 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Firefly: Supporting Drone Localization With Visible Light Communication
Dec 13, 2021
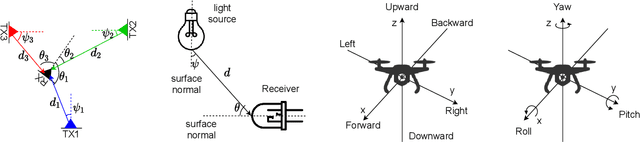

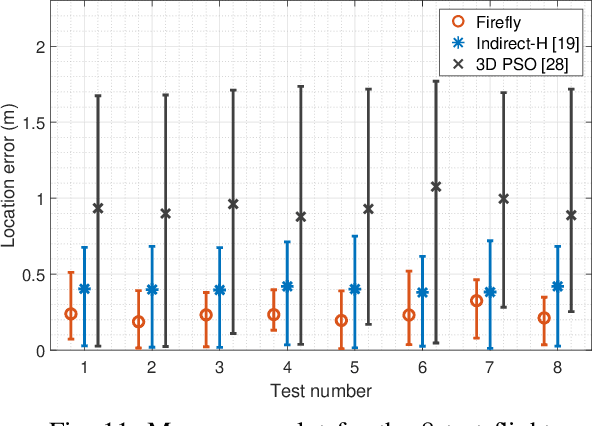
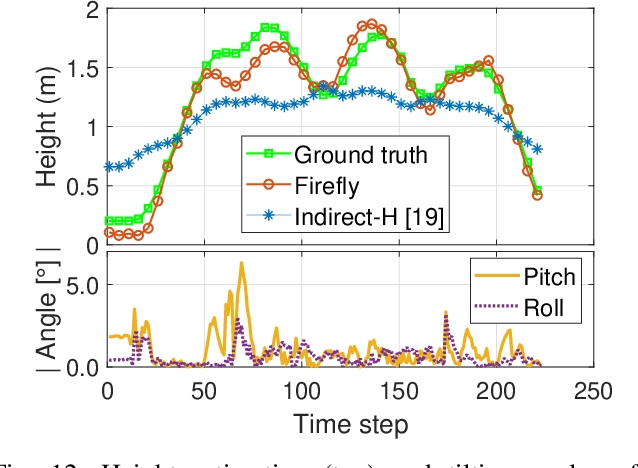
Drones are not fully trusted yet. Their reliance on radios and cameras for navigation raises safety and privacy concerns. These systems can fail, causing accidents, or be misused for unauthorized recordings. Considering recent regulations allowing commercial drones to operate only at night, we propose a radically new approach where drones obtain navigation information from artificial lighting. In our system, standard light bulbs modulate their intensity to send beacons and drones decode this information with a simple photodiode. This optical information is combined with the inertial and altitude sensors in the drones to provide localization without the need for radios, GPS or cameras. Our framework is the first to provide 3D drone localization with light and we evaluate it with a testbed consisting of four light beacons and a mini-drone. We show that, our approach allows to locate the drone within a few decimeters of the actual position and compared to state-of-the-art positioning methods, reduces the localization error by 42%.
