 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge Augmented BERT Mutual Network in Multi-turn Spoken Dialogues
Feb 23, 2022
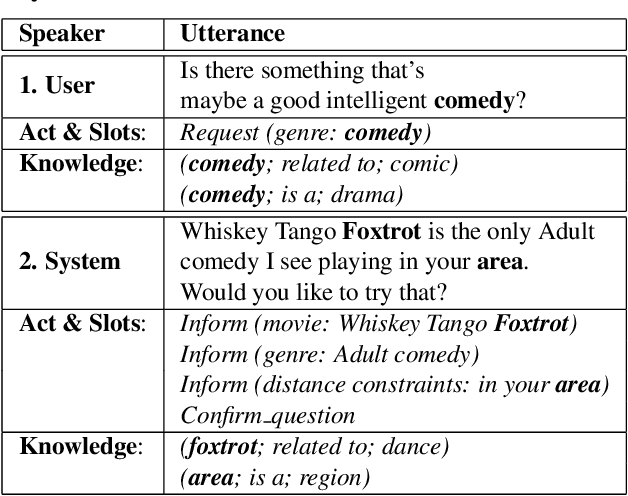
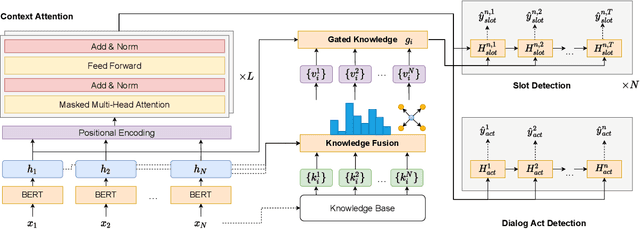
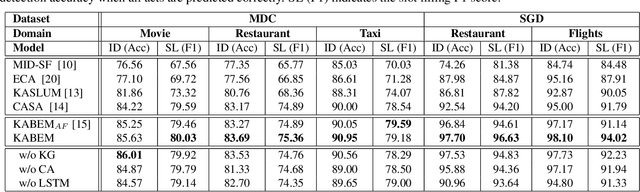

Modern spoken language understanding (SLU) systems rely on sophisticated semantic notions revealed in single utterances to detect intents and slots. However, they lack the capability of modeling multi-turn dynamics within a dialogue particularly in long-term slot contexts. Without external knowledge, depending on limited linguistic legitimacy within a word sequence may overlook deep semantic information across dialogue turns. In this paper, we propose to equip a BERT-based joint model with a knowledge attention module to mutually leverage dialogue contexts between two SLU tasks. A gating mechanism is further utilized to filter out irrelevant knowledge triples and to circumvent distracting comprehension. Experimental results in two complicated multi-turn dialogue datasets have demonstrate by mutually modeling two SLU tasks with filtered knowledge and dialogue contexts, our approach has considerable improvements compared with several competitive baselines.
Medication Error Detection Using Contextual Language Models
Jan 09, 2022
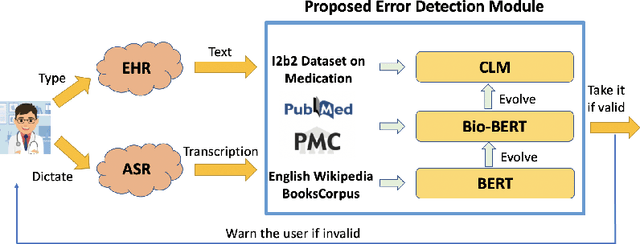
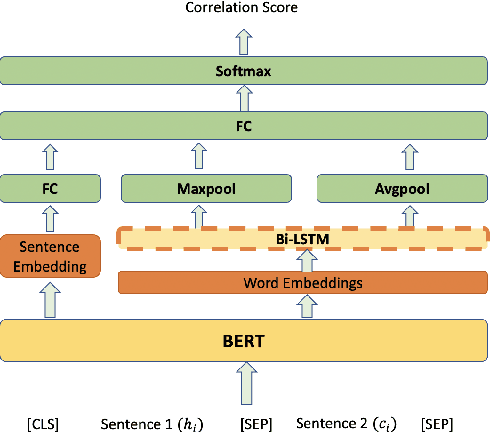
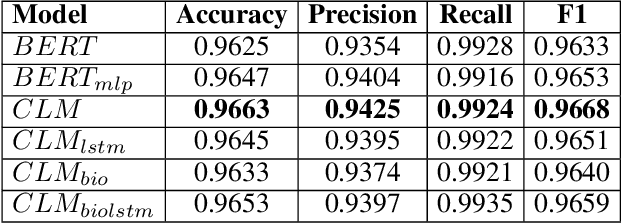
Medication errors most commonly occur at the ordering or prescribing stage, potentially leading to medical complications and poor health outcomes. While it is possible to catch these errors using different techniques; the focus of this work is on textual and contextual analysis of prescription information to detect and prevent potential medication errors. In this paper, we demonstrate how to use BERT-based contextual language models to detect anomalies in written or spoken text based on a data set extracted from real-world medical data of thousands of patient records. The proposed models are able to learn patterns of text dependency and predict erroneous output based on contextual information such as patient data. The experimental results yield accuracy up to 96.63% for text input and up to 79.55% for speech input, which is satisfactory for most real-world applications.
