 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sequential Recommendation with Causal Behavior Discovery
Apr 01, 2022
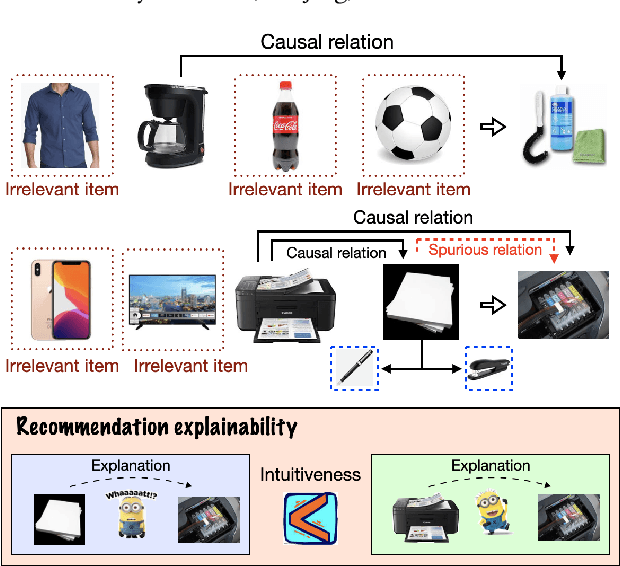
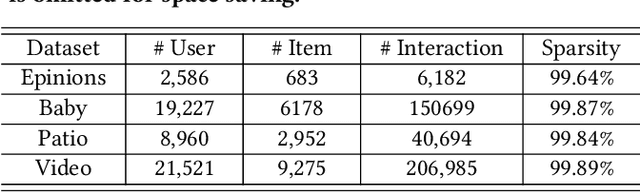
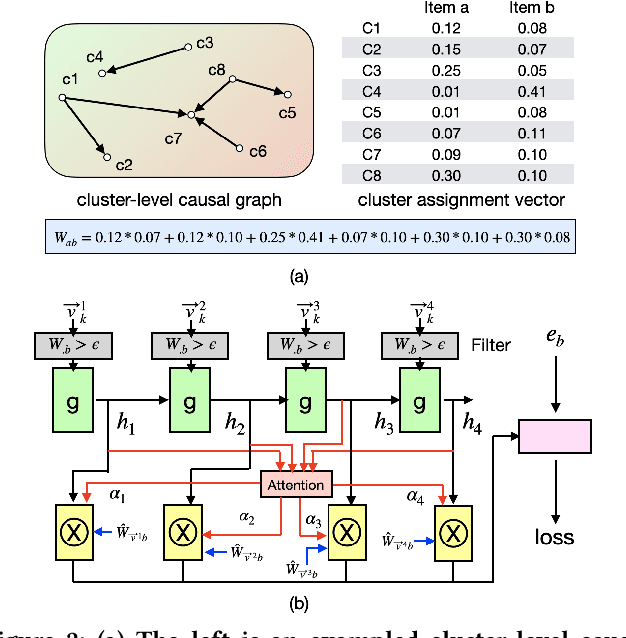
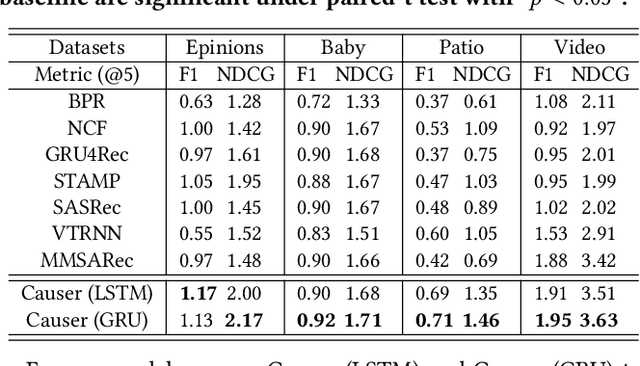
The key of sequential recommendation lies in the accurate item correlation modeling. Previous models infer such information based on item co-occurrences, which may fail to capture the real causal relations, and impact the recommendation performance and explainability. In this paper, we equip sequential recommendation with a novel causal discovery module to capture causalities among user behaviors. Our general idea is firstly assuming a causal graph underlying item correlations, and then we learn the causal graph jointly with the sequential recommender model by fitting the real user behavior data. More specifically, in order to satisfy the causality requirement, the causal graph is regularized by a differentiable directed acyclic constraint. Considering that the number of items in recommender systems can be very large, we represent different items with a unified set of latent clusters, and the causal graph is defined on the cluster level, which enhances the model scalability and robustness. In addition, we provide theoretical analysis on the identifiability of the learned causal graph. To the best of our knowledge, this paper makes a first step towards combining sequential recommendation with causal discovery. For evaluating the recommendation performance, we implement our framework with different neural sequential architectures, and compare them with many state-of-the-art methods based on real-world datasets. Empirical studies manifest that our model can on average improve the performance by about 7% and 11% on f1 and NDCG, respectively. To evaluate the model explainability, we build a new dataset with human labeled explanations for both quantitative and qualitative analysis.