Symbol quantization in interstellar communications: methods and observations
Mar 18, 2022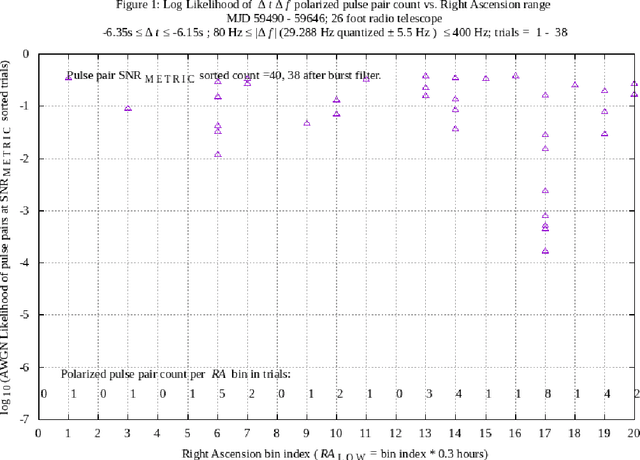
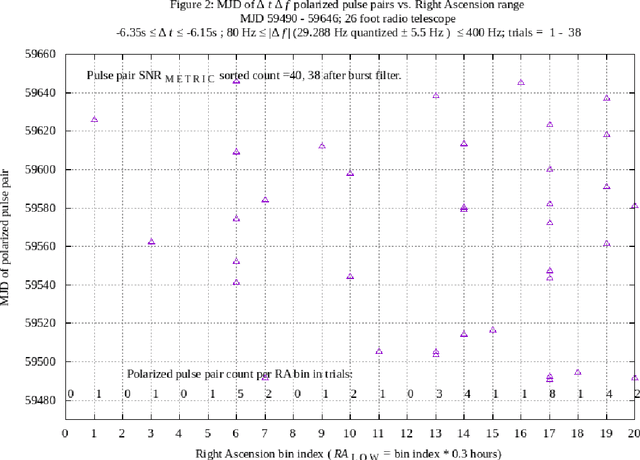
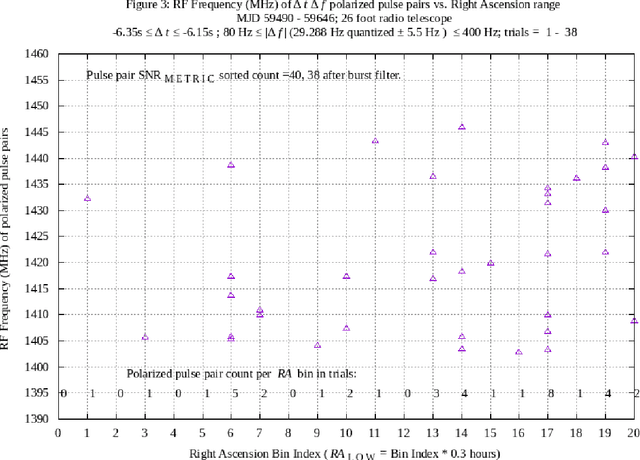
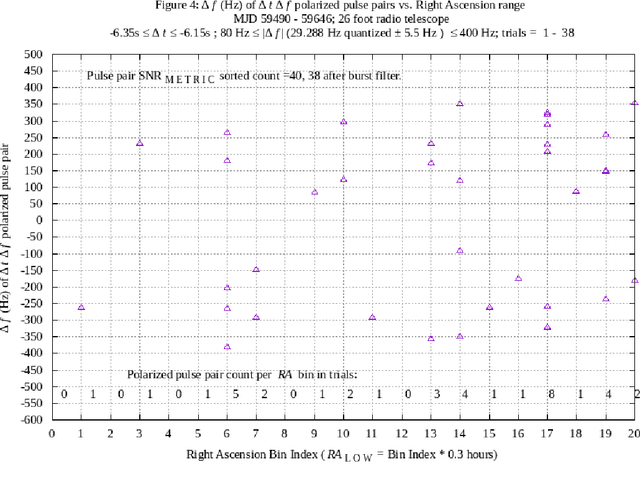
Interstellar communication transmitters, intended to be discovered and decoded to information bits, are expected to transmit signals that contain message symbols quantized in at least one of the degrees of freedom of the transmitted signal. A hypothesis is proposed that signal quantization, in the form of multiplicative values of one or more signal measurements, may be observable during the reception of hypothetical discoverable interstellar communication signals. In previous work, using single and multiple synchronized radio telescopes, candidate hypothetical interstellar communication signals comprising delta-t delta-f opposite circular polarized pulse pairs have been reported and analyzed (ref. arXiv:2105.03727, arXiv:2106.10168, arXiv:2202.12791). In the latter report, an apparent quantization of delta-f at multiples of 58.575 Hz was observed. In the current work, a machine process has been implemented to further examine anomalous delta-f and delta-t quantization, with results reported in this paper. As in some past work, a 26 foot diameter radio telescope with fixed azimuth and elevation pointing is used to enable a Right Ascension filter to measure signals associated with a celestial direction of interest, relative to other directions, over a 6.3 hour range of Right Ascension. The 5.25 plus or minus 0.15 hour Right Ascension, -7.6 degrees plus or minus 1 degree Declination celestial direction presents repetition and quantization anomalies, during an experiment lasting 157 days, with the first 143 days overlapping the previous experiment.
