 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transformation Coding: Simple Objectives for Equivariant Representations
Feb 19, 2022
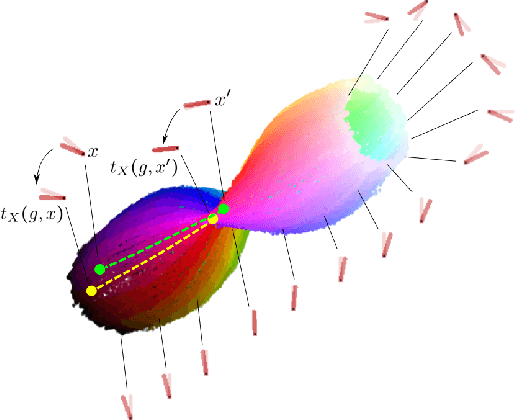

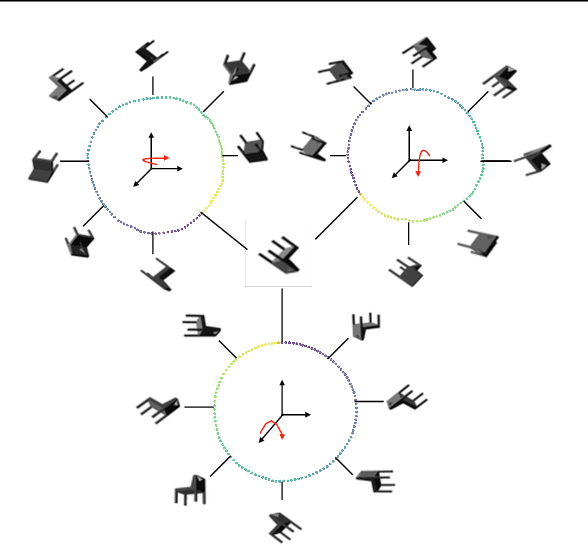

We present a simple non-generative approach to deep representation learning that seeks equivariant deep embedding through simple objectives. In contrast to existing equivariant networks, our transformation coding approach does not constrain the choice of the feed-forward layer or the architecture and allows for an unknown group action on the input space. We introduce several such transformation coding objectives for different Lie groups such as the Euclidean, Orthogonal and the Unitary groups. When using product groups, the representation is decomposed and disentangled. We show that the presence of additional information on different transformations improves disentanglement in transformation coding. We evaluate the representations learnt by transformation coding both qualitatively and quantitatively on downstream tasks, including reinforcement learning.
A Quantitative Comparison between Shannon and Tsallis Havrda Charvat Entropies Applied to Cancer Outcome Prediction
Mar 22, 2022
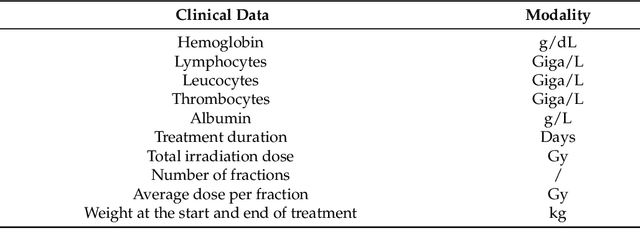
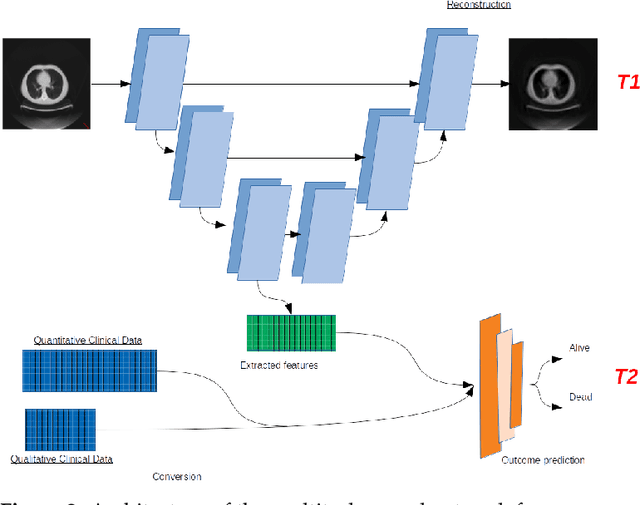

In this paper, we propose to quantitatively compare loss functions based on parameterized Tsallis-Havrda-Charvat entropy and classical Shannon entropy for the training of a deep network in the case of small datasets which are usually encountered in medical applications. Shannon cross-entropy is widely used as a loss function for most neural networks applied to the segmentation, classification and detection of images. Shannon entropy is a particular case of Tsallis-Havrda-Charvat entropy. In this work, we compare these two entropies through a medical application for predicting recurrence in patients with head-neck and lung cancers after treatment. Based on both CT images and patient information, a multitask deep neural network is proposed to perform a recurrence prediction task using cross-entropy as a loss function and an image reconstruction task. Tsallis-Havrda-Charvat cross-entropy is a parameterized cross entropy with the parameter $\alpha$. Shannon entropy is a particular case of Tsallis-Havrda-Charvat entropy for $\alpha$ = 1. The influence of this parameter on the final prediction results is studied. In this paper, the experiments are conducted on two datasets including in total 580 patients, of whom 434 suffered from head-neck cancers and 146 from lung cancers. The results show that Tsallis-Havrda-Charvat entropy can achieve better performance in terms of prediction accuracy with some values of $\alpha$.