Motif Mining: Finding and Summarizing Remixed Image Content
Mar 17, 2022
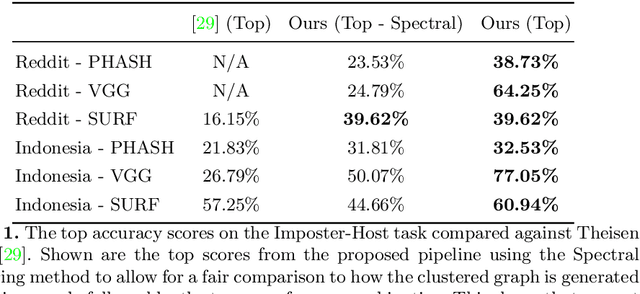
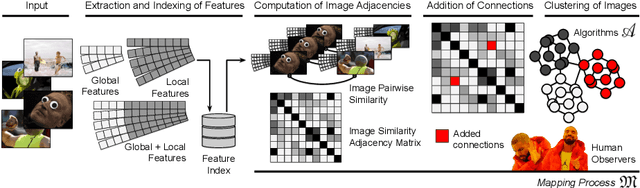
On the internet, images are no longer static; they have become dynamic content. Thanks to the availability of smartphones with cameras and easy-to-use editing software, images can be remixed (i.e., redacted, edited, and recombined with other content) on-the-fly and with a world-wide audience that can repeat the process. From digital art to memes, the evolution of images through time is now an important topic of study for digital humanists, social scientists, and media forensics specialists. However, because typical data sets in computer vision are composed of static content, the development of automated algorithms to analyze remixed content has been limited. In this paper, we introduce the idea of Motif Mining - the process of finding and summarizing remixed image content in large collections of unlabeled and unsorted data. In this paper, this idea is formalized and a reference implementation is introduced. Experiments are conducted on three meme-style data sets, including a newly collected set associated with the information war in the Russo-Ukrainian conflict. The proposed motif mining approach is able to identify related remixed content that, when compared to similar approaches, more closely aligns with the preferences and expectations of human observers.
FedRecAttack: Model Poisoning Attack to Federated Recommendation
Apr 01, 2022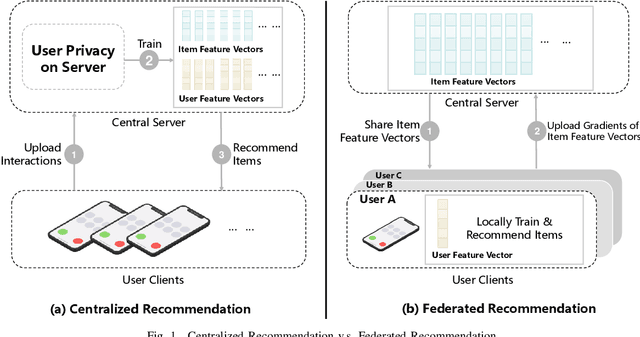
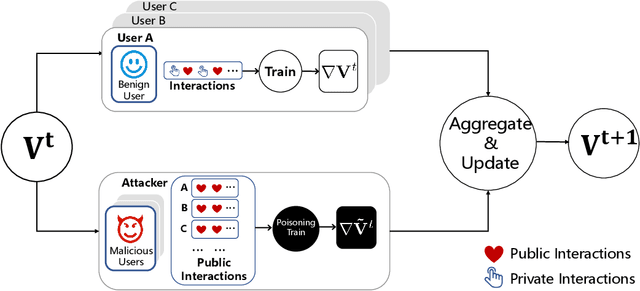
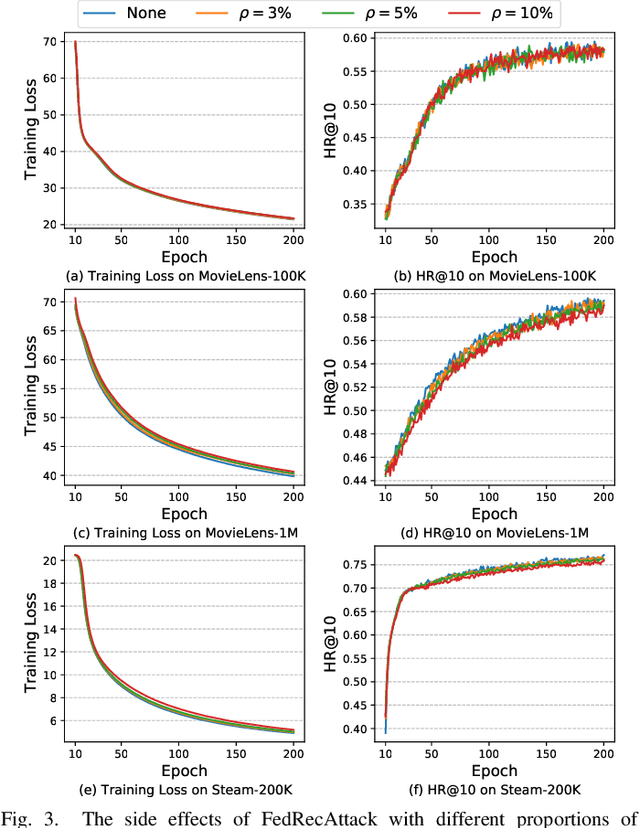

