 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Modelling and Analysis of Car Following Algorithms for Fuel Economy Improvement in Connected and Autonomous Vehicles (CAVs)
Mar 25, 2022
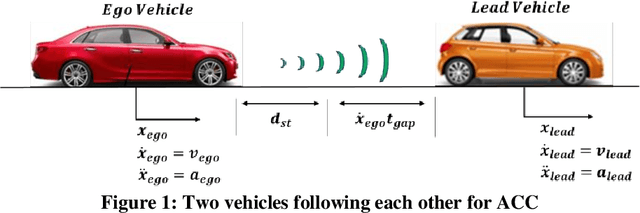
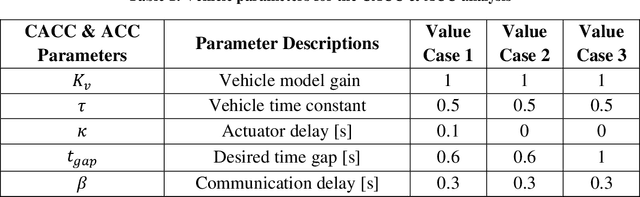
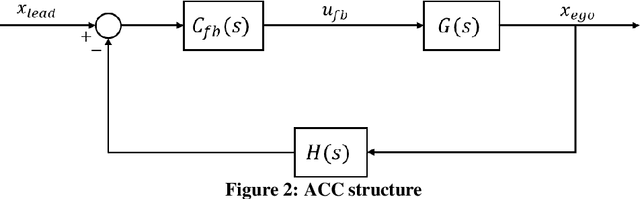

Connectivity in ground vehicles allows vehicles to share crucial vehicle data, such as vehicle acceleration, with each other. Using sensors such as cameras, radars and lidars, on the other hand, the intravehicular distance between a leader vehicle and a host vehicle can be detected, as well as the relative speed. Cooperative Adaptive Cruise Control (CACC) builds upon ground vehicle connectivity and sensor information to form convoys with automated car following. CACC can also be used to improve fuel economy and mobility performance of vehicles in the said convoy. In this paper, 3 car following algorithms for fuel economy of CAVs are presented. An Adaptive Cruise Control (ACC) algorithm was designed as the benchmark model for comparison. A Cooperative Adaptive Cruise Control (CACC) was designed, which uses lead vehicle acceleration received through V2V in car following. an Ecological Cooperative Adaptive Cruise Control (Eco-CACC) model was developed that takes the erratic lead vehicle acceleration as a disturbance to be attenuated. A High Level (HL) controller was designed for decision making when the lead vehicle was an erratic driver. Model-in-the-Loop (MIL) and Hardware-in-the-Loop (HIL) simulations were run to test these car following algorithms for fuel economy performance. The results show that the HL controller was able to attain a smooth speed profile that consumed less fuel through using CACC and Eco-CACC than its ACC counterpart when the lead vehicle was erratic.
Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion
Mar 18, 2022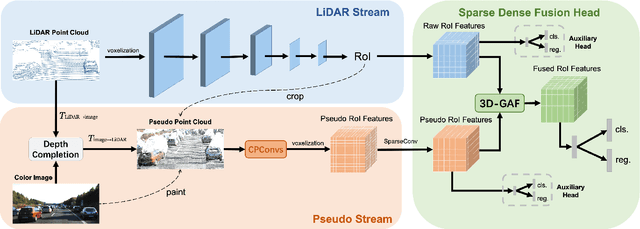
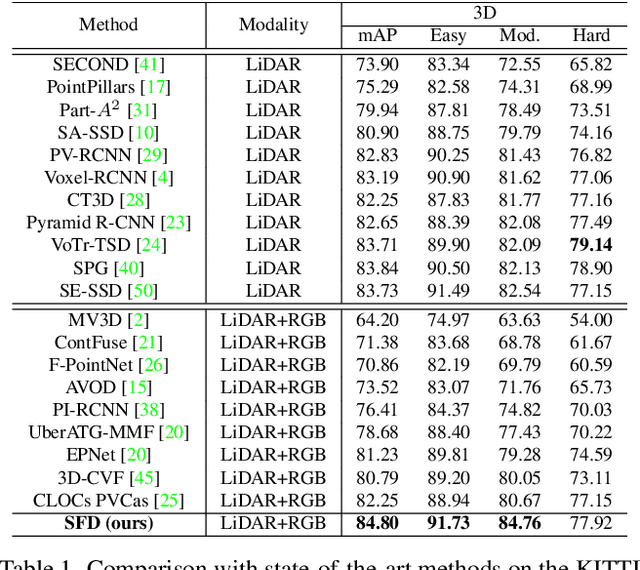
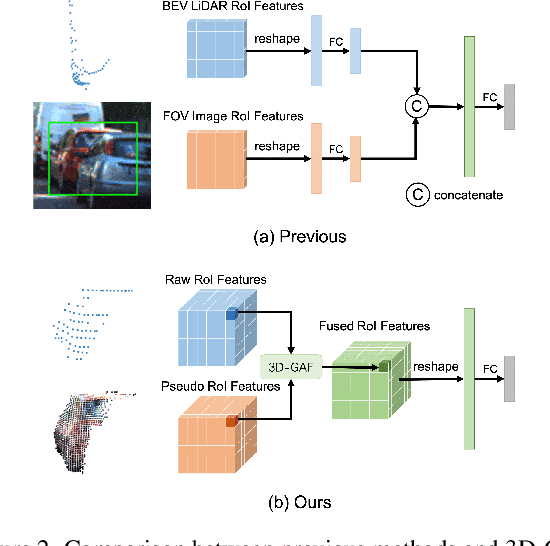
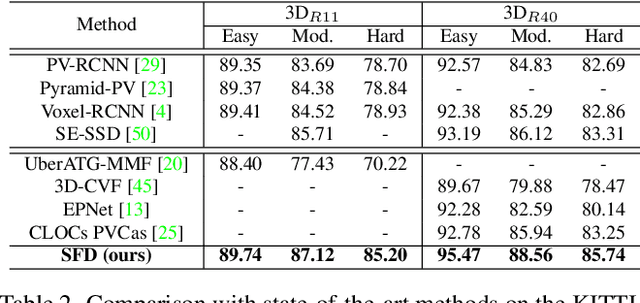
