset (FTFDD). The evaluation of the proposed work has shown an excellent performance on the detection of fake talking face videos, which is able to arrive at a detection rate above 97%.
A Transformer-based Network for Deformable Medical Image Registration
Feb 24, 2022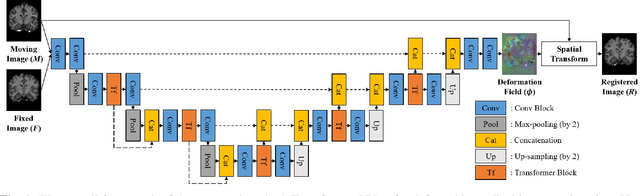
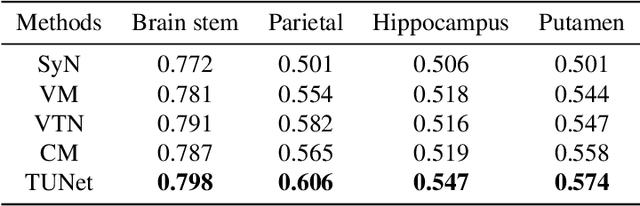
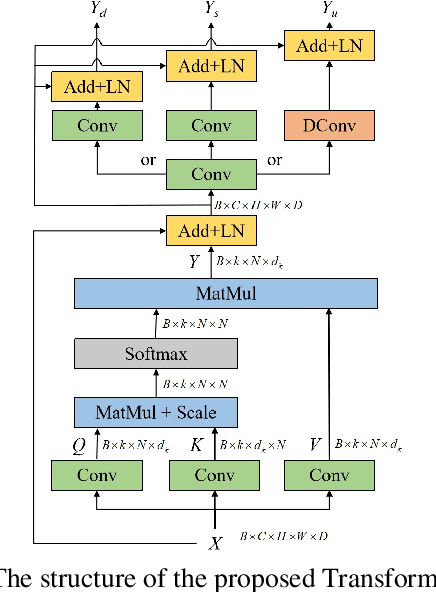
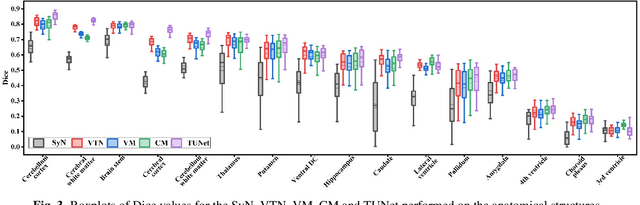
Deformable medical image registration plays an important role in clinical diagnosis and treatment. Recently, the deep learning (DL) based image registration methods have been widely investigated and showed excellent performance in computational speed. However, these methods cannot provide enough registration accuracy because of insufficient ability in representing both the global and local features of the moving and fixed images. To address this issue, this paper has proposed the transformer based image registration method. This method uses the distinctive transformer to extract the global and local image features for generating the deformation fields, based on which the registered image is produced in an unsupervised way. Our method can improve the registration accuracy effectively by means of self-attention mechanism and bi-level information flow. Experimental results on such brain MR image datasets as LPBA40 and OASIS-1 demonstrate that compared with several traditional and DL based registration methods, our method provides higher registration accuracy in terms of dice values.