Federated Recommendation (FR) has received considerable popularity and attention in the past few years. In FR, for each user, its feature vector and interaction data are kept locally on its own client thus are private to others. Without the access to above information, most existing poisoning attacks against recommender systems or federated learning lose validity. Benifiting from this characteristic, FR is commonly considered fairly secured. However, we argue that there is still possible and necessary security improvement could be made in FR. To prove our opinion, in this paper we present FedRecAttack, a model poisoning attack to FR aiming to raise the exposure ratio of target items. In most recommendation scenarios, apart from private user-item interactions (e.g., clicks, watches and purchases), some interactions are public (e.g., likes, follows and comments). Motivated by this point, in FedRecAttack we make use of the public interactions to approximate users' feature vectors, thereby attacker can generate poisoned gradients accordingly and control malicious users to upload the poisoned gradients in a well-designed way. To evaluate the effectiveness and side effects of FedRecAttack, we conduct extensive experiments on three real-world datasets of different sizes from two completely different scenarios. Experimental results demonstrate that our proposed FedRecAttack achieves the state-of-the-art effectiveness while its side effects are negligible. Moreover, even with small proportion (3%) of malicious users and small proportion (1%) of public interactions, FedRecAttack remains highly effective, which reveals that FR is more vulnerable to attack than people commonly considered.
