 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exact Community Recovery over Signed Graphs
Feb 22, 2022
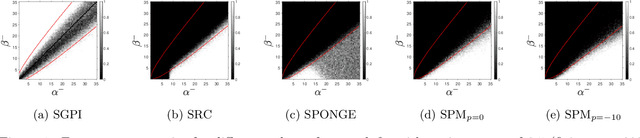
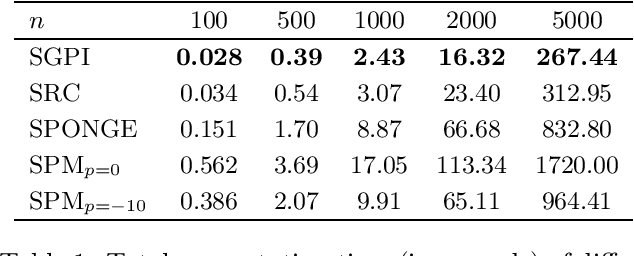

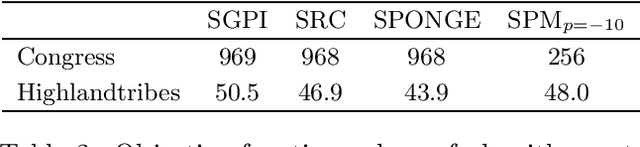
Signed graphs encode similarity and dissimilarity relationships among different entities with positive and negative edges. In this paper, we study the problem of community recovery over signed graphs generated by the signed stochastic block model (SSBM) with two equal-sized communities. Our approach is based on the maximum likelihood estimation (MLE) of the SSBM. Unlike many existing approaches, our formulation reveals that the positive and negative edges of a signed graph should be treated unequally. We then propose a simple two-stage iterative algorithm for solving the regularized MLE. It is shown that in the logarithmic degree regime, the proposed algorithm can exactly recover the underlying communities in nearly-linear time at the information-theoretic limit. Numerical results on both synthetic and real data are reported to validate and complement our theoretical developments and demonstrate the efficacy of the proposed method.
NOMA Inspired Integrated Sensing and Communication
Jan 12, 2022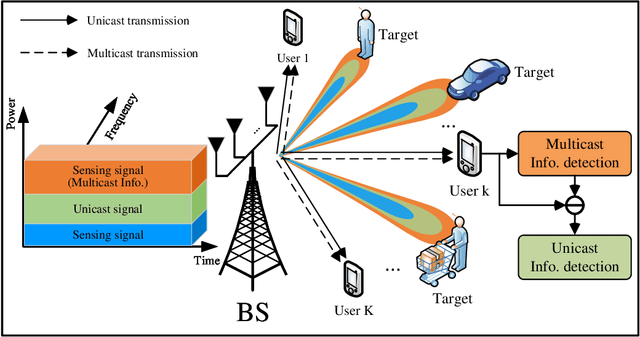
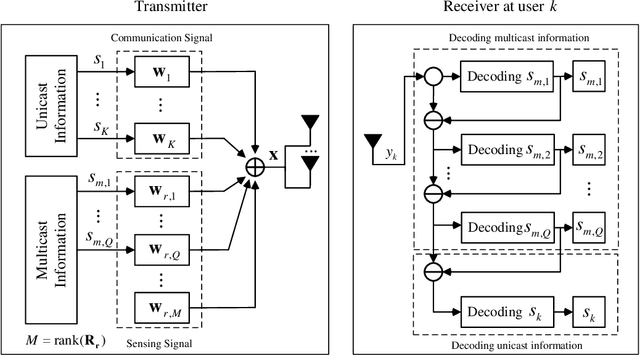
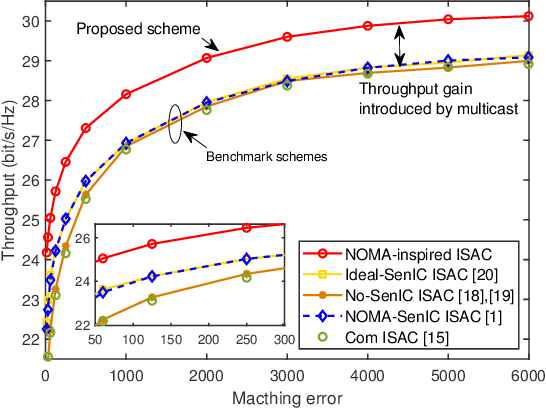
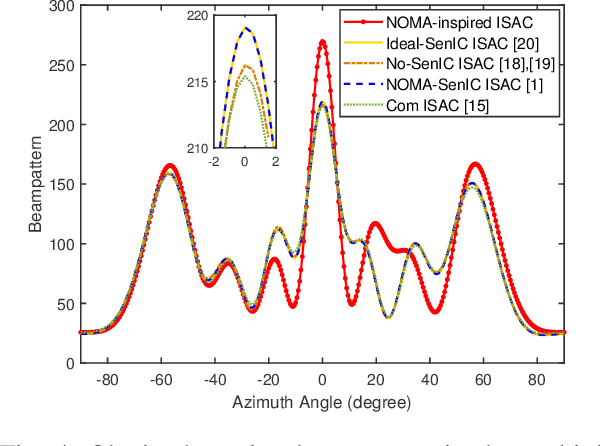
A non-orthogonal multiple access (NOMA)-inspired integrated sensing and communication (ISAC) framework is proposed, where a dual-functional base station (BS) transmits the composite unicast communication signal and sensing signal. In contrast to treating the sensing signal as the harmful interference to communication, in this work, multiple beams of the sensing signal are employed to convey multicast information following the concept of NOMA. Then, each communication user receives multiple multicast streams and one desired unicast stream, which are detected via successive interference cancellation (SIC). Based on the proposed framework, a multiple-objective optimization problem (MOOP) is formulated for designing the transmit beamforming, which characterizes the communication-sensing trade-off. For general the multiple-user scenario, the formulated MOOP is converted to a single-objective optimization problem (SOOP) via the e-constraint method. Then, a block coordinate descent (BCD) algorithm is proposed by employing fractional programming (FP) and successive convex approximation (SCA) to find a suboptimal solution. For the special single-user scenario, the globally optimal solution can be obtained by transforming the MOOP to a quadratic semidefinite program (QSDP). Moreover, it is rigorously proved that 1) in the multiple-user scenario, the proposed framework always outperform the sensing-interference-cancellation (SenIC) ISAC frameworks by further exploiting sensing signal for delivering information; 2) in the single-user scenario, the proposed framework achieves the same performance as the existing SenIC ISAC frameworks, which reveals that the sensing interference coordination is not required in this case. Numerical results verify the theoretical results and show that exploiting one beam of the sensing signal for delivering multicast information is sufficient for the proposed framework.
Cross-Centroid Ripple Pattern for Facial Expression Recognition
Jan 16, 2022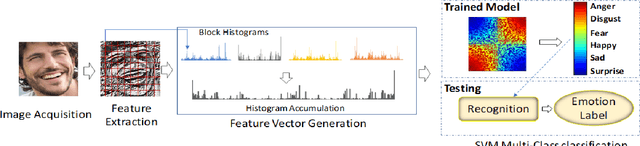
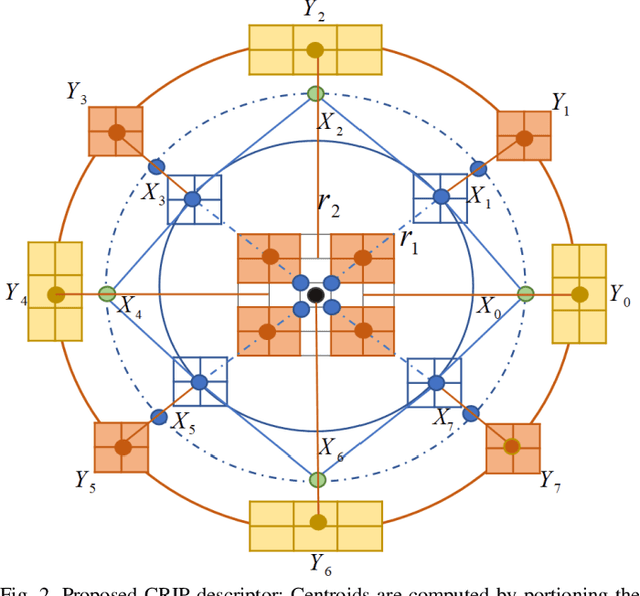


In this paper, we propose a new feature descriptor Cross-Centroid Ripple Pattern (CRIP) for facial expression recognition. CRIP encodes the transitional pattern of a facial expression by incorporating cross-centroid relationship between two ripples located at radius r1 and r2 respectively. These ripples are generated by dividing the local neighborhood region into subregions. Thus, CRIP has ability to preserve macro and micro structural variations in an extensive region, which enables it to deal with side views and spontaneous expressions. Furthermore, gradient information between cross centroid ripples provides strenght to captures prominent edge features in active patches: eyes, nose and mouth, that