 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Socially Compliant Navigation Dataset (SCAND): A Large-Scale Dataset of Demonstrations for Social Navigation
Mar 28, 2022



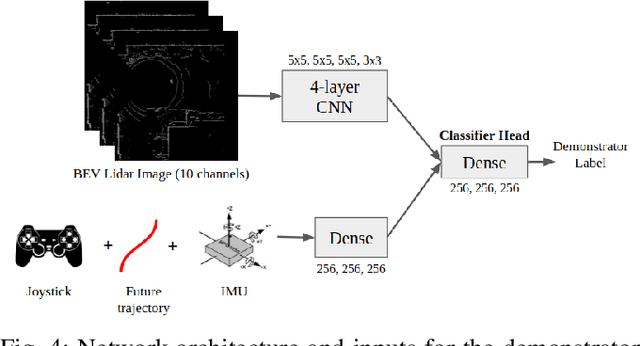
Social navigation is the capability of an autonomous agent, such as a robot, to navigate in a 'socially compliant' manner in the presence of other intelligent agents such as humans. With the emergence of autonomously navigating mobile robots in human populated environments (e.g., domestic service robots in homes and restaurants and food delivery robots on public sidewalks), incorporating socially compliant navigation behaviors on these robots becomes critical to ensuring safe and comfortable human robot coexistence. To address this challenge, imitation learning is a promising framework, since it is easier for humans to demonstrate the task of social navigation rather than to formulate reward functions that accurately capture the complex multi objective setting of social navigation. The use of imitation learning and inverse reinforcement learning to social navigation for mobile robots, however, is currently hindered by a lack of large scale datasets that capture socially compliant robot navigation demonstrations in the wild. To fill this gap, we introduce Socially CompliAnt Navigation Dataset (SCAND) a large scale, first person view dataset of socially compliant navigation demonstrations. Our dataset contains 8.7 hours, 138 trajectories, 25 miles of socially compliant, human teleoperated driving demonstrations that comprises multi modal data streams including 3D lidar, joystick commands, odometry, visual and inertial information, collected on two morphologically different mobile robots a Boston Dynamics Spot and a Clearpath Jackal by four different human demonstrators in both indoor and outdoor environments. We additionally perform preliminary analysis and validation through real world robot experiments and show that navigation policies learned by imitation learning on SCAND generate socially compliant behaviors
DWIE: an entity-centric dataset for multi-task document-level information extraction
Sep 26, 2020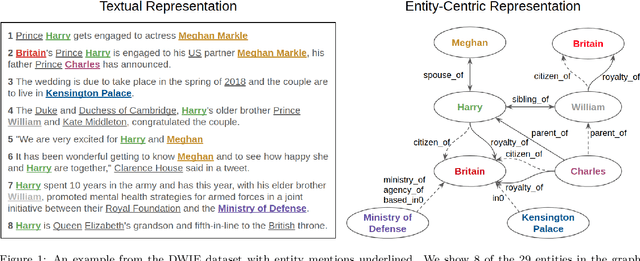
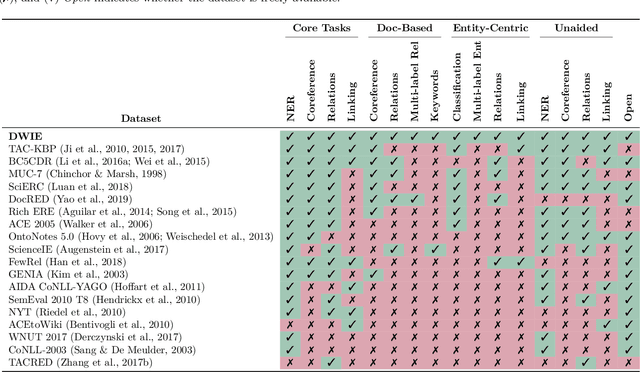
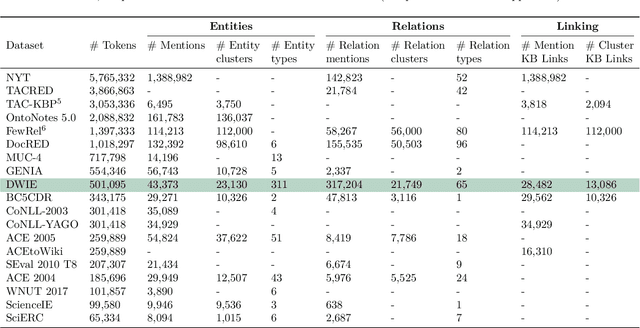
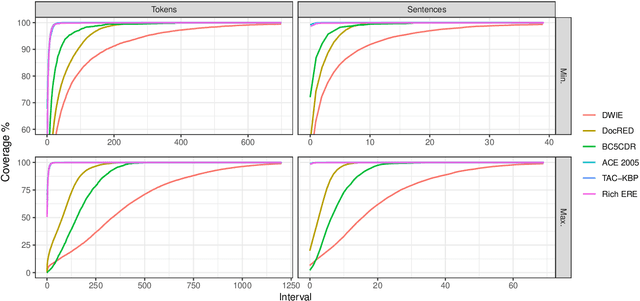
This paper presents DWIE, the 'Deutsche Welle corpus for Information Extraction', a newly created multi-task dataset that combines four main Information Extraction (IE) annotation sub-tasks: (i) Named Entity Recognition (NER), (ii) Coreference Resolution, (iii) Relation Extraction (RE), and (iv) Entity Linking. DWIE is conceived as an entity-centric dataset that describes interactions and properties of conceptual entities on the level of the complete document. This contrasts with currently dominant mention-driven approaches