End-to-end system for object detection from sub-sampled radar data
Mar 08, 2022
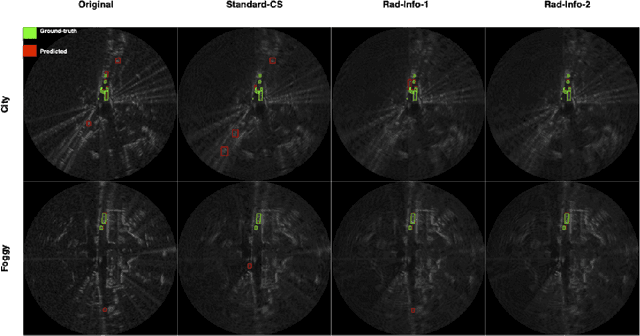
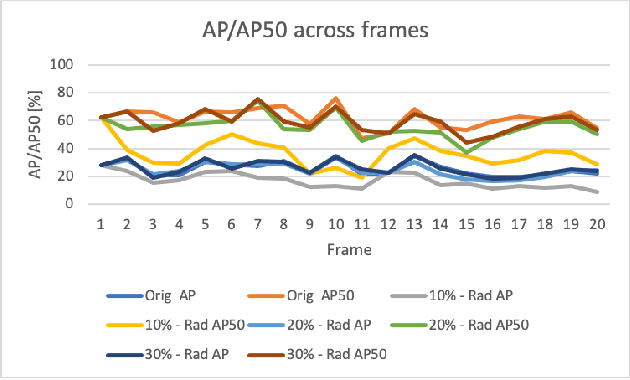
Robust and accurate sensing is of critical importance for advancing autonomous automotive systems. The need to acquire situational awareness in complex urban conditions using sensors such as radar has motivated research on power and latency-efficient signal acquisition methods. In this paper, we present an end-to-end signal processing pipeline, capable of operating in extreme weather conditions, that relies on sub-sampled radar data to perform object detection in vehicular settings. The results of the object detection are further utilized to sub-sample forthcoming radar data, which stands in contrast to prior work where the sub-sampling relies on image information. We show robust detection based on radar data reconstructed using 20% of samples under extreme weather conditions such as snow or fog, and on low-illuminated nights. Additionally, we generate 20% sampled radar data in a fine-tuning set and show 1.1% gain in AP50 across scenes and 3% AP50 gain in motorway condition.
A Joint Morphological Profiles and Patch Tensor Change Detection for Hyperspectral Imagery
Jan 20, 2022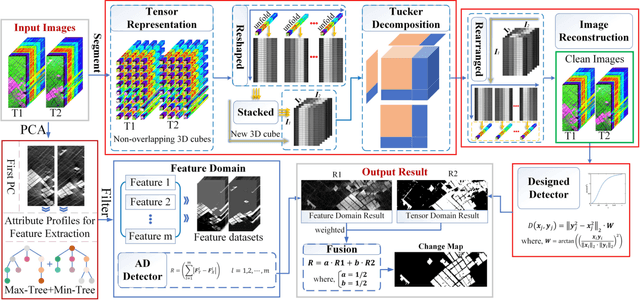
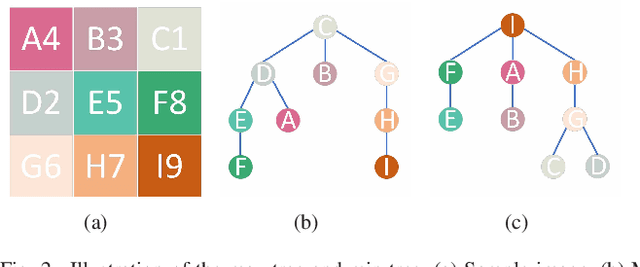
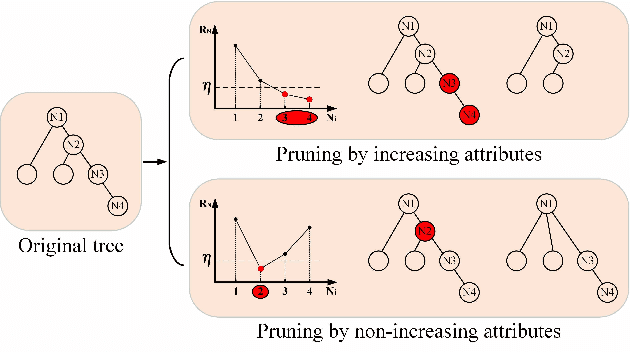

Multi-temporal hyperspectral images can be used to detect changed information, which has gradually attracted researchers' attention. However, traditional change detection algorithms have not deeply explored the relevance of spatial and spectral changed features, which leads to low detection accuracy. To better excavate both spectral and spatial information of changed features, a joint morphology and patch-tensor change detection (JMPT) method is proposed. Initially, a patch-based tensor strategy is adopted to exploit similar property of spatial structure, where the non-overlapping local patch image is reshaped into a new tensor cube, and then three-order Tucker decompositon and image reconstruction strategies are adopted to obtain more robust multi-temporal hyperspectral datasets. Meanwhile, multiple morphological profiles including max-tree and min-tree are applied to extract different attributes of multi-temporal images. Finally, these results are fused to general a final change detection map. Experiments conducted on two real hyperspectral datasets demonstrate that the proposed detector achieves better detection performance.