define the disparities between different facial expressions. Cross centroid information also provides robustness to irregular illumination. Moreover, CRIP utilizes the averaging behavior of pixels at subregions that yields robustness to deal with noisy conditions. The performance of proposed descriptor is evaluated on seven comprehensive expression datasets consisting of challenging conditions such as age, pose, ethnicity and illumination variations. The experimental results show that our descriptor consistently achieved better accuracy rate as compared to existing state-of-art approaches.
Which side are you on? Insider-Outsider classification in conspiracy-theoretic social media
Mar 08, 2022
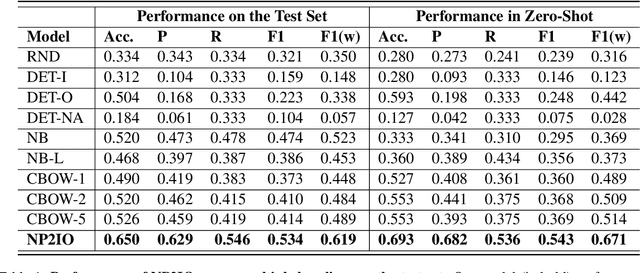
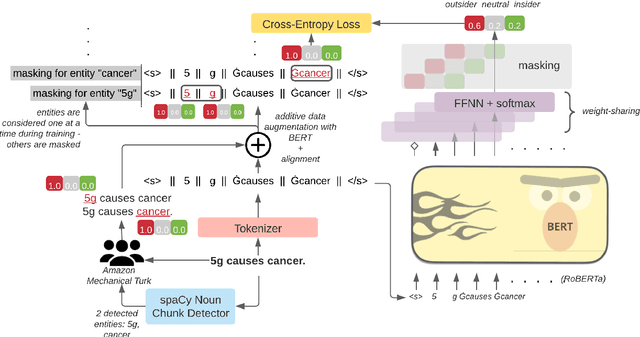
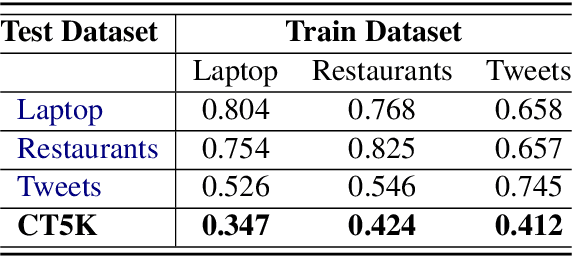
Social media is a breeding ground for threat narratives and related conspiracy theories. In these, an outside group threatens the integrity of an inside group, leading to the emergence of sharply defined group identities: Insiders -- agents with whom the authors identify and Outsiders -- agents who threaten the insiders. Inferring the members of these groups constitutes a challenging new NLP task: (i) Information is distributed over many poorly-constructed posts; (ii) Threats and threat agents are highly contextual, with the same post potentially having multiple agents assigned to membership in either group; (iii) An agent's identity is often implicit and transitive; and (iv) Phrases used to imply Outsider status often do not follow common negative sentiment patterns. To address these challenges, we define a novel Insider-Outsider classification task. Because we are not aware of any appropriate existing datasets or attendant models, we introduce a labeled dataset (CT5K) and design a model (NP2IO) to address this task. NP2IO leverages pretrained language modeling to classify Insiders and Outsiders. NP2IO is shown to be robust, generalizing to noun phrases not seen during training, and exceeding the performance of non-trivial baseline models by $20\%$.