that start from the detection and classification of named entity mentions in individual sentences. Further, DWIE presented two main challenges when building and evaluating IE models for it. First, the use of traditional mention-level evaluation metrics for NER and RE tasks on entity-centric DWIE dataset can result in measurements dominated by predictions on more frequently mentioned entities. We tackle this issue by proposing a new entity-driven metric that takes into account the number of mentions that compose each of the predicted and ground truth entities. Second, the document-level multi-task annotations require the models to transfer information between entity mentions located in different parts of the document, as well as between different tasks, in a joint learning setting. To realize this, we propose to use graph-based neural message passing techniques between document-level mention spans. Our experiments show an improvement of up to 5.5 F1 percentage points when incorporating neural graph propagation into our joint model. This demonstrates DWIE's potential to stimulate further research in graph neural networks for representation learning in multi-task IE. We make DWIE publicly available at https://github.com/klimzaporojets/DWIE.
A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution
Mar 18, 2022
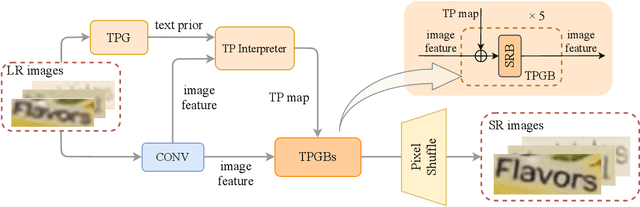
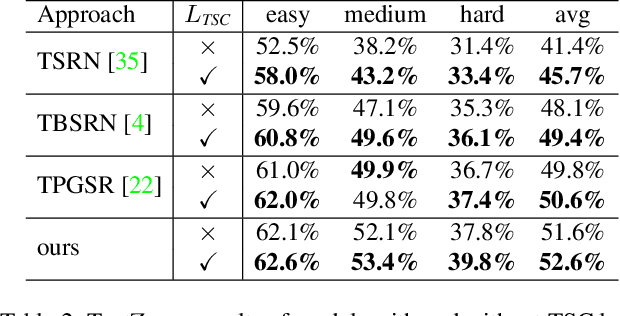
Scene text image super-resolution aims to increase the resolution and readability of the text in low-resolution images. Though significant improvement has been achieved by deep convolutional neural networks (CNNs), it remains difficult to reconstruct high-resolution images for spatially deformed texts, especially rotated and curve-shaped ones. This is because the current CNN-based methods adopt locality-based operations, which are not effective to deal with the variation caused by deformations. In this paper, we propose a CNN based Text ATTention network (TATT) to address this problem. The semantics of the text are firstly extracted by a text recognition module as text prior information. Then we design a novel transformer-based module, which leverages global attention mechanism, to exert the semantic guidance of text prior to the text reconstruction process. In addition, we propose a text structure consistency loss to refine the visual appearance by imposing structural consistency on the reconstructions of regular and deformed texts. Experiments on the benchmark TextZoom dataset show that the proposed TATT not only achieves state-of-the-art performance in terms of PSNR/SSIM metrics, but also significantly improves the recognition accuracy in the downstream text recognition task, particularly for text instances with multi-orientation and curved shapes. Code is available at https://github.com/mjq11302010044/TATT.