High-Performance Transformer Tracking
Mar 25, 2022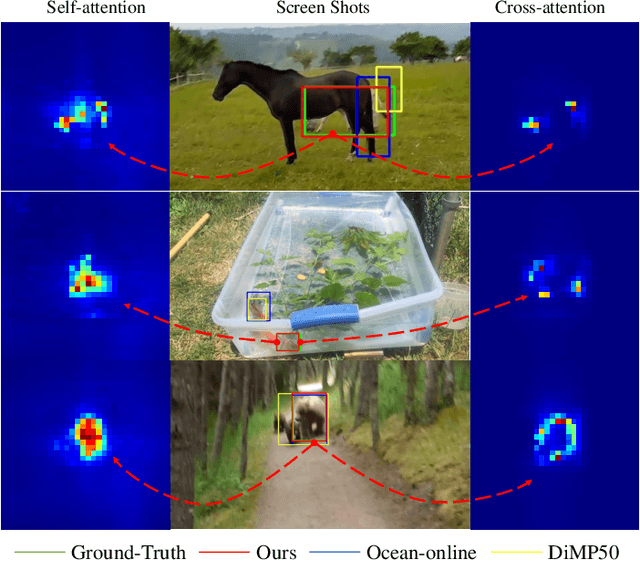
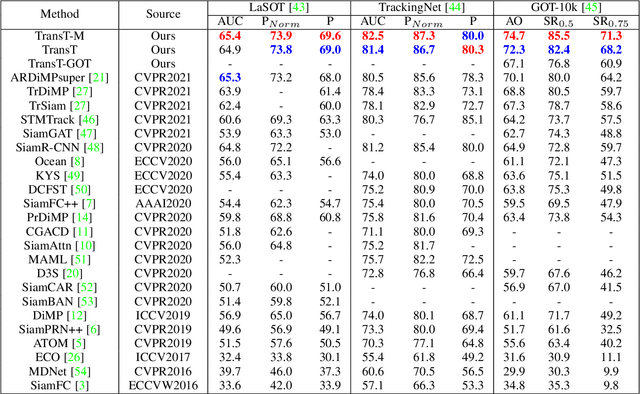
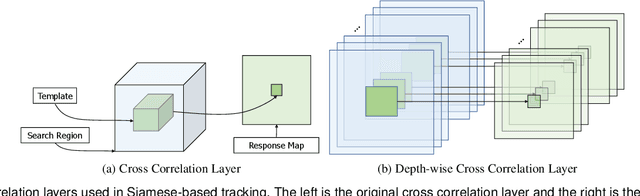
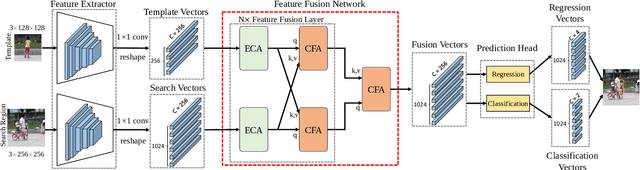
Correlation has a critical role in the tracking field, especially in recent popular Siamese-based trackers. The correlation operation is a simple fusion manner to consider the similarity between the template and the search region. However, the correlation operation is a local linear matching process, losing semantic information and falling into local optimum easily, which may be the bottleneck of designing high-accuracy tracking algorithms. In this work, to determine whether a better feature fusion method exists than correlation, a novel attention-based feature fusion network, inspired by Transformer, is presented. This network effectively combines the template and the search region features using attention. Specifically, the proposed method includes an ego-context augment module based on self-attention and a cross-feature augment module based on cross-attention. First, we present a Transformer tracking (named TransT) method based on the Siamese-like feature extraction backbone, the designed attention-based fusion mechanism, and the classification and regression head. Based on the TransT baseline, we further design a segmentation branch to generate an accurate mask. Finally, we propose a stronger version of TransT by extending TransT with a multi-template design and an IoU prediction head, named TransT-M. Experiments show that our TransT and TransT-M methods achieve promising results on seven popular datasets. Code and models are available at https://github.com/chenxin-dlut/TransT-M.