Learning to Learn with Variational Information Bottleneck for Domain Generalization
Jul 15, 2020
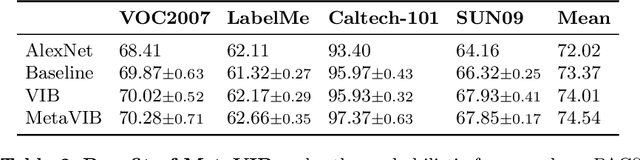

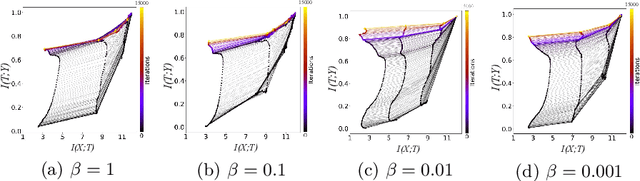
Domain generalization models learn to generalize to previously unseen domains, but suffer from prediction uncertainty and domain shift. In this paper, we address both problems. We introduce a probabilistic meta-learning model for domain generalization, in which classifier parameters shared across domains are modeled as distributions. This enables better handling of prediction uncertainty on unseen domains. To deal with domain shift, we learn domain-invariant representations by the proposed principle of meta variational information bottleneck, we call MetaVIB. MetaVIB is derived from novel variational bounds of mutual information, by leveraging the meta-learning setting of domain generalization. Through episodic training, MetaVIB learns to gradually narrow domain gaps to establish domain-invariant representations, while simultaneously maximizing prediction accuracy. We conduct experiments on three benchmarks for cross-domain visual recognition. Comprehensive ablation studies validate the benefits of MetaVIB for domain generalization. The comparison results demonstrate our method outperforms previous approaches consistently.
Simultaneous Transmit Diversity and Passive Beamforming with Large-Scale Intelligent Reflecting Surface
Feb 09, 2022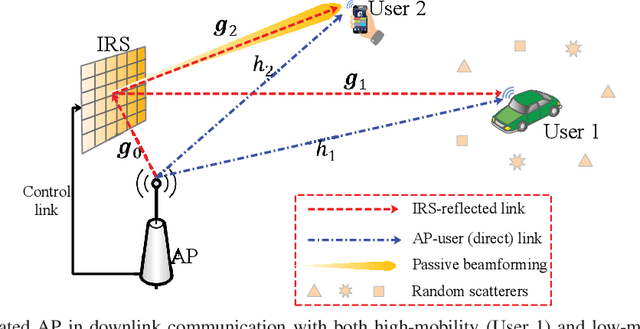
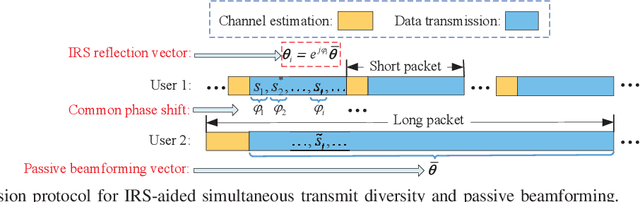
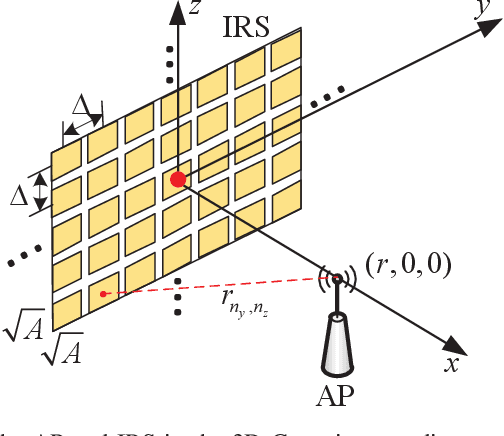
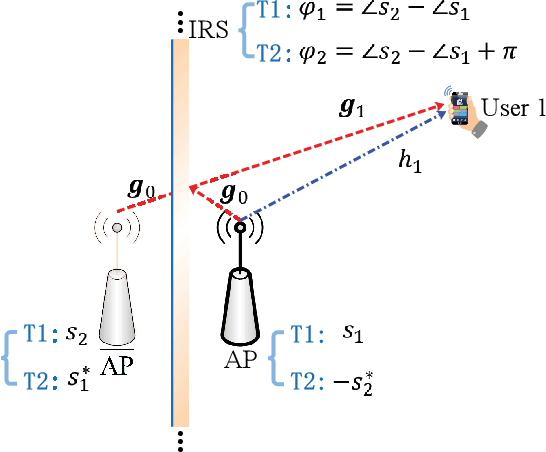
Intelligent reflecting surface (IRS) has emerged as a cost-effective solution to enhance wireless communication performance via passive signal reflection. Existing works on IRS have mainly focused on investigating IRS's passive beamforming/reflection design to boost the communication rate for users assuming that their channel state information (CSI) is fully or partially known. However, how to exploit IRS to improve the wireless transmission reliability without any CSI, which is typical in high-mobility/delay-sensitive communication scenarios, remains largely open. In this paper, we study a new IRS-aided communication system with the IRS integrated to its aided access point (AP) to achieve both functions of transmit diversity and passive beamforming simultaneously. Specifically, we first show an interesting result that the IRS's passive beamforming gain in any direction is