 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Audio-Visual MLP for Scoring Sport
Mar 22, 2022
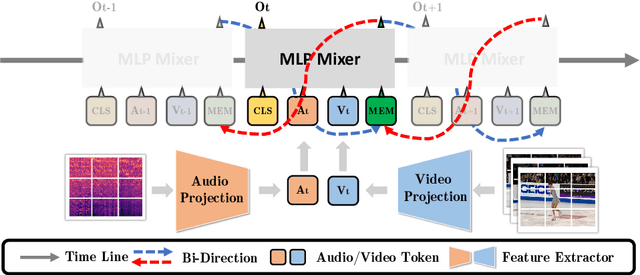
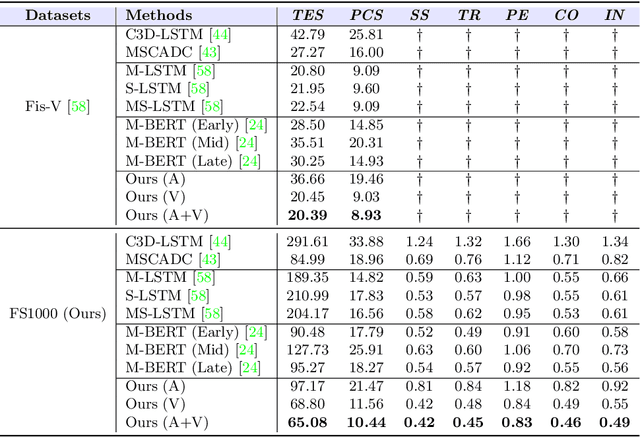
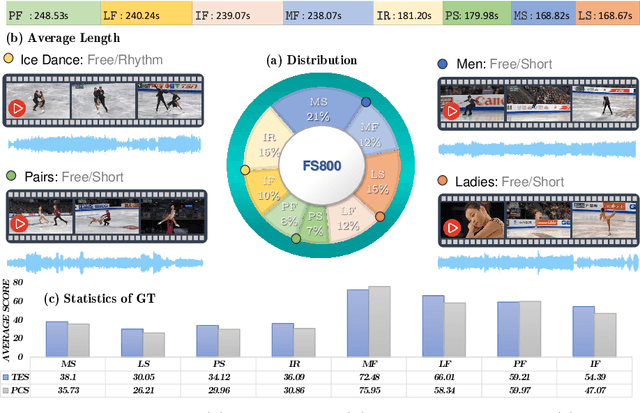
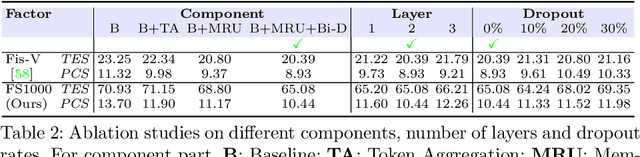
Figure skating scoring is a challenging task because it requires judging players' technical moves as well as coordination with the background music. Prior learning-based work cannot solve it well for two reasons: 1) each move in figure skating changes quickly, hence simply applying traditional frame sampling will lose a lot of valuable information, especially in a 3-5 minutes lasting video, so an extremely long-range representation learning is necessary; 2) prior methods rarely considered the critical audio-visual relationship in their models. Thus, we introduce a multimodal MLP architecture, named Skating-Mixer. It extends the MLP-Mixer-based framework into a multimodal fashion and effectively learns long-term representations through our designed memory recurrent unit (MRU). Aside from the model, we also collected a high-quality audio-visual FS1000 dataset, which contains over 1000 videos on 8 types of programs with 7 different rating metrics, overtaking other datasets in both quantity and diversity. Experiments show the proposed method outperforms SOTAs over all major metrics on the public Fis-V and our FS1000 dataset. In addition, we include an analysis applying our method to recent competitions that occurred in Beijing 2022 Winter Olympic Games, proving our method has strong robustness.