Knowledge Graph Embedding Methods for Entity Alignment: An Experimental Review
Mar 17, 2022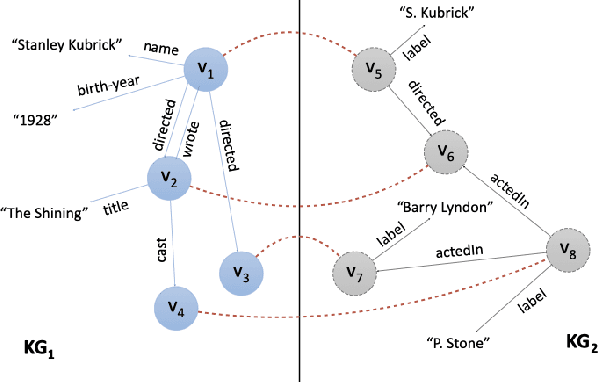
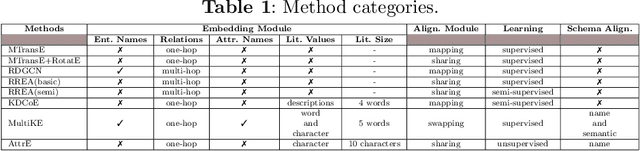
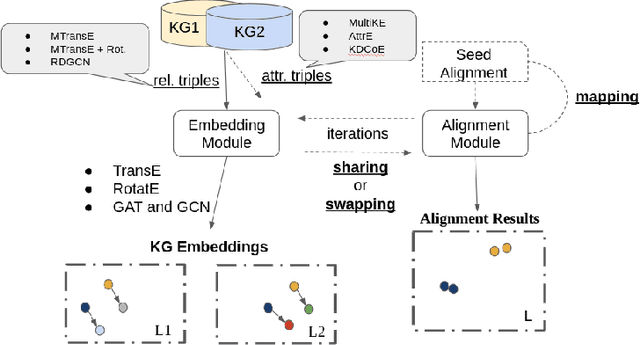

In recent years, we have witnessed the proliferation of knowledge graphs (KG) in various domains, aiming to support applications like question answering, recommendations, etc. A frequent task when integrating knowledge from different KGs is to find which subgraphs refer to the same real-world entity. Recently, embedding methods have been used for entity alignment tasks, that learn a vector-space representation of entities which preserves their similarity in the original KGs. A wide variety of supervised, unsupervised, and semi-supervised methods have been proposed that exploit both factual (attribute based) and structural information (relation based) of entities in the KGs. Still, a quantitative assessment of their strengths and weaknesses in real-world KGs according to different performance metrics and KG characteristics is missing from the literature. In this work, we conduct the first meta-level analysis of popular embedding methods for entity alignment, based on a statistically sound methodology. Our analysis reveals statistically significant correlations of different embedding methods with various meta-features extracted by KGs and rank them in a statistically significant way according to their effectiveness across all real-world KGs of our testbed. Finally, we study interesting trade-offs in terms of methods' effectiveness and efficiency.
Decoupling and Recoupling Spatiotemporal Representation for RGB-D-based Motion Recognition
Dec 16, 2021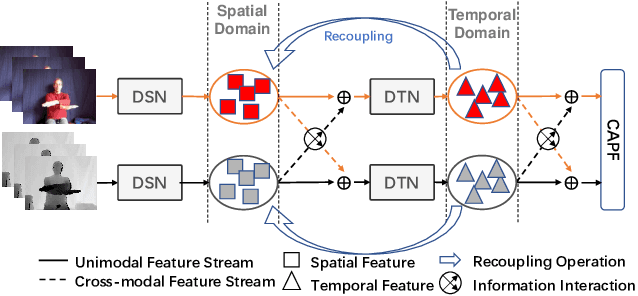
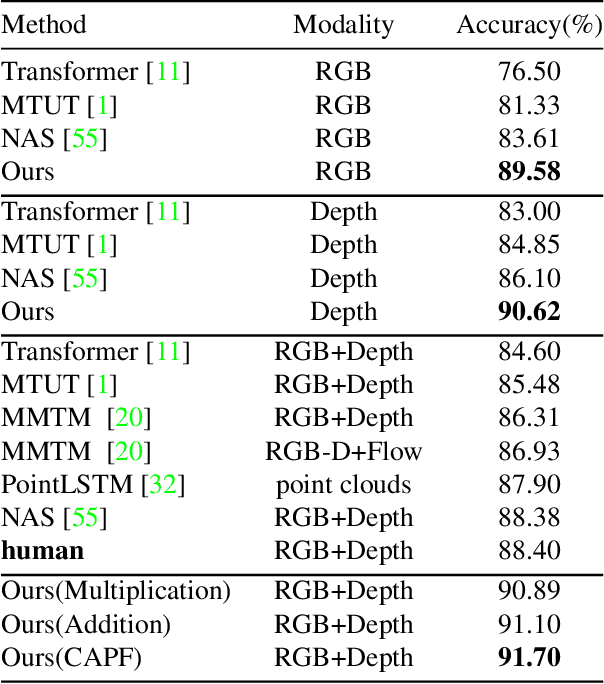
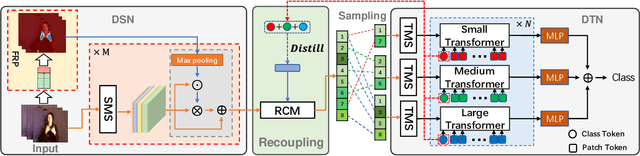
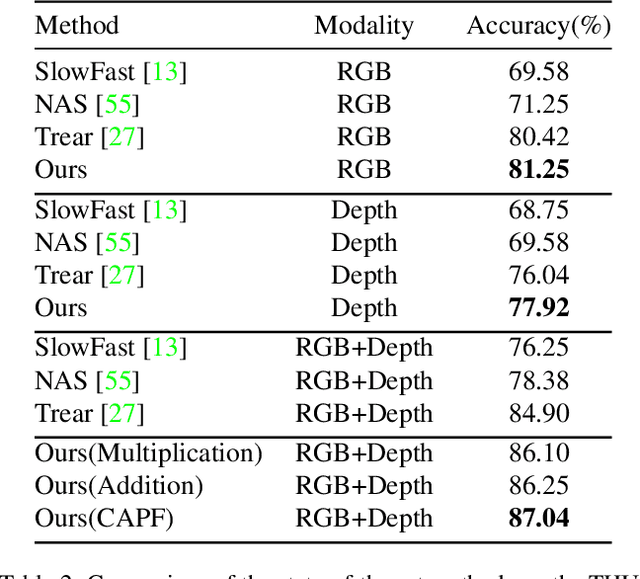
Decoupling spatiotemporal representation refers to decomposing the spatial and temporal features into dimension-independent factors. Although previous RGB-D-based motion recognition methods have achieved promising performance through the tightly coupled multi-modal spatiotemporal representation, they still suffer from (i) optimization difficulty under small data setting due to the tightly spatiotemporal-entangled modeling;(ii) information redundancy as it usually contains lots of marginal information that is weakly relevant to classification; and (iii) low interaction between multi-modal spatiotemporal information caused by insufficient late fusion. To alleviate these drawbacks, we propose to decouple and recouple spatiotemporal representation for RGB-D-based motion recognition. Specifically, we disentangle the task of learning spatiotemporal representation into 3 sub-tasks: (1) Learning high-quality and dimension independent features through a decoupled spatial and temporal modeling network. (2) Recoupling the decoupled representation to establish stronger space-time dependency. (3) Introducing a Cross-modal Adaptive Posterior Fusion (CAPF) mechanism to capture cross-modal spatiotemporal information from RGB-D data. Seamless combination of these novel designs forms a robust spatialtemporal representation and achieves better performance than state-of-the-art methods on four public motion datasets. Our code is available at https://github.com/damo-cv/MotionRGBD.
Towards Micro-video Thumbnail Selection via a Multi-label Visual-semantic Embedding Model
Feb 07, 2022The thumbnail, as the first sight of a micro-video, plays a pivotal role in attracting users to click and watch. While in the real scenario, the more the thumbnails satisfy the users, the more likely the micro-videos will be clicked. In this paper, we aim to select the thumbnail of a given micro-video that meets most users` interests. Towards this end, we present a multi-label visual-semantic embedding model to estimate the similarity between the pair of each frame and the popular topics that users are interested in. In this model, the visual and textual information is embedded into a shared semantic space, whereby the similarity can be measured directly, even the unseen words. Moreover, to compare the frame to all words from the popular topics, we devise an attention embedding space associated with the semantic-attention projection. With the help of these two embedding spaces, the popularity score of a frame, which is defined by the sum of similarity scores over the corresponding visual information and popular topic pairs, is achieved. Ultimately, we fuse the visual representation score and the popularity score of each frame to select the attractive thumbnail for the given micro-video. Extensive experiments conducted on a real-world dataset have well-verified that our model significantly outperforms several state-of-the-art baselines.