invariant to the common phase-shift applied to all of its reflecting elements. Accordingly, we design the common phase-shift of IRS elements to achieve transmit diversity at the AP side without the need of any CSI of the users. In addition, we propose a practical method for the users to estimate the CSI at the receiver side for information decoding. Meanwhile, we show that the conventional passive beamforming gain of IRS can be retained for the other users with their CSI known at the AP. Furthermore, we derive the asymptotic performance of both IRS-aided transmit diversity and passive beamforming in closed-form, by considering the large-scale IRS with an infinite number of elements. Numerical results validate our analysis and show the performance gains of the proposed IRS-aided simultaneous transmit diversity and passive beamforming scheme over other benchmark schemes.
TCGM: An Information-Theoretic Framework for Semi-Supervised Multi-Modality Learning
Jul 14, 2020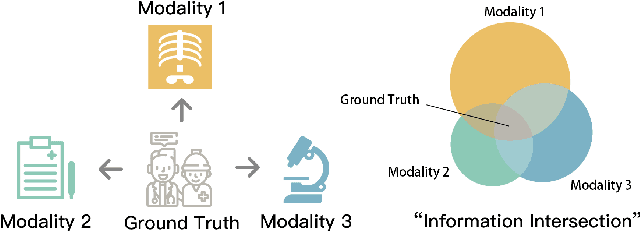
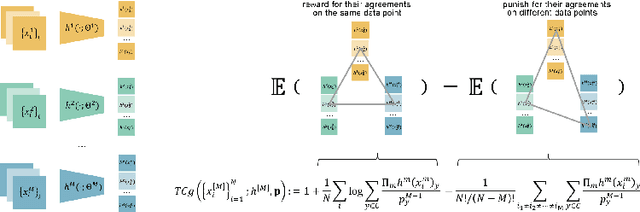
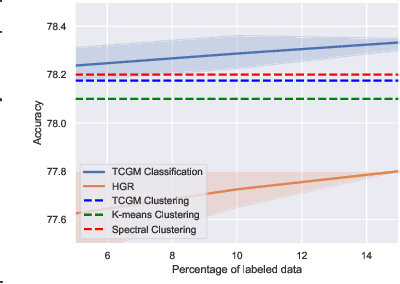
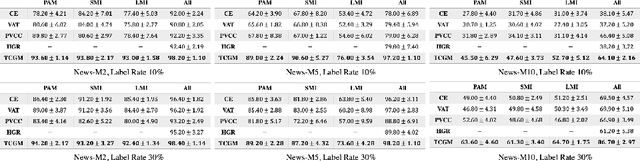
Fusing data from multiple modalities provides more information to train machine learning systems. However, it is prohibitively expensive and time-consuming to label each modality with a large amount of data, which leads to a crucial problem of semi-supervised multi-modal learning. Existing methods suffer from either ineffective fusion across modalities or lack of theoretical guarantees under proper assumptions. In this paper, we propose a novel information-theoretic approach, namely \textbf{T}otal \textbf{C}orrelation \textbf{G}ain \textbf{M}aximization (TCGM), for semi-supervised multi-modal learning, which is endowed with promising properties: (i) it can utilize effectively the information across different modalities of unlabeled data points to facilitate training classifiers of each modality (ii) it has theoretical guarantee to identify Bayesian classifiers, i.e., the ground truth posteriors of all modalities. Specifically, by maximizing TC-induced loss (namely TC gain) over classifiers of all modalities, these classifiers can cooperatively discover the equivalent class of ground-truth classifiers; and identify the unique ones by leveraging limited percentage of labeled data. We apply our method to various tasks and achieve state-of-the-art results, including news classification, emotion recognition and disease prediction.