Integrate Lattice-Free MMI into End-to-End Speech Recognition
Apr 02, 2022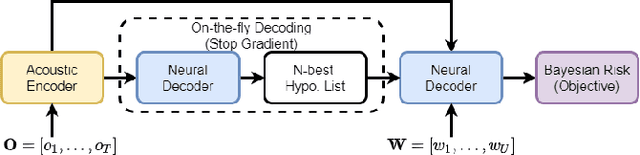
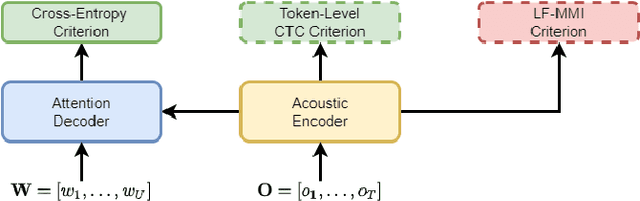
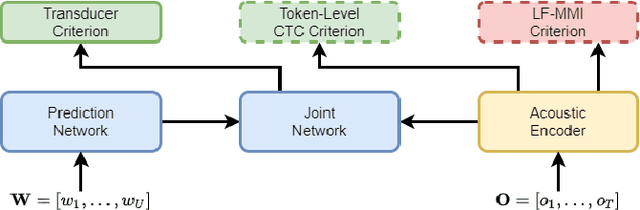
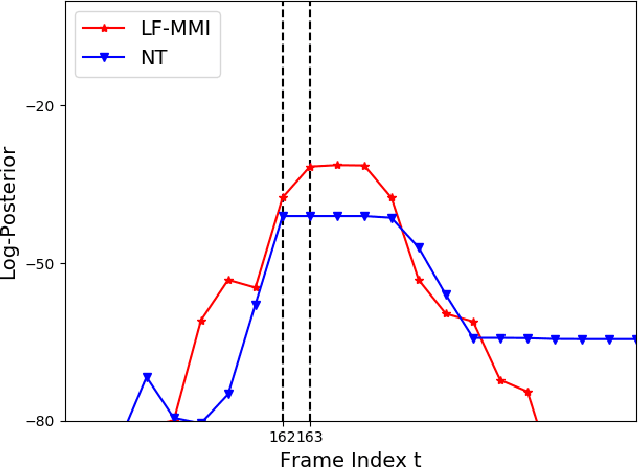
In automatic speech recognition (ASR) research, discriminative criteria have achieved superior performance in DNN-HMM systems. Given this success, the adoption of discriminative criteria is promising to boost the performance of end-to-end (E2E) ASR systems. With this motivation, previous works have introduced the minimum Bayesian risk (MBR, one of the discriminative criteria) into E2E ASR systems. However, the effectiveness and efficiency of the MBR-based methods are compromised: the MBR criterion is only used in system training, which creates a mismatch between training and decoding; the on-the-fly decoding process in MBR-based methods results in the need for pre-trained models and slow training speeds. To this end, novel algorithms are proposed in this work to integrate another widely used discriminative criterion, lattice-free maximum mutual information (LF-MMI), into E2E ASR systems not only in the training stage but also in the decoding process. The proposed LF-MMI training and decoding methods show their effectiveness on two widely used E2E frameworks: Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Compared with MBR-based methods, the proposed LF-MMI method: maintains the consistency between training and decoding; eschews the on-the-fly decoding process; trains from randomly initialized models with superior training efficiency. Experiments suggest that the LF-MMI method outperforms its MBR counterparts and consistently leads to statistically significant performance improvements on various frameworks and datasets from 30 hours to 14.3k hours. The proposed method achieves state-of-the-art (SOTA) results on Aishell-1 (CER 4.10%) and Aishell-2 (CER 5.02%) datasets. Code is released.