Question Answering Survey: Directions, Challenges, Datasets, Evaluation Matrices
Dec 07, 2021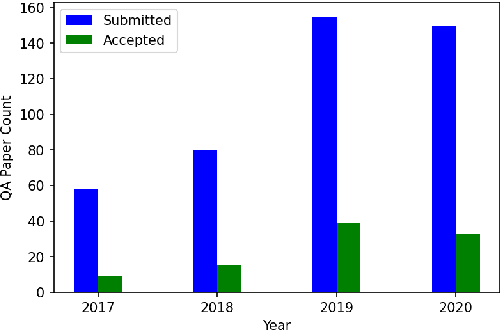
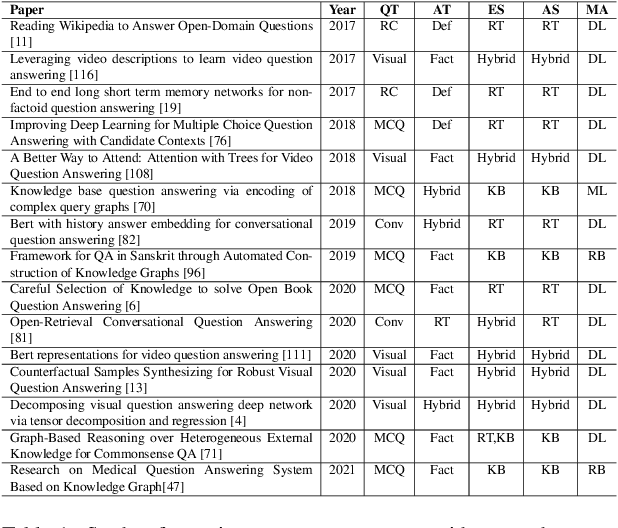
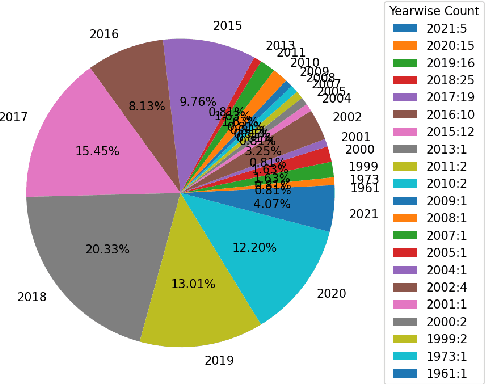
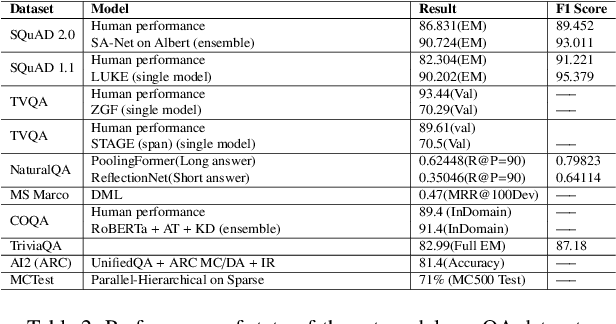
The usage and amount of information available on the internet increase over the past decade. This digitization leads to the need for automated answering system to extract fruitful information from redundant and transitional knowledge sources. Such systems are designed to cater the most prominent answer from this giant knowledge source to the user query using natural language understanding (NLU) and thus eminently depends on the Question-answering(QA) field. Question answering involves but not limited to the steps like mapping of user question to pertinent query, retrieval of relevant information, finding the best suitable answer from the retrieved information etc. The current improvement of deep learning models evince compelling performance improvement in all these tasks. In this review work, the research directions of QA field are analyzed based on the type of question, answer type, source of evidence-answer, and modeling approach. This detailing followed by open challenges of the field like automatic question generation, similarity detection and, low resource availability for a language. In the end, a survey of available datasets and evaluation measures is presented.