Sparsity and Heterogeneous Dropout for Continual Learning in the Null Space of Neural Activations
Mar 12, 2022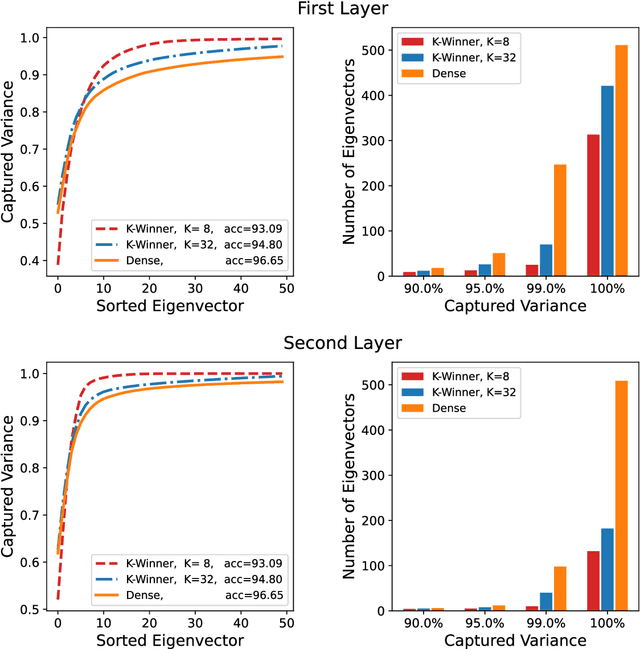
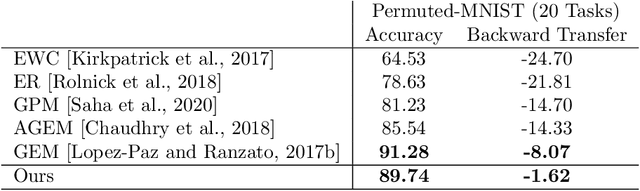
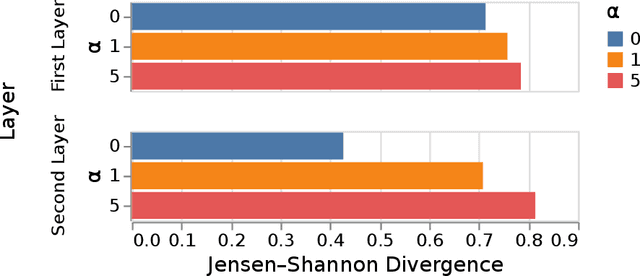
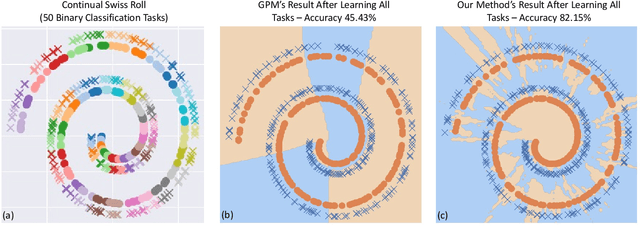
Continual/lifelong learning from a non-stationary input data stream is a cornerstone of intelligence. Despite their phenomenal performance in a wide variety of applications, deep neural networks are prone to forgetting their previously learned information upon learning new ones. This phenomenon is called "catastrophic forgetting" and is deeply rooted in the stability-plasticity dilemma. Overcoming catastrophic forgetting in deep neural networks has become an active field of research in recent years. In particular, gradient projection-based methods have recently shown exceptional performance at overcoming catastrophic forgetting. This paper proposes two biologically-inspired mechanisms based on sparsity and heterogeneous dropout that significantly increase a continual learner's performance over a long sequence of tasks. Our proposed approach builds on the Gradient Projection Memory (GPM) framework. We leverage K-winner activations in each layer of a neural network to enforce layer-wise sparse activations for each task, together with a between-task heterogeneous dropout that encourages the network to use non-overlapping activation patterns between different tasks. In addition, we introduce Continual Swiss Roll as a lightweight and interpretable -- yet challenging -- synthetic benchmark for continual learning. Lastly, we provide an in-depth analysis of our proposed method and demonstrate a significant performance boost on various benchmark continual learning problems.
