 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Speech-Based Emotion Recognition using Neural Networks and Information Visualization
Oct 28, 2020
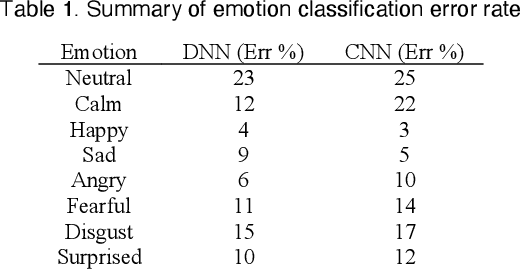
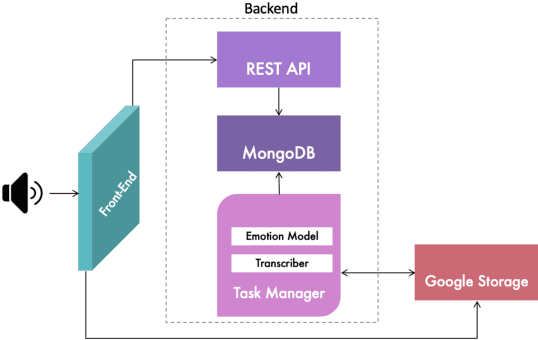
Emotions recognition is commonly employed for health assessment. However, the typical metric for evaluation in therapy is based on patient-doctor appraisal. This process can fall into the issue of subjectivity, while also requiring healthcare professionals to deal with copious amounts of information. Thus, machine learning algorithms can be a useful tool for the classification of emotions. While several models have been developed in this domain, there is a lack of userfriendly representations of the emotion classification systems for therapy. We propose a tool which enables users to take speech samples and identify a range of emotions (happy, sad, angry, surprised, neutral, clam, disgust, and fear) from audio elements through a machine learning model. The dashboard is designed based on local therapists' needs for intuitive representations of speech data in order to gain insights and informative analyses of their sessions with their patients.
* IEEE Vis 2020 Abstract
ISDE : Independence Structure Density Estimation
Mar 18, 2022

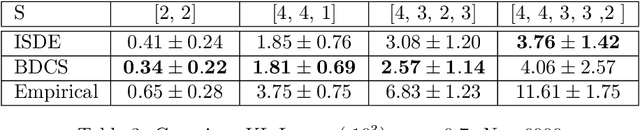

Density estimation appears as a subroutine in many learning procedures, so it is of interest to have efficient methods for it to perform in practical situations. Multidimensional density estimation suffers from the curse of dimensionality. A solution to this problem is to add a structural hypothesis through an undirected graphical model on the underlying distribution. We propose ISDE (Independence Structure Density Estimation), an algorithm designed to estimate a density and an undirected graphical model from a particular family of graphs corresponding to Independence Structure (IS), a situation where we can separate features into independent groups. ISDE works for moderately high-dimensional data (up to a few dozen features), and it is useable in parametric and nonparametric situations. Existing methods on nonparametric graphical model estimation focus on multidimensional dependencies only through pairwise ones: ISDE does not suffer from this restriction and can address structures not yet covered by available algorithms. In this paper, we present the existing theory about IS, explain the construction of our algorithm and prove its effectiveness. This is done on synthetic data both quantitatively, through measures of density estimation performance under Kullback-Leibler loss, and qualitatively, in terms of capability to recover IS. By applying ISDE on mass cytometry datasets, we also show how it performs both quantitatively and qualitatively on real-world datasets. Then we provide information about running time.