STDAN: Deformable Attention Network for Space-Time Video Super-Resolution
Mar 14, 2022
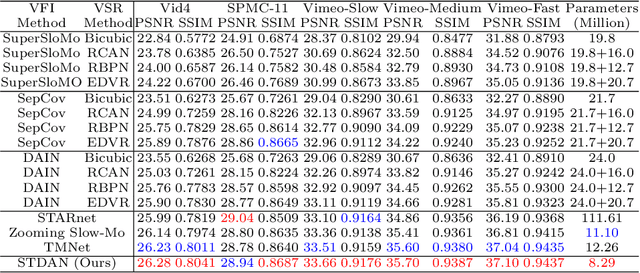
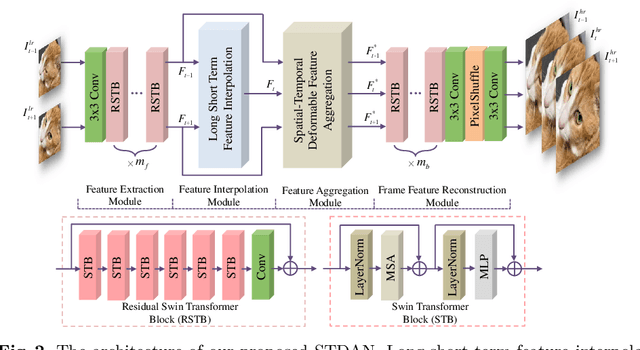
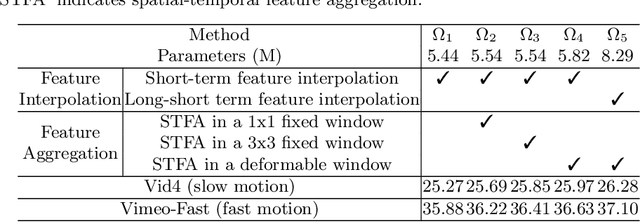
The target of space-time video super-resolution (STVSR) is to increase the spatial-temporal resolution of low-resolution (LR) and low frame rate (LFR) videos. Recent approaches based on deep learning have made significant improvements, but most of them only use two adjacent frames, that is, short-term features, to synthesize the missing frame embedding, which suffers from fully exploring the information flow of consecutive input LR frames. In addition, existing STVSR models hardly exploit the temporal contexts explicitly to assist high-resolution (HR) frame reconstruction. To address these issues, in this paper, we propose a deformable attention network called STDAN for STVSR. First, we devise a long-short term feature interpolation (LSTFI) module, which is capable of excavating abundant content from more neighboring input frames for the interpolation process through a bidirectional RNN structure. Second, we put forward a spatial-temporal deformable feature aggregation (STDFA) module, in which spatial and temporal contexts in dynamic video frames are adaptively captured and aggregated to enhance SR reconstruction. Experimental results on several datasets demonstrate that our approach outperforms state-of-the-art STVSR methods.
Few Shot Generative Model Adaption via Relaxed Spatial Structural Alignment
Mar 14, 2022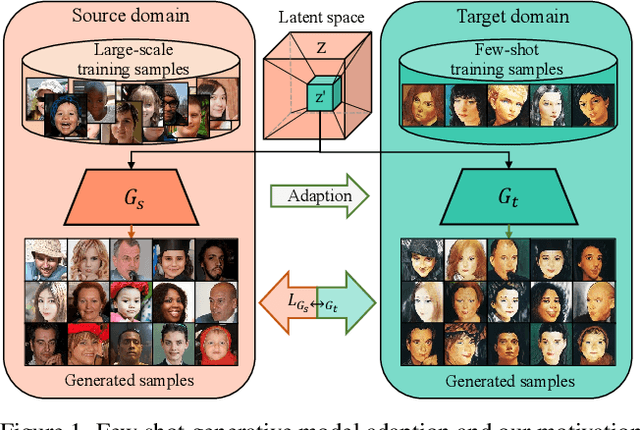
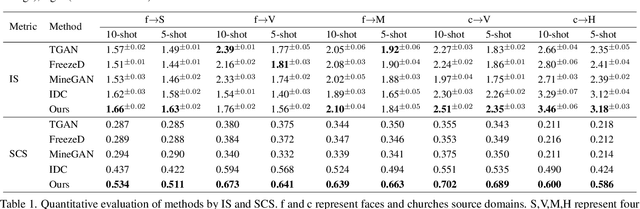
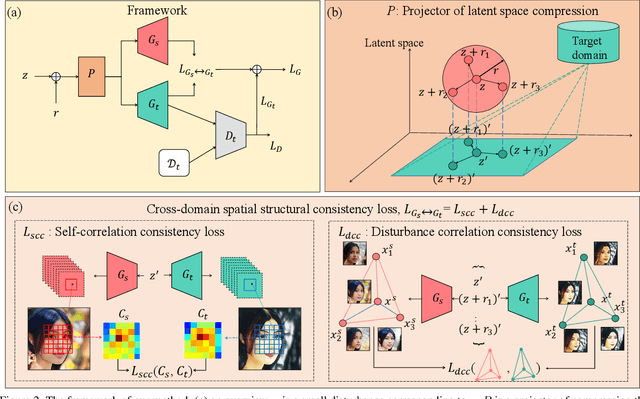

Training a generative adversarial network (GAN) with limited data has been a challenging task. A feasible solution is to start with a GAN well-trained on a large scale source domain and adapt it to the target domain with a few samples, termed as few shot generative model adaption. However, existing methods are prone to model overfitting and collapse in extremely few shot setting (less than 10). To solve this problem, we propose a relaxed