Neural Hierarchical Factorization Machines for User's Event Sequence Analysis
Dec 31, 2021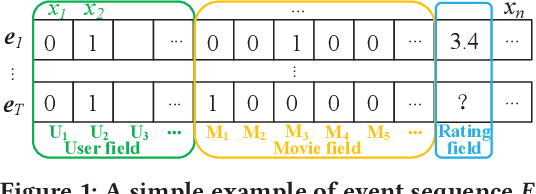
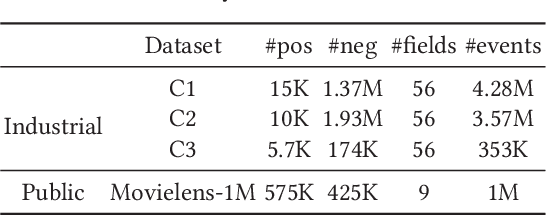
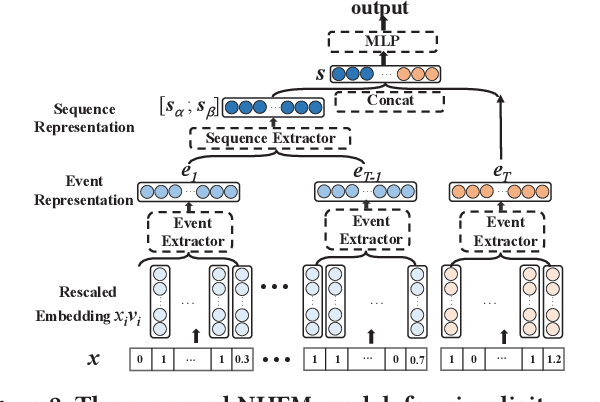
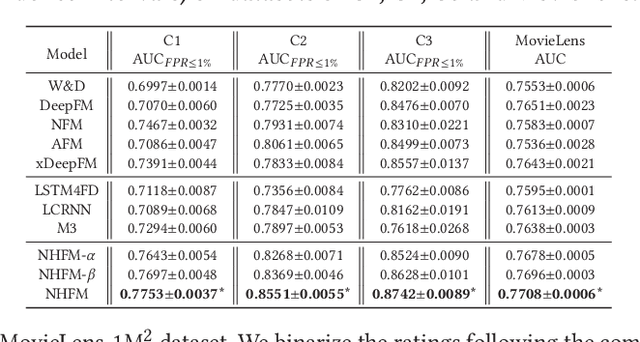
Many prediction tasks of real-world applications need to model multi-order feature interactions in user's event sequence for better detection performance. However, existing popular solutions usually suffer two key issues: 1) only focusing on feature interactions and failing to capture the sequence influence; 2) only focusing on sequence information, but ignoring internal feature relations of each event, thus failing to extract a better event representation. In this paper, we consider a two-level structure for capturing the hierarchical information over user's event sequence: 1) learning effective feature interactions based event representation; 2) modeling the sequence representation of user's historical events. Experimental results on both industrial and public datasets clearly demonstrate that our model achieves significantly better performance compared with state-of-the-art baselines.