NetRCA: An Effective Network Fault Cause Localization Algorithm
Feb 23, 2022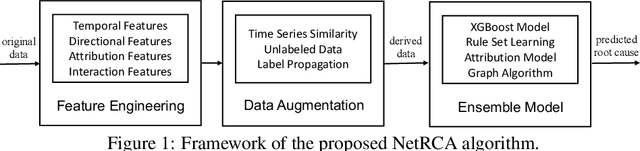
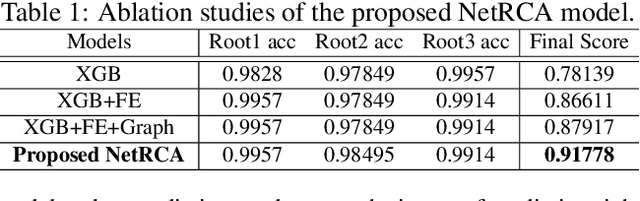
Localizing the root cause of network faults is crucial to network operation and maintenance. However, due to the complicated network architectures and wireless environments, as well as limited labeled data, accurately localizing the true root cause is challenging. In this paper, we propose a novel algorithm named NetRCA to deal with this problem. Firstly, we extract effective derived features from the original raw data by considering temporal, directional, attribution, and interaction characteristics. Secondly, we adopt multivariate time series similarity and label propagation to generate new training data from both labeled and unlabeled data to overcome the lack of labeled samples. Thirdly, we design an ensemble model which combines XGBoost, rule set learning, attribution model, and graph algorithm, to fully utilize all data information and enhance performance. Finally, experiments and analysis are conducted on the real-world dataset from ICASSP 2022 AIOps Challenge to demonstrate the superiority and effectiveness of our approach.
Modelling Underwater Acoustic Propagation using One-way Wave Equations
Feb 14, 2022The primary contribution of this paper is to characterize the propagation of acoustic signal carrying information through any medium and the interaction of the travelling acoustic signal with the surrounding medium. We will use the concept of damped harmonic oscillator to model the medium and Milne's oscillator technique to map the interaction of the acoustic signal with the medium. The acoustic signal itself will be modelled using the one-way wave equation formulated in terms of acoustic pressure and velocity of acoustic waves through the medium. Using the above-mentioned concepts, we calculated the effective signal strength, phase shift and time period of the communicated signal. Numerical results are generated to present the evolution of signal strength and received signal envelope in underwater environment.
Model Comparison and Calibration Assessment: User Guide for Consistent Scoring Functions in Machine Learning and Actuarial Practice
Feb 25, 2022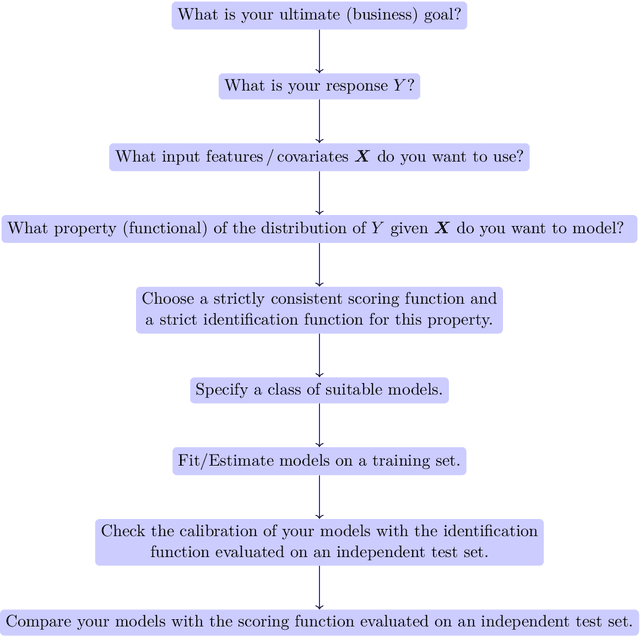

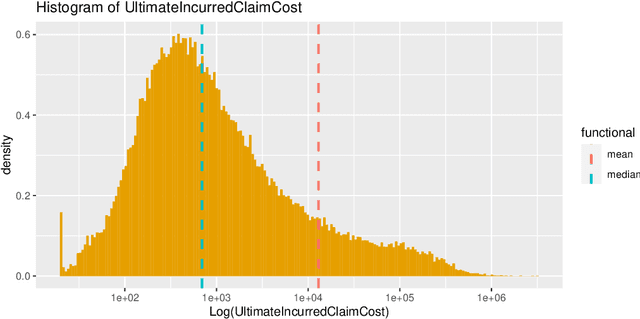