spatial structural alignment method to calibrate the target generative models during the adaption. We design a cross-domain spatial structural consistency loss comprising the self-correlation and disturbance correlation consistency loss. It helps align the spatial structural information between the synthesis image pairs of the source and target domains. To relax the cross-domain alignment, we compress the original latent space of generative models to a subspace. Image pairs generated from the subspace are pulled closer. Qualitative and quantitative experiments show that our method consistently surpasses the state-of-the-art methods in few shot setting.
Prompt-based Generative Approach towards Multi-Hierarchical Medical Dialogue State Tracking
Mar 18, 2022
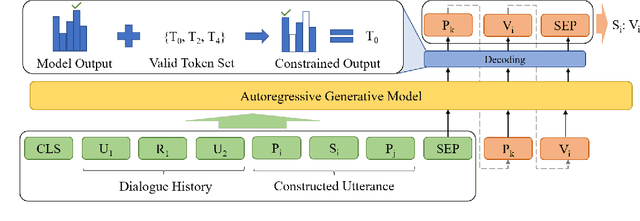


The medical dialogue system is a promising application that can provide great convenience for patients. The dialogue state tracking (DST) module in the medical dialogue system which interprets utterances into the machine-readable structure for downstream tasks is particularly challenging. Firstly, the states need to be able to represent compound entities such as symptoms with their body part or diseases with degrees of severity to provide enough information for decision support. Secondly, these named entities in the utterance might be discontinuous and scattered across sentences and speakers. These also make it difficult to annotate a large corpus which is essential for most methods. Therefore, we first define a multi-hierarchical state structure. We annotate and publish a medical dialogue dataset in Chinese. To the best of our knowledge, there are no publicly available ones before. Then we propose a Prompt-based Generative Approach which can generate slot values with multi-hierarchies incrementally using a top-down approach. A dialogue style prompt is also supplemented to utilize the large unlabeled dialogue corpus to alleviate the data scarcity problem. The experiments show that our approach outperforms other DST methods and is rather effective in the scenario with little data.