Optimizing Information Loss Towards Robust Neural Networks
Aug 07, 2020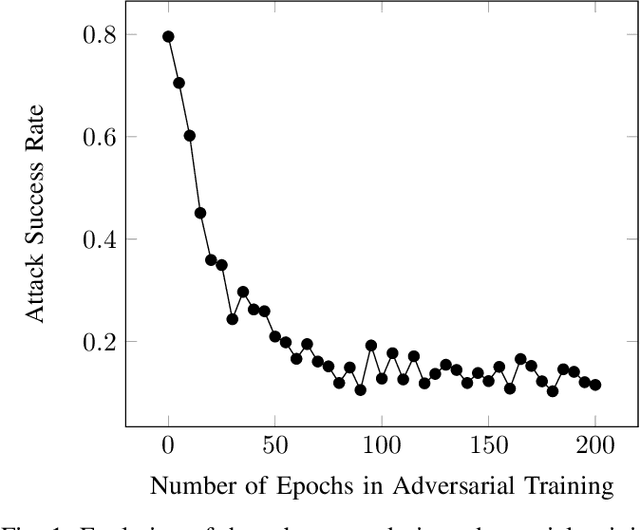
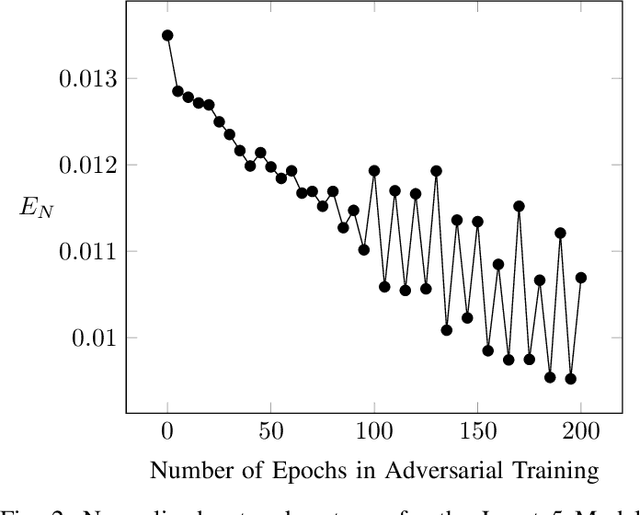
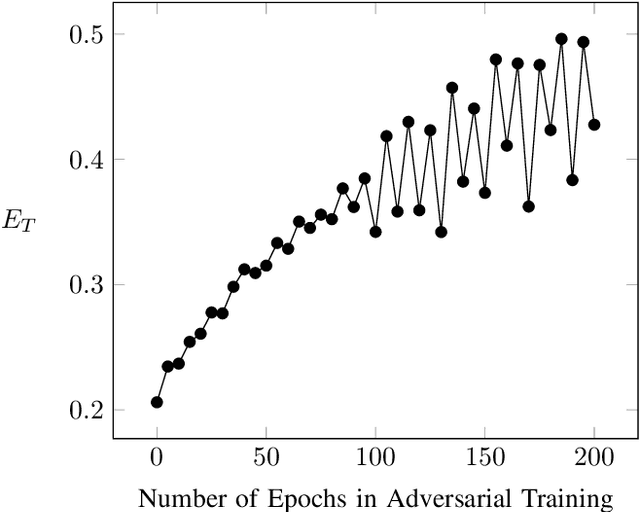
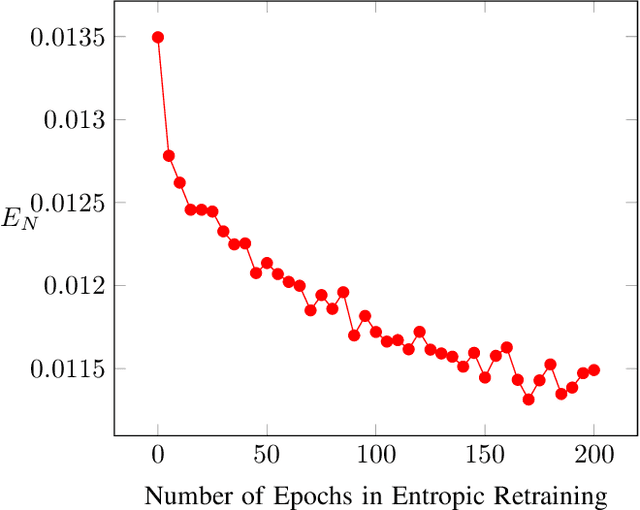
Neural Networks (NNs) are vulnerable to adversarial examples. Such inputs differ only slightly from their benign counterparts yet provoke misclassifications of the attacked NNs. The required perturbations to craft the examples are often negligible and even human imperceptible. To protect deep learning based system from such attacks, several countermeasures have been proposed with adversarial training still being considered the most effective. Here, NNs are iteratively retrained using adversarial examples forming a computational expensive and time consuming process often leading to a performance decrease. To overcome the downsides of adversarial training while still providing a high level of security, we present a new training approach we call entropic retraining. Based on an information-theoretic analysis, entropic retraining mimics the effects of adversarial training without the need of the laborious generation of adversarial examples. We empirically show that entropic retraining leads to a significant increase in NNs' security and robustness while only relying on the given original data. With our prototype implementation we validate and show the effectiveness of our approach for various NN architectures and data sets.