One of the main tasks of actuaries and data scientists is to build good predictive models for certain phenomena such as the claim size or the number of claims in insurance. These models ideally exploit given feature information to enhance the accuracy of prediction. This user guide revisits and clarifies statistical techniques to assess the calibration or adequacy of a model on the one hand, and to compare and rank different models on the other hand. In doing so, it emphasises the importance of specifying the prediction target at hand a priori and of choosing the scoring function in model comparison in line with this target. Guidance for the practical choice of the scoring function is provided. Striving to bridge the gap between science and daily practice in application, it focuses mainly on the pedagogical presentation of existing results and of best practice. The results are accompanied and illustrated by two real data case studies on workers' compensation and customer churn.
ESS: Learning Event-based Semantic Segmentation from Still Images
Mar 18, 2022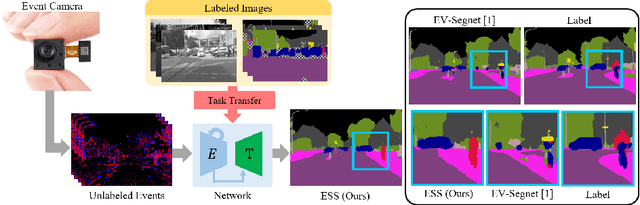

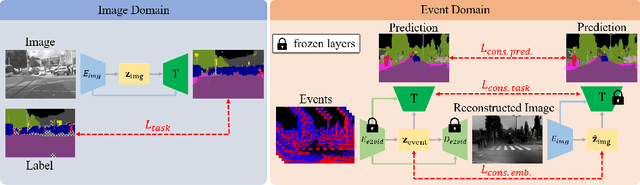
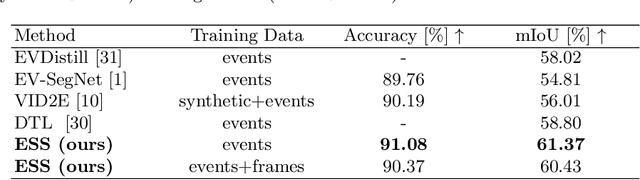
Retrieving accurate semantic information in challenging high dynamic range (HDR) and high-speed conditions remains an open challenge for image-based algorithms due to severe image degradations. Event cameras promise to address these challenges since they feature a much higher dynamic range and are resilient to motion blur. Nonetheless, semantic segmentation with event cameras is still in its infancy which is chiefly due to the novelty of the sensor, and the lack of high-quality, labeled datasets. In this work, we introduce ESS, which tackles this problem by directly transferring the semantic segmentation task from existing labeled image datasets to unlabeled events via unsupervised domain adaptation (UDA). Compared to existing UDA methods, our approach aligns recurrent, motion-invariant event embeddings with image embeddings. For this reason, our method neither requires video data nor per-pixel alignment between images and events and, crucially, does not need to hallucinate motion from still images. Additionally, to spur further research in event-based semantic segmentation, we introduce DSEC-Semantic, the first large-scale event-based dataset with fine-grained labels. We show that using image labels alone, ESS outperforms existing UDA approaches, and when combined with event labels, it even outperforms state-of-the-art supervised approaches on both DDD17 and DSEC-Semantic. Finally, ESS is general-purpose, which unlocks the vast amount of existing labeled image datasets and paves the way for new and exciting research directions in new fields previously inaccessible for event cameras.