Derivation of Information-Theoretically Optimal Adversarial Attacks with Applications to Robust Machine Learning
Jul 28, 2020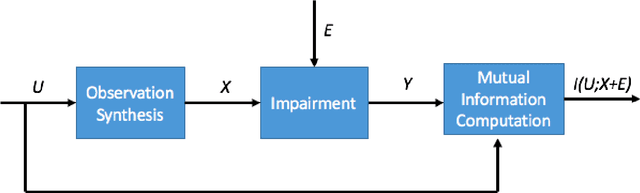
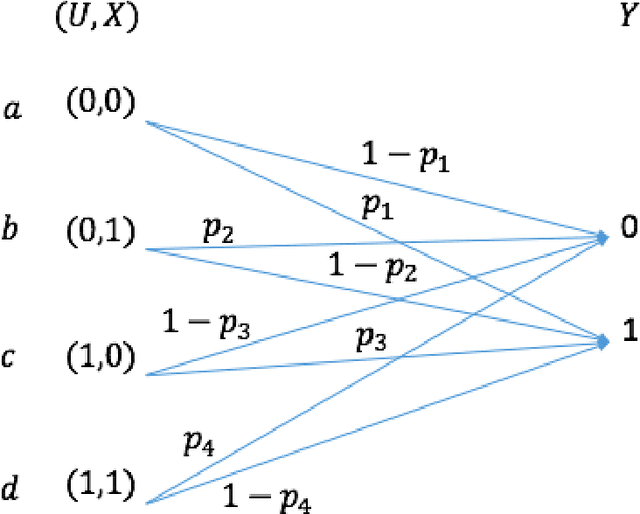
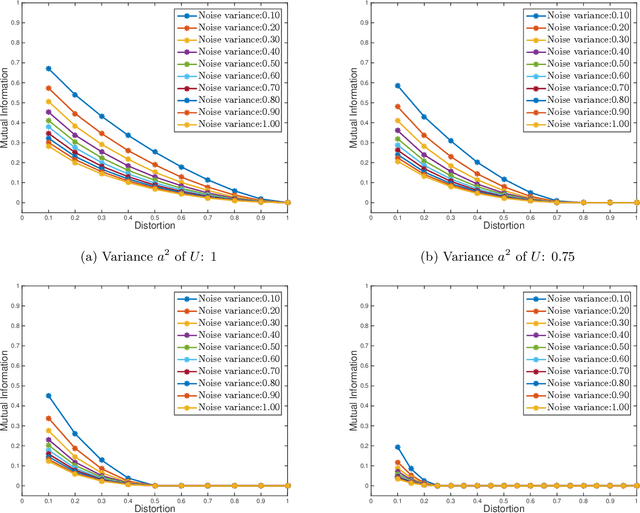
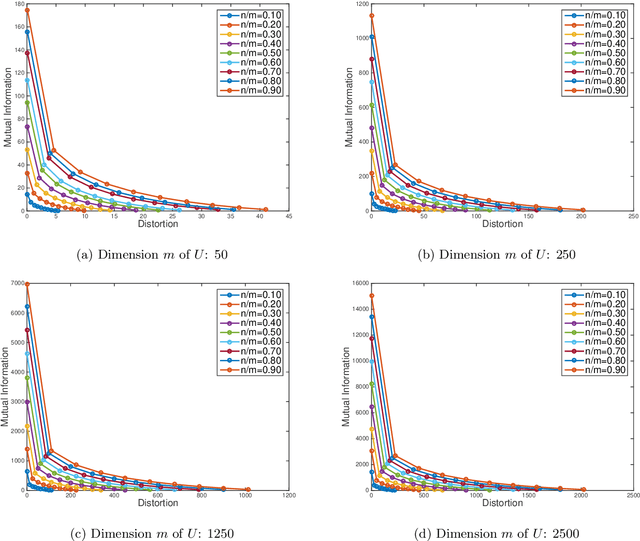
We consider the theoretical problem of designing an optimal adversarial attack on a decision system that maximally degrades the achievable performance of the system as measured by the mutual information between the degraded signal and the label of interest. This problem is motivated by the existence of adversarial examples for machine learning classifiers. By adopting an information theoretic perspective, we seek to identify conditions under which adversarial vulnerability is unavoidable i.e. even optimally designed classifiers will be vulnerable to small adversarial perturbations. We present derivations of the optimal adversarial attacks for discrete and continuous signals of interest, i.e., finding the optimal perturbation distributions to minimize the mutual information between the degraded signal and a signal following a continuous or discrete distribution. In addition, we show that it is much harder to achieve adversarial attacks for minimizing mutual information when multiple redundant copies of the input signal are available. This provides additional support to the recently proposed ``feature compression" hypothesis as an explanation for the adversarial vulnerability of deep learning classifiers. We also report on results from computational experiments to illustrate our theoretical results.
A Novel Skeleton-Based Human Activity Discovery Technique Using Particle Swarm Optimization with Gaussian Mutation
Jan 14, 2022