Current LiDAR-only 3D detection methods inevitably suffer from the sparsity of point clouds. Many multi-modal methods are proposed to alleviate this issue, while different representations of images and point clouds make it difficult to fuse them, resulting in suboptimal performance. In this paper, we present a novel multi-modal framework SFD (Sparse Fuse Dense), which utilizes pseudo point clouds generated from depth completion to tackle the issues mentioned above. Different from prior works, we propose a new RoI fusion strategy 3D-GAF (3D Grid-wise Attentive Fusion) to make fuller use of information from different types of point clouds. Specifically, 3D-GAF fuses 3D RoI features from the couple of point clouds in a grid-wise attentive way, which is more fine-grained and more precise. In addition, we propose a SynAugment (Synchronized Augmentation) to enable our multi-modal framework to utilize all data augmentation approaches tailored to LiDAR-only methods. Lastly, we customize an effective and efficient feature extractor CPConv (Color Point Convolution) for pseudo point clouds. It can explore 2D image features and 3D geometric features of pseudo point clouds simultaneously. Our method holds the highest entry on the KITTI car 3D object detection leaderboard, demonstrating the effectiveness of our SFD. Code will be made publicly available.
ACID: Action-Conditional Implicit Visual Dynamics for Deformable Object Manipulation
Mar 14, 2022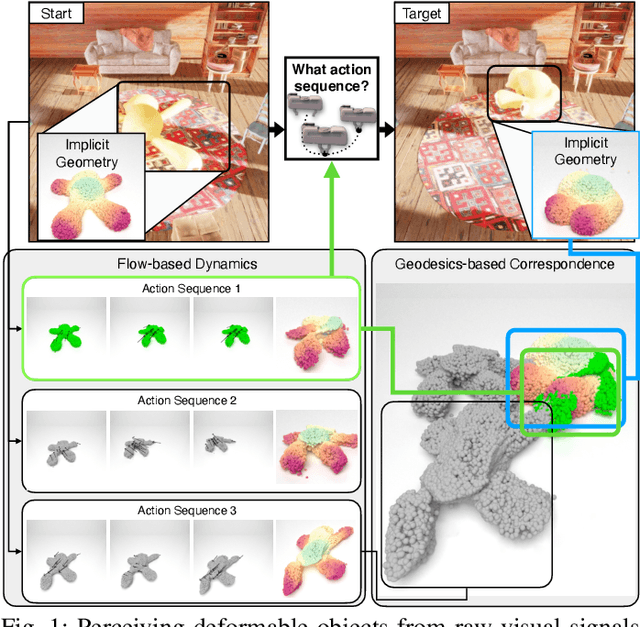
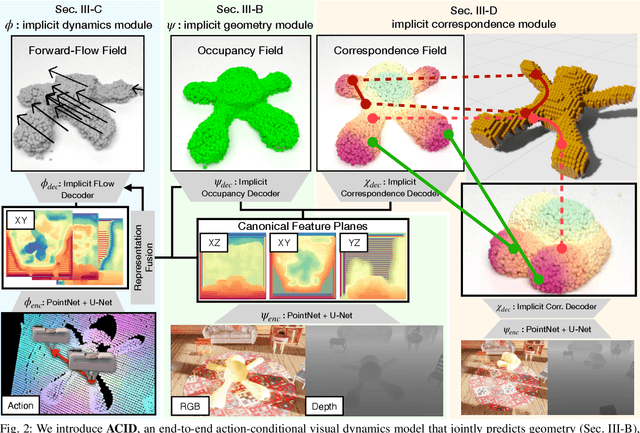


Manipulating volumetric deformable objects in the real world, like plush toys and pizza dough, bring substantial challenges due to infinite shape variations, non-rigid motions, and partial observability. We introduce ACID, an action-conditional visual dynamics model for volumetric deformable objects based on structured implicit neural representations. ACID integrates two new techniques: implicit representations for action-conditional dynamics and geodesics-based contrastive learning. To represent deformable dynamics from partial RGB-D observations, we learn implicit representations of occupancy and flow-based forward dynamics. To accurately identify state change under large non-rigid deformations, we learn a correspondence embedding field through