* 5 pages, 4 figures, 18 conferences
Contrastive Regularization for Semi-Supervised Learning
Jan 17, 2022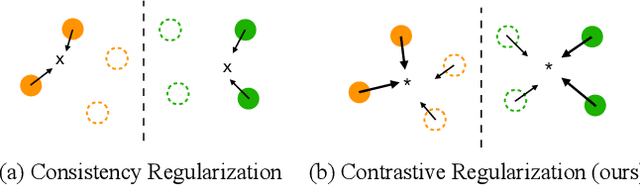
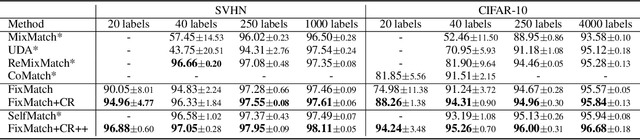
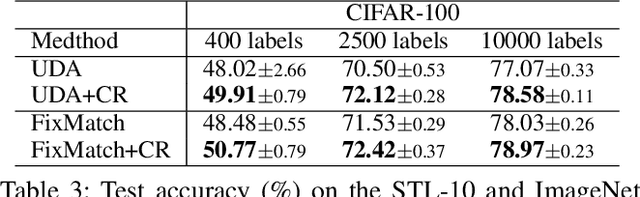
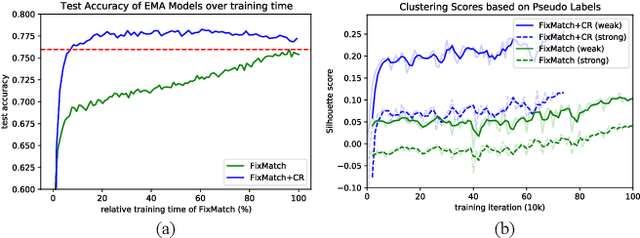
Consistency regularization on label predictions becomes a fundamental technique in semi-supervised learning, but it still requires a large number of training iterations for high performance. In this study, we analyze that the consistency regularization restricts the propagation of labeling information due to the exclusion of samples with unconfident pseudo-labels in the model updates. Then, we propose contrastive regularization to improve both efficiency and accuracy of the consistency regularization by well-clustered features of unlabeled data. In specific, after strongly augmented samples are assigned to clusters by their pseudo-labels, our contrastive regularization updates the model so that the features with confident pseudo-labels aggregate the features in the same cluster, while pushing away features in different clusters. As a result, the information of confident pseudo-labels can be effectively propagated into more unlabeled samples during training by the well-clustered features. On benchmarks of semi-supervised learning tasks, our contrastive regularization improves the previous consistency-based methods and achieves state-of-the-art results, especially with fewer training iterations. Our method also shows robust performance on open-set semi-supervised learning where unlabeled data includes out-of-distribution samples.
TBN-ViT: Temporal Bilateral Network with Vision Transformer for Video Scene Parsing
Dec 02, 2021

Video scene parsing in the wild with diverse scenarios is a challenging and great significance task, especially with the rapid development of automatic driving technique. The dataset Video Scene Parsing in the Wild(VSPW) contains well-trimmed long-temporal, dense annotation and high resolution clips. Based on VSPW, we design a Temporal Bilateral Network with Vision Transformer. We first design a spatial path with convolutions to generate low level features which can preserve the spatial information. Meanwhile, a context path with vision transformer is employed to obtain sufficient context information. Furthermore, a temporal context module is designed to harness the inter-frames contextual information. Finally, the proposed method can achieve the mean intersection over union(mIoU) of 49.85\% for the VSPW2021 Challenge test dataset.