Human activity discovery aims to distinguish the activities performed by humans, without any prior information of what defines each activity. Most methods presented in human activity recognition are supervised, where there are labeled inputs to train the system. In reality, it is difficult to label data because of its huge volume and the variety of activities performed by humans. In this paper, a novel unsupervised approach is proposed to perform human activity discovery in 3D skeleton sequences. First, important frames are selected based on kinetic energy. Next, the displacement of joints, set of statistical, angles, and orientation features are extracted to represent the activities information. Since not all extracted features have useful information, the dimension of features is reduced using PCA. Most human activity discovery proposed are not fully unsupervised. They use pre-segmented videos before categorizing activities. To deal with this, we used the fragmented sliding time window method to segment the time series of activities with some overlapping. Then, activities are discovered by a novel hybrid particle swarm optimization with a Gaussian mutation algorithm to avoid getting stuck in the local optimum. Finally, k-means is applied to the outcome centroids to overcome the slow rate of PSO. Experiments on three datasets have been presented and the results show the proposed method has superior performance in discovering activities in all evaluation parameters compared to the other state-of-the-art methods and has increased accuracy of at least 4 % on average. The code is available here: https://github.com/parhamhadikhani/Human-Activity-Discovery-HPGMK
N-QGN: Navigation Map from a Monocular Camera using Quadtree Generating Networks
Feb 24, 2022
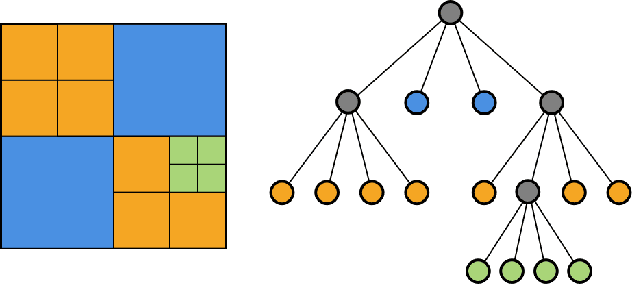
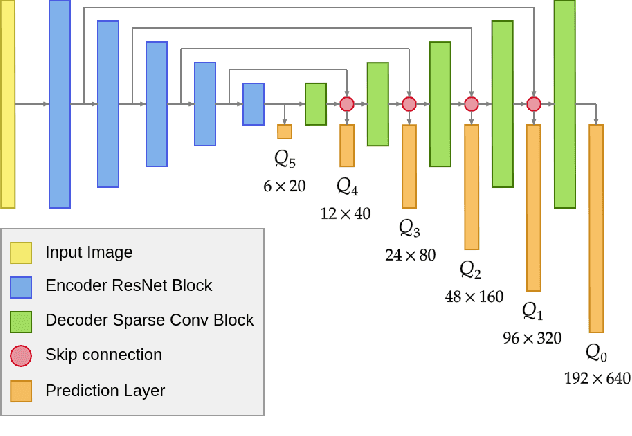
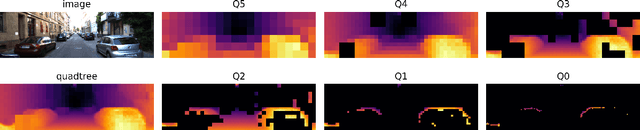