Improving Adversarial Transferability with Spatial Momentum
Mar 25, 2022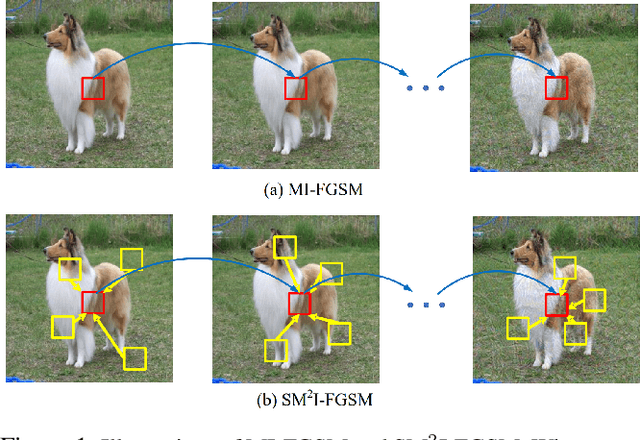
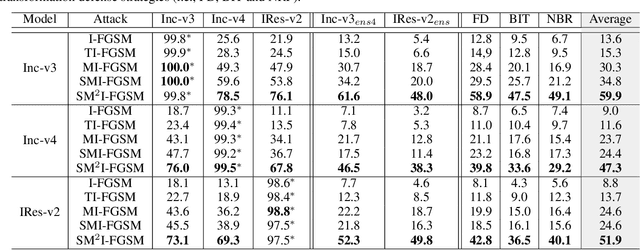
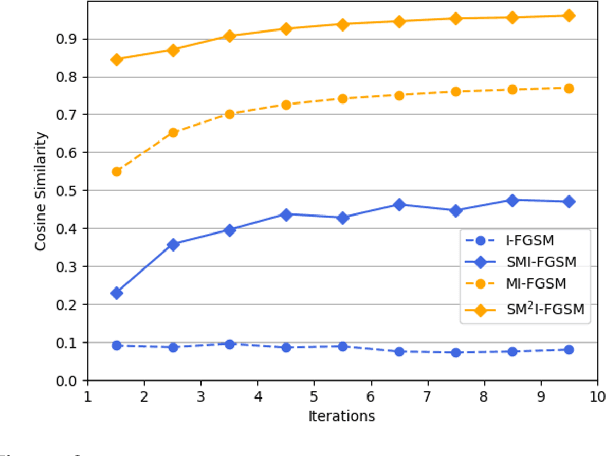
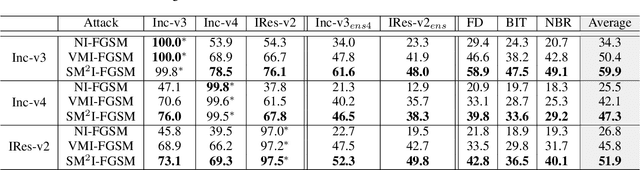
Deep Neural Networks (DNN) are vulnerable to adversarial examples. Although many adversarial attack methods achieve satisfactory attack success rates under the white-box setting, they usually show poor transferability when attacking other DNN models. Momentum-based attack (MI-FGSM) is one effective method to improve transferability. It integrates the momentum term into the iterative process, which can stabilize the update directions by adding the gradients' temporal correlation for each pixel. We argue that only this temporal momentum is not enough, the gradients from the spatial domain within an image, i.e. gradients from the context pixels centered on the target pixel are also important to the stabilization. For that, in this paper, we propose a novel method named Spatial Momentum Iterative FGSM Attack (SMI-FGSM), which introduces the mechanism of momentum accumulation from temporal domain to spatial domain by considering the context gradient information from different regions within the image. SMI-FGSM is then integrated with MI-FGSM to simultaneously stabilize the gradients' update direction from both the temporal and spatial domain. The final method is called SM$^2$I-FGSM. Extensive experiments are conducted on the ImageNet dataset and results show that SM$^2$I-FGSM indeed further enhances the transferability. It achieves the best transferability success rate for multiple mainstream undefended and defended models, which outperforms the state-of-the-art methods by a large margin.