Paying U-Attention to Textures: Multi-Stage Hourglass Vision Transformer for Universal Texture Synthesis
Feb 23, 2022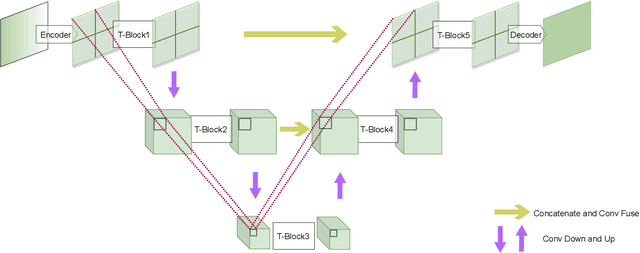
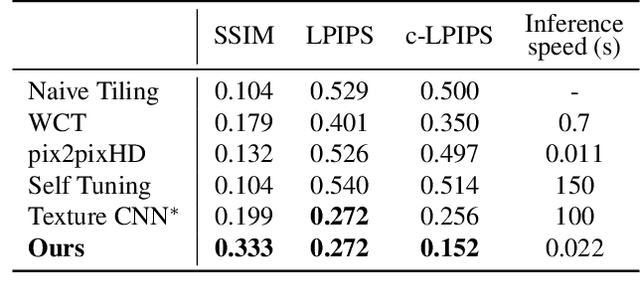
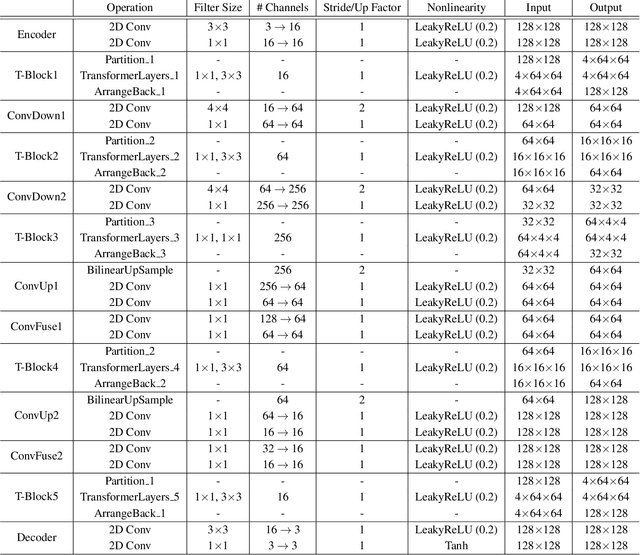

We present a novel U-Attention vision Transformer for universal texture synthesis. We exploit the natural long-range dependencies enabled by the attention mechanism to allow our approach to synthesize diverse textures while preserving their structures in a single inference. We propose a multi-stage hourglass backbone that attends to the global structure and performs patch mapping at varying scales in a coarse-to-fine-to-coarse stream. Further completed by skip connection and convolution designs that propagate and fuse information at different scales, our U-Attention architecture unifies attention to microstructures, mesostructures and macrostructures, and progressively refines synthesis results at successive stages. We show that our method achieves stronger 2$\times$ synthesis than previous work on both stochastic and structured textures while generalizing to unseen textures without fine-tuning. Ablation studies demonstrate the effectiveness of each component of our architecture.