Monocular depth estimation has been a popular area of research for several years, especially since self-supervised networks have shown increasingly good results in bridging the gap with supervised and stereo methods. However, these approaches focus their interest on dense 3D reconstruction and sometimes on tiny details that are superfluous for autonomous navigation. In this paper, we propose to address this issue by estimating the navigation map under a quadtree representation. The objective is to create an adaptive depth map prediction that only extract details that are essential for the obstacle avoidance. Other 3D space which leaves large room for navigation will be provided with approximate distance. Experiment on KITTI dataset shows that our method can significantly reduce the number of output information without major loss of accuracy.
WaveFuzz: A Clean-Label Poisoning Attack to Protect Your Voice
Mar 25, 2022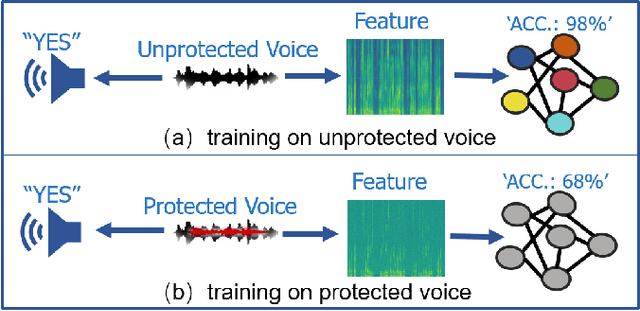
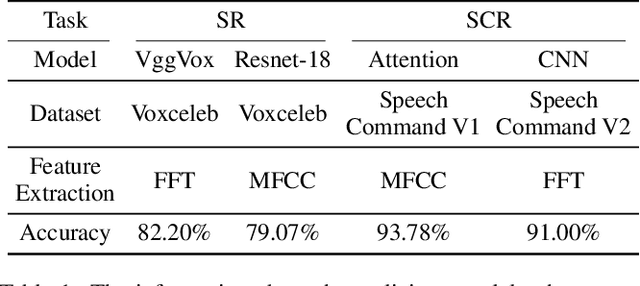
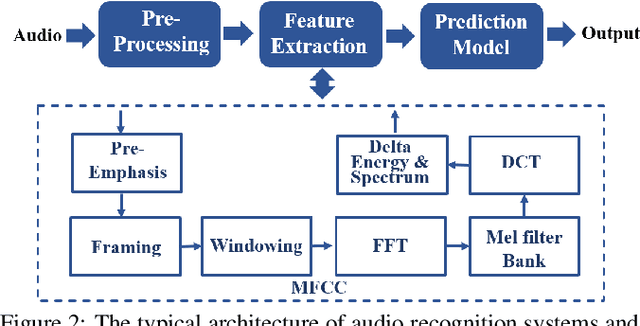
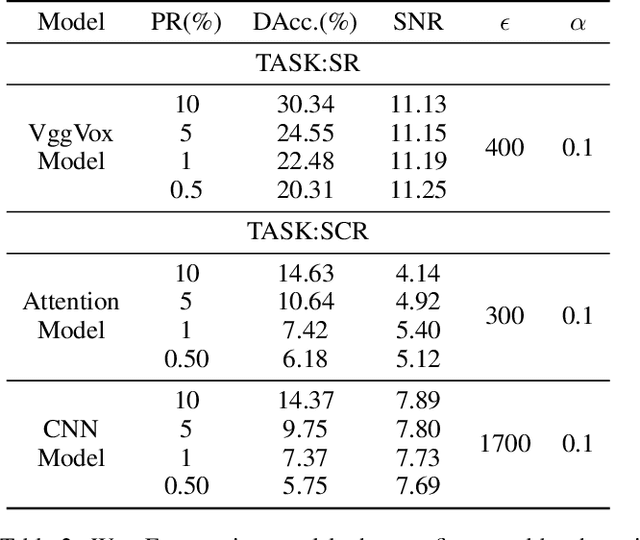
People are not always receptive to their voice data being collected and misused. Training the audio intelligence systems needs these data to build useful features, but the cost for getting permissions or purchasing data is very high, which inevitably encourages hackers to collect these voice data without people's awareness. To discourage the hackers from proactively collecting people's voice data, we are the first to propose a clean-label poisoning attack, called WaveFuzz, which can prevent intelligence audio models from building useful features from protected (poisoned) voice data but still preserve the semantic information to the humans. Specifically, WaveFuzz perturbs the voice data to cause Mel