a novel geodesics-based contrastive loss. To evaluate our approach, we develop a simulation framework for manipulating complex deformable shapes in realistic scenes and a benchmark containing over 17,000 action trajectories with six types of plush toys and 78 variants. Our model achieves the best performance in geometry, correspondence, and dynamics predictions over existing approaches. The ACID dynamics models are successfully employed to goal-conditioned deformable manipulation tasks, resulting in a 30% increase in task success rate over the strongest baseline. For more results and information, please visit https://b0ku1.github.io/acid-web/ .
Downlink Precoding for FBMC-based Massive MIMO with Imperfect Channel Reciprocity
Jan 26, 2022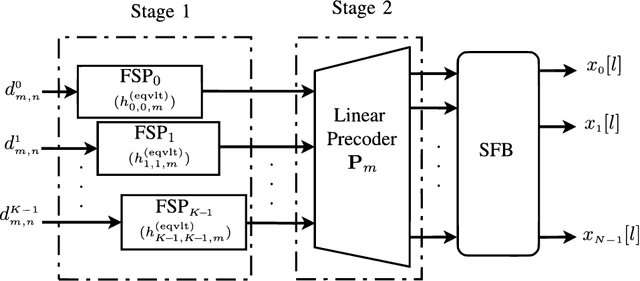
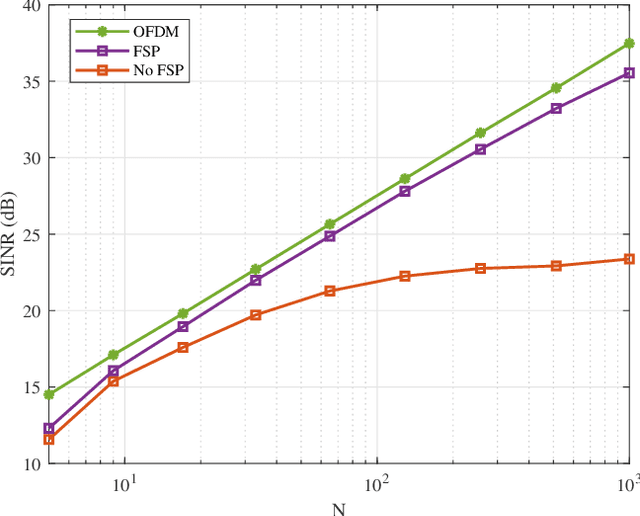
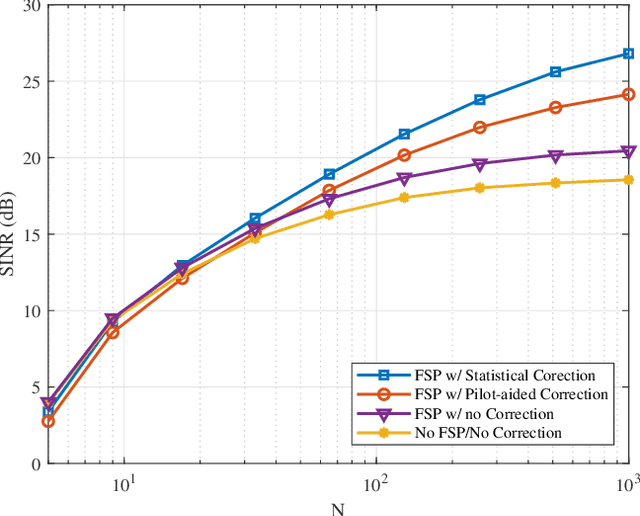
In this paper, a practical precoding method for the downlink of filter bank multicarrier-based (FBMC-based) massive multiple-input multiple-output (MIMO) is developed. The proposed method includes a two-stage precoder consisting of a fractionally spaced prefilter (FSP) per subcarrier for flattening/equalizing the channel across the subcarrier band, followed by a conventional precoder whose goal is to concentrate the signals of different users at their spatial locations. This way, each user receives only the intended information. In this paper, we take note that channel reciprocity may not hold perfectly in practical scenarios due to the mismatch of radio chains in uplink and downlink. Additionally, channel state information (CSI) at the base station may not be perfectly known. This, together with imperfect channel reciprocity can lead to detrimental effects on the downlink precoder performance. We theoretically analyze the performance of the proposed precoder in the presence of imperfect CSI and channel reciprocity calibration errors. This leads to an effective method for compensating these effects. Finally, we numerically evaluate the performance of the proposed precoder. Our results show that the proposed precoder leads to an excellent performance when benchmarked against OFDM.