General lower bounds for interactive high-dimensional estimation under information constraints
Oct 13, 2020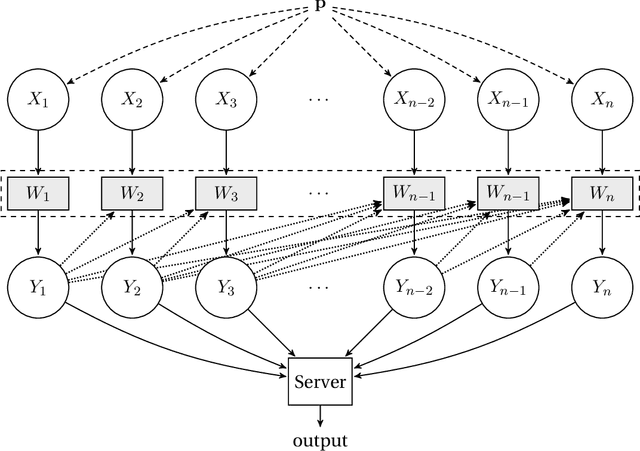


We consider the task of distributed parameter estimation using sequentially interactive protocols subject to local information constraints such as bandwidth limitations, local differential privacy, and restricted measurements. We provide a general framework enabling us to derive a variety of (tight) minimax lower bounds under different parametric families of distributions, both continuous and discrete, under any $\ell_p$ loss. Our lower bound framework is versatile, and yields "plug-and-play" bounds that are widely applicable to a large range of estimation problems. For the families considered, we further complement our lower bounds with matching upper bounds.
When Accuracy Meets Privacy: Two-Stage Federated Transfer Learning Framework in Classification of Medical Images on Limited Data: A COVID-19 Case Study
Mar 24, 2022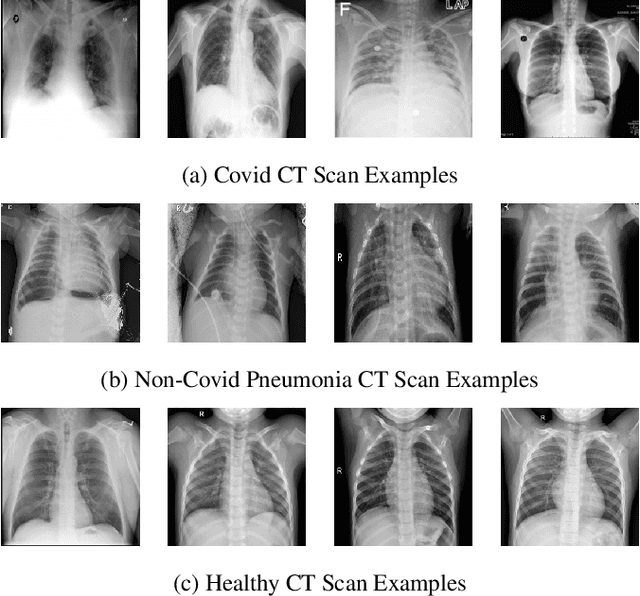
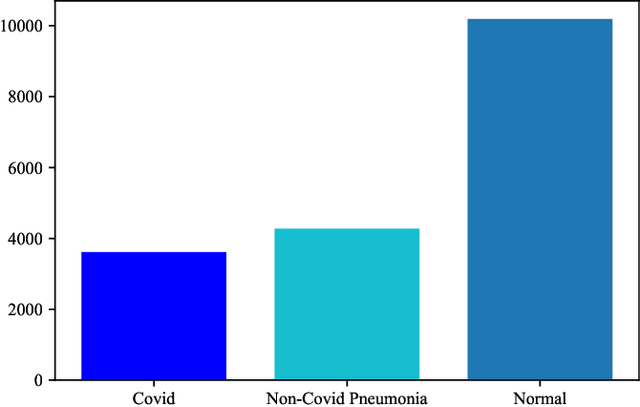

COVID-19 pandemic has spread rapidly and caused a shortage of global medical resources. The efficiency of COVID-19 diagnosis has become highly significant. As deep learning and convolutional neural network (CNN) has been widely utilized and been verified in analyzing medical images, it has become a powerful tool for computer-assisted diagnosis. However, there are two most significant challenges in medical image classification with the help of deep learning and neural networks, one of them is the difficulty of acquiring enough samples, which may lead to model overfitting. Privacy concerns mainly bring the other challenge since medical-related records are often deemed patients' private information and protected by laws such as GDPR and HIPPA. Federated learning can ensure the model training is decentralized on different devices and no data is shared among them, which guarantees privacy. However, with data located on different devices, the accessible data of each device could be limited. Since transfer learning has been verified in dealing with limited data with good performance, therefore, in this paper, We made a trial to implement federated learning and transfer learning techniques using CNNs to classify COVID-19 using lung CT scans. We also explored the impact of dataset distribution at the client-side in federated learning and the number of training epochs a model is trained. Finally, we obtained very high performance with federated learning, demonstrating our success in leveraging accuracy and privacy.