Frequency Cepstral Coefficients (MFCC) (typical representations of audio signals) to generate the poisoned frequency features. These poisoned features are then fed to audio prediction models, which degrades the performance of audio intelligence systems. Empirically, we show the efficacy of WaveFuzz by attacking two representative types of intelligent audio systems, i.e., speaker recognition system (SR) and speech command recognition system (SCR). For example, the accuracies of models are declined by $19.78\%$ when only $10\%$ of the poisoned voice data is to fine-tune models, and the accuracies of models declined by $6.07\%$ when only $10\%$ of the training voice data is poisoned. Consequently, WaveFuzz is an effective technique that enables people to fight back to protect their own voice data, which sheds new light on ameliorating privacy issues.
Do You Do Yoga? Understanding Twitter Users' Types and Motivations using Social and Textual Information
Jan 27, 2021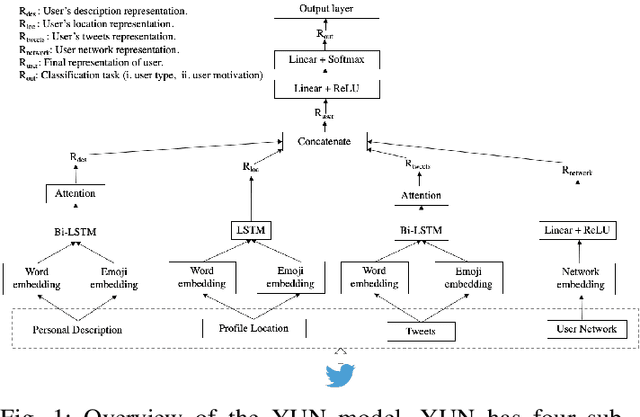
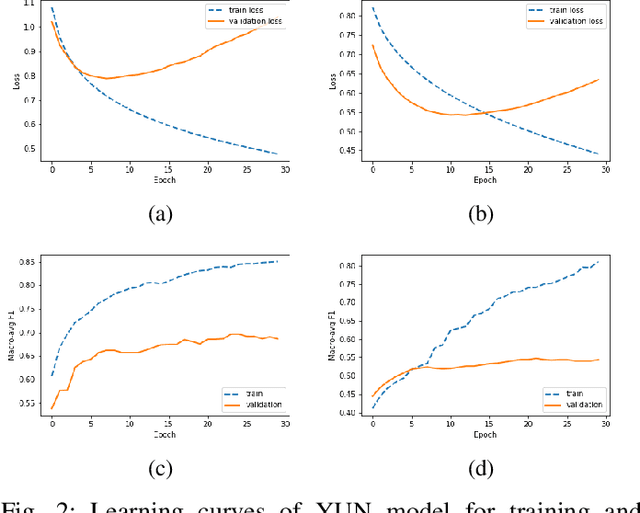
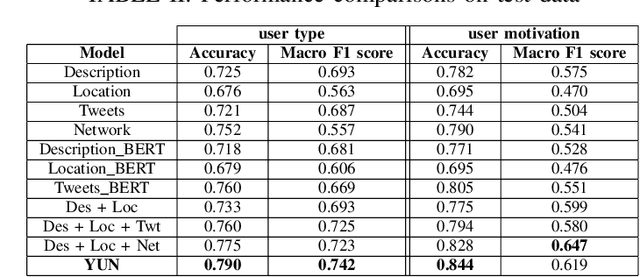
Leveraging social media data to understand people's lifestyle choices is an exciting domain to explore but requires a multiview formulation of the data. In this paper, we propose a joint embedding model based on the fusion of neural networks with attention mechanism by incorporating social and textual information of users to understand their activities and motivations. We use well-being related tweets from Twitter, focusing on 'Yoga'. We demonstrate our model on two downstream tasks: (i) finding user type such as either practitioner or promotional (promoting yoga studio/gym), other; (ii) finding user motivation i.e. health benefit, spirituality, love to tweet/retweet about yoga but do not practice yoga.