ICLEA: Interactive Contrastive Learning for Self-supervised Entity Alignment
Jan 17, 2022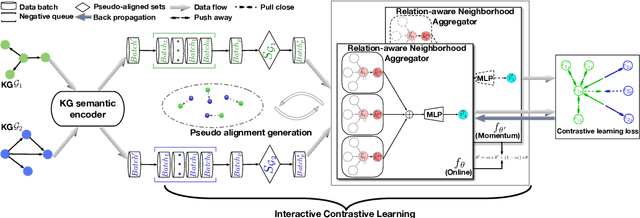
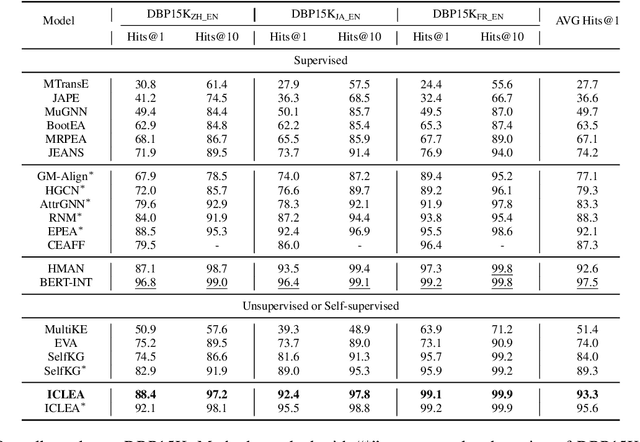
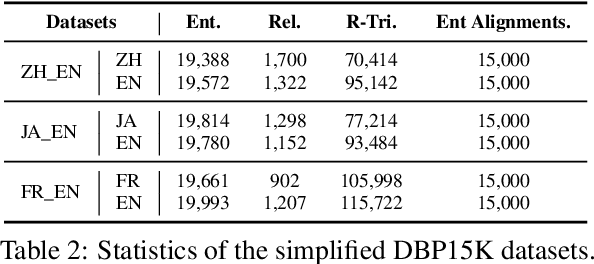
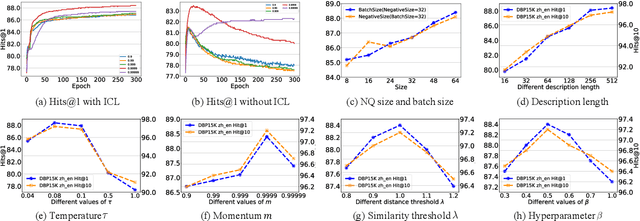
Self-supervised entity alignment (EA) aims to link equivalent entities across different knowledge graphs (KGs) without seed alignments. The current SOTA self-supervised EA method draws inspiration from contrastive learning, originally designed in computer vision based on instance discrimination and contrastive loss, and suffers from two shortcomings. Firstly, it puts unidirectional emphasis on pushing sampled negative entities far away rather than pulling positively aligned pairs close, as is done in the well-established supervised EA. Secondly, KGs contain rich side information (e.g., entity description), and how to effectively leverage those information has not been adequately investigated in self-supervised EA. In this paper, we propose an interactive contrastive learning model for self-supervised EA. The model encodes not only structures and semantics of entities (including entity name, entity description, and entity neighborhood), but also conducts cross-KG contrastive learning by building pseudo-aligned entity pairs. Experimental results show that our approach outperforms previous best self-supervised results by a large margin (over 9% average improvement) and performs on par with previous SOTA supervised counterparts, demonstrating the effectiveness of the interactive contrastive learning for self-supervised EA.
Explainability for identification of vulnerable groups in machine learning models
Mar 01, 2022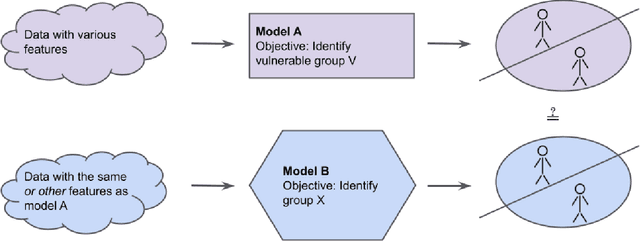
If a prediction model identifies vulnerable individuals or groups, the use of that model may become an ethical issue. But can we know that this is what a model does? Machine learning fairness as a field is focused on the just treatment of individuals and groups under information processing with machine learning methods. While considerable attention has been given to mitigating discrimination of protected groups, vulnerable groups have not received the same attention. Unlike protected groups, which can be regarded as always vulnerable, a vulnerable group may be vulnerable in one context but not in another. This raises new challenges on how and when to protect vulnerable individuals and groups under machine learning. Methods from explainable artificial intelligence (XAI), in contrast, do consider more contextual issues and are concerned with answering the question "why was this decision made?". Neither existing fairness nor existing explainability methods allow us to ascertain if a prediction model identifies vulnerability. We discuss this problem and propose approaches for analysing prediction models in this respect.