Ray-transfer functions for camera simulation of 3D scenes with hidden lens design
Feb 23, 2022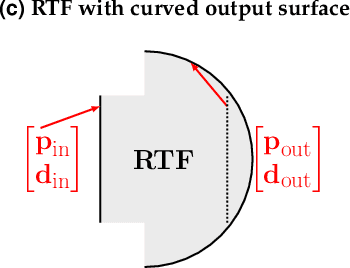

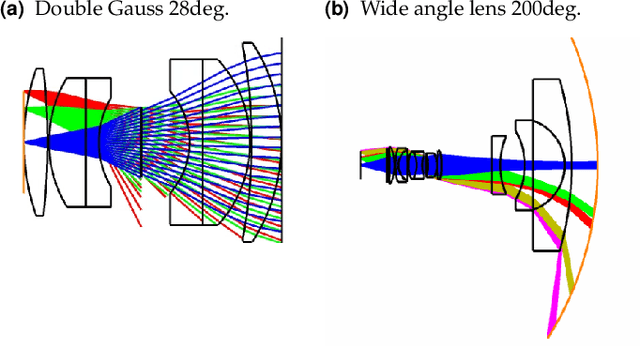
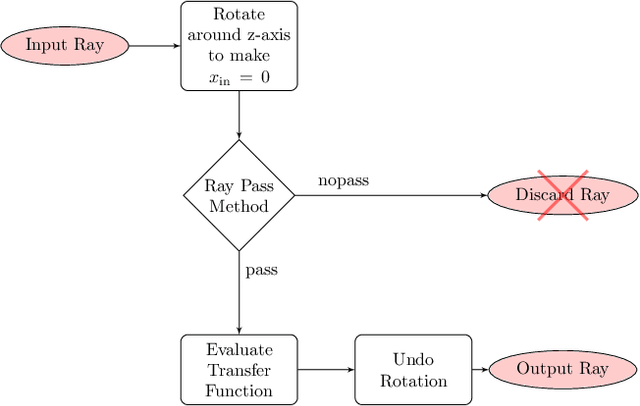
Combining image sensor simulation tools (e.g., ISETCam) with physically based ray tracing (e.g., PBRT) offers possibilities for designing and evaluating novel imaging systems as well as for synthesizing physically accurate, labeled images for machine learning. One practical limitation has been simulating the optics precisely: Lens manufacturers generally prefer to keep lens design confidential. We present a pragmatic solution to this problem using a black box lens model in Zemax; such models provide necessary optical information while preserving the lens designer's intellectual property. First, we describe and provide software to construct a polynomial ray transfer function that characterizes how rays entering the lens at any position and angle subsequently exit the lens. We implement the ray-transfer calculation as a camera model in PBRT and confirm that the PBRT ray-transfer calculations match the Zemax lens calculations for edge spread functions and relative illumination.
Back to Reality: Weakly-supervised 3D Object Detection with Shape-guided Label Enhancement
Mar 10, 2022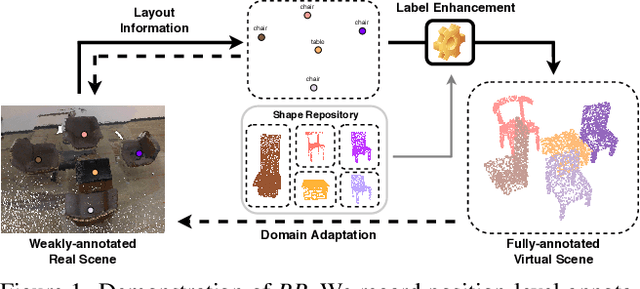

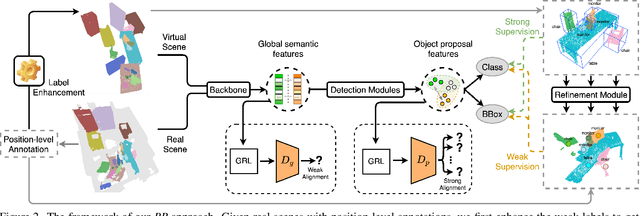

In this paper, we propose a weakly-supervised approach for 3D object detection, which makes it possible to train strong 3D detector with position-level annotations (i.e. annotations of object centers). In order to remedy the information loss from box annotations to centers, our method, namely Back to Reality (BR), makes use of synthetic 3D shapes to convert the weak labels into fully-annotated virtual scenes as stronger supervision, and in turn utilizes the perfect virtual labels to complement and refine the real labels. Specifically, we first assemble 3D shapes into physically reasonable virtual scenes according to the coarse scene layout extracted from position-level annotations. Then we go back to reality by applying a virtual-to-real domain adaptation method, which refine the weak labels and additionally supervise the training of detector with the virtual scenes. Furthermore, we propose a more challenging benckmark for indoor 3D object detection with more diversity in object sizes to better show the potential of BR. With less than 5% of the labeling labor, we achieve comparable detection performance with some popular fully-supervised approaches on the widely used ScanNet dataset. Code is available at: https://github.com/xuxw98/BackToReality
Mirror Descent Strikes Again: Optimal Stochastic Convex Optimization under Infinite Noise Variance