Bike Sharing Demand Prediction based on Knowledge Sharing across Modes: A Graph-based Deep Learning Approach
Mar 18, 2022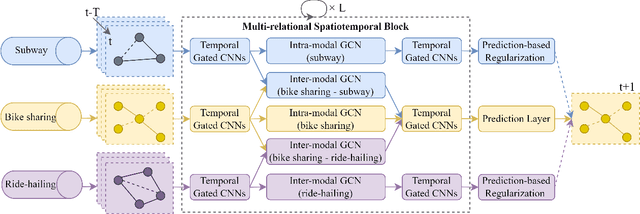
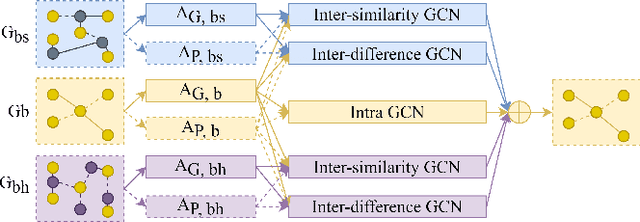
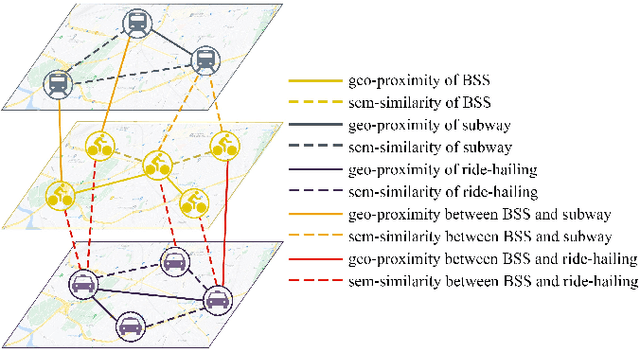
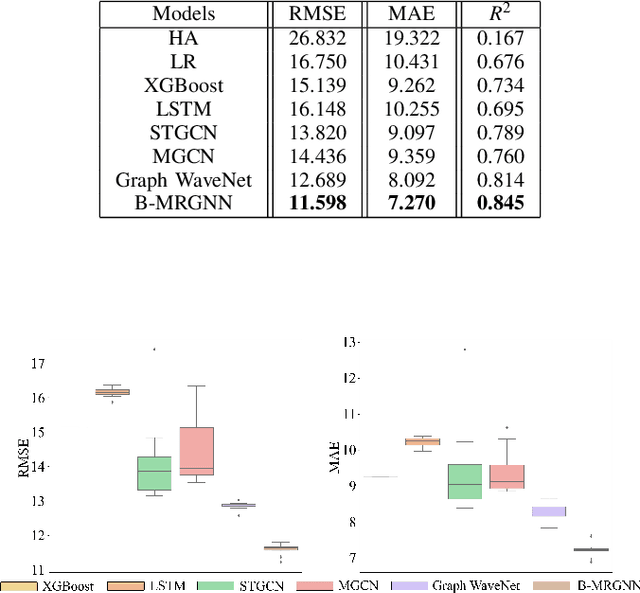
Bike sharing is an increasingly popular part of urban transportation systems. Accurate demand prediction is the key to support timely re-balancing and ensure service efficiency. Most existing models of bike-sharing demand prediction are solely based on its own historical demand variation, essentially regarding bike sharing as a closed system and neglecting the interaction between different transport modes. This is particularly important because bike sharing is often used to complement travel through other modes (e.g., public transit). Despite some recent efforts, there is no existing method capable of leveraging spatiotemporal information from multiple modes with heterogeneous spatial units. To address this research gap, this study proposes a graph-based deep learning approach for bike sharing demand prediction (B-MRGNN) with multimodal historical data as input. The spatial dependencies across modes are encoded with multiple intra- and inter-modal graphs. A multi-relational graph neural network (MRGNN) is introduced to capture correlations between spatial units across modes, such as bike sharing stations, subway stations, or ride-hailing zones. Extensive experiments are conducted using real-world bike sharing, subway and ride-hailing data from New York City, and the results demonstrate the superior performance of our proposed approach compared to existing methods.