Functional Classification of Bitcoin Addresses
Feb 24, 2022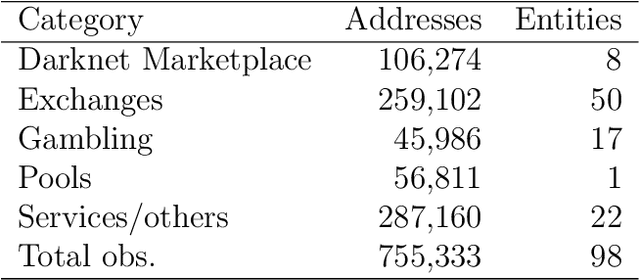
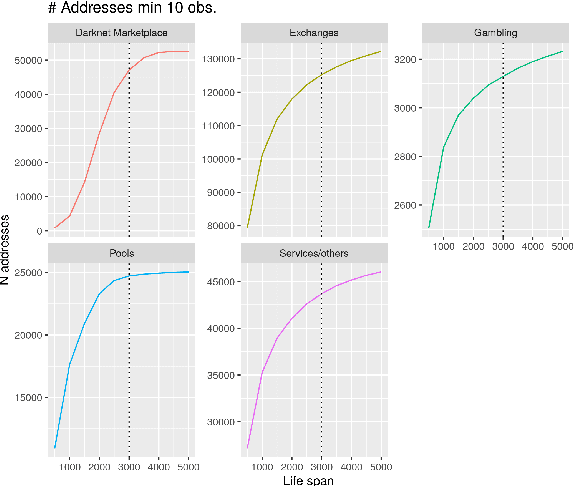
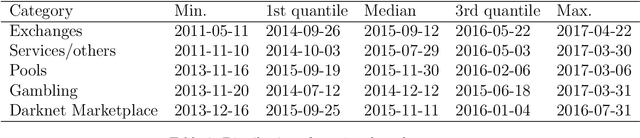
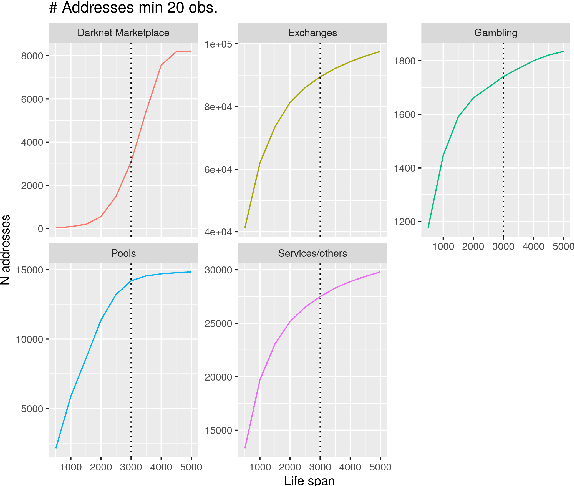
This paper proposes a classification model for predicting the main activity of bitcoin addresses based on their balances. Since the balances are functions of time, we apply methods from functional data analysis; more specifically, the features of the proposed classification model are the functional principal components of the data. Classifying bitcoin addresses is a relevant problem for two main reasons: to understand the composition of the bitcoin market, and to identify accounts used for illicit activities. Although other bitcoin classifiers have been proposed, they focus primarily on network analysis rather than curve behavior. Our approach, on the other hand, does not require any network information for prediction. Furthermore, functional features have the advantage of being straightforward to build, unlike expert-built features. Results show improvement when combining functional features with scalar features, and similar accuracy for the models using those features separately, which points to the functional model being a good alternative when domain-specific knowledge is not available.