Graph Attention Retrospective
Apr 02, 2022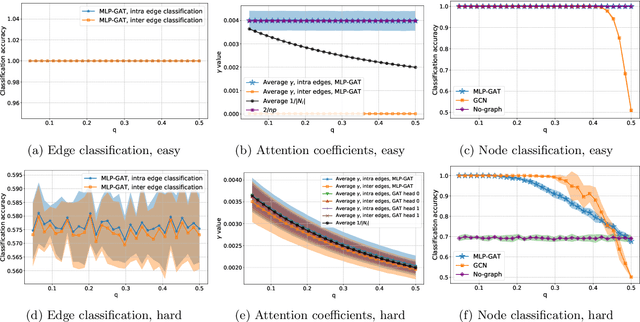
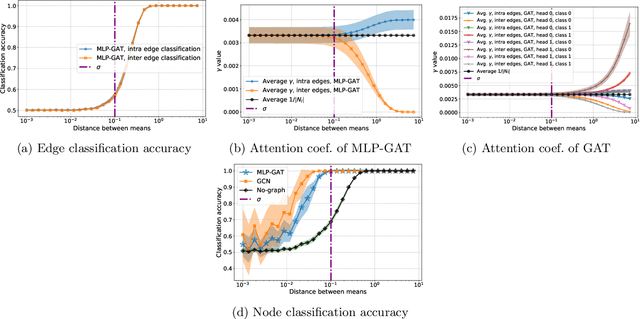
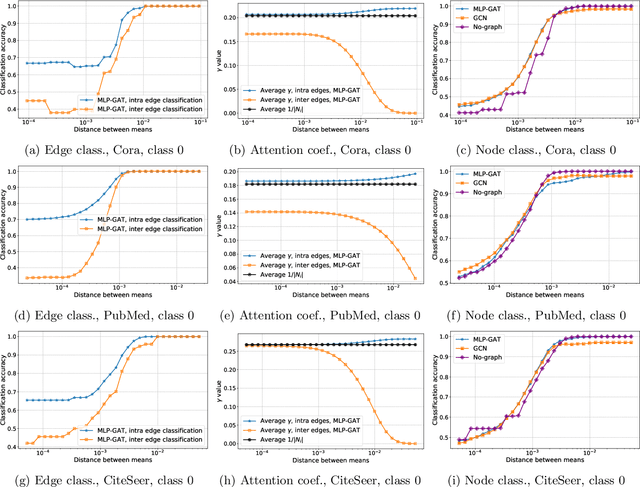
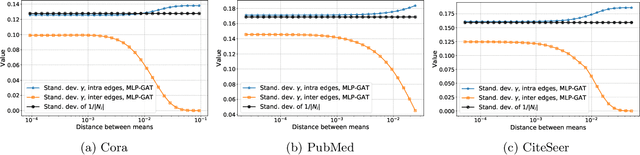
Graph-based learning is a rapidly growing sub-field of machine learning with applications in social networks, citation networks, and bioinformatics. One of the most popular type of models is graph attention networks. These models were introduced to allow a node to aggregate information from the features of neighbor nodes in a non-uniform way in contrast to simple graph convolution which does not distinguish the neighbors of a node. In this paper, we study theoretically this expected behaviour of graph attention networks. We prove multiple results on the performance of the graph attention mechanism for the problem of node classification for a contextual stochastic block model. Here the features of the nodes are obtained from a mixture of Gaussians and the edges from a stochastic block model where the features and the edges are coupled in a natural way. First, we show that in an "easy" regime, where the distance between the means of the Gaussians is large enough, graph attention maintains the weights of intra-class edges and significantly reduces the weights of the inter-class edges. As a corollary, we show that this implies perfect node classification independent of the weights of inter-class edges. However, a classical argument shows that in the "easy" regime, the graph is not needed at all to classify the data with high probability. In the "hard" regime, we show that every attention mechanism fails to distinguish intra-class from inter-class edges. We evaluate our theoretical results on synthetic and real-world data.