AutoFITS: Automatic Feature Engineering for Irregular Time Series
Dec 29, 2021
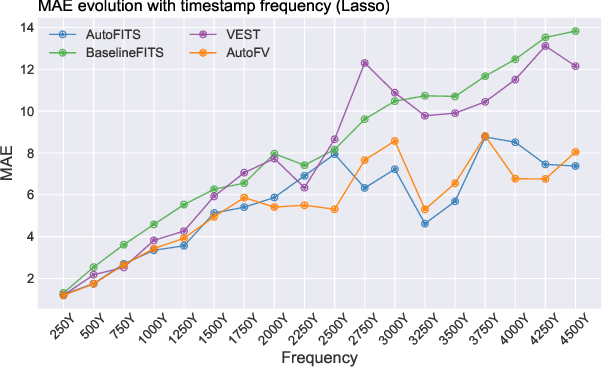
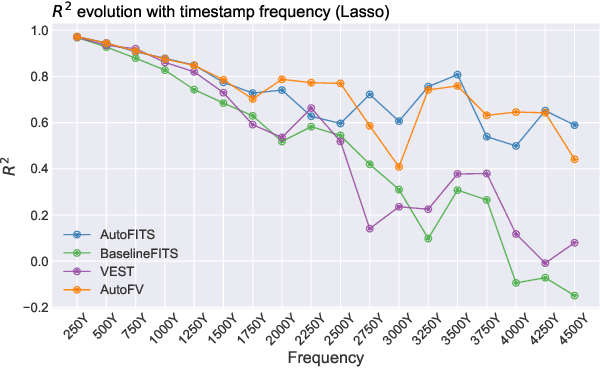
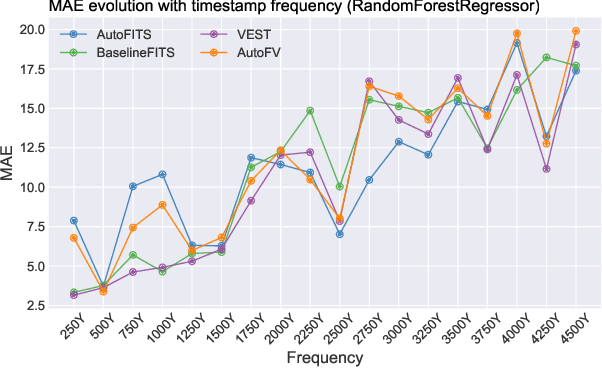
A time series represents a set of observations collected over time. Typically, these observations are captured with a uniform sampling frequency (e.g. daily). When data points are observed in uneven time intervals the time series is referred to as irregular or intermittent. In such scenarios, the most common solution is to reconstruct the time series to make it regular, thus removing its intermittency. We hypothesise that, in irregular time series, the time at which each observation is collected may be helpful to summarise the dynamics of the data and improve forecasting performance. We study this idea by developing a novel automatic feature engineering framework, which focuses on extracting information from this point of view, i.e., when each instance is collected. We study how valuable this information is by integrating it in a time series forecasting workflow and investigate how it compares to or complements state-of-the-art methods for regular time series forecasting. In the end, we contribute by providing a novel framework that tackles feature engineering for time series from an angle previously vastly ignored. We show that our approach has the potential to further extract more information about time series that significantly improves forecasting performance.