Feb 23, 2022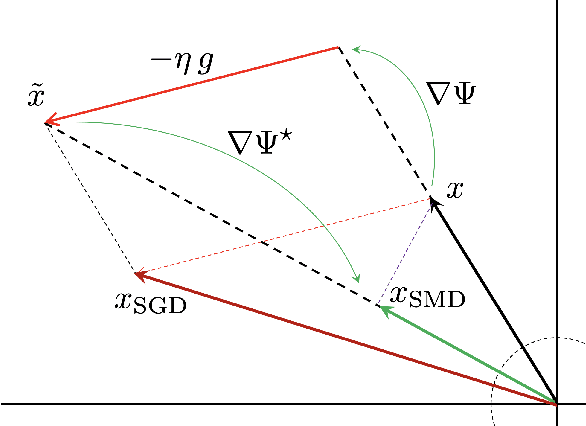
We study stochastic convex optimization under infinite noise variance. Specifically, when the stochastic gradient is unbiased and has uniformly bounded $(1+\kappa)$-th moment, for some $\kappa \in (0,1]$, we quantify the convergence rate of the Stochastic Mirror Descent algorithm with a particular class of uniformly convex mirror maps, in terms of the number of iterations, dimensionality and related geometric parameters of the optimization problem. Interestingly this algorithm does not require any explicit gradient clipping or normalization, which have been extensively used in several recent empirical and theoretical works. We complement our convergence results with information-theoretic lower bounds showing that no other algorithm using only stochastic first-order oracles can achieve improved rates. Our results have several interesting consequences for devising online/streaming stochastic approximation algorithms for problems arising in robust statistics and machine learning.
Boosting Image Super-Resolution Via Fusion of Complementary Information Captured by Multi-Modal Sensors
Dec 07, 2020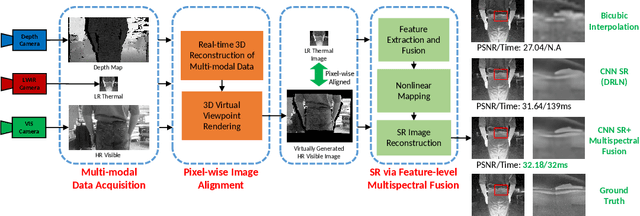

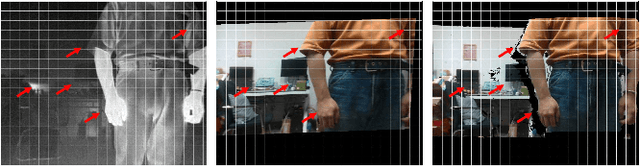
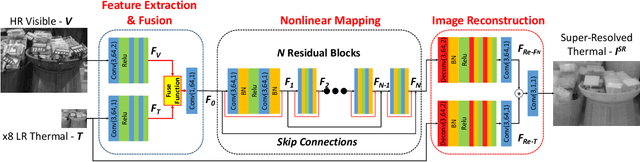
Image Super-Resolution (SR) provides a promising technique to enhance the image quality of low-resolution optical sensors, facilitating better-performing target detection and autonomous navigation in a wide range of robotics applications. It is noted that the state-of-the-art SR methods are typically trained and tested using single-channel inputs, neglecting the fact that the cost of capturing high-resolution images in different spectral domains varies significantly. In this paper, we attempt to leverage complementary information from a low-cost channel (visible/depth) to boost image quality of an expensive channel (thermal) using fewer parameters. To this end, we first present an effective method to virtually generate pixel-wise aligned visible and thermal images based on real-time 3D reconstruction of multi-modal data captured at various viewpoints. Then, we design a feature-level multispectral fusion residual network model to perform high-accuracy SR of thermal images by adaptively integrating co-occurrence features presented in multispectral images. Experimental results demonstrate that this new approach can effectively alleviate the ill-posed inverse problem of image SR by taking into account complementary information from an additional low-cost channel, significantly outperforming state-of-the-art SR approaches in terms of both accuracy and efficiency.