Variational Autoencoder with CCA for Audio-Visual Cross-Modal Retrieval
Dec 05, 2021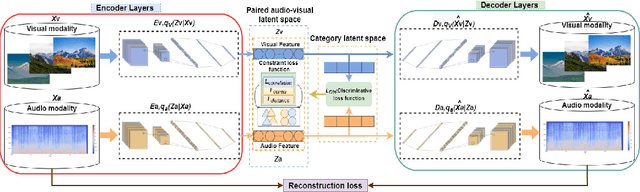


Cross-modal retrieval is to utilize one modality as a query to retrieve data from another modality, which has become a popular topic in information retrieval, machine learning, and database. How to effectively measure the similarity between different modality data is the major challenge of cross-modal retrieval. Although several reasearch works have calculated the correlation between different modality data via learning a common subspace representation, the encoder's ability to extract features from multi-modal information is not satisfactory. In this paper, we present a novel variational autoencoder (VAE) architecture for audio-visual cross-modal retrieval, by learning paired audio-visual correlation embedding and category correlation embedding as constraints to reinforce the mutuality of audio-visual information. On the one hand, audio encoder and visual encoder separately encode audio data and visual data into two different latent spaces. Further, two mutual latent spaces are respectively constructed by canonical correlation analysis (CCA). On the other hand, probabilistic modeling methods is used to deal with possible noise and missing information in the data. Additionally, in this way, the cross-modal discrepancy from intra-modal and inter-modal information are simultaneously eliminated in the joint embedding subspace. We conduct extensive experiments over two benchmark datasets. The experimental outcomes exhibit that the proposed architecture is effective in learning audio-visual correlation and is appreciably better than the existing cross-modal retrieval methods.
Boosting Image Super-Resolution Via Fusion of Complementary Information Captured by Multi-Modal Sensors
Dec 07, 2020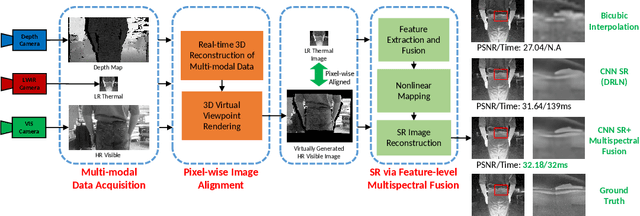

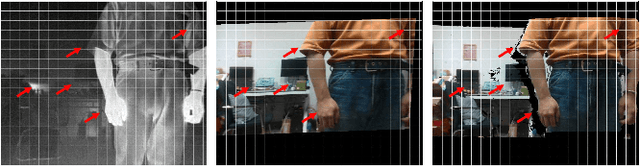
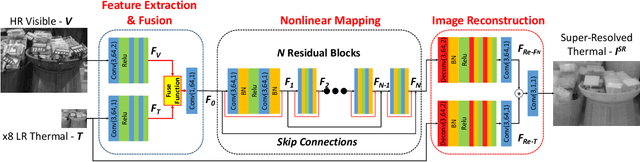
Image Super-Resolution (SR) provides a promising technique to enhance the image quality of low-resolution optical sensors, facilitating better-performing target detection and autonomous navigation in a wide range of robotics applications. It is noted that the state-of-the-art SR methods are typically trained and tested using single-channel inputs, neglecting the fact that the cost of capturing high-resolution images in different spectral domains varies significantly. In this paper, we attempt to leverage complementary information from a low-cost channel (visible/depth) to boost image quality of an expensive channel (thermal) using fewer parameters. To this end, we first present an effective method to virtually generate pixel-wise aligned visible and thermal images based on real-time 3D reconstruction of multi-modal data captured at various viewpoints. Then, we design a feature-level multispectral fusion residual network model to perform high-accuracy SR of thermal images by adaptively integrating co-occurrence features presented in multispectral images. Experimental results demonstrate that this new approach can effectively alleviate the ill-posed inverse problem of image SR by taking into account complementary information from an additional low-cost channel, significantly outperforming state-of-the-art SR approaches in terms of both accuracy and efficiency.