Healthy Twitter discussions? Time will tell
Mar 21, 2022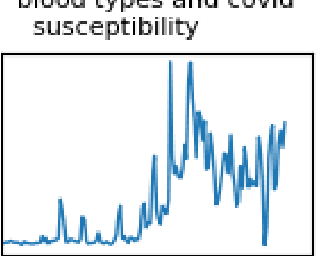

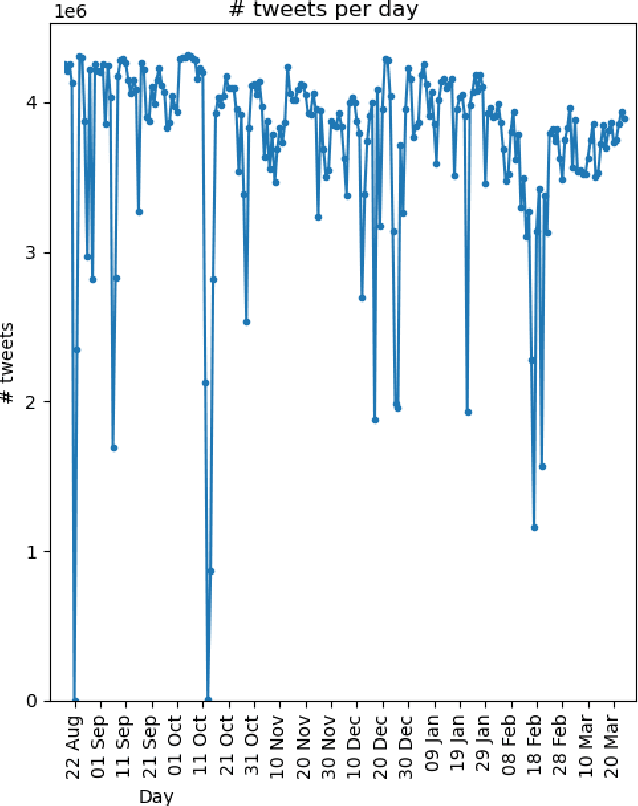
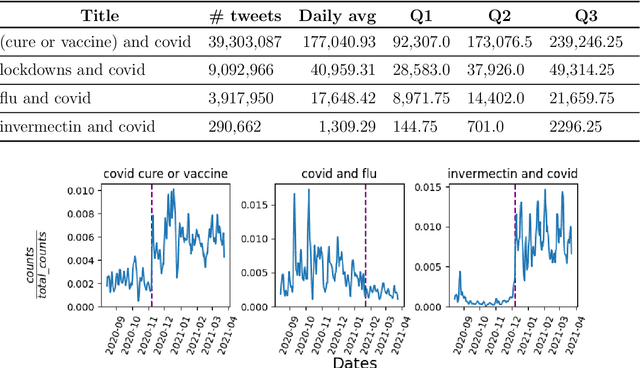
Studying misinformation and how to deal with unhealthy behaviours within online discussions has recently become an important field of research within social studies. With the rapid development of social media, and the increasing amount of available information and sources, rigorous manual analysis of such discourses has become unfeasible. Many approaches tackle the issue by studying the semantic and syntactic properties of discussions following a supervised approach, for example using natural language processing on a dataset labeled for abusive, fake or bot-generated content. Solutions based on the existence of a ground truth are limited to those domains which may have ground truth. However, within the context of misinformation, it may be difficult or even impossible to assign labels to instances. In this context, we consider the use of temporal dynamic patterns as an indicator of discussion health. Working in a domain for which ground truth was unavailable at the time (early COVID-19 pandemic discussions) we explore the characterization of discussions based on the the volume and time of contributions. First we explore the types of discussions in an unsupervised manner, and then characterize these types using the concept of ephemerality, which we formalize. In the end, we discuss the potential use of our ephemerality definition for labeling online discourses based on how desirable, healthy and constructive they are.