Deep Generative Models for Downlink Channel Estimation in FDD Massive MIMO Systems
Mar 14, 2022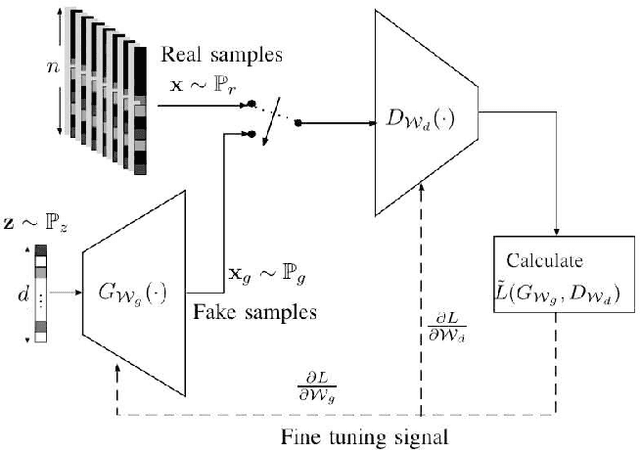
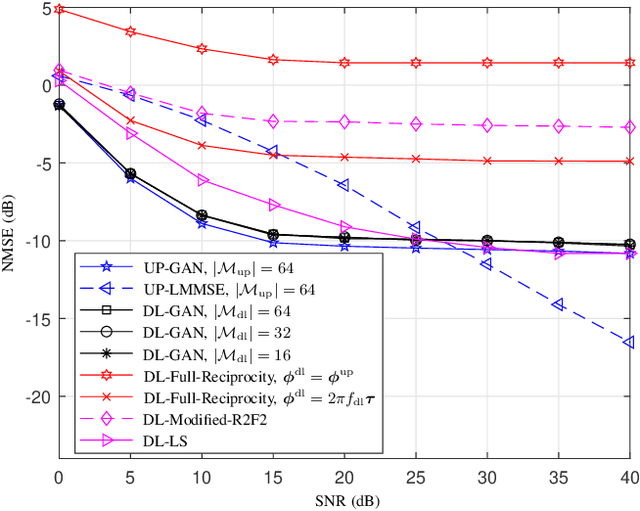
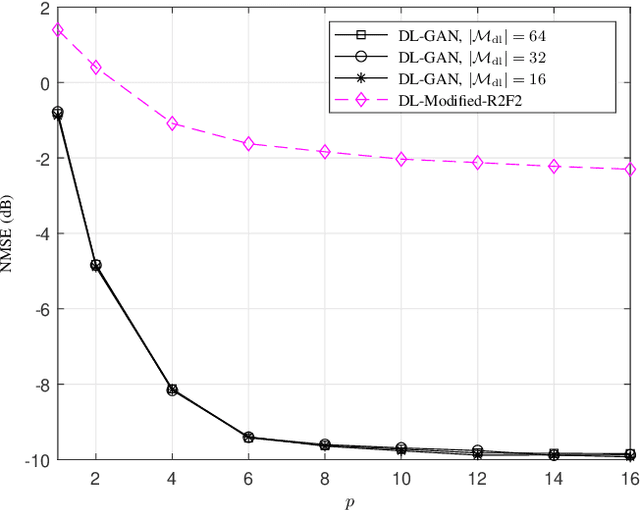
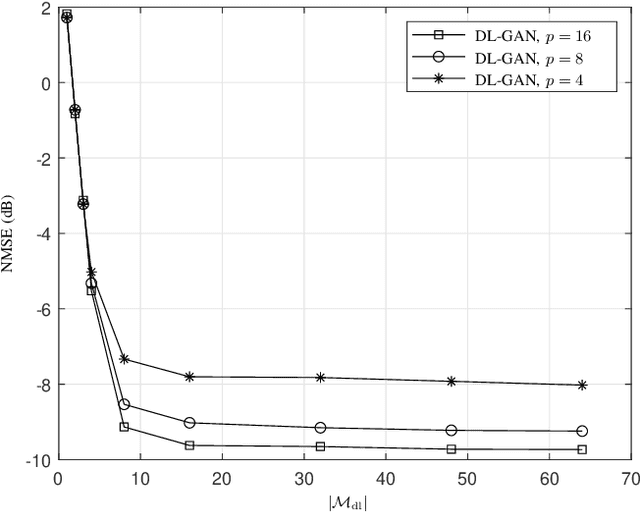
It is well accepted that acquiring downlink channel state information in frequency division duplexing (FDD) massive multiple-input multiple-output (MIMO) systems is challenging because of the large overhead in training and feedback. In this paper, we propose a deep generative model (DGM)-based technique to address this challenge. Exploiting the partial reciprocity of uplink and downlink channels, we first estimate the frequency-independent underlying channel parameters, i.e., the magnitudes of path gains, delays, angles-of-arrivals (AoAs) and angles-of-departures (AoDs), via uplink training, since these parameters are common in both uplink and downlink. Then, the frequency-specific underlying channel parameters, namely, the phase of each propagation path, are estimated via downlink