Online handwriting, signature and touch dynamics: tasks and potential applications in the field of security and health
Feb 24, 2022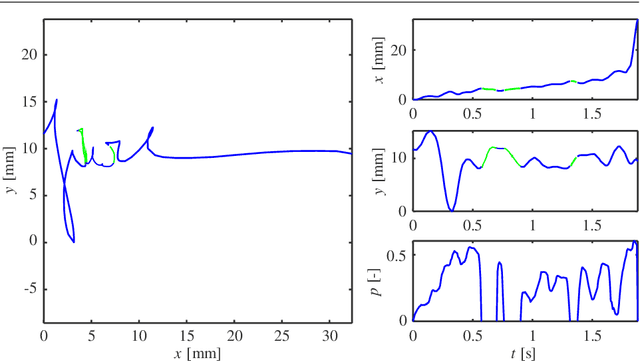

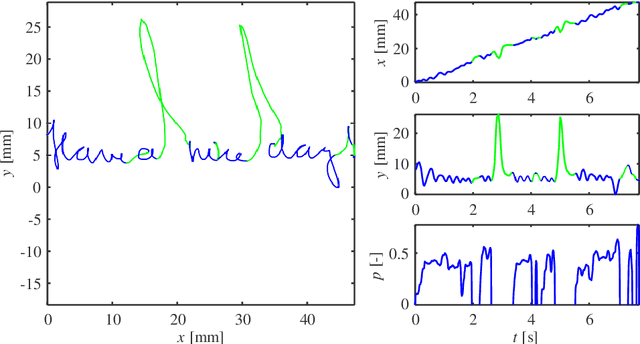
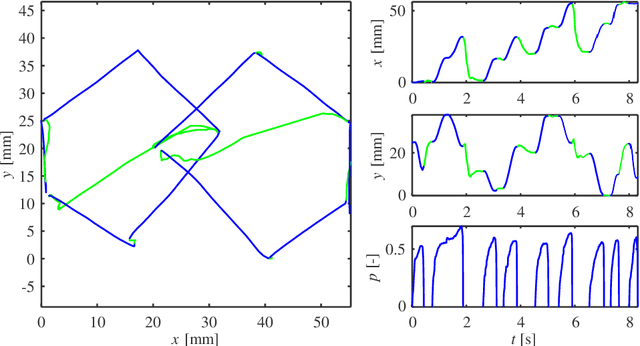
Background: An advantageous property of behavioural signals ,e.g. handwriting, in contrast to morphological ones, such as iris, fingerprint, hand geometry, etc., is the possibility to ask a user for a very rich amount of different tasks. Methods: This article summarises recent findings and applications of different handwriting and drawing tasks in the field of security and health. More specifically, it is focused on on-line handwriting and hand-based interaction, i.e. signals that utilise a digitizing device (specific devoted or general-purpose tablet/smartphone) during the realization of the tasks. Such devices permit the acquisition of on-surface dynamics as well as in-air movements in time, thus providing complex and richer information when compared to the conventional pen and paper method. Conclusions: Although the scientific literature reports a wide range of tasks and applications, in this paper, we summarize only those providing competitive results (e.g. in terms of discrimination power) and having a significant impact in the field.