Grounding Commands for Autonomous Vehicles via Layer Fusion with Region-specific Dynamic Layer Attention
Mar 14, 2022
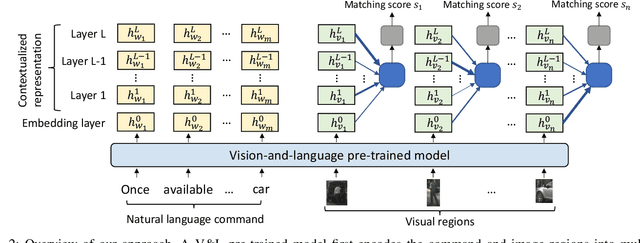
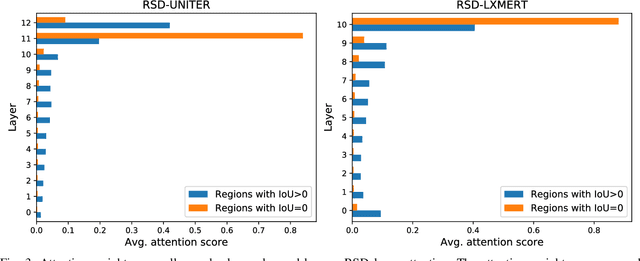
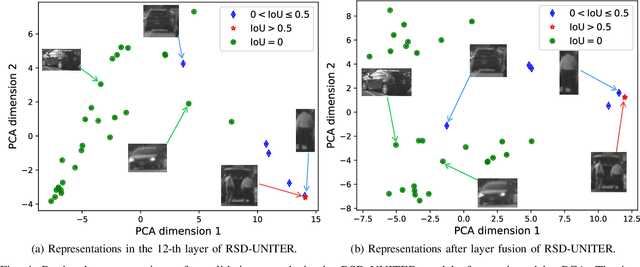
Grounding a command to the visual environment is an essential ingredient for interactions between autonomous vehicles and humans. In this work, we study the problem of language grounding for autonomous vehicles, which aims to localize a region in a visual scene according to a natural language command from a passenger. Prior work only employs the top layer representations of a vision-and-language pre-trained model to predict the region referred to by the command. However, such a method omits the useful features encoded in other layers, and thus results in inadequate understanding of the input scene and command. To tackle this limitation, we present the first layer fusion approach for this task. Since different visual regions may require distinct types of features to disambiguate them from each other, we further propose the region-specific dynamic (RSD) layer attention to adaptively fuse the multimodal information across layers for each region. Extensive experiments on the Talk2Car benchmark demonstrate that our approach helps predict more accurate regions and outperforms state-of-the-art methods.
BERT-ASC: Auxiliary-Sentence Construction for Implicit Aspect Learning in Sentiment Analysis
Mar 22, 2022
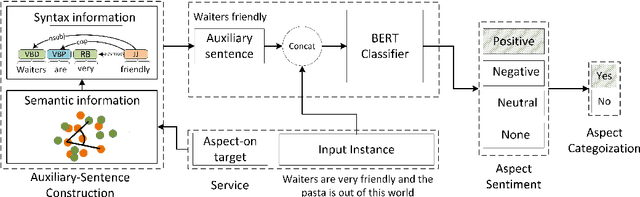
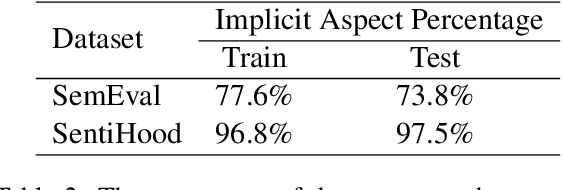

Aspect-based sentiment analysis (ABSA) task aims to associate a piece of text with a set of aspects and meanwhile infer their respective sentimental polarities. Up to now, the state-of-the-art approaches are built upon fine-tuning of various pre-trained language models. They commonly aim to learn the aspect-specific representation in the corpus. Unfortunately, the aspect is often expressed implicitly through a set of representatives and thus renders implicit mapping process unattainable unless sufficient labeled examples. In this paper, we propose to jointly address aspect categorization and aspect-based sentiment subtasks in a unified framework. Specifically, we first introduce a simple but effective mechanism that collaborates the semantic and syntactic information to construct auxiliary-sentences for the implicit aspect. Then, we encourage BERT to learn the aspect-specific representation in response to the automatically constructed auxiliary-sentence instead of the aspect itself. Finally, we empirically evaluate the performance of the proposed solution by a comparative study on real benchmark datasets for both ABSA and Targeted-ABSA tasks. Our extensive experiments show that it consistently achieves state-of-the-art performance in terms of aspect categorization and aspect-based sentiment across all datasets and the improvement margins are considerable.