Parameter-Efficient Mixture-of-Experts Architecture for Pre-trained Language Models
Mar 02, 2022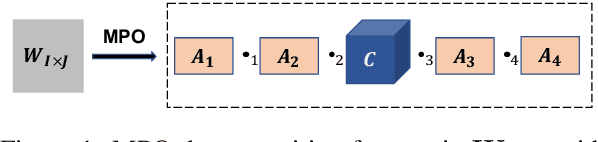
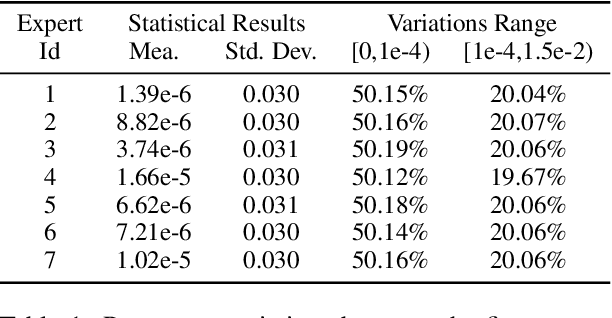
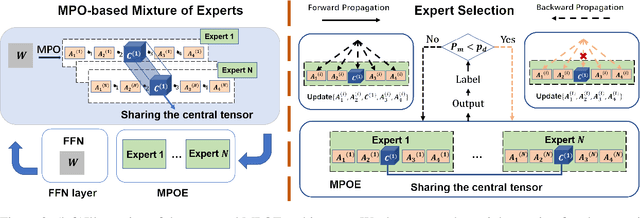
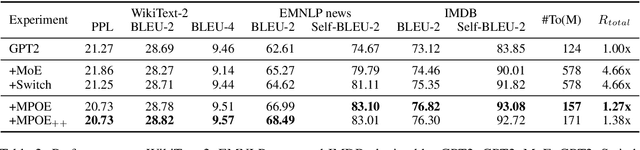
The state-of-the-art Mixture-of-Experts (short as MoE) architecture has achieved several remarkable successes in terms of increasing model capacity. However, MoE has been hindered widespread adoption due to complexity, communication costs, and training instability. Here we present a novel MoE architecture based on matrix product operators (MPO) from quantum many-body physics. It can decompose an original matrix into central tensors (containing the core information) and auxiliary tensors (with only a small proportion of parameters). With the decomposed MPO structure, we can reduce the parameters of the original MoE architecture by sharing a global central tensor across experts and keeping expert-specific auxiliary tensors. We also design the gradient mask strategy for the tensor structure of MPO to alleviate the overfitting problem. Experiments on the three well-known downstream natural language datasets based on GPT2 show improved performance and efficiency in increasing model capacity (7.26x fewer parameters with the same amount of experts). We additionally demonstrate an improvement in the positive transfer effects of our approach for multi-task learning.
TAFNet: A Three-Stream Adaptive Fusion Network for RGB-T Crowd Counting
Feb 17, 2022
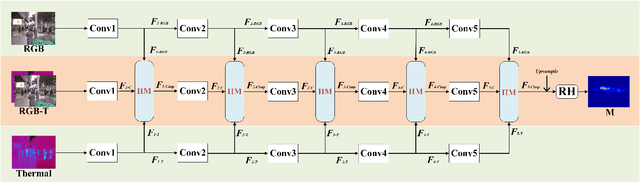
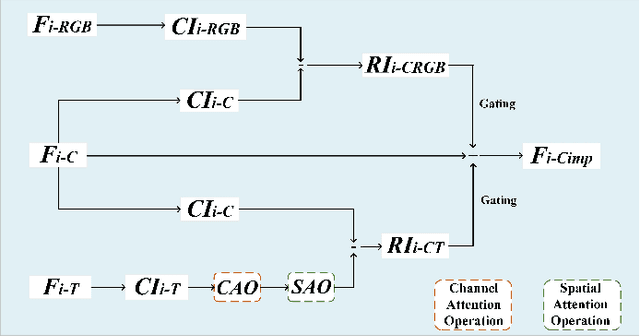
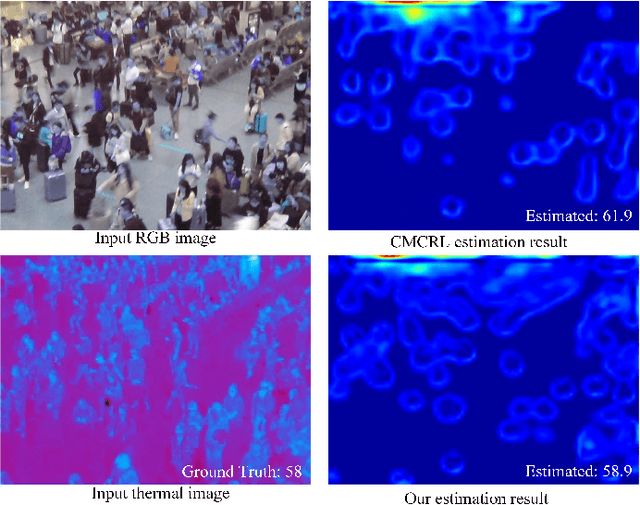
In this paper, we propose a three-stream adaptive fusion network named TAFNet, which uses paired RGB and thermal images for crowd counting. Specifically, TAFNet is divided into one main stream and two auxiliary streams. We combine a pair of RGB and thermal images to constitute the input of main