* 27 pages
On Multi-Human Multi-Robot Remote Interaction: A Study of Transparency, Inter-Human Communication, and Information Loss in Remote Interaction
Feb 04, 2021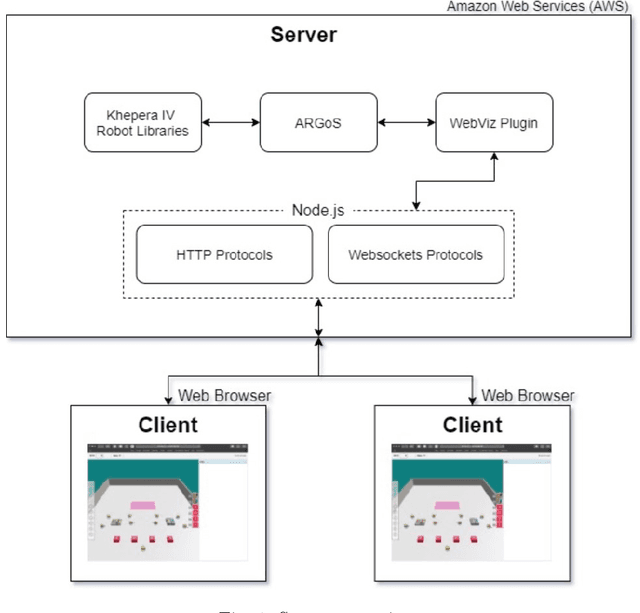
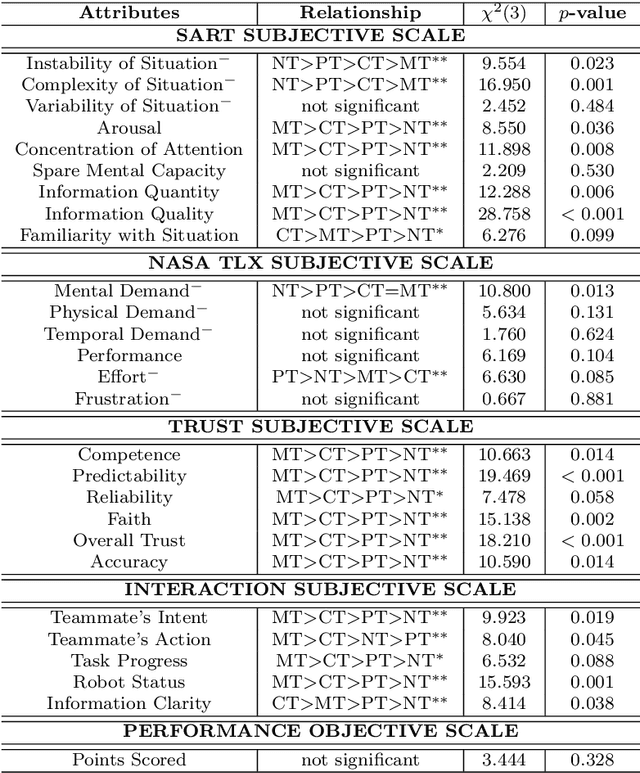
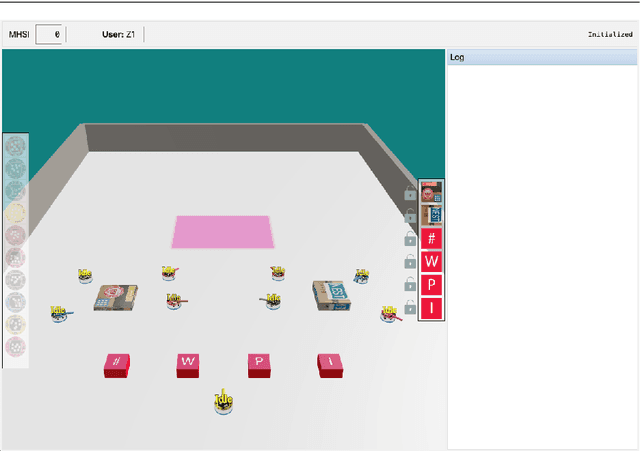

In this paper, we investigate how to design an effective interface for remote multi-human multi-robot interaction. While significant research exists on interfaces for individual human operators, little research exists for the multi-human case. Yet, this is a critical problem to solve to make complex, large-scale missions achievable in which direct human involvement is impossible or undesirable, and robot swarms act as a semi-autonomous agents. This paper's contribution is twofold. The first contribution is an exploration of the design space of computer-based interfaces for multi-human multi-robot operations. In particular, we focus on information transparency and on the factors that affect inter-human communication in ideal conditions, i.e., without communication issues. Our second contribution concerns the same problem, but considering increasing degrees of information loss, defined as intermittent reception of data with noticeable gaps between individual receipts. We derived a set of design recommendations based on two user studies involving 48 participants.