Structure Extraction in Task-Oriented Dialogues with Slot Clustering
Mar 03, 2022


Extracting structure information from dialogue data can help us better understand user and system behaviors. In task-oriented dialogues, dialogue structure has often been considered as transition graphs among dialogue states. However, annotating dialogue states manually is expensive and time-consuming. In this paper, we propose a simple yet effective approach for structure extraction in task-oriented dialogues. We first detect and cluster possible slot tokens with a pre-trained model to approximate dialogue ontology for a target domain. Then we track the status of each identified token group and derive a state transition structure. Empirical results show that our approach outperforms unsupervised baseline models by far in dialogue structure extraction. In addition, we show that data augmentation based on extracted structures enriches the surface formats of training data and can achieve a significant performance boost in dialogue response generation.
Revisiting Neighborhood-based Link Prediction for Collaborative Filtering
Mar 29, 2022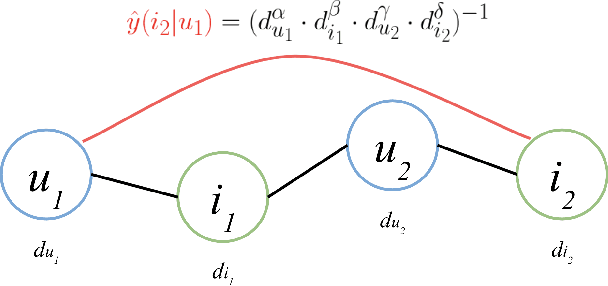
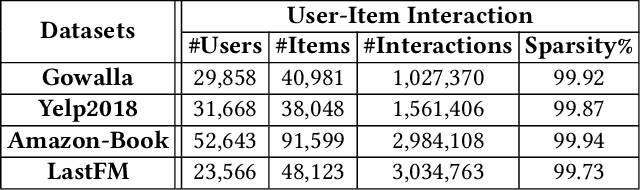
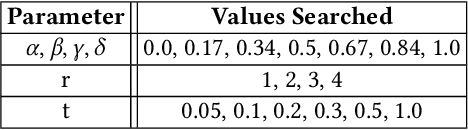
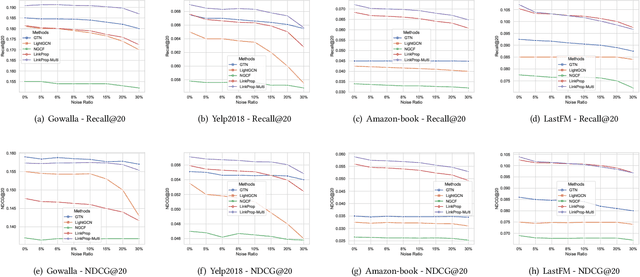
Collaborative filtering (CF) is one of the most successful and fundamental techniques in recommendation systems. In recent years, Graph Neural Network (GNN)-based CF models, such as NGCF [31], LightGCN [10] and GTN [9] have achieved tremendous success and significantly advanced the state-of-the-art. While there is a rich literature of such works using advanced models for learning user and item representations separately, item recommendation is essentially a link prediction problem between users and items. Furthermore, while there have been early works employing link prediction for collaborative filtering [5, 6], this trend has largely given way to works focused on aggregating information from user and item nodes, rather than modeling links directly. In this paper, we propose a new linkage (connectivity) score for bipartite graphs, generalizing multiple standard link prediction methods. We combine this new score with an iterative degree update process in the user-item interaction bipartite graph to exploit local graph structures without any node modeling. The result is a simple, non-deep learning model with only six learnable parameters. Despite its simplicity, we demonstrate our approach significantly outperforms existing state-of-the-art GNN-based CF approaches on four widely used benchmarks. In particular, on Amazon-Book, we demonstrate an over 60% improvement for both Recall and NDCG. We hope our work would invite the community to revisit the link prediction aspect of collaborative filtering, where significant performance gains could be achieved through aligning link prediction with item recommendations.