stream. Two auxiliary streams respectively exploit RGB image and thermal image to extract modality-specific features. Besides, we propose an Information Improvement Module (IIM) to fuse the modality-specific features into the main stream adaptively. Experiment results on RGBT-CC dataset show that our method achieves more than 20% improvement on mean average error and root mean squared error compared with state-of-the-art method. The source code will be publicly available at https://github.com/TANGHAIHAN/TAFNet.
GIPA: General Information Propagation Algorithm for Graph Learning
May 13, 2021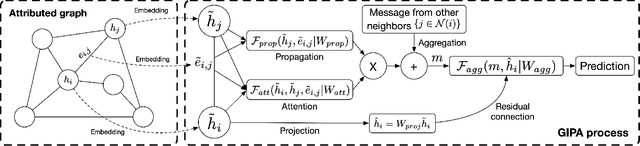
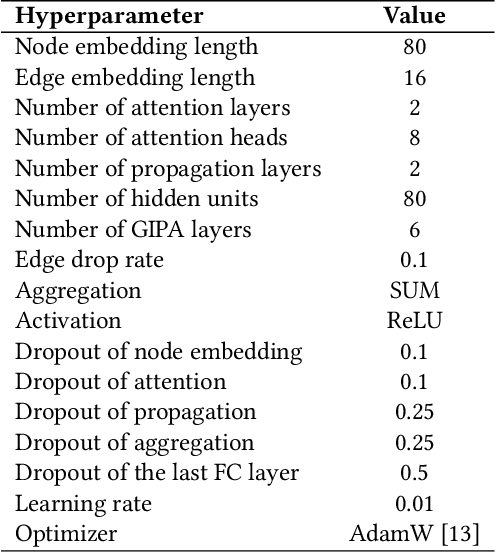
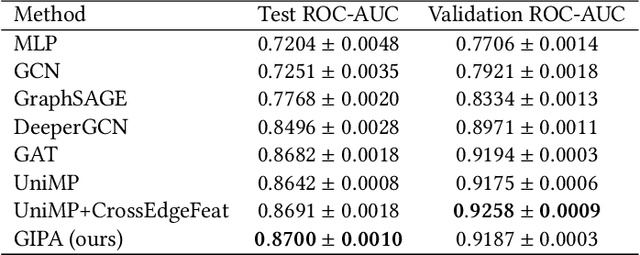
Graph neural networks (GNNs) have been popularly used in analyzing graph-structured data, showing promising results in various applications such as node classification, link prediction and network recommendation. In this paper, we present a new graph attention neural network, namely GIPA, for attributed graph data learning. GIPA consists of three key components: attention, feature propagation and aggregation. Specifically, the attention component introduces a new multi-layer perceptron based multi-head to generate better non-linear feature mapping and representation than conventional implementations such as dot-product. The propagation component considers not only node features but also edge features, which differs from existing GNNs that merely consider node features. The aggregation component uses a residual connection to generate the final embedding. We evaluate the performance of GIPA using the Open Graph Benchmark proteins (ogbn-proteins for short) dataset. The experimental results reveal that GIPA can beat the state-of-the-art models in terms of prediction accuracy, e.g., GIPA achieves an average ROC-AUC of $0.8700\pm 0.0010$ and outperforms all the previous methods listed in the ogbn-proteins leaderboard.