Variable Rate Compression for Raw 3D Point Clouds
Feb 28, 2022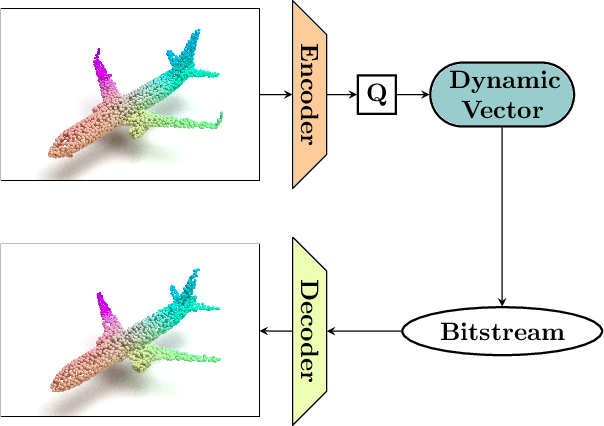
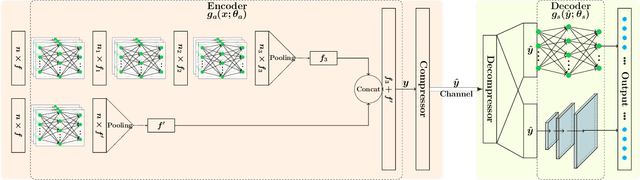

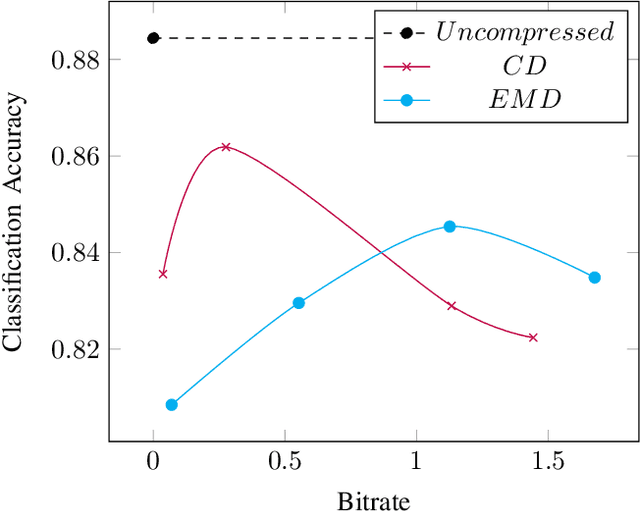
In this paper, we propose a novel variable rate deep compression architecture that operates on raw 3D point cloud data. The majority of learning-based point cloud compression methods work on a downsampled representation of the data. Moreover, many existing techniques require training multiple networks for different compression rates to generate consolidated point clouds of varying quality. In contrast, our network is capable of explicitly processing point clouds and generating a compressed description at a comprehensive range of bitrates. Furthermore, our approach ensures that there is no loss of information as a result of the voxelization process and the density of the point cloud does not affect the encoder/decoder performance. An extensive experimental evaluation shows that our model obtains state-of-the-art results, it is computationally efficient, and it can work directly with point cloud data thus avoiding an expensive voxelized representation.
How Much Position Information Do Convolutional Neural Networks Encode?
Jan 22, 2020
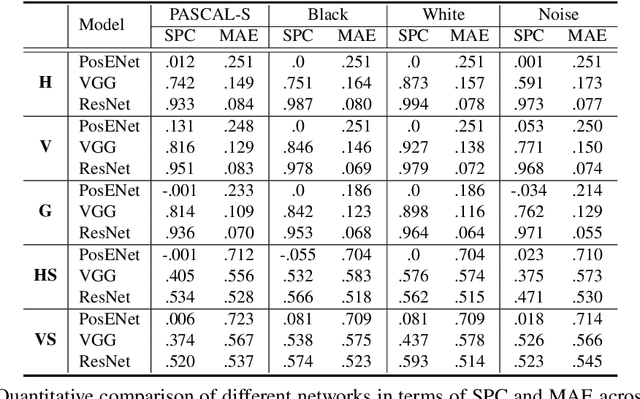
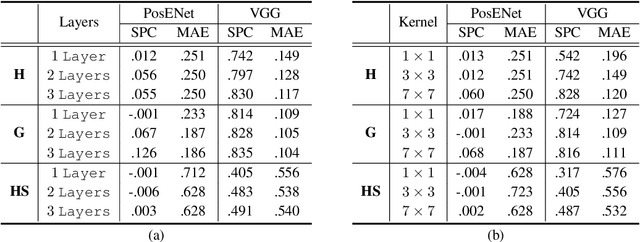

In contrast to fully connected networks, Convolutional Neural Networks (CNNs) achieve efficiency by learning weights associated with local filters with a finite spatial extent. An implication of this is that a filter may know what it is looking at, but not where it is positioned in the image. Information concerning absolute position is inherently useful, and it is reasonable to assume that deep CNNs may implicitly learn to encode this information if there is a means to do so. In this paper, we test this hypothesis revealing the surprising degree of absolute position information that is encoded in commonly used neural networks. A comprehensive set of experiments show the validity of this hypothesis and shed light on how and where this information is represented while offering clues to where positional information is derived from in deep CNNs.