* 11 pages, 3 figures
Rate Splitting in FDD Massive MIMO Systems Based on the Second Order Statistics of Transmission Channels
Jan 26, 2022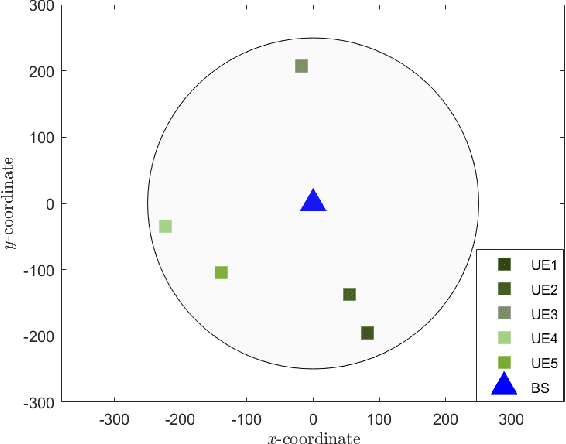
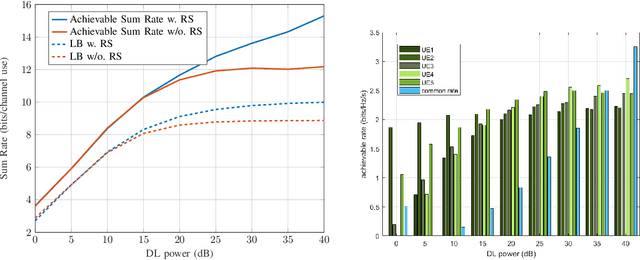
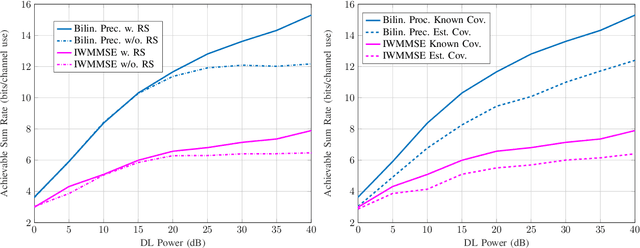
In this work, we present new results for the application of rate splitting multiple access (RSMA) to the downlink (DL) of a massive multiple-input-multiple-output (MaMIMO) system operating in frequency-division-duplex (FDD) mode. Due to the lack of uplink (UL) - DL channel reciprocity in such systems, explicit training in the DL has to be performed in order to gain knowledge about the single-antenna users' channels at the base station (BS). This is ensured through a feedback link from the users to the BS. Dealing with the DL of a massive MIMO system implies that acquiring the DL channel state information (CSI) comes at the cost of a huge training overhead that scales with the number of BS antennas. Therefore, we limit the resources allocated to training by reusing the pilot sequences among the BS antennas that results in a contaminated channel observation. Despite this incomplete channel knowledge at the transmitter side, the proposed RS approach combined with a statistical precoder relying on the channels' second-order information achieves excellent results in terms of spectral efficiency compared to the state-of-art techniques. This is demonstrated via Monte-Carlo simulations of typical communication scenarios.
Forecast Evaluation for Data Scientists: Common Pitfalls and Best Practices
Apr 04, 2022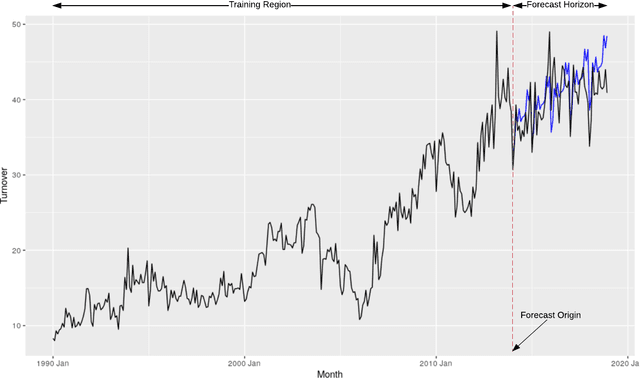
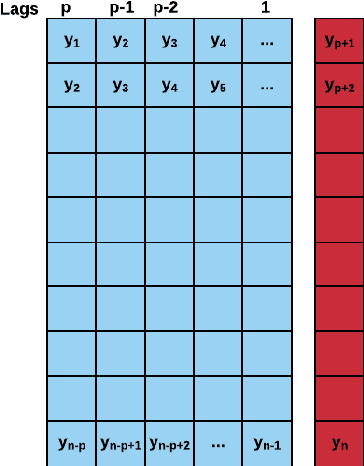

Machine Learning (ML) and Deep Learning (DL) methods are increasingly replacing traditional methods in many domains involved with important decision making activities. DL techniques tailor-made for specific tasks such as image recognition, signal processing, or speech analysis are being introduced at a fast pace with many improvements. However, for the domain of forecasting, the current state in the ML community is perhaps where other domains such as Natural Language Processing and Computer Vision were at several years ago. The field of forecasting has mainly been fostered by statisticians/econometricians; consequently the related concepts are not the mainstream knowledge among general ML practitioners. The different non-stationarities associated with time series challenge the data-driven ML models. Nevertheless, recent trends in the domain have shown that with the availability of massive amounts of time series, ML techniques are quite competent in forecasting, when related pitfalls are properly handled. Therefore, in this work we provide a tutorial-like compilation of the details of one of the most important steps in the overall forecasting process, namely the evaluation. This way, we intend to impart the information of forecast evaluation to fit the context of ML, as means of bridging the knowledge gap between traditional methods of forecasting and state-of-the-art ML techniques. We elaborate on the different problematic characteristics of time series such as non-normalities and non-stationarities and how they are associated with common pitfalls in forecast evaluation. Best practices in forecast evaluation are outlined with respect to the different steps such as data partitioning, error calculation, statistical testing, and others. Further guidelines are also provided along selecting valid and suitable error measures depending on the specific characteristics of the dataset at hand.
RTNet: Relation Transformer Network for Diabetic Retinopathy Multi-lesion Segmentation
Jan 26, 2022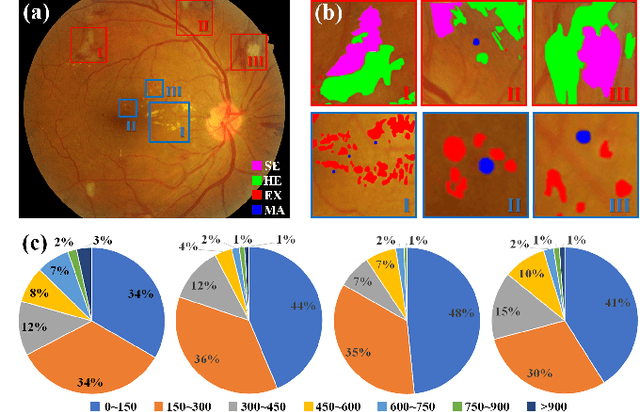
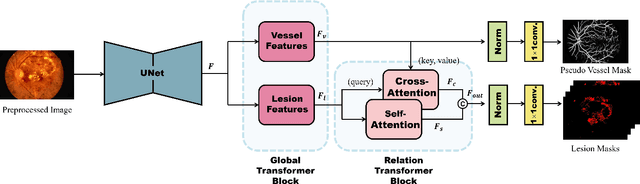
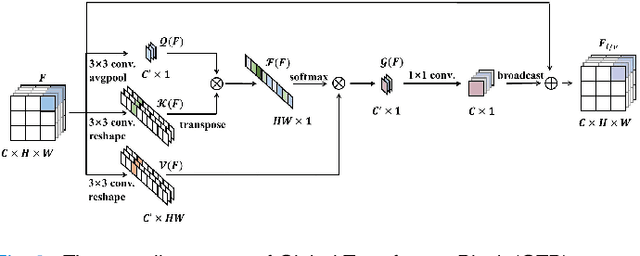
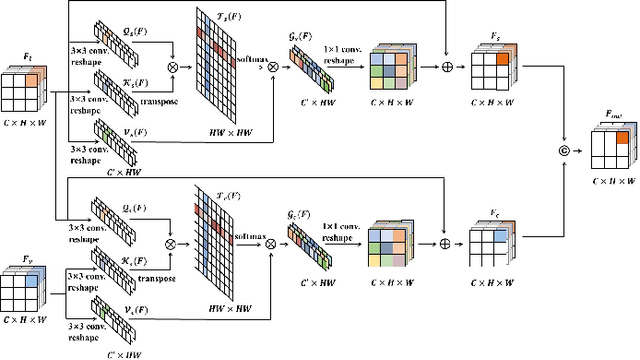
Automatic diabetic retinopathy (DR) lesions segmentation makes great sense of assisting ophthalmologists in diagnosis. Although many researches have been conducted on this task, most prior works paid too much attention to the designs of networks instead of considering the pathological association for lesions. Through investigating the pathogenic causes of DR lesions in advance, we found that certain lesions are closed to specific vessels and present relative patterns to each other. Motivated by the observation, we propose a relation transformer block (RTB) to incorporate attention mechanisms at two main levels: a self-attention transformer exploits global dependencies among lesion features, while a cross-attention transformer allows interactions between lesion and vessel features by integrating valuable vascular information to alleviate ambiguity in lesion detection caused by complex fundus structures. In addition, to capture the small lesion patterns first, we propose a global transformer block (GTB) which preserves detailed information in deep network. By integrating the above blocks of dual-branches, our network segments the four kinds of lesions simultaneously. Comprehensive experiments on IDRiD and DDR datasets well demonstrate the superiority of our approach, which achieves competitive performance compared to state-of-the-arts.
Modelling variability in vibration-based PBSHM via a generalised population form
Mar 14, 2022


Structural health monitoring (SHM) has been an active research area for the last three decades, and has accumulated a number of critical advances over that period, as can be seen in the literature. However, SHM is still facing challenges because of the paucity of damage-state data, operational and environmental fluctuations, repeatability issues, and changes in boundary conditions. These issues present as inconsistencies in the captured features and can have a huge impact on the practical implementation, but more critically, on the generalisation of the technology. Population-based SHM has been designed to address some of these concerns by modelling and transferring missing information using data collected from groups of similar structures. In this work, vibration data were collected from four healthy, nominally-identical, full-scale composite helicopter blades. Manufacturing differences (e.g., slight differences in geometry and/or material properties), among the blades presented as variability in their structural dynamics, which can be very problematic for SHM based on machine learning from vibration data. This work aims to address this variability by defining a general model for the frequency response functions of the blades, called a form, using mixtures of Gaussian processes.
Physics-informed ConvNet: Learning Physical Field from a Shallow Neural Network
Jan 26, 2022

Big-data-based artificial intelligence (AI) supports profound evolution in almost all of science and technology. However, modeling and forecasting multi-physical systems remain a challenge due to unavoidable data scarcity and noise. Improving the generalization ability of neural networks by "teaching" domain knowledge and developing a new generation of models combined with the physical laws have become promising areas of machine learning research. Different from "deep" fully-connected neural networks embedded with physical information (PINN), a novel shallow framework named physics-informed convolutional network (PICN) is recommended from a CNN perspective, in which the physical field is generated by a deconvolution layer and a single convolution layer. The difference fields forming the physical operator are constructed using the pre-trained shallow convolution layer. An efficient linear interpolation network calculates the loss function involving boundary conditions and the physical constraints in irregular geometry domains. The effectiveness of the current development is illustrated through some numerical cases involving the solving (and estimation) of nonlinear physical operator equations and recovering physical information from noisy observations. Its potential advantage in approximating physical fields with multi-frequency components indicates that PICN may become an alternative neural network solver in physics-informed machine learning.
Delay-adaptive step-sizes for asynchronous learning
Feb 27, 2022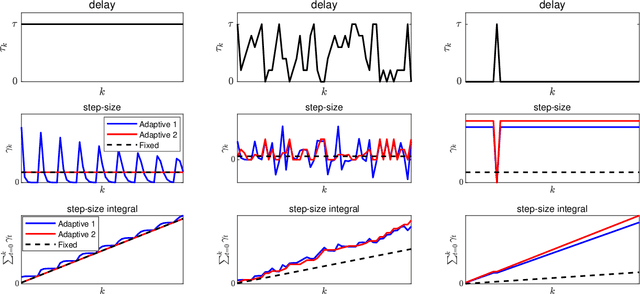
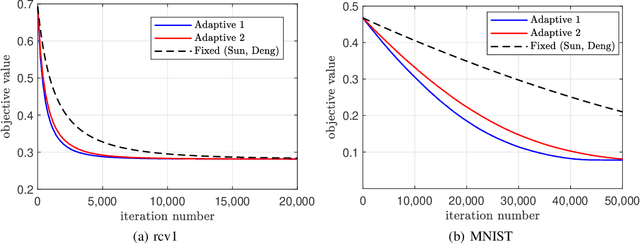
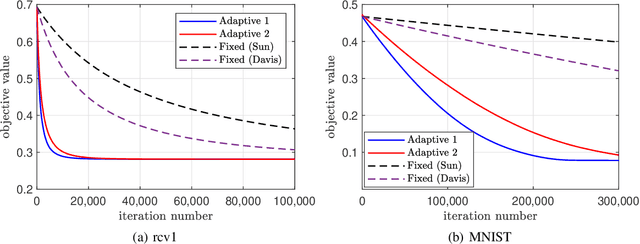
In scalable machine learning systems, model training is often parallelized over multiple nodes that run without tight synchronization. Most analysis results for the related asynchronous algorithms use an upper bound on the information delays in the system to determine learning rates. Not only are such bounds hard to obtain in advance, but they also result in unnecessarily slow convergence. In this paper, we show that it is possible to use learning rates that depend on the actual time-varying delays in the system. We develop general convergence results for delay-adaptive asynchronous iterations and specialize these to proximal incremental gradient descent and block-coordinate descent algorithms. For each of these methods, we demonstrate how delays can be measured on-line, present delay-adaptive step-size policies, and illustrate their theoretical and practical advantages over the state-of-the-art.
Dual-Tasks Siamese Transformer Framework for Building Damage Assessment
Jan 26, 2022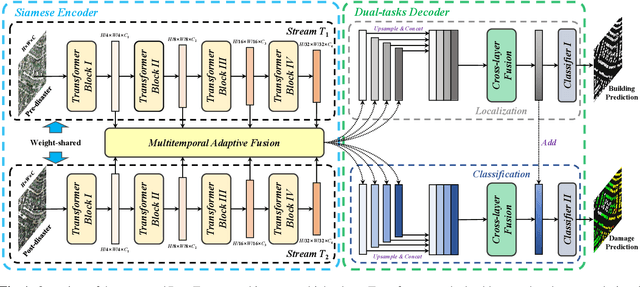
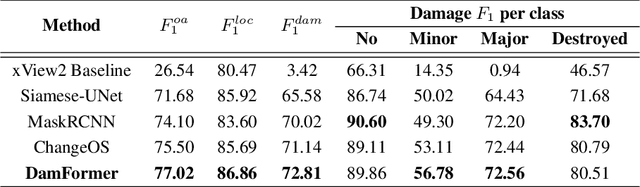
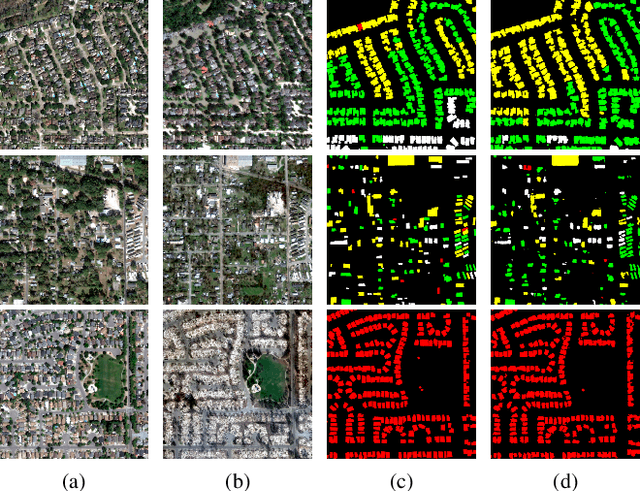
Accurate and fine-grained information about the extent of damage to buildings is essential for humanitarian relief and disaster response. However, as the most commonly used architecture in remote sensing interpretation tasks, Convolutional Neural Networks (CNNs) have limited ability to model the non-local relationship between pixels. Recently, Transformer architecture first proposed for modeling long-range dependency in natural language processing has shown promising results in computer vision tasks. Considering the frontier advances of Transformer architecture in the computer vision field, in this paper, we present the first attempt at designing a Transformer-based damage assessment architecture (DamFormer). In DamFormer, a siamese Transformer encoder is first constructed to extract non-local and representative deep features from input multitemporal image-pairs. Then, a multitemporal fusion module is designed to fuse information for downstream tasks. Finally, a lightweight dual-tasks decoder aggregates multi-level features for final prediction. To the best of our knowledge, it is the first time that such a deep Transformer-based network is proposed for multitemporal remote sensing interpretation tasks. The experimental results on the large-scale damage assessment dataset xBD demonstrate the potential of the Transformer-based architecture.
TCTrack: Temporal Contexts for Aerial Tracking
Mar 05, 2022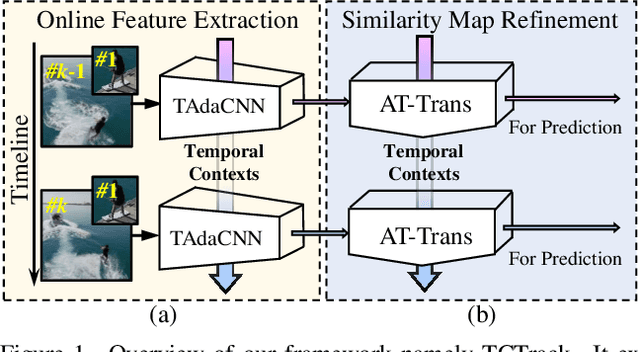
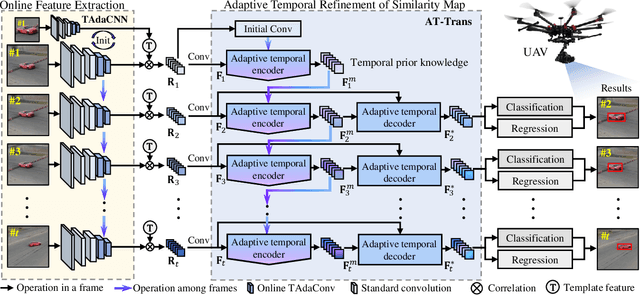
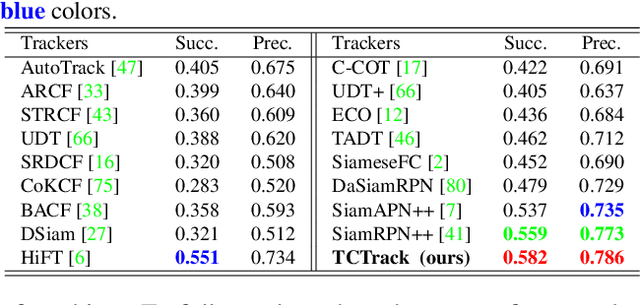
Temporal contexts among consecutive frames are far from being fully utilized in existing visual trackers. In this work, we present TCTrack, a comprehensive framework to fully exploit temporal contexts for aerial tracking. The temporal contexts are incorporated at \textbf{two levels}: the extraction of \textbf{features} and the refinement of \textbf{similarity maps}. Specifically, for feature extraction, an online temporally adaptive convolution is proposed to enhance the spatial features using temporal information, which is achieved by dynamically calibrating the convolution weights according to the previous frames. For similarity map refinement, we propose an adaptive temporal transformer, which first effectively encodes temporal knowledge in a memory-efficient way, before the temporal knowledge is decoded for accurate adjustment of the similarity map. TCTrack is effective and efficient: evaluation on four aerial tracking benchmarks shows its impressive performance; real-world UAV tests show its high speed of over 27 FPS on NVIDIA Jetson AGX Xavier.