training using a very short training signal. In the first step, we incorporate the underlying distribution of the channel parameters as a prior into our channel estimation algorithm. We use DGMs to learn this distribution. Simulation results indicate that our proposed DGM-based channel estimation technique outperforms, by a large gap, the conventional channel estimation techniques in practical ranges of signal-to-noise ratio (SNR). In addition, a near-optimal performance is achieved using only few downlink pilot measurements.
Beyond the Limitation of Pulse Width in Optical Time-domain Reflectometry
Mar 14, 2022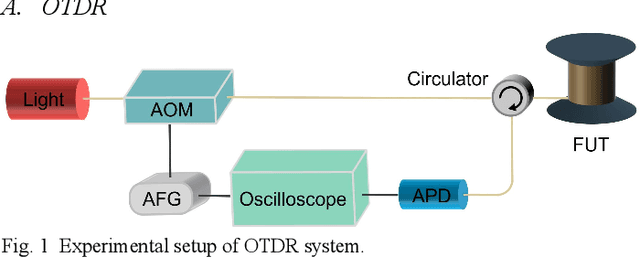
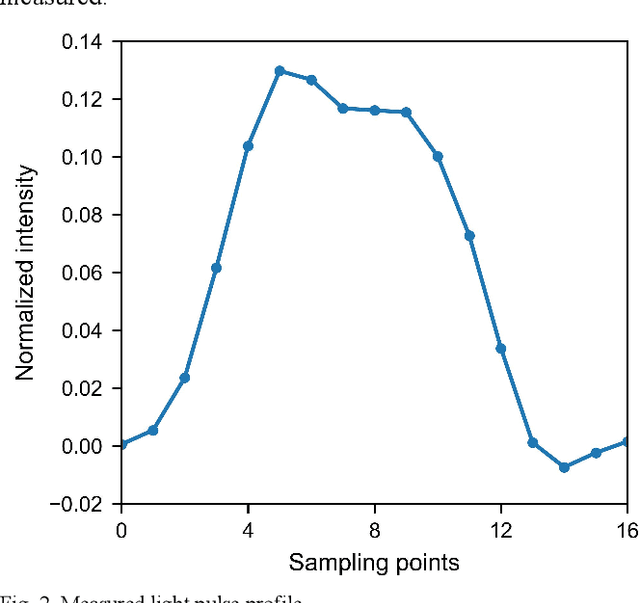
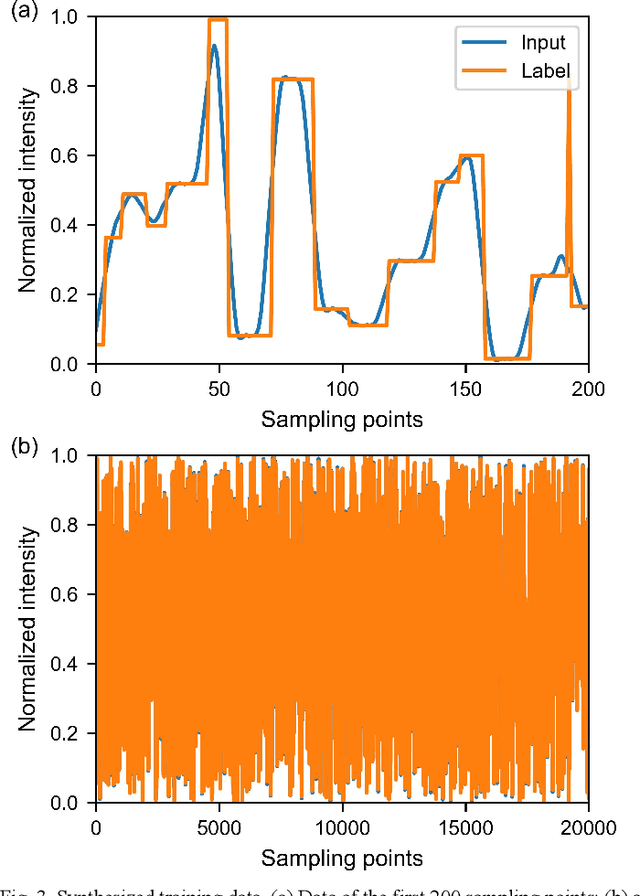
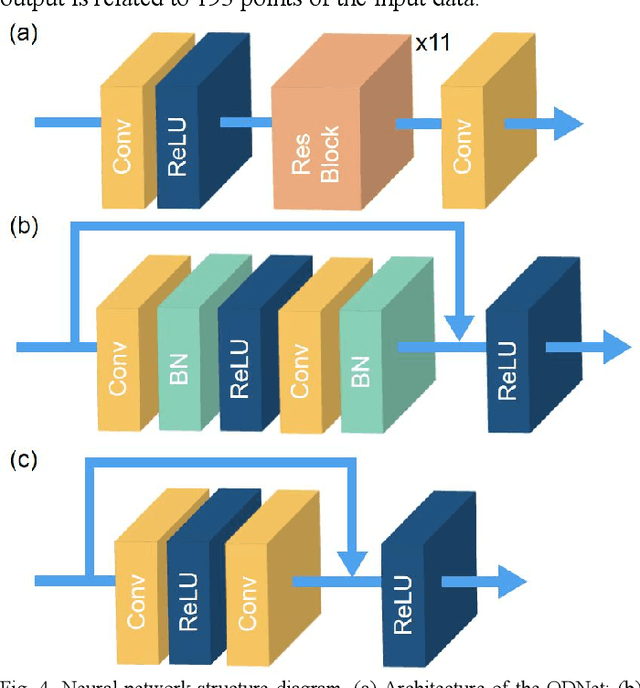
Optical time-domain reflectometry (OTDR) is the basis for distributed time-domain optical fiber sensing techniques. By injecting pulse light into an optical fiber, the distance information of an event can be obtained based on the time of light flight. The minimum distinguishable event separation along the fiber length is called the spatial resolution, which is determined by the optical pulse width. By reducing the pulse width, the spatial resolution can be improved. However, at the same time, the signal-to-noise ratio of the system is degraded, and higher speed equipment is required. To solve this problem, data processing methods such as iterative subdivision, deconvolution, and neural networks have been proposed. However, they all have some shortcomings and thus have not been widely applied. Here, we propose and experimentally demonstrate an OTDR deconvolution neural network based on deep convolutional neural networks. A simplified OTDR model is built to generate a large amount of training data. By optimizing the network structure and training data, an effective OTDR deconvolution is achieved. The simulation and experimental results show that the proposed neural network can achieve more accurate deconvolution than the conventional deconvolution algorithm with a higher signal-to-noise ratio.