Ethics, Rules of Engagement, and AI: Neural Narrative Mapping Using Large Transformer Language Models
Feb 05, 2022
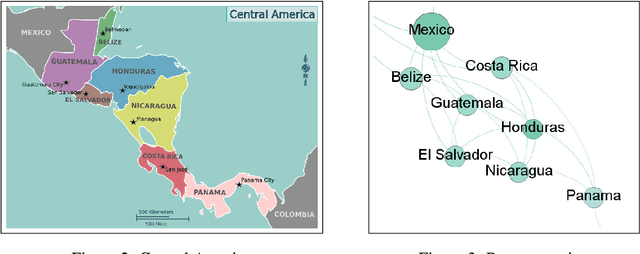
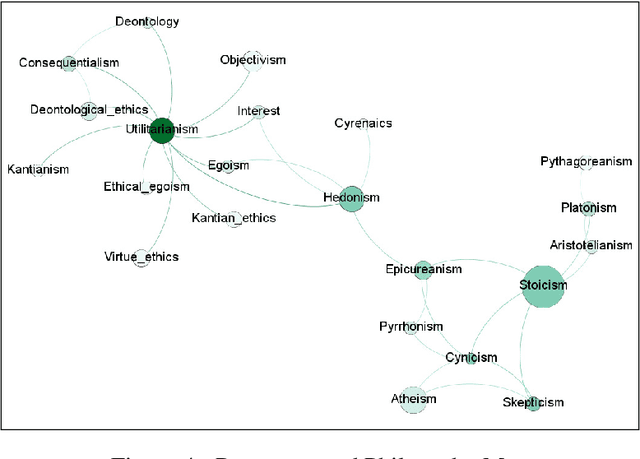
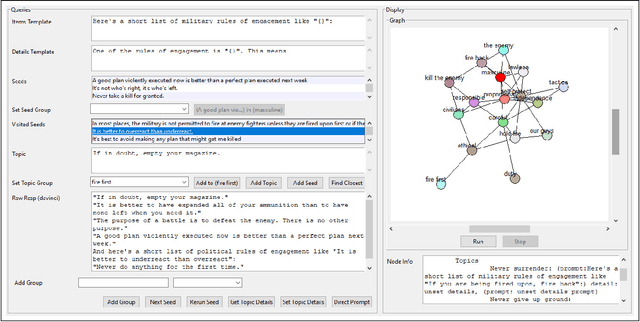
The problem of determining if a military unit has correctly understood an order and is properly executing on it is one that has bedeviled military planners throughout history. The advent of advanced language models such as OpenAI's GPT-series offers new possibilities for addressing this problem. This paper presents a mechanism to harness the narrative output of large language models and produce diagrams or "maps" of the relationships that are latent in the weights of such models as the GPT-3. The resulting "Neural Narrative Maps" (NNMs), are intended to provide insight into the organization of information, opinion, and belief in the model, which in turn provide means to understand intent and response in the context of physical distance. This paper discusses the problem of mapping information spaces in general, and then presents a concrete implementation of this concept in the context of OpenAI's GPT-3 language model for determining if a subordinate is following a commander's intent in a high-risk situation. The subordinate's locations within the NNM allow a novel capability to evaluate the intent of the subordinate with respect to the commander. We show that is is possible not only to determine if they are nearby in narrative space, but also how they are oriented, and what "trajectory" they are on. Our results show that our method is able to produce high-quality maps, and demonstrate new ways of evaluating intent more generally.
* 18 Pages, 13 figures