Hybrid Neural Coded Modulation: Design and Training Methods
Feb 04, 2022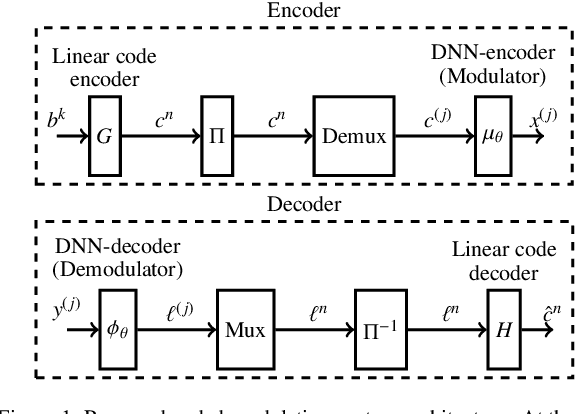
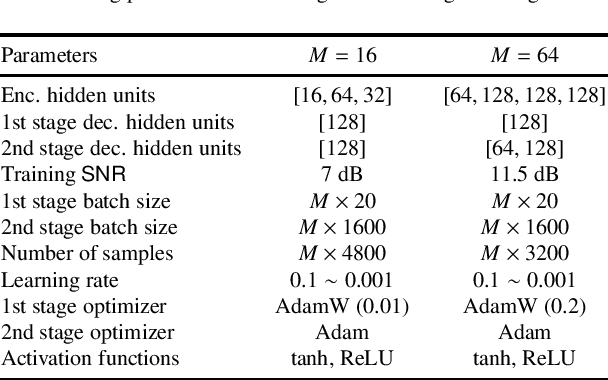
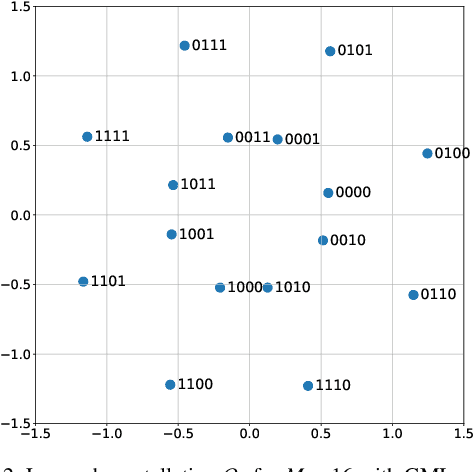
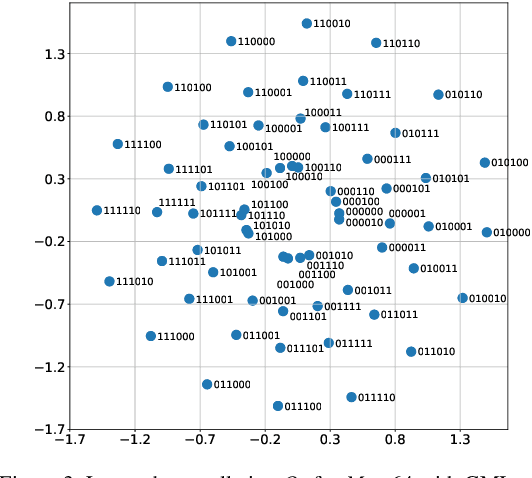
We propose a hybrid coded modulation scheme which composes of inner and outer codes. The outer-code can be any standard binary linear code with efficient soft decoding capability (e.g. low-density parity-check (LDPC) codes). The inner code is designed using a deep neural network (DNN) which takes the channel coded bits and outputs modulated symbols. For training the DNN, we propose to use a loss function that is inspired by the generalized mutual information. The resulting constellations are shown to outperform the conventional quadrature amplitude modulation (QAM) based coding scheme for modulation order 16 and 64 with 5G standard LDPC codes.