Paper Plain: Making Medical Research Papers Approachable to Healthcare Consumers with Natural Language Processing
Feb 28, 2022
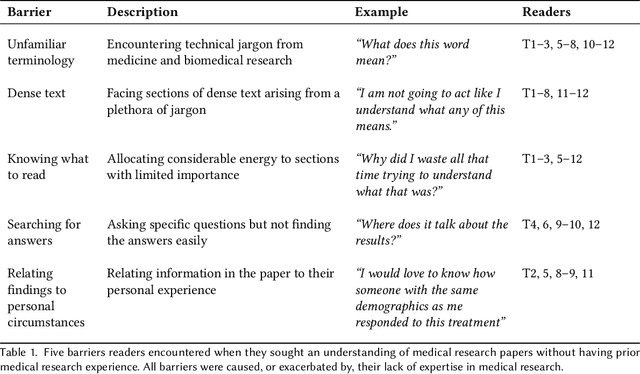

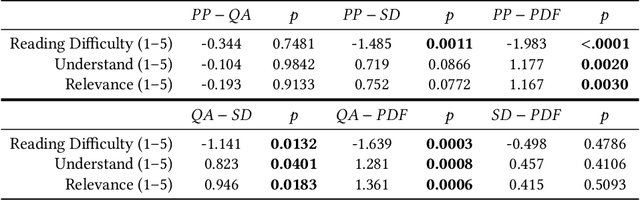
When seeking information not covered in patient-friendly documents, like medical pamphlets, healthcare consumers may turn to the research literature. Reading medical papers, however, can be a challenging experience. To improve access to medical papers, we introduce a novel interactive interface-Paper Plain-with four features powered by natural language processing: definitions of unfamiliar terms, in-situ plain language section summaries, a collection of key questions that guide readers to answering passages, and plain language summaries of the answering passages. We evaluate Paper Plain, finding that participants who use Paper Plain have an easier time reading and understanding research papers without a loss in paper comprehension compared to those who use a typical PDF reader. Altogether, the study results suggest that guiding readers to relevant passages and providing plain language summaries, or "gists," alongside the original paper content can make reading medical papers easier and give readers more confidence to approach these papers.
General lower bounds for interactive high-dimensional estimation under information constraints
Oct 13, 2020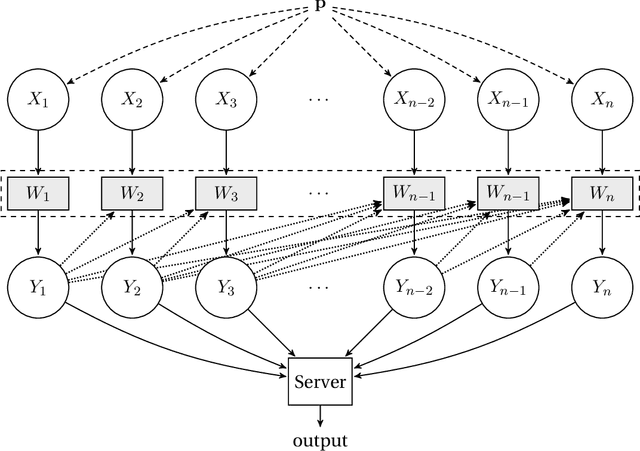


We consider the task of distributed parameter estimation using sequentially interactive protocols subject to local information constraints such as bandwidth limitations, local differential privacy, and restricted measurements. We provide a general framework enabling us to derive a variety of (tight) minimax lower bounds under different parametric families of distributions, both continuous and discrete, under any $\ell_p$ loss. Our lower bound framework is versatile, and yields "plug-and-play" bounds that are widely applicable to a large range of estimation problems. For the families considered, we further complement our lower bounds with matching upper bounds.