Temporal Aggregation for Adaptive RGBT Tracking
Jan 29, 2022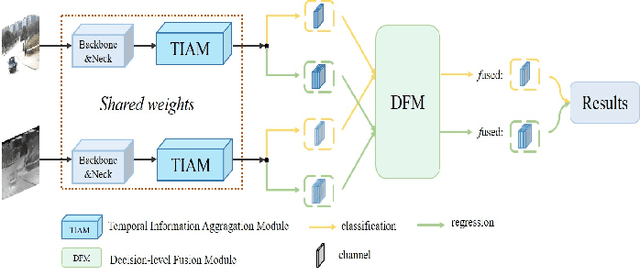
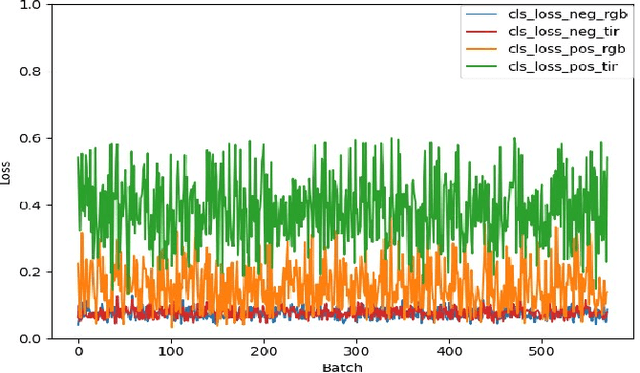
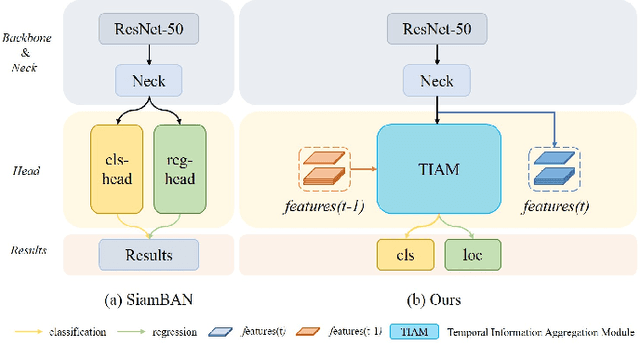
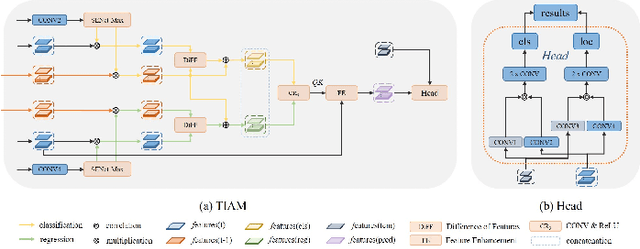
Visual object tracking with RGB and thermal infrared (TIR) spectra available, shorted in RGBT tracking, is a novel and challenging research topic which draws increasing attention nowadays. In this paper, we propose an RGBT tracker which takes spatio-temporal clues into account for robust appearance model learning, and simultaneously, constructs an adaptive fusion sub-network for cross-modal interactions. Unlike most existing RGBT trackers that implement object tracking tasks with only spatial information included, temporal information is further considered in this method. Specifically, different from traditional Siamese trackers, which only obtain one search image during the process of picking up template-search image pairs, an extra search sample adjacent to the original one is selected to predict the temporal transformation, resulting in improved robustness of tracking performance.As for multi-modal tracking, constrained to the limited RGBT datasets, the adaptive fusion sub-network is appended to our method at the decision level to reflect the complementary characteristics contained in two modalities. To design a thermal infrared assisted RGB tracker, the outputs of the classification head from the TIR modality are taken into consideration before the residual connection from the RGB modality. Extensive experimental results on three challenging datasets, i.e. VOT-RGBT2019, GTOT and RGBT210, verify the effectiveness of our method. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/TAAT}}.