Socially Compliant Navigation Dataset (SCAND): A Large-Scale Dataset of Demonstrations for Social Navigation
Mar 28, 2022


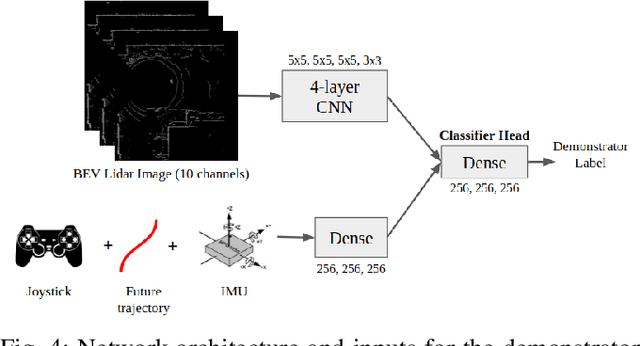
Social navigation is the capability of an autonomous agent, such as a robot, to navigate in a 'socially compliant' manner in the presence of other intelligent agents such as humans. With the emergence of autonomously navigating mobile robots in human populated environments (e.g., domestic service robots in homes and restaurants and food delivery robots on public sidewalks), incorporating socially compliant navigation behaviors on these robots becomes critical to ensuring safe and comfortable human robot coexistence. To address this challenge, imitation learning is a promising framework, since it is easier for humans to demonstrate the task of social navigation rather than to formulate reward functions that accurately capture the complex multi objective setting of social navigation. The use of imitation learning and inverse reinforcement learning to social navigation for mobile robots, however, is currently hindered by a lack of large scale datasets that capture socially compliant robot navigation demonstrations in the wild. To fill this gap, we introduce Socially CompliAnt Navigation Dataset (SCAND) a large scale, first person view dataset of socially compliant navigation demonstrations. Our dataset contains 8.7 hours, 138 trajectories, 25 miles of socially compliant, human teleoperated driving demonstrations that comprises multi modal data streams including 3D lidar, joystick commands, odometry, visual and inertial information, collected on two morphologically different mobile robots a Boston Dynamics Spot and a Clearpath Jackal by four different human demonstrators in both indoor and outdoor environments. We additionally perform preliminary analysis and validation through real world robot experiments and show that navigation policies learned by imitation learning on SCAND generate socially compliant behaviors
Probing the Information Encoded in X-vectors
Sep 30, 2019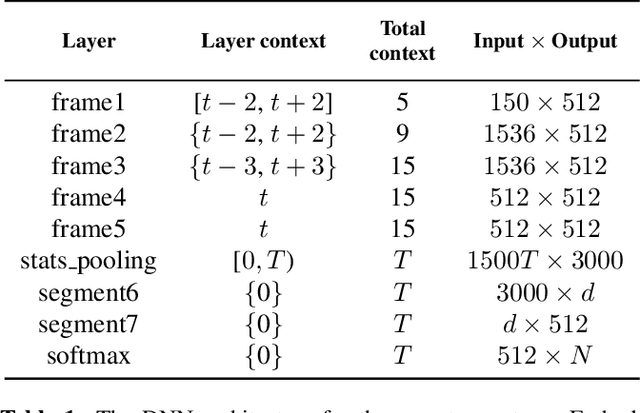
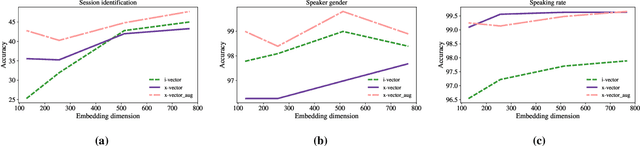

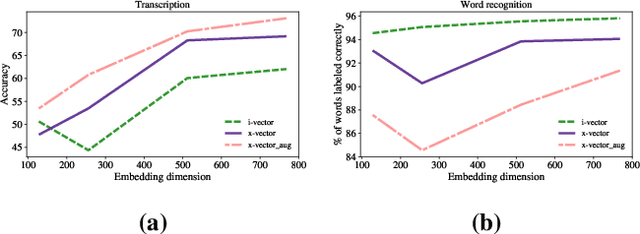
Deep neural network based speaker embeddings, such as x-vectors, have been shown to perform well in text-independent speaker recognition/verification tasks. In this paper, we use simple classifiers to investigate the contents encoded by x-vector embeddings. We probe these embeddings for information related to the speaker, channel, transcription (sentence, words, phones), and meta information about the utterance (duration and augmentation type), and compare these with the information encoded by i-vectors across a varying number of dimensions. We also study the effect of data augmentation during extractor training on the information captured by x-vectors. Experiments on the RedDots data set show that x-vectors capture spoken content and channel-related information, while performing well on speaker verification tasks.
Computing with Modular Robots
Feb 15, 2022Propagating patterns are used to transfer and process information in chemical and physical prototypes of unconventional computing devices. Logical values are represented by fronts of traveling diffusive, trigger or phase waves. We apply this concept of pattern based computation to develop experimental prototypes of computing circuits implemented in small modular robots. In the experimental prototypes the modular robots Cubelets are concatenated into channels and junction. The structures developed by Cubelets propagate signals in parallel and asynchronously. The approach is illustrated with a working circuit of a one-bit full adder. Complementarily a formalization of these constructions are developed across Sleptsov nets. Finally, a perspective to swarm dynamics is discussed.
* 33